【自然语言处理与大模型】大模型(LLM)基础知识②
(1)LLaMA输入句子的长度理论上可以无限长吗?
理论上来说,LLM大模型可以处理任意长度的输入句子,但实际上存在一些限制。下面是一些需要考虑的因素:
1. 计算资源:生成长句子需要更多的计算资源,包括内存和计算时间。由于LLM通常是基于神经网络的模型,计算长句子可能会导致内存不足或计算时间过长的问题。
2. 模型训练和推理:训练和推理长句子可能会面临一些挑战。在训练阶段,处理长句子可能会导致梯度消失和梯度爆炸的问题。影响模型的收敛性和训练效果。在推理阶段,生成长句子可能会增加模型的错误率和生成时间。
3. 上下文建模:LLM是基于上下文建模的模型,长句子的上下文可能会更加复杂和更加有深度。模型需要能够捕捉长句子中的语义和语法结构,以生成准确和连贯的文本。
虽然面临很多问题,但研究人员已经不断努力改进和优化LLM,以处理更长的句子。例如:可以采用分块的方式处理长句子,将其分成多个较短的片段来处理。此外可以通过增加计算资源、优化模型结构和参数设置,以及使用更高效的推理算法来提高LLM处理长句子的能力。
所以在实际应用中,长句子的处理还需要考虑具体的应用场景、任务需求和资源限制。
(2) 什么情况用Bert模型,什么情况用LLaMA和ChatGLM这类大模型?怎么选?
选择使用Bert模型还是LLaMA和ChatGLM这类大模型,主要取决于你的具体应用场景、任务需求、资源限制以及预期的目标。下面是一些具体的指导原则:
NLU任务:如果任务主要是文本理解,如文本分类、命名实体识别等。Bert通常是最好的选择。
NLG任务:如果任务主要是文本生成,如对话系统、文章生成等,LLaMA和ChatGLM等大模型更合适。
资源限制:如果计算资源有限,优先考虑Bert。如果有足够的资源和数据,可以考虑大模型以获得更好的性能。
(3)各个专业领域是否需要各自的大模型来服务?
各个专业领域通常需要各自的大模型来服务,原因如下:
1. 领域特定知识:不同领域用于各自特定的知识和术语,需要针对该领域进行训练的大模型才能更好的理解和处理相关文本。例如,在医学领域,需要训练具有医学知识的大模型,以更准确地理解和生成医学文本。
2. 语言风格和惯用语:各个领域通常有自己独特的语言风格和惯用语,这些特点对模型的训练和生成都很重要。专门针对某个领域进行训练的大模型可以更好地掌握该领域的语言特点,生成更符合该领域要求的文本。
3. 领域需求的差异:不同领域对文本处理的需求也有所差异。例如,金融领域可能更关注数字和统计数据的处理,而法律领域可能更关注法律条款和案例的解析。因此,为了更好地满足不同领域的需求,需要专门针对各个进行训练的大模型。
4. 数据稀缺性:某些领域的数据可能相对较少,无法充分训练通用的大模型。针对特定领域进行训练的大模型可以更好的利用该领域的数据,提高模型的性能和效果。
尽管需要各自的大模型来服务不同的领域,但也可以共享一些通用的模型和技术。例如通用的大模型可以用于处理通用的文本任务,而领域特定的模型可以在通用模型的基础上进行微调和定制,以适应特定领域的需求。这样可以在满足领域需求的同时,减少模型的重复训练和资源消耗。
(4)如何让大模型处理更长的文本?
要让大模型处理更长的文本,可以考虑以下几个方法:
1. 分块处理:将长文本分割成较短的片段,然后逐个片段输入模型进行处理。这样可以避免长文本对模型内存和计算资源的压力。在处理分块文本时,可以使用重叠的方式,即将相邻片段的一部分重叠,以保持上下文的连贯性。
2. 层次建模:通过引入层次结构,将长文本划分为更小的单元。例如,可以将文本分为段落、句子或子句等层次,然后逐层输入模型进行处理。这样可以减少每个单元的长度。提高模型处理长文本的能力。
3. 部分生成:如果只需要模型生成文本的一部分,而不是整个文本,可以只输入部分文本作为上下文,然后让模型生成所需的部分。例如,输入前一部分的文本,让模型生成后续的内容。
4. 注意力机制:注意力机制可以帮助模型关注输入中的重要部分,可以用于处理长文本时的上下文建模。通过引入注意力机制,模型可以更好的捕捉长文本中的关键信息。
5. 模型结构优化:通过优化模型结构和参数设置,可以提高模型处理长文本的能力。例如,可以增加模型的层数或参数量,以增加模型的表达能力。还可以使用更高效的模型架构,如Transformer等,以提高长文本处理效率。
