Hadoop——HDFS
什么是HDFS
HDFS(Hadoop Distributed File System)是Apache Hadoop的核心组件之一,是一个分布式文件系统,专门设计用于在大规模集群上存储和管理海量数据。它的设计目标是提供高吞吐量的数据访问和容错能力,以支持大数据处理任务。下面是HDFS的主要特性和功能:
1. 架构
- 主从架构:
- NameNode:HDFS的主节点,负责管理文件系统的元数据,如文件和目录结构、文件块的位置等。NameNode不存储实际数据,只管理数据的元信息。
- DataNode:HDFS的从节点,负责实际存储数据块。每个文件在HDFS中被分割成多个数据块(默认大小为128MB或256MB),并分布存储在多个DataNode上。
2. 高容错性
- 数据复制:HDFS通过将每个数据块复制多个副本(默认3个副本)来确保数据的高可用性和容错性。如果某个DataNode故障,系统仍可以从其他副本中恢复数据。
- 自动故障恢复:当DataNode宕机时,NameNode会监控并自动重新复制丢失的数据块,以保证数据的冗余性。
3. 高吞吐量
- 优化读写:HDFS针对大文件的存储和访问进行了优化,适合顺序读写操作。它不适合频繁的随机读取,因为这种模式会降低性能。
- 流式访问:HDFS允许数据流式访问,用户可以在数据写入的同时进行读取,提高数据处理的效率。
4. 可扩展性
- 横向扩展:HDFS支持通过简单地添加新的DataNode来扩展存储容量。这种方式可以灵活应对不断增长的数据量。
5. 数据完整性
- 校验和:HDFS对存储的数据块进行校验和检测,以确保数据在存储和传输过程中的完整性。如果发现损坏,系统会自动从其他副本中恢复数据。
6. 接口
- API接口:HDFS提供了一组API,支持Java和其他语言的开发,方便用户对文件的读写操作。
总结
HDFS是一个为处理和存储海量数据而设计的分布式文件系统,具备高容错性、高吞吐量和可扩展性等优点。它通过将数据分割成多个块并在集群中分布存储,确保了数据的高可用性和高性能,成为大数据处理的基础设施之一。
HDFS的基础架构
1. NameNode主角色
- 功能:作为HDFS的主节点,负责管理文件系统的元数据,包括文件和目录的命名空间、文件的属性、文件块的位置等。
- 职责:
- 元数据管理:维护文件系统的结构,跟踪每个文件的块及其在DataNode上的位置。
- 客户端请求处理:处理来自客户端的文件操作请求(如创建、删除、重命名文件等),并相应地更新元数据。
- 故障监控:监控DataNode的健康状态,并在发现故障时采取措施(如重新复制丢失的块)。
2. Secondary NameNode辅助角色
- 功能:Secondary NameNode并不是NameNode的备份,而是一个辅助角色,主要用于定期合并NameNode的元数据文件,以减小NameNode的内存占用和元数据文件的大小。
- 职责:
- 合并元数据:定期从NameNode获取编辑日志,并将其与文件系统的镜像文件合并,从而减少NameNode的内存使用。
- 故障恢复:虽然Secondary NameNode不能替代NameNode,但在NameNode故障时,可以通过它的快照恢复部分元数据。
DataNode 从角色
- 功能:HDFS中的从节点,负责存储实际的数据块。
- 职责:
- 数据存储:接收并存储来自客户端或其他DataNode的数据块。
- 心跳信号:定期向NameNode发送心跳信号,以报告自身的健康状态和存储情况。
- 数据块复制:根据NameNode的指令,执行数据块的复制和删除操作,以确保数据的冗余性和高可用性。
HDFS 设计原理

