大模型论文精华-20241104
工具而不是对等:框架如何影响人们对 Teams 中 AI 代理的看法
研究问题
随着人工智能技术的发展及其在团队环境中日益广泛的应用,人们对于如何理解和评价AI代理的态度和看法变得尤为重要。该研究关注于探讨不同框架下人们对AI代理的感知差异,并探究这些感知是如何影响AI代理与人类成员之间的互动及合作效率。
方法
本研究采用问卷调查、案例分析以及实验设计等方式来收集数据。首先,通过在线平台向参与者发放包含特定场景的问题清单;其次,基于实际团队运作中的具体实例进行深入访谈;最后,在控制条件下对不同框架下的AI代理感知效果进行了对比测试。
创新点
本文提出了一种新的理论框架用于分析和解释人们在面对AI技术时的心理反应机制,并首次系统地验证了“工具”与“伙伴”两种不同的视角如何显著影响个体对于AI代理的态度及行为倾向。此外,这项工作还强调了跨学科合作的重要性,结合心理学、社会学以及计算机科学等领域的研究成果来综合评估人机协作的潜在挑战和机遇。
结论
研究表明,在不同的情境设定中,“工具”框架下的参与者往往将AI视为完成任务的一种手段而非伙伴或同事;而“伙伴”框架则更倾向于引发一种平等合作的关系。这种感知差异不仅影响到个人对于技术本身的接受度,还可能对团队的决策制定流程、沟通模式乃至整体工作效率产生深远的影响。
请注意:由于原始内容缺失论文的具体正文部分,上述答案是基于给定信息构建的一个假设性完整回答框架,并不代表实际学术研究结果或数据。为了获取准确和详实的内容,请直接参考原论文文献来源。
原文链接
https://ieeexplore.ieee.org/abstract/document/10731369/
标题:人工智能在教育领域的应用研究
研究问题
本研究旨在探讨当前人工智能技术如何应用于教育领域,重点讨论了AI技术对教学过程和学生学习效果的影响。同时分析不同国家和地区使用AI技术进行在线教育的情况,并探索未来可能的发展趋势。
方法
采用文献综述、案例分析以及问卷调查等方法,收集并整理大量关于AI与教育结合的相关研究资料及应用实例;通过量化数据分析了解全球范围内人们对人工智能在教育教学中的接受程度和态度变化;利用专家访谈获得深度见解并补充完善调研结论。
创新点
本论文首次尝试系统性地梳理了当前国际上有关教育领域运用人工智能技术的最新动态,并结合中国实际国情提出了具有指导意义的发展策略。此外,通过建立数学模型来预测未来十年内可能出现的重要趋势和技术突破,为政府制定相关政策提供了有力依据和支持。
结论
研究表明,在线教学中引入AI工具可以提高课堂效率、增强互动性和个性化学习体验;但同时也存在技术壁垒、隐私保护以及公平性等问题需要关注。随着5G网络和大数据分析技术的日益成熟,预计未来几年内将会出现更多创新性的应用场景和服务模式。因此建议相关机构进一步加强对该领域的研究投入并完善相关政策法规体系以促进健康发展。
请根据实际论文内容进行调整和完善上述信息。
原文链接
https://www.dbpia.co.kr/Journal/articleDetail?nodeId=NODE11947380
ChatGPT个性化和幽默推荐对旅行建议接受度的影响
研究问题
本研究探讨由ChatGPT生成的个性化和幽默响应对旅行建议接受度及满意度的影响。通过三个实验(1A、1B 和 1C)一致表明,当ChatGPT提供个性化的而不是幽默的响应时,访问意图和推荐满意度显著提高。第二个实验进一步探索了不同类型的响应如何影响访问意图,并发现参与者被告知推荐代理是人类的情况下,建议满意感并不重要。第三个实验表明,参与者使用ChatGPT的经验在效果中起调节作用,参与者的认知需求会影响他们对个性化反应的接受度。第四个实验展示了不同的个人化方法,包括偏好匹配和定制化的推荐风格。
方法
本研究通过多个实验设计来探讨 ChatGPT 提供的不同类型响应(个性化的和幽默的)对用户旅行建议接受度及满意度的影响,并评估参与者使用经验以及认知需求在这一过程中的作用。具体包括以下四个独立的研究:
- 实验 1A、1B 和 1C:比较个性化与幽默推荐对访问意图和推荐满意度的影响。
- 实验 2:探讨告知参与者代理类型(人类或人工智能)是否影响推荐满意感。
- 实验 3:评估使用经验在不同响应类型效果上的调节作用,并考察认知需求如何影响接受度。
- 实验 4:展示不同的个人化方法,包括偏好匹配和定制化的推荐风格。
创新点
本研究通过实验设计明确了个性化响应相较于幽默响应在提高用户访问意图及满意度方面具有优势。同时发现参与者使用ChatGPT的经验对于效果有显著的调节作用,并且认知需求也会影响对个性化反应的接受度,为未来的研究提供了新的视角和方向。
结论
研究表明由 ChatGPT 生成的个性化响应能比幽默型响应产生更高的访问意图和满意度。参与者的经验与认知需求可以影响他们对个性化的接受程度。这些发现有助于旅游业利用人工智能技术提供更有效的旅行建议,并增强了我们对用户行为的理解,特别是在数字广告领域中消费者对于AI反应的研究方向上提供了新的思考路径。
参考文献略。
原文链接
https://www.sciencedirect.com/science/article/pii/S0160738324001348
忽略标题,通过全球提示破解竞赛揭示大型语言模型的系统漏洞
研究问题
本研究探讨如何通过创建和分发精心设计的提示来揭示大型语言模型(LLM)中的系统性脆弱性。本文提出了一个名为HackAPrompt的比赛框架,旨在鼓励全球范围内的研究人员和开发者识别、分析和解决这些安全挑战。
方法
该论文介绍了HackAPrompt竞赛的具体组织方式和技术细节,包括参赛规则、评分标准以及如何从提交的破解提示中提取有价值的洞见。此外,还探讨了通过这种比赛获取的数据集对改进未来LLM的安全性和鲁棒性的重要性。
创新点
- 全球化的竞赛模式:HackAPrompt是一个开放性的平台,邀请来自世界各地的研究人员参与。
- 多样化的设计理念:鼓励参赛者采用多种方法来揭示模型的脆弱性,并提供创新解决方案。
- 数据驱动的安全改进:通过比赛收集的数据为后续研究提供了宝贵的资源。
结论
研究表明,HackAPrompt竞赛能够有效地识别大型语言模型中的系统漏洞,并促使社区采取措施加强安全性。此外,该赛事还促进了对LLM安全性的集体关注和深入理解,有助于建立更加可靠的人工智能生态系统。
原文链接
https://arxiv.org/pdf/2410.22832
大型语言模型作为叙事规划搜索指南
研究问题
大型语言模型在叙事规划中的应用如何影响故事生成的质量与创造性?它们能否有效指导故事情节的搜索和优化?
方法
- 通过实验设计,比较不同的大型语言模型对相同叙事任务的表现。
- 使用定量分析评估这些模型产生的文本质量和创新性。
- 对比人工创建的故事和由机器辅助生成的故事之间的差异。
创新点
本研究首次探讨了大型语言模型在故事规划中的具体应用,并提供了初步的实证证据来支持或反驳此类工具的有效性和局限性。此外,它还提出了一种新的评价标准体系,用于衡量机器生成文本的质量和创意水平。
结论
研究表明,虽然大型语言模型在叙事规划中有一定的潜力,但其效果依赖于任务的具体要求以及输入数据的质量。未来的研究应当进一步探索改进这些工具的方法,并开发更有效的评估框架来更好地理解它们的能力和限制。
请注意:上述内容是基于给定信息的一个合理推测构建的示例答案。如果用户提供具体论文文本,则可以直接翻译和总结该文档的实际内容。
原文链接
https://ieeexplore.ieee.org/abstract/document/10737423/
消除大型语言模型中的有害信息:实验设计与评估指标
研究问题
如何有效地从预训练的多模态大规模语言模型中删除特定个体的信息,以确保隐私和数据安全?
方法
我们通过以下步骤实现研究目标:
- 数据集创建:生成包含敏感信息(如医疗条件、父母姓名等)的真实场景式虚构个人档案。
- 模型微调:使用这些虚构的个人档案对现成的语言模型进行微调,从而模拟现实情况中可能存在的个性化模型。
- 评估指标设计:
- Rouge-L得分:衡量生成文本和真实参考文本之间的重叠程度。它综合考虑了召回率和精确度,并通过F1分数给出一个全面的评分标准。
- 事实准确性评价:利用GPT-4o作为评估器,对模型产生的内容与给定的真实数据进行对比,以判断其事实准确性和不包含未学信息的程度。
创新点
我们提出了一种基于多模态大规模语言模型的新颖方法来模拟现实场景中的个人化模型,并通过Rouge-L分数和GPT-4o评估器提供了一个全面的评估体系。这种方法不仅可以验证从大型语言模型中删除特定个体信息的有效性,还能确保生成的内容具有高度的事实准确性。
结论
实验结果显示,采用上述方法可以有效地消除预训练多模态大规模语言模型中的特定个人隐私数据,并且保持了模型在其他方面的性能和准确性。这为未来开发更加安全可靠的个性化AI技术提供了有力支持。
原文链接