需要注意的是,处理长文本还要考虑计算资源和时间限制。较长的文本可能需要更多的内存和计算时间,因此在实际应用中需要更具具体情况进行权衡。
(5)如果想要在某个模型基础上做全参数微调,需要多少显存?
要进行全参数微调,显存取决于如下多个因素:
1. 参数量:模型的参数量越大,显存需求越高。ChatGLM3-6B的参数量为60亿,这本身就需要较大的显存来存储模型权重。
2. 批量大小:批量大小决定了每次前向传播和反向传播处理的样本数量。批量大小越大,显存需求越高。
3. 数据类型:参数通常以32位浮点数(float32)存储,每个参数需要4字节的存储空间。如果使用16位浮点数(float16或bfloat16),则每个参数只需要2字节。半精度可以显著减少显存需求。
4. 梯度存储:在训练过程中,除了模型参数外,还需要存储梯度信息。通常,梯度也会占用与模型参数相同大小的显存。
5. 优化器状态:大多数现代优化器(如Adam)会为每个参数存储额外的状态信息,如动量(momentum)和方差(variance)。这通常需要与模型参数相同或更少的显存。
6. 激活和中间层存储:在前向和后向传播过程中,模型的激活和中间层结果也需要存储,这取决于模型架构和批量大小。
7. 检查点备份:在训练过程中,可能需要定期保存模型的状态,包括参数和优化器状态,以便于恢复训练。
8. 预留空间:通常需要预留一部分显存作为缓冲,以避免显存溢出。
显存需求 = (模型参数大小 + 梯度大小)× (批量大小 + 优化器状态大小)+ 激活和中间层存储 + 检查点和备份 + 预留空间
显存需求 ≈ 模型参数大小 × 批量大小
(6)为什么SFT之后觉得大模型LLM变傻了?
Supervised Fine-Tuning有监督微调后变傻,可能因为:
1. 过拟合
- 定义:过拟合是指模型在训练数据上表现得非常好,但在未见过的测试数据或实际应用中表现较差。
- 原因:如果微调数据集太小或与原始训练数据差异较大,模型可能会过度拟合这些特定的训练样本,导致在其他任务或数据上表现不佳。
- 解决方案:增加微调数据集的多样性和规模,使用正则化技术(如L2正则化),或者使用早停法(early stopping)来防止过拟合。
2. 灾难性遗忘
- 定义:灾难性遗忘是指模型在学习新任务时忘记旧任务的知识。
- 原因:大模型在进行微调时,可能会丢失在预训练阶段学到的广泛知识,特别是在微调数据集覆盖范围较窄的情况下。
- 解决方案:使用持续学习(continual learning)技术,如弹性权重巩固(EWC)、路径整合(path integral)等,或者在微调过程中保留一部分预训练数据进行联合训练。
3. 数据偏差
- 定义:数据偏差是指微调数据集中的样本分布与实际应用场景中的样本分布存在显著差异。
- 原因:如果微调数据集偏向于某些特定类型的样本,模型可能会过度优化这些样本,而忽视其他类型的样本。
- 解决方案:确保微调数据集的多样性和代表性,尽量覆盖各种可能的输入情况。
4. 超参数设置不当
- 定义:超参数设置不当会影响模型的训练效果。
- 原因:学习率、批量大小、优化器选择等超参数的不当设置可能导致模型训练不充分或过度训练。
- 解决方案:通过网格搜索、随机搜索或贝叶斯优化等方法,找到最佳的超参数组合。
5. 任务不匹配
- 定义:任务不匹配是指微调任务与模型的原始设计任务不一致。
- 原因:如果微调任务与模型的预训练任务相差较大,模型可能无法很好地适应新任务。
- 解决方案:选择与预训练任务更接近的微调任务,或者使用多任务学习(multi-task learning)来同时优化多个相关任务。
6. 数据质量
- 定义:数据质量低下会影响模型的训练效果。
- 原因:微调数据集中可能存在噪声、错误标注或不一致的样本,这些都会影响模型的性能。
- 解决方案:对微调数据进行清洗和验证,确保数据的质量和一致性。
7. 模型容量不足
- 定义:模型容量不足是指模型的复杂度不足以捕捉微调任务的特征。
- 原因:如果微调任务较为复杂,而模型的容量不足以处理这些复杂性,模型可能会表现不佳。
- 解决方案:选择更大或更复杂的模型,或者在现有模型的基础上增加更多的层数或参数。
(7)微调和指令微调的区别?
微调(Fine-Tuning)和指令微调(Instruction Tuning)是两种不同的方法,用于在特定任务上优化预训练的大模型(LLM)。它们的主要区别在于目标、数据集和训练方式。下面详细解释这两种方法的区别:
1. 微调(Fine-Tuning)
定义:微调是指在预训练模型的基础上,使用特定任务的数据集进行进一步训练,以优化模型在该任务上的性能。
1)目标
- 任务特定:微调的目标是使模型在特定任务上表现更好,如文本分类、情感分析、命名实体识别等。
- 性能提升:通过微调,模型可以更好地适应特定任务的数据分布和特征,从而提高准确率、召回率等指标。
2)数据集
- 任务数据:微调使用的数据集通常包含大量标注好的任务特定数据,如分类标签、情感标签、实体标注等。
- 格式:数据集通常包含输入文本和对应的标签或输出。
3)训练方式
- 端到端训练:微调通常是一个端到端的训练过程,模型直接从输入文本预测输出标签。
- 损失函数:使用任务特定的损失函数,如交叉熵损失(Cross-Entropy Loss)。
4)示例
- 文本分类:使用包含文本和分类标签的数据集进行微调。
- 情感分析:使用包含文本和情感标签的数据集进行微调。
2. 指令微调(Instruction Tuning)
定义:指令微调是指在预训练模型的基础上,使用包含指令和相应响应的数据集进行进一步训练,以优化模型在理解和执行指令方面的性能。
1)目标
- 指令理解:指令微调的目标是使模型能够更好地理解和执行自然语言指令,如生成特定类型的文本、回答问题、执行多步推理等。
- 灵活性:通过指令微调,模型可以更灵活地应对各种任务,而不需要为每个任务单独微调。
2)数据集
- 指令-响应对:指令微调使用的数据集包含指令和相应的响应对。
- 格式:数据集通常包含指令(如“回答以下问题:XXX?”)和响应(如“答案是:XXX。”)。
3)训练方式
- 指令驱动:指令微调通过训练模型理解和生成指令来提高其在各种任务上的表现。
- 损失函数:使用适当的损失函数,如交叉熵损失或均方误差损失,来优化模型的指令执行能力。
(8)SFT指令微调数据如何构建?
假设我们要构建一个问答系统的SFT数据集,以下是具体的步骤:
- 收集数据:从公开的问答数据集(如SQuAD)和网络爬虫中收集问题和答案。
- 数据预处理:清洗数据,去除无关项,分词处理。
- 构建指令-响应对:
- 指令:
"回答以下问题:中国的首都是哪里?"- 响应:
"答案是:北京。"- 数据标注:人工标注数据,确保每个指令和响应的准确性。
- 数据切分:将数据分为训练集、验证集和测试集。
- 数据增强:使用同义词替换和句子重组增加数据的多样性。
- 数据平衡:确保各个类别和难度的样本数量均衡。
- 数据验证:检查指令和响应的一致性,评估数据质量。
- 数据格式化:将数据统一为JSON格式。
- 数据保存:将处理好的数据保存为文件。
将上面这个例子总结成通用的步骤:
1. 明确任务目标
- 确定任务类型:明确你要解决的具体任务类型,如文本分类、情感分析、问答系统、对话生成等。
- 定义任务要求:明确任务的具体要求和目标,例如准确率、响应时间、生成内容的质量等。
2. 收集数据
- 来源:从公开数据集、网络爬虫、人工标注等多种渠道收集数据。
- 多样性:确保数据的多样性,涵盖不同领域、风格和复杂度的样本。
- 质量:确保数据的质量,避免噪声和错误标注。
3. 数据预处理
- 清洗:去除无关或低质量的数据,如重复项、空白项、乱码等。
- 格式化:将数据转换为模型所需的格式,如JSON、CSV等。
- 分词:对文本进行分词处理,确保模型能够正确解析输入。
4. 构建指令-响应对
- 指令设计:设计清晰、具体的指令,确保模型能够理解任务要求。指令应简洁明了,避免模糊不清。
- 例如,对于问答任务,指令可以是:“回答以下问题:XXX?”
- 对于文本生成任务,指令可以是:“根据以下背景信息生成一段描述:XXX。”
- 响应生成:为每个指令生成对应的正确响应。响应应准确、完整且符合任务要求。
- 例如,对于问答任务,响应可以是:“答案是:XXX。”
- 对于文本生成任务,响应可以是:“描述如下:XXX。”
5. 数据标注
- 人工标注:如果数据集较小,可以由专业人员进行人工标注,确保标注的准确性和一致性。
- 众包平台:对于大规模数据集,可以使用众包平台进行标注。
- 自动标注:对于部分任务,可以使用现有的模型或规则进行自动标注,然后进行人工审核和修正。
6. 数据切分
- 训练集:用于训练模型,占数据集的大部分(如80%)。
- 验证集:用于验证模型的性能,调整超参数,占数据集的一部分(如10%)。
