从0开始学python-day17-数据结构2
2.3 队列
队列(Queue),它是一种运算受限的线性表,先进先出(FIFO First In First Out)
-
队列是一种受限的线性结构
-
受限之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作

Python标准库中的queue模块提供了多种队列实现,包括普通队列、双端队列、优先队列等。
当两个程序效率不一样时,可以用队列作为缓冲池(提高系统性能,把同步操作变成异步操作)。生产者-消费者模式。
redis:可以存数组,
2.3.1 普通队列
queue.Queue 是 Python 标准库 queue 模块中的一个类,适用于多线程环境。它实现了线程安全的 FIFO(先进先出)队列。
案例:
import queue q = queue.Queue() q.put(1) q.put(3) q.put(2) print(q.qsize()) print(q.get()) print(q.get()) print(q.get())
2.3.2 双端队列
双端队列(Deque,Double-Ended Queue)是一种具有队列和栈性质的数据结构,它允许我们在两端进行元素的添加(push)和移除(pop)操作。在Python中,双端队列可以通过collections模块中的deque类来实现。
deque是一个双端队列的实现,它提供了在两端快速添加和移除元素的能力。
案例:
from collections import deque q = deque() q.append(1) q.append(2) q.appendleft(3) q.appendleft(4) print(q.pop()) print(q.popleft())
当结合使用appendleft和popleft时,你实际上是在实现一个栈(Stack)的数据结构,因为栈是后进先出(LIFO)的,而这两个操作正好模拟了栈的“压栈”和“弹栈”行为。append和pop结合使用同理。
2.3.3 优先队列
优先队列(Priority Queue)是一种特殊的队列,其中的元素按照优先级进行排序。优先级最高的元素总是最先出队。Python 标准库中提供了 queue.PriorityQueue 和 heapq 模块来实现优先队列。
queue.PriorityQueue
queue.PriorityQueue 是 Python 标准库 queue 模块中的一个类,适用于多线程环境。它实现了线程安全的优先队列。
案例:
import queue q = queue.PriorityQueue() # 向队列中添加元素,元素是一个元组 (priority, item),其中 priority 是优先级,item 是实际的数据 q.put((1,'item1')) q.put((3,'item3')) q.put((2,'item2')) print(q.get()) print(q.get()) print(q.get())
heapq
heapq 模块是 Python 标准库中的一个模块,提供了基于堆的优先队列实现。heapq 模块不是线程安全的,适用于单线程环境。
案例:
import heapq # 创建一个列表作为堆 heap = [] # 向堆中添加元素,元素是一个元组 (priority, item) heapq.heappush(heap, (3, 'Task 3')) heapq.heappush(heap, (1, 'Task 1')) heapq.heappush(heap, (2, 'Task 2')) # 从堆中取出元素 print(heapq.heappop(heap)) # 输出: (1, 'Task 1') print(heapq.heappop(heap)) # 输出: (2, 'Task 2') print(heapq.heappop(heap)) # 输出: (3, 'Task 3')
import queue
from collections import deque
import heapq
def pd_queue():#Queue:普通队列,从队尾入队,从队头出队#put():入队#get():出队q=queue.Queue()q.put(1)q.put(2)q.put(3)
print(q.get())print(q.get())print(q.get())
#deque:双端队列,既可以在队尾进行入队和出队操作,也可以在队头进行入队和出队操作
#append():在队尾入队
#appendleft():在队头入队
#pop():在队尾出队
#popleft():在队头出队
#appendleft和popleft组合使用时,相当于栈的操作
#appned和pop组合使用同理dq=deque()dq.append(1)dq.append(2)dq.appendleft(3)dq.appendleft(4)
print(dq.popleft())print(dq.popleft())print(dq.popleft())print(dq.popleft())
#PriorityQueue:优先队列,参数:元组(优先级,元素),优先级的数值越小,优先级越高pq=queue.PriorityQueue()pq.put((1,'item1'))pq.put((3, 'item2'))pq.put((3, 'item3'))
print('--------------')print(pq.get())print(pq.get())print(pq.get())
#heapq:优先队列,基于堆实现的,预先定义一个数组作为heap对象,线程不安全#heappush():参数1:heap是预先定义的堆,参数2:向队中添加优先级的元素元祖(优先级,元素值),优先级的数值越小,优先级越高#heappop(heap):参数:heap是预先定义的堆heap=[ ]heapq.heappush(heap,(1,'hq1'))heapq.heappush(heap,(3,'hq2'))heapq.heappush(heap,(2,'hq3'))
print('-----------')print(heapq.heappop(heap))print(heapq.heappop(heap))print(heapq.heappop(heap))
if __name__=='__main__':pd_queue2.4 树
2.4.1 概念和术语
模拟树结构
将组织架构里的数据移除, 抽象出来结构, 那么就是我们要学习的树结构

