[笔记] SQL 优化
一. 数据库设计优化
1. 选择合适的字段类型
设计表时,尽量选择存储空间小的字段类型:
- 整型字段:从
TINYINT、SMALLINT、INT到BIGINT。 - 小数类型:对于金额等需精确计算的数值使用
DECIMAL,避免使用FLOAT和DOUBLE。 - 字符串:根据实际长度选择
CHAR(定长)或VARCHAR(变长)。VARCHAR不宜超过5000字符;长度需求大的数据建议使用TEXT,并将大字段拆分到单独的表中
2. 确定字段的合理长度
字段长度表示字符数或字节数,例如VARCHAR(32)适用于用户名字段(通常为5到20个字符)。建议字段长度设为2的幂,如32、64、128等。
3. 控制表的字段数量
一张表的字段数量尽量控制在20个以内,以避免数据量过大导致查询效率低。如果字段较多,建议分拆为多张表。
4. 尽量定义字段为 NOT NULL
为防止空指针问题,并提升查询性能,除非有特殊需求,字段都应定义为NOT NULL,可以通过默认值或常量来填充字段。
5. 使用数值类型代替字符串
数值类型占用存储空间小、比较速度更快。
例子: 性别字段建议用数值(如0代表女生,1代表男生)而非字符串(如"WOMEN"、“MAN”)。
6. 评估并添加必要的索引
根据表的数据量和查询需求设置索引:
-
索引数量不宜过多(单表索引个数不超过5个)。
-
区分度低的字段(如性别)不适合建立索引。
-
可通过联合索引优化多列条件查询。
-
定期分析和优化索引
ANALYZE TABLE user_info_tab;
7. 避免使用MySQL保留字
避免库名、表名或字段名使用MySQL的保留字(如SELECT、DESC等),否则需要使用反引号引用,会增加代码复杂性。
8. 统一字符集的选择
字符集推荐使用utf8或utf8mb4以支持中英文及emoji。其他字符集如GBK仅适合中文环境,latin1适合仅支持英文的场景。
9. 数据冗余
在某些场景下,适当的数据冗余可以提高查询效率,例如在读多写少的应用中。
10. 使用分区表
对于大数据量的表,使用分区表可以提高查询性能。
示例:
-
范围分区(Range Partitioning):
- 根据某个字段的值范围进行分区。适用于时间戳、日期等有序字段。
CREATE TABLE sales (sale_id INT,sale_date DATE,amount DECIMAL(10,2) ) PARTITION BY RANGE (YEAR(sale_date)) (PARTITION p2019 VALUES LESS THAN (2020),PARTITION p2020 VALUES LESS THAN (2021),PARTITION p2021 VALUES LESS THAN (2022) ); -
列表分区(List Partitioning):
- 根据某个字段的特定值列表进行分区。适用于类别、地区等离散字段。
CREATE TABLE employees (emp_id INT,department VARCHAR(20) ) PARTITION BY LIST (department) (PARTITION p_sales VALUES IN ('Sales'),PARTITION p_marketing VALUES IN ('Marketing'),PARTITION p_it VALUES IN ('IT') ); -
哈希分区(Hash Partitioning):
- 根据某个字段的哈希值进行分区。适用于均匀分布的数据。
CREATE TABLE customers (cust_id INT,name VARCHAR(50) ) PARTITION BY HASH (cust_id) PARTITIONS 4; -
复合分区(Composite Partitioning):
- 结合多种分区策略,先按一种策略分区,再在每个子分区中按另一种策略分区。适用于复杂的数据分布。
CREATE TABLE sales (sale_id INT,sale_date DATE,region VARCHAR(20) ) PARTITION BY RANGE (YEAR(sale_date)) SUBPARTITION BY LIST (region) (PARTITION p2019 VALUES LESS THAN (2020) (SUBPARTITION p2019_north VALUES IN ('North'),SUBPARTITION p2019_south VALUES IN ('South')),PARTITION p2020 VALUES LESS THAN (2021) (SUBPARTITION p2020_north VALUES IN ('North'),SUBPARTITION p2020_south VALUES IN ('South')) );
二. 分析与调优
1. 使用 EXPLAIN 分析查询计划
EXPLAIN 可以帮助你了解查询的执行计划,找出潜在的性能瓶颈。
例子:
EXPLAIN SELECT * FROM orders WHERE user_id = 123;
2. 使用 PARTITION PRUNING 优化分区表查询
PARTITION PRUNING 可以显著提高分区表的查询性能,因为它可以跳过不需要的分区。
例子:
SELECT * FROM sales WHERE sale_date BETWEEN '2023-01-01' AND '2023-12-31';
3. 使用 EXPLAIN ANALYZE 深入分析查询性能
EXPLAIN ANALYZE 可以提供详细的查询执行计划和实际执行时间,帮助你更好地优化查询。
例子:
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 123;
4. 使用 OPTIMIZE TABLE 优化表性能
OPTIMIZE TABLE 可以回收未使用的空间,提高表的性能。
OPTIMIZE TABLE users;
5. 使用 ANALYZE TABLE 更新统计信息
ANALYZE TABLE 可以更新表的统计信息,帮助优化器生成更高效的查询计划。
例子:
ANALYZE TABLE users;
三. 查询语句优化
1. 避免使用 SELECT *,使用具体字段
反例:
SELECT * FROM employee;
正例:
SELECT id, name, age FROM employee;
原因: 使用具体字段可以节省资源、减少网络开销,且能避免回表查询。
2. 避免在 WHERE 子句中使用 OR
反例:
SELECT * FROM user WHERE userid=1 OR age=18;
正例:
-- 使用 UNION ALL
SELECT * FROM user WHERE userid=1
UNION ALL
SELECT * FROM user WHERE age=18;
原因:当 OR 操作符连接的条件涉及多个列时,数据库优化器可能无法有效地使用索引。特别是当这些列上有不同的索引时,优化器可能无法选择最优的索引组合。
3. 避免在 WHERE 子句中使用函数
反例:
SELECT * FROM users WHERE UPPER(username) = 'JOHN';
正例:
SELECT * FROM users WHERE username = 'JOHN';
原因: 在 WHERE 子句中使用函数会导致索引失效。
4. 避免在 WHERE 子句中对字段进行表达式操作
反例:
SELECT * FROM user WHERE age - 1 = 10;
正例:
SELECT * FROM user WHERE age = 11;
原因 : 表达式操作会增加额外的计算开销。数据库引擎需要对每一行数据进行表达式计算,然后再进行过滤,这会显著增加查询的执行时间。
5. 使用 LIMIT 避免不必要的数据返回
反例:
SELECT id, order_date FROM order_tab WHERE user_id=666 ORDER BY create_date DESC;
正例:
SELECT id, order_date FROM order_tab WHERE user_id=666 ORDER BY create_date DESC LIMIT 1;
原因: LIMIT 提升查询效率,避免多余的数据返回。
6. 批量操作(插入、删除、查询)
反例:
for(User u : list) {INSERT INTO user(name, age) VALUES(#name#, #age#);
}
正例:
INSERT INTO user(name, age) VALUES
<foreach collection="list" item="item" index="index" separator=",">(#{item.name}, #{item.age})
</foreach>
原因: 批量插入性能更优。
7. 使用 UNION ALL 替换 UNION(无重复记录时)
反例:
SELECT * FROM user WHERE userid=1
UNION
SELECT * FROM user WHERE age=10;
正例:
SELECT * FROM user WHERE userid=1
UNION ALL
SELECT * FROM user WHERE age=10;
原因: UNION 会排序和合并,UNION ALL 则省去这一步。
8. 避免在索引列上使用内置函数
反例:
SELECT * FROM orders WHERE MONTH(order_date) = 10 AND YEAR(order_date) = 2023;
正例:
SELECT * FROM orders WHERE order_date >= '2023-10-01' AND order_date < '2023-11-01';
原因: 索引列上使用函数会导致索引失效。
9. 在 GROUP BY 前进行条件过滤
反例:
SELECT user_id, SUM(amount) AS total_amount
FROM orders
GROUP BY user_id
HAVING city = '北京';
正例:
SELECT user_id, SUM(amount) AS total_amount
FROM orders
WHERE city = '北京'
GROUP BY user_id;
10. 优化 LIKE 语句
反例:
SELECT userId, name FROM user WHERE userId LIKE '%123';
正例:
SELECT userId, name FROM user WHERE userId LIKE '123%';
原因: % 放在前面会导致索引失效。
11. 使用小表驱动大表
例子: 假设我们有个客户表和一个订单表。其中订单表有10万记录,客户表只有1000行记录。现在要查询下单过的客户信息,可以这样写:
正例:
SELECT * FROM customers c
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.id
);
使用 IN 实现:
SELECT * FROM customers
WHERE id IN (SELECT customer_id FROM orders
);
原因: EXISTS 会逐行扫描 customers 表(即小表),对每一行 c.id,在 orders 表(大表)中检查是否有 customer_id = c.id 的记录。
12. IN 查询的元素不宜太多
反例:
SELECT user_id, name FROM user WHERE user_id IN (1,2,3...1000000);
正例: 分批进行,比如每批200个:
SELECT user_id, name FROM user WHERE user_id IN (1,2,3...200);
原因: 如果 IN 后面的元素过多,即使后面的条件加了索引,还是会影响性能。
13. 优化 LIMIT 分页
反例:
SELECT id, name, balance FROM account WHERE create_time > '2020-09-19' LIMIT 100000, 10;
正例: 使用标签记录法:
SELECT id, name, balance FROM account WHERE id > 100000 LIMIT 10;
延迟关联法:
SELECT acct1.id, acct1.name, acct1.balance
FROM account acct1
INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' LIMIT 100000, 10
) AS acct2
ON acct1.id = acct2.id;
14. 避免返回过多数据量
反例:
SELECT * FROM LivingInfo WHERE watchId = userId AND watchTime >= DATE_SUB(NOW(), INTERVAL 1 YEAR);
正例:
-- 分页查询
SELECT * FROM LivingInfo WHERE watchId = userId AND watchTime >= DATE_SUB(NOW(), INTERVAL 1 YEAR) LIMIT offset, pageSize;
