YOLOv6-4.0部分代码阅读笔记-dbb_transforms.py
dbb_transforms.py
yolov6\layers\dbb_transforms.py
目录
dbb_transforms.py
1.所需的库和模块
2.def transI_fusebn(kernel, bn):
3.def transII_addbranch(kernels, biases):
4.def transIII_1x1_kxk(k1, b1, k2, b2, groups):
5.def transIV_depthconcat(kernels, biases):
6.def transV_avg(channels, kernel_size, groups):
7.def transVI_multiscale(kernel, target_kernel_size):
1.所需的库和模块
import torch
import numpy as np
import torch.nn.functional as F2.def transI_fusebn(kernel, bn):
# 它用于将一个卷积核与一个批量归一化(Batch Normalization)层融合。这种融合通常用于在模型部署时简化网络结构,减少计算量和内存消耗。
# 1.kernel :卷积核的权重张量。
# 2.bn :批量归一化层,预期是一个 nn.BatchNorm2d 的实例。
def transI_fusebn(kernel, bn):# 获取批量归一化层的缩放因子(也称为权重)。gamma = bn.weight# 计算批量归一化层的标准差,其中 running_var 是运行方差, eps 是用于数值稳定性的小常数。std = (bn.running_var + bn.eps).sqrt()# kernel * ((gamma / std).reshape(-1, 1, 1, 1)) :将卷积核与缩放因子除以标准差的值相乘,并重塑为 (-1, 1, 1, 1) 的形状,以匹配卷积核的维度。这样,每个卷积核通道都被乘以相应的缩放因子。# bn.bias - bn.running_mean * gamma / std :计算去除均值偏移后的偏置。这里, running_mean 是批量归一化层的运行均值, gamma 是缩放因子, std 是标准差。# 返回融合后的卷积核和偏置。return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std3.def transII_addbranch(kernels, biases):
# 它用于将多个卷积核和偏置相加,通常用于在模型部署时合并具有相同功能的多个分支。
# 1.kernels :一个包含多个卷积核权重张量的列表或元组。
# 2.biases :一个包含多个卷积核偏置张量的列表或元组。
def transII_addbranch(kernels, biases):# 将 kernels 列表中的所有卷积核权重张量相加,得到总的卷积核权重张量。# 将 biases 列表中的所有偏置张量相加,得到总的偏置张量。# 返回合并后的卷积核和偏置。return sum(kernels), sum(biases)
# 这个方法可以在需要将多个卷积分支合并为一个单一卷积层的场景中使用,尤其是在模型部署时。4.def transIII_1x1_kxk(k1, b1, k2, b2, groups):
# 它用于将两个卷积核(一个1x1和一个kxk)以及它们的偏置进行融合。这种融合通常用于在模型部署时简化网络结构,特别是在处理分组卷积时。
# 1.k1 :第一个卷积核(1x1卷积核)的权重张量。
# 2.b1 :第一个卷积核的偏置张量。
# 3.k2 :第二个卷积核(kxk卷积核)的权重张量。
# 4.b2 :第二个卷积核的偏置张量。
# 5.groups :分组卷积的组数。
def transIII_1x1_kxk(k1, b1, k2, b2, groups):# 当 groups 参数为 1 时,表示没有使用分组卷积,或者所有卷积核都在同一组中。if groups == 1:# 使用 PyTorch 的 F.conv2d 函数将 kxk 卷积核 k2 与转置后的 1x1 卷积核 k1 进行卷积操作。# k1.permute(1, 0, 2, 3) 将 k1 的维度从 (out_channels, in_channels, height, width) 转换为 (in_channels, out_channels, height, width) ,以匹配 F.conv2d 函数的要求。k = F.conv2d(k2, k1.permute(1, 0, 2, 3))# 将 kxk 卷积核 k2 与 1x1 卷积核的偏置 b1 相乘。# b1.reshape(1, -1, 1, 1) 将 b1 从一维张量转换为四维张量,以便与 k2 进行元素乘法。然后,通过 .sum((1, 2, 3)) 在空间维度(高度和宽度)上对结果进行求和,得到新的偏置 b_hat 。b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))# 多组情况,即当卷积核被分成多个组进行处理时。else:# 初始化两个列表,用于存储每个分组计算得到的卷积核和偏置。k_slices = []b_slices = []# 将1x1卷积核 k1 转置,以适应 F.conv2d 的输入要求。k1_T = k1.permute(1, 0, 2, 3)# 计算1x1卷积核每组的通道数。k1_group_width = k1.size(0) // groups# 计算kxk卷积核每组的通道数。