论文翻译:ICLR 2024.DETECTING PRETRAINING DATA FROM LARGE LANGUAGE MODELS
文章目录
- 检测大型语言模型的预训练数据
- 摘要
- 1 引言
- 2 预训练数据检测问题
- 2.1 问题定义和挑战
- 2.2 WIKIMIA:动态评估基准
- 3 MIN-K% PROB:简单的无参考预训练数据检测方法
- 4 实验
- 4.1 数据集和指标
- 4.2 基线检测方法
- 4.3 实现和结果
- 4.4 分析
- 5 案例研究:检测预训练数据中的版权书籍
- 5.1 实验设置
- 5.2 结果
- 6 案例研究:检测下游数据集污染
- 6.1 实验
- 6.2 结果与分析
- 7 相关工作
- 8 结论
- 7 相关工作
- 8 结论
ICLR 2024 DETECTING PRETRAINING DATA FROM LARGE LANGUAGE MODELS
检测大型语言模型的预训练数据
翻译来源:https://kimi.moonshot.cn/chat/csh0tvhhmfr80ap97bdg
摘要
尽管大型语言模型(LLMs)被广泛部署,用于训练它们的数据很少被公开。考虑到这些数据的惊人规模,高达数万亿个标记,几乎可以肯定它包含了潜在问题文本,如版权材料、个人身份信息以及广泛报道的参考基准的测试数据。然而,我们目前没有办法知道哪些这类数据被包含在内,或者它们的比例是多少。在本文中,我们研究了预训练数据检测问题:给定一段文本和对一个LLM的黑盒访问,而不知道预训练数据,我们能否确定模型是否在提供的文本上进行了训练?为了促进这项研究,我们引入了一个动态基准WIKIMIA,它使用模型训练前后创建的数据来支持真实性检测。我们还引入了一种新的检测方法MIN-K% PROB,基于一个简单的假设:未见过的样本可能包含一些在LLM下概率很低的异常词,而见过的样本不太可能有这样的低概率词。MIN-K% PROB可以在没有任何关于预训练语料库的知识或任何额外训练的情况下应用,这与之前需要在与预训练数据相似的数据上训练参考模型的检测方法不同。此外,我们的实验表明,MIN-K% PROB在WIKIMIA上比这些先前的方法提高了7.4%。我们将MIN-K% PROB应用于三个现实世界场景,版权书籍检测、污染的下游示例检测和机器学习的隐私审计,发现它是一个始终有效的解决方案。
1 引言
随着语言模型(LM)训练语料库规模的增长,模型开发者(例如GPT4(Brown等人,2020年)和LLaMA 2(Touvron等人,2023b))变得不愿意公开他们的数据的全部组成或来源。这种缺乏透明度对科学模型评估和道德部署提出了关键挑战。在预训练期间可能会暴露关键的私人信息;先前的研究表明,LLMs生成了版权书籍(Chang等人,2023年)和个人电子邮件(Mozes等人,2023年)的摘录,可能侵犯了原始内容创作者的法律权利并侵犯了他们的隐私。此外,Sainz等人(2023年);Magar & Schwartz(2022年);Narayanan(2023年)表明,预训练语料库可能无意中包含了基准评估数据,这使得评估这些模型的有效性变得困难。
在本文中,我们研究了预训练数据检测问题:给定一段文本和对一个LLM的黑盒访问,而不知道其预训练数据,我们能否确定模型是否在文本上进行了预训练?我们提出了一个基准WIKIMIA和一个方法MIN-K% PROB,用于预训练数据检测。这个问题是成员推断攻击(MIAs)的一个实例,最初由Shokri等人(2016年)提出。最近的研究已经将微调数据检测(Song & Shmatikov,2019年;Shejwalkar等人,2021年;Mahloujifar等人,2021年)作为MIAs问题进行了研究。然而,将这些方法应用于检测当代大型LLMs的相关数据,面临着两个独特的技术挑战:首先,与通常运行多个周期的微调不同,预训练使用了一个更大的数据集,但只暴露每个实例一次,显著降低了成功MIAs所需的潜在记忆(Leino & Fredrikson,2020年;Kandpal等人,2022年)。此外,先前的方法通常依赖于一个或多个参考模型(Carlini等人,2022年;Watson等人,2022年),这些模型以与目标模型相同的方式进行训练(例如,在从相同的底层预训练数据分布中采样的影子数据上),以实现精确检测。这对于大型语言模型来说是不可能的,因为训练分布通常不可用,而且训练成本过高。