术语
树的结构:

树的定义:
-
树(Tree): n(n≥0)个结点构成的有限集合。
-
当n=0时,称为空树;
-
对于任一棵非空树(n> 0),它具备以下性质:
-
树中有一个称为“根(Root)”的特殊结点,用 root 表示;
-
其余结点可分为m(m>0)个互不相交的有限集T1,T2,... ,Tm,其中每个集合本身又是一棵树,称为原来树的“子树(SubTree)”
注意:
-
子树之间不可以相交
-
除了根结点外,每个结点有且仅有一个父结点;
-
一棵N个结点的树有N-1条边。
-
树的术语:
-
1.结点的度(Degree):该结点的拥有的子节点数量。
-
2.树的度:树的所有结点中最大的度数. (树的度通常为结点的个数N-1)
-
3.叶子结点(Leaf):度为0的结点. (也称为叶子结点)
-
4.父结点(Parent):有子树的结点是其子树的根结点的父结点
-
5.子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点。
-
6.兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点。
-
7.路径和路径长度:从结点n1到nk的路径为一个结点序列n1 , n2,… , nk, ni是 ni+1的父结点。路径所包含边的个数为路径的长度。
-
8.结点的层次(Level):规定根结点在1层,其它任一结点的层数是其父结点的层数加1。
-
9.树的深度(Depth):树中所有结点中的最大层次是这棵树的深度。
2.4.2 二叉树
2.4.2.1 概念
二叉树的定义
-
二叉树可以为空, 也就是没有结点.
-
若不为空,则它是由根结点和称为其左子树TL和右子树TR的两个不相交的二叉树组成。
二叉树有五种形态:
-
注意c和d是不同的二叉树, 因为二叉树是有左右之分的.

2.4.2.2 特性
-
二叉树有几个比较重要的特性, 在笔试题中比较常见:
-
一个二叉树第 i 层的最大结点数为:2^(i-1), i >= 1;
-
深度为k的二叉树有最大结点总数为: 2^k - 1, k >= 1;
-
对任何非空二叉树 T,若n0表示叶结点的个数、n2是度为2的非叶结点个数,那么两者满足关系n0 = n2 + 1。

-
2.4.2.3 特殊的二叉树
满二叉树(Full Binary Tree)
-
在二叉树中, 除了最下一层的叶结点外, 每层节点都有2个子结点, 就构成了满二叉树.

完全二叉树(Complete Binary Tree)
-
除二叉树最后一层外, 其他各层的节点数都达到最大个数.
-
且最后一层从左向右的叶结点连续存在, 只缺右侧若干节点.
-
满二叉树是特殊的完全二叉树.
-
下面不是完全二叉树, 因为D节点还没有右结点, 但是E节点就有了左右节点.

2.4.2.4 二叉树的存储
二叉树的存储常见的方式是链表.
链表存储:
-
二叉树最常见的方式还是使用链表存储.
-
每个结点封装成一个Node, Node中包含存储的数据, 左结点的引用, 右结点的引用.

2.4.2.5 二叉树遍历
前序遍历(Pre-order Traversal)、中序遍历(In-order Traversal)和后序遍历(Post-order Traversal)是二叉树的三种基本遍历方式。
遍历规则:
前序遍历,按照以下顺序访问节点:根节点、左子树、右子树。
中序遍历,按照以下顺序访问节点:左子树、根节点、右子树。
后序遍历,按照以下顺序访问节点:左子树、右子树、根节点。
2.4.3 二叉查找树
二叉查找树(Binary Search Tree, BST)是一种特殊的二叉树,它具有以下性质:
-
每个节点都有一个键值(key)。
-
对于每个节点,其左子树中的所有节点的键值都小于该节点的键值。
-
对于每个节点,其右子树中的所有节点的键值都大于该节点的键值。
-
左子树和右子树也分别是二叉查找树。
-
二叉查找树不允许出现键值相等的结点。

