DFA算法实现敏感词过滤
DFA算法实现敏感词过滤
需求:检测一段文本中是否含有敏感词。
比如检测一段文本中是否含有:“滚蛋”,“滚蛋吧你”,“有病”,
可使用的方法有:
- 遍历敏感词,判断文本中是否含有这个敏感词。
for (keyword in [“滚蛋”、“滚蛋吧你”、“有病”]) {if (text.indexOf(keyword) != -1) {return true;}
}
return false;
- 使用正则表达式
Pattern pattern = Pattern.compile("滚蛋|滚蛋吧你|有病"); // 编写正则表达式
Matcher matcher = pattern.matcher(text); // 编写正则表达式
return matcher.matches();
以上两个方法,随着敏感词的增加,效率会越来越低。
而我们使用DFA算法只需遍历一遍文本,就可以找出文本中所有敏感词。
DFA算法
我先大致讲讲DFA算法是怎么做到敏感词过滤的。
DFA查找过程
-
DFA算法会维护一个map结构的敏感词库
map结构就是一个个key、value。在一个key,value中,【key里装的是敏感词的首个字符】,【value又是一个map结构】,这个value里一般存储两对key,value:一对key,value的key是isEnd变量,value为0表示这个字符不是这个敏感词的最后一个字符;value为1表示这个字符是这个敏感词的最后一个字符。另一对key,value的key里装的则是下一个字符,value则又是一个map结构……;
也就是说对于每个敏感词的一个字符中,都记录着这个字符是否为最后一个,如果不是最后一个的话还记录下一个字符的信息。

画成树的结构就是这样:

-
遍历文本中的每个字符,【此时的map的key都是敏感词的第一个字符】。
-
如果map.get(这个字符)不为空,表示这个字符可能是敏感词的第一个字符
-
获取这个敏感词字符的下一个字符信息,和isEnd信息。【此时的map的key是下一个字符】。判断isEnd是否为1,为1表示匹配到敏感词,结束。
-
不为1,继续遍历文本的下一个字符,判断map.get(这个字符)是否为空。
-
如果不为空,获取这个敏感词字符的下一个字符信息,和isEnd信息。【此时的map的key是下一个字符】。判断isEnd是否为1,为1表示匹配到敏感词,结束。
-
不为1,……
-
直到isEnd为1
上面的步骤归纳起来,一个循环主要做的就是
- map.get(这个字符)
- 是否为空,不为空,获取这个敏感词字符的下一个字符信息和isEnd信息。如果isEnd为1,结束
- 继续循环遍历。
经过上述步骤,就可以匹配到一个敏感词,如果文本中有多个敏感词炸糕?将文本中的每个字符作为初始字符,都经过上面步骤的匹配,最终都可以找到文本中包含的所有敏感词。
敏感词库初始化
知道了大致匹配的过程后,就是要构建一个敏感词库,也就是给你一堆敏感词,构建一个map结构。如下图:
与匹配差不多思路:
-
遍历敏感词的每一个字符
-
curMap一开始就是表示敏感词一个字符的map结构
-
Map<String, Object> wordMap = (Map<String, Object>) curMap.get(key);
-
如果wordMap 为空,则建一个wordMap ,这个wordMap 涵盖两个信息:下一个字符、isEnd
-
不管wordMap 为不为空,curMap被赋值为wordMap ,表示下一个字符的map结构。
-
……循环
/*** 生成敏感词库* @param words* @return*/
private Map<String, Object> handleToMap(Collection<String> words) {if (words == null) {return null;}// map初始长度words.size(),整个字典库的入口字数(小于words.size(),因为不同的词可能会有相同的首字)Map<String, Object> map = new HashMap<>(words.size());// 遍历过程中当前层次的数据Map<String, Object> curMap = null;Iterator<String> iterator = words.iterator();while (iterator.hasNext()) {String word = iterator.next();curMap = map;int len = word.length();for (int i =0; i < len; i++) {// 遍历每个词的字String key = String.valueOf(word.charAt(i));// 当前字在当前层是否存在, 不存在则新建, 当前层数据指向下一个节点, 继续判断是否存在数据Map<String, Object> wordMap = (Map<String, Object>) curMap.get(key);if (wordMap == null) {// 每个节点存在两个数据: 下一个节点和isEnd(是否结束标志)wordMap = new HashMap<>(2);wordMap.put("isEnd", "0");curMap.put(key, wordMap);}curMap = wordMap;// 如果当前字是词的最后一个字,则将isEnd标志置1if (i == len -1) {curMap.put("isEnd", "1");}}}return map;
}
/*** 文本中是否含有敏感词* @param text* @param beginIndex* @return*/
private int checkWord(String text, int beginIndex) {if (dictionaryMap == null) {throw new RuntimeException("字典不能为空");}boolean isEnd = false;int wordLength = 0;Map<String, Object> curMap = dictionaryMap;int len = text.length();// 从文本的第beginIndex开始匹配for (int i = beginIndex; i < len; i++) {String key = String.valueOf(text.charAt(i));// 获取当前key的下一个节点curMap = (Map<String, Object>) curMap.get(key);if (curMap == null) {break;} else {wordLength ++;if ("1".equals(curMap.get("isEnd"))) {isEnd = true;}}}if (!isEnd) {wordLength = 0;}return wordLength;
}/*** 获取匹配到的敏感词和命中次数* @param text* @return*/
public Map<String, Integer> matchWords(String text) {Map<String, Integer> wordMap = new HashMap<>();int len = text.length();for (int i = 0; i < len; i++) {int wordLength = checkWord(text, i);if (wordLength > 0) {String word = text.substring(i, i + wordLength);// 添加敏感词匹配次数if (wordMap.containsKey(word)) {wordMap.put(word, wordMap.get(word) + 1);} else {wordMap.put(word, 1);}i += wordLength - 1;}}return wordMap;
}
put(word, wordMap.get(word) + 1);} else {wordMap.put(word, 1);}i += wordLength - 1;}}return wordMap;
}
参考:
https://www.zhihu.com/collection/922374522
https://www.jianshu.com/p/e58a148eecc5
相关文章:
DFA算法实现敏感词过滤
DFA算法实现敏感词过滤 需求:检测一段文本中是否含有敏感词。 比如检测一段文本中是否含有:“滚蛋”,“滚蛋吧你”,“有病”, 可使用的方法有: 遍历敏感词,判断文本中是否含有这个敏感词。 …...