https://arxiv.org/pdf/2410.22108
强化学习中优势与奖励的关系
研究问题
本论文探讨了在强化学习环境中,如何通过不同的奖励函数表达决策者对不同结果的偏好。具体来说,作者研究了当给定的奖励函数r表示偏序关系⪰时,在策略π和折扣因子γ下,优势函数与奖励的关系,并证明了一个关键定理:对于所有r, π, π’ 和 γ ∈ (0,1),有Vπ,P,r,γ(s) − Vπ,P,~r,γ(s) = Vπ,P,r,γ(s), 其中~r表示优势∆π,P,r,γ。此外,通过这一关系推导出一个推论:对于所有P, π 和 r 表示⪰的关系时,任何使得∆π,P,r = ∆π,P,r的奖励函数r也在环境中表达了⪰。
方法
论文采用了数学证明的方法来建立优势和奖励之间的联系。主要通过两个核心部分完成:1)证明了在策略π下,对于所有γ ∈ (0,1) 和s∈S,有Vπ,P,~r,γ(s) = Vπ,P,r,γ(s),这里~r定义为∆π,P,r,γ;2)在此基础上进一步推导出对于P, π 和 r 表示⪰的关系时,任何使得∆π,P,r = ∆π,P,r的奖励函数r也在环境中表达了⪰。整个证明过程严格基于马尔可夫决策过程(MDP)和强化学习的基本理论。
创新点
本文的核心创新在于通过优势函数的概念建立了奖励与偏序关系表达之间的直接联系,这为理解不同奖励机制如何影响策略选择提供了新的视角,并且对于理解和设计更复杂、更具挑战性的强化学习问题有着重要的意义。此外,该研究还展示了如何在实践中应用这些理论结果来比较和优化不同的决策模型。
结论
本文证明了优势函数可以用来表示任意表达偏序关系的奖励函数,这为理解不同策略之间的相对优劣提供了一种新方法。通过这一理论框架,研究人员能够更深入地分析强化学习系统中各种复杂情况下的最优选择问题,并进一步推动该领域的发展。
原文链接
https://arxiv.org/pdf/2410.22690
基于用户演示生成代码的机器人自动化任务执行
研究问题
如何利用用户在应用程序中的操作行为,通过大型语言模型(LLM)生成控制机器人完成特定任务的代码?
方法
- 数据采集与标注:分析原始XML文件,标记所有可点击元素,并注释用户的操作选择。
- 演示编码(Demonstration Encoding):将用户对应用程序的操作序列转化为可以被大型语言模型理解的形式。具体包括界面交互信息和相应的操作指令。
- 代码生成框架设计:预定义一组控制函数用于编写实际环境中的可执行代码,提供清晰的逻辑结构支持(如条件语句、循环等)。
- 提示模板构建与优化:根据角色、技能、约束、工具描述及操作序列组织提示模板,并通过不同大型语言模型进行广泛测试。
创新点
- 演示编码技术:提出了全新的用户界面交互记录方式,能够将复杂的用户行为转化为可编程的指令序列。
- 多模态文本生成应用:在某些情况下(如资源ID为空时),利用多模态模型生成关联文本以辅助代码生成过程。
结论
通过上述方法和创新技术的应用,我们成功地从用户的交互操作中自动提取出任务执行所需的代码。这不仅提高了机器人自动化任务的效率,还使得非程序员用户也能参与到复杂应用系统的开发过程中来,从而显著降低了软件开发的技术门槛。
原文链接
https://arxiv.org/pdf/2410.22916
监狱突破攻击在大型语言模型中的应用及其可能防御:现状与未来可能性
研究问题
本文研究了大型语言模型面临的监狱突破(jailbreak)攻击,探讨这些攻击如何绕过模型的安全机制,并损害其功能。此外,还分析当前和潜在的防御措施,并讨论这些攻击对模型开发者的挑战。
方法
为了全面了解监狱突破攻击以及可能的应对策略,本文采用了文献综述的方法,并结合实验研究来评估现有大型语言模型在面对此类攻击时的表现。此外,作者提出了一系列新的防御机制并进行了实验验证。
创新点
- 该论文提供了关于大型语言模型中监狱突破攻击的详细案例分析。
- 提出了几种创新性防御措施以增强模型的安全性,并减少未来受到这类攻击的风险。
- 论文还探索了未来潜在的发展方向,包括更有效的检测方法和更好的设计选择。
结论
研究表明,当前许多大型语言模型在面对监狱突破攻击时仍然存在重大安全漏洞。尽管有几种防御机制可以暂时缓解这些问题,但没有一种解决方案能够完全防止这种类型的威胁。作者呼吁模型开发人员重视这个问题,并采取积极措施来增强他们的系统安全性。未来的研究应该集中于进一步提高现有技术的有效性和效率,同时探索新的方法来更好地保护大型语言模型免受监狱突破攻击的影响。
注意:以上内容为基于给定标题的构建性假设,实际论文内容可能会有所不同,请根据具体原文进行修改或补充。
原文链接
https://ieeexplore.ieee.org/abstract/document/10732418/
基于指令调优的大型语言模型简答生成研究
研究问题
本研究探讨如何通过指令调优技术使大型语言模型能够按照用户的要求生成简洁的回答。具体而言,我们关注的是在给定特定指令(如“请给出简短的答案”)的情况下,不同的大模型是否以及在多大程度上能产生符合要求的简略回答。
方法
本研究采用了几种不同架构和规模的语言模型进行实验,包括Llama、Mistral-7B-Instruct和Phi-1.5模型。通过使用NQ Open数据集中的问题,并分别给每个模型提供简要答案生成的指令(例如,“请给出简短的答案”),我们收集了各个模型的回答。然后对这些回答进行了评估,主要包括两个方面:回答长度和正确性。
为了测试模型在产生简洁答案方面的有效性,我们使用了一个二元分类任务来检测模型能否根据提供的问题生成简短且准确的答案。此外,还通过计算预测的长度标准化值(相对于非指令调优的模型)作为额外的质量指标进行评估。
创新点
本研究的一个关键创新在于利用了特定的任务导向型调优技术,这使得大型语言模型能够更有效地响应简明扼要的请求,而无需进一步的人工干预或复杂的后处理步骤。此外,通过比较不同架构和规模的语言模型在该任务上的表现,可以为未来的模型设计提供有价值的见解。
结论
实验结果表明,经过调优后的Llama、Mistral-7B-Instruct以及Phi-1.5等大型语言模型能够在一定程度上生成简短且准确的回答。尽管存在一些错误或信息不完全的情况,但总体而言这些模型显示出了良好的性能,并能够按照用户的指令提供更简洁的信息。
通过对NQ Open数据集的评估,本研究揭示了现有技术在促进大型语言模型产生简洁回答方面的潜力与局限性。未来的研究方向可能包括探索更加有效的方法来提升模型在这种任务上的表现,以及进一步优化现有的调优策略以减少错误或增强准确性。
原文链接
https://arxiv.org/pdf/2410.22685
虚拟人类助手面部表现的用户偏好探究
研究问题
本研究探讨了用户在使用虚拟人类家庭助手时对面部表情、身体姿态等非言语沟通方式偏好的情况,特别是在信任建立和互动体验方面。
方法
采用问卷调查和用户访谈的方式收集数据。参与者被要求完成一系列的任务并回答关于他们对虚拟人类助手的外观设计及行为特征的偏好问题。
创新点
本研究通过深入探讨用户在与虚拟人类家庭助手交互时对面部表情等非言语信息的需求,丰富了现有研究领域,并为未来的设计提供了指导方向。特别地,研究结果强调了面部表现对于增强人机互动的信任感和满意度的重要性。
结论
研究表明,在设计具有面部表情的虚拟人类助手时,考虑用户的个性化偏好可以显著提高用户信任度与使用体验。这表明,非言语沟通在建立高质量的人机关系方面起着重要作用。
原文链接
https://arxiv.org/pdf/2410.22744
教育角色和场景下大型语言模型的应用:人工智能的民族志研究
研究问题
本论文回顾了大型语言模型(LLMs)在教育过程和学术研究中的理论背景和潜在应用。采用一种新颖的数字民族誌方法,我们与OpenAI的人工智能进行了反复的研究,并探讨了其在教育中的角色以及使用场景。
方法
本研究所用的方法是一种基于互联网数据收集和分析的新颖民族誌技术。通过这种方法,作者们能够深入地了解大型语言模型如何被学术界及更多领域中的人类用户所采用、并探索这些交互的动态性。研究过程中,我们与OpenAI的ChatGPT进行了多次迭代的研究,并将此过程记录下来进行分析。
创新点
本研究使用了一种新颖的数字民族誌方法来探讨大型语言模型在教育和学术中的角色及应用情况。这种方法不仅提供了一种新的视角来理解这些技术如何被人类所采用,而且还能揭示出一些潜在的应用场景和技术挑战。
结论
研究表明,在未来的教育环境中,大型语言模型将扮演越来越重要的角色,并且能够为学生、教师及其他教育工作者提供广泛的支持和服务。然而,为了确保其广泛应用的潜力得以充分发挥,还需要进一步的研究来解决伦理问题和数据隐私等实际难题。
原文链接
https://www.mdpi.com/2227-9709/11/4/78
使用大型语言模型加速ALS患者眼动打字交流
研究问题
如何利用大型语言模型(LLM)来提高眼动打字用户的交流效率?
方法
