YOLOv6-4.0部分代码阅读笔记-common.py
common.py
yolov6\layers\common.py
目录
common.py
1.所需的库和模块
2.class SiLU(nn.Module):
3.class ConvModule(nn.Module):
4.class ConvBNReLU(nn.Module):
5.class ConvBNSiLU(nn.Module):
6.class ConvBN(nn.Module):
7.class ConvBNHS(nn.Module):
8.class SPPFModule(nn.Module):
9.class SimSPPF(nn.Module):
10.class SPPF(nn.Module):
11.class CSPSPPFModule(nn.Module):
12.class SimCSPSPPF(nn.Module):
13.class CSPSPPF(nn.Module):
14.class Transpose(nn.Module):
15.class RepVGGBlock(nn.Module):
16.class QARepVGGBlock(RepVGGBlock):
17.class QARepVGGBlockV2(RepVGGBlock):
18.class RealVGGBlock(nn.Module):
19.class ScaleLayer(torch.nn.Module):
20.class LinearAddBlock(nn.Module):
21.class DetectBackend(nn.Module):
22.class RepBlock(nn.Module):
23.class BottleRep(nn.Module):
24.class BottleRep3(nn.Module):
25.class BepC3(nn.Module):
26.class MBLABlock(nn.Module):
27.class BiFusion(nn.Module):
28.def get_block(mode):
29.class SEBlock(nn.Module):
30.def channel_shuffle(x, groups):
31.class Lite_EffiBlockS1(nn.Module):
32.class Lite_EffiBlockS2(nn.Module):
33.class DPBlock(nn.Module):
34.class DarknetBlock(nn.Module):
35.class CSPBlock(nn.Module):
1.所需的库和模块
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import os
import warnings
import numpy as np
from pathlib import Path
import torch
import torch.nn as nn
import torch.nn.init as init
from torch.nn.parameter import Parameter
from yolov6.utils.general import download_ckpt# 一个字典
activation_table = {'relu':nn.ReLU(),'silu':nn.SiLU(),'hardswish':nn.Hardswish()}2.class SiLU(nn.Module):
class SiLU(nn.Module):# SiLU 的激活。'''Activation of SiLU'''@staticmethoddef forward(x):return x * torch.sigmoid(x)3.class ConvModule(nn.Module):
class ConvModule(nn.Module):# Conv + BN + Activation 的组合。'''A combination of Conv + BN + Activation'''def __init__(self, in_channels, out_channels, kernel_size, stride, activation_type, padding=None, groups=1, bias=False):super().__init__()if padding is None:padding = kernel_size // 2 # 计算 填充 值大小。为保证特征图前后尺寸不变,一般padding值的大小为 :kernel_size // 2 。# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)# in_channels :输入的通道数,RGB 图像的输入通道数为 3。# out_channels :输出的通道数。# kernel_size :卷积核的大小。# stride = 1 :卷积核在图像窗口上每次平移的间隔,即所谓的步长。# padding :指图像填充,后面的int型常数代表填充的多少(行数、列数),默认为0。# dilation :是否采用空洞卷积,默认为1(不采用)。# groups :决定了是否采用分组卷积。# bias :即是否要添加偏置参数作为可学习参数的一个,默认为True。# padding_mode :即padding的模式,默认采用零填充。self.conv = nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bias=bias,)# torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)# PyTorch 提供的一个用于2D卷积层的批量归一化模块。它通过标准化每个小批量数据的均值和方差来稳定和加速训练过程。批量归一化可以缓解梯度消失或爆炸的问题,从而使得训练更加稳定和高效。# num_features :输入的通道数,即卷积层的输出通道数,即输入的特征图数量。# eps :一个小值,防止除以零,默认值为 1e-5。# momentum :动量因子,用于计算运行时的均值和方差,默认值为 0.1。# affine :若为 True,则该层会有可学习的缩放和偏移参数,默认为 True。# track_running_stats :若为 True,该层会跟踪运行时均值和方差;若为 False,则使用批量数据的统计值。self.bn = nn.BatchNorm2d(out_channels)if activation_type is not None:# dict.get(key, default=None)# key :字典中要查找的键。# default :键不存在时要返回的默认值,若不提供,则返回None。self.act = activation_table.get(activation_type)self.activation_type = activation_typedef forward(self, x):if self.activation_type is None:return self.bn(self.conv(x))return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):if self.activation_type is None:return self.conv(x)return self.act(self.conv(x))4.class ConvBNReLU(nn.Module):
class ConvBNReLU(nn.Module):# 带有 ReLU 激活的 Conv 和 BN。'''Conv and BN with ReLU activation'''def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, bias=False):super().__init__()self.block = ConvModule(in_channels, out_channels, kernel_size, stride, 'relu', padding, groups, bias)def forward(self, x):return self.block(x)5.class ConvBNSiLU(nn.Module):
class ConvBNSiLU(nn.Module):# 带有 SiLU 激活的 Conv 和 BN。'''Conv and BN with SiLU activation'''def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, bias=False):super().__init__()self.block = ConvModule(in_channels, out_channels, kernel_size, stride, 'silu', padding, groups, bias)def forward(self, x):return self.block(x)6.class ConvBN(nn.Module):
class ConvBN(nn.Module):# 无需激活函数的 Conv 和 BN'''Conv and BN without activation'''def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, bias=False):super().__init__()self.block = ConvModule(in_channels, out_channels, kernel_size, stride, None, padding, groups, bias)def forward(self, x):return self.block(x)7.class ConvBNHS(nn.Module):
class ConvBNHS(nn.Module):# 带有 Hardswish 激活的 Conv 和 BN'''Conv and BN with Hardswish activation'''def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, bias=False):super().__init__()self.block = ConvModule(in_channels, out_channels, kernel_size, stride, 'hardswish', padding, groups, bias)def forward(self, x):return self.block(x)8.class SPPFModule(nn.Module):
class SPPFModule(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=5, block=ConvBNReLU):super().__init__()c_ = in_channels // 2 # hidden channels 隐藏通道数self.cv1 = block(in_channels, c_, 1, 1)self.cv2 = block(c_ * 4, out_channels, 1, 1)# torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)# 对于输入信号的输入通道,提供2维最大池化(max pooling)操作。# 如果输入的大小是(N,C,H,W),那么输出的大小是(N,C,H_out,W_out)。# 参数:# kernel_size(int or tuple) :max pooling的窗口大小。# stride(int or tuple, optional) :max pooling的窗口移动的步长。默认值是kernel_size。# padding(int or tuple, optional) :输入的每一条边补充0的层数。# dilation(int or tuple, optional) :一个控制窗口中元素步幅的参数。# return_indices :如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助。# ceil_mode :如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作。self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size // 2)def forward(self, x):x = self.cv1(x)# 如果明知正在使用会引起警告的代码,比如某个废弃函数,但不想看到警告(即便警告已经通过命令行作了显式配置),那么可以使用 catch_warnings 上下文管理器来抑制警告。# 在上下文管理器中,所有的警告将被简单地忽略。这样就能使用已知的过时代码而又不必看到警告,同时也不会限制警告其他可能不知过时的代码。# 注意:只能保证在单线程应用程序中生效。如果两个以上的线程同时使用 catch_warnings 上下文管理器,行为不可预知。with warnings.catch_warnings():# warnings.simplefilter(action, category=Warning, lineno=0, append=False)# 在警告过滤器种类列表中插入一条简单数据项。warnings.simplefilter('ignore')y1 = self.m(x)y2 = self.m(y1)# torch.cat(tensors, dim=0, out=None)# torch.cat() :是一个非常实用的函数,用于将多个张量(Tensor)沿指定维度连接起来。# tensors :一个张量序列,可以是任何形式的Python序列,如列表或元组。# dim :要连接的维度。在PyTorch中,每个维度都有一个索引,从0开始。# out :可选参数,用于指定输出张量。return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))9.class SimSPPF(nn.Module):
class SimSPPF(nn.Module):# 带有 ReLU 激活的简化 SPPF'''Simplified SPPF with ReLU activation'''def __init__(self, in_channels, out_channels, kernel_size=5, block=ConvBNReLU):super().__init__()self.sppf = SPPFModule(in_channels, out_channels, kernel_size, block)def forward(self, x):return self.sppf(x)10.class SPPF(nn.Module):
class SPPF(nn.Module):# 带 SiLU 激活的 SPPF'''SPPF with SiLU activation'''def __init__(self, in_channels, out_channels, kernel_size=5, block=ConvBNSiLU):super().__init__()self.sppf = SPPFModule(in_channels, out_channels, kernel_size, block)def forward(self, x):return self.sppf(x)11.class CSPSPPFModule(nn.Module):
class CSPSPPFModule(nn.Module):# CSP https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, in_channels, out_channels, kernel_size=5, e=0.5, block=ConvBNReLU):super().__init__()c_ = int(out_channels * e) # hidden channels 隐藏通道self.cv1 = block(in_channels, c_, 1, 1)self.cv2 = block(in_channels, c_, 1, 1)self.cv3 = block(c_, c_, 3, 1)self.cv4 = block(c_, c_, 1, 1)self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size // 2)self.cv5 = block(4 * c_, c_, 1, 1)self.cv6 = block(c_, c_, 3, 1)self.cv7 = block(2 * c_, out_channels, 1, 1)def forward(self, x):x1 = self.cv4(self.cv3(self.cv1(x)))y0 = self.cv2(x)# 在警告过滤器种类列表中插入一条简单数据项。# 如果明知正在使用会引起警告的代码,比如某个废弃函数,但不想看到警告(即便警告已经通过命令行作了显式配置),那么可以使用 catch_warnings 上下文管理器来抑制警告。# 在上下文管理器中,所有的警告将被简单地忽略。这样就能使用已知的过时代码而又不必看到警告,同时也不会限制警告其他可能不知过时的代码。# 注意:只能保证在单线程应用程序中生效。如果两个以上的线程同时使用 catch_warnings 上下文管理器,行为不可预知。with warnings.catch_warnings():warnings.simplefilter('ignore')y1 = self.m(x1)y2 = self.m(y1)y3 = self.cv6(self.cv5(torch.cat([x1, y1, y2, self.m(y2)], 1)))return self.cv7(torch.cat((y0, y3), dim=1))12.class SimCSPSPPF(nn.Module):
class SimCSPSPPF(nn.Module):# 带 ReLU 激活的 CSPSPPF'''CSPSPPF with ReLU activation'''def __init__(self, in_channels, out_channels, kernel_size=5, e=0.5, block=ConvBNReLU):super().__init__()self.cspsppf = CSPSPPFModule(in_channels, out_channels, kernel_size, e, block)def forward(self, x):return self.cspsppf(x)13.class CSPSPPF(nn.Module):
class CSPSPPF(nn.Module):# 带 SiLU 激活的 CSPSPPF'''CSPSPPF with SiLU activation'''def __init__(self, in_channels, out_channels, kernel_size=5, e=0.5, block=ConvBNSiLU):super().__init__()self.cspsppf = CSPSPPFModule(in_channels, out_channels, kernel_size, e, block)def forward(self, x):return self.cspsppf(x)14.class Transpose(nn.Module):
class Transpose(nn.Module):# 正常转置,上采样的默认设置'''Normal Transpose, default for upsampling'''def __init__(self, in_channels, out_channels, kernel_size=2, stride=2):super().__init__()# torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros')# nn.ConvTranspose2d 是 PyTorch 中的一个模块,用于实现二维转置卷积(也称为反卷积或上采样卷积)。# 转置卷积通常用于生成比输入更大的输出,例如在生成对抗网络(GANs)和卷积神经网络(CNNs)的解码器部分。# in_channels :输入通道的数量。# out_channels :输出通道的数量。# kernel_size :卷积核的大小,可以是单个整数或是一个包含两个整数的元组。# stride :卷积的步长,默认为1。可以是单个整数或是一个包含两个整数的元组。# padding :输入的每一边补充0的数量,默认为0。# output_padding :输出的每一边额外补充0的数量,默认为0。用于控制输出的大小。# groups :将输入分成若干组,默认为1。# bias :如果为True,则会添加偏置,默认为True。# dilation :卷积核元素之间的间距,默认为1。# padding_mode :可选的填充模式,包括 ‘zeros’, ‘reflect’, ‘replicate’ 或 ‘circular’。默认为 ‘zeros’。self.upsample_transpose = torch.nn.ConvTranspose2d(in_channels=in_channels,out_channels=out_channels,kernel_size=kernel_size,stride=stride,bias=True)def forward(self, x):return self.upsample_transpose(x)15.class RepVGGBlock(nn.Module):
