Oracle 第19章:高级查询技术
在Oracle数据库中,高级查询技术是数据库管理员和开发人员必须掌握的重要技能。这些技术能够帮助优化查询性能,简化复杂的查询逻辑,并提高数据处理的效率。本章将重点讨论两个关键概念:子查询和连接与并集操作。
子查询
定义:
子查询(Subquery)是指嵌套在另一个SQL语句中的查询。子查询可以出现在SELECT、INSERT、UPDATE或DELETE语句中,也可以作为其他子查询的一部分。根据其返回的结果数量,子查询可以分为单行子查询和多行子查询。
单行子查询:
单行子查询只返回一行结果。它们通常用于比较操作,例如使用=, <>, >, <等比较运算符。
示例:
假设我们有一个员工表employees和一个部门表departments。我们要找出工资高于平均工资的所有员工的名字。
SELECT first_name, last_name
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
在这个例子中,(SELECT AVG(salary) FROM employees)是一个单行子查询,它计算所有员工的平均工资。
多行子查询:
多行子查询可以返回多行结果。它们经常与IN, ANY和ALL关键字一起使用。
示例:
如果我们想找到所有属于销售部门的员工,而销售部门的ID为100,我们可以这样做:
SELECT first_name, last_name
FROM employees
WHERE department_id IN (SELECT department_id FROM departments WHERE department_name = 'Sales');
这里,IN关键字用来检查employees表中的department_id是否存在于由子查询返回的列表中。
连接与并集操作
连接(Joins):
连接是用于从多个表中组合数据的一种方法。根据连接条件的不同,可以有多种类型的连接,包括内连接(INNER JOIN)、外连接(LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN)和自连接(Self Join)等。
内连接:
内连接返回两个表中满足连接条件的记录。
示例:
要获取每个员工的名字及其所在部门的名称,可以执行以下查询:
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id;
外连接:
外连接不仅返回满足连接条件的记录,还返回一个或两个表中不符合条件的记录。对于这些记录,结果集中来自不匹配表的列将包含NULL值。
左外连接:
左外连接返回左表中的所有记录,即使右表中没有匹配项。
示例:
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.department_id;
这将列出所有员工,即使有些员工不属于任何已知的部门。
并集操作(Unions):
并集操作用于合并两个或更多SELECT语句的结果集。UNION操作符会自动去除重复的行,而UNION ALL则保留所有行,包括重复的行。
示例:
如果想要查找所有在’IT’或’Sales’部门工作的员工,可以使用如下查询:
SELECT first_name, last_name
FROM employees
WHERE department_id IN (SELECT department_id FROM departments WHERE department_name = 'IT')
UNION
SELECT first_name, last_name
FROM employees
WHERE department_id IN (SELECT department_id FROM departments WHERE department_name = 'Sales');
子查询的其他用法
相关子查询(Correlated Subqueries)
相关子查询是指子查询依赖于外部查询中的某个值。这意味着子查询会针对外部查询的每一行执行一次。
示例:
假设我们有一个订单表orders和一个订单详情表order_details。我们想要找出每个订单的总金额。
SELECT o.order_id, (SELECT SUM(od.quantity * od.price)FROM order_details odWHERE od.order_id = o.order_id) AS total_amount
FROM orders o;
在这个例子中,子查询计算了每个订单的总金额,它依赖于外部查询中的o.order_id。
EXISTS 和 NOT EXISTS
EXISTS 和 NOT EXISTS 用于检测子查询是否返回任何行。如果子查询返回至少一行,则 EXISTS 返回 TRUE;否则返回 FALSE。NOT EXISTS 则相反。
示例:
假设我们有一个客户表customers和一个订单表orders。我们想要找出所有从未下过订单的客户。
SELECT c.customer_id, c.customer_name
FROM customers c
WHERE NOT EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id);