k2_group_width = k2.size(0) // groups# 遍历每个分组,对每个分组的卷积核和偏置进行操作。for g in range(groups):# 提取1x1卷积核的当前分组切片。k1_T_slice = k1_T[:, g*k1_group_width:(g+1)*k1_group_width, :, :]# 提取kxk卷积核的当前分组切片。k2_slice = k2[g*k2_group_width:(g+1)*k2_group_width, :, :, :]# 对当前分组的kxk卷积核和1x1卷积核进行卷积操作,并将结果添加到 k_slices 列表中。k_slices.append(F.conv2d(k2_slice, k1_T_slice))# 计算当前分组的偏置,并将结果添加到 b_slices 列表中。b_slices.append((k2_slice * b1[g * k1_group_width:(g+1) * k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))# def transIV_depthconcat(kernels, biases): -> 它用于将多个卷积核和偏置在深度维度上进行拼接(concatenation)。返回拼接后的卷积核和偏置。 -> return torch.cat(kernels, dim=0), torch.cat(biases)# 使用 transIV_depthconcat 函数将所有分组的卷积核和偏置在深度维度上进行拼接,得到最终的卷积核 k 和偏置 b_hat 。k, b_hat = transIV_depthconcat(k_slices, b_slices)# 返回 融合后的卷积核 k 和 偏置 b_hat + b2 。return k, b_hat + b25.def transIV_depthconcat(kernels, biases):
# 它用于将多个卷积核和偏置在深度维度上进行拼接(concatenation)。这种操作通常用于在模型中合并来自不同分支的特征,特别是在深度学习模型中处理多通道数据时。
# 1.kernels :一个包含多个卷积核权重张量的列表或元组。.
# 2.biases :一个包含多个卷积核偏置张量的列表或元组。
def transIV_depthconcat(kernels, biases):# torch.cat(kernels, dim=0) :在深度维度(即通道维度)上拼接所有卷积核权重张量。这里的 dim=0 表示在第一个维度上进行拼接,通常对应于通道数。# torch.cat(biases) :将所有偏置张量拼接在一起。由于偏置通常是一维张量,因此不需要指定维度。# 返回拼接后的卷积核和偏置。return torch.cat(kernels, dim=0), torch.cat(biases)6.def transV_avg(channels, kernel_size, groups):
# 它用于创建一个平均池化操作的等效卷积核。
# 1.channels :输入和输出的通道数。
# 2.kernel_size :卷积核的大小,也就是平均池化的窗口大小。
# 3.groups :分组数,用于确定卷积核的形状。
def transV_avg(channels, kernel_size, groups):# 计算每个组的输入通道数。input_dim = channels // groups# 创建一个形状为 (channels, input_dim, kernel_size, kernel_size) 的零张量,用于存储卷积核的值。k = torch.zeros((channels, input_dim, kernel_size, kernel_size))# np.tile(A,reps)# 函数可对输入的数组,元组或列表进行重复构造,其输出是数组。# 该函数有两个参数:# A :输入的数组,元组或列表。# reps :重复构造的形状,可为数组,元组或列表。# 为卷积核的每个通道设置值。这里使用 np.arange(channels) 生成通道索引, np.tile(np.arange(input_dim), groups) 生成每个组内的通道索引,然后为每个位置设置值为 1.0 / kernel_size ** 2 。# 这样,卷积核的每个元素都是平均池化窗口大小的倒数,实现了平均池化的效果。k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2# 返回创建的平均池化等效卷积核 k 。return k
# 这个方法可以在需要将平均池化层转换为卷积层的场景中使用,尤其是在模型部署时。7.def transVI_multiscale(kernel, target_kernel_size):
# 它用于将一个卷积核调整到目标尺寸,通常是通过填充(padding)来实现。这个函数可以帮助在不同尺寸的卷积核之间进行转换,特别是在需要将卷积核适配到特定大小时。
# 尚未使用非方形内核( kernel.size(2) != kernel.size(3) )或偶数大小内核进行测试
# This has not been tested with non-square kernels (kernel.size(2) != kernel.size(3)) nor even-size kernels
# 1.kernel :原始的卷积核权重张量。
# 2.target_kernel_size :目标卷积核的大小,通常是一个整数,表示期望的卷积核尺寸。
