【机器学习导引】ch5-神经网络
Q&A
-
1x1 卷积层在深度学习中的作用?
1x1 卷积层在深度学习中具有几个重要的作用:
- 通道压缩:1x1卷积可以通过调整输出通道数来减少特征图的深度,从而降低计算成本和参数数量。这有助于在保持特征的情况下简化模型。
- 特征融合:1x1 卷积可以看作是对每个像素点的不同通道进行线性组合,能够有效地融合不同通道的信息,增强特征表示能力。
- 增加非线性:在1x1卷积后通常会加上激活函数(如ReLU),这可以引入非线性变换,从而使模型更具表达能力。
- 作为瓶颈层:在Inception模块和其他网络架构中,1x1卷积常被用作瓶颈层,先进行降维再进行更大尺寸卷积(如3x3或5x5),以减少后续层的计算量。
- 提高网络深度:通过在网络中引入多个 1x1 卷积层,可以构建更深的网络结构,从而学习更复杂的特征。
二分类模型中权重更新
更新公式:
w i = w i + Δ w i Δ w i = η y i x i w_i = w_i+\Delta w_i \\ \Delta w_i = \eta y_ix_i wi=wi+ΔwiΔwi=ηyixi
其中,
- η ∈ ( 0 , 1 ) \eta \in (0,1) η∈(0,1) 是学习率
- 感知器的输出为: y i ^ \hat{y_i} yi^
- 真实标签值为: y i y_i yi
情景1: y i = 1 y_i = 1 yi=1 , 但模型预测 y ^ i = − 1 \hat{y}_i = -1 y^i=−1
这个情景表示:
-
真实标签 y i y_i yi 是 1 1 1(表示正类)。
-
模型当前的预测 y ^ i \hat{y}_i y^i 是 − 1 -1 −1(表示模型预测错误,判为负类)。
y i ^ = s i g n ( w T x i ) = − 1 \hat{y_i} = sign(w^Tx_i) = -1 yi^=sign(wTxi)=−1
-
根据 y ^ i = sign ( w T x i ) = − 1 \hat{y}_i = \text{sign}(w^T x_i) = -1 y^i=sign(wTxi)=−1 ,可以推出当前的权重 w T x i < 0 w^T x_i < 0 wTxi<0 ,即权重和输入特征的点积小于 0 0 0,导致预测错误。
更新后的推导过程
模型希望通过调整权重来更正分类结果。因此,采用梯度更新的方式:
-
更新公式:
y ^ i n e w = sign ( ( w + η y i x i ) T x i ) \hat{y}_i^{new} = \text{sign}((w + \eta y_i x_i)^T x_i) y^inew=sign((w+ηyixi)Txi)
-
展开推导:
y ^ i n e w = sign ( w T x i + η y i x i T x i ) \hat{y}_i^{new} = \text{sign}(w^T x_i + \eta y_i x_i^T x_i) y^inew=sign(wTxi+ηyixiTxi)
再进一步简化为:
y ^ i n e w = sign ( w T x i + η ∥ x i ∥ 2 2 ) \hat{y}_i^{new} = \text{sign}(w^T x_i + \eta \|x_i\|_2^2) y^inew=sign(wTxi+η∥xi∥22)
其中, ∥ x i ∥ 2 2 \|x_i\|_2^2 ∥xi∥22 是输入特征 x i x_i xi 的 L 2 L2 L2 范数平方。
学习率的选择条件
为了使模型的更新后预测正确,即 y ^ i n e w = y i = 1 \hat{y}_i^{new} = y_i = 1 y^inew=yi=1 ,需要满足以下条件:
w T x i + η ∥ x i ∥ 2 2 > 0 w^T x_i + \eta \|x_i\|_2^2 > 0 wTxi+η∥xi∥22>0
通过选择合适的学习率 η \eta η ,保证这个不等式成立,即模型能够将输入正确分类为正类。
总结
这部分课件展示了如何通过梯度更新权重来纠正分类错误。其核心思想是:当模型错误地预测时,利用标签信息 y i y_i yi 来调整权重,使得更新后的点积 w T x i w^T x_i wTxi 加上一个正数项 η ∥ x i ∥ 2 2 \eta \|x_i\|_2^2 η∥xi∥22 后变为正值,从而让模型的预测变得正确。
这个过程是感知机算法(Perceptron)或神经网络权重更新中的典型步骤之一。通过合适的学习率控制,每次调整都能逐步逼近正确分类。
直观解释
对于任一直线 W 0 + W 1 X 1 + W 2 X 2 = 0 W_0+ W_1X_1 +W_2X_2=0 W0+W1X1+W2X2=0,当 W 1 > 0 W_1>0 W1>0 时,左边的点代入方程小于 0 0 0 ,右边的点则大于 0 0 0。
**注:**事实上,任何直线的方程都可以写成 W 0 + W 1 X 1 + W 2 X 2 = 0 W_0+ W_1X_1 +W_2X_2=0 W0+W1X1+W2X2=0,且 W 1 > 0 W_1>0 W1>0的形式。
深度神经网络
梯度下降
批量梯度下降(Batch Gradient Descent,BGD)