HDFS副本块数量的配置
在HDFS(Hadoop Distributed File System)中,副本块数量的配置是一个重要的参数,它直接影响数据的可靠性和存储效率。副本块数量决定了每个数据块在集群中保存的副本数量,从而影响到容错能力和数据读取的性能。
1. 默认副本数量
- HDFS的默认副本块数量通常是3。这意味着每个数据块会在集群中的3个不同的Datanode上存储副本,以提高数据的可用性和容错性。
2. 配置副本块数量
副本块数量可以在HDFS的配置文件中进行设置,主要配置文件为hdfs-site.xml。可以通过以下属性来修改副本数量:
<configuration><property><name>dfs.replication</name><value>3</value> <!-- 设置为所需的副本数量 --></property>
</configuration>
3. 调整副本数量的注意事项
-
高可用性与性能:增加副本数量可以提高数据的可靠性,但也会增加存储需求和网络流量。对于经常访问的数据,建议保持较高的副本数量,而对于不常用的数据,可以减少副本数量。
-
集群规模:在小规模集群中,设置较高的副本数量可能会导致存储资源的浪费。反之,在大规模集群中,可以根据数据的重要性和访问频率来调整。
-
副本的分布:HDFS会智能地在不同的Datanode上存储副本,以确保负载均衡和容错性。因此,配置副本数量时,也要考虑集群的实际节点数和分布。
4. 动态调整副本数量
HDFS允许对已经存在的文件动态调整副本数量,可以使用以下命令:
复制代码
hdfs dfs -setrep -w <replication_factor> /path/to/file-w参数表示等待操作完成。<replication_factor>是目标副本数量。
假设我们希望将一个特定文件的副本数量设置为2,可以执行以下命令:
hdfs dfs -setrep -w 2 /user/hadoop/example.txt
fsck命令查看文件系统状态及验证文件的数据副本
fsck(File System Check)命令在HDFS中用于检查文件系统的状态以及验证文件的数据副本。这个命令可以帮助管理员发现和解决文件系统中的问题,确保数据的完整性和可用性。以下是关于fsck命令的详细信息:
1. 基本用法
fsck命令的基本语法如下:
hdfs fsck /path/to/directory_or_file2. 功能和作用
-
检查文件系统状态:
fsck命令可以检查HDFS中指定目录或文件的状态,包括是否存在、是否有损坏的块、是否有丢失的副本等。 -
验证副本状态:命令会验证文件的每个块副本,检查它们在各个Datanode上的状态。这样可以确保数据的完整性和一致性。
3. 常用选项
-
-delete:此选项用于删除文件系统中丢失或损坏的数据块,适用于清理无效数据。 -
-files:显示文件的详细信息。 -
-blocks:显示块的详细信息,包括每个块的副本状态。 -
-locations:显示每个块的副本存储位置。
4. 示例
以下是使用fsck命令的一些示例:
-
检查整个文件系统:
hdfs fsck / -
检查特定文件:
hdfs fsck /user/hadoop/example.txt -
显示块信息:
hdfs fsck /user/hadoop/example.txt -blocks -
删除丢失的块:
hdfs fsck / -delete
5. 输出结果
fsck命令的输出结果通常包含以下信息:
- 文件路径:被检查的文件或目录路径。
- 文件状态:包括是否存在、是否损坏等。
- 块信息:每个数据块的状态、数量和副本位置。
- 问题总结:如丢失块、重复块等问题的汇总信息。
NameNode元数据
在Hadoop的HDFS(Hadoop Distributed File System)中,NameNode是管理文件系统元数据的核心组件。它负责跟踪所有文件和目录的信息,包括文件的名称、权限、块信息、位置等。NameNode使用edits和fsimage两个重要的概念来完成文件系统的管理和维护。下面详细解释它们的作用及其配合关系:
1. fsimage文件
-
定义:
fsimage是一个持久化的文件,包含了HDFS文件系统的所有元数据的快照。它记录了当前文件系统的结构,包括文件和目录的层次结构、块的信息和它们在数据节点上的位置等。 -
作用:
- 作为文件系统状态的完整备份,可以快速加载文件系统的基本信息。
- 当NameNode启动时,会读取这个文件来恢复文件系统的状态。
2. edits文件
-
定义:
edits文件是一个事务日志,记录了对文件系统元数据所做的所有更改操作,如创建文件、删除文件、修改文件权限等。每当对HDFS进行写操作时,这些变更会被追加到edits文件中。 -
作用:
- 记录所有的操作,可以用于恢复文件系统的状态。
- 提供了对文件系统变更的追踪,确保数据的一致性。
3. 配合关系
-
工作流程:
- NameNode在启动时会首先加载
fsimage文件,以获取当前的文件系统状态。 - 在运行过程中,所有对文件系统的更改(如新文件的创建、文件的删除等)都会被记录到
edits文件中。 - 为了保持数据一致性,NameNode会定期将
edits文件中的更改合并到fsimage中,生成一个新的fsimage文件,这个过程称为“合并”或“快照”。
- NameNode在启动时会首先加载
-
故障恢复:
- 如果NameNode发生故障或重启,可以通过先加载
fsimage文件来恢复文件系统的状态,然后应用edits文件中的所有操作,以恢复到最新的状态。 - 这种方式确保了即使在故障情况下,文件系统的完整性和一致性也能得到保障。
- 如果NameNode发生故障或重启,可以通过先加载
4.元数据合并控制参数
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage) 然后合并完成后提供给NameNode使用:
对于元数据的合并,是一个定时过程,基于:
dfs.namenode.checkpoint.period,默认3600(秒)即1小时
dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
只要有一个达到条件就执行。 检查是否达到条件,默认60秒检查一次,基于: dfs.namenode.checkpoint.check.period,默认60(秒),来决定
5. 总结
NameNode通过fsimage和edits文件的配合,实现了对整个HDFS文件系统的有效管理和维护。fsimage提供了文件系统的静态快照,而edits则记录了动态变化。两者的结合确保了文件系统在高可用性和可靠性方面的表现,使得HDFS能够处理大规模数据的存储与管理。
一键启停脚本
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
单独控制进程的启停
1. $HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)
2. $HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
相关文章:
Hadoop——HDFS
什么是HDFS HDFS(Hadoop Distributed File System)是Apache Hadoop的核心组件之一,是一个分布式文件系统,专门设计用于在大规模集群上存储和管理海量数据。它的设计目标是提供高吞吐量的数据访问和容错能力,以支持大数…...