def transVI_multiscale(kernel, target_kernel_size):# 计算高度方向需要填充的像素数。 kernel.size(2) 是卷积核的高度。H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2# 计算宽度方向需要填充的像素数。 kernel.size(3) 是卷积核的宽度。W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2# torch.nn.functional.pad(input, pad, mode='constant', value=0)# F.pad 是 PyTorch 中的一个函数,用于对张量进行填充(padding)。这个函数可以对多维张量进行操作,按照指定的模式在张量的边界或内部添加值(通常是0)。# 参数 :# input :要进行填充的输入张量。# pad :一个元组,指定了每个边界的填充量。对于二维张量(例如图像), pad 元组的形式为 (left, right, top, bottom) 。对于三维张量,形式为 (left, right, top, bottom, front, back) 。# mode :填充模式,可选值为 'constant' 、 'reflect' 、 'replicate' 或 'circular' 。默认为 'constant' 。# 'constant' :填充常数值(由 value 参数指定)。# 'reflect' :反射填充,即张量的边界值会反射到另一边。# 'replicate' :复制填充,即张量的边界值会被复制。# 'circular' :循环填充,即张量的最后一个值会填充到开始位置,反之亦然。# value :用于 'constant' 模式下的填充值,默认为0。# 返回值 :# 返回填充后的张量。# 使用 PyTorch 的 F.pad 函数对卷积核进行填充。填充的参数 [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad] 分别对应于左、右、上、下的填充量。return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])# 在PyTorch框架中, nn.ReLU 和 F.relu 都用于实现 ReLU (Rectified Linear Unit,修正线性单元)激活函数,但它们在用法和场景上存在明显的区别。
# 以下是两者的主要区别:
# 1.本质差异
# nn.ReLU :这是一个类,继承自 torch.nn.Module 。它作为一个网络层(layer)存在,具有内部状态,适合在构建神经网络模型时使用。在定义模型时, nn.ReLU 需要被实例化并添加到模型中,以作为模型的一部分。
# F.relu :这是一个函数,属于 torch.nn.functional 模块。它作为一个函数接口存在,无内部状态,适用于在模型的前向传播(forward pass)中直接调用。
# 2.使用方式
# nn.ReLU :使用前需要先实例化,然后作为模型的一部分进行调用。例如,在模型的 forward 方法中,可以通过 self.relu(input) 的方式调用。
# F.relu :直接通过 torch.nn.functional.relu(input) 或简写为 F.relu(input) 的方式在 forward 方法中调用,无需实例化。
# 3.场景差异
# nn.ReLU :更适合在定义模型结构时使用,因为它可以被视为模型的一部分,具有更明确的层次结构。
# F.relu :更适用于快速原型开发或在前向传播中直接调用,因为它不需要实例化,使用起来更为简洁。
# 4.打印网络结构
# 当使用 print(model) 来打印模型结构时, nn.ReLU 会被视为模型的一层并显示出来,而 F.relu 则不会出现在模型结构的打印输出中,因为它只是作为函数调用的一部分。
# 5.性能与效果
# 两者在功能和效果上是等价的,都是实现 ReLU 激活函数。但是,由于 nn.ReLU 作为模型的一部分,可能在某些优化或自动微分方面与模型的其他部分有更好的集成。# 总结
# 选择 nn.ReLU 还是 F.relu 主要取决于使用场景和个人偏好。在定义模型结构时,推荐使用 nn.ReLU 以保持模型的清晰性和一致性。而在需要快速实现或调试时, F.relu 的简洁性可能更加吸引人。
# 两者在功能上是等价的,因此选择哪一种方式并不会对模型的性能产生显著影响。
相关文章:
YOLOv6-4.0部分代码阅读笔记-dbb_transforms.py
dbb_transforms.py yolov6\layers\dbb_transforms.py 目录 dbb_transforms.py 1.所需的库和模块 2.def transI_fusebn(kernel, bn): 3.def transII_addbranch(kernels, biases): 4.def transIII_1x1_kxk(k1, b1, k2, b2, groups): 5.def transIV_depthconcat(kernel…...
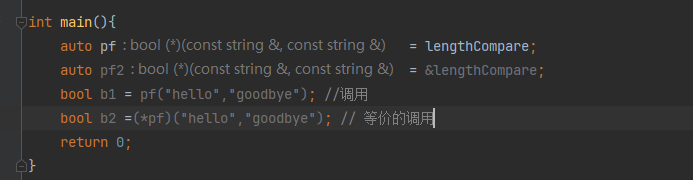
C++ 基础语法 一
C 基础语法 一 文章目录 C 基础语法 一const 限定符常量指针类型别名autodecltypeQStringvector迭代器指针和数组显示转换static_castconst_cast 函数尽量使用常量引用数组形参不要返回局部对象的引用和指针返回数组指针 C四种转换内联函数constexpr函数函数指针 const 限定符 …...

