语言模型的采样方法
语言模型的采样方法
语言模型的输出为一个向量,该向量的每一维代表着词典中对应词的概率。
在采用自回归范式的文本生成任务中,语言模型将依次生成一组向量并将其解码为文本。将这组向量解码为文本的过程被成为语言模型解码。
解码过程显著影响着生成文本的质量。当前,两类主流的解码方法可以总结为 (1). 概率最大化方法; (2).随机采样方法。
自回归
自回归(Autoregression,简称AR)是一种统计模型,用于描述时间序列数据中各个时间点的值与其之前时间点值之间的关系。在自回归模型中,一个变量的当前值被认为是其过去值的函数,加上一个随机误差项。这种模型用于预测和分析时间序列数据。
基本概念
- 时间序列数据:指按时间顺序排列的数据点。
- 自回归模型:假设当前值 Y t Y_t Yt 是过去 p p p 个时间点值的线性组合加上一个随机误差项 ϵ t \epsilon_t ϵt。数学表达式为:
Y t = c + ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + … + ϕ p Y t − p + ϵ t Y_t = c + \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \ldots + \phi_p Y_{t-p} + \epsilon_t Yt=c+ϕ1Yt−1+ϕ2Yt−2+…+ϕpYt−p+ϵt
其中, c c c 是常数项, ϕ 1 , ϕ 2 , … , ϕ p \phi_1, \phi_2, \ldots, \phi_p ϕ1,ϕ2,…,ϕp 是模型参数, ϵ t \epsilon_t ϵt 是随机误差项。
模型类型
- AR(1):一阶自回归模型,只包含一个滞后项。
Y t = c + ϕ 1 Y t − 1 + ϵ t Y_t = c + \phi_1 Y_{t-1} + \epsilon_t Yt=c+ϕ1Yt−1+ϵt - AR§:p阶自回归模型,包含 p p p 个滞后项。
Y t = c + ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + … + ϕ p Y t − p + ϵ t Y_t = c + \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \ldots + \phi_p Y_{t-p} + \epsilon_t Yt=c+ϕ1Yt−1+ϕ2Yt−2+…+ϕpYt−p+ϵt
参数估计
自回归模型的参数通常通过最小化误差项的平方和来估计,这可以通过最大似然估计(MLE)或最小二乘法(OLS)来实现。
注意事项
- 自回归模型假设误差项是白噪声,即具有零均值和恒定方差。
- 模型的阶数 p p p 需要根据数据和问题背景来确定,过高或过低的阶数都可能导致模型拟合不佳。
自回归模型是时间序列分析中的基础工具,通过捕捉数据的自相关性,帮助我们理解和预测时间序列数据的行为。
概率最大化方法
- 目标:
- 目标是最大化生成文本 P ( w N + 1 : N + M ) P(w_{N+1}:N+M) P(wN+1:N+M) 的概率,即在给定前文的情况下,找到最有可能的后续词序列。
- 公式:
- 生成文本的概率可以表示为:
P ( w N + 1 : N + M ) = ∏ i = N N + M − 1 P ( w i + 1 ∣ w 1 : i ) = ∏ i = N N + M − 1 o i [ w i + 1 ] P(w_{N+1}:N+M) = \prod_{i=N}^{N+M-1} P(w_{i+1}|w_1:i) = \prod_{i=N}^{N+M-1} o_i[w_{i+1}] P(wN+1:N+M)=∏i=NN+M−1P(wi+1∣w1:i)=∏i=NN+M−1oi[wi+1]
- 生成文本的概率可以表示为:
贪心搜索(Greedy Search)
- 初始化:
- 从一个初始状态或初始词开始,通常是特殊的起始符号,如
<s>。
- 从一个初始状态或初始词开始,通常是特殊的起始符号,如
- 迭代选择:
- 在每一步,模型根据当前的上下文(可能是空的或之前选择的词序列)计算所有可能的下一个词的概率。
- 选择概率最大的词:
- 选择概率最高的词作为当前步骤的输出:
w i + 1 = arg max w ∈ D o i [ w ] w_{i+1} = \arg\max_{w \in D} o_i[w] wi+1=argmaxw∈Doi[w]
其中 w i + 1 w_{i+1} wi+1 是下一步的词, D D D 是词汇表, o i o_i oi 是在给定上下文下计算的输出概率分布。
- 选择概率最高的词作为当前步骤的输出:
- 更新上下文:
- 将选择的词添加到当前上下文中,并更新模型的状态。
- 重复:
- 重复步骤2-4,直到达到终止条件,如特定的结束符号
</s>或达到最大序列长度。
- 重复步骤2-4,直到达到终止条件,如特定的结束符号
- 问题:
- 贪心搜索只考虑当前步骤中概率最大的词,可能导致后续词的概率都很小,陷入局部最优。
贪心搜索的问题
- 局部最优:
- 贪心搜索在每一步都选择局部最优的词,这可能导致整个序列的全局最优解被忽略。换句话说,它可能会陷入局部最优,而不是找到全局最优解。
- 缺乏回溯:
- 贪心搜索不进行回溯,一旦选择了一个词,就会一直沿着这个选择前进,不会考虑其他可能的路径。
- 忽略长距离依赖:
- 在某些情况下,早期的贪心选择可能会影响序列的长距离依赖关系,使得最终的输出序列质量下降。### 波束搜索(Beam Search)
波束搜索(Beam Search)
波束搜索(Beam Search)是一种在序列生成问题中常用的启发式搜索算法,特别是在自然语言处理领域,如机器翻译、文本摘要等任务中。它旨在找到使得整个序列的概率最大化的词序列。
- 初始化:
- 从一个初始状态开始,通常是特殊的起始符号,如
<s>。初始化一个波束,其中包含这个起始状态。
- 从一个初始状态开始,通常是特殊的起始符号,如
- 扩展波束:
- 在每一步 i i i(从 N N N 到 N + M − 1 N+M-1 N+M−1),对于波束中的每个状态,生成所有可能的下一个词。
- 计算每个扩展状态的概率,并选择概率最高的 b b b个状态作为新的波束。这里 b b b 是波束的大小,表示在每一步保留的可能性最高的词的数量。
- 在每轮预测中保留 b b b 个可能性最高的词,构成波束:
min o i [ w ] for w ∈ B i > max o i [ w ] for w ∈ D − B i \min_{o_i[w] \text{ for } w \in B_i} > \max_{o_i[w] \text{ for } w \in D - B_i} minoi[w] for w∈Bi>maxoi[w] for w∈D−Bi
- 终止条件:
- 继续扩展波束,直到达到预定的序列长度 M M M 或遇到终止符号
</s>。
- 继续扩展波束,直到达到预定的序列长度 M M M 或遇到终止符号
- 选择最优序列:
- 在所有 M M M 个波束中,选择联合概率最大的词序列作为最终输出:
{ w N + 1 , w N + 2 , … , w N + M } = arg max { w i ∈ B i for 1 ≤ i ≤ M } ∏ i = 1 M o N + i [ w i ] \{w_{N+1}, w_{N+2}, \ldots, w_{N+M}\} = \arg\max_{\{w_i \in B_i \text{ for } 1 \leq i \leq M\}} \prod_{i=1}^{M} o_{N+i}[w_i] {wN+1,wN+2,…,wN+M}=argmax{wi∈Bi for 1≤i≤M}∏i=1MoN+i[wi]
- 在所有 M M M 个波束中,选择联合概率最大的词序列作为最终输出:
波束搜索的关键点
- 波束修剪(Beam Pruning):
- 在每一步,只保留概率最高的 b b b 个状态,这有助于减少计算量并避免无效搜索。
- 长度归一化:
- 有时,波束搜索会考虑长度归一化,即通过惩罚过长的序列来平衡长度对概率的影响。
- 多样性:
- 为了增加结果的多样性,可以采用一些技术,如束熵搜索(Beam Entropy Search)或束多样性搜索(Beam Diversity Search)。
波束搜索的优势
- 全局最优:
- 与贪心搜索相比,波束搜索考虑了多个候选词,更有可能找到全局最优解。
- 避免局部最优:
- 波束搜索避免了贪心搜索中的局部最优问题,因为它在每一步都考虑了多个可能的下一步。
- 灵活性:
- 波束搜索的参数(如波束大小 b b b)可以根据具体任务进行调整,以平衡计算成本和结果质量。
概率最大化方法的问题
- 平庸文本:
- 概率最大化方法倾向于生成最常见的平庸文本,缺乏多样性和新颖性。
- 改进:
- 为了提升生成文本的新颖度和多样性,可以在解码过程中加入随机元素,如随机采样方法。
随机采样方法
为了增加生成文本的多样性,随机采样的方法在预测时增加了随机性。在每轮预测时,其先选出一组可能性高的候选词,然后按照其概率分布进行随机采样,采样出的词作为本轮的预测结果。
当前,主流的 Top-K 采样和 Top-P 采样方法分别通过指定候选词数量和划定候选词概率阈值的方法对候选词进行选择。
在采样方法中加入 Temperature 机制可以对候选词的概率分布进行调整。
Top-K 采样
Top-K 采样是一种结合了贪心搜索和随机采样的序列生成方法,它旨在平衡探索(exploration)和利用(exploitation)。这种方法在每轮预测中不是选择概率最高的单个词,而是选择概率最高的 K K K 个词作为候选词集合,然后从这个集合中随机采样一个词作为下一步的输出。
- 选择候选词:
- 在每一步 i i i,从所有可能的词中选择概率最高的 K K K 个词作为候选词集合。
- 概率归一化:
- 对这 K K K 个候选词的概率进行归一化,使得它们的和为1。这通常通过softmax函数实现,但在这里只对 K K K 个候选词应用,而不是整个词汇表。
- 随机采样:
- 根据归一化后的概率分布,从 K K K 个候选词中随机采样一个词作为输出。
Top-K 采样的公式
对于每个候选词 w j w_j wj(其中 j = 1 , 2 , … , K j = 1, 2, \ldots, K j=1,2,…,K),归一化的概率 p ( w i + 1 ) p(w_{i+1}) p(wi+1) 计算如下:
p ( w i + 1 ) = ( exp ( o i [ w 1 ] T ) ∑ j = 1 K exp ( o i [ w j ] T ) , … , exp ( o i [ w K ] T ) ∑ j = 1 K exp ( o i [ w j ] T ) ) p(w_{i+1}) = \left( \frac{\exp\left(\frac{o_i[w_1]}{T}\right)}{\sum_{j=1}^{K} \exp\left(\frac{o_i[w_j]}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_i[w_K]}{T}\right)}{\sum_{j=1}^{K} \exp\left(\frac{o_i[w_j]}{T}\right)} \right) p(wi+1)= ∑j=1Kexp(Toi[wj])exp(Toi[w1]),…,∑j=1Kexp(Toi[wj])exp(Toi[wK])
然后,根据这个分布随机采样 w i + 1 w_{i+1} wi+1:
w i + 1 ∼ p ( w i + 1 ) w_{i+1} \sim p(w_{i+1}) wi+1∼p(wi+1)