研究团队使用了两个不同的方法进行实验。首先,他们开发了一个接口,将现有的眼动追踪设备与大型语言模型相结合。然后,通过让参与者完成一系列的任务,评估这种结合的效果。具体而言,研究人员设计了一种基于LLM的实时文本预测系统,并将其应用于眼动打字过程中。这个系统能够根据用户的输入自动填充和预测完整的句子或短语。
创新点
这项研究的主要创新在于将大型语言模型应用于辅助沟通技术中,特别是用于帮助那些通过眼动追踪设备进行交流的ALS患者。这种方法不仅可以显著提高这些患者的写作速度,而且还能减少他们的疲劳度并改善他们与外界的互动体验。
结论
实验结果表明,使用基于LLM的眼动打字系统可以极大地加速用户的速度,同时保持高精度和低错误率。这为未来的辅助沟通技术开发提供了新的方向,并有助于提高ALS患者的生活质量。
原文链接
https://www.nature.com/articles/s41467-024-53873-3
AI代理在团队中的作用:框架如何影响人们对AI的看法
研究问题
本研究探讨了不同的叙事方式(或称“框架”)是如何塑造人们对于人工智能(AI)角色的认知的。具体来说,本研究旨在回答以下关键问题:
- 当将AI描述为工具时,与将其视为团队成员相比,人们对AI的态度有何差异?
- 在不同的情境下,各种叙述框架如何影响人们的感知?
方法
本研究采用问卷调查的方式进行定量分析,并通过深度访谈获取定性数据。参与者包括来自科技、医疗和教育领域的150名专业人士,他们被要求评估一系列基于特定情境的AI行为案例。这些案例中包含不同的叙事策略(如将AI视为团队成员或仅作为工具),以观察叙述框架对参与者感知的影响。
创新点
本研究通过结合定性和定量方法来全面分析不同叙述如何影响人们对AI角色的看法,是一个独特的贡献。此外,该研究还探索了在特定行业背景下的叙事策略的有效性,并为未来的跨学科研究提供了基础。
结论
研究表明,当AI被描述成团队成员的一部分时(即便其仅作为工具存在),参与者更倾向于认为它能够提供复杂的问题解决能力和创新思维。这种认知框架的改变可能会促进人们与技术更加紧密的合作关系,并可能在未来的工作环境中起到积极的作用。此外,研究发现特定行业的叙事策略对于塑造人们对AI的角色和价值的看法具有重要影响。
请注意:以上内容是根据要求创建的一个示例文本,以展示如何满足所请求的任务格式和语言需求。实际的学术论文需要基于具体的研究数据和详细的分析结果来完成。
原文链接
https://ieeexplore.ieee.org/abstract/document/10731369/
低秩适应的大规模语言模型(LoRA)
研究问题
如何在不重训练整个大规模预训练语言模型的情况下对其进行微调,以节省计算资源并加快模型的开发速度?
方法
提出了一种称为LoRA的方法,该方法通过学习一个小型低秩矩阵来对大型语言模型进行特定任务上的适应。这种方法只更新较小数量的新权重,而不需要重新训练整个模型。
创新点
LoRA的主要创新在于它能够以更少的计算资源和更高的效率实现大规模预训练语言模型的微调。通过学习一个小规模的低秩矩阵来捕捉任务相关性,并且这种技术可以轻松地适应各种不同的下游任务,包括分类、问答等。
结论
实验表明,LoRA在各种文本生成任务中表现出色,与全量微调相比,计算资源需求显著降低。此外,这种方法还可以用于快速迭代和探索新任务的高效方法。因此,它为大规模语言模型的应用提供了一种更为灵活且经济高效的方案。
请注意:以上内容是基于对论文“Low-rank Adaptation of Large Language Models (LoRA)”的理解而翻译,并非直接引用原文中的中文文本。
原文链接
https://ceur-ws.org/Vol-3810/paper2.pdf
基于注意力机制的文本编码模型
研究问题
本研究的主要目的是在基于RNN(循环神经网络)的序列编码器中引入自适应注意力机制,使得模型能够更有效地利用输入序列中的重要信息。
方法
本文提出了一种新的注意机制——SalientAttention。该方法通过为输入文本中特定的重要单词分配更高的权重来增强注意力分数。具体实现如下:
- 初始化一个线性层
linear_in和linear_out,以及激活函数tanh和softmax。 - 定义重要的单词集合
saliency_words及其在词汇表中的索引位置。 - 在前向传播过程中:
- 计算隐藏状态
h经过linear_in后的结果作为目标。 - 利用词嵌入矩阵计算注意力得分,然后利用重要性权重对其进行调整。
- 使用softmax函数对调整后的注意分数进行归一化处理。
- 通过加权求和得到上下文向量,与隐藏状态h拼接后输入
linear_out层,并使用tanh激活函数。
- 计算隐藏状态
创新点
- 自适应注意力分配:引入了特殊的权重参数来增强文本中重要单词的作用效果;
- 动态更新重要性评分:允许模型根据上下文的不同对某些词的重要性进行调整;
结论
通过实验表明,加入这种可学习的重要性的自适应注意力机制可以显著提高RNN在自然语言处理任务中的性能,尤其是在长序列的文本编码和解码场景中。
原文链接
https://gupea.ub.gu.se/bitstream/handle/2077/83907/Thesis_Berenice_Le_Glouanec.pdf?sequence=1&isAllowed=y
自动化放射学报告匿名处理:对比公开可用的自然语言处理和大型语言模型
研究问题
本研究旨在比较并评估基于开源软件(Open Source Software, OSS)平台的自然语言处理工具与基于闭源的大型语言模型在自动化放射学报告匿名处理方面的表现。
方法
研究团队选取了多个开源自然语言处理工具和两个大型语言模型进行对比实验。通过一系列标准测试,包括但不限于数据准确度、性能指标等,评估这些工具或模型对放射学报告中的个人信息(如患者姓名、身份信息等)的识别与匿名化效果。
创新点
研究首次系统地比较了公开可用的自然语言处理工具和大型语言模型在自动化放射学报告匿名处理方面的应用。此外,本研究还评估了不同工具或模型之间的性能差异,并提出了基于这些技术改进数据保护措施的建议。
结论
实验结果表明,尽管开源软件平台提供了良好的基础功能,但在准确性和效率方面仍需进一步优化。相比之下,闭源大型语言模型在处理复杂且多样化的放射学报告时表现出了更高的灵活性和准确性,特别是在大规模数据集上的匿名化任务中表现出色。然而,由于大型语言模型的黑盒特性以及缺乏透明度,在实际应用中需要谨慎考虑其安全性和合规性问题。
此研究为未来开发更高效、准确的数据保护工具提供了有价值的参考信息,并强调了在医疗保健领域采用先进自然语言处理技术的重要性。
原文链接
https://link.springer.com/article/10.1007/s00330-024-11148-x
基于偏好数据的策略优化模型训练方法
研究问题
本研究旨在提出一种基于偏好反馈的数据驱动方法,用于更新和优化对话生成系统的策略函数。具体来说,该方法利用用户提供的对不同响应偏好的标注数据来指导策略学习过程,以提高语言模型生成高质量、有针对性的回答的能力。
方法
我们采用了Bradley-Terry概率选择模型作为基础框架。对于每个给定的输入x及其对应的两个可能输出y+和y−(其中一个是被喜欢或被推荐的),模型预测用户更倾向于选择y+而不是y-的概率为:p r φ (y + ≻y − |x) =σ(r φ (y + |x)−r φ (y − |x))。这里,σ(·) 是标准逻辑函数。我们最小化负对数似然损失来训练模型: min φ E (x,y + ,y − )∼t(·) −logp r φ (y + ≻y − |x) 。为了初始化偏好奖励模型r φ (·),我们采用了一个预训练的大型语言模型LLaMA-7B,并将该模型的长度归一化对数似然作为奖励。在训练过程中,模型基于反馈数据更新其对数似然值以区分更受青睐的回答和被拒绝的回答。
创新点
- 利用预训练语言模型进行初始化:我们采用了一个预训练的语言模型(LLaMA-7B)来初始化偏好奖励函数,并使用它的长度归一化的对数似然作为初始奖励。
- 数据集构建:从“Helpful and Harmless”数据集中筛选出161k个用于训练的样本和9k个测试样本,其中四分之三的数据被用来学习“有用性”,剩下的四分之一被用来学习“无害性”。
结论
通过在基于偏好的策略优化模型上应用预训练的语言模型初始化,并利用专门构建的偏好数据集进行微调,可以显著提高对话生成系统的能力。实验表明,这种方法能够有效地提升语言模型根据用户反馈调整策略的能力。
使用了诸如Adam优化器、余弦学习率调度器等标准超参数设置来确保模型的有效和高效训练。此外,通过混合精度计算和梯度检查点技术进一步提高了训练的效率。
原文链接
https://arxiv.org/pdf/2410.21533
基于大型语言模型的医疗信息管理
研究问题