B2020 分糖果
题目描述 某个幼儿园里,有 55 位小朋友编号依次为 1,2,3,4,51,2,3,4,5 他们按照自己的编号顺序围坐在一张圆桌旁。他们身上有若干糖果,现在他们玩一个分糖果游戏。从 11 号小朋友开始,将自己的糖果均分成 33 份(如果有多余的糖果…...
VBA字典与数组第二十讲:如何在代码运行时创建数组
《VBA数组与字典方案》教程(10144533)是我推出的第三套教程,目前已经是第二版修订了。这套教程定位于中级,字典是VBA的精华,我要求学员必学。7.1.3.9教程和手册掌握后,可以解决大多数工作中遇到的实际问题。…...

字符串统计(Python)
接收键盘任意录入,分别统计大小写字母、数字及其它字符数量,打印输出。 (笔记模板由python脚本于2024年11月02日 08:23:31创建,本篇笔记适合熟悉python字符串并懂得基本编程技法的coder翻阅) 【学习的细节是欢悦的历程】 Python 官网…...

NVR小程序接入平台/设备EasyNVR多个NVR同时管理视频监控新选择
在数字化转型的浪潮中,视频监控作为安防领域的核心组成部分,正经历着前所未有的技术革新。随着技术的不断进步和应用场景的不断拓展,视频监控系统的兼容性、稳定性以及安全性成为了用户关注的焦点。NVR小程序接入平台/设备EasyNVR,…...
怎样能把图片做压缩处理?学会4款在线工具高效压缩图片
随着现在图片质量不断的提高,导致图片的大小也越来越大,很多的网上平台只能上传比较小的图片,那么可以使用压缩图片或者图片改尺寸的方式来修改图片大小,那么图片压缩的操作技巧是什么样的呢?本文将带大家了解4个操作简…...