Python自动化运维:技能掌握与快速入门指南
#编程小白如何成为大神?大学生的最佳入门攻略# 在当今快速发展的IT行业中,Python自动化运维已经成为了一个不可或缺的技能。本文将为您详细介绍Python自动化运维所需的技能,并提供快速入门的资源,帮助您迅速掌握这一领域。 必备…...

在linux系统中安装pygtftk软件
1.下载和安装 网址: https://dputhier.github.io/pygtftk/index.html ## 手动安装 git clone http://gitgithub.com:dputhier/pygtftk.git pygtftk cd pygtftk # Check your Python version (>3.8,<3.9) pip install -r requirements.txt python setup.py in…...

decodeURIComponentSafe转义%问题记录URI malformed
decodeURIComponentSafe转义%问题记录 问题背景 当我们解析包涵 % 字符的字符串时,会出现错误如下 Uncaught URIError: URI malformed 解决方案: function decodeURIComponentSafe(s) {if (!s) {return s;}return decodeURIComponent(s.replace(/%(?…...

自由学习记录(18)
动画事件的碰撞器触发 Physics 类的常用方法 RaycastHit hit; if (Physics.Raycast(origin, direction, out hit, maxDistance)) {Debug.Log("Hit: " hit.collider.name); } Physics.Raycast:从指定点向某个方向发射射线,检测是否与碰撞体…...

vue3-ref 和 reactive
文章目录 vue3 中 ref 和 reactivereactive 与 ref 不同之处ref 处理复杂类型ref在dom中的应用 vue3 中 ref 和 reactive ref原理 基本原理 ref是Vue 3中用于创建响应式数据的一个函数。它的基本原理是通过Object.defineProperty()(在JavaScript的规范中用于定义对…...

Apache Calcite - 查询优化之自定义优化规则
RelOptRule简介 为了自定义优化规则,我们需要继承RelOptRule类。org.apache.calcite.plan.RelOptRule 是 Apache Calcite 中的一个抽象类,用于定义优化规则。优化规则是用于匹配查询计划中的特定模式,并将其转换为更优化的形式的逻辑。通过继…...
的小型化研究进展)
大型语言模型(LLM)的小型化研究进展
2024年,大型语言模型(LLM)的小型化研究取得了显著进展,主要采用以下几种方法实现: 模型融合:通过将多个模型或检查点合并为一个单一模型,减少资源消耗并提升整体性能。例如,《WARM: …...