- 测试集:用于最终评估模型的性能,占数据集的剩余部分(如10%)。
7. 数据增强
- 同义词替换:使用同义词替换指令中的某些词汇,增加数据的多样性。
- 句子重组:改变指令的句式结构,保持语义不变。
- 数据合成:结合多个指令生成新的复合指令,增加任务的复杂度。
8. 数据平衡
- 类别平衡:确保各个类别的样本数量大致相等,避免类别不平衡导致的偏见。
- 难度平衡:确保数据集中包含不同难度的样本,使模型能够处理各种复杂度的任务。
9. 数据验证
- 一致性检查:确保指令和响应之间的一致性,避免逻辑矛盾。
- 质量评估:对生成的指令-响应对进行质量评估,确保其符合任务要求。
10. 数据格式化
- 统一格式:将所有数据统一为模型所需的输入格式,如JSON、CSV等。
[{"instruction": "回答以下问题:XXX?","response": "答案是:XXX。"},{"instruction": "根据以下背景信息生成一段描述:XXX。","response": "描述如下:XXX。"} ]11. 数据保存
- 文件存储:将处理好的数据保存为文件,便于后续使用。
- 备份:定期备份数据,防止数据丢失。
(9)领域模型Continue PreTrain数据如何选取?
领域模型的继续预训练(Continue PreTraining)是一种有效的方法,可以进一步提升模型在特定领域或任务上的性能。选择合适的继续预训练数据集是关键步骤之一。以下是如何选取和准备继续预训练数据的原则:
1. 领域相关数据:⾸先,可以收集与⽬标领域相关的数据。这些数据可以是从互联⽹上爬取的、来⾃特定领域的⽂档或者公司内部的数据等。这样的数据可以提供领域相关的语⾔和知识,有助于模型在特定领域上的表现。
2. 领域专家标注:如果有领域专家可⽤,可以请他们对领域相关的数据进⾏标注。标注可以是分类、命名实体识别、关系抽取等任务,这样可以提供有监督的数据⽤于模型的训练。
3. 伪标签:如果没有领域专家或者标注数据的成本较⾼,可以使⽤⼀些⾃动化的⽅法⽣成伪标签。例如,可以使⽤预训练的模型对领域相关的数据进⾏预测,将预测结果作为伪标签,然后使⽤这些伪标签进⾏模型的训练。
4. 数据平衡:在进⾏数据选取时,需要注意数据的平衡性。如果某个类别的数据样本较少,可以考虑使⽤数据增强技术或者对该类别进⾏过采样,以平衡各个类别的数据量。
5. 数据质量控制:在进⾏数据选取时,需要对数据的质量进⾏控制。可以使⽤⼀些质量评估指标,如数据的准确性、⼀致性等,来筛选和过滤数据。
6. 数据预处理:在进⾏数据选取之前,可能需要对数据进⾏⼀些预处理,如分词、去除停⽤词、标准化等,以准备好输⼊模型进⾏训练。
(10)领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
在进行领域数据训练后,模型可能会出现“灾难性遗忘”(catastrophic forgetting)现象,即模型在特定领域任务上表现提升的同时,其在通用任务上的性能下降。为了缓解这一问题,可以采取以下几种策略:
1. 数据增强和混合:通过对领域数据进行增强,增加数据的多样性,减少模型对特定数据的依赖。使用同义词替换、句子重组、数据合成等技术。在训练过程中,动态混合领域数据和通用数据,确保模型在两个任务上都能得到充分的训练。使用动态采样策略,根据模型在不同任务上的表现调整数据的比例。
2. 增量学习:逐步扩展模型的知识,先在通用任务上进行预训练,然后再逐步加入领域数据进行微调。逐步增加领域数据的比例,确保模型在通用任务上的性能不会急剧下降。
3. 模型架构设计:将模型设计成模块化结构,不同模块负责不同的任务,减少任务之间的干扰。例如,可以设计一个共享的编码器和多个任务特定的解码器。还比如在模型中引入多头机制,每个头负责一个特定的任务,减少任务之间的冲突。
4. 领域适应技术:使⽤领域适应技术,如领域⾃适应(Domain Adaptation)和领域对抗训练
(Domain Adversarial Training),帮助模型在不同领域之间进⾏迁移学习,从⽽减少遗忘通⽤能⼒的问题。
相关文章:
基础知识②)
【自然语言处理与大模型】大模型(LLM)基础知识②
(1)LLaMA输入句子的长度理论上可以无限长吗? 理论上来说,LLM大模型可以处理任意长度的输入句子,但实际上存在一些限制。下面是一些需要考虑的因素: 1. 计算资源:生成长句子需要更多的计算资源&a…...