图1:MIN-K% PROB概述。为了确定文本X是否在LLM(如GPT)的预训练数据中,MIN-K% PROB首先获取X中每个标记的概率,选择k%概率最小的标记,并计算它们的平均对数似然。如果平均对数似然高,文本很可能在预训练数据中。
我们解决这些挑战的第一步是建立一个可靠的基准。我们引入了WIKIMIA,这是一个动态基准,旨在定期且自动地评估任何新发布的预训练LLMs上的检测方法。通过利用维基百科数据的时间戳和模型发布日期,我们选择旧的维基百科事件数据作为我们的成员数据(即,在预训练期间看到的数据)和近期的维基百科事件数据(例如,2023年之后的)作为我们的非成员数据(未看到)。我们的数据集因此展现出三个理想的属性:(1)准确:在LLM预训练后发生的事件保证不会出现在预训练数据中。事件的时间性质确保非成员数据确实是未看到的,并且在预训练数据中没有提及。(2)通用:我们的基准不局限于任何特定模型,可以应用于使用维基百科预训练的各种模型(例如,OPT、LLaMA、GPT-Neo),因为维基百科是常用的预训练数据来源。(3)动态:我们将通过从维基百科收集更新的非成员数据(即,更近期的事件)不断更新我们的基准,因为我们的数据构建流程是完全自动化的。
微调的MIA方法(Carlini等人,2022年;Watson等人,2022年)通常使用在类似数据分布上训练的影子参考模型来校准目标模型的概率。然而,这些方法由于预训练数据的黑盒特性和高计算成本,对于预训练数据检测是不切实际的。因此,我们提出了一种无需参考的MIA方法MIN-K% PROB。我们的方法基于一个简单的假设:未见过的示例倾向于包含一些概率低的异常词,而见过的示例不太可能包含这样低概率的词。MIN-K% PROB计算异常标记的平均概率。MIN-K% PROB可以在没有任何关于预训练语料库的知识或任何额外训练的情况下应用,这与依赖影子参考模型的现有MIA方法不同(Mattern等人,2023年;Carlini等人,2021年)。我们的实验表明,MIN-K% PROB在WIKIMIA上的AUC得分比现有最强基线提高了7.4%。进一步分析表明,检测性能与模型大小和检测文本长度呈正相关。
为了验证我们提出的方法在现实世界设置中的适用性,我们进行了三个案例研究:版权书籍检测(§5)、LLMs的隐私审计(§??)和数据集污染检测(§6)。我们发现MIN-K% PROB在两种场景中都显著优于基线方法。从我们对版权书籍检测的实验中,我们看到了强有力的证据表明GPT-3 1是在Books3数据集(Gao等人,2020年;Min等人,2023年)中的版权书籍上预训练的。从我们对机器学习的隐私审计实验中,我们使用MIN-K% PROB审计一个被训练忘记版权书籍的未学习LLM,使用机器学习方法(Eldan & Russinovich,2023年),并发现这样的模型仍然可以输出相关的版权内容。此外,我们对数据集污染检测的对照研究揭示了预训练设计选择对检测难度的影响;我们发现当训练数据大小增加,检测示例的出现频率和学习率降低时,检测变得更加困难。
2 预训练数据检测问题
我们研究预训练数据检测问题,即检测一段文本是否是训练数据的一部分。首先,我们正式定义了这个问题,并描述了它在先前的微调数据检测研究中不存在的独特挑战(§2.1)。然后,我们策划了WIKIMIA,这是第一个评估预训练数据检测方法的基准(§2.2)。
2.1 问题定义和挑战
我们遵循Shokri等人(2016年)和Mattern等人(2023年)对成员推断攻击(MIA)的标准定义。给定一个语言模型( f_{\theta} )及其相关的预训练数据( D = {z_i}{i \in [n]} ),这些数据是从底层分布( D )中采样的,任务目标是学习一个检测器( h ),它可以推断任意数据点( x )的成员资格:( h(x, f{\theta}) \rightarrow {0, 1} )。我们遵循MIA的标准设置,假设检测器只能将LM作为黑盒访问,并且可以为任何数据点( x )计算标记概率。
挑战1:预训练数据分布的不可用性。现有的微调数据检测的最先进的MIA方法(Long等人,2018年;Watson等人,2022年;Miresghallah等人,2022年)通常使用参考模型( g_{\gamma} )来计算数据点的背景难度,并校准目标语言模型的输出概率:( h(x, f_{\theta}, g_{\gamma}) \rightarrow {0, 1} )。这些参考模型通常与( f_{\theta} )共享相同的模型架构,并在影子数据( D_{\text{shadow}} \subset D )上训练(Carlini等人,2022年;Watson等人,2022年),这些数据是从相同的底层分布( D )中采样的。这些方法假设检测器可以访问(1)目标模型的训练数据分布,以及(2)足够数量的来自( D )的样本来训练校准模型。然而,这种访问预训练训练数据分布的假设是不现实的,因为这些信息并不总是可用的(例如,模型开发者没有发布(Touvron等人,2023b;OpenAI,2023年))。即使可以访问,鉴于预训练数据的惊人规模,在其上预训练一个参考模型的计算成本将极其昂贵。总之,预训练数据检测问题符合MIA定义,但包括一个假设,即检测器无法访问预训练数据分布( D )。
挑战2:检测难度。预训练和微调在数据和计算使用量以及优化设置(如训练周期和学习率计划)上有很大差异。这些因素显著影响检测难度。人们可能会直观地推断,当数据集大小增加,训练周期和学习率降低时,检测变得更加困难。我们在下面简要描述了一些理论证据,这些证据支持这些直觉,并在§6中展示了支持这些假设的经验结果。
例如,给定一个来自( D )的示例( z ),我们表示模型输出为( f_{\theta}(z) )。现在,再取另一个从( D \setminus D )中采样的示例( y )(不是预训练数据的一部分)。如果输出( f_{\theta}(z) )和( f_{\theta}(y) )相似,确定一个示例( x )是否是训练集的一部分就变得具有挑战性。可以使用总变异距离来量化( f_{\theta}(z) )和( f_{\theta}(y) )之间的相似度。根据先前的研究(Hardt等人,2016年;Bassily等人,2020年),( f_{\theta}(z) )和( f_{\theta}(y) )之间的总变异距离的界限与示例( x )的出现频率、学习率和数据集大小的倒数成正比,这意味着检测难度也与这些因素相关。
2.2 WIKIMIA:动态评估基准
我们通过使用在特定日期后添加到维基百科的事件来构建我们的基准,将它们视为非成员数据,因为它们保证不会出现在预训练数据中,这是我们基准的核心思想。
数据构建。我们从维基百科收集近期事件页面。步骤1:我们将2023年1月1日设为截止日期,将2023年后发生的事件视为近期事件(非成员数据)。我们使用维基百科API自动检索文章,并应用两个过滤标准:(1)文章必须属于事件类别,以及(2)页面必须在2023年后创建。步骤2:对于成员数据,我们收集了2017年之前创建的文章,因为许多预训练模型,例如LLaMA、GPT-NeoX和OPT,都是在2017年后发布的,并且将维基百科转储纳入它们的预训练数据中。步骤3:此外,我们过滤掉了缺乏有意义文本的维基百科页面,例如标题为“…的时间线”或“…的列表”的页面。鉴于2023年后的事件数量有限,我们最终收集了394个近期事件作为我们的非成员数据,并从2016年前的维基百科页面中随机选取了394个事件作为我们的成员数据。数据构建流程是自动化的,允许为未来的截止日期策划新的非成员数据。
基准设置。在实践中,LM用户可能还需要检测被改写和编辑的文本。先前使用MIA的研究专门关注检测在预训练期间使用的确切匹配数据的示例。MIA方法是否可以用来识别传达与原始示例相同含义的改写示例,这仍然是一个未解决的问题。除了逐字设置(原始)之外,我们因此引入了一个改写设置,我们利用ChatGPT2来改写示例,然后评估MIA指标是否能够有效识别语义等价的示例。
此外,先前的MIA评估通常在评估中混合不同长度的数据,并报告单一的性能指标。然而,我们的结果揭示了数据长度显著影响检测难度。直观地说,较短的句子更难检测。因此,不同的数据长度桶可能会导致MIA方法的不同排名。为了进一步调查这一点,我们提出了一个不同长度的设置:我们将维基百科事件数据截断为不同的长度—32、64、128、256—并分别为每个长度段报告MIA方法的性能。我们在附录B中描述了理想的属性。
3 MIN-K% PROB:简单的无参考预训练数据检测方法
我们介绍了一种预训练数据检测方法MIN-K% PROB,它利用文本的最小标记概率进行检测。MIN-K% PROB基于这样的假设:非成员示例更有可能包含一些具有高负对数似然(或低概率)的异常词,而成员示例不太可能包含具有高负对数似然的词。考虑一个句子中的标记序列,表示为( x = x_1, x_2, …, x_N ),给定其前面的标记,标记( x_i )的对数似然计算为( \log p(x_i | x_1, …, x_{i-1}) )。然后我们选择( x )中k%的标记,形成具有最小标记概率的集合Min-K%(x),并计算这个集合中标记的平均对数似然:

其中E是Min-K%(x)集合的大小。我们可以通过对这个MIN-K% PROB结果进行阈值处理来检测一段文本是否包含在预训练数据中。我们在附录B的算法1中总结了我们的方法。
4 实验
我们在WIKIMIA上评估了MIN-K% PROB和基线检测方法对LLaMA(Touvron等人,2023a)、GPT-Neo(Black等人,2022)和Pythia(Biderman等人,2023)等语言模型的性能。
4.1 数据集和指标
我们的实验使用了不同长度(32、64、128、256)的WIKIMIA,以及原始和改写设置。遵循(Carlini等人,2022;Miresghallah等人,2022a),我们使用真正例率(TPR)及其假正例率(FPR)来评估检测方法的有效性。我们绘制ROC曲线来衡量TPR和FPR之间的权衡,并报告AUC得分(ROC曲线下的面积)和低FPR下的TPR(TPR@5%FPR)作为我们的指标。
4.2 基线检测方法
我们采用现有的基于参考和无参考的MIA方法作为我们的基线方法,并在WIKIMIA上评估它们的性能。这些方法只考虑句子级概率。具体来说,我们使用了LOSS攻击方法(Yeom等人,2018a),该方法基于目标模型在输入示例时的损失来预测示例的成员资格。在LMs的背景下,这个损失对应于示例的困惑度(PPL)。我们还考虑了利用概率曲率来检测成员资格的邻域攻击(Mattern等人,2023),这种方法与最近提出的用于分类机器生成与人类编写文本的DetectGPT(Mitchell等人,2023)方法相同。最后,我们比较了(Carlini等人,2021)中提出的成员推断方法,包括将示例困惑度与zlib压缩熵(Zlib)进行比较,与小写示例困惑度(Lowercase)进行比较,以及与在同一数据上预训练的较小模型的示例困惑度(Smaller Ref)进行比较。对于较小的参考模型设置,我们使用LLaMA-7B作为LLaMA-65B和LLaMA-30B的较小模型,GPT-Neo-125M作为GPT-NeoX-20B的较小模型,OPT-350M作为OPT-66B的较小模型,Pythia-70M作为Pythia-2.8B的较小模型。
4.3 实现和结果
实现细节。MIN-K% PROB的关键超参数是我们选择形成top-k%集合的最高负对数似然的标记百分比。我们在LLAMA-60B模型上使用留出的验证集对10、20、30、40、50进行了小范围的扫描,发现k=20效果最好。我们在所有实验中使用这个值,无需进一步调整。由于我们报告AUC得分作为我们的指标,我们不需要确定阈值ϵ。
主要结果。我们在表1中比较了MIN-K% PROB和基线方法。我们的实验表明,MIN-K% PROB在原始和改写设置中一致地优于所有基线方法,无论是针对不同的目标语言模型。MIN-K% PROB平均实现了0.72的AUC得分,比最佳基线方法(即,PPL)提高了7.4%。在基线中,简单的LOSS攻击(PPL)表现优于其他方法。这证明了MIN-K% PROB在检测各种LMs的预训练数据方面的有效性和通用性。附录A中的进一步结果,如TPR@5%FPR,显示了与表5类似的趋势。
4.4 分析
我们进一步深入研究影响检测难度的因素,重点关注两个方面:(1)目标模型的大小,以及(2)文本的长度。
模型大小。我们在不同大小的LLaMA模型(7、13、30、65B)上评估无参考方法检测预训练128长度文本的性能。图2a展示了一个明显的趋势:随着模型大小的增加,方法的AUC得分上升。这可能是因为更大的模型有更多的参数,因此更有可能记住预训练数据。