class RepVGGBlock(nn.Module):# RepVGGBlock 是一个基本的 rep 样式块,包括训练和部署状态# 本代码基于 https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py'''RepVGGBlock is a basic rep-style block, including training and deploy statusThis code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py'''# dilation :卷积的膨胀率,默认为1。# padding_mode :填充模式,默认为'zeros'。# deploy :布尔值,指示是否处于部署模式。 deploy 参数控制模块在训练模式和部署模式之间的切换。# use_se :布尔值,指示是否使用Squeeze-and-Excitation(SE)块,当前未实现。def __init__(self, in_channels, out_channels, kernel_size=3,stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):super(RepVGGBlock, self).__init__()""" Initialization of the class. 类的初始化。Args:in_channels (int): Number of channels in the input image 输入图像的通道数out_channels (int): Number of channels produced by the convolution 卷积产生的通道数kernel_size (int or tuple): Size of the convolving kernel 卷积核的大小stride (int or tuple, optional): Stride of the convolution. Default: 1 卷积的步长。默认值:1padding (int or tuple, optional): Zero-padding added to both sides of 在输入的两侧添加零填充。默认值:1the input. Default: 1dilation (int or tuple, optional): Spacing between kernel elements. Default: 1 内核元素之间的间距。默认值:1groups (int, optional): Number of blocked connections from input 从输入通道到输出通道的阻塞连接数。默认值:1channels to output channels. Default: 1padding_mode (string, optional): Default: 'zeros' 默认值:'zeros'deploy: Whether to be deploy status or training status. Default: False 是否为部署状态或训练状态。默认值:Falseuse_se: Whether to use se. Default: False 是否使用 se。默认值:False"""self.deploy = deployself.groups = groupsself.in_channels = in_channelsself.out_channels = out_channelsassert kernel_size == 3assert padding == 1padding_11 = padding - kernel_size // 2self.nonlinearity = nn.ReLU()if use_se:# 如果 use_se 为True,抛出未实现的异常。# 尚不支持 se block 。# 在Python中, NotImplementedError 是一个内置异常类,用于表示一个方法或函数应该被实现,但实际上并没有被实现。它通常用于抽象基类( ABC )中,作为占位符,提醒子类必须覆盖这个方法。raise NotImplementedError("se block not supported yet")else:# 否则,设置 self.se 为一个恒等映射( nn.Identity )。# nn.Identity()# 是 PyTorch 中的一个层(layer)。它实际上是一个恒等映射,不对输入进行任何变换或操作,只是简单地将输入返回作为输出。self.se = nn.Identity()if deploy:self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)else:# 如果输出通道数等于输入通道数且步长为1,创建一个批量归一化层。self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None# 创建一个 ConvModule ,用于3x3卷积。self.rbr_dense = ConvModule(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, activation_type=None, padding=padding, groups=groups)# 创建另一个 ConvModule ,用于1x1卷积,用于调整通道数。self.rbr_1x1 = ConvModule(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, activation_type=None, padding=padding_11, groups=groups)def forward(self, inputs):# 正向过程'''Forward process'''# hasattr(object, name)# 用于检查对象是否具有指定的属性。它接受两个参数:要检查属性的对象( object )和属性的名称( name )。如果对象具有指定的属性,则返回 True,否则返回 False。if hasattr(self, 'rbr_reparam'):return self.nonlinearity(self.se(self.rbr_reparam(inputs)))if self.rbr_identity is None:id_out = 0else:id_out = self.rbr_identity(inputs)return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))# 它用于计算 RepVGGBlock 中所有分支的等效卷积核和偏置。这个方法将不同分支(3x3卷积、1x1卷积和恒等映射)的权重和偏置合并,以得到一个等效的3x3卷积核和偏置,这样可以在部署模式下简化网络结构。def get_equivalent_kernel_bias(self): # get_equivalent_kernel_bias获得等效核偏置# 对3x3卷积分支调用 _fuse_bn_tensor 方法,获取其等效卷积核和偏置。kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)# 对1x1卷积分支调用 _fuse_bn_tensor 方法,获取其等效卷积核和偏置。kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)# 对恒等映射分支调用 _fuse_bn_tensor 方法,获取其等效卷积核和偏置。kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)# 将3x3卷积核、1x1卷积核(经过填充变为3x3大小)和恒等映射的卷积核相加,得到最终的等效卷积核。# 返回合并后的等效卷积核和偏置。# 调用 get_equivalent_kernel_bias 方法来获取等效的卷积核和偏置。这个方法在模型优化和部署时非常有用,因为它可以将多个分支合并为一个等效的卷积层,从而减少模型的复杂度。return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasiddef _avg_to_3x3_tensor(self, avgp):channels = self.in_channelsgroups = self.groupskernel_size = avgp.kernel_sizeinput_dim = channels // groupsk = torch.zeros((channels, input_dim, kernel_size, kernel_size))# np.arange([start=None], stop=None, [step=None], dtype=None)# 生成一个从 start (包含)到 stop (不包含),以 step 为步长的序列。返回一个 ndarray 对象。# 可以生成整型、浮点型序列,毫无压力。# 当 step 参数为非整数时(如 step=0.1 ),结果往往不一致。对于这些情况,最好使用“ linspace() ”函数。# 参数含义:# start :数值型,可选填。包含此值。默认为0。# stop :数值型,必填。不包含此值。除非 step 的值不是整数,浮点舍入会影响“ out ”的长度。# step :数值型,可选填。默认为1,如果步长有指定,则 start 必须给出来。# dtype :数据类型。输出的 array 数据类型。如果未指定 dtype ,则输出的 array 类型由其它的输入参数决定。# start 、 stop 、 step 若任一个为浮点型,那么都会生成一个浮点型序列。# np.tile(A,reps)# 函数可对输入的数组,元组或列表进行重复构造,其输出是数组。# 该函数有两个参数:# A :输入的数组,元组或列表。# reps :重复构造的形状,可为数组,元组或列表。k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2return k# 它用于将 1x1 卷积核的张量填充(pad)成 3x3 卷积核的形状。这通常用于在某些网络结构中将 1x1 卷积和 3x3 卷积的输出合并或者等效替换。# kernel1x1 :1x1 卷积核的张量。def _pad_1x1_to_3x3_tensor(self, kernel1x1):if kernel1x1 is None:return 0else:# torch.nn.functional.pad(input, pad, mode='xxx', value=x)# torch.nn.functional.pad 是 PyTorch 中用于对张量进行填充操作的函数。填充操作在处理图像、序列数据等任务时非常常见,它可以在张量的指定维度两端添加一定数量的元素,填充方式多样,包括零填充、常数填充、反射填充和边界填充等。# 返回一个新的张量,对输入张量进行了指定方式的填充。# input (Tensor) :输入的张量。# pad (tuple) :指定每个维度填充的数目。格式为 (left, right, top, bottom, …)。# mode (str, 可选) :填充模式,包括 constant (常数填充,默认)、 reflect (反射填充)、 replicate (边界填充)和 circular( 循环填充)。# value (float, 可选) :常数填充模式下填充值,仅当 mode 为 ‘ constant ’ 时有效,其他模式时即使指定了值也会被忽略掉。# 使用 torch.nn.functional.pad 函数对 kernel1x1 进行填充。填充的参数 [1, 1, 1, 1] 表示在张量的四个边缘分别填充 1 个单位的零。# 对于一个 1x1 卷积核,这将把它变成一个 3x3 卷积核的形状,但实际的卷积效果仍然是 1x1 的,因为所有的非原始部分都是零。# 返回填充后的 3x3 卷积核张量。return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])# 它用于融合卷积层和批量归一化层的权重和偏置。这种融合通常用于优化模型,在模型部署时减少运行时的计算量和内存消耗。# 1.branch :要融合的层,可以是 ConvModule 或 nn.BatchNorm2d 的实例。def _fuse_bn_tensor(self, branch):if branch is None:# 如果 branch 为 None ,则返回 (0, 0) ,表示没有融合任何层。return 0, 0# isinstance(object, classinfo) # 用于判断一个对象是否为指定类型或指定类型的子类。if isinstance(branch, ConvModule):# 如果 branch 是 ConvModule 的实例,直接返回其卷积层的权重 kernel 和偏置 bias 。kernel = branch.conv.weightbias = branch.conv.biasreturn kernel, biaselif isinstance(branch, nn.BatchNorm2d):# 如果 branch 是 nn.BatchNorm2d 的实例,执行以下操作。# hasattr(object, name)# 用于检查对象是否具有指定的属性。它接受两个参数:要检查属性的对象( object )和属性的名称( name )。如果对象具有指定的属性,则返回 True,否则返回 False。# 检查实例属性中是否已经有 id_tensor 。如果没有,将创建一个新的恒等核。if not hasattr(self, 'id_tensor'):# 计算每个组的输入通道数。input_dim = self.in_channels // self.groups# 创建一个形状为 (in_channels, input_dim, 3, 3) 的零矩阵,用于存储恒等核的值。kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)# 遍历输入通道,设置恒等核的对角线元素为1,实现恒等映射。for i in range(self.in_channels):kernel_value[i, i % input_dim, 1, 1] = 1# torch.from_numpy()# 函数用于将 NumPy 数组转换为 PyTorch 张量 Tensor 。这对于在 PyTorch 和 NumPy 之间进行数据转换非常有用,尤其是在处理已经使用 NumPy 构建的数据集时。# 将 NumPy 数组 kernel_value 转换为 PyTorch 张量,并将其移动到批量归一化层权重所在的设备(CPU或GPU)。self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensor# 获取批量归一化层的运行均值。running_mean = branch.running_mean# 获取批量归一化层的运行方差。running_var = branch.running_var# 获取批量归一化层的缩放因子(也称为权重)。gamma = branch.weight# 获取批量归一化层的偏移量(也称为偏置)。beta = branch.bias# 获取批量归一化层的epsilon值,用于数值稳定性。eps = branch.eps# math.sqrt(n)# n :为要计算平方根的数值。# 在Python编程中, sqrt() 函数是 math 模块中的一个函数,其功能是计算一个数的平方根。# 计算批量归一化层的标准差。std = (running_var + eps).sqrt()# 计算缩放因子除以标准差的值,并重塑为卷积核的形状。t = (gamma / std).reshape(-1, 1, 1, 1)# kernel * t :将恒等核与计算得到的 t 相乘,得到融合后的卷积核。# beta - running_mean * gamma / std :计算融合后的偏置。# 返回融合后的卷积核 kernel * t 和偏置 beta - running_mean * gamma / std 。return kernel * t, beta - running_mean * gamma / std# 它用于将 RepVGGBlock 从训练模式切换到部署模式。在部署模式下,网络结构会被简化,以便于推理时的效率。def switch_to_deploy(self):if hasattr(self, 'rbr_reparam'):# 如果已经有了 rbr_reparam 属性,说明已经在部署模式下,直接返回。return# 调用 get_equivalent_kernel_bias 方法计算所有分支的等效卷积核和偏置。# def get_equivalent_kernel_bias(self):# -> 它用于计算 RepVGGBlock 中所有分支的等效卷积核和偏置。这个方法将不同分支(3x3卷积、1x1卷积和恒等映射)的权重和偏置合并,以得到一个等效的3x3卷积核和偏置,这样可以在部署模式下简化网络结构。# -> 将3x3卷积核、1x1卷积核(经过填充变为3x3大小)和恒等映射的卷积核相加,得到最终的等效卷积核。# -> return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasidkernel, bias = self.get_equivalent_kernel_bias()# 创建一个新的 nn.Conv2d 层 self.rbr_reparam ,其参数与 self.rbr_dense 相同,但额外添加了 bias=True 以包含偏置项。self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)# 将计算得到的等效卷积核赋值给 self.rbr_reparam 的权重。self.rbr_reparam.weight.data = kernel# 将计算得到的等效偏置赋值给 self.rbr_reparam 的偏置。self.rbr_reparam.bias.data = bias# 遍历所有参数,并调用 para.detach_() 方法将它们从当前计算图中分离,这样它们就不会在后续的推理中被梯度更新。for para in self.parameters():# model.parameters()# 在PyTorch中, .parameters() 是 torch.nn.Module 类的一个实例方法,用于返回模型中所有参数的迭代器。这个方法通常用于在模型训练和推理中获取参数,尤其是在需要对参数进行操作(如梯度清零、参数更新等)时。# 参数 : 无参数。# 返回值 : 返回一个迭代器,包含模型中所有的参数( tensor )。# .parameters() 方法非常有用,因为它允许你 :# 遍历参数 :遍历模型中的所有参数,这在自定义优化器或进行特殊的参数操作时非常有用。# 梯度清零 :在训练循环中,通常需要清零梯度,可以通过 .zero_() 方法直接在参数上调用。# 参数更新 :在自定义训练循环中,可以手动更新参数。# 参数统计 :统计模型中的参数数量,例如计算模型的总参数量。# .detach() 是 PyTorch 中用于从计算图中分离张量的方法。当我们在 PyTorch 中进行张量运算时,操作会构建一个计算图来跟踪计算历史,这个计算图用于自动求导和反向传播来计算梯度。# 使用 .detach() 方法可以将一个张量从当前的计算图中分离出来,使其变成一个不再需要梯度追踪的普通张量,即使它是由需要梯度的操作创建的。这样做有时可以避免梯度传播,也可以用于获取不需要梯度的张量副本。para.detach_()# __delattr__# 在Python中, __delattr__ 是一个特殊方法(也称为魔术方法或双下划线方法),它在尝试删除对象的属性时被调用。当你使用 del 语句来删除一个对象的属性时,Python会自动调用这个方法来执行删除操作。# __delattr__ 方法接受一个参数,即要删除的属性的名称(通常是一个字符串)。你可以在这个方法中自定义属性删除的行为。# 删除 self.rbr_dense 和 self.rbr_1x1 分支,因为它们在部署模式下不再需要。self.__delattr__('rbr_dense')self.__delattr__('rbr_1x1')if hasattr(self, 'rbr_identity'):# 如果存在 self.rbr_identity 分支,也将其删除。self.__delattr__('rbr_identity')if hasattr(self, 'id_tensor'):# 如果存在 self.id_tensor ,也将其删除。self.__delattr__('id_tensor')# 设置标志表明现在处于部署模式。self.deploy = True16.class QARepVGGBlock(RepVGGBlock):