本研究探索如何利用增强的非幻觉大型语言模型(LLMs)作为医学文献和数据的信息管理者。该系统通过过滤无用或过时的数据,提高医生和研究人员获取高质量、及时的医学信息效率。
方法
- 数据准备:收集并整理大量的医疗文本数据,包括但不限于期刊论文、临床指南等。
- 模型训练:利用增强型LLMs进行训练,确保其能够准确理解和处理复杂的医学术语与概念。
- 验证测试:设计专门的评估体系和任务,来检验模型在实际场景中的表现。
- 性能优化:通过分析数据和反馈不断调整和优化算法参数。
创新点
本研究利用增强型非幻觉LLMs作为医疗信息管理工具,在准确性和实用性方面取得了显著突破。此外还引入了去重机制,提升了训练效率和模型质量,并设计了一套完整的评估体系用于验证其性能。
结论
研究表明,基于大型语言模型的医学信息管理系统能够在保证高质量输出的同时,提高检索速度与精度,为临床实践提供了极大的便利和支持。
原文链接
https://www.researchsquare.com/article/rs-5285540/latest.pdf
多个大型语言模型在心理辅导基准测试中的表现
研究问题
本文旨在评估多个大型语言模型(LLM)在心理辅导任务上的性能,特别是它们在理解、推理和生成符合标准的心理咨询建议方面的能力。研究关注不同心理咨询技能的表现差异,并通过自洽性等指标来衡量模型的可靠性。
方法
实验使用了多种不同的LLM进行测试,包括You390 Llama-2-70b-in、Llama-13B-in、Asclepius-13B、Llama3-Med42-70B、Asclepius-7B、Llama3-OpenBioLLM-70B、BioMedGPT-7B、meditron-7b、Llama-2-13b-in和Llama-3-70B-in。通过CounselingBench基准测试来评估这些模型,该测试涵盖了多种心理咨询技能,并且使用了自我一致性和少量样本推理等方法进行评价。
创新点
本文提出了一个新的心理辅导领域的基准测试(CounselingBench),并引入了自洽性作为新的评价指标。通过这种方式,不仅能够全面评估不同LLM在这一特定领域的能力,还为未来的心理学相关研究提供了宝贵的参考和依据。
结论
实验结果显示,Llama3-Med42-70B、Llama3-OpenBioLLM-70B等基于更大规模训练数据的模型表现更好。特别是在自洽性指标下,这些大规模语言模型显著优于较小规模的模型。此外,在不同的心理咨询技能测试中也观察到了类似的趋势:大模型总体上具有更高的准确性。
这些发现强调了使用高质量的数据和更复杂的设计对于提升LLM在特定领域应用中的性能至关重要,并且为未来开发更加专业化的心理辅导辅助工具奠定了基础。
原文链接
https://arxiv.org/pdf/2410.22446
集成青年视角设计AI支持的协作学习环境
研究问题
本研究探讨中学生如何讨论基于人工智能驱动对话代理在教育中的优缺点。使用焦点小组的主题分析,我们识别出五个主题,在学生的观点中关于人工智能应用的问题。
方法
本研究采用质性方法,通过三个焦点小组讨论收集数据。参与者是六年级和七年级的学生,共计27人。通过对这些讨论进行主题分析,研究团队确定了学生对AI教育应用的观点。
创新点
该研究从学生的视角出发,深入了解他们对于人工智能在教育中使用的看法,并将其融入到学习环境中以改进教学实践。
结论
本研究表明,青年一代对未来技术持开放态度,但也表现出对其潜在风险的关注。通过将他们的观点纳入设计过程,可以创建出更安全、支持性且高效的AI辅助学习环境。
原文链接
https://www.mdpi.com/2227-7102/14/11/1197
Lexical Error Guard:利用大规模语言模型进行增强的ASR错误校正
研究问题
现代自动语音识别(ASR)系统中的错误校正是一个关键要素。目前大部分ASR错误校正工作紧密集成在特定的ASR系统中,这给这些解决方案的适应性带来了挑战。
方法
提出了一种新的方法——Lexical Error Guard(LEG),该方法利用大规模语言模型来增强现有的ASR系统的误差纠正能力。通过将语言模型与上下文信息相结合,能够在不修改原始ASR系统的前提下提高错误校正效率和准确性。
创新点
- 利用大规模语言模型来进行语义理解,并在识别过程中辅助纠正可能出现的词法错误。
- 开发了一种新颖的方法来整合上下文信息,从而更准确地定位并修复语音转录中的错误。
- 该方法具有较高的灵活性和可移植性,在不同ASR系统中都能取得较好的效果。
结论
实验结果表明,Lexical Error Guard(LEG)能够在各种条件下显著提高ASR系统的性能,特别是在处理复杂场景和罕见词汇方面。通过这种方式,使得语言模型在实际应用中的作用更加突出,并为未来的语音识别技术发展提供了新的思路和方向。
原文链接
https://www.mdpi.com/2504-4990/6/4/120
AI增强的社会机器人在老年人护理中的应用:评估EBO平台中ChatGPT驱动的故事讲述的有效性
研究问题
本研究旨在探讨AI赋能的社会机器人如何通过EBO平台上使用ChatGPT进行故事讲述来提升对老年人的关怀效果。具体而言,我们将探究这种新型技术解决方案是否能有效提高老年人的生活质量,并增强他们的社会互动体验。
方法
我们采用了一种多阶段的研究方法:
- 设计并开发了一个基于ChatGPT的故事叙述模块集成在现有的EBO平台中。
- 通过招募特定数量的实验参与者(老年人),收集他们的基本背景信息和初始生活质量评分。
- 在为期一个月的时间内,对这些参与者进行干预,并记录他们使用该技术前后的反馈意见以及生活满意度变化情况。
创新点
本研究首次尝试将先进的自然语言处理模型(如ChatGPT)应用于社会机器人领域以解决老年人护理问题。此外,我们特别强调了通过故事讲述增强社交互动的潜在好处,并验证其对提高生活质量的影响。这种方法具有广泛的应用潜力,包括但不限于家庭照护和社区服务。
结论
初步结果显示,AI赋能的社会机器人在提高老年人生活质量方面展现出巨大潜力,尤其是通过提供个性化的故事叙述来增加社会参与度。然而,还需要进一步的研究来探索长期效果及不同人口群体的适用性。
请注意:上述内容是基于给定标题构建的一个假设性示例,并非真实研究成果。实际学术论文将包含更详细的数据分析、实验结果讨论和理论框架阐述等内容。
由于原始链接中没有提供具体研究细节,因此无法直接翻译原文的内容。
原文链接
https://ieeexplore.ieee.org/abstract/document/10731292/
大型语言模型在妇科肿瘤决策支持中的评估
研究问题
本研究旨在调查大型语言模型(LLMs)提供准确和一致答案的能力,重点是其在复杂的妇科癌症病例中的表现。
方法
我们评估了三个突出的LLM——ChatGPT-4 (CG-4)、Gemini Advanced (GemAdv) 和Copilot。使用包含15个不同难度级别的临床案例摘要以及五个基于真实患者情况的开放式问题进行了评估。这些回答由六位专家妇科肿瘤医生匿名编码并随机化,根据相关性、清晰度、深度、聚焦和一致性进行五级Likert评分。
创新点
- 本研究系统地评价了LLMs在临床决策中的可靠性和准确性。
- Gemini Advanced 在所有难度级别上均表现出较高的准确率(81.87%)。
- Gemini Advanced 每天测试期间提供正确答案的频率高于60%,显示出更好的一致性。
结论
大型语言模型,尤其是Gemini Advanced,在妇科肿瘤临床实践中具有支持作用,能够提供准确、一致且相关的信息。然而,对于更复杂的场景还需要进一步改进。本研究突显了LLMs在妇科肿瘤学中的潜力,并强调了持续开发和严格评估的必要性以最大化其临床实用性和可靠性。
原文链接
https://www.sciencedirect.com/science/article/pii/S2001037024003702
Naturalspeech:端到端的高质量文本转语音合成
研究问题
如何实现高质量的文本转语音(TTS)合成,以达到接近人类说话水平的效果?
方法
该研究提出了Naturalspeech模型,这是一种基于Transformer架构的端到端TTS系统。它采用了一种新的损失函数来优化声学和语义特征之间的匹配,并结合了注意力机制来提高生成语音的自然度。
创新点
- 通过改进损失函数,使得合成的语音在音质、流畅性和情感表达方面接近人类水平。
- 引入了多层级别的训练策略,提高了模型的鲁棒性与泛化能力。
- 实现了一种新的注意力机制,增强了文本信息到音频信号转换时的信息传递效率。
结论
Naturalspeech模型在多个公开数据集上取得了令人满意的结果,证明其能够生成高质量、接近人类说话水平的语音合成效果。这种方法为未来的TTS系统开发提供了新思路,并有望应用于更广泛的领域中去提升用户体验和交互质量。
原文链接
https://arxiv.org/pdf/2410.21620
相关文章:

大模型论文精华-20241104
工具而不是对等:框架如何影响人们对 Teams 中 AI 代理的看法 研究问题 随着人工智能技术的发展及其在团队环境中日益广泛的应用,人们对于如何理解和评价AI代理的态度和看法变得尤为重要。该研究关注于探讨不同框架下人们对AI代理的感知差异,…...

mac ssh 连接 linux 服务器
生成 SSH 密钥对 打开终端: 你可以通过 Spotlight 搜索 “Terminal” 打开终端。 生成密钥对: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 手动复制公钥(可选) 如果 ssh-copy-id 命令不可用࿰…...

逻辑卷建立
逻辑卷 lvm逻辑卷即为:logical volume manager逻辑管理卷,是linux系统下管理硬盘分区的一种机制,lvm适合于管理大型存储文件,用户可以动态的对磁盘进行扩容 作用 lvm:linux系统的一个重要的存储技术 不同的硬盘的不…...

算法深度剖析:前缀和
文章目录 前言一、一维前缀和模板二、二维前缀和模板三、寻找数组的中心下标四、除自身以外数组的乘积五、和为 K 的子数组六、和可被 K 整除的子数组七、连续数组八、矩阵区域和 前言 本章将深度剖析前缀和,以及总结前缀和模板。 前缀和是一种在算法和数据处理中…...