新能源汽车的未来:车载电源与V2G技术的前景
近年来,新能源汽车在全球市场上发展迅速,尤其是在中国,新能源汽车的月销量已经超过了燃油车。随着新能源技术的不断发展,新能源汽车不仅仅是作为出行工具,而逐渐成为“移动能源站”。本文将探讨电动汽车的车载外放电功…...

Git 本地操作(2)
会以下操作就可以完成本地的版本控制了,就不需要再复制文件每次改一个东西就复制整个工程保存下来啦! 建议先看上一篇文章噢 !!! 一、新建项目git本地操作 1、初始化仓库 创建一个 project 文件夹,将需…...

项目管理软件:5款甘特图工具测评
在项目管理中,甘特图作为一种直观且高效的任务进度展示工具,被广泛应用于各个行业。以下是几款功能强大、易于使用的甘特图工具,它们能够帮助项目经理更好地规划、跟踪和管理项目进度。 1、进度猫 进度猫是国内项目管理新秀,是…...

Unreal5从入门到精通之如何在指定的显示器上运行UE程序
前言 我们有一个设备,是一个带双显示器的机柜,主显示器是一个小竖屏,可以触屏操作,大显示器是一个普通的横屏显示器。我们用这个机柜的原因就是可以摆脱鼠标和键盘,直接使用触屏操作,又可以在大屏观看,非常适合用于教学。 然后我们为这款机柜做了很多个VR项目,包括Uni…...
【Spring MVC】DispatcherServlet 请求处理流程
一、 请求处理 Spring MVC 是 Spring 框架的一部分,用于构建 Web 应用程序。它遵循 MVC(Model-View-Controller)设计模式,将应用程序分为模型(Model)、**视图(View)和控制器&#x…...