(a) AUC得分与模型大小的关系 (b) AUC得分与文本长度的关系
图2:随着模型大小或文本长度的增加,检测变得更容易。
文本长度。在另一个实验中,我们在原始设置中评估了不同长度示例的检测方法性能。如图2b所示,不同方法的AUC得分随着文本长度的增加而增加,这可能是因为更长的文本包含更多被目标模型记住的信息,使它们更容易与未见文本区分开来。
表1:在WIKIMIA上检测给定模型的预训练示例的AUC得分,MIN-K% PROB和基线比较。Ori.和Para.分别表示原始和改写设置。粗体显示了每列中最好的AUC。

在接下来的两个部分中,我们将MIN-K% PROB应用于现实世界场景,以检测LLMs中的版权书籍和污染的下游任务。
5 案例研究:检测预训练数据中的版权书籍
MIN-K% PROB还可以检测训练数据中潜在的版权侵犯,我们在本节中展示这一点。具体来说,我们使用MIN-K% PROB来检测Pile数据集的Books3子集中可能包含在GPT-3训练数据中的版权书籍摘录(Gao等人,2020)。
5.1 实验设置
验证数据以确定检测阈值。我们使用已知被ChatGPT记忆的50本书构建验证集,这可能表明它们存在于其训练数据中(Chang等人,2023),作为正例。对于负例,我们收集了50本2023年首次出版的新书,这些书不可能在训练数据中。从每本书中,我们随机提取100个512字的片段,创建了一个平衡的验证集,包含10,000个示例。我们通过在这个集合上最大化检测精度来确定MIN-K% PROB的最佳分类阈值。
测试数据和指标。我们从已知包含版权内容的Books3语料库中随机选取100本书(Min等人,2023)。从每本书中,我们提取100个随机的512字片段,创建了一个包含10,000个摘录的测试集。我们应用阈值来决定这些书籍摘录是否与GPT-3一起训练。然后我们报告这些摘录中有多少百分比(即,污染率)被识别为预训练数据的一部分。
5.2 结果
图3显示MIN-K% PROB在检测版权书籍方面达到了0.88的AUC,超过了基线。我们将MIN-K% PROB的最佳阈值应用于来自Books3的100本书的10,000个摘录的测试集。表2代表了预测污染率最高的前20本书。图4揭示了近90%的书籍的污染率超过50%,这是一个令人担忧的数字。

图3:在GPT-3上检测版权书籍验证集的AUC得分。

图4:100本版权书籍检测到的污染率分布。
表2:GPT-3预训练数据中前20本版权书籍。列出的污染率代表从每本书中识别出的文本摘录在预训练数据中的百分比。

6 案例研究:检测下游数据集污染
评估下游任务数据泄露到预训练语料库是一个重要问题,但由于缺乏对预训练数据集的访问,这个问题难以解决。在本节中,我们探讨使用MIN-K% PROB来检测信息泄露的可能性,并进行消融研究以了解各种训练因素如何影响检测难度。具体来说,我们持续预训练7B参数的LLaMA模型(Touvron等人,2023a),在故意被下游任务示例污染的预训练数据上进行训练。
6.1 实验
实验设置。为了模拟现实世界设置中可能发生的下游任务污染,我们通过将下游任务的示例插入到预训练语料库中来创建污染的预训练数据。具体来说,我们从RedPajama语料库(TogetherCompute,2023)中采样文本,并将下游数据集BoolQ(Clark等人,2019)、IMDB(Maas等人,2011)、Truthful QA(Lin等人,2021)和Commonsense QA(Talmor等人,2019)的格式化示例以连续段落的形式随机插入到未污染的文本中。我们在预训练数据中从这些数据集中各插入200个(正面)示例,同时从每个数据集中分离出200个(负面)示例,这些示例已知不在污染语料库中。这创建了一个包含2700万个标记的污染预训练数据集,其中0.1%来自下游数据集。
我们通过在污染的预训练数据上微调一个周期的LLaMA 7B模型,以恒定的学习率1e-4来评估MIN-K% PROB检测泄露基准示例的有效性,通过计算这400个示例上的AUC得分。
主要结果。我们在表3中展示了主要的攻击结果。我们发现MIN-K% PROB优于所有基线。我们在附录A的表6中报告TPR@5%FPR,其中MIN-K% PROB比最佳基线提高了12.2%。
表3:检测污染下游示例的AUC得分。粗体显示了每列中最好的AUC得分。