MiniWord
1.nuget 下载配置 2.引用 3. var value = new Dictionary<string, object>() { ["nianfen"] = nianfen, ["yuefen"] = yuefen, ["yuefenjian1"] = (int.Par…...
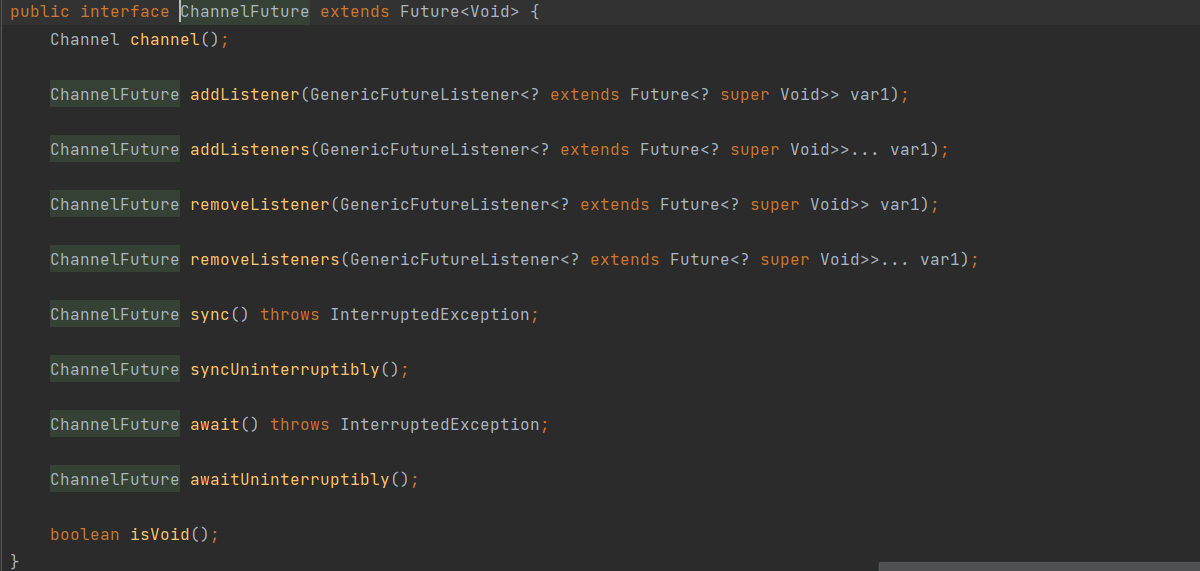
Netty 常见组件介绍
Netty 常见组件介绍 上篇文章Netty入门程序echo 基本包含了Netty常见的组件,本文分别介绍各个组件 Bootstrap or ServerBootstrapEventLoopEventLoopGroupChannelPipelineChannelFuture or ChannelFutureChannelInitializerChannelHandler Bootstrap vs ServerBo…...

高频电子线路---倍频器与振荡器
目录 倍频电路原理 丙类倍频器原理电路 问题: 提升滤波方法: 导通角 振荡器 振荡器基本工作原理 首先是怎么维持 那么如何振荡呢? 思考题: 组成要素 振荡器的起振条件 平衡条件 要点提示 稳定条件 振幅平衡 硬激励起振时: 稳定条件 相位平衡 倍频电路原理 简单原理 : …...

删除 git submodule
直接运行下面命令即可: git rm <path-to-submodule>然后提交修改即可。 但是,还有一个小问题:上面命令只是将 submodule 的代码目录删除了。 以下痕迹还存在你的仓库中: .gitmodule 中关于该 submodule 的信息.git 目录…...
)
el-table 多选默认选中(根据返回的id给数据加默认选中状态)
前言 el-table是我们最常用的展示数据的方式,但是有时候需要用到多选来选择数据,新增数据的时候还好,选中状态都是正常的,但是修改就遇到问题,需要对这个已经选择过的数据加上默认的选中状态,本次就是解决…...

境外网站翻译之自由职业
Polls Do you use AI tools (e.g ChatGPT, Midjourney, Github Copilot) as part of your work? 你在工作中会使用人工智能工具(如 ChatGPT、Midjourney、Github Copilot)吗? Yes, as an assistant 是的,作为一种辅助工具。 Y…...

批量图片转PDF文件的多种方法详解
要将批量图片转换为PDF文件,可以使用多种方法,包括使用在线工具、桌面应用程序或编程语言。以下是几种常见的方法: 方法一:使用在线工具 选择工具:搜索“图片转PDF”在线工具,如 Smallpdf、ILovePDF 等。…...

Web服务器(理论)
目录 Web服务器www简介常见Web服务程序介绍:服务器主机主要数据浏览器 网址及HTTP简介URLhttp请求方法:2.3 HTTP协议请求的工作流程: www服务器的类型静态网站动态网站 快速安装Apache安装准备工作httpd所需目录主配置文件 nignx安装1、安装2、准备工作 …...
=>(,);()的作用:明确表达式的边界。)
js:()=>(,);()的作用:明确表达式的边界。
()>{表达式1;表达式2;表达式3;... return 结果} 等同于 ()>(表达式1,表达式2,表达式3,... 结果) 例子: const strarr [a, b, c];const result strarr.reduce((acc, curr) > {(acc[curr] 1);console.lo…...