其中:
- o i [ w j ] o_i[w_j] oi[wj] 是第 i i i 轮预测中词 w j w_j wj 的原始概率。
- T T T 是温度参数(temperature),用于控制概率分布的平滑程度。 T T T 的值越大,分布越平滑,值越小,分布越尖锐。
Top-K 采样的优势
- 平衡探索和利用:
- Top-K 采样通过选择 K K K 个最高概率的词,增加了生成多样性,避免了贪心搜索中的局部最优问题。
- 控制随机性:
- 通过调整 K K K 的值,可以控制生成过程中的随机性。较小的 K K K 值会增加随机性,而较大的 K K K 值会接近贪心搜索。
- 灵活性:
- 温度参数 T T T 提供了额外的控制,允许调整概率分布的形状,以适应不同的生成需求。
Top-P 采样
Top-P 采样,也称为 Nucleus 采样,是一种序列生成技术,它不是简单地选择概率最高的 K K K 个词,而是选择累积概率达到某个阈值 p p p 的所有词作为候选词集合。
这种方法旨在生成更多样化和连贯的文本,同时避免贪心搜索的局部最优问题。
- 选择候选词:
- 在每一步 i i i,从所有可能的词中选择累积概率达到阈值 (p) 的词作为候选词集合 S p S_p Sp。
- 概率归一化:
- 对候选词集合 S p S_p Sp 中的词的概率进行归一化,使得它们的和为1。这通常通过softmax函数实现,但在这里只对候选词集合中的词应用。
- 随机采样:
- 根据归一化后的概率分布,从候选词集合 S p S_p Sp 中随机采样一个词作为输出。
Top-P 采样的公式
对于每个候选词 w j w_j wj(其中 j = 1 , 2 , … , ∣ S p ∣ j = 1, 2, \ldots, |S_p| j=1,2,…,∣Sp∣),归一化的概率 p ( w i + 1 ) p(w_{i+1}) p(wi+1) 计算如下:
p ( w i + 1 ) = ( exp ( o i [ w 1 ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w j ] T ) , … , exp ( o i [ w ∣ S p ∣ ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w j ] T ) ) p(w_{i+1}) = \left( \frac{\exp\left(\frac{o_i[w_1]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_j]}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_i[w_{|S_p|}]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_j]}{T}\right)} \right) p(wi+1)= ∑j=1∣Sp∣exp(Toi[wj])exp(Toi[w1]),…,∑j=1∣Sp∣exp(Toi[wj])exp(Toi[w∣Sp∣])
然后,根据这个分布随机采样 w i + 1 w_{i+1} wi+1:
w i + 1 ∼ p ( w i + 1 ) w_{i+1} \sim p(w_{i+1}) wi+1∼p(wi+1)
其中:
- o i [ w j ] o_i[w_j] oi[wj] 是第 i i i 轮预测中词 w j w_j wj 的原始概率。
- T T T 是温度参数(temperature),用于控制概率分布的平滑程度。 T T T 的值越大,分布越平滑,值越小,分布越尖锐。
- ∣ S p ∣ |S_p| ∣Sp∣ 是候选词集合 S p S_p Sp 的大小。
Top-P 采样的优势
- 提高多样性:
- 通过选择累积概率达到阈值 (p) 的词,Top-P 采样可以生成更多样化的文本。
- 控制风险:
- 通过设置阈值 (p),可以控制生成文本的冒险程度,避免生成概率极低的词。
- 灵活性:
- 温度参数 T T T 提供了额外的控制,允许调整概率分布的形状,以适应不同的生成需求。
Temperature 机制的作用
Temperature 机制是一种调整 Softmax 函数输出概率分布的方法,它通过改变 Softmax 函数中输入的尺度来控制输出概率分布的形状。
这种机制在机器学习和深度学习中被用来控制模型的不确定性和随机性,特别是在生成模型和强化学习中。
-
增加随机性:当 Temperature T > 1 T > 1 T>1 时,Softmax 函数的输出分布变得更加平坦,这意味着各个类别的概率更加接近,从而增加了模型输出的随机性。
-
减少随机性:当 0 < T < 1 0 < T < 1 0<T<1 时,Softmax 函数的输出分布变得更加集中,这意味着模型更倾向于输出概率最高的类别,从而减少了模型输出的随机性。
Temperature 机制的公式
对于一个给定的输入 o i o_i oi 和类别集合 S p S_p Sp,Softmax 函数的输出 p ( w i + 1 ) p(w_{i+1}) p(wi+1) 可以表示为:
p ( w i + 1 ) = exp ( o i [ w 1 ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w j ] T ) , … , exp ( o i [ w ∣ S p ∣ ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w j ] T ) p(w_{i+1}) = \frac{\exp\left(\frac{o_i[w_1]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_j]}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_i[w_{|S_p|}]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_j]}{T}\right)} p(wi+1)=∑j=1∣Sp∣exp(Toi[wj])exp(Toi[w1]),…,∑j=1∣Sp∣exp(Toi[wj])exp(Toi[w∣Sp∣])