批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。
优点:
(1)一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时, B G D BGD BGD 一定能够得到全局最优。
缺点:
(1)当样本数目 m m m 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
随机梯度下降(Stochastic Gradient Descent,SGD)

随机梯度下降法不同于批量梯度下降,随机梯度下降是每次迭代使用一个样本来对参数进行更新。使得训练速度加快。
优点:
(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下, S G D SGD SGD 仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
小批量梯度下降(Mini-Batch Gradient Descent, MBGD)

小批量梯度下降是对批量梯度下降以及随机梯度下降的一个折中办法。其思想是:每次迭代 使用 batch_size 个样本来对参数进行更新。
优点:
(1)通过矩阵运算,每次在一个 b a t c h batch batch 上优化神经网络参数并不会比单个数据慢太多。
(2)每次使用一个 batch 可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。(比如上例中的30W,设置batch_size=100时,需要迭代 3000 次,远小于 S G D SGD SGD 的 30 W 30W 30W 次)
(3)可实现并行化。
缺点:
(1)batch_size的不当选择可能会带来一些问题。
batcha_size的选择带来的影响:
(1)在合理地范围内,增大batch_size的好处:
a. 内存利用率提高了,大矩阵乘法的并行化效率提高。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
c. 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
(2)盲目增大batch_size的坏处:
a. 内存利用率提高了,但是内存容量可能撑不住了。
b. 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
c. Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
交叉熵损失函数(Cross-Entropy Loss)
也称为对数损失函数(log loss)。其数学表达式如下:
L C E ( y , f ( w ; x ) ) = − ∑ c = 1 C y c log ( f ( w ; x ) c ) L_{CE}(y, f(\mathbf{w}; \mathbf{x})) = - \sum_{c=1}^{C} y_c \log(f(\mathbf{w}; \mathbf{x})_c) LCE(y,f(w;x))=−c=1∑Cyclog(f(w;x)c)
- 交叉熵损失函数:这是用于分类问题中的一种常用损失函数,特别适用于多分类任务。在这种情况下,模型的输出是每个类别的概率分布,交叉熵度量了真实类别标签与模型预测的概率分布之间的差异。
- 公式中的符号:
- y c y_c yc 是实际的标签,它是一个独热向量(one-hot vector),在正确的类别位置上为 1 1 1,其他位置为 0 0 0。
- f ( w ; x ) c f(\mathbf{w}; \mathbf{x})_c f(w;x)c 是模型对类别 c c c 的预测概率, w \mathbf{w} w 是模型的权重, x \mathbf{x} x 是输入数据。
- C C C 表示类别总数。