不同类型的连接
自连接(Self Join)
自连接是指在一个表上进行的连接操作,其中表自身被当作两个不同的表来处理。这种连接通常用于处理具有层次结构的数据。
示例:
假设我们有一个员工表employees,其中包含员工的直接上级信息。我们想要找出每个员工的上级姓名。
SELECT e1.first_name AS employee, e1.last_name, e2.first_name AS manager, e2.last_name
FROM employees e1
LEFT JOIN employees e2 ON e1.manager_id = e2.employee_id;
交叉连接(CROSS JOIN)
交叉连接返回两个表的笛卡尔积,即第一个表的每一行与第二个表的每一行组合。
示例:
假设我们有两个表colors和sizes,我们想要生成所有颜色和尺寸的组合。
SELECT c.color, s.size
FROM colors c
CROSS JOIN sizes s;
并集操作的高级用法
UNION ALL 与性能
UNION ALL 不会去除重复的行,因此通常比 UNION 更快。如果不需要去重,建议使用 UNION ALL。
示例:
假设我们有两个表sales_q1和sales_q2,我们想要合并两个季度的销售数据。
SELECT * FROM sales_q1
UNION ALL
SELECT * FROM sales_q2;
使用并集操作处理复杂查询
并集操作可以用于处理复杂的查询需求,例如将多个来源的数据合并成一个结果集。
示例:
假设我们有一个产品表products和一个促销表promotions,我们想要列出所有产品及其促销价格(如果有促销)。
SELECT p.product_id, p.product_name, p.price AS regular_price, NULL AS promo_price
FROM products p
UNION ALL
SELECT p.product_id, p.product_name, NULL AS regular_price, pr.promo_price
FROM products p
JOIN promotions pr ON p.product_id = pr.product_id;
性能优化技巧
- 索引优化:确保在连接条件和子查询中使用的列上有适当的索引。
- 避免不必要的子查询:尽量减少子查询的使用,特别是在可以使用连接的情况下。
- 使用合适的连接类型:选择最合适的连接类型,以减少不必要的数据扫描。
- 分页查询:对于大数据量的查询,使用分页查询可以提高性能。
- 查询重构:有时重新编写查询可以显著提高性能,特别是当涉及到复杂的子查询和连接时。
通过这些高级查询技术,你可以更高效地管理和查询数据,解决复杂的业务需求。希望这些示例和解释对你有所帮助!
接下来我们将继续深入探讨一些更高级的主题,包括子查询的优化、复杂连接的应用、以及并集操作的高级技巧。此外,我们还会介绍一些实用的性能优化策略和最佳实践。
子查询的优化
避免相关子查询
相关子查询可能会导致性能问题,因为它需要为外部查询的每一行执行一次子查询。可以通过使用连接或其他方法来优化。
示例:
假设我们有一个订单表orders和一个订单详情表order_details。我们想要找出每个订单的总金额。
原始查询:
SELECT o.order_id, (SELECT SUM(od.quantity * od.price)FROM order_details odWHERE od.order_id = o.order_id) AS total_amount
FROM orders o;
优化后的查询:
SELECT o.order_id, SUM(od.quantity * od.price) AS total_amount
FROM orders o
JOIN order_details od ON o.order_id = od.order_id
GROUP BY o.order_id;
使用 WITH 子句(Common Table Expressions, CTE)
CTE 可以提高查询的可读性和性能,尤其是在处理复杂的子查询时。
示例:
假设我们有一个员工表employees和一个部门表departments。我们想要找出每个部门的最高工资和对应的员工。
原始查询:
SELECT d.department_name, e.first_name, e.last_name, e.salary
FROM departments d
JOIN employees e ON d.department_id = e.department_id
WHERE (d.department_id, e.salary) IN (SELECT department_id, MAX(salary)FROM employeesGROUP BY department_id
);
优化后的查询:
WITH max_salaries AS (SELECT department_id, MAX(salary) AS max_salaryFROM employeesGROUP BY department_id