计算机的一些基础知识
文章目录 编程语言 程序 所谓程序,就是 一组指令 以及 这组指令要处理的数据。狭义上来说,程序对我们来说,通常表现为一组文件。 程序 指令 指令要处理的数据。 编程语言发展 机器语言:0、1 二进制构成汇编语言:…...

学习RocketMQ(记录了个人艰难学习RocketMQ的笔记)
一、部署单点RocketMQ Docker 部署 RocketMQ (图文并茂超详细)_docker 部署rocketmq-CSDN博客 这个博主讲的很好,可食用,替大家实践了一遍 二、原理篇 为什么使用RocketMQ: 为什么选择RocketMQ | RocketMQ 关于一些原理,感觉…...

【设计模式】策略模式定义及其实现代码示例
文章目录 一、策略模式1.1 策略模式的定义1.2 策略模式的参与者1.3 策略模式的优点1.4 策略模式的缺点1.5 策略模式的使用场景 二、策略模式简单实现2.1 案例描述2.2 实现代码 三、策略模式的代码优化3.1 优化思路3.2 抽象策略接口3.3 上下文3.4 具体策略实现类3.5 测试 参考资…...
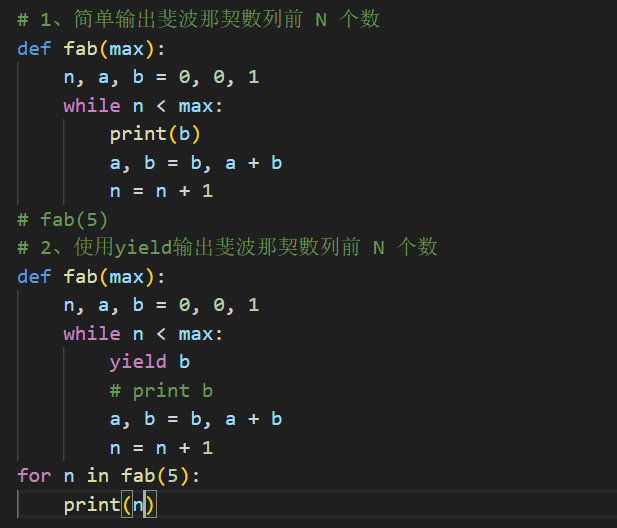
list与iterator的之间的区别,如何用斐波那契数列探索yield
问题 list与iterator的之间的区别是什么?如何用斐波那契数列探索yield? 2 方法 将数据转换成list,通过对list索引和切片操作,以及可以进行添加、删除和修改元素。 iterator是一种对象,用于遍历可迭代对象(如列表、元组…...