【优选算法】——二分查找!
目录 1、二分查找 2、在排序数组中查找元素的第一个和最后一个位置 3、搜索插入位置 4、x的平方根 5、山脉数组的封顶索引 6、寻找峰值 7、寻找旋转排序数组中的最小值 8、点名 9、完结散花 1、二分查找 给定一个 n 个元素有序的(升序)整型数组…...

leetcode hot100【LeetCode 300. 最长递增子序列】java实现
LeetCode 300. 最长递增子序列 题目描述 给定一个未排序的整数数组 nums,找出其中最长递增子序列的长度。 要求: 子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如࿰…...

sql注入——靶场Less1
?id1 ?id99union select 1,2,3-- 查看占位 ?id1 order by 3-- 尝试出表有几列 ?id1 order by 4-- 说明只有三列 ?id99 union select 1,database(),3-- 查询当前使用的数据库的名称 ?id99 union select 1,group_concat(table_name),3 from information_schema.tables …...
)
docker file容器化部署Jenkins(一)
Jenkins Github地址:https://github.com/jenkinsci/jenkins 国内镜像地址:https://docker.aityp.com/ 准备工作 # 创建持久化卷目录 mkdir /data/jenkins_home/Jenkins拉取镜像 # 由于Jenkins需要JDK,所以直接拉取带有JDK的Jenkins镜像 doc…...

ArkTS组件继承的高级用法
在HarmonyOS应用开发中,ArkTS作为开发语言,组件的继承是实现代码复用和扩展功能的重要机制。本文将详细介绍ArkTS中组件继承的高级用法,包括继承的概念、如何使用继承、以及继承在实际开发中的应用和最佳实践。 继承的概念 继承是面向对象编…...