class QARepVGGBlock(RepVGGBlock):"""RepVGGBlock 是一个基本的 rep 样式块,包括训练和部署状态。RepVGGBlock is a basic rep-style block, including training and deploy status此代码基于https://arxiv.org/abs/2212.01593This code is based on https://arxiv.org/abs/2212.01593"""def __init__(self, in_channels, out_channels, kernel_size=3,stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):super(QARepVGGBlock, self).__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups,padding_mode, deploy, use_se)if not deploy:self.bn = nn.BatchNorm2d(out_channels)self.rbr_1x1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, groups=groups, bias=False)self.rbr_identity = nn.Identity() if out_channels == in_channels and stride == 1 else Noneself._id_tensor = Nonedef forward(self, inputs):if hasattr(self, 'rbr_reparam'):return self.nonlinearity(self.bn(self.se(self.rbr_reparam(inputs))))if self.rbr_identity is None:id_out = 0else:id_out = self.rbr_identity(inputs)return self.nonlinearity(self.bn(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)))# 定义了一个名为 get_equivalent_kernel_bias 的方法,它用于计算 RepVGGBlock 中所有分支的等效卷积核和偏置。这个方法将3x3卷积、1x1卷积和恒等映射(如果存在)的权重和偏置合并,以得到一个等效的3x3卷积核和偏置。def get_equivalent_kernel_bias(self): # get_equivalent_kernel_bias获得等效核偏置# 对3x3卷积分支调用 _fuse_bn_tensor 方法,获取其等效卷积核和偏置。# def _fuse_bn_tensor(self, branch):# -> 它用于融合卷积层和批量归一化层的权重和偏置。这种融合通常用于优化模型,在模型部署时减少运行时的计算量和内存消耗。返回融合后的卷积核 kernel * t 和偏置 beta - running_mean * gamma / std 。# -> return kernel * t, beta - running_mean * gamma / stdkernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)# 将3x3卷积核与1x1卷积核(经过填充变为3x3大小)相加,得到初步的等效卷积核。# def _pad_1x1_to_3x3_tensor(self, kernel1x1):# -> 它用于将 1x1 卷积核的张量填充(pad)成 3x3 卷积核的形状。这通常用于在某些网络结构中将 1x1 卷积和 3x3 卷积的输出合并或者等效替换。# -> 返回填充后的 3x3 卷积核张量。# -> return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])kernel = kernel3x3 + self._pad_1x1_to_3x3_tensor(self.rbr_1x1.weight)# 将3x3卷积的偏置作为等效偏置。bias = bias3x3# 如果 self.rbr_identity 不为 None ,则计算恒等核。if self.rbr_identity is not None:# 计算每个组的输入通道数。input_dim = self.in_channels // self.groups# 创建一个形状为 (in_channels, input_dim, 3, 3) 的零矩阵,用于存储恒等核的值。kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)# 遍历输入通道。for i in range(self.in_channels):# 设置恒等核的对角线元素为1,实现恒等映射。kernel_value[i, i % input_dim, 1, 1] = 1# 将 NumPy 数组 kernel_value 转换为 PyTorch 张量,并将其移动到1x1卷积权重所在的设备(CPU或GPU)。id_tensor = torch.from_numpy(kernel_value).to(self.rbr_1x1.weight.device)# 将恒等核添加到初步的等效卷积核中。kernel = kernel + id_tensor# 返回合并后的等效卷积核 kernel 和偏置 bias 。return kernel, bias# _fuse_extra_bn_tensor 的方法,它用于将一个卷积核与额外的批量归一化层(Batch Normalization layer)融合。这种融合通常用于优化模型,在模型部署时减少运行时的计算量和内存消耗。# 1.kernel :卷积核的权重张量。# 2.bias :卷积核的偏置张量。# 3.branch :要融合的批量归一化层,预期是一个 nn.BatchNorm2d 的实例。def _fuse_extra_bn_tensor(self, kernel, bias, branch):# isinstance(object, classinfo) # 用于判断一个对象是否为指定类型或指定类型的子类。# 断言检查,确保传入的 branch 确实是 nn.BatchNorm2d 类型的实例。assert isinstance(branch, nn.BatchNorm2d)# 从批量归一化层的运行均值中减去卷积层的偏置,以去除偏置的影响。running_mean = branch.running_mean - bias # remove bias 去除偏置# 获取批量归一化层的运行方差。running_var = branch.running_var# 获取批量归一化层的缩放因子(也称为权重)。gamma = branch.weight# 获取批量归一化层的偏移量(也称为偏置)。beta = branch.bias# 获取批量归一化层的epsilon值,用于数值稳定性。eps = branch.eps# 计算批量归一化层的标准差。std = (running_var + eps).sqrt()# 计算缩放因子除以标准差的值,并重塑为卷积核的形状。t = (gamma / std).reshape(-1, 1, 1, 1)# beta - running_mean * gamma / std :计算去除均值偏移后的偏置。# 返回 :融合后的卷积核 kernel * t 和偏置 beta - running_mean * gamma / std 。return kernel * t, beta - running_mean * gamma / std# 定义了一个名为 switch_to_deploy 的方法,它用于将 QARepVGGBlock 从训练模式切换到部署模式。在部署模式下,网络结构会被简化,以便于推理时的效率。def switch_to_deploy(self):if hasattr(self, 'rbr_reparam'):# 如果已经有了 rbr_reparam 属性,说明已经在部署模式下,直接返回。return# 调用 get_equivalent_kernel_bias 方法计算所有分支的等效卷积核和偏置。# def get_equivalent_kernel_bias(self):# -> 它用于计算 RepVGGBlock 中所有分支的等效卷积核和偏置。这个方法将不同分支(3x3卷积、1x1卷积和恒等映射)的权重和偏置合并,以得到一个等效的3x3卷积核和偏置,这样可以在部署模式下简化网络结构。# -> 将3x3卷积核、1x1卷积核(经过填充变为3x3大小)和恒等映射的卷积核相加,得到最终的等效卷积核。# -> return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasidkernel, bias = self.get_equivalent_kernel_bias()# 创建一个新的 nn.Conv2d 层 self.rbr_reparam ,其参数与 self.rbr_dense 相同,但额外添加了 bias=True 以包含偏置项。self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)# 将计算得到的等效卷积核赋值给 self.rbr_reparam 的权重。self.rbr_reparam.weight.data = kernel# 将计算得到的等效偏置赋值给 self.rbr_reparam 的偏置。self.rbr_reparam.bias.data = biasfor para in self.parameters():# 遍历所有参数,并调用 para.detach_() 方法将它们从当前计算图中分离,这样它们就不会在后续的推理中被梯度更新。para.detach_()# 删除 self.rbr_dense 和 self.rbr_1x1 分支,因为它们在部署模式下不再需要。self.__delattr__('rbr_dense')self.__delattr__('rbr_1x1')if hasattr(self, 'rbr_identity'):# 如果存在 self.rbr_identity 分支,也将其删除。self.__delattr__('rbr_identity')if hasattr(self, 'id_tensor'):# 如果存在 self.id_tensor ,也将其删除。self.__delattr__('id_tensor')# keep post bn for QAT# if hasattr(self, 'bn'):# self.__delattr__('bn')# 设置标志表明现在处于部署模式。self.deploy = True17.class QARepVGGBlockV2(RepVGGBlock):
class QARepVGGBlockV2(RepVGGBlock):"""RepVGGBlock 是一个基本的 rep 样式块,包括训练和部署状态。RepVGGBlock is a basic rep-style block, including training and deploy status此代码基于https://arxiv.org/abs/2212.01593This code is based on https://arxiv.org/abs/2212.01593"""def __init__(self, in_channels, out_channels, kernel_size=3,stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):super(QARepVGGBlockV2, self).__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups,padding_mode, deploy, use_se)if not deploy:self.bn = nn.BatchNorm2d(out_channels)self.rbr_1x1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, groups=groups, bias=False)# nn.Identity()# 是 PyTorch 中的一个层(layer)。它实际上是一个恒等映射,不对输入进行任何变换或操作,只是简单地将输入返回作为输出。self.rbr_identity = nn.Identity() if out_channels == in_channels and stride == 1 else None# torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)# 对信号的输入通道,提供2维的平均池化(average pooling )。# 如果 padding 不是0,会在输入的每一边添加相应数目0。# 参数 :# kernel_size(int or tuple) :池化窗口大小。# stride(int or tuple, optional) :max pooling的窗口移动的步长。默认值是kernel_size。# padding(int or tuple, optional) :输入的每一条边补充0的层数。# dilation(int or tuple, optional) :一个控制窗口中元素步幅的参数。# ceil_mode :如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作。# count_include_pad :如果等于True,计算平均池化时,将包括padding填充的0。# shape :# input :(N,C,H_in,W_in)# output :(N,C,H_out,W_out)# H_out = [(H_in+2×padding[0]-kernel_size[0])/(stride[0])+1] W_out = [(W_in+2×padding[1]-kernel_size[1])/(stride[1])+1]self.rbr_avg = nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding) if out_channels == in_channels and stride == 1 else Noneself._id_tensor = Nonedef forward(self, inputs):if hasattr(self, 'rbr_reparam'):return self.nonlinearity(self.bn(self.se(self.rbr_reparam(inputs))))if self.rbr_identity is None:id_out = 0else:id_out = self.rbr_identity(inputs)if self.rbr_avg is None:avg_out = 0else:avg_out = self.rbr_avg(inputs)return self.nonlinearity(self.bn(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out + avg_out)))def get_equivalent_kernel_bias(self): # get_equivalent_kernel_bias获得等效核偏置kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)kernel = kernel3x3 + self._pad_1x1_to_3x3_tensor(self.rbr_1x1.weight)if self.rbr_avg is not None:kernelavg = self._avg_to_3x3_tensor(self.rbr_avg)kernel = kernel + kernelavg.to(self.rbr_1x1.weight.device)bias = bias3x3if self.rbr_identity is not None:input_dim = self.in_channels // self.groupskernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)for i in range(self.in_channels):kernel_value[i, i % input_dim, 1, 1] = 1id_tensor = torch.from_numpy(kernel_value).to(self.rbr_1x1.weight.device)kernel = kernel + id_tensorreturn kernel, biasdef _fuse_extra_bn_tensor(self, kernel, bias, branch): # _fuse_extra_bn_tensor融合额外的 bn 张量assert isinstance(branch, nn.BatchNorm2d)running_mean = branch.running_mean - bias # remove bias 去除偏置running_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta - running_mean * gamma / stddef switch_to_deploy(self): # switch_to_deploy切换到部署if hasattr(self, 'rbr_reparam'):returnkernel, bias = self.get_equivalent_kernel_bias()self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)# torch.nn.Conv2d.weight.data# torch.nn.Conv2d.bias.data# 为 torch.tensor 类型。自定义 weight 和 bias 为需要的数均分布类型,只要对这两个属性进行操作即可。self.rbr_reparam.weight.data = kernelself.rbr_reparam.bias.data = biasfor para in self.parameters():para.detach_()self.__delattr__('rbr_dense')self.__delattr__('rbr_1x1')if hasattr(self, 'rbr_identity'):self.__delattr__('rbr_identity')if hasattr(self, 'rbr_avg'):self.__delattr__('rbr_avg')if hasattr(self, 'id_tensor'):self.__delattr__('id_tensor')# keep post bn for QAT# if hasattr(self, 'bn'):# self.__delattr__('bn')self.deploy = True18.class RealVGGBlock(nn.Module):
class RealVGGBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,dilation=1, groups=1, padding_mode='zeros', use_se=False,):super(RealVGGBlock, self).__init__()self.relu = nn.ReLU()self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False)self.bn = nn.BatchNorm2d(out_channels)if use_se:# NotImplementedError()# 在Python中, NotImplementedError 是一个内置异常类,用于表示一个方法或函数应该被实现,但实际上并没有被实现。它通常用于抽象基类( ABC )中,作为占位符,提醒子类必须覆盖这个方法。raise NotImplementedError("se block not supported yet")else:self.se = nn.Identity()def forward(self, inputs):out = self.relu(self.se(self.bn(self.conv(inputs))))return out19.class ScaleLayer(torch.nn.Module):
class ScaleLayer(torch.nn.Module):def __init__(self, num_features, use_bias=True, scale_init=1.0):super(ScaleLayer, self).__init__()# nn.Parameter()# 对于 nn.Parameter() 是pytorch中定义可学习参数的一种方法,因为我们在搭建网络时,网络中会存在一些矩阵,这些矩阵内部的参数是可学习的,也就是可梯度求导的。# torch.nn.Parameter 继承 torch.Tensor ,其作用将一个不可训练的类型为 Tensor 的参数转化为可训练的类型为 parameter 的参数,# 并将这个参数绑定到 module 里面,成为 module 中可训练的参数。self.weight = Parameter(torch.Tensor(num_features))# torch.nn.init.constant_(tensor, val)# 参数说明:# tensor:需要初始化的张量。# val:要设置的常数值。# nn.init.constant_ 函数将输入的张量(tensor)中的所有元素初始化为指定的常数值。这个函数通常用于初始化神经网络的权重( weights )和偏置( biases )参数。init.constant_(self.weight, scale_init)self.num_features = num_featuresif use_bias:# torch.tensor()# torch.Tensor()# 通过 Tensor 建立数组有 torch.tensor([1,2]) 或 torch.Tensor([1,2]) 两种方式。那么,这两种方式有什么 区别 呢?# torch.tensor 是从数据中推断数据类型,而 torch.Tensor 是 torch.empty (会随机产生数组)和 torch.tensor 之间的一种混合。但是,当传入数据时, torch.Tensor 使用全局默认dtype( FloatTensor )。# torch.tensor(1) 返回一个固定值1,而 torch.Tensor(1) 返回一个大小为1的张量,它是初始化的随机值。self.bias = Parameter(torch.Tensor(num_features))# nn.init.zeros_(a)# 初始化a为0。init.zeros_(self.bias)else:self.bias = None# 这段代码定义了一个 forward 方法,它是一个神经网络模块的前向传播函数。这个方法通常用于 nn.Module 的子类中,以定义如何处理输入数据并产生输出。# inputs :输入数据,预期是一个 PyTorch 张量。def forward(self, inputs):# 检查是否存在偏置项 self.bias 。如果 self.bias 为 None ,则表示没有偏置项。if self.bias is None:# 如果没有偏置项,将输入数据 inputs 与权重 self.weight 相乘。权重被重塑为 (1, self.num_features, 1, 1) 以匹配输入数据的维度,从而实现逐特征通道的缩放。return inputs * self.weight.view(1, self.num_features, 1, 1)else:# 如果存在偏置项,则执行以下操作。# 将输入数据 inputs 与权重 self.weight 相乘,并加上偏置项 self.bias 。权重和偏置都被重塑为 (1, self.num_features, 1, 1) 以匹配输入数据的维度,从而实现逐特征通道的缩放和偏移。return inputs * self.weight.view(1, self.num_features, 1, 1) + self.bias.view(1, self.num_features, 1, 1)
20.class LinearAddBlock(nn.Module):
# CSLA 块是具有 is_csla=True 的 LinearAddBlock
# A CSLA block is a LinearAddBlock with is_csla=True
class LinearAddBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,dilation=1, groups=1, padding_mode='zeros', use_se=False, is_csla=False, conv_scale_init=1.0):super(LinearAddBlock, self).__init__()self.in_channels = in_channelsself.relu = nn.ReLU()self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False)self.scale_conv = ScaleLayer(num_features=out_channels, use_bias=False, scale_init=conv_scale_init)self.conv_1x1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=0, bias=False)self.scale_1x1 = ScaleLayer(num_features=out_channels, use_bias=False, scale_init=conv_scale_init)if in_channels == out_channels and stride == 1:self.scale_identity = ScaleLayer(num_features=out_channels, use_bias=False, scale_init=1.0)self.bn = nn.BatchNorm2d(out_channels)if is_csla: # Make them constant 使它们恒定# p.requires_grad_(False)# requires_grad_() 这个函数的作用是改变 requires_grad 属性并返回tensor,修改 requires_grad 属性是 inplace 操作,默认参数为 requires_grad=True 。# 在 PyTorch 中,tensor 不设置 requires_grad 和设置 requires_grad=False 的区别在于是否需要计算梯度。# 当一个 tensor 不设置 requires_grad 时,默认值为 False,表示该 tensor 不需要计算梯度。# 这种情况下,PyTorch 不会构建用于计算 tensor 梯度的计算图,因此也不会计算 tensor 的梯度。# 而当一个 tensor 设置 requires_grad=False 时,表示该 tensor 明确地告知 PyTorch 不需要计算梯度。# 这种情况下,PyTorch 不会为该 tensor 计算梯度,从而节省计算资源。# 需要注意的是,如果一个 tensor 设置了 requires_grad=True,那么其依赖的所有 tensor 也会自动设置为 requires_grad=True 。# 这是因为这些 tensor 在计算梯度时都是必要的。因此,如果我们需要对某个 tensor 计算梯度,那么它所依赖的所有 tensor 也需要计算梯度。self.scale_1x1.requires_grad_(False)self.scale_conv.requires_grad_(False)if use_se:raise NotImplementedError("se block not supported yet")else:self.se = nn.Identity()def forward(self, inputs):out = self.scale_conv(self.conv(inputs)) + self.scale_1x1(self.conv_1x1(inputs))if hasattr(self, 'scale_identity'):out += self.scale_identity(inputs)out = self.relu(self.se(self.bn(out)))return out21.class DetectBackend(nn.Module):
class DetectBackend(nn.Module):def __init__(self, weights='yolov6s.pt', device=None, dnn=True):super().__init__()# os.path.exists(path)# path :表示文件系统路径的类路径对象。类路径对象是表示路径的字符串或字节对象。# 返回类型 :此方法返回一个类 bool 的布尔值。如果 path 存在,此方法返回 True ,否则返回 False 。if not os.path.exists(weights):# def download_ckpt(path): -> 下载预训练模型的检查点download_ckpt(weights) # try to download model from github automatically. 尝试自动从 github 下载模型。# .suffix# suffix 函数是 Python 内置的字符串函数之一,用于判断一个字符串是否以指定的后缀结尾。它的基本语法如下:# str.endswith(suffix[, start[, end]])# 其中,参数 suffix 是要判断的后缀,参数 start 和 end 可选,用于指定判断的起始位置和结束位置。如果字符串以 suffix 结尾,该函数返回 True ,否则返回 False 。assert isinstance(weights, str) and Path(weights).suffix == '.pt', f'{Path(weights).suffix} format is not supported.' # 不支持 {Path(weights).suffix} 格式。from yolov6.utils.checkpoint import load_checkpoint# def load_checkpoint(weights, map_location=None, inplace=True, fuse=True): -> 从检查点文件加载模型。 -> return modelmodel = load_checkpoint(weights, map_location=device)stride = int(model.stride.max())# locals()# locals() 函数会以字典类型返回当前位置的全部局部变量。# self.__dict__.update# dict.update(dict2) update() 函数把字典 dict2 的键/值对更新到 dict 里。# .__dict__ 查看对象的属性。# obj.__dict__.update() 批量更新属性时使用。self.__dict__.update(locals()) # assign all variables to self 将所有变量赋值给自身def forward(self, im, val=False):y, _ = self.model(im)if isinstance(y, np.ndarray):y = torch.tensor(y, device=self.device)return y
22.class RepBlock(nn.Module):
class RepBlock(nn.Module):# RepBlock 是具有 rep 样式基本块的阶段块'''RepBlock is a stage block with rep-style basic block'''def __init__(self, in_channels, out_channels, n=1, block=RepVGGBlock, basic_block=RepVGGBlock):super().__init__()self.conv1 = block(in_channels, out_channels)self.block = nn.Sequential(*(block(out_channels, out_channels) for _ in range(n - 1))) if n > 1 else Noneif block == BottleRep:self.conv1 = BottleRep(in_channels, out_channels, basic_block=basic_block, weight=True)n = n // 2self.block = nn.Sequential(*(BottleRep(out_channels, out_channels, basic_block=basic_block, weight=True) for _ in range(n - 1))) if n > 1 else Nonedef forward(self, x):x = self.conv1(x)if self.block is not None:x = self.block(x)return x23.class BottleRep(nn.Module):
class BottleRep(nn.Module):def __init__(self, in_channels, out_channels, basic_block=RepVGGBlock, weight=False):super().__init__()self.conv1 = basic_block(in_channels, out_channels)self.conv2 = basic_block(out_channels, out_channels)if in_channels != out_channels:self.shortcut = Falseelse:self.shortcut = Trueif weight:# nn.Parameter()# 对于 nn.Parameter() 是pytorch中定义可学习参数的一种方法,因为我们在搭建网络时,网络中会存在一些矩阵,这些矩阵内部的参数是可学习的,也就是可梯度求导的。# torch.nn.Parameter 继承 torch.Tensor ,其作用将一个不可训练的类型为 Tensor 的参数转化为可训练的类型为 parameter 的参数,# 并将这个参数绑定到 module 里面,成为 module 中可训练的参数。# torch.ones(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor# 返回创建 size 大小的维度,里面元素全部填充为1。self.alpha = Parameter(torch.ones(1))else:self.alpha = 1.0def forward(self, x):outputs = self.conv1(x)outputs = self.conv2(outputs)return outputs + self.alpha * x if self.shortcut else outputs24.class BottleRep3(nn.Module):
class BottleRep3(nn.Module):def __init__(self, in_channels, out_channels, basic_block=RepVGGBlock, weight=False):super().__init__()self.conv1 = basic_block(in_channels, out_channels)self.conv2 = basic_block(out_channels, out_channels)self.conv3 = basic_block(out_channels, out_channels)if in_channels != out_channels:self.shortcut = Falseelse:self.shortcut = Trueif weight:self.alpha = Parameter(torch.ones(1))else:self.alpha = 1.0def forward(self, x):outputs = self.conv1(x)outputs = self.conv2(outputs)outputs = self.conv3(outputs)return outputs + self.alpha * x if self.shortcut else outputs25.class BepC3(nn.Module):
class BepC3(nn.Module):# CSPStackRep 块'''CSPStackRep Block'''def __init__(self, in_channels, out_channels, n=1, e=0.5, block=RepVGGBlock):super().__init__()c_ = int(out_channels * e) # hidden channels 隐藏通道self.cv1 = ConvBNReLU(in_channels, c_, 1, 1)self.cv2 = ConvBNReLU(in_channels, c_, 1, 1)self.cv3 = ConvBNReLU(2 * c_, out_channels, 1, 1)if block == ConvBNSiLU:self.cv1 = ConvBNSiLU(in_channels, c_, 1, 1)self.cv2 = ConvBNSiLU(in_channels, c_, 1, 1)self.cv3 = ConvBNSiLU(2 * c_, out_channels, 1, 1)self.m = RepBlock(in_channels=c_, out_channels=c_, n=n, block=BottleRep, basic_block=block)def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))26.class MBLABlock(nn.Module):