其中:
- o i [ w j ] o_i[w_j] oi[wj] 是模型对于第 i i i 个输入和第 j j j 个类别的原始输出(通常是神经网络的最后一层的输出)。
- T T T 是 Temperature 参数,控制概率分布的形状。
- ∣ S p ∣ |S_p| ∣Sp∣ 是类别集合 S p S_p Sp 中的类别数量。
- exp \exp exp 是指数函数。
引入 Temperature
在引入 Temperature 机制后,Top-K 采样和 Top-P 采样的候选集分布都受到了 Temperature 参数 T T T 的影响。这两种采样方法都是在生成模型中常用的技术,用于从模型输出的概率分布中选择最可能的候选集。
Top-K 采样
Top-K 采样是一种选择概率分布中前 K K K 个最高概率值的方法。在引入 Temperature 机制后,Top-K 采样的候选集分布可以表示为:
p ( w i 1 + 1 , … , w i K + 1 ) = ( exp ( o i [ w 1 i + 1 ] T ) ∑ j = 1 K exp ( o i [ w j i + 1 ] T ) , … , exp ( o i [ w K i + 1 ] T ) ∑ j = 1 K exp ( o i [ w j i + 1 ] T ) ) p(w_{i1+1}, \ldots, w_{iK+1}) = \left( \frac{\exp\left(\frac{o_i[w_{1i+1}]}{T}\right)}{\sum_{j=1}^{K} \exp\left(\frac{o_i[w_{ji+1}]}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_i[w_{Ki+1}]}{T}\right)}{\sum_{j=1}^{K} \exp\left(\frac{o_i[w_{ji+1}]}{T}\right)} \right) p(wi1+1,…,wiK+1)= ∑j=1Kexp(Toi[wji+1])exp(Toi[w1i+1]),…,∑j=1Kexp(Toi[wji+1])exp(Toi[wKi+1])
这里:
- w i 1 + 1 , … , w i K + 1 w_{i1+1}, \ldots, w_{iK+1} wi1+1,…,wiK+1 表示选择的前 K K K 个候选。
- o i [ w j i + 1 ] o_i[w_{ji+1}] oi[wji+1] 是模型对于第 i i i 个输入和第 j j j 个候选的输出。
- T T T 是 Temperature 参数。
Top-P 采样
Top-P 采样是一种选择累积概率达到 P P P 百分比的候选集的方法。在引入 Temperature 机制后,Top-P 采样的候选集分布可以表示为:
p ( w i 1 + 1 , … , w i ∣ S p ∣ + 1 ) = ( exp ( o i [ w 1 i + 1 ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w j i + 1 ] T ) , … , exp ( o i [ w ∣ S p ∣ i + 1 ] T ) ∑ j = 1 ∣ S p ∣ exp ( o i [ w j i + 1 ] T ) ) p(w_{i1+1}, \ldots, w_{i|S_p|+1}) = \left( \frac{\exp\left(\frac{o_i[w_{1i+1}]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_{ji+1}]}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_i[w_{|S_p|i+1}]}{T}\right)}{\sum_{j=1}^{|S_p|} \exp\left(\frac{o_i[w_{ji+1}]}{T}\right)} \right) p(wi1+1,…,wi∣Sp∣+1)= ∑j=1∣Sp∣exp(Toi[wji+1])exp(Toi[w1i+1]),…,∑j=1∣Sp∣exp(Toi[wji+1])exp(Toi[w∣Sp∣i+1])
这里:
- w i 1 + 1 , … , w i ∣ S p ∣ + 1 w_{i1+1}, \ldots, w_{i|S_p|+1} wi1+1,…,wi∣Sp∣+1 表示选择的累积概率达到 P P P 百分比的候选集。
- ∣ S p ∣ |S_p| ∣Sp∣ 是候选集的大小,即累积概率达到 P P P 百分比所需的候选数量。
- o i [ w j i + 1 ] o_i[w_{ji+1}] oi[wji+1] 是模型对于第 i i i 个输入和第 j j j 个候选的输出。
- T T T 是 Temperature 参数。
影响
引入 Temperature 机制后,这两种采样方法都会受到 T T T 的影响,从而改变候选集的分布形状:
- 当 T > 1 T > 1 T>1 时,分布变得更加平坦,增加了随机性,使得更多的候选被选中的可能性增加。
- 当 0 < T < 1 0 < T < 1 0<T<1 时,分布变得更加集中,减少了随机性,使得更高概率的候选被选中的可能性增加。
这种调整可以帮助模型在生成过程中平衡探索和利用,或者根据特定的任务需求调整生成的多样性和一致性。
相关文章:

语言模型的采样方法
语言模型的采样方法 语言模型的输出为一个向量,该向量的每一维代表着词典中对应词的概率。 在采用自回归范式的文本生成任务中,语言模型将依次生成一组向量并将其解码为文本。将这组向量解码为文本的过程被成为语言模型解码。 解码过程显著影响着生成文本…...

使用 Nginx 配置真实 IP 地址转发
使用 Nginx 配置真实 IP 地址转发 在许多 web 应用程序中,获取客户端的真实 IP 地址非常重要,尤其是在使用反向代理服务器(如 Nginx)时。本文将指导你如何在 Nginx 中配置 X-Real-IP 和 X-Forwarded-For 头部,以确保你…...

WPF+MVVM案例实战与特效(二十四)- 粒子字体效果实现
文章目录 1、案例效果2、案例实现1、文件创建2.代码实现3、界面与功能代码3、总结1、案例效果 提示:这里可以添加本文要记录的大概内容: 2、案例实现 1、文件创建 打开 Wpf_Examples 项目,在 Views 文件夹下创建窗体界面 ParticleWindow.xaml,在 Models 文件夹下创建粒子…...

Oracle视频基础1.4.3练习
15个视频 1.4.3 できない dbca删除数据库 id ls cd cd dbs ls ls -l dbca# delete a database 勾选 # chris 勾选手动删除数据库 ls ls -l ls -l cd /u01/oradata ls cd /u01/admin/ ls cd chris/ ls clear 初始化参数文件,admin,数据文件#新版本了…...