)
SELECT d.department_name, e.first_name, e.last_name, e.salary
FROM departments d
JOIN employees e ON d.department_id = e.department_id
JOIN max_salaries ms ON e.department_id = ms.department_id AND e.salary = ms.max_salary;
复杂连接的应用
多表连接
在实际应用中,经常需要连接多个表来获取所需的数据。多表连接可以通过逐步连接的方式来实现。
示例:
假设我们有一个订单表orders、一个订单详情表order_details和一个产品表products。我们想要列出每个订单的详细信息,包括产品名称和数量。
SELECT o.order_id, p.product_name, od.quantity
FROM orders o
JOIN order_details od ON o.order_id = od.order_id
JOIN products p ON od.product_id = p.product_id;
外连接的高级用法
外连接可以用于处理不完整或缺失的数据。通过使用不同的外连接类型,可以灵活地处理各种情况。
示例:
假设我们有一个客户表customers、一个订单表orders和一个支付表payments。我们想要列出所有客户的订单和支付情况,即使某些客户没有订单或支付记录。
SELECT c.customer_id, c.customer_name, o.order_id, p.payment_id, p.amount
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
LEFT JOIN payments p ON o.order_id = p.order_id;
并集操作的高级技巧
使用 UNION ALL 优化性能
如前所述,UNION ALL 不会去除重复的行,因此通常比 UNION 更快。在不需要去重的情况下,应优先使用 UNION ALL。
示例:
假设我们有两个表sales_q1和sales_q2,我们想要合并两个季度的销售数据。
SELECT * FROM sales_q1
UNION ALL
SELECT * FROM sales_q2;
处理复杂的数据合并
并集操作可以用于处理复杂的查询需求,例如将多个来源的数据合并成一个结果集。
示例:
假设我们有一个产品表products、一个促销表promotions和一个折扣表discounts,我们想要列出所有产品的促销价格和折扣价格。
SELECT p.product_id, p.product_name, p.price AS regular_price, NULL AS promo_price, NULL AS discount_price
FROM products p
UNION ALL
SELECT p.product_id, p.product_name, NULL AS regular_price, pr.promo_price, NULL AS discount_price
FROM products p
JOIN promotions pr ON p.product_id = pr.product_id
UNION ALL
SELECT p.product_id, p.product_name, NULL AS regular_price, NULL AS promo_price, d.discount_price
FROM products p
JOIN discounts d ON p.product_id = d.product_id;
性能优化策略和最佳实践
-
索引优化:
- 确保在连接条件和子查询中使用的列上有适当的索引。
- 考虑使用复合索引(Composite Indexes)来提高性能。
-
避免全表扫描:
- 尽量使用索引和过滤条件来减少扫描的数据量。
- 使用
EXPLAIN PLAN来分析查询的执行计划,找出潜在的性能瓶颈。
-
合理使用临时表:
- 对于复杂的查询,可以考虑将中间结果存储在临时表中,以减少重复计算。
- 临时表可以在多次查询中复用,提高整体性能。
-
分页查询:
- 对于大数据量的查询,使用分页查询可以显著提高性能。
- 使用
ROWNUM或OFFSET和FETCH子句来实现分页。
-
查询重构:
- 有时重新编写查询可以显著提高性能,特别是当涉及到复杂的子查询和连接时。
- 考虑使用视图(Views)来封装复杂的查询逻辑,提高代码的可维护性。
-
使用绑定变量:
- 在动态生成的SQL语句中使用绑定变量,可以减少SQL解析的时间,提高性能。
- 绑定变量还可以防止SQL注入攻击,提高安全性。
-
定期维护数据库:
- 定期分析和优化表的统计信息,确保查询优化器能够生成最优的执行计划。
- 定期清理不再需要的数据,减少表的大小,提高查询性能。
通过这些高级查询技术和性能优化策略,你可以更高效地管理和查询数据,解决复杂的业务需求。希望这些内容对你有所帮助!如果你有任何具体的问题或需要进一步的解释,请随时告诉我。
相关文章:

Oracle 第19章:高级查询技术
在Oracle数据库中,高级查询技术是数据库管理员和开发人员必须掌握的重要技能。这些技术能够帮助优化查询性能,简化复杂的查询逻辑,并提高数据处理的效率。本章将重点讨论两个关键概念:子查询和连接与并集操作。 子查询 定义: 子…...
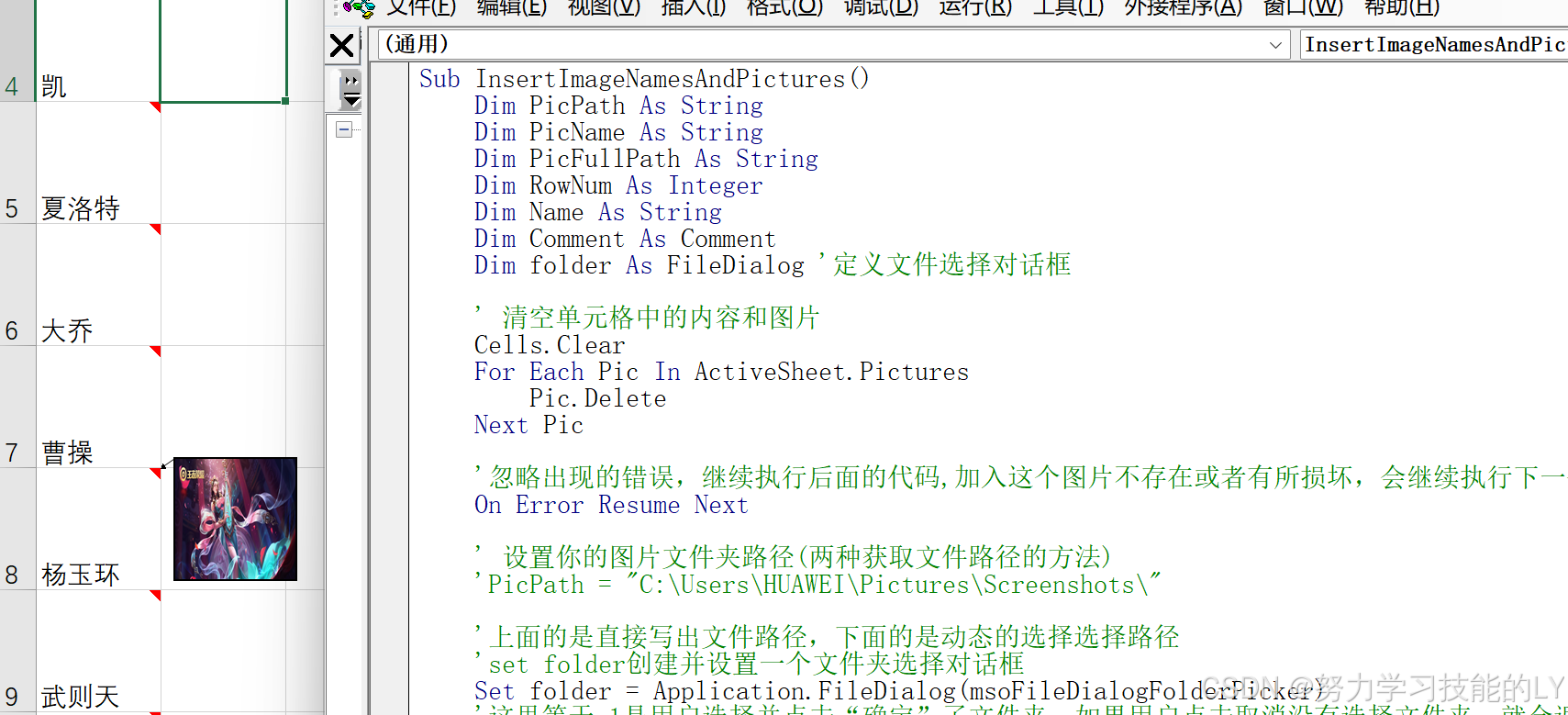
Excel:vba运行时错误“7“:内存溢出错误
我这里出现这个错误是在批注中插入图片时报错 原因:我插入的图片不都是jpg的类型的,但是其中的两张图片是webp类型的,但是我把文件后缀名修改成了jpg,以为变成了jpg类型的图片,但是图片在批注里面无法显示,所以运行到第…...