class MBLABlock(nn.Module):# 多分支层聚合块''' Multi Branch Layer Aggregation Block'''def __init__(self, in_channels, out_channels, n=1, e=0.5, block=RepVGGBlock):super().__init__()n = n // 2if n <= 0:n = 1# max add one branch 最多添加一个分支if n == 1:n_list = [0, 1]else:extra_branch_steps = 1while extra_branch_steps * 2 < n:extra_branch_steps *= 2n_list = [0, extra_branch_steps, n]branch_num = len(n_list)c_ = int(out_channels * e) # hidden channels 隐藏通道self.c = c_self.cv1 = ConvModule(in_channels, branch_num * self.c, 1, 1, 'relu', bias=False)self.cv2 = ConvModule((sum(n_list) + branch_num) * self.c, out_channels, 1, 1,'relu', bias=False)if block == ConvBNSiLU:self.cv1 = ConvModule(in_channels, branch_num * self.c, 1, 1, 'silu', bias=False)self.cv2 = ConvModule((sum(n_list) + branch_num) * self.c, out_channels, 1, 1,'silu', bias=False)# nn.ModuleList()# 在PyTorch中,nn.ModuleList 是一个容器,用于包含子模块(nn.Module)的列表。self.m = nn.ModuleList()for n_list_i in n_list[1:]:# nn.Sequential()# 是一个序列容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到容器中。# 利用 nn.Sequential() 搭建好模型架构,模型前向传播时调用 forward() 方法,模型接收的输入首先被传入 nn.Sequential() 包含的第一个网络模块中。# 然后,第一个网络模块的输出传入第二个网络模块作为输入,按照顺序依次计算并传播,直到 nn.Sequential() 里的最后一个模块输出结果。self.m.append(nn.Sequential(*(BottleRep3(self.c, self.c, basic_block=block, weight=True) for _ in range(n_list_i))))# tuple(iterable)# iterable :要转换为元组的可迭代序列。# Python 元组 tuple() 函数将列表转换为元组。self.split_num = tuple([self.c]*branch_num)def forward(self, x):# str.split(str="", num=string.count(str))# 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串。# str :分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。y = list(self.cv1(x).split(self.split_num, 1))all_y = [y[0]]for m_idx, m_i in enumerate(self.m):all_y.append(y[m_idx+1])all_y.extend(m(all_y[-1]) for m in m_i)return self.cv2(torch.cat(all_y, 1))27.class BiFusion(nn.Module):
class BiFusion(nn.Module):# PAN 中的 BiFusion 块'''BiFusion Block in PAN'''def __init__(self, in_channels, out_channels):super().__init__()self.cv1 = ConvBNReLU(in_channels[0], out_channels, 1, 1)self.cv2 = ConvBNReLU(in_channels[1], out_channels, 1, 1)self.cv3 = ConvBNReLU(out_channels * 3, out_channels, 1, 1)self.upsample = Transpose(in_channels=out_channels,out_channels=out_channels,)self.downsample = ConvBNReLU(in_channels=out_channels,out_channels=out_channels,kernel_size=3,stride=2)def forward(self, x):x0 = self.upsample(x[0])x1 = self.cv1(x[1])x2 = self.downsample(self.cv2(x[2]))return self.cv3(torch.cat((x0, x1, x2), dim=1))28.def get_block(mode):
def get_block(mode):# 如果 mode 是 'repvgg' ,返回 RepVGGBlock 类。# 如果 mode 是 'qarepvgg' ,返回 QARepVGGBlock 类。# 如果 mode 是 'qarepvggv2' ,返回 QARepVGGBlockV2 类。# 如果 mode 是 'hyper_search' ,返回 LinearAddBlock 类。# 如果 mode 是 'repopt' ,返回 RealVGGBlock 类。# 如果 mode 是 'conv_relu' ,返回 ConvBNReLU 类。# 如果 mode 是 'conv_silu' ,返回 ConvBNSiLU 类。if mode == 'repvgg':return RepVGGBlockelif mode == 'qarepvgg':return QARepVGGBlockelif mode == 'qarepvggv2':return QARepVGGBlockV2elif mode == 'hyper_search':return LinearAddBlockelif mode == 'repopt':return RealVGGBlockelif mode == 'conv_relu':return ConvBNReLUelif mode == 'conv_silu':return ConvBNSiLUelse:# 未定义的 Repblock 选择模式 {}raise NotImplementedError("Undefied Repblock choice for mode {}".format(mode))29.class SEBlock(nn.Module):
class SEBlock(nn.Module):def __init__(self, channel, reduction=4):super().__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv1 = nn.Conv2d(in_channels=channel,out_channels=channel // reduction,kernel_size=1,stride=1,padding=0)self.relu = nn.ReLU()self.conv2 = nn.Conv2d(in_channels=channel // reduction,out_channels=channel,kernel_size=1,stride=1,padding=0)self.hardsigmoid = nn.Hardsigmoid()def forward(self, x):identity = xx = self.avg_pool(x)x = self.conv1(x)x = self.relu(x)x = self.conv2(x)x = self.hardsigmoid(x)out = identity * xreturn out30.def channel_shuffle(x, groups):
# 它用于对输入张量 x 进行通道洗牌(channel shuffle)操作。通道洗牌是一种常用的技巧,特别是在分组卷积中,用于提高信息在不同分组之间的流动性,从而提高网络的性能。
# 1.x :输入的张量,预期是一个四维张量,格式为 (batchsize, num_channels, height, width) 。
# 2.groups :整数,表示将输入张量的通道分成多少组进行洗牌。
def channel_shuffle(x, groups):# 获取输入张量的 批次大小 、 通道数 、 高度 和 宽度 。batchsize, num_channels, height, width = x.data.size() #图像的size() :批量大小、通道数、高、宽。# 计算每组应该包含的通道数。channels_per_group = num_channels // groups# reshape# view()# 相当于reshape、resize,重新调整Tensor的形状。# 将输入张量重新整理成 (batchsize, groups, channels_per_group, height, width) 的形状。x = x.view(batchsize, groups, channels_per_group, height, width)# torch.transpose(input, dim0, dim1)# input :待交换维度的张量。# dim0 :第一个要交换的维度。# dim1 :第二个要交换的维度。# torch.transpose 函数用于交换给定张量的两个维度。# .contiguous()# 方法的作用是确保张量在内存中是连续存储的,为了避免不必要的性能损失。# 对张量进行转置操作,交换 groups 和 channels_per_group 的位置,实现通道洗牌。 contiguous() 方法用于确保张量在内存中是连续的,这是进行某些操作(如转置)的前提。x = torch.transpose(x, 1, 2).contiguous()# flatten 展平。# 将洗牌后的张量展平回 (batchsize, num_channels, height, width) 的形状,其中 num_channels 现在是洗牌后的通道数。# 返回通道洗牌后的张量 x 。x = x.view(batchsize, -1, height, width)# 洗牌后的张量 shuffled_x 保持了原始的形状,但通道的顺序已经被打乱。这种方法在提高网络性能和减少信息在分组卷积中的损失方面非常有用。return x31.class Lite_EffiBlockS1(nn.Module):
class Lite_EffiBlockS1(nn.Module):def __init__(self,in_channels,mid_channels,out_channels,stride):super().__init__()self.conv_pw_1 = ConvBNHS(in_channels=in_channels // 2,out_channels=mid_channels,kernel_size=1,stride=1,padding=0,groups=1)self.conv_dw_1 = ConvBN(in_channels=mid_channels,out_channels=mid_channels,kernel_size=3,stride=stride,padding=1,groups=mid_channels)self.se = SEBlock(mid_channels)self.conv_1 = ConvBNHS(in_channels=mid_channels,out_channels=out_channels // 2,kernel_size=1,stride=1,padding=0,groups=1)# 这个方法描述了一个特定的网络结构,其中输入被分割,分别通过不同的卷积层处理,然后重新组合并进行通道洗牌。# inputs :输入数据,预期是一个 PyTorch 张量。def forward(self, inputs):# torch.split(tensor, split_size_or_sections, dim=0)# tensor :要拆分的张量。# split_size_or_sections :一个整数或者一个包含每个子张量大小的列表。# 当为 整数 时,表示每个子张量的大小,最后一个子张量可能会小于这个大小。# 当为 列表 时,表示每个子张量的大小。# dim :沿着哪个维度进行拆分,默认值为0。# 将输入张量 inputs 在通道维度( dim=1 )上分割成两个相等的部分, x1 和 x2 。x1, x2 = torch.split(inputs,split_size_or_sections=[inputs.shape[1] // 2, inputs.shape[1] // 2],dim=1)# 将 x2 通过一个点卷积(pointwise convolution)层 conv_pw_1 进行处理。x2 = self.conv_pw_1(x2)# 将 x2 的输出通过一个深度卷积(depthwise convolution)层 conv_dw_1 进行处理。x3 = self.conv_dw_1(x2)# 将 x3 的输出通过一个 squeeze-and-excitation(SE)块 se 进行处理,以增强特征的表示能力。x3 = self.se(x3)x3 = self.conv_1(x3)# 将原始的 x1 和处理后的 x3 在通道维度( axis=1 )上进行拼接。out = torch.cat([x1, x3], axis=1)# 对拼接后的输出 out 进行通道洗牌, 2 表示将通道分成两组进行洗牌。# 返回通道洗牌后的输出张量。return channel_shuffle(out, 2)32.class Lite_EffiBlockS2(nn.Module):
class Lite_EffiBlockS2(nn.Module):def __init__(self,in_channels,mid_channels,out_channels,stride):super().__init__()# branch1self.conv_dw_1 = ConvBN(in_channels=in_channels,out_channels=in_channels,kernel_size=3,stride=stride,padding=1,groups=in_channels)self.conv_1 = ConvBNHS(in_channels=in_channels,out_channels=out_channels // 2,kernel_size=1,stride=1,padding=0,groups=1)# branch2self.conv_pw_2 = ConvBNHS(in_channels=in_channels,out_channels=mid_channels // 2,kernel_size=1,stride=1,padding=0,groups=1)self.conv_dw_2 = ConvBN(in_channels=mid_channels // 2,out_channels=mid_channels // 2,kernel_size=3,stride=stride,padding=1,groups=mid_channels // 2)self.se = SEBlock(mid_channels // 2)self.conv_2 = ConvBNHS(in_channels=mid_channels // 2,out_channels=out_channels // 2,kernel_size=1,stride=1,padding=0,groups=1)self.conv_dw_3 = ConvBNHS(in_channels=out_channels,out_channels=out_channels,kernel_size=3,stride=1,padding=1,groups=out_channels)self.conv_pw_3 = ConvBNHS(in_channels=out_channels,out_channels=out_channels,kernel_size=1,stride=1,padding=0,groups=1)def forward(self, inputs):x1 = self.conv_dw_1(inputs)x1 = self.conv_1(x1)x2 = self.conv_pw_2(inputs)x2 = self.conv_dw_2(x2)x2 = self.se(x2)x2 = self.conv_2(x2)out = torch.cat([x1, x2], axis=1)out = self.conv_dw_3(out)out = self.conv_pw_3(out)return out33.class DPBlock(nn.Module):
class DPBlock(nn.Module):def __init__(self,in_channel=96,out_channel=96,kernel_size=3,stride=1):super().__init__()self.conv_dw_1 = nn.Conv2d(in_channels=in_channel,out_channels=out_channel,kernel_size=kernel_size,groups=out_channel,padding=(kernel_size - 1) // 2,stride=stride)self.bn_1 = nn.BatchNorm2d(out_channel)self.act_1 = nn.Hardswish()self.conv_pw_1 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel,kernel_size=1,groups=1,padding=0)self.bn_2 = nn.BatchNorm2d(out_channel)self.act_2 = nn.Hardswish()def forward(self, x):x = self.act_1(self.bn_1(self.conv_dw_1(x)))x = self.act_2(self.bn_2(self.conv_pw_1(x)))return xdef forward_fuse(self, x):x = self.act_1(self.conv_dw_1(x))x = self.act_2(self.conv_pw_1(x))return x
34.class DarknetBlock(nn.Module):
class DarknetBlock(nn.Module):def __init__(self,in_channels,out_channels,kernel_size=3,expansion=0.5):super().__init__()hidden_channels = int(out_channels * expansion)self.conv_1 = ConvBNHS(in_channels=in_channels,out_channels=hidden_channels,kernel_size=1,stride=1,padding=0)self.conv_2 = DPBlock(in_channel=hidden_channels,out_channel=out_channels,kernel_size=kernel_size,stride=1)def forward(self, x):out = self.conv_1(x)out = self.conv_2(out)return out35.class CSPBlock(nn.Module):
class CSPBlock(nn.Module):def __init__(self,in_channels,out_channels,kernel_size=3,expand_ratio=0.5):super().__init__()mid_channels = int(out_channels * expand_ratio)self.conv_1 = ConvBNHS(in_channels, mid_channels, 1, 1, 0)self.conv_2 = ConvBNHS(in_channels, mid_channels, 1, 1, 0)self.conv_3 = ConvBNHS(2 * mid_channels, out_channels, 1, 1, 0)self.blocks = DarknetBlock(mid_channels,mid_channels,kernel_size,1.0)def forward(self, x):x_1 = self.conv_1(x)x_1 = self.blocks(x_1)x_2 = self.conv_2(x)x = torch.cat((x_1, x_2), axis=1)x = self.conv_3(x)return x相关文章:

YOLOv6-4.0部分代码阅读笔记-common.py
common.py yolov6\layers\common.py 目录 common.py 1.所需的库和模块 2.class SiLU(nn.Module): 3.class ConvModule(nn.Module): 4.class ConvBNReLU(nn.Module): 5.class ConvBNSiLU(nn.Module): 6.class ConvBN(nn.Module): 7.class ConvBNHS(nn.Module): …...

移植 AWTK 到 纯血鸿蒙 (HarmonyOS NEXT) 系统 (4) - 平台适配
在移植 AWTK 到 HarmonyOS NEXT 系统之前,我们需要先完成平台适配,比如文件、多线程(线程和同步)、时间、动态库和资源管理。 1. 文件 HarmonyOS NEXT 支持标准的 POSIX 文件操作接口,我们可以直接使用下面的代码&am…...

Java 多线程(八)—— 锁策略,synchronized 的优化,JVM 与编译器的锁优化,ReentrantLock,CAS
前言 本文为 Java 面试小八股,一句话,理解性记忆,不能理解就死背吧。 锁策略 悲观锁与乐观锁 悲观锁和乐观锁是锁的特性,并不是特指某个具体的锁。 我们知道在多线程中,锁是会被竞争的,悲观锁就是指锁…...
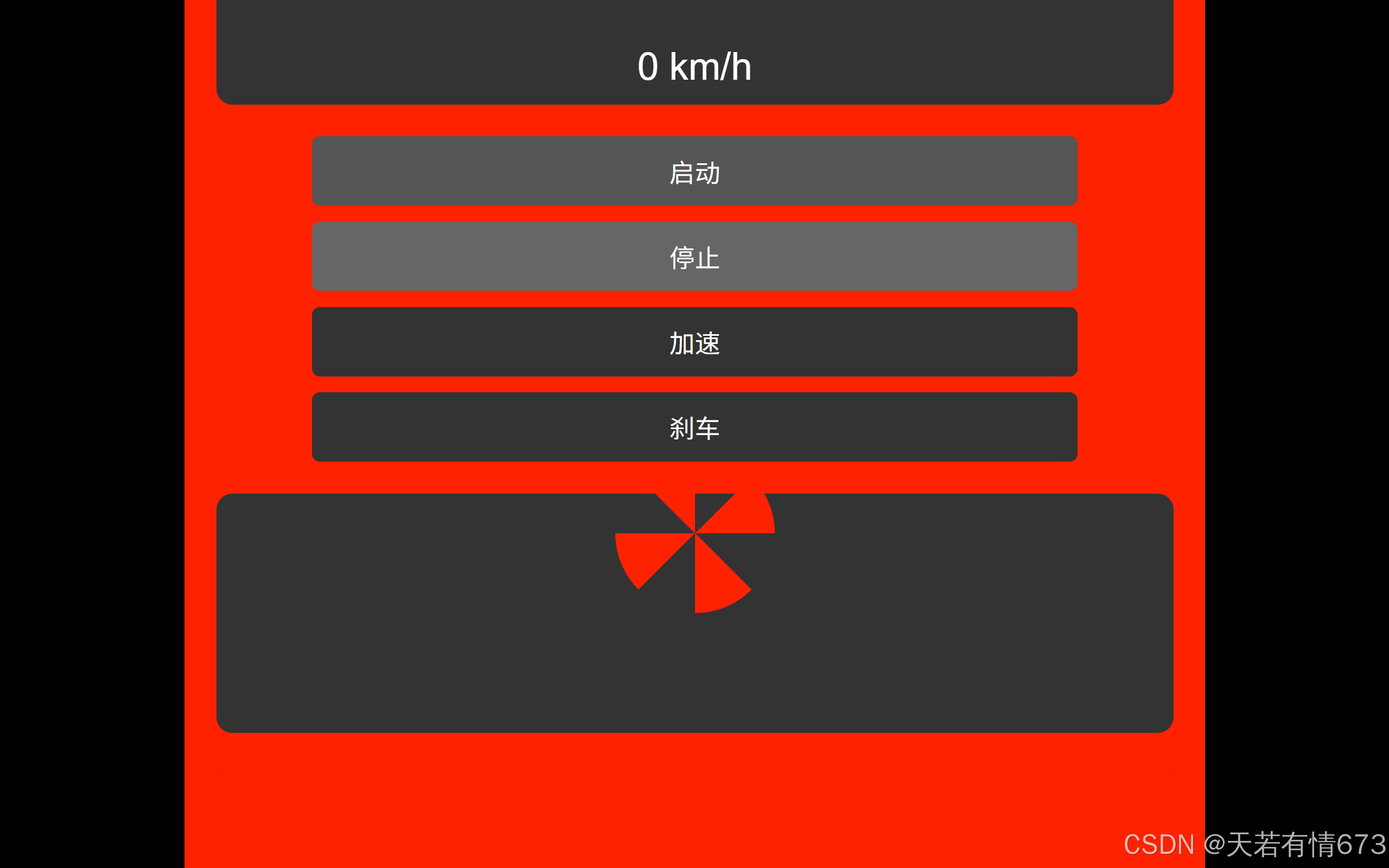
【项目分享】法拉利中控台模拟 html+css+js
引入: 制作一个模拟法拉利中控台的网页是一个有趣且富有挑战性的项目。为了简化这个任务,我们可以使用一些HTML、CSS和JavaScript来实现一个基本的界面。以下是一个简单的示例,展示了如何创建一个基本的法拉利中控台模拟网页。 效果展示&…...