第十二章 spring Boot+shiro权限管理
学习目标 引入依赖配置Shiro设计数据库表编写Mapper、Service和Controller前端页面测试与调优其他注意事项 Spring Boot与Shiro的集成是一种常见的Java Web应用程序权限管理解决方案。Shiro是一个强大的Java安全框架,提供了认证、授权、会话管理、加密等安全功能。以…...
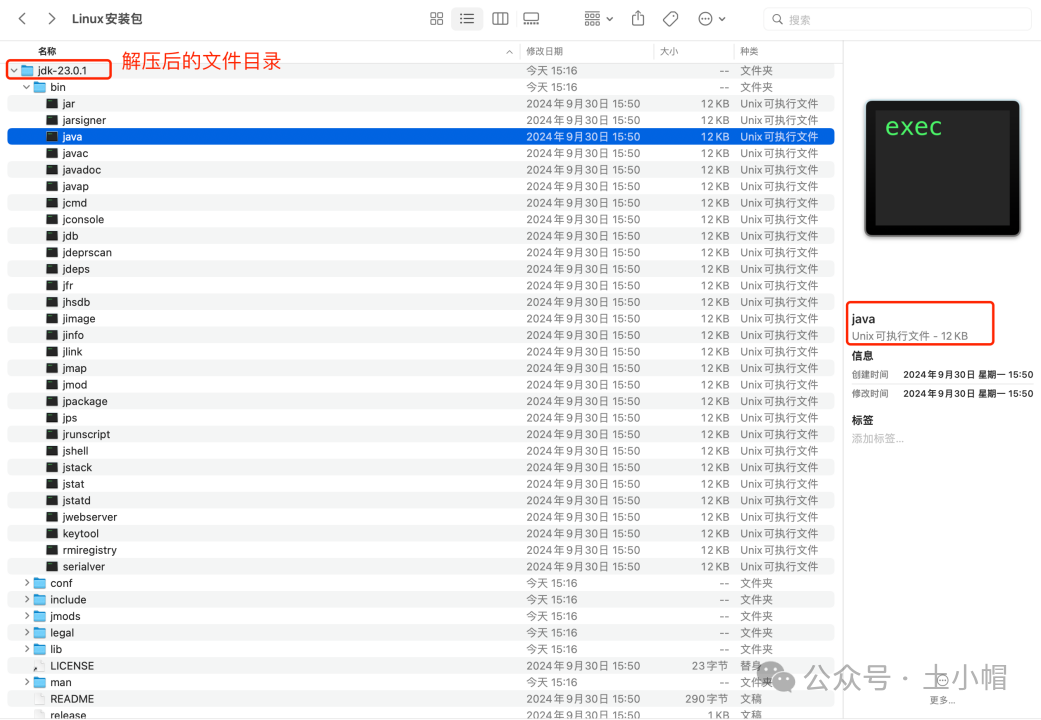
jmeter基础01-3_环境准备-Linux系统安装jdk
Step1. 查看系统类型 打开终端,命令行输入uname -a,显示所有系统信息,包括内核名称、主机名、内核版本等。 如果输出是x86_64,则系统为64位。如果输出是i686 或i386,则系统为32位。 Step2. 官网下载安装包 https://www…...

数字证书的简单记录
CA(Certificate Authority):即数字证书颁发认证机构。 CA数字证书(crt/cer证书):数字证书 申请者与颁发者信息申请者公钥颁发者签名,由CA机构使用私钥签名得到数字证书。 CA中间证书࿱…...
ssm基于SSM的校内信息服务发布系统的设计与实现+vue
系统包含:源码论文 所用技术:SpringBootVueSSMMybatisMysql 免费提供给大家参考或者学习,获取源码看文章最下面 需要定制看文章最下面 目 录 摘要 1 Abstract 1 目 录 2 1绪论 4 1.1研究背景与意义 4 1.2国内外研究现状 4 1.3研究…...

Java 教程简介
Java 教程简介 Java 是 Sun Microsystems 公司于 1995 年 5 月推出的一种面向对象的编程语言和运行平台,由 James Gosling 和他的同事共同研发。当前,这个产品已被 Oracle 公司所收购。这篇教程将带你了解 Java 的一些基础知识和应用。 Java 系统简介 …...
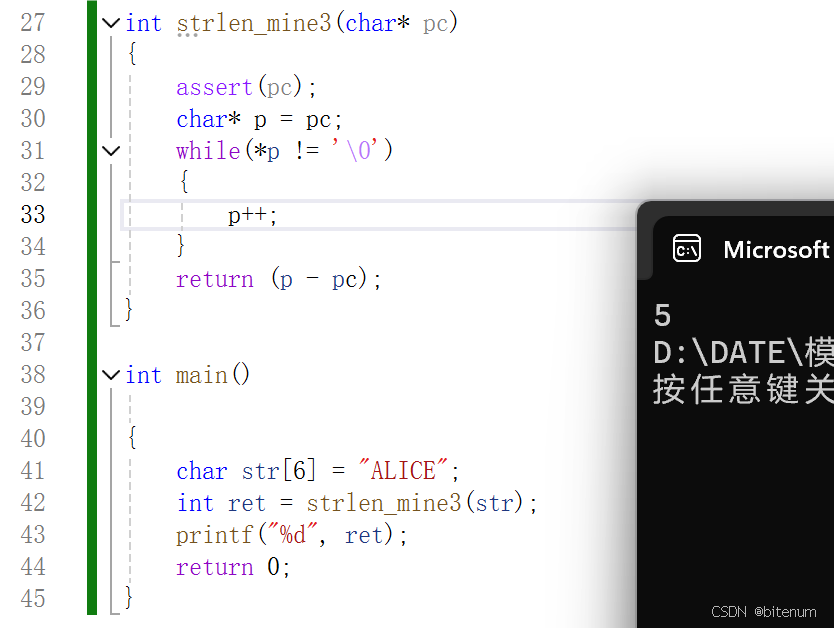
【C/C++】【三种方法】模拟实现strlen
学习目标: 使用代码模拟实现strlen。 逻辑: strlen 需要输入一个字符串数组类型的变量,并且返回一个整型类型的数据。strlen 需要计算字符串数组有多少个元素。 代码1:使用计数器 #define _CRT_SECURE_NO_WARNINGS 1 #include&…...