【MyBatis源码】BoundSql分析
基础 BoundSql是对SQL语句及参数信息的封装,它是SqlSource解析后的结果。Executor组件并不是直接通过StaticSqlSource对象完成数据库操作的,而是与BoundSql交互。BoundSql是对Executor组件执行SQL信息的封装,具体实现代码如下: …...

KTHREAD--InitialStack和KernelStack和TSS的esp0
InitialStack和TSS.esp0的关系,在这里可以看到 mov ecx, [esi_KTHREAD.InitialStack] ; esi: newthread lea eax, [ecx-210h] ; 越过FPXSAVE指令存储地址 test byte ptr [eax-1Ah], 2 ; 判断efalgs寄存器的VIF位是否为1 jnz short loc_458743 sub eax, 10h…...

Skia基础运用(Ubuntu环境下使用BUILD.gn)
1.拉取代码 git clone https://skia.googlesource.com/skia python tools/git-sync-deps // 这一步可能会出现部分错误,再次执行直到成功 // 这里面拉取完三方库之后会拉取node,linux等压缩包,从google下载上面执行完,代码就完全…...

Vue中props和data的优先级哪个更高?
前言 Vue组件之间的数据传递是一个非常重要的环节。而在组件内部,我们经常会用到props和data来管理和传递数据。那么,问题来了:当props和data有冲突时,哪个优先级更高呢? 为了更好地理解这个问题,我们先来…...

springboot2.x使用SSE方式代理或者转发其他流式接口
文章目录 1.需求描述2.代码2.1.示例controller2.2.示例service2.3.示例impl 3.测试 1.需求描述 使用SSE的方式主要还是要跟前端建立一个EventSource的链接,有了这个连接,然后往通道里写入数据流,前端自然会拿到流式数据,写啥拿啥…...

consul入门教程
一、介绍Consul Consul是由HashiCorp开发的一种服务发现和配置管理工具,它可以提供分布式系统所需的多个关键功能,如服务发现、配置管理、键值存储等。Consul可以帮助开发人员轻松构建分布式系统,提高系统的可靠性和可扩展性。 二、Consul实…...

