jieba-fenci 05 结巴分词之简单聊一聊
拓展阅读
DFA 算法详解
为了便于大家学习,项目开源地址如下,欢迎 fork+star 鼓励一下老马~
敏感词 sensitive-word
分词 segment
分词系列专题
jieba-fenci 01 结巴分词原理讲解 segment
jieba-fenci 02 结巴分词原理讲解之数据归一化 segment
jieba-fenci 03 结巴分词与繁简体转换 segment
jieba-fenci 04 结巴分词之词性标注实现思路 speechTagging segment
jieba-fenci 05 结巴分词之简单聊一聊
结巴分词
结巴分词(Jieba)是一个广泛使用的中文文本分词工具,因其高效和易用而受到欢迎。以下是结巴分词的一些关键特性和使用方法:
特性
三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析。
- 全模式:把句子中所有的可能分词都找出来,速度较快,但不适合文本分析。
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,适合用于搜索引擎构建倒排索引。
自定义词典:用户可以添加自己的词典,以提高分词的准确性。通过自定义词典,可以为一些特定领域的词汇提供更好的支持。
词性标注:结巴分词不仅可以进行分词,还可以为每个词语进行词性标注,方便进一步的自然语言处理。
支持多种编码:可以处理 UTF-8 和 GBK 编码的文本,适用于多种场景。
自定义词典
可以使用自定义词典来提升特定领域词汇的识别度。自定义词典的格式为每行一个词,格式为“词语 词频 词性”。
应用场景
- 文本分析:如情感分析、主题建模等。
- 搜索引擎:为搜索引擎提供分词支持,构建倒排索引。
- 推荐系统:通过对用户输入的文本进行分词,分析用户兴趣。
结巴分词因其灵活性和高效性,广泛应用于各种中文自然语言处理任务中。
java 结巴分词入门例子
要在 Java 中使用结巴分词(Jieba),可以通过引入结巴分词的 Java 实现库(如 jieba-analysis)来实现。
以下是一个简单的入门示例,包括 Maven 的依赖配置和代码示例。
1. Maven 依赖
在你的 Maven 项目的 pom.xml 文件中,添加以下依赖:
<dependencies><dependency><groupId>com.github.hankcs</groupId><artifactId>jieba-analysis</artifactId><version>7.0.0</version> <!-- 请检查最新版本 --></dependency>
</dependencies>2. Java 代码示例
以下是一个简单的 Java 程序,演示如何使用结巴分词进行分词处理:
import com.hankcs.jieba.JiebaSegmenter;
import com.hankcs.jieba.WordDictionary;import java.util.List;public class JiebaExample {public static void main(String[] args) {// 初始化 Jieba 分词器JiebaSegmenter segmenter = new JiebaSegmenter();// 要分词的文本String text = "我爱自然语言处理";// 精确模式分词List<String> words = segmenter.sentenceProcess(text);System.out.println("精确模式分词: " + words);// 全模式分词List<String> allWords = segmenter.process(text, JiebaSegmenter.SegMode.SEARCH);System.out.println("全模式分词: " + allWords);// 添加自定义词典(可选)// WordDictionary.getInstance().add("自然语言处理");// List<String> customWords = segmenter.sentenceProcess(text);// System.out.println("自定义词典分词: " + customWords);}
}结巴分词词性标注 HMM 示意代码
下面是一个基于动态规划和隐马尔可夫模型(HMM)进行词性标注的简化实现。
这个示例展示了基本的动态规划算法如何与 HMM 结合使用。
完整代码实现
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class HMMPOSTagger {// 状态转移概率private static final Map<String, Map<String, Double>> transitionProbabilities = new HashMap<>();// 发射概率private static final Map<String, Map<String, Double>> emissionProbabilities = new HashMap<>();// 词典private static final String[] states = {"名词", "动词", "形容词", "代词", "副词"};static {// 状态转移概率(简化示例)transitionProbabilities.put("名词", Map.of("名词", 0.3, "动词", 0.2, "形容词", 0.1, "代词", 0.1, "副词", 0.1));transitionProbabilities.put("动词", Map.of("名词", 0.2, "动词", 0.3, "形容词", 0.1, "代词", 0.1, "副词", 0.2));// ... 更多状态转移概率// 发射概率(简化示例)emissionProbabilities.put("名词", Map.of("自然语言处理", 0.8, "计算机", 0.2));emissionProbabilities.put("动词", Map.of("爱", 1.0));emissionProbabilities.put("形容词", Map.of("好", 1.0));// ... 更多发射概率}public static String[] viterbi(List<String> words) {int n = words.size();int m = states.length;double[][] dp = new double[n][m];int[][] backpointer = new int[n][m];// 初始化for (int j = 0; j < m; j++) {String state = states[j];dp[0][j] = emissionProbabilities.getOrDefault(state, new HashMap<>()).getOrDefault(words.get(0), 0.0);}// 动态规划for (int i = 1; i < n; i++) {for (int j = 0; j < m; j++) {String state = states[j];double maxProb = 0.0;int bestState = 0;for (int k = 0; k < m; k++) {String prevState = states[k];double prob = dp[i - 1][k] * transitionProbabilities.getOrDefault(prevState, new HashMap<>()).getOrDefault(state, 0.0);if (prob > maxProb) {maxProb = prob;bestState = k;}}dp[i][j] = maxProb * emissionProbabilities.getOrDefault(state, new HashMap<>()).getOrDefault(words.get(i), 0.0);backpointer[i][j] = bestState;}}// 回溯找到最优路径double maxProb = 0.0;int bestLastState = 0;for (int j = 0; j < m; j++) {if (dp[n - 1][j] > maxProb) {maxProb = dp[n - 1][j];bestLastState = j;}}// 构建最优状态序列String[] result = new String[n];int currentState = bestLastState;for (int i = n - 1; i >= 0; i--) {result[i] = states[currentState];currentState = backpointer[i][currentState];}return result;}public static void main(String[] args) {List<String> words = List.of("我", "爱", "自然语言处理");String[] posTags = viterbi(words);// 输出结果for (int i = 0; i < words.size(); i++) {System.out.println(words.get(i) + ": " + posTags[i]);}}
}实现细节
- 状态转移概率(Transition Probabilities):用于描述从一个状态(词性)转移到另一个状态的概率。
- 发射概率(Emission Probabilities):描述给定状态(词性)时,生成特定观察(词)的概率。
- 动态规划(Viterbi Algorithm):
- 初始化 DP 表格。
- 填充 DP 表,计算每个状态的最大概率。
- 使用回溯表找到最优路径。
- 词典:在实际应用中,应该加载更完整的状态转移和发射概率数据。
注意事项
- 这个示例中的概率数据是简化的,实际使用时应基于真实的训练数据进行统计。
- 代码为简化版本,未处理所有边界情况,实际应用中需进行完善。
- 可以考虑使用现成的 HMM 库,减少实现复杂度和错误。
相关文章:

jieba-fenci 05 结巴分词之简单聊一聊
拓展阅读 DFA 算法详解 为了便于大家学习,项目开源地址如下,欢迎 forkstar 鼓励一下老马~ 敏感词 sensitive-word 分词 segment 分词系列专题 jieba-fenci 01 结巴分词原理讲解 segment jieba-fenci 02 结巴分词原理讲解之数据归一化 segment jieba…...
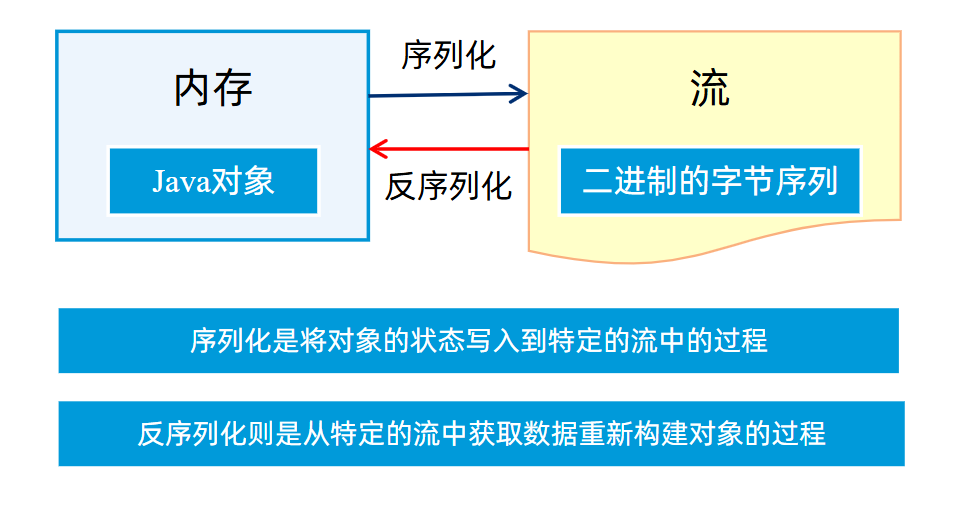
Hadoop期末复习(完整版)
前言(全部为语雀导出,个人所写,仅用于学习!!!!) 复习之前我们要有目的性,明确考什么,不考什么。 对于hadoop来说,首先理论方面是跑不掉的&#x…...

Python篮球王子
系列文章 序号直达链接爱心系列1Python制作一个无法拒绝的表白界面2Python满屏飘字表白代码3Python无限弹窗满屏表白代码4Python李峋同款可写字版跳动的爱心5Python流星雨代码6Python漂浮爱心代码7Python爱心光波代码8Python普通的玫瑰花代码9Python炫酷的玫瑰花代码10Python多…...