二叉查找树的主要操作包括插入、删除和遍历。代码实现如下:
2.4.3.1 创建二叉查找树节点
class TreeNode:def __init__(self, key):self.key = keyself.left = Noneself.right = None
-
key: 节点的键值。
-
left: 指向左子节点的指针。
-
right: 指向右子节点的指针。
2.4.3.2 创建二叉查找树类
class BinarySearchTree:def __init__(self):self.root = None
-
root: 指向二叉搜索树的根节点。初始时为 None。
2.4.3.3 插入节点
插入操作的步骤:
-
如果树为空:直接将新节点作为根节点。
-
如果树不为空:
-
从根节点开始,根据新节点的键值与当前节点的键值的比较结果,决定向左子树还是右子树移动。
-
如果新节点的键值小于当前节点的键值,如果当前节点没有左子树,则将新节点插入到当前节点的左子树,否则向左子树移动。
-
如果新节点的键值大于当前节点的键值,如果当前节点没有右子树,则将新节点插入到当前节点的右子树,否则向右子树移动。
-
重复上述步骤,直到找到一个空位置,将新节点插入到该位置。
-
def insert(self, key):if self.root is None:self.root = TreeNode(key)else:self._insert(self.root, key) def _insert(self, node, key):if key < node.key:if node.left is None:node.left = TreeNode(key)else:self._insert(node.left, key)elif key > node.key:if node.right is None:node.right = TreeNode(key)else:self._insert(node.right, key)
-
insert(key): 公开的插入方法。如果树为空,则创建一个新节点作为根节点;否则,调用 _insert 方法进行递归插入。
-
_insert(node, key): 递归插入方法。根据键值的大小,递归地在左子树或右子树中插入新节点。
2.4.3.4 查找节点
def search(self, key):return self._search(self.root, key) def _search(self, node, key):if node is None or node.key == key:return nodeif key < node.key:return self._search(node.left, key)return self._search(node.right, key)
2.4.3.5 删除节点
删除逻辑:
1.递归查找待删除节点
-
如果待删除节点的键值小于当前节点的键值,递归地在左子树中查找并删除。
-
如果待删除节点的键值大于当前节点的键值,递归地在右子树中查找并删除。
2.找到待删除节点
删除操作的步骤可以分为以下几种情况:
-
待删除节点是叶子节点(没有子节点):直接删除该节点。
-
待删除节点只有一个子节点:用其子节点替换该节点。
-
待删除节点有两个子节点:
-
找到右子树中的最小节点(即后继节点)。
-
用后继节点的键值替换待删除节点的键值。
-
删除后继节点(后继节点要么是叶子节点,要么只有一个右子节点)。
-
假设我们有以下二叉搜索树:
50/ \30 70/ \ / \20 40 60 80
删除节点 20
-
找到键值为 20 的节点。
-
该节点是叶子节点,直接删除。
删除后的树:
50/ \30 70\ / \40 60 80
删除节点 30
-
找到键值为 30 的节点。
-
该节点有一个右子节点 40,用 40 替换 30。
删除后的树:
50/ \40 70/ \60 80
删除节点 50
-
找到键值为 50 的节点。
-
该节点有两个子节点,找到右子树中的最小节点 60(即后继节点)。
-
用 60 替换 50。
-
删除右子树中的 60。
删除后的树:
60/ \40 70\80
def delete(self, key):self.root = self._delete(self.root, key) def _delete(self, node, key):if node is None:return node if key < node.key:node.left = self._delete(node.left, key)elif key > node.key:node.right = self._delete(node.right, key)else:# 找到要删除的节点# 情况 1: 节点是叶子节点if node.left is None and node.right is None:return None# 情况 2: 节点只有一个子节点elif node.left is None:return node.rightelif node.right is None:return node.left# 情况 3: 节点有两个子节点temp = self._min_value_node(node.right)node.key = temp.keynode.right = self._delete(node.right, temp.key) return node def _min_value_node(self, node):current = nodewhile current.left is not None:current = current.leftreturn current
2.4.3.6 中序遍历
先遍历左子树,然后访问当前节点,最后遍历右子树。
def inorder_traversal(self):result = []self._inorder_traversal(self.root, result)return result def _inorder_traversal(self, node, result):if node:self._inorder_traversal(node.left, result)result.append(node.key)self._inorder_traversal(node.right, result)
2.4.3.7 前序遍历
先访问根节点、然后遍历左子树、最后遍历右子树。
def preorder_search(self):result = []if self.root is None:return Noneself._preorder_search(self.root, result)return result def _preorder_search(self,node,result):if node is None:return Noneresult.append(node.key)self._preorder_search(node.left,result)self._preorder_search(node.right,result)# 后序遍历,按照以下顺序访问节点:左子树、右子树、根节点。def _behind_search(self, node, result):if node:self._behind_search(node.left, result)self._behind_search(node.right, result)result.append(node.key) def remove(self,key):if self.root is None:return Noneself.root=self._remove(self.root,key)