6.2 结果与分析
使用污染数据集的模拟使我们能够进行消融研究,以实证分析数据集大小、数据出现频率和学习率对检测难度的影响,如第2.1节中的理论分析。实证结果大体上与理论框架一致并验证了该框架。总之,我们发现随着数据出现频率和学习率的降低,检测变得更加困难,数据集大小对检测难度的影响取决于污染物是否相对于预训练数据的分布是异常值。
预训练数据集大小。我们通过将固定的下游示例(每个下游任务200个示例)与不同量的RedPajama数据混合,构建了包含0.17M、0.27M、2.6M和26M个标记的污染数据集,模拟现实世界的预训练。尽管理论表明更多的预训练数据会带来更大的难度,但图5a显示AUC得分与直觉相反地随着预训练数据集大小的增加而增加。这与发现LMs更好地记忆尾部异常值(Feldman,2020;Zhang等人,2021)一致。在构建的数据集中,有更多的RedPajama标记,下游示例变得更加显著的异常值。我们假设它们增强的记忆可能使得基于困惑度的度量更容易检测。
为了验证我们的假设,我们构建了控制数据,其中污染物不是异常值。我们采样了2023年8月实时数据新闻4,包含不在LLaMA预训练中的2023年后的新闻。我们通过连接这个语料库中的1000、5000和10000个示例,创建了三个合成语料库,分别创建了大小为0.77M、3.9M和7.6M标记的语料库。在每种设置中,我们认为这100个示例是污染(正面)示例,并从2023年8月新闻中留出另一组100个示例(负面)。图5b显示,随着数据集大小的增加,AUC得分降低。
检测像下游示例这样的异常污染物随着数据大小的增加变得更容易,因为模型有效地记忆长尾样本。然而,从预训练数据分布中检测一般的分布样本随着数据量的增加变得更加困难,符合理论预期。
数据出现频率。为了研究检测难度与数据出现频率之间的关系,我们通过将每个下游数据点的多个副本插入预训练语料库,构建了一个污染的预训练语料库,其中每个示例的出现频率遵循泊松分布。我们测量预训练语料库中示例的频率与其AUC得分之间的关系。图5c显示AUC得分与示例的出现频率呈正相关。

(a) 异常污染物,例如下游示例,随着数据集大小的增加变得更容易检测。
(b) 分布内的污染物,例如新闻文章,随着数据集大小的增加变得更难以检测。
© 在数据集中出现频率更高的污染物更容易被检测到。
图5:我们展示了污染率(以预训练标记总数的百分比表示)和出现频率对使用MIN-K% PROB检测数据污染物的难易程度的影响。
表4:使用两种不同的学习率检测下游污染示例的AUC得分。在训练期间使用更高的学习率会使检测变得更容易。粗体显示了每列中最好的AUC得分。