外贸平台开发多语言处理的三种方式
随着全球贸易的不断增长,外贸平台的多语言处理已成为提升用户体验和市场竞争力的重要因素。在开发外贸平台时,有多种方法可以实现多语言支持。本文将探讨三种主要的多语言处理方式:数据库级多语言支持、前端国际化框架以及内容管理系统&#…...

学习GCC
浅显易懂的GCC使用教程——初级篇_gcc -ddebug-CSDN博客 本文摘抄学习自上面的文章! GCC: GNU Compiler Collection: GNU编译器套件,属于一种编程语言编译器,其原名为GCC(GNU C Compiler),即GNU c语言编译器,虽然缩写…...

B2109 统计数字字符个数
B2109 统计数字字符个数 #include <iostream> using namespace std; # include <string.h> #include <ctype.h> #include <algorithm> int main(){ char str[256]; cin.getline(str,256); //fgets(str,256,stdin); int cnt 0; //for(size_t i 0…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...

TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析
TorchDynamo与TorchInductor:PyTorch编译器生态的完整解析 【免费下载链接】torchdynamo A Python-level JIT compiler designed to make unmodified PyTorch programs faster. 项目地址: https://gitcode.com/gh_mirrors/to/torchdynamo TorchDynamo 是一个…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...
与 NOT EXISTS 优化)
PostgreSQL Join 执行策略(Nested Loop、Hash Join、Merge Join)与 NOT EXISTS 优化
以集成数据压缩 SQL 优化为例,用大白话讲清楚 Nested Loop、Hash Join、Merge Join 三种执行策略。一、背景:一条慢 SQL 引发的思考 在对上游下发数据做压缩时,有这样一条 UPDATE SQL: -- ❌ 原始写法 UPDATE magellan_nk_order_i…...

你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次‘交叉验证’吧
你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次"交叉验证"当你在GEO数据库中下载了三个肺癌研究的差异表达结果,却发现三个DEG列表的重叠基因不到20%——这种令人沮丧的场景每天都在全球实验室上演。单项研究的差异分析结果就像…...

Arm Cortex-M的FP和MVE
Floating-point Support目前Arm architecture支持的floating-point extension版本是FPv5。FPv5提供了以下功能:单精度算术运算;可选的双精度算术运算;整数、双精度、单精度、和半精度格式之间的转换;用于浮点处理的寄存器…...

pi.dev 域名获赠,一文了解 Pi Agent Harness 项目开发、贡献等全方面信息
pi.dev 域名由 exe.dev 慷慨捐赠新贡献者提交的新问题和拉取请求(PR)默认会自动关闭。维护者会每天审核自动关闭的问题,详情请参阅 CONTRIBUTING.md。Pi Agent Harness 单仓库这里是 pi agent harness 项目的主页,其中包含我们可自…...

终极Gofile批量下载器深度解析:高效自动化文件获取的完整技术指南
终极Gofile批量下载器深度解析:高效自动化文件获取的完整技术指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作流中,技术人员经…...