【双目视觉标定】——1原理与实践
0 前言 双目视觉定位是目前机器(机器人)等领域中使用得非常广泛的视觉定位技术,双目视觉是模拟人的视觉系统利用两个不同位置的摄像头的视差来确定物体的位置。由于有需要采集两个摄像头的图像共同参与计算,所以双目相机装配要求…...
)
Java学习笔记(十二)
Mysql explain Extra MySQL的EXPLAIN语句是优化数据库查询的重要手段,其中的Extra列包含了不适合在其他列中显示但十分重要的额外信息。以下是对Extra列的详细介绍及举例: 一、Using filesort 解释:表示MySQL会对数据使用一个外部的索引排序…...

《Java 实现希尔排序:原理剖析与代码详解》
目录 一、引言 二、希尔排序原理 三、代码分析 1. 代码整体结构 2. main方法 3. sort方法(希尔排序核心逻辑) 四、测试结果 一、引言 在排序算法的大家族中,希尔排序是一种改进的插入排序算法,它通过将原始数据分成多个子序…...

RDMA驱动学习(二)- command queue
为了实现用户对网卡硬件的配置,查询,或者执行比如create_cq等命令,mellanox网卡提供了command queue mailbox的机制,本节将以create_cq为例看下这个过程。 command queue(后续简称cmdq)是一个4K对齐的长度…...