7 相关工作
自然语言处理中的成员推断攻击。成员推断攻击(MIAs)旨在确定任意样本是否是给定模型训练数据的一部分(Shokri等人,2017;Yeom等人,2018b)。这些攻击对个人隐私构成重大风险,通常作为更严重攻击(如数据重建(Carlini等人,2021;Gupta等人,2022;Cummings等人,2023))的基础。由于其与隐私风险的基本关联,MIA最近在量化机器学习模型中的隐私漏洞和验证隐私保护机制的准确实施方面找到了应用(Jayaraman & Evans,2019;Jagielski等人,2020;Zanella-Béguelin等人,2020;Nasr等人,2021;Huang等人,2022;Nasr等人,2023;Steinke等人,2023)。最初应用于表格和计算机视觉数据,MIA的概念最近扩展到了语言任务领域。然而,这种扩展主要围绕微调数据检测(Song & Shmatikov,2019;Shejwalkar等人,2021;Mahloujifar等人,2021;Jagannatha等人,2021;Miresghallah等人,2022b)。我们的工作集中在将MIA应用于预训练数据检测,这是以前研究工作中受到有限关注的一个领域。
8 结论
我们提出了一个预训练数据检测数据集WIKIMIA和一种新方法MIN-K% PROB。我们的方法利用了训练数据相对于其他基线而言,往往包含较少具有非常低概率的异常标记的直觉。此外,我们在现实世界环境中验证了我们方法的有效性,进行了两个案例研究:检测数据集污染和已发布书籍检测。对于数据集污染,我们观察到的经验结果与理论预测一致,即检测难度如何随着数据集大小、示例频率和学习率的变化而变化。最引人注目的是,我们的书籍检测实验为GPT-3模型可能在版权书籍上进行训练提供了强有力的证据。
**学习率。**我们还研究了在预训练期间使用不同学习率对污染物统计的影响(见表4)。我们发现将学习率从(10{-5})提高到(10{-4})在所有下游任务中显著提高了AUC得分,这意味着更高的学习率导致模型更强烈地记忆它们的预训练数据。附录A中的表7的更深入分析表明,更高的学习率导致对这些下游任务的记忆而不是泛化。
7 相关工作
自然语言处理中的成员推断攻击。成员推断攻击(MIAs)旨在确定任意样本是否是给定模型训练数据的一部分(Shokri等人,2017;Yeom等人,2018b)。这些攻击对个人隐私构成重大风险,通常作为更严重攻击(如数据重建(Carlini等人,2021;Gupta等人,2022;Cummings等人,2023))的基础。由于其与隐私风险的基本关联,MIA最近在量化机器学习模型中的隐私漏洞和验证隐私保护机制的准确实施方面找到了应用(Jayaraman & Evans,2019;Jagielski等人,2020;Zanella-Béguelin等人,2020;Nasr等人,2021;Huang等人,2022;Nasr等人,2023;Steinke等人,2023)。最初应用于表格和计算机视觉数据,MIA的概念最近扩展到了语言任务领域。然而,这种扩展主要围绕微调数据检测(Song & Shmatikov,2019;Shejwalkar等人,2021;Mahloujifar等人,2021;Jagannatha等人,2021;Miresghallah等人,2022b)。我们的工作集中在将MIA应用于预训练数据检测,这是以前研究工作中受到有限关注的一个领域。
8 结论
我们提出了一个预训练数据检测数据集WIKIMIA和一种新方法MIN-K% PROB。我们的方法利用了训练数据相对于其他基线而言,往往包含较少具有非常低概率的异常标记的直觉。此外,我们在现实世界环境中验证了我们方法的有效性,进行了两个案例研究:检测数据集污染和已发布书籍检测。对于数据集污染,我们观察到的经验结果与理论预测一致,即检测难度如何随着数据集大小、示例频率和学习率的变化而变化。最引人注目的是,我们的书籍检测实验为GPT-3模型可能在版权书籍上进行训练提供了强有力的证据。学习率。我们还研究了在预训练期间使用不同学习率对污染物统计的影响(见表4)。我们发现将学习率从(10{-5})提高到(10{-4})在所有下游任务中显著提高了AUC得分,这意味着更高的学习率导致模型更强烈地记忆它们的预训练数据。附录A中的表7的更深入分析表明,更高的学习率导致对这些下游任务的记忆而不是泛化。
相关文章:
论文翻译:ICLR 2024.DETECTING PRETRAINING DATA FROM LARGE LANGUAGE MODELS
文章目录 检测大型语言模型的预训练数据摘要1 引言2 预训练数据检测问题2.1 问题定义和挑战2.2 WIKIMIA:动态评估基准 3 MIN-K% PROB:简单的无参考预训练数据检测方法4 实验4.1 数据集和指标4.2 基线检测方法4.3 实现和结果4.4 分析 5 案例研究ÿ…...

Spring 框架精髓:从基础到分布式架构的进阶之路
一、概述 (一)Spring框架概念 1.概念: Spring框架是一个用于简化Java企业级应用开发的开源应用程序框架。 2.Spring框架的核心与提供的技术支持: 核心: IoC控制反转|反转控制:利用框架创建类的对象的…...

深入理解C++ Lambda表达式:语法、用法与原理及其包装器的使用
深入理解C Lambda表达式:语法、用法与原理及其包装器的使用 lambda表达式C98中的一个例子lambda表达式语法lambda表达式各部分说明捕获列表说明 函数对象与lambda表达式 包装器function包装器 bind 🌏个人博客主页: 个人主页 本文深入介绍了…...

C# 编程语言:跨时代的革命
C# 是一种由微软开发的现代、类型安全、面向对象的编程语言,自2000年推出以来,它已经成为.NET平台的核心组成部分。在本文中,我们将探讨C#语言的特点、优势以及它在软件开发领域中的应用。 C# 语言特点 类型安全和自动垃圾回收 C# 是一种类…...

恋爱脑学Rust之Box与RC的对比
在遥远的某个小镇,住着一对年轻的恋人:阿丽和小明。他们的爱情故事就像 Rust 中的 Rc 和 Box 智能指针那样,有着各自不同的「所有权」和「共享」的理解。 故事背景 阿丽和小明准备共同养一株非常珍贵的花(我们称之为“心之花”&…...

Rust 力扣 - 1423. 可获得的最大点数
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 题目所求结果存在下述等式 可获得的最大点数 所有卡牌的点数之和 - 长度为(卡牌数量 - k)的窗口的点数之和的最小值 我们遍历长度为(卡牌数量 - k)的窗口&#…...

Android15音频进阶之Cuttlefish搭建音频开发环境(九十二)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【原创干货持续更新中……】🚀 优质视频课程:AAOS车载系统+…...