ZooKeeper 客户端API操作
文章目录 一、节点信息1、创建节点2、获取子节点并监听节点变化3、判断节点是否存在4、客户端向服务端写入数据写入请求直接发给 Leader 节点写入请求直接发给 follow 节点 二、服务器动态上下线监听1、监听过程2、代码 三、分布式锁1、什么是分布式锁?2、Curator 框架实现分布…...
-限幅滤波法)
常用滤波算法(一)-限幅滤波法
文章目录 一、限幅滤波法原理二、C语言实现限幅滤波法三、代码解析定义限制值:限幅滤波函数:模拟获取新数据:主函数: 四、结论 限幅滤波法 限幅滤波法,作为一种简单而有效的滤波方法,通过限制信号的幅值范围…...

江协科技STM32学习- P33 实验-软件I2C读写MPU6050
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...
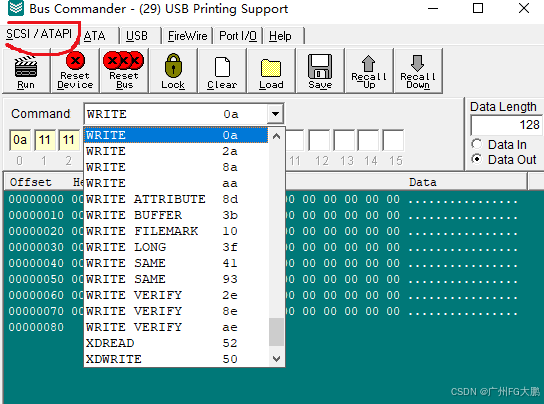
BusHound工具的使用-调试USB
12 1.Capture(捕捉按钮)、2.Save(保存按钮)、3.Setting(设置要监听的,输入输出)、4.Device(选择要监听的设备)、5.Help(帮助按钮)、6.Exit(退出按钮)。 一、Capture页面 1.Device 表示是29设备端口,打印机。 2.Phase,各类协议,…...

Hadoop生态圈框架部署(四)- Hadoop完全分布式部署
文章目录 前言一、Hadoop完全分布式部署(手动部署)1. 下载hadoop2. 上传安装包2. 解压hadoop安装包3. 配置hadoop配置文件3.1 虚拟机hadoop1修改hadoop配置文件3.1.1 修改 hadoop-env.sh 配置文件3.3.2 修改 core-site.xml 配置文件3.3.3 修改 hdfs-site…...

Spring Boot 与 Vue 共铸卓越采购管理新平台
作者介绍:✌️大厂全栈码农|毕设实战开发,专注于大学生项目实战开发、讲解和毕业答疑辅导。 🍅获取源码联系方式请查看文末🍅 推荐订阅精彩专栏 👇🏻 避免错过下次更新 Springboot项目精选实战案例 更多项目…...

leetcode3. Longest Substring Without Repeating Characters
Given a string s, find the length of the longest substring without repeating characters. Example 1: Input: s “abcabcbb” Output: 3 Explanation: The answer is “abc”, with the length of 3. Example 2: Input: s “bbbbb” Output: 1 Explanation: The ans…...

Mongodb使用视图连接两个集合
您可以使用 $lookup 为两个集合创建一个视图,然后对该视图运行查询。应用程序可以查询视图,而无需构建或维护复杂的管道。 例子 创建两个样本集合 inventory 和 orders: db.inventory.insertMany( [{ prodId: 100, price: 20, quantity: 1…...

SIP是什么?
SIP(Session Initiation Protocol,会话启动协议)是一个用于建立、更改和终止多媒体会话的应用层控制协议,其中的会话可以是IP电话、多媒体会话或多媒体会议。 SIP是IETF多媒体数据和控制体系结构的核心协议(最新RFC文档…...

Day 39 || 01背包、416. 分割等和子集
01背包 题目链接:卡码网第46题 二维解题思路:需要建立一个i行k列的dp数组,i表示每个物品,k代表容量,初始化数组子一列为0,第一行从背包开始能够放入起始为价值,其他都为0。for双循环先背包后物…...

调用detr-resnet-50进行目标检测
from transformers import DetrImageProcessor, DetrForObjectDetection import torch from PIL import Imageimage = Image.open("1.jpg") torch.set_default_device("cuda"...