软考:大数据架构设计
大数据总结 大数据处理系统的特征 1、鲁棒性和容错性 2、低延迟读取和更新能力 3、横向扩容 4、通用性 5、延展性 6、即席查询能力 7、最少维护能力 8、可调试性 Lambda架构 批处理层 存储数据集和生成Batch View 管理主数据集,原始的,不可变的&…...
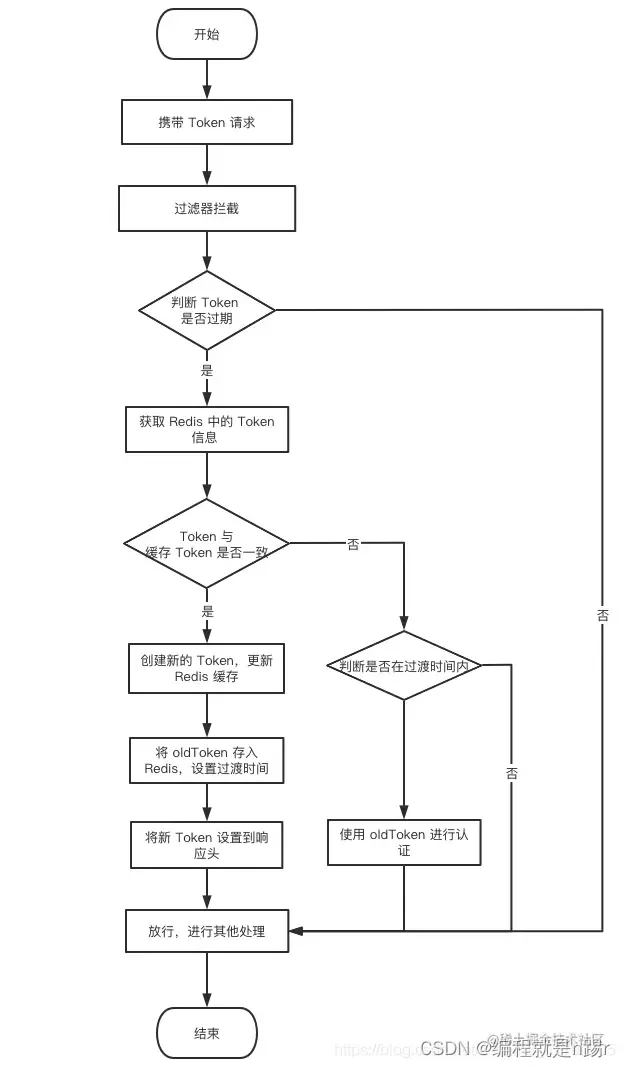
token无感刷新+处理并发的后端方案
问题描述: 当用户通过登陆后进入一个web网站,会把token保存到localStorage。假设token过期时间30min。 那么当用户在网站快乐地玩耍了30min后,这时进行了一次提交表单,它会被重定向到登陆页面。 作为用户:我表单填了…...