energy 发布 v2.4.5
更新内容 修复 energy cli install 命令安装开发环境 修复 动态库加载error未暴露 增加 JS ipc.on 监听模式,异步返回结果 修复 energy cli 不能强制退出问题 修复 MacOS 开发模式 debug 时不更新 helper 进程 优化 energy cli 在 MacOS 开发模式和安装包制作 link…...
一文详解工单管理系统,工单系统是什么意思
在现代企业管理中,工单管理系统已经成为提升效率和客户满意度的重要工具。随着企业规模的扩大和业务复杂性的增加,传统的手工工单处理方式已经无法满足企业的需求。本文将详细解析工单管理系统的定义、功能、优势,并推荐一款优秀的工单管理系…...

【无标题】基于SpringBoot的母婴商城的设计与实现
一、项目背景 当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术,对行业内的各种相关数据进行科学化,规范化管理。这样的大环境让那些止步不前,…...

你需要了解的Android主题相关知识
在 Android 开发中,主题(Theme)是用于定义应用的视觉风格的一组样式集合。主题决定了应用的配色、字体样式、控件外观等,是整个应用的一致性视觉体验的重要组成部分。以下是对 Android 主题的全面介绍,包括主题的基础概…...

基于Multisim数控直流稳压电源电路(含仿真和报告)
【全套资料.zip】数控直流稳压电源电路设计Multisim仿真设计数字电子技术 文章目录 功能一、Multisim仿真源文件二、原理文档报告资料下载【Multisim仿真报告讲解视频.zip】 功能 1.输出直流电压调节范围5-12V。 2.输出电流0-500mA。 3.输出直流电压能步进调节,步…...

精读预告Bigtable
文章目录 1. 引言:2. 背景 1. 引言: 在本期的精读会中,我们将深入解读另一篇具有里程碑意义的论文——《Bigtable: A Distributed Storage System for Structured Data》。这篇论文详细介绍了 Bigtable 作为谷歌用于管理结构化数据的分布式存…...
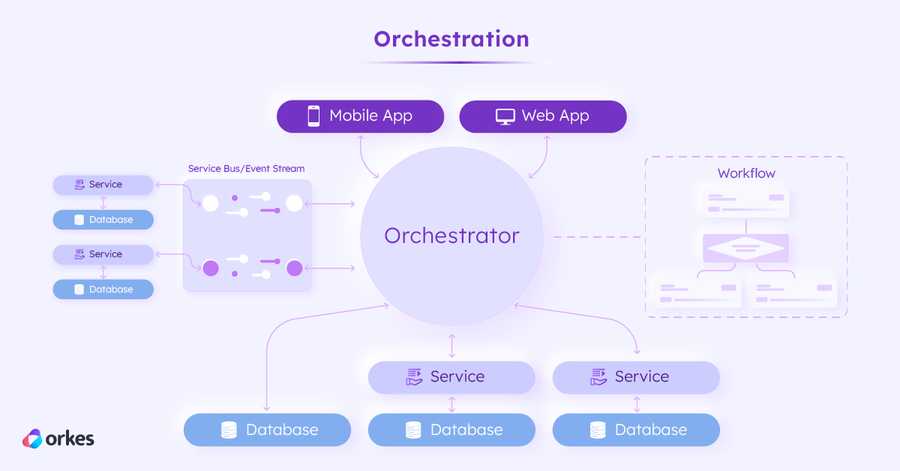
软件架构演变:从单体架构到LLM链式调用
0 前言 软件架构——我们数字世界的蓝图——自20世纪中叶计算机时代诞生以来,已经发生了巨大演变。 20世纪60年代和70年代早期,以大型主机和单体软件为主导。而今天,数字领域已完全不同,运行在由云计算、API连接、AI算法、微服务…...