发现不为人知的AI宝藏:发现AI新天地! —— 《第八期》
在人工智能(AI)领域,尽管ChatGPT、Midjourney等知名产品广为人知,但还有许多小众而有趣的AI工具等待你的探索。本文将推荐五款实用的AI工具,它们不仅功能强大,而且使用简单,帮助你在各种场景中提…...
基于物联网设计的地下煤矿安全监测与预警
文章目录 一、前言1.1 项目介绍【1】项目开发背景【2】设计实现的功能【3】项目硬件模块组成 1.2 设计思路1.3 系统功能总结1.4 开发工具的选择【1】设备端开发【2】上位机开发 1.5 模块的技术详情介绍【1】NBIOT-BC26模块【2】MQ5传感器【4】DHT11传感器【5】红外热释电人体检…...

Java 23 的12 个新特性!!
Java 23 来啦!和 Java 22 一样,这也是一个非 LTS(长期支持)版本,Oracle 仅提供六个月的支持。下一个长期支持版是 Java 25,预计明年 9 月份发布。 Java 23 一共有 12 个新特性! 有同学表示&…...

.NET 8 中 Entity Framework Core 的使用
本文代码:https://download.csdn.net/download/hefeng_aspnet/89935738 概述 Entity Framework Core (EF Core) 已成为 .NET 开发中数据访问的基石工具,为开发人员提供了强大而多功能的解决方案。随着 .NET 8 和 C# 10 中引入的改进,开发人…...

ai数字人分身123口播克隆数字人小程序源码_博纳软云
功能配置 一、用户 用户管理小黑屋用户反馈登录设置短信参数 二、作品 视频作品背景音乐库背景音乐分类 三、形象分身 上传记录视频要求参数配置 四、声音克隆 克隆记录参数配置声音要求文案示例 五、AI文案 生成记录创作模型模型分类Al配置 六、充值 充值订单积分套…...

从0开始学PHP面向对象内容之(类,对象,构造/析构函数)
上期我们讲了面向对象的一些基本信息,这期让我们详细的了解一下 一、面向对象—类 1、PHP类的定义语法: <?php class className {var $var1;var $var2 "constant string";function classfunc ($arg1, $arg2) {[..]}[..] } ?>2、解…...

openGauss数据库-头歌实验1-5 修改数据库
一、查看表结构与修改表名 (一)任务描述 本关任务:修改表名,并能顺利查询到修改后表的结构。 (二)相关知识 为了完成本关任务,你需要掌握: 1.如何查看表的结构; 2.如…...

《JVM第3课》运行时数据区
无痛快速学习入门JVM,欢迎订阅本免费专栏 运行时数据区结构图如下: 可分为 5 个区域,分别是方法区、堆区、虚拟机栈、本地方法栈、程序计数器。这里大概介绍一下各个模块的作用,会在后面的文章展开讲。 类加载子系统会把类信息…...

阅读笔记 Contemporary strategy analysis Chapter 14
来源:Robert M. Grant - Contemporary strategy analysis (2018) Chapter 14 External Growth Strategies: Mergers, Acquisitions, and Alliances 合并、收购和联盟 Ⅰ Introduction and Objectives 企业并购与联盟是公司实现快速扩张的重要战略工具。通过这些手段…...
2024网鼎杯青龙组wp:Crypto2
题目 附件内容如下 # coding: utf-8 #!/usr/bin/env python2import gmpy2 import random import binascii from hashlib import sha256 from sympy import nextprime from Crypto.Cipher import AES from Crypto.Util.Padding import pad from Crypto.Util.number import long…...

能通过Ping命令访问CentOS 9 Stream,但在使用Xshell连接
能通过Ping命令访问CentOS 9 Stream,但在使用Xshell进行SSH连接失败 1. **确认SSH服务状态**:2. **检查SSH配置**:要检查和设置PermitRootLogin选项,您需要编辑SSH配置文件/etc/ssh/sshd_config。以下是具体步骤:1. 打…...