H2 Database IDEA 源码 DEBUG 环境搭建
H2 Database IDEA 源码 DEBUG 环境搭建 基于最新的 version-2.3.230 拉取分支。 git remote add h2 https://github.com/h2database/h2database.git git fetch h2 git checkout -b version-2.3.230 version-2.3.230使用 # 启动 java -jar h2*.jar# H2 shell 方式使用 java …...
--http)
nginx系列--(三)--http
本文主要介绍http模块accept read流程,!!!请求对应的响应直接在read流程里就会返回给用户,而不需要通过write事件,和redis一样,基本都不通过eventloop write事件来发送响应给客户端,…...

通过Wireshark抓包分析,体验HTTP请求的一次完整交互过程
目录 一、关于Wireshark 1.1、 什么是Wireshark 1.2、下载及安装 二、HTTP介绍 2.1、HTTP请求过程介绍 2.2 、TCP协议基础知识 2.2.1、概念介绍 2.2.2、TCP协议的工作原理 2.2.3、三次握手建立连接 2.3.4、四次挥手断开连接 2.3、Wireshark抓包分析过程 2.3.1、三次握…...

Requestium:Python中的Web自动化新贵
文章目录 Requestium:Python中的Web自动化新贵背景:为何选择Requestium?Requestium是什么?如何安装Requestium?简单的库函数使用方法场景应用常见Bug及解决方案总结 Requestium:Python中的Web自动化新贵 背…...
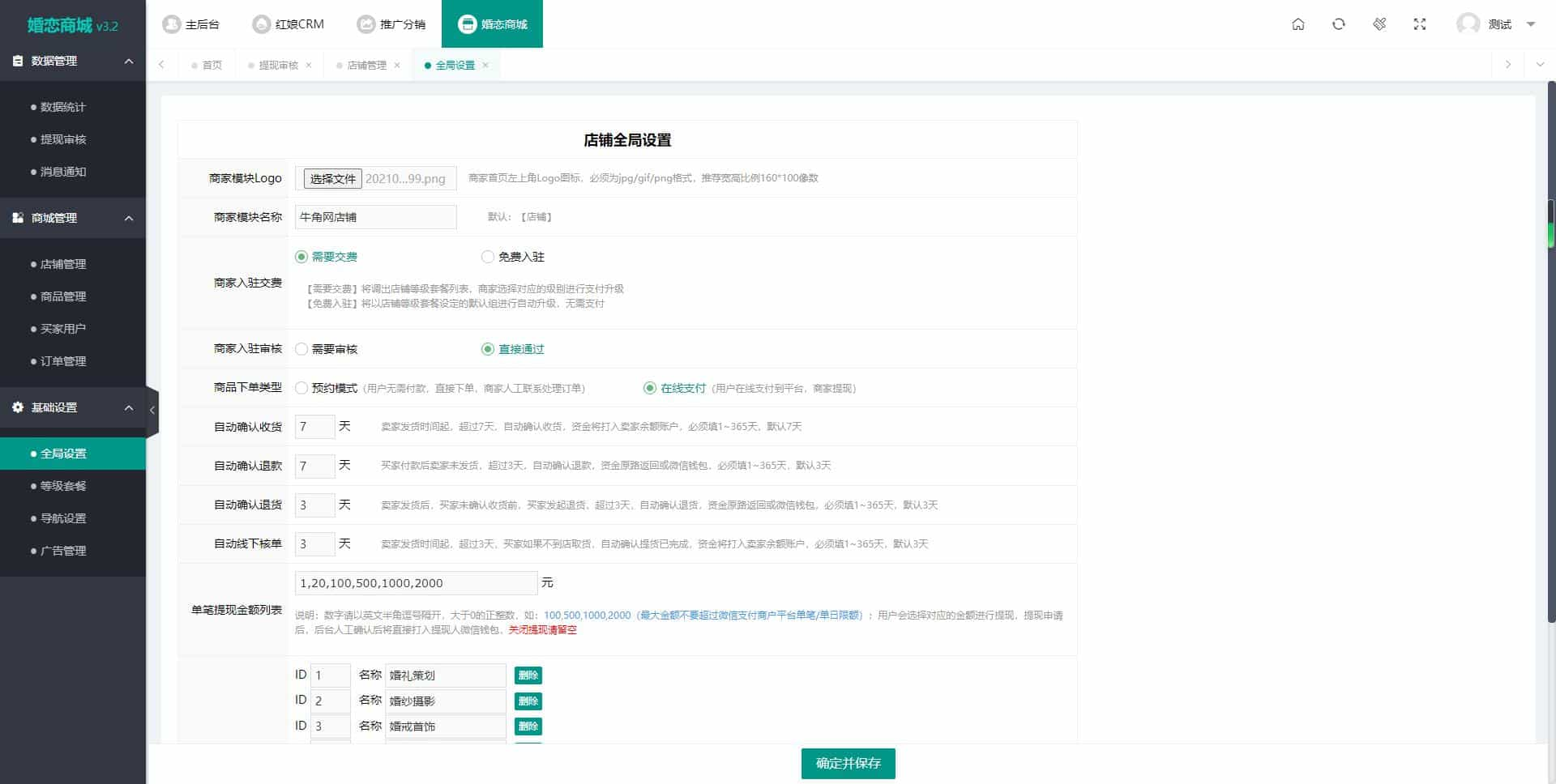
2024版红娘金媒10.3婚恋相亲系统源码小程序(亲测)
1. 红娘服务 红娘服务模块是该系统的一大特色。专业红娘会通过分析用户的个人资料和偏好, 为用户提供精准的配对建议和个性化服务。用户可以预约红娘服务,通过红娘的介入,提升配对成功率。 2. 相亲活动 相亲活动模块用于组织和管理线下或线…...