抖音店铺数据也就是抖店,如何使用小店数据集来挖掘价值?
抖音商家现在基本达到二百多万家抖店,有一些公司可能会根据开放的数据研究行业分布、GMV等等,就像是也出了专业的一些平台如“蝉妈妈”、“达多多”,对我来说受限制就是难受。 当然也有很多大型合法的数据平台有抖店数据集,但…...

KubeVirt 安装和配置 Windows虚拟机
本文将将介绍如何安装 KubeVirt 和使用 KubeVirt 配置 Windows 虚拟机。 前置条件 准备 Ubuntu 操作系统,一定要安装图形化界面。 安装 Docker(最新版本) 安装 libvirt 和 TigerVNC: apt install libvirt-daemon-system libvir…...

CM API方式设置YARN队列资源
简述 对于CDH版本我们可以参考Fayson的文章,本次是CDP7.1.7 CM7.4.4 ,下面只演示一个设置队列容量百分比的示例,其他请参考cloudera官网。 获取cookies文件 生成cookies.txt文件 curl -i -k -v -c cookies.txt -u admin:admin http://192.168.242.100:7180/api/v44/clusters …...

Mysql常用语法一篇文章速成
文章目录 前言前置环境数据库的增删改查查询数据查询所有条件查询多条件查询模糊查询分页查询排序查询分组查询⭐️⭐️关联查询关联分页查询 添加数据insert插入多条记录不指定列名(适用于所有列都有值的情况) 更新数据更新多条记录更新多个列更新不满足条件的记录 删除统计数…...
)
Intel nuc x15 重装系统步骤和注意事项(LAPKC71F、LAPKC71E、LAPKC51E)
注意本教程的对象是11代CPU,英伟达独显的nuc x15,不是12代arc显卡的。 x15安装win11 24h2,如果在装系统时联网,windows自动下载的最新驱动有兼容问题,会导致【英特尔显卡控制中心】装不上,或者【英特尔nuc…...

Linux之实战命令59:iwlist应用实例(九十三)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【…...

数据库_SQLite3
下载 1、更新软件源: sudo apt-get update 2、下载SQLite3: sudo apt-get install sqlite3 3、验证: sqlite3启动数据库,出现以下界面代表运行正常。输入 .exit 可以退出数据库 4、安装sqlite3的库 sudo apt-get install l…...

.Net Framework里演示怎么样使用StringBuilder、Math.Min和String.Format
StringBuilder、Math.Min和String.Format, 这几个功能都是我们经常使用的功能, 但是怎么样正确地使用,还是得向微软的开发人员学习。 他们在写.Net Framework的源码时,就会大量使用。 因此,我们可以多看看这分代码,就可以理解他们怎么样使用的。 他们的使用方式,一…...

Oracle创建存储过程,创建定时任务
在Oracle数据库中,创建存储过程和定时任务(也称为调度任务)是常见的数据库管理任务。以下是创建存储过程和定时任务的步骤和说明。 创建存储过程 创建存储过程的sql脚本 create or replace procedure 存储过程名称... is begin脚本逻辑...…...

<HarmonyOS第一课>应用/元服务上架的课后习题
善者,吾善之; 不善者,吾亦善之,德善。 信者,吾信之; 不信者,吾亦信之,德信。 圣人在天下,歙歙焉为天下浑其心,百姓皆注其耳目,圣人皆孩之。 通过&…...

【Python】探索函数的奥秘:从基础到高级的深度解析(下)
目录 🍔 函数的参数进阶 1、函数的参数 2、函数的参数类型(调用) 2.1 位置参数 2.2 关键词参数(Python特有) 3、函数定义时缺省参数(参数默认值) 4、不定长参数 4.1 不定长元组(位置)参数…...

ima.copilot:智慧因你而生
在数字化时代,信息的获取、处理和创作已经成为我们日常工作和学习中不可或缺的一部分。腾讯公司推出的ima.copilot(简称ima)正是为了满足这一需求,它是一款由腾讯混元大模型提供技术支持的智能工作台产品,旨在通过智能…...

Vue-$el属性
原博客地址:深入 Vue.js 的心脏:全面剖析 $el 属性_vue $el-CSDN博客 目录 1 $el是什么 1.1 $el本质 1.2 访问$el时机 1.3 $el与模板的关系 2 $el使用场景 2.1 集成第三方库 2.2 操作DOM元素样式 2.3 处理焦点和事件 2.4 实现自定义指令 3 $e…...