class TreeNode:def __init__(self,key):self.key=keyself.left=Noneself.right=None
class BST:def __init__(self):self.root=None
def insert(self,key):#判断树是否为空,是则将新节点赋给根节点if self.root is None:self.root=TreeNode(key)else:self._insert(self.root,key)
def _insert(self,node,key):#如果要插入的键值小于当前节点的键值,则判断当前节点是否有左子树,没有则将新节点赋给当前节点的左子树,#有则继续向当前节点的左子树移动,递归插入if key<node.key:if node.left is None:node.left=TreeNode(key)else:#node.left:当前节点的左子树节点self._insert(node.left,key)#如果要插入的键值大于当前节点的键值,则判断当前节点是否有右子树,没有则将新节点插入到当前节点的右子树#有则继续向当前节点的右子树移动,递归插入else:if node.right is None:node.right=TreeNode(key)else:self._insert(node.right,key)
def inorder_search(self):result=[ ]self._inorder_search(self.root,result)return result#中序遍历:左子树、根、右子树def _inorder_search(self,node,result):if node:self._inorder_search(node.left,result)result.append(node.key)self._inorder_search(node.right,result)
def frontorder_search(self):result=[ ]if self.root is None:return Noneself._front_search(self.root,result)return result
# 前序遍历,按照以下顺序访问节点:根节点、左子树、右子树。def _front_search(self, node, result):if node is None:return Noneelse:result.append(node.key)self._front_search(node.left, result)self._front_search(node.right, result)
def behindorder_search(self):result=[ ]self._behind_search(self.root,result)return result
# 后序遍历,按照以下顺序访问节点:左子树、右子树、根节点。def _behind_search(self, node, result):if node:self._behind_search(node.left, result)self._behind_search(node.right, result)result.append(node.key)
def remove(self,key):if self.root is None:return Noneself.root=self._remove(self.root,key)
def _remove(self,node,key):#如果树为空,则返回Noneif node is None:return None#判断指定的key和当前节点的key的大小,如果指定key小于当前节点的key,则递归遍历左子树#如果指定key大于当前节点的key,则递归遍历右子树if key <node.key:node.left=self._remove(node.left,key)elif key >node.key:node.right=self._remove(node.right,key)#指定key等于当前节点的key:#1.当前节点没有子节点,则直接删除,返回None#2.当前节点有一个子节点,1).有右子节点,则用右子节点替换当前节点;2).有左子结点,则用左子结点替换当前节点#3.当前节点有两个子节点:查找当前节点右子树的左子树,找到最小值,用最小值节点替换当前节点,删除最小值节点else:#如果当前节点左右子树都为空则返回Noneif node.left is None and node.right is None:return None#如果当前节点只有一个子树,如果左子树为空,则返回右子树节点;如果右子树节点为空,则返回左子树节点elif node.left is None:return node.rightelif node.right is None:return node.left#如果当前节点有两个子树,则查询当前节点右子树的左子树,找到最小值节点#将最小值替换到当前节点#将最小值节点递归删除else:temp=self._min_value_node(node.right)node.key=temp.key#以当前节点的右子树节点为根节点,删除最小值节点node.right=self._remove(node.right,temp.key)
return node#查找当前节点的最小值,最小值在当前节点的左子树中def _min_value_node(self,node):while node.left is not None:node=node.leftreturn node
if __name__=='__main__':bst=BST()bst.insert(5)bst.insert(8)bst.insert(3)bst.insert(2)bst.insert(7)bst.insert(4)
result=bst.inorder_search()print(result)result1 = bst.frontorder_search()print(result1)result2 = bst.behindorder_search()print(result2)
# bst.remove(4)# result=bst.inorder_search()# print(result)
相关文章:
从0开始学python-day17-数据结构2
2.3 队列 队列(Queue),它是一种运算受限的线性表,先进先出(FIFO First In First Out) 队列是一种受限的线性结构 受限之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作 P…...
—— 编程基础)
(蓝桥杯C/C++)—— 编程基础
文章目录 一、C基础格式 1.打印hello, world 2.基本数据类型 二、string 1.string简介 2.string的声明和初始化 3.string其他基本操作 (1)获取字符串长度 (2) 拼接字符串( 或 append) (3)字符串查找(find) (4)字符串替换 (5)提取子字符串…...
企业物流管理数据仓库建设的全面指南
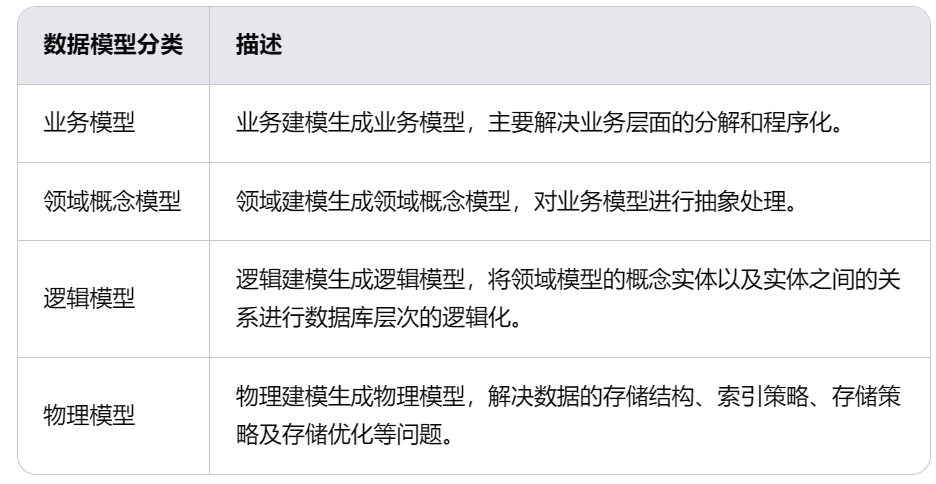
文章目录 一、物流管理目标二、总体要求三、数据分层和数据构成(1)数据分层(2)数据构成 四、数据存储五、数据建模和数据模型(1)数据建模(2)数据模型 六、总结 在企业物流管理中&…...