RSI 5G通信技术中用于标识小区的特定参数
RSI是指在5G通信技术中用于标识小区的特定参数,全称为Radio Subframe Indicator(无线子帧指示符)。在原文的上下文中,RSI被用来确保相邻小区间有足够的间隔,避免由于RSI冲突导致用户设备(UE)随机…...

JavaScript中的闭包、递归问题
一、函数定义和调用 1.函数的定义方式 方式一 函数声明方式 function 关键字(命名函数) function fn(){}方式二 函数表达式(匿名函数) var fn function(){}方式三 new Function() var f new Function(a,b,console.log(a b););//语法 var fn new Fu…...

【青牛科技】GC4938替代A4938/Allegro在水泵、筋膜枪、吸尘器和电动工具中的应用
随着技术的不断进步,电机驱动控制器在各类电动设备中的应用越来越广泛。GC4938作为一种新型的电机驱动控制器,逐渐被视为A4938/Allegro的替代品。在这篇文章中,我们将探讨GC4938在水泵、筋膜枪、吸尘器和电动工具等设备中的应用优势和特点。 …...

极简黑魔法:用 gh gist 搭建我们的私有配置分发 CDN
在多端协作的时代,我们经常需要在 PC、手机和路由器之间同步一些私密的订阅配置(如应用服务配置文件,凭据等)。 如果使用公共 Gist 会有隐私泄露风险;维护一个私有 Git 仓库又需要处理复杂的 API Token 鉴权࿰…...

LVGL容器控件Contain的10种布局模式全解析:从入门到实战避坑指南
LVGL容器控件Contain的10种布局模式全解析:从入门到实战避坑指南 在嵌入式GUI开发中,如何高效管理界面元素的排列一直是开发者面临的挑战。LVGL作为轻量级通用图形库,其容器控件(Contain)通过10种布局模式提供了灵活的解决方案。本文将带您深…...

技能管理框架skill-mix:用YAML与声明式配置构建可量化技能体系
1. 项目概述与核心价值最近在梳理团队的知识库和技能树时,我又一次深刻体会到,一个清晰、可量化、可追踪的技能管理体系对个人成长和团队效能有多重要。无论是作为技术负责人评估团队战斗力,还是作为一线开发者规划自己的学习路径,…...

SQL如何提取分组中的第一条记录_使用ROW_NUMBER定位数据
ROW_NUMBER() 是最稳的分组取首行解法,需在子查询或CTE中按PARTITION BY分组、ORDER BY排序,外层筛选rn1;GROUP BY配MIN(id)易导致数据错乱,且无ORDER BY时顺序不保证;须建联合索引覆盖分组与排序字段,并注…...

Visual C++运行库终极解决方案:一站式修复所有Windows程序依赖问题
Visual C运行库终极解决方案:一站式修复所有Windows程序依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否经常遇到"缺少msvcp140.…...

Mac用户必看:彻底解决NTFS读写难题的终极免费方案
Mac用户必看:彻底解决NTFS读写难题的终极免费方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NT…...

LangChain-Rust:用系统级语言重构大语言模型应用框架
1. 项目概述:当LangChain遇上Rust,会擦出怎样的火花?如果你和我一样,既是LangChain生态的深度用户,又对Rust语言的高性能与安全性念念不忘,那么看到“Abraxas-365/langchain-rust”这个项目标题时ÿ…...

凌壹科技ZO-3965U-6C2L嵌入式主板深度拆解:硬件解析与工业应用实战
1. 项目概述:一块嵌入式主板的深度拆解最近在整理手头的工控项目资料,翻出了一块来自凌壹科技的ZO-3965U-6C2L嵌入式主板。这块板子之前在一个边缘计算网关项目里服役了两年多,一直稳定可靠。趁着这个机会,我决定把它从机箱里拆出…...

[GESP202512 C++ 三级] 判断题第 3 题 ← strcmp
【题目描述】 strcmp(str1, str2) 返回 0 表示 str1 大于 str2 ,返回正数表示两者相等。(❌️)【题目解析】 返回 0 → 两个字符串完全相等。 返回正数 → str1 > str2。 返回负数 → str1 < str2。...

FreeRTOS任务通知:轻量级任务通信机制的原理与应用实践
1. 项目概述:从“消息队列”到“任务通知”的思维跃迁在嵌入式实时操作系统(RTOS)的开发中,任务间的通信与同步是核心议题。我们习惯了使用队列(Queue)、信号量(Semaphore)、事件组&…...