分享一些在部署k8s集群时遇到的问题
目录 一、k8s拉取镜像失败,多半是docker镜像源失效了,需要经常更新 1.编辑该配置文件: 2.重启服务器: 二、kubectl get nodes时出现:The connection to the server localhost:8080 was refused - did you specify t…...

【Canal 中间件】Canal使用原理与基本组件概述
文章目录 一、canal 概述1.2 什么是 canal2.3 canal 的所有组件 二、canal 工作原理2.1 MySQL 主备复制原理2.2 canal 工作原理 三、canal.server 组件3.1 canal.server 的架构3.2 instance 模块组成部分 四、canal.client 组件4.1 类设计4.2 server/clinet 交互协议4.3 使用案…...

《Baichuan-Omni》论文精读:第1个7B全模态模型 | 能够同时处理文本、图像、视频和音频输入
技术报告Baichuan-Omni Technical ReportGitHub仓库地址 文章目录 论文摘要1. 引言简介2. 训练2.1. 高质量的多模态数据2.2. 多模态对齐预训练2.2.1. 图像-语言分支2.2.2. 视频语音分支2.2.3. 音频语言分支2.2.4. 图像-视频-音频全方位对齐 2.3. 多模态微调监督 3. 实验3.1. 语…...

YOLOv6-4.0部分代码阅读笔记-common.py
common.py yolov6\layers\common.py 目录 common.py 1.所需的库和模块 2.class SiLU(nn.Module): 3.class ConvModule(nn.Module): 4.class ConvBNReLU(nn.Module): 5.class ConvBNSiLU(nn.Module): 6.class ConvBN(nn.Module): 7.class ConvBNHS(nn.Module): …...

移植 AWTK 到 纯血鸿蒙 (HarmonyOS NEXT) 系统 (4) - 平台适配
在移植 AWTK 到 HarmonyOS NEXT 系统之前,我们需要先完成平台适配,比如文件、多线程(线程和同步)、时间、动态库和资源管理。 1. 文件 HarmonyOS NEXT 支持标准的 POSIX 文件操作接口,我们可以直接使用下面的代码&am…...

Java 多线程(八)—— 锁策略,synchronized 的优化,JVM 与编译器的锁优化,ReentrantLock,CAS
前言 本文为 Java 面试小八股,一句话,理解性记忆,不能理解就死背吧。 锁策略 悲观锁与乐观锁 悲观锁和乐观锁是锁的特性,并不是特指某个具体的锁。 我们知道在多线程中,锁是会被竞争的,悲观锁就是指锁…...
【项目分享】法拉利中控台模拟 html+css+js
引入: 制作一个模拟法拉利中控台的网页是一个有趣且富有挑战性的项目。为了简化这个任务,我们可以使用一些HTML、CSS和JavaScript来实现一个基本的界面。以下是一个简单的示例,展示了如何创建一个基本的法拉利中控台模拟网页。 效果展示&…...

Rust 力扣 - 2461. 长度为 K 子数组中的最大和
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 我们遍历长度为k的窗口,用一个哈希表记录窗口内的所有元素(用来对窗口内元素去重),我们取哈希表中元素数量等于k的窗口总和的最大值 题解代码 use std::collecti…...
)
stm32103c8t6 pwm驱动舵机(SG90)
本方法采用通用定时器(TIM2、TIM3、TIM4、TIM5)实现 代码: PWM.h #ifndef __PWM_H // 防止头文件重复包含 #define __PWM_H#include "stm32f10x.h" // 包含STM32F10x系列的设备头文件// 函数声明 void TIM2_PWM_In…...

Python For循环
Python 的 for 循环是自动化重复任务的强大工具,可以使代码更高效、更易于管理。本教程将解释 for 循环的工作原理,探讨不同的应用场景,并提供大量实用示例。无论你是初学者还是希望提升技能的开发者,这些示例都将帮助你更好地在 …...

C++入门——“C++11-右值引用和移动语义”
C11相比于C98增加以许多新特性,让C语言更加灵活好用,但是貌似也增加了许多学习的难度,现在先看第一部分。 一、右值引用和移动语义 1.右值引用和左值引用 在C中,值可以大致分为右值和左值,左值大概是哪些已经被定义的变…...

timm使用笔记
timm(Timm is a model repository for PyTorch)是一个 PyTorch 原生实现的计算机视觉模型库。它提供了预训练模型和各种网络组件,可以用于各种计算机视觉任务,例如图像分类、物体检测、语义分割等等。timm(库提供了预训…...

android浏览器源码 可输入地址或关键词搜索 android studio 2024 可开发可改地址
Android 浏览器是一种运行在Android操作系统上的应用程序,主要用于访问和查看互联网内容。以下是关于Android浏览器的详细介绍: 1. 基本功能 Android浏览器提供了用户浏览网页的基本功能,如: 网页加载:支持加载静态…...