【系统设计】让 Java “动起来”:动态语言与静态语言的比较及 DSL 实现
在编程语言的世界里,语言的特性决定了它们在不同场景下的适用性。动态语言和静态语言是两种常见的编程范式,它们的差异不仅影响开发者的使用习惯,还决定了它们在某些应用场景中的表现。在这篇博文中,我们将通过Python和Java这两种…...
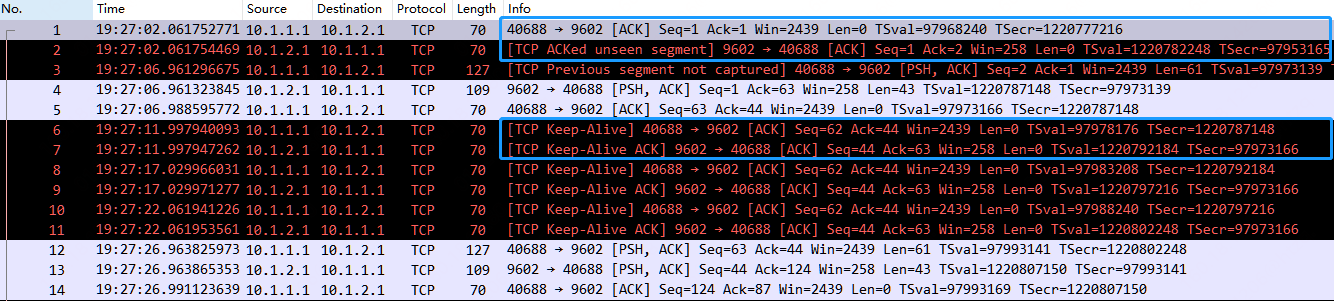
TCP Analysis Flags 之 TCP Keep-Alive
前言 默认情况下,Wireshark 的 TCP 解析器会跟踪每个 TCP 会话的状态,并在检测到问题或潜在问题时提供额外的信息。在第一次打开捕获文件时,会对每个 TCP 数据包进行一次分析,数据包按照它们在数据包列表中出现的顺序进行处理。可…...
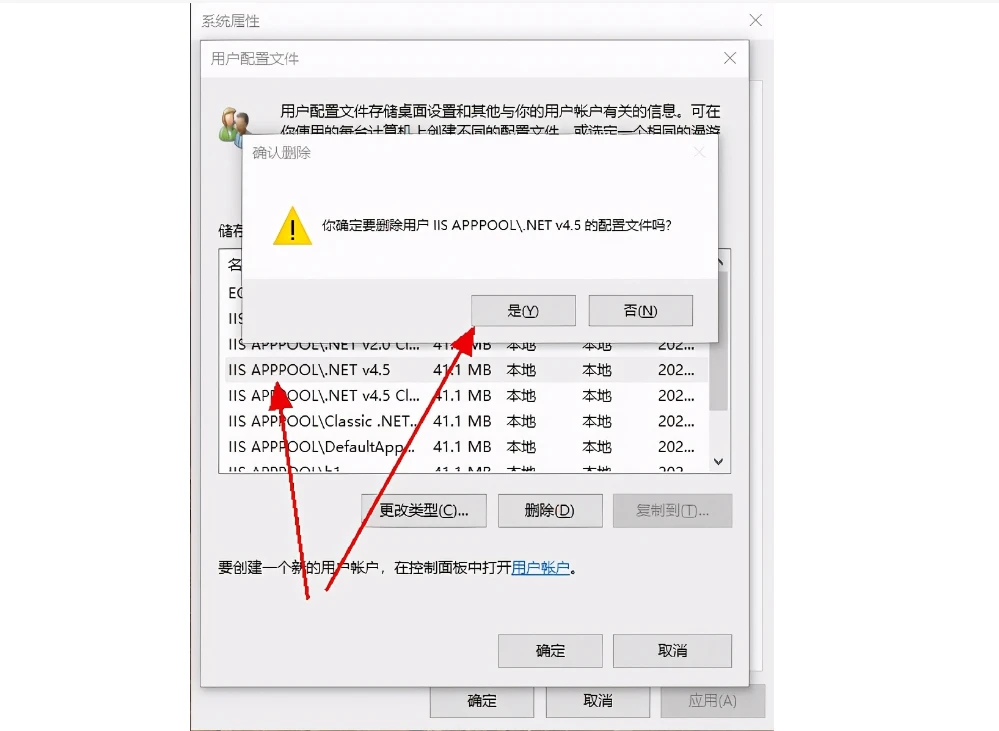
mfc140u.dll丢失怎么办? mfc140u.dll文件缺失的修复技巧
mfc140u.dll 是 Microsoft Foundation Classes (MFC) 库的一部分,它是 Visual Studio 2015 的组件之一,主要服务于使用 C 编写的 Windows 应用程序。这个动态链接库文件包含了 MFC 14.0 Unicode 版本的实现代码,为应用程序提供运行时支持。当…...
Spring Security使用
文章目录 Spring Security的起点FilterChain重写重写登录验证逻辑增加CSRF Token增加方法权限校验 Spring Security的起点 在AbstractApplicationContext.refresh()方法时,子类ServletWebServerApplicationContext会创建一个ServletContextInitializerBeans这个Bea…...

CSS网页布局综合练习(涵盖大多CSS知识点)
该综合练习就是为这个学校静态网页设置CSS样式,使其变成下面的模样 其基本骨架代码为: <!DOCTYPE html> <html lang"zh"> <head> <meta charset"UTF-8"> <meta name"viewport" content…...

解决 Hardhat Verify 超时
问题背景 今天在学习使用Hardhat进行verify 合约 到 Ethscan的时候,出现了如下报错 fafafafadeMacBook-Air Web3_Solidity_Study % npx hardhat verify --network sepolia XXXXXXXXXXXXXXXXXXXXXXXX "10" Successfully verifie…...

ACIS创建各种基本体,举例说明
ACIS(Advanced CAD Interoperability System)是一个广泛使用的三维几何建模内核,它支持创建和操作各种基本的三维几何体。虽然ACIS没有专门的函数来直接创建某些特定的基本体(如椭球体),但可以通过一系列变…...