Redis-“自动分片、一定程度的高可用性”(sharding水平拆分、failover故障转移)特性(Sentinel、Cluster)
文章目录 零、写在前面一、水平拆分(sharding/分片)、故障转移(failover)机制介绍水平拆分(Sharding)故障转移机制 二、Redis的水平拆分的机制有关的配置1. 环境准备2. 配置文件配置3. 启动所有Redis实例4. 创建集群5. 测试集群读/写6. 集群管理 三、Red…...
 (并发-----原子性/互斥临界区/生产者消费者问题/临界区问题三条件/互斥性/进展性/公平性))
操作系统(9) (并发-----原子性/互斥临界区/生产者消费者问题/临界区问题三条件/互斥性/进展性/公平性)
目录 1. 并发(Concurrency)的定义 2. 原子性(Atomicity) 3. 互斥(Mutual Exclusion) 4. 生产者-消费者问题(Producer-Consumer Problem) 5. 临界区Critical Section 6. 临界区问题…...

Django响应
HTTPResponse: 是由Django创造的, 他的返回格式为 HTTPResponse(content响应体,content_type响应体数据类型,status状态码), 可以修改返回的数据类型,适用于返回图片,视频,音频等二进…...

算法:图的相关算法
图的相关算法 1. 图的遍历算法1.1 深度优先搜索1.2 广度优先搜索 2. 最小生成树求解算法普里姆(Prim)算法克鲁斯卡尔(Kruskal)算法 3. 拓扑排序4. 最短路径算法 1. 图的遍历算法 图的遍历是指从某个顶点出发,沿着某条搜索路径对图中的所有顶点进行访问且只访问次的…...

django的models使用介绍。
from django.db import modelsfrom utils.models import CommonModel# Create your models here. class User(CommonModel):#用户数据模型username models.CharField(用户名,max_length32, uniqueTrue)password models.CharField(密码,max_length256)nickname models.CharFi…...

【分布式技术】分布式事务深入理解
文章目录 概述产生原因关键点 分布式事务解决方案3PC3PC的三个阶段:3PC相比于2PC的改进:3PC的缺点: TCCTCC事务的三个阶段:TCC事务的设计原则:TCC事务的适用场景:TCC事务的优缺点:如何解决TCC模…...

力扣hot100-->hash表/map
hash表/map 1. 1. 两数之和 简单 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 …...

基于redis实现延迟队列
Redis实现延时队列 延时队列里装的主要是延时任务,用延时队列来维护延时任务的执行时间。 1、延时队列有哪些使用情景? 1、如果请求加锁没加成功 可以将这个请求扔到延时队列里,延后处理。 2、业务中有延时任务的需要 比如说࿰…...

PHP微信小程序共享充电桩系统设计与实现计算机毕业设计源代码作品和开题报告
博主介绍:黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育、辅导。 所有项目都配有从入门到精通的基础知识视频课程ÿ…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...

3PEAK思瑞浦 TPA6531-S5TR SOT23-5 运算放大器
特性 供电电压:1.75V至5.5V 偏移电压:1.5mV(最大值) 最大可调工作频率:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1赫兹至10赫兹电压噪声:1伏峰值 开关电源时无显著输出抖动 低功耗:每通道最大25安培 工作温度范围:-40C至125C...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...

[特殊字符] 高效统计排序数组中目标元素的出现次数
给定一个已排序的数组和一个目标值,如何快速统计该目标值在数组中出现的次数?这是面试中非常经典的一道题,今天就来聊聊两种解法:线性搜索和二分搜索。 问题描述 假设有一个已排序的数组 arr[] 和一个整数 target,需…...

5步快速上手OpenVSP:免费开源的飞机参数化设计终极指南
5步快速上手OpenVSP:免费开源的飞机参数化设计终极指南 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP OpenVSP是一款由NASA开发的免费开源飞机参数化设计工具,让航空工程…...

暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南
暗黑破坏神2存档编辑器:d2s-editor免费可视化编辑终极指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 想要轻松修改暗黑破坏神2存档却不懂十六进制?d2s-editor是你的完美解决方案!这款基于…...

使用taotoken cli工具,一键为团队开发环境配置多模型api密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken cli工具,一键为团队开发环境配置多模型api密钥 在团队协作开发中,统一管理多个大模型API的密…...