- log ( f ( w ; x ) c ) \log(f(\mathbf{w}; \mathbf{x})_c) log(f(w;x)c) 是预测概率的对数,交叉熵函数通过求和计算每个类别的对数损失。
- 直观理解:交叉熵损失衡量的是模型预测的概率分布和真实标签之间的距离。它惩罚模型对正确类别的预测概率较低的情况。当模型预测的类别概率与真实标签越接近,损失越小;如果模型偏离真实标签的预测较远,损失则会增大。
交叉熵(Cross-Entropy):
-
公式为:
H ( p , q ) = − E p [ log q ] = − ∑ i = 1 n p ( x i ) log q ( x i ) H(p, q) = -E_p[\log q] = -\sum_{i=1}^n p(x_i) \log q(x_i) H(p,q)=−Ep[logq]=−i=1∑np(xi)logq(xi)
-
这里的 p p p 和 q q q 分别代表两个概率分布。交叉熵表示两个分布之间的不确定性程度。它在信息论中用于衡量实际分布 p p p 与估计分布 q q q 的差异。
-
交叉熵值越小,说明两个分布越接近。
总结来说
- 交叉熵损失函数是机器学习中常用的损失函数,用于优化分类模型,使其预测分布更接近真实分布;
- 交叉熵则是衡量两个概率分布相似性的度量。
焦点损失函数(Focal Loss)
-
焦点损失函数公式:
F L ( p t ) = − ( 1 − p t ) γ log ( p t ) FL(p_t) = - (1 - p_t)^{\gamma} \log(p_t) FL(pt)=−(1−pt)γlog(pt)
- 其中, p t = ( f ( w ; x ) ) t p_t = (f(\mathbf{w}; \mathbf{x}))_t pt=(f(w;x))t ,表示模型对真实标签 t t t 的预测概率, t ∈ { 1 , … , C } t \in \{1, \dots, C\} t∈{1,…,C} 表示样本的真实标签类别。
- γ \gamma γ 是一个调节参数,用于调整对难分类样本和易分类样本的关注度。较大的 γ \gamma γ 值会增加对难分类样本的惩罚。
-
焦点损失的意义:
- 焦点损失的引入是为了应对类别不平衡问题,尤其在目标检测任务中,通常存在大量的背景(负样本)和少量的目标物体(正样本)。
- 通过 ( 1 − p t ) γ (1 - p_t)^{\gamma} (1−pt)γ 这一项,焦点损失会对预测概率较低的难分类样本赋予更高的权重,而对易分类样本的损失权重减小。这样,模型可以更多地关注那些难以分类的样本。
卷积神经网络
基础知识:
- 卷积
- 激活函数:引入非线性功能
- 池化Pooling:
- 减少特征维度,提升效率
- 对小幅度平移保持不变
卷积

输入: N × N N \times N N×N
卷积核: F × F F \times F F×F
步长: S S S
输出: [ ( N − F ) / S + 1 ] × [ ( N − F ) / S + 1 ] [(N-F)/S+1]\times[(N-F)/S+1] [(N−F)/S+1]×[(N−F)/S+1]
padding

输入: N × N N \times N N×N
卷积核: F × F F \times F F×F
步长: S S S
填充: P P P
输出: [ ( N − F + 2 P ) / S + 1 ] × [ ( N − F + 2 P ) / S + 1 ] [(N-F+2P)/S+1]\times[(N-F+2P)/S+1] [(N−F+2P)/S+1]×[(N−F+2P)/S+1]
常见网络
AlexNet网络【2012】
参考链接:
- https://zhuofujiang.github.io/2019/11/20/卷积神经网络结构-AlexNet/
- https://xinpingwang.github.io/2019/12/15/alexnet/