[CISCN 2019华北]PWN1-好久不见7
Partial RELRO 表示部分 RELRO 保护已启用。在这种情况下,只有某些部分(如 GOT 中的只读部分)是只读的。 NX enabled 表示这个二进制文件启用了 NX 保护,数据段是不可执行的。这可以防止某些类型的代码注入攻击。 这里是ida识别…...

代码随想录day16| 513找树左下角的值 、 路径总和 、 从中序与后序遍历序列构造二叉树
代码随想录day16| 找树左下角的值 、 路径总和 、 从中序与后序遍历序列构造二叉树 513找树左下角的值层序遍历法递归法 路径总和112. 路径总和113. 路径总和 II 从中序与后序遍历序列构造二叉树思路 513找树左下角的值 层序遍历法 使用层序遍历,找到最后一层最左边…...
使用 MMDetection 实现 Pascal VOC 数据集的目标检测项目练习(二) ubuntu的下载安装
首先,Linux系统是人工智能和深度学习首选系统。原因如下: 开放性和自由度:Linux 是一个开源操作系统,允许开发者自由修改和分发代码。这在开发和研究阶段非常有用,因为开发者可以轻松地访问和修改底层代码。社区支持:…...

ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在
ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的nc…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

构建轻量级LLM工具集:模块化设计、多模型集成与本地化部署实践
1. 项目概述:一个面向日常的轻量级LLM工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Daily-LLM”。光看名字,你可能会觉得这又是一个庞大的、需要海量算力才能跑起来的“大模型”项目。但点进去仔细研究后,我…...

基于Stable Diffusion与LoRA技术打造个人AI头像:从原理到实战
1. 项目概述:当AI开始“自拍”——SelfyAI的定位与核心价值最近在AI图像生成领域,一个名为SelfyAI的项目引起了我的注意。它不是一个简单的文生图工具,而是瞄准了一个非常具体且高频的需求:生成高质量、风格一致的个人AI头像。简单…...

AI编程助手CodeBuddy:VS Code扩展的架构、部署与高效使用指南
1. 项目概述:CodeBuddy,你的AI编程伙伴最近在GitHub上看到一个挺有意思的项目,叫codebuddy,作者是olasunkanmi-SE。光看名字就能猜个大概——“代码伙伴”,这显然是一个旨在辅助编程的工具。作为一个在开发一线摸爬滚打…...

基于树莓派与QT Py的本地化物联网红外遥控器DIY指南
1. 项目概述与核心价值想没想过,把家里那堆遥控器——电视的、机顶盒的、空调的、音响的——统统集成到一个你手机能打开的网页里?而且这个控制中心完全在你家局域网里运行,不依赖任何云服务,不用担心厂商倒闭后设备变砖。今天分享…...

Kubernetes上Jenkins全栈部署:动态Agent与生产环境调优指南
1. 项目概述:一个面向Kubernetes的Jenkins全栈部署方案在容器化和云原生技术成为主流的今天,如何高效、稳定地部署和管理持续集成/持续交付(CI/CD)流水线,是每个开发团队和运维工程师必须面对的课题。传统的单体Jenkin…...
基于PWM舵机与NeoPixel的万圣节互动蝙蝠制作全解析
1. 项目概述:一个会动的万圣节蝙蝠又快到万圣节了,想给家里的装饰来点不一样的“活物”吗?每年都摆静态的南瓜灯和蜘蛛网,总觉得少了点气氛。今年我琢磨着,不如自己动手做一个能扑腾翅膀、眼睛还会发光的机械蝙蝠&…...

PyTorch:torch.nonzero——从稀疏数据到精准索引的实战指南
1. 为什么你需要掌握torch.nonzero? 在处理数据时,我们经常会遇到这样的情况:一个大型张量中只有少数几个值是我们真正关心的。想象一下你在分析一张医学影像,可能只有几个像素点显示异常;或者在自然语言处理中&#x…...

湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告 为何“wet plate collodion”提示词突然失灵? 在 Midjourney v6.1 及 N…...