数据采集-Kepware 安装证书异常处理
这里写目录标题 一、 问题描述二、原因分析三、处理方案3.1 1.执行根证书的更新3.2 安装KepServerEx 资源 一、 问题描述 在进行KepServerEx进行安装的情况下,出现了如下的报错: The installer was unable to find required root certificates ,please …...

ubuntu禁止自动更新设置
背景概述 从CentOS变更到uBuntu或多或少会遇到一些坑,今天分享一个。 在Ubuntu系统中,自动更新是一个既方便又引发争议的功能。它可以帮助用户保持系统的最新状态,但有时也会因为自动更新而导致系统不稳定或不兼容。 Ubuntu系统的自动更新主…...

Rust 力扣 - 1461. 检查一个字符串是否包含所有长度为 K 的二进制子串
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 长度为k的二进制子串所有取值的集合为[0, sum(k)],其中sum(k)为1 2 4 … 1 << (k - 1) 我们只需要创建一个长度为sum(k) 1的数组 f ,其中下标为 i 的元素用来标记字符串中子串…...
C#/.NET/.NET Core技术前沿周刊 | 第 11 期(2024年10.21-10.31)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录、追踪C#/.NET/.NET Core领域、生态的每周最新、最实用、最有价值的技术文章、社区动态、优质项目和学习资源等。让你时刻站在技术前沿,助力技术成长与视野拓宽。 欢迎投稿、推荐…...