贪心算法入门(一)
1.什么是贪心算法? 贪心算法是一种解决问题的策略,它将复杂的问题分解为若干个步骤,并在每一步都选择当前最优的解决方案,最终希望能得到全局最优解。这种策略的核心在于“最优”二字,意味着我们追求的是以最少的时间和…...

C# ref和out 有什么区别,分别用在那种场景
在C#中,ref和out都是用于按引用传递参数的关键字,但它们有一些细微的差别和使用场景。 ref 关键字 ref 关键字用于按引用传递参数。这意味着当你将一个变量作为参数传递给一个方法时,你不是传递变量的值,而是传递变量的引用。因…...

TikTok直播专线:提升直播效果和体验
作为当今全球最受欢迎的社交媒体平台之一,TikTok为商家提供了无限的商机和市场。然而,商家在使用TikTok时也面临着许多挑战,如网络延迟、直播中断以及账号被封等问题。TikTok直播专线旨在为商家提供高速稳定的网络连接,助力他们在…...

由浅入深逐步理解spring boot中如何实现websocket
实现websocket的方式 1.springboot中有两种方式实现websocket,一种是基于原生的基于注解的websocket,另一种是基于spring封装后的WebSocketHandler 基于原生注解实现websocket 1)先引入websocket的starter坐标 <dependency><grou…...

全志T113-i音视频编解码测试:从环境搭建到问题排查全流程
1. 项目概述与核心价值最近在调试一块基于全志T113-i芯片的开发板,核心任务是对其音视频编解码能力进行全面的功能与性能验证。这听起来像是一个标准的硬件测试流程,但如果你真的上手做过,就会知道从拿到一块“裸板”到能稳定播放1080P视频、…...
)
零基础想学挖漏洞?普通人也能看懂的网络安全入门学习路线(建议收藏)
很多人对网络安全的第一印象:黑客、代码、入侵、黑框代码疯狂滚动、随手就能让ATM吐钱,随手一个漏洞几千上万,日进斗金!!! 但真实情况是:90%零基础新人不会挖漏洞,不是天赋不够&…...

从天气预报App到数值模型:拆解‘气旋路径预报’背后的关键技术栈
从天气预报App到数值模型:拆解‘气旋路径预报’背后的关键技术栈 清晨打开手机查看台风路径,指尖划过屏幕上那些彩色线条时,你是否想过这些动态轨迹背后隐藏着怎样的技术交响曲?现代气象预报早已不是简单的经验推测,而…...

推理服务为什么一上模型压缩组合就开始精度雪崩:从量化-剪枝-蒸馏的叠加效应到恢复策略的工程实战
一、精度雪崩的生产现场 🔥 某团队部署 LLaMA-2-7B 推理服务时,为降低显存、提升吞吐,同时对模型做 W4A16 量化、30% 结构化剪枝与层蒸馏。单独测试时,量化版困惑度上升 8%,剪枝版上升 12%,蒸馏版上升 15%。…...

别再只盯着p值和FC了!用DisGeNET给你的Hub Gene打分,提升下游验证成功率
别再只盯着p值和FC了!用DisGeNET给你的Hub Gene打分,提升下游验证成功率 在基因功能研究的海洋中,Hub Gene如同灯塔般指引着研究方向。然而,许多研究者仍被困在传统筛选方法的局限中——过度依赖差异表达基因的p值和fold change阈…...

B站缓存视频拯救计划:3分钟实现m4s转MP4永久保存
B站缓存视频拯救计划:3分钟实现m4s转MP4永久保存 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾因B站视频突然下架而痛失珍…...

BilibiliDown:B站视频批量下载的终极解决方案
BilibiliDown:B站视频批量下载的终极解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibi…...

FPGA验证核心:Vivado中功能与代码覆盖率的实战指南
1. 项目概述:为什么验证是FPGA开发的重中之重? 如果你刚接触FPGA开发,可能会觉得写代码(HDL)是最核心、最花时间的部分。但等你真正上手几个项目,尤其是那些需要流片或者部署到关键系统的项目后,…...

昇思大模型预训练数据来源
昇思 MindSpore 大模型(如鹏程・盘古、Qwen、Skywork 等)的预训练数据以中文为核心、多源异构融合、高质量过滤为特点,依托开源数据、互联网爬虫、电子书与领域数据构建,经分布式清洗、去重、过滤后形成百亿至千亿级 Token 的训练…...

轻松解包网易游戏资源:unnpk工具完整使用指南
轻松解包网易游戏资源:unnpk工具完整使用指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 想要探索网易游戏如《阴阳师》、《魔法禁书目录》中的精美角色立…...