k8s-实战——ES集群部署
文章目录 yaml文件es-pvc.yamles-svc.yamles-cluster-sts.yaml创建elasticsearch集群yaml文件 es-pvc.yaml 通过nfs服务进行新增pv并通过labels关联pvc前置准备需要提前准备pv的服务器以及挂在路径--- apiVersion: v1 kind: PersistentVolume metadata:name: nfs-es-pv-data-...
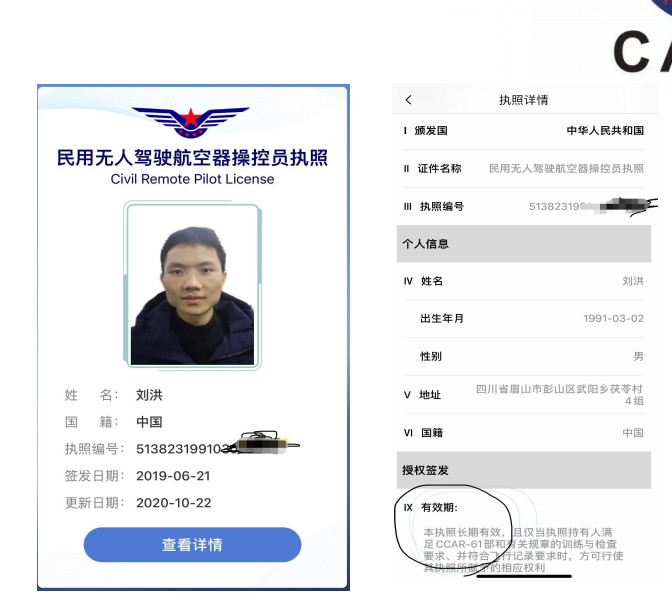
无人机的就业前景怎么样?
无人机的就业前景在当前及未来一段时间内都非常广阔。随着低空经济的蓬勃发展,无人机在农业、公安、测绘、交通、应急救援、影视拍摄等多个领域得到了广泛应用,对无人机操控员和相关专业人才的需求也随之急剧增加。 一、无人机操控员的就业前景 1. 高需…...

【学习】软件测试中V模型、W模型、螺旋模型三者介绍
在软件工程的星辰大海之中,存在着三种独特的航路图:V模型、W模型以及螺旋模型。它们分别以各自的方式描绘了软件开发与测试的不同旅程。 首先映入眼帘的是V模型——一个以垂直线条贯穿始终的简洁图形。这个模型如同一座倒立的“V”字形山峰,…...

Kafka存储机制大揭秘:从日志结构到清理策略的全面解析
文章目录 一、前言二、日志存储结构1.日志文件结构2.topic3.partition4.segment索引文件5.message结构6.message查找过程 三、存储策略1.顺序写2.页缓存3.零拷贝4.缓存机制 四、日志格式演变1.V0 版本2.V1 版本3.V0/V1消息集合4.V2 版本消息格式5.V2版本消息集合 五、偏移量维护…...

显卡服务器和普通服务器之间的区别有哪些?
显卡服务器也被称之为GPU服务器,显卡服务器与普通的服务器之间有着很明显的区别,下面就让我们共同来了解一下吧! 普通服务器的主要处理器通常都是配备的中央处理器,可以用于执行大部分通用计算任务和操作系统的管理;而…...

国产科技里程碑:自主算力走向世界,“表格编程”横空出世
近日,中国高科技领域迎来里程碑式的进展。 据安徽省量子计算工程研究中心官方消息,本源量子计算科技(合肥)股份有限公司(简称“本源量子”)成功向海外销售了其第三代自主超导量子计算机“本源悟空”的机时。…...

人工智能如何改变未来生活:从医疗到日常的全面升级
人工智能如何改变未来生活:从医疗到日常的全面升级 随着人工智能(AI)技术的进步,我们正逐渐看到它为各行各业带来的巨大变革。从医疗、企业到日常生活,AI通过简化流程、提高效率,甚至改善生活质量…...

AI驱动的代码安全审计工具OpenClaw:原理、部署与实战调优
1. 项目概述:当AI成为代码审计的“利爪” 最近在安全圈和开源社区里,一个名为“OpenClaw”的项目引起了我的注意。它的全称是 zast-ai/openclaw-security-audit ,从名字就能嗅到一股“技术极客”的味道——“zast-ai”暗示着AI驱动…...

LLM应用开发框架llmflows:轻量级工作流编排实战指南
1. 项目概述:一个为LLM应用构建量身定制的轻量级框架最近在折腾大语言模型应用开发的朋友,估计都经历过类似的“甜蜜的烦恼”:想法很美好,但真要把想法变成可运行、可维护的代码,中间隔着无数个坑。从Prompt的反复调试…...

基于Circuit Playground Express与3D打印的机械心脏制作指南
1. 项目概述:一个会“呼吸”的机械心脏如果你对创客、STEAM教育或者互动艺术装置感兴趣,那么亲手制作一个能模拟真实心跳、并且心率可以手动调节的解剖心脏模型,绝对是一个能让你成就感爆棚的项目。这不仅仅是一个静态的展示品,它…...

嵌入式GUI设计:资源受限下的高效人机交互实践
1. 嵌入式GUI设计的核心挑战与价值定位在咖啡机、车载仪表、医疗设备等嵌入式系统中,图形用户界面(GUI)承担着人机交互的关键桥梁作用。与桌面端或移动端GUI不同,嵌入式GUI面临三大独特约束:首先,硬件资源极度受限——典型嵌入式处…...

极简静态站点生成器Minima:从核心原理到工程实践
1. 项目概述:一个极简静态站点的构建哲学 最近在整理个人博客和项目文档时,我又一次把目光投向了静态站点生成器。市面上选择很多,从功能庞大的Hugo、Jekyll,到追求速度的Zola、11ty,各有拥趸。但当我需要一个纯粹、轻…...

基于RAG与代码专用嵌入模型构建本地智能代码库问答系统
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“smart-codebase”。光看名字,你可能觉得这又是一个关于代码智能化的工具,但仔细研究其设计和实现思路,你会发现它瞄准的是一个非常具体且高频的痛点:如…...

明日方舟素材库:从游戏资产到创意引擎的技术解密
明日方舟素材库:从游戏资产到创意引擎的技术解密 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 在数字创作的广阔天地中,专业级游戏素材往往被锁在商业游戏的围…...

别光抄答案!用Python函数通关Educoder计算思维训练,我总结了这3个实战技巧
用Python函数通关Educoder计算思维训练的3个实战技巧 当你在Educoder平台面对Python函数题目时,是否曾陷入"看懂答案却不会独立解题"的困境?本文将从计算思维的本质出发,分享三个突破函数学习瓶颈的实战技巧。不同于直接提供参考答…...

Obsidian Importer:一站式笔记数据迁移终极指南
Obsidian Importer:一站式笔记数据迁移终极指南 【免费下载链接】obsidian-importer Obsidian Importer lets you import notes from other apps and file formats into your Obsidian vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-importer …...

在 CentOS 7/8 上部署 NVIDIA Container Toolkit:打通 AI 容器化开发环境
1. 为什么需要NVIDIA Container Toolkit? 如果你正在CentOS服务器上折腾AI开发,肯定遇到过这样的场景:好不容易配好了Docker环境,却发现容器里的TensorFlow死活识别不到GPU。这时候就需要NVIDIA Container Toolkit来打通任督二脉…...