unity 三维数学 ,角度 弧度计算
弧度 角度*π/180...
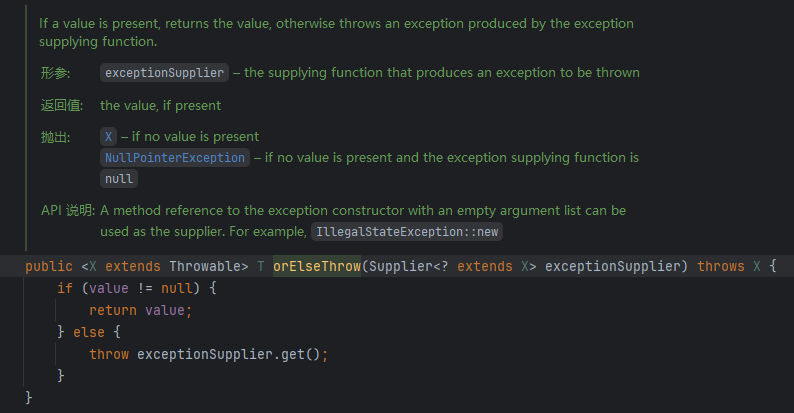
Java基础4-控制流程
控制流程 Java使用条件语句和循环结构确定控制流程。基本和C一样,但是没有goto语句,但break语句可以有标签,用于跳出内层循环。 块作用域(block) 块(即复合语句)是指由一堆花括号括起来的若干…...
面试题分享11月1日
1、过滤器和拦截器的区别 过滤器是基于spring的 拦截器是基于Java Web的 2、session 和 cookie 的区别、关系 cookie session 存储位置 保存在浏览器 (客户端) 保存在服务器 存储数据大小 限制大小,存储数据约为4KB 不限制大小&…...

【含文档】基于ssm+jsp的学科竞赛系统(含源码+数据库+lw)
1.开发环境 开发系统:Windows10/11 架构模式:MVC/前后端分离 JDK版本: Java JDK1.8 开发工具:IDEA 数据库版本: mysql5.7或8.0 数据库可视化工具: navicat 服务器: apache tomcat 主要技术: Java,Spring,SpringMvc,mybatis,mysql,vue 2.视频演示地址 3.功能 系统定义了四个…...

Docker方式部署ClickHouse
Docker方式部署ClickHouse ClickHouse docker 版本镜像:https://docker.aityp.com/r/docker.io/clickhouse/clickhouse-server ClickHouse 21.8.13.6 docker 版本镜像:https://docker.aityp.com/image/docker.io/clickhouse/clickhouse-server:21.8.13.…...

车载通信架构 --- PNC、UB与信号的关系
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 所有人的看法和评价都是暂时的,只有自己的经历是伴随一生的,几乎所有的担忧和畏惧,都是来源于自己的想象,只有你真的去做了,才会发现有多快乐。…...

智慧农业云平台:大数据赋能现代农业的未来
近年来,随着科技的迅速发展,农业作为传统行业正面临着前所未有的变革。智慧农业,作为现代农业发展的重要方向,借助云计算、大数据、物联网等技术,正在为农业生产、管理和服务提供全新的解决方案。在这个背景下…...

【python】OpenCV—Tracking(10.4)—Centroid
文章目录 1、任务描述2、人脸检测模型3、完整代码4、结果展示5、涉及到的库函数6、参考 1、任务描述 基于质心实现多目标(以人脸为例)跟踪 人脸检测采用深度学习的方法 核心步骤: 步骤#1:接受边界框坐标并计算质心 步骤#2&…...
2倍MSL)
为什么TCP(TIME_WAIT)2倍MSL
为什么TCP(TIME_WAIT)2倍MSL 一、TCP关闭连接的四次挥手流程进入TIME_WAIT 二、TIME_WAIT状态的意义1. 确保ACK报文到达对方2. 防止旧报文干扰新连接 三、为什么是2倍MSL四、TIME_WAIT的图解五、TIME_WAIT在实际应用中的影响总结 在TCP连接的关闭过程中&…...

jieba-fenci 05 结巴分词之简单聊一聊
拓展阅读 DFA 算法详解 为了便于大家学习,项目开源地址如下,欢迎 forkstar 鼓励一下老马~ 敏感词 sensitive-word 分词 segment 分词系列专题 jieba-fenci 01 结巴分词原理讲解 segment jieba-fenci 02 结巴分词原理讲解之数据归一化 segment jieba…...
Hadoop期末复习(完整版)
前言(全部为语雀导出,个人所写,仅用于学习!!!!) 复习之前我们要有目的性,明确考什么,不考什么。 对于hadoop来说,首先理论方面是跑不掉的&#x…...