网络结构如上图所示,共有5个卷积层,3个最大池化层,3个全连接层。这是2012年由Alex Krizhevsky等人提出的卷积神经网络,用于图像分类。让我逐层解释:
-
输入层:输入的图像尺寸为 224x224x3,表示 224x224 像素的RGB图像。
-
第一层卷积层:卷积核大小为 11x11,步长为 4,输出尺寸为 55x55x48,之后跟随了一个最大池化层。
-
48 是什么意思
图中标注的“48”表示第一层卷积层中使用了48个卷积核(或滤波器)。这意味着这一层会输出48个特征图,每个特征图的尺寸为55x55。因此,这一层的输出是一个尺寸为55x55x48的三维张量。
-
-
第二层卷积层:卷积核大小为 5x5,步长为 1,输出尺寸为 27x27x128,之后也跟随一个最大池化层。
-
第三、第四、第五层卷积层:卷积核大小为 3x3,步长为 1。第三层输出 192 个特征图,第四层和第五层分别输出192和128个特征图。第五层后也有一个最大池化层。
-
全连接层:接下来是三个全连接层,每层有 4096 个神经元。这三层全连接层用于将特征映射到分类空间。
-
输出层:最后的输出层有1000个神经元,对应ImageNet数据集中的1000个类别。
创新点:
- 首次在CNN中采用ReLU激活函数
- 首次在CNN中采用dropout技术
- 采用大量数据增强
LeNet网络【1998】
参考链接:https://1187100546.github.io/2020/01/14/lenet-5/

这是 1998 年由 Yann LeCun 等人提出的卷积神经网络,主要用于手写数字识别(如 MNIST 数据集)。LeNet 是较早的卷积神经网络之一,在图像分类任务中开创了深度学习的先河。
- 输入层:输入图像大小为 32x32(在 MNIST 数据集中,通常将 28x28 的图像填充为 32x32)。
- C1层(卷积层):使用 6 个 5x5 的卷积核,输出 6 个特征图,每个特征图的尺寸为 28x28。这个层提取了局部的图像特征。
- S2层(池化层):进行 2x2 的平均池化,步长为2,输出6个特征图,每个特征图的尺寸为14x14。池化层用于降低特征图的尺寸,同时保留重要特征。
- C3层(卷积层):使用 16 个 5x5 的卷积核,输出16个特征图,每个特征图的尺寸为10x10。
- S4层(池化层):进行2x2的平均池化,步长为2,输出16个特征图,每个特征图的尺寸为5x5。
- C5层(全连接层):这一层可以看作是卷积层或全连接层,有120个节点,每个节点连接到S4层的所有16个5x5特征图。
- F6层(全连接层):有84个神经元,使用Sigmoid激活函数。
- 输出层:最后输出10个节点,对应于10个类别(如0到9的数字分类)。
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), // 将多维特征图展平为一维,以便输入到全连接层中。nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10)
)
- 定义一个二维卷积层,输入通道为 1(灰度图像),输出通道为 6,卷积核大小为 5x5。这个层对应于 LeNet 中的 C1 层。
- 激活函数,使用 S i g m o i d Sigmoid Sigmoid 将输出值映射到 ( 0 , 1 ) (0,1) (0,1) 之间。
- 定义一个 2x2 的平均池化层,步长为 2。该层会将特征图尺寸缩小一半,对应 LeNet 中的 S2层。
- 全连接层,输入大小为 16x5x5(S4层的输出特征图展平为400个特征),输出大小为 120,对应LeNet 中的 C5 层。
VGG 网络【2014】
参考链接:https://zh.d2l.ai/chapter_convolutional-modern/vgg.html

VGG网络是一种深度卷积神经网络架构,由牛津大学的视觉几何组(Visual Geometry Group)在2014年提出。VGG网络以其简单而有效的设计而闻名,主要特点包括:
- 统一的卷积核大小:VGG网络使用了多个3x3的小卷积核,所有的卷积层都采用相同大小的卷积核,这种设计使得网络结构非常简单而易于理解。
- 深度结构:VGG网络通常有多个卷积层和全连接层的堆叠,典型的模型如VGG16和VGG19分别具有16和19个权重层(包括卷积层和全连接层)。深度的网络结构使得VGG能够捕捉到更复杂的特征。
- 池化层:在卷积层之后,VGG使用2x2的最大池化层进行下采样,这有助于逐渐减小特征图的尺寸,同时增加特征的抽象程度。
- 全连接层:在网络的最后,VGG包含几个全连接层,用于将提取到的特征映射到最终的分类结果。
- 较少的参数量:尽管VGG网络很深,但由于使用了小卷积核,其参数数量比一些其他深度网络(如GoogleNet)要少,这使得VGG在一定程度上避免了过拟合。
VGG网络在图像分类、目标检测等任务中表现出色,并且其设计理念影响了后续的网络架构,如ResNet等。由于其结构简单,VGG也成为了很多研究和应用中的基准模型。
创新点
- 相比AlexNet网络更深
- 仅采用3x3卷积核和2x2最大池化
GoogleNet 网络【2014】