Chromium 中chrome.fontSettings扩展接口定义c++
一、chrome.fontSettings 使用 chrome.fontSettings API 管理 Chrome 的字体设置。 权限 fontSettings 要使用 Font Settings API,您必须在扩展程序中声明 "fontSettings" 权限 清单。例如: {"name": "My Font Settings E…...

在Unity游戏开发在面试时会面试哪些内容?
1、请描述游戏动画有几种,以及其原理。 关键帧动画:每一帧动画序列当中包含了顶点的空间位置信息以及改变量,然后通过插值运算,得出动画效果。选中某一游戏对象,创建animation,添加属性Transform࿰…...

AI大模型大数据隐私安全解决方案
随着人工智能技术飞速迭代,大模型训练、精调与推理愈发依赖海量数据,云上环境的便捷性也让数据隐私保护面临严峻挑战。AI大模型数据处理全流程包含大量敏感信息,一旦泄露、篡改或滥用,将损害用户权益、引发合规风险与信任危机。因…...

光模块PCB设计学习记录01
/*光模块布局,有错误可以指出,有不足可以补充*/ 光模块PCB布局规划 01导入板框与结构约束导入 这里的outline板框一般由机械提供.dxf文件,板框决定PCB尺寸、器件可用区域和接口位置;成功导入dxf文件后,打开Board Geo…...

VASP和QE能带图画不好?可能是你的Python数据处理踩了这些坑
VASP和QE能带图绘制中的Python数据处理陷阱与解决方案 在材料计算领域,能带结构图是理解电子性质的关键可视化工具。许多研究人员在使用VASP或Quantum ESPRESSO(QE)完成第一性原理计算后,往往会选择Python进行数据处理和绘图。然而,这个看似标…...

企业级应用如何通过Taotoken实现API调用的审计与安全管控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken实现API调用的审计与安全管控 将大模型能力集成到企业内部系统,为业务流程带来智能化的同时…...

Manus Open Claw开源技能库:构建可共享的机器人抓取解决方案
1. 项目概述:一个面向机器人抓取的开源技能库最近在机器人抓取领域,一个名为simpliolabs/manus-open-claw-skill-hunter-and-developer的项目引起了我的注意。乍一看这个标题,信息量不小,它融合了“开放爪具”、“技能猎人”和“开…...

Harnessclaw:轻量级自动化工作流编排工具,告别脚本泥潭
1. 项目概述:一个被低估的自动化利器如果你经常在GitHub上寻找一些能解决实际问题的工具,可能会发现一个现象:很多名字看起来平平无奇、甚至有点“怪”的项目,往往藏着巨大的潜力。harnessclaw/harnessclaw就是这样一个典型的例子…...

构建部署标准化:Code-Agnostic理念在混合技术栈下的实践
1. 项目概述:一个“代码无关”的构建与部署新思路最近在折腾一个老项目的现代化改造,遇到了一个经典难题:项目里混杂着Python、Java、Node.js,甚至还有几段古老的Perl脚本。每次构建部署,都得为每种语言准备一套环境、…...

为ClaudeCode配置Taotoken作为稳定可靠的API供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为ClaudeCode配置Taotoken作为稳定可靠的API供应商 Claude Code 是一款广受开发者欢迎的编程助手工具,它依赖于后端的大…...

面试题详解:GraphRAG 全面解析——知识图谱增强 RAG、Local Search、Global Search、社区摘要、工程落地与评估指标一次讲透
一、什么是 GraphRAG?1.1 先用一句话讲清楚GraphRAG 可以理解为:在传统 RAG 的基础上,把文档里的实体、关系、事件和主题组织成一张图,再利用这张图来增强检索和生成。普通 RAG 更像“在文档块里找相似内容”,GraphRAG…...

BilibiliDown:如何轻松实现B站视频批量下载与音频提取的终极指南
BilibiliDown:如何轻松实现B站视频批量下载与音频提取的终极指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh…...