LLC Power Switches and Resonant Tank 笔记
1.概述 上面是一个典型的LLC电路。注意Lm是励磁电感,就是次级线圈空载时的主变压器电感,据说在计算谐振频率时无需关心。然后,作为DCDC电源,它通过调整谐振频率,来改变输出的电流。负载越大,频率越低&#…...

Python 如何在 Web 环境中使用 Matplotlib 进行数据可视化
Python Matplotlib 在 Web 环境中的可视化 数据可视化是数据科学和分析中一个至关重要的部分,它能帮助我们更好地理解和解释数据。在现代应用中,越来越多的开发者希望能够将数据可视化结果展示在网页上。Matplotlib 是 Python 中最常用的数据可视化库之…...

数字孪生-三维重建-透明建筑-以智能管控为价值
透明建筑的核心透明建筑,本质上不是 “玻璃造房子”,而是以三维重构为骨架、以空间连续为逻辑、以全域可视为目标、以智能管控为价值的新一代数字孪生空间形态。它的核心可以浓缩为四句话:1. 空间可视核心:打破物理遮挡࿰…...
。)
Linux连接用户态和内核态的唯一合法通道:系统调用 (System Call)。
发起请求:运行在用户态的程序调用了 write(fd, "1", 1)。上下文切换 (Context Switch):CPU 触发一个特殊的软中断指令(Trap),强制暂停当前程序,并将 CPU 的运行模式从“用户态(低权限…...

AI商品计划:中国鞋服零售如何用机器学习解决库存与周转难题
过去十年,中国鞋服零售经历了从线下到线上、从粗放铺货到精准运营的剧烈转变。但一个老问题始终没变:该备多少货,备在哪,备什么颜色尺码。备多了,资金压在仓库,季末折扣吞噬利润;备少了…...
报错?用Clock.tick()轻松搞定(附完整代码示例))
别慌!Pygame里time.sleep()报错?用Clock.tick()轻松搞定(附完整代码示例)
Pygame时间控制革命:为什么Clock.tick()比time.sleep()更适合游戏开发 在Pygame游戏开发的世界里,时间控制是构建流畅游戏体验的核心要素。许多初学者在从Python标准库转向Pygame时,常常会本能地使用time.sleep()来控制游戏节奏,却…...

当声带萎缩遇上AI建模:ElevenLabs老年女性语音不可忽视的5项生理声学特征补偿技术
更多请点击: https://intelliparadigm.com 第一章:声带萎缩与老年女性语音建模的交叉挑战 随着人口老龄化加剧,构建高保真、个体化老年女性语音合成模型面临独特的生理—声学耦合难题。声带萎缩导致基频降低、抖动率(jitter&…...

游戏修改入门:用Cheat Engine精确扫描血量,5分钟搞定单机游戏数值修改
游戏修改入门:用Cheat Engine精确扫描血量,5分钟搞定单机游戏数值修改 在单机游戏的世界里,偶尔会遇到难度过高或重复刷怪的疲惫感。你是否想过像开发者一样自由调整游戏参数?Cheat Engine(简称CE)这款开源…...

高性能PDF文本提取引擎:基于Poppler C++的pdftotext架构解析与性能优化实践
高性能PDF文本提取引擎:基于Poppler C的pdftotext架构解析与性能优化实践 【免费下载链接】pdftotext Simple PDF text extraction 项目地址: https://gitcode.com/gh_mirrors/pd/pdftotext 在当今数字化办公环境中,PDF文档作为信息交换的标准格式…...

别再死磕官方文档了!R语言circlize包画圈图,这份新手避坑笔记帮你省下三天时间
R语言circlize包实战指南:从挫败感到高效绘图的进阶之路 第一次打开circlize包的官方文档时,那种扑面而来的复杂参数和抽象概念让人望而生畏。作为生物信息学分析中常用的环形可视化工具,circlize包在基因组数据展示、多维度数据关联分析等领…...

Winhance中文版:Windows系统优化终极指南,3分钟让电脑焕然一新
Winhance中文版:Windows系统优化终极指南,3分钟让电脑焕然一新 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mir…...

在多模型AI应用开发中利用Taotoken实现成本与性能的平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型AI应用开发中利用Taotoken实现成本与性能的平衡 开发一个复杂的AI应用,往往意味着需要调用多个模型来完成不同…...