GoogLeNet架构

Inception块的架构
GoogleNet(也称为Inception V1)是一种深度卷积神经网络架构,由谷歌团队在2014年提出。它在ImageNet挑战赛中表现出色,以其创新的Inception模块而闻名。以下是GoogleNet的一些关键特点:
- Inception模块:GoogleNet的核心是Inception模块,它通过并行的卷积层和池化层对输入特征进行多尺度处理。这些模块能够同时提取不同大小的特征,增强网络的表现力。
- 深度和宽度的平衡:GoogleNet使用了多个Inception模块,使网络既深又宽,同时在计算效率和性能之间取得平衡。
- 辅助分类器:为了缓解梯度消失问题,GoogleNet在中间层引入了辅助分类器。这些分类器可以在训练过程中提供额外的梯度信号,帮助优化深层网络。
- 减少参数数量:GoogleNet通过使用1x1卷积层有效地减少了参数数量,避免了过拟合。这使得网络在保持高性能的同时,计算成本较低。
- 全局平均池化:在网络的最后,GoogleNet采用全局平均池化替代传统的全连接层,这不仅减少了模型参数,还有效提高了泛化能力。
GoogleNet的设计理念影响了后续的深度学习模型,特别是在高效性和灵活性方面,推动了Inception系列网络的发展。
创新点
- 相比VGG网络更深(22层)
- 采用Inception模块
- 没有全连接层
- 参数仅有5百万,仅AlexNet的1/12
ResNet 网络【2015】
参考链接:https://zh.d2l.ai/chapter_convolutional-modern/resnet.html

ResNet-18 架构

残差块
ResNet(Residual Network)是一种深度神经网络架构,最早由何恺明等人在2015年提出。它的主要创新是:
- 引入了**“残差学习”框架**
- 通过使用跳跃连接(skip connections),使得网络能够更容易地学习到残差函数,从而缓解深度网络训练中的梯度消失和爆炸问题。
ResNet的结构由多个残差块(residual blocks)组成,每个块包含两个或更多的卷积层以及一个跳跃连接,这样可以将输入直接加到块的输出上。通过这种方式,网络能够学习到恒等映射,从而在深层网络中保持有效的信息流。
创新点
- 更深的网络:可以构建非常深的网络(如152层或更深),而不出现性能退化。
- 易于训练:残差结构使得网络更容易优化,降低了训练的难度。
- 高效的特征学习:能够有效地捕捉和学习数据中的特征。
DNN 网络
DNN(Deep Neural Network)指的是深度神经网络的一个通用概念,通常用于描述**包含多个隐藏层的神经网络。**DNN的主要特点和组成包括:
- 多层结构:DNN 由输入层、多个隐藏层和输出层组成。隐藏层的数量和神经元的数量可以根据任务的复杂性进行调整。
- 非线性激活函数:DNN 中的每个神经元通常使用非线性激活函数(如ReLU、sigmoid或tanh)来引入非线性,使得网络能够学习复杂的映射关系。
- 特征学习:DNN 能够从原始输入数据中自动学习特征,无需手动提取特征。这使得它在许多任务(如图像分类、语音识别、自然语言处理等)中非常有效。
- 反向传播:DNN使用反向传播算法进行训练,通过计算损失函数的梯度来更新网络中的权重,以最小化预测误差。
- 应用广泛:DNN在各个领域的应用非常广泛,包括计算机视觉、语音识别、自然语言处理等,推动了深度学习的快速发展。
DNN是一种非常基础的深度学习模型,许多复杂的网络架构(如卷积神经网络CNN、循环神经网络RNN等)都是在DNN的基础上发展而来的。
相关文章:
【机器学习导引】ch5-神经网络
Q&A 1x1 卷积层在深度学习中的作用? 1x1 卷积层在深度学习中具有几个重要的作用: 通道压缩:1x1卷积可以通过调整输出通道数来减少特征图的深度,从而降低计算成本和参数数量。这有助于在保持特征的情况下简化模型。特征融合&am…...