Python篮球王子
系列文章 序号直达链接爱心系列1Python制作一个无法拒绝的表白界面2Python满屏飘字表白代码3Python无限弹窗满屏表白代码4Python李峋同款可写字版跳动的爱心5Python流星雨代码6Python漂浮爱心代码7Python爱心光波代码8Python普通的玫瑰花代码9Python炫酷的玫瑰花代码10Python多…...

分享一些在部署k8s集群时遇到的问题
目录 一、k8s拉取镜像失败,多半是docker镜像源失效了,需要经常更新 1.编辑该配置文件: 2.重启服务器: 二、kubectl get nodes时出现:The connection to the server localhost:8080 was refused - did you specify t…...
)
手把手教你用STM32实现国标交流充电桩的CP信号检测(附完整代码)
手把手教你用STM32实现国标交流充电桩的CP信号检测(附完整代码) 在电动汽车充电基础设施快速发展的今天,交流充电桩因其成本优势和广泛适用性成为市场主流。作为嵌入式开发者,理解并实现充电控制导引(CP)信…...

【Autosar】MCAL - 从零到一的工程配置实战
1. 工程创建:从零搭建MCAL开发环境 第一次打开Autosar配置工具时,面对满屏的选项确实容易发懵。记得我刚接触MCAL配置时,光是工程创建就反复折腾了好几次。下面我就把踩过的坑和验证过的正确姿势分享给大家。 创建新工程时,工程名…...
)
QGIS背景图层全攻略:从在线电子地图到本地DEM,打造专业级GIS底图(以南京为例)
QGIS背景图层全攻略:从在线电子地图到本地DEM,打造专业级GIS底图(以南京为例) 当你的GIS项目已经具备基础矢量数据(比如行政区划边界)时,如何选择合适的背景图层往往成为提升地图专业度的关键。…...

探索ONVIF世界:轻松对接RTSP视频流的开源宝藏
探索ONVIF世界:轻松对接RTSP视频流的开源宝藏 【下载地址】ONVIF协议RTSP视频流与OnvifDeviceManager对接实现 本资源文件提供了一个成功实现ONVIF协议RTSP视频流与OnvifDeviceManager对接的代码示例。该示例对于希望实现ONVIF视频对接的开发者具有一定的参考价值 …...

【亲测免费】 使用S-Function函数实现离散PID控制器
使用S-Function函数实现离散PID控制器 【下载地址】使用S-Function函数实现离散PID控制器 本资源文件提供了使用S-Function函数实现离散PID控制器,并建立Simulink仿真模型的详细教程和代码。通过本资源,您将学习如何在Simulink中使用S-Function模块来实现…...
)
NSIS进阶玩法:手把手教你用HM NIS Edit打造个性化安装界面(替换图标、文字与进度条)
NSIS深度定制指南:从默认界面到品牌化安装体验 当用户双击你的安装程序时,第一印象往往决定了他们对产品的整体期待。那些千篇一律的NSIS默认界面,就像穿着标准制服的接待员——功能完备但缺乏个性。作为开发者,我们完全有能力让安…...

视觉驱动的空间碎片智能感知方法【附数据】
✨ 长期致力于空间碎片、智能感知、图像融合、显著性检测、目标识别研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)像素级图像融合的低照度增强方法&…...

Discovery与Kubernetes深度集成:实现容器化微服务注册发现的终极指南
Discovery与Kubernetes深度集成:实现容器化微服务注册发现的终极指南 【免费下载链接】discovery A registry for resilient mid-tier load balancing and failover. 项目地址: https://gitcode.com/gh_mirrors/discov/discovery 在当今云原生时代࿰…...
和MSB8020错误的根治方法)
别再只改项目属性了!彻底搞懂Visual Studio平台工具集(Platform Toolset)和MSB8020错误的根治方法
深入解析Visual Studio平台工具集:从MSB8020错误到构建系统精要 当你在Visual Studio中打开一个历史项目时,是否曾被突如其来的MSB8020错误打断工作流程?这个看似简单的"找不到生成工具"提示背后,隐藏着Visual Studio构…...

NoFences:重新定义Windows桌面管理的开源革命
NoFences:重新定义Windows桌面管理的开源革命 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否也曾为杂乱无章的Windows桌面而烦恼?图标散落各处…...