Rust 力扣 - 2461. 长度为 K 子数组中的最大和
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 我们遍历长度为k的窗口,用一个哈希表记录窗口内的所有元素(用来对窗口内元素去重),我们取哈希表中元素数量等于k的窗口总和的最大值 题解代码 use std::collecti…...
)
stm32103c8t6 pwm驱动舵机(SG90)
本方法采用通用定时器(TIM2、TIM3、TIM4、TIM5)实现 代码: PWM.h #ifndef __PWM_H // 防止头文件重复包含 #define __PWM_H#include "stm32f10x.h" // 包含STM32F10x系列的设备头文件// 函数声明 void TIM2_PWM_In…...

Python For循环
Python 的 for 循环是自动化重复任务的强大工具,可以使代码更高效、更易于管理。本教程将解释 for 循环的工作原理,探讨不同的应用场景,并提供大量实用示例。无论你是初学者还是希望提升技能的开发者,这些示例都将帮助你更好地在 …...

C++入门——“C++11-右值引用和移动语义”
C11相比于C98增加以许多新特性,让C语言更加灵活好用,但是貌似也增加了许多学习的难度,现在先看第一部分。 一、右值引用和移动语义 1.右值引用和左值引用 在C中,值可以大致分为右值和左值,左值大概是哪些已经被定义的变…...