【Axure原型分享】颜色选择器——填充颜色
今天和大家分享颜色选择器——填充颜色的原型模板,点击颜色区域可以弹出颜色选择器,点击可以选择对应颜色,颜色区域会变色我们选择的颜色,具体效果可以观看下方视频或者打开预览地址体验。 【原型效果】 【Axure高保真原型】颜色…...

怎么安装行星减速电机才是正确的
行星减速电机由于其高效、精密的传动能力,广泛应用于自动化设备、机器人、机床以及其他需要精准控制的领域。正确的安装行星减速电机对于确保设备的性能与延长使用寿命至关重要。 一、前期准备 在进行行星减速电机的安装之前,必须做好充分的前期准备工作…...

Unity程序化生成地形
制作地形: 绘制方块逐个绘制方块并加噪波高度删除Gizmos和逐个绘制 1.draw quad using System.Collections; using System.Collections.Generic; using UnityEngine;[RequireComponent(typeof(MeshFilter))] public class mesh_generator : MonoBehaviour {Mesh m…...

Vxe UI vue vxe-table 表格中使用下拉表格,单元格渲染下拉表格
Vxe UI vue vxe-table 表格中使用下拉表格,单元格渲染下拉表格 单元格中渲染下拉表格,需要使用到 vxe-table-select 这个组件,在 vxe-table 4.7 中使用非常简单,只需要配置好渲染器数据源就可以。 支持单选 也可以多选 代码 …...

Android开发教程实加载中...动效
Android开发教程实加载中…动效 加载中,发送中,匹配中都可以用,就是后面是三个点还是两个点,不断在切换 一、思路: 隔500ms发送一次,改变内容 二、效果图: 看视频更加直观点: An…...

NVR设备ONVIF接入平台EasyCVR视频融合平台智慧小区视频监控系统建设方案
一、方案背景 智慧小区构成了“平安城市”建设的基石。随着社会的进步,社区安全问题逐渐成为公众关注的热点。诸如高空抛物、乱丢垃圾、破坏车辆、入室盗窃等不文明行为和违法行为频繁出现。目前,许多小区的物业管理和安全防护系统仍然较为简单和陈旧&a…...

适配器模式适用的场景
适配器模式是一种常用的设计模式,能够将不兼容的接口转换为客户端所需的接口。在实际开发中,我们常常会遇到需要统一接口、替换外部系统、兼容旧接口或适配不同数据格式的情况。本文将结合详细的代码示例,介绍适配器模式的适用场景。 1. 统一…...