Oracle 第19章:高级查询技术
在Oracle数据库中,高级查询技术是数据库管理员和开发人员必须掌握的重要技能。这些技术能够帮助优化查询性能,简化复杂的查询逻辑,并提高数据处理的效率。本章将重点讨论两个关键概念:子查询和连接与并集操作。 子查询 定义: 子…...
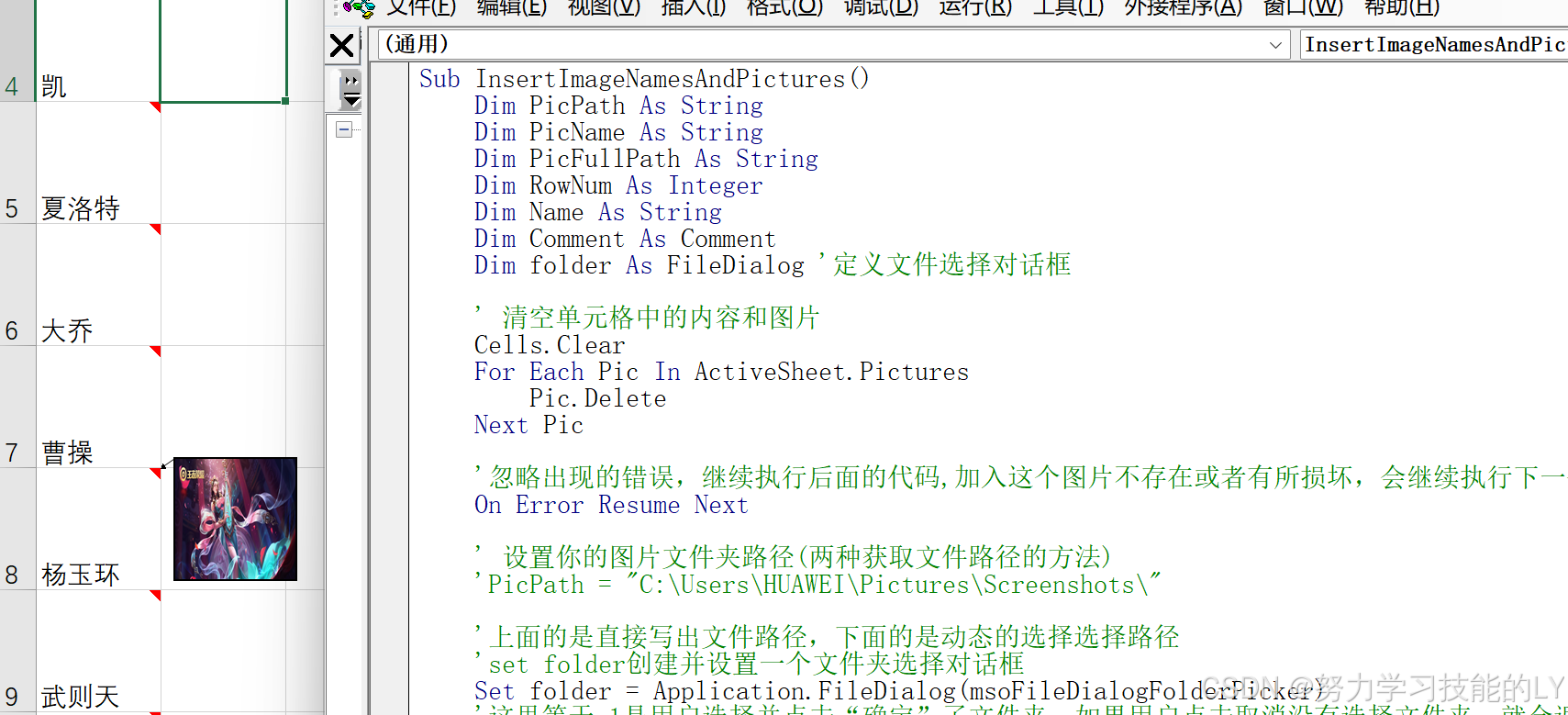
Excel:vba运行时错误“7“:内存溢出错误
我这里出现这个错误是在批注中插入图片时报错 原因:我插入的图片不都是jpg的类型的,但是其中的两张图片是webp类型的,但是我把文件后缀名修改成了jpg,以为变成了jpg类型的图片,但是图片在批注里面无法显示,所以运行到第…...

Unity游戏开发集成MCP协议:AI助手自动化操作指南
1. 项目概述:Unity游戏开发中的MCP革命如果你是一名Unity开发者,最近可能已经注意到一个名为“CoderGamester/mcp-unity”的项目在GitHub上悄然走红。这不仅仅是一个普通的插件或工具包,它代表了一种全新的工作流范式,旨在将大型语…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

开源技能安全仪表盘:从架构解析到CI/CD集成的DevSecOps实践
1. 项目概述:一个面向技能开发者的安全仪表盘最近在折腾一些智能设备上的技能开发,发现一个挺普遍但容易被忽视的问题:我们花大量时间在功能实现和用户体验上,但技能本身的安全性评估,往往只能等到上线后,通…...

从零打造专业GitHub个人资料页:Markdown与动态集成实战指南
1. 项目概述与核心价值 在技术圈子里混了十几年,我越来越觉得,一个开发者的“数字门面”和代码能力同等重要。这个门面,很多时候就是你的GitHub主页。早些年,大家的GitHub个人页面就是个简单的仓库列表,加上一些贡献图…...

CI/CD安全最佳实践:保护软件交付流程
CI/CD安全最佳实践:保护软件交付流程 一、CI/CD安全最佳实践概述 1.1 CI/CD安全最佳实践的定义 CI/CD安全最佳实践是指在持续集成和持续部署流程中实施的安全策略和措施。它涵盖代码提交、构建、测试、部署等各个阶段的安全防护。 1.2 CI/CD安全最佳实践的价值 安全…...

Linux压缩归档与备份文件管理
Linux压缩归档与备份文件管理在 Linux 运维工作中,压缩与归档几乎无处不在。日志备份、数据迁移、配置留档、故障现场保存,都会涉及文件打包和压缩。如果缺乏规范,备份文件很容易散落各处、命名混乱、占用失控,最终从保障手段变成…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...

基于WebSocket的机械爪远程控制桥接系统设计与实战
1. 项目概述:一个连接物理世界与数字世界的“机械爪”远程控制桥最近在捣鼓一个挺有意思的开源项目,叫lucas-jo/openclaw-bridge-remote。光看名字,你可能觉得这又是一个关于机器人或者机械臂的遥控项目,但实际深入进去࿰…...

GitHub自动化运维:构建模块化Operator集提升开发效率
1. 项目概述:一个为GitHub开发者量身定制的“操作集”如果你是一个重度GitHub用户,无论是维护个人项目、参与开源贡献,还是管理团队仓库,大概率都经历过这样的场景:每天要重复执行一堆琐碎但必要的操作。比如ÿ…...