timm使用笔记
timm(Timm is a model repository for PyTorch)是一个 PyTorch 原生实现的计算机视觉模型库。它提供了预训练模型和各种网络组件,可以用于各种计算机视觉任务,例如图像分类、物体检测、语义分割等等。timm(库提供了预训…...

android浏览器源码 可输入地址或关键词搜索 android studio 2024 可开发可改地址
Android 浏览器是一种运行在Android操作系统上的应用程序,主要用于访问和查看互联网内容。以下是关于Android浏览器的详细介绍: 1. 基本功能 Android浏览器提供了用户浏览网页的基本功能,如: 网页加载:支持加载静态…...

贪心算法入门(一)
1.什么是贪心算法? 贪心算法是一种解决问题的策略,它将复杂的问题分解为若干个步骤,并在每一步都选择当前最优的解决方案,最终希望能得到全局最优解。这种策略的核心在于“最优”二字,意味着我们追求的是以最少的时间和…...

C# ref和out 有什么区别,分别用在那种场景
在C#中,ref和out都是用于按引用传递参数的关键字,但它们有一些细微的差别和使用场景。 ref 关键字 ref 关键字用于按引用传递参数。这意味着当你将一个变量作为参数传递给一个方法时,你不是传递变量的值,而是传递变量的引用。因…...

TikTok直播专线:提升直播效果和体验
作为当今全球最受欢迎的社交媒体平台之一,TikTok为商家提供了无限的商机和市场。然而,商家在使用TikTok时也面临着许多挑战,如网络延迟、直播中断以及账号被封等问题。TikTok直播专线旨在为商家提供高速稳定的网络连接,助力他们在…...

由浅入深逐步理解spring boot中如何实现websocket
实现websocket的方式 1.springboot中有两种方式实现websocket,一种是基于原生的基于注解的websocket,另一种是基于spring封装后的WebSocketHandler 基于原生注解实现websocket 1)先引入websocket的starter坐标 <dependency><grou…...
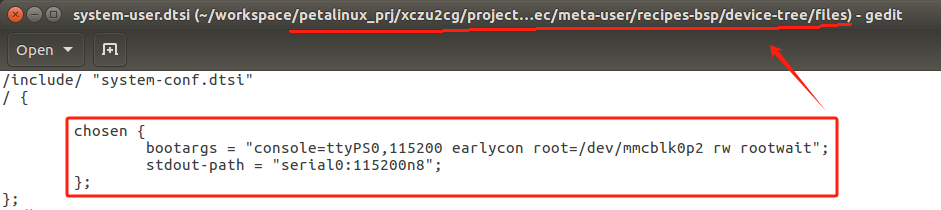
1-petalinux 问题记录-根文件系统分区问题
在MPSOC上使用SD第二分区配置根文件系统的时候,需要选择对应的bootargs,但是板子上有emmc和sd两个区域,至于配置哪一种mmcblk0就出现了问题,从vivado中的BlockDesign和MLK XCZU2CG原理图来看的话,我使用的SD卡应该属于…...

微信小程序的上拉刷新与下拉刷新
效果图如下: 上拉刷新 与 下拉刷新 代码如下: joked.wxml <scroll-view class"scroll" scroll-y refresher-enabled refresher-default-style"white" bindrefresherrefresh"onRefresh" refresher-triggered&qu…...

【大语言模型】ACL2024论文-05 GenTranslate: 大型语言模型是生成性多语种语音和机器翻译器
【大语言模型】ACL2024论文-05 GenTranslate: 大型语言模型是生成性多语种语音和机器翻译器 GenTranslate: 大型语言模型是生成性多语种语音和机器翻译器 目录 文章目录 【大语言模型】ACL2024论文-05 GenTranslate: 大型语言模型是生成性多语种语音和机器翻译器目录摘要研究背…...

KPRCB结构之ReadySummary和DispatcherReadyListHead
ReadySummary: Uint4B DispatcherReadyListHead : [32] _LIST_ENTRY 请参考 _KTHREAD *__fastcall KiSelectReadyThread(ULONG LowPriority, _KPRCB *Prcb)...

批处理之for语句从入门到精通--呕血整理
文章目录 一、前言二、for语句的基本用法三、文本解析显神威:for /f 用法详解四、翻箱倒柜遍历文件夹:for /r五、仅仅为了匹配第一层目录而存在:for /d六、计数循环:for /l后记 for语句从入门到精通 一、前言 在批处理中&#…...
pycharm小游戏贪吃蛇及pygame模块学习()
由于代码量大,会逐渐发布 一.pycharm学习 在PyCharm中使用Pygame插入音乐和图片时,有以下这些注意事项: 插入音乐: - 文件格式支持:Pygame常用的音乐格式如MP3、OGG等,但MP3可能需额外安装库…...

让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略
让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager 还在为足球经理游戏中千篇一律…...

Perplexity学校信息检索的“黑箱”终于被打开:基于37所样本校实测的响应延迟、召回率与可信度三维评估报告
更多请点击: https://codechina.net 第一章:Perplexity学校信息检索的“黑箱”终于被打开:基于37所样本校实测的响应延迟、召回率与可信度三维评估报告 实测方法论:三维度穿透式评估框架 我们对全国37所高校(含985/2…...
)
技术文档检索总失败?Perplexity的chunking策略、embedding模型选型与rerank阈值调优(附实测Benchmark数据)
更多请点击: https://codechina.net 第一章:技术文档检索总失败?Perplexity的chunking策略、embedding模型选型与rerank阈值调优(附实测Benchmark数据) 技术文档检索失败常源于文本切分不合理、语义表征能力不足或重排…...

别再乱设Public了!Minio权限控制实战:从用户、分组到自定义策略的完整配置流程
别再乱设Public了!Minio权限控制实战:从用户、分组到自定义策略的完整配置流程 在分布式存储系统的日常运维中,权限配置不当引发的数据泄露事件屡见不鲜。最近某科技公司因对象存储桶误设为公开访问,导致数万份客户资料暴露的案例…...

实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s
实测Llama3 8B在国产AI盒子上的推理速度:算丰SG2300x Airbox跑出9.6 token/s 当Meta开源Llama3大模型的消息席卷AI社区时,一个更实际的问题浮出水面:如何让这个性能怪兽在边缘设备上真正跑起来?我们拿到搭载算丰SG2300x芯片的Radx…...

高端工程场景实测:OpenAI Codex CLI 在微服务重构中的 3 类能力边界
1. 微服务重构现场:Codex CLI 不是万能胶,但能精准补上三块关键拼图 我接手一个运行了四年的电商微服务集群时,它正卡在「订单履约链路」的重构临界点上。17个服务、32个跨服务调用点、4种异步消息协议、2套数据库分片策略——人工梳理接口契约要两周,写迁移脚本要三天,验…...

STM32驱动OV7670摄像头,从寄存器配置到LCD显示的避坑全记录
STM32与OV7670摄像头实战:从寄存器配置到LCD显示的全链路解析 1. 项目背景与硬件架构设计 在嵌入式视觉系统中,OV7670作为一款低成本CMOS图像传感器,与STM32的组合常被用于智能门禁、工业检测等场景。本项目的核心挑战在于解决传感器输出数据…...

GitHub网络加速终极指南:如何实现10倍下载速度的智能优化方案
GitHub网络加速终极指南:如何实现10倍下载速度的智能优化方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾…...

源地工作室ESP32-S2核心板深度体验:与乐鑫官方DevKitM-1到底有啥区别?
ESP32-S2核心板深度横评:第三方与官方开发板的硬核抉择指南 在物联网设备开发领域,ESP32-S2凭借其出色的性价比和丰富的功能接口,已成为众多开发者的首选芯片平台。面对市场上琳琅满目的开发板选项,特别是第三方厂商推出的兼容板与…...

黑苹果配置复杂化挑战:OCAT跨平台管理工具的智能化解决方案
黑苹果配置复杂化挑战:OCAT跨平台管理工具的智能化解决方案 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 面对日益复杂…...