Ambari里面添加hive组件
1.创建hive数据库 在添加hive组件之前需要做的事情,先在master这个虚拟机里面创建好hive 先进入虚拟机里面进入mysql 然后输入这个命令看看有没有自己创建的hive数据库 show databases;有的话会显示下面这个样子 没有的同学使用以下命令可以在MySQL中创建hive数…...
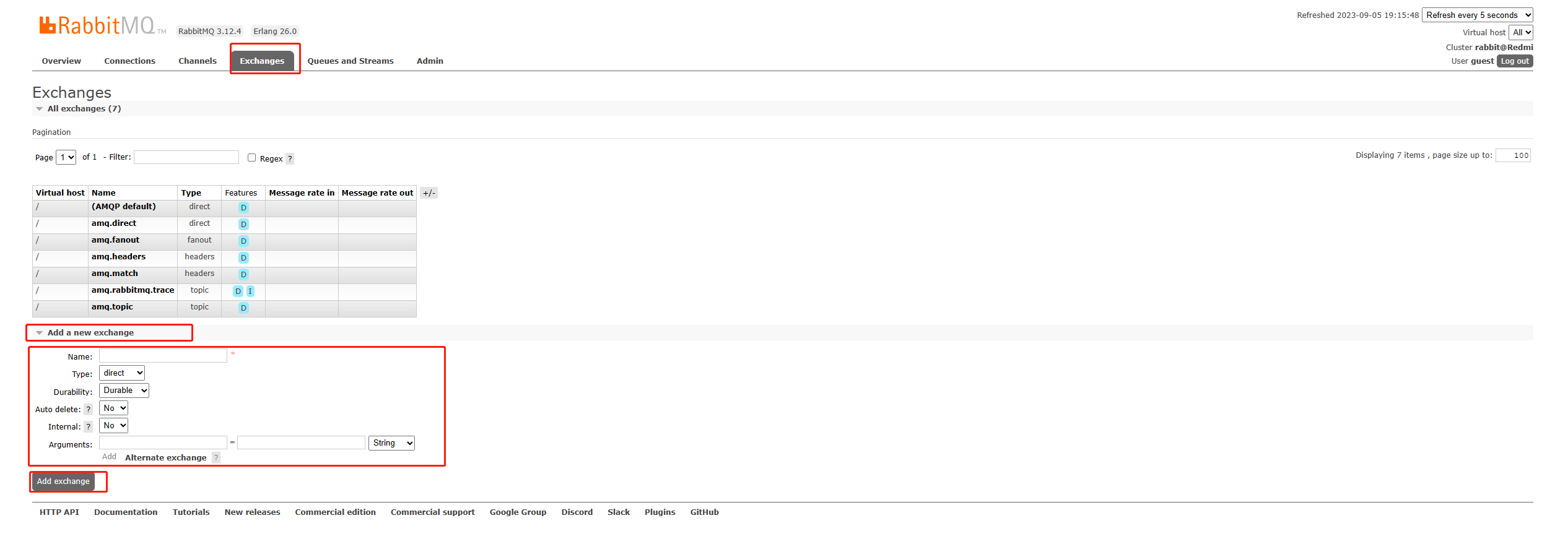
Windows部署rabbitmq
本次安装环境: 系统:Windows 11 软件建议版本: erlang OPT 26.0.2rabbitmq 3.12.4 一、下载 1.1 下载erlang 官网下载地址: 1.2 下载rabbitmq 官网下载地址: 建议使用解压版,安装版可能会在安装软件…...

【Flask】四、flask连接并操作数据库
目录 前言 一、 安装必要的库 二、配置数据库连接 三、定义模型 四、操作数据库 1.添加用户 2.删除用户 3.更新用户信息 4查询所有用户 五、测试结果 前言 在Flask框架中,数据库的操作是一个核心功能,它允许开发者与后端数据库进行交互…...

ES跟Kafka集成
配合流程 1. Kafka作为分布式流处理平台,能够实时收集和处理不同数据源的数据流; 2. 通过Kafka Connect或者Logstash等中间件,可以将Kafka中的数据流实时推送到Elasticsearch中; 3. Elasticsearch接收到数据后,会根据…...

Python Matplotlib:基本图表绘制指南
Python Matplotlib:基本图表绘制指南 Matplotlib 是 Python 中一个非常流行的绘图库,它以简单易用和功能丰富而闻名,适合各种场景的数据可视化需求。在数据分析和数据科学领域,Matplotlib 是我们展示数据的有力工具。本文将详细讲…...

供应商图纸外发:如何做到既安全又高效?
供应商跟合作伙伴、客户之间会涉及到图纸外发的场景,这是一个涉及数据安全、效率及合规性的重要环节。供应商图纸发送流程一般如下: 1.申请与审批 采购人员根据需要提出发放图纸的申请并提交审批; 采购部负责人审批发放申请,确…...

探索 Move 编程语言:智能合约开发的新纪元
目录 引言 一、变量的定义 二、整型 如何在Move中表示小数和负数? 三、运算符 as运算符 布尔型 地址类型 四、什么是包? 五、什么是模块? 六、如何定义方法? 方法访问权限控制 init方法 总结 引言 Move 是一种专为区…...

vue3+vant实现视频播放(含首次禁止进度条拖拽,视频看完后恢复,保存播放视频进度,刷新及下次进入继续播放,判断视频有无全部看完等)
1、效果图 2、 <div><videocontrolsclass"video_player"ref"videoPlayer":src"videoSrc"timeupdate"handleTimeUpdate"play"onPlay"pause"onPause"ended"onVideoEnded"></video><…...

情感强度分析:精确衡量文本情感强弱的 AI 技术
情感强度分析:精确衡量文本情感强弱的 AI 技术 一、引言 在当今信息爆炸的时代,我们每天都会接触到大量的文本信息。这些文本中蕴含着各种各样的情感,如喜悦、悲伤、愤怒、恐惧等。如何准确地理解和分析这些文本的情感强度,对于…...

工厂方法模式与抽象工厂模式
工厂方法模式 (Factory Method) 定义: 工厂方法模式是一种创建型设计模式,它定义了一个用于创建对象的接口,但让子类决定实例化哪个类。工厂方法将类的实例化推迟到子类。 优点: 解耦:客户端代码与具体的产品类解耦…...

「Math」初等数学知识点大纲(占位待处理)
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasoli…...

百元高性价比头戴式降噪耳机选哪款?四款平价性价比品牌别错过!
随着科技的发展,现在的头戴式耳机真的是越来越多样了,很多的朋友在选购耳机的时候,不知道哪一款头戴式耳机的性价比较高,究竟百元高性价比头戴式降噪耳机选哪款?身为一名数码爱好者,这里就给大家推带来四款…...

Nintendo Switch文件管理终极指南:NSC_BUILDER如何成为你的游戏库管家
Nintendo Switch文件管理终极指南:NSC_BUILDER如何成为你的游戏库管家 【免费下载链接】NSC_BUILDER Nintendo Switch Cleaner and Builder. A batchfile, python and html script based in hacbuild and Nuts python libraries. Designed initially to erase title…...

5分钟解锁虚拟多屏生产力:Rust驱动打造Windows虚拟显示器终极方案
5分钟解锁虚拟多屏生产力:Rust驱动打造Windows虚拟显示器终极方案 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc 项目地址: htt…...

剪流AI事业大使是不是割韭菜?深度解析其真实运作细节与收益模型
近年来,“AI事业大使”成为一个热门话题,尤其是剪流AI推出的相关计划,引发了广泛讨论。其中,“AI事业大使是不是割韭菜”是许多观望者心中的核心疑问。本文将基于其公开的运作细节与权益体系,进行客观、深度的解析&…...

m4s-converter:一键解决B站缓存视频的格式兼容难题
m4s-converter:一键解决B站缓存视频的格式兼容难题 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的场景&…...

新手入门教程使用Python快速调用Taotoken提供的多模型API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门教程使用Python快速调用Taotoken提供的多模型API服务 对于刚开始接触大模型API的开发者而言,直接对接不同厂商…...

长期使用taotoken服务观察其api服务的稳定性与可用性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用 Taotoken 服务观察其 API 服务的稳定性与可用性 在持续数周将 Taotoken 作为主要的大模型 API 接入平台进行开发与测试后…...

抖音去水印下载器终极指南:批量保存视频、音乐、图集和直播
抖音去水印下载器终极指南:批量保存视频、音乐、图集和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

传统 OA 系统为什么难以满足现代企业管理需求
传统 OA 系统为什么难以满足现代企业管理需求 OA 曾经是很多企业数字化的起点:通知公告、请假报销、文件流转、会议管理、用印审批,让办公室从纸质时代进入线上时代。但今天,企业对 OA 的期待已经变了。 现代企业不只需要“把审批搬到线上…...

WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案
WandEnhancer:彻底解锁WeMod专业版功能的终极解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的种种限制而烦恼吗…...

如何彻底解决C盘空间不足:Windows Cleaner终极清理指南
如何彻底解决C盘空间不足:Windows Cleaner终极清理指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘空间不足的困扰?…...