原因:
- 查询效率: 当返回的数据量过大时,查询所需的时间会显著增加,导致数据库性能下降。
- 网络传输: 大量数据的传输会占用网络带宽,可能导致网络拥堵和延迟。
- 减少返回的数据量可以降低网络传输的负担,提高数据传输效率。
15. 优先使用连接查询而非子查询
反例:
SELECT * FROM customers WHERE id IN (SELECT customer_id FROM orders);
正例:
SELECT DISTINCT c.*
FROM customers c
JOIN orders o ON c.id = o.customer_id;
原因: 使用子查询可能会创建临时表。
16. INNER JOIN、LEFT JOIN、RIGHT JOIN,优先使用 INNER JOIN,如果是 LEFT JOIN,左边表结果尽量小
反例:
SELECT * FROM tab1 t1 LEFT JOIN tab2 t2 ON t1.size = t2.size WHERE t1.id > 2;
正例:
SELECT * FROM (SELECT * FROM tab1 WHERE id > 2) t1
LEFT JOIN tab2 t2 ON t1.size = t2.size;
原因: 如果 INNER JOIN 是等值连接,返回的行数可能较少,性能更好。使用 LEFT JOIN 时,左边表数据结果尽量小,条件尽量放在左边处理。
17. 避免 != 或 <> 操作符
反例:
SELECT age, name FROM user WHERE age <> 18;
正例: 分为两个查询:
SELECT age, name FROM user WHERE age < 18;
SELECT age, name FROM user WHERE age > 18;
原因: 某些情况下,使用 != 或 <> 操作符可能导致索引失效,从而影响查询性能。这是因为 != 和 <> 操作符通常会导致数据库引擎无法高效地利用索引。
18. 使用联合索引时遵循最左匹配原则
例子: 联合索引 (userId, age),查询 userId 和 age 时优先使用 userId。
表结构:
CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT,`userId` int(11) NOT NULL,`age` int(11) DEFAULT NULL,`name` varchar(255) NOT NULL,PRIMARY KEY (`id`),KEY `idx_userid_age` (`userId`, `age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
反例:
SELECT * FROM user WHERE age = 10;
正例:
SELECT * FROM user WHERE userId = 10 AND age = 10;
正例:
SELECT * FROM user WHERE userId = 10;
原因: 使用联合索引时遵循最左匹配原则是非常重要的,这有助于数据库引擎高效地利用索引,从而提高查询性能。最左匹配原则意味着在查询条件中,从联合索引的最左边开始匹配索引列,直到遇到不匹配的列为止。
19. 对 WHERE 和 ORDER BY 涉及的列建索引
反例:
SELECT * FROM user WHERE address = '深圳' ORDER BY age;
正例:
ALTER TABLE user ADD INDEX idx_address_age (address, age);
20. 使用覆盖索引
正例:
SELECT id, name FROM user WHERE userId LIKE '123%';
21. 删除冗余索引
反例:
KEY `idx_userId` (`userId`)
KEY `idx_userId_age` (`userId`, `age`)
正例:
-- 删除 `userId` 索引,因为组合索引(A,B)相当于创建了(A)和(A,B)索引
KEY `idx_userId_age` (`userId`, `age`)
原因: 重复的索引需要维护,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能。
22. 使用 INDEX HINTS 强制使用特定索引
例子:
SELECT * FROM users USE INDEX (idx_username) WHERE username = 'john';
原因: 在某些情况下,优化器可能选择错误的索引,使用 INDEX HINTS 可以强制使用特定索引。
23. 使用 FULLTEXT 索引进行全文搜索
例子:
CREATE FULLTEXT INDEX idx_fulltext ON articles (content);SELECT * FROM articles WHERE MATCH(content) AGAINST('search term');
原因: FULLTEXT 索引可以提高全文搜索的性能。
24. 避免在 ORDER BY 子句中使用表达式
反例:
SELECT * FROM users ORDER BY LENGTH(username);
正例:
SELECT * FROM users ORDER BY username;
原因: 在 ORDER BY 子句中使用表达式会导致索引失效。
25. 避免超过3个以上的表连接
原因: 连接表越多,编译的时间和开销也就越大。把连接表拆开成较小的几个执行,可读性更高。
26. 使用 CASE 语句替代复杂的 IF 条件
例子:
SELECT id, CASE WHEN age < 18 THEN 'Minor'WHEN age BETWEEN 18 AND 60 THEN 'Adult'ELSE 'Senior'END AS age_group
FROM users;
原因: CASE 语句可以使逻辑更清晰,提高可读性和维护性。
27. 使用 WITH 子句(Common Table Expressions, CTE)
例子:
WITH active_users AS (SELECT id FROM users WHERE status = 'active'
)
SELECT * FROM orders WHERE user_id IN (SELECT id FROM active_users);
原因: CTE 可以使查询结构更清晰,便于理解和维护。
28. 避免使用 DISTINCT 除非必要
反例:
SELECT DISTINCT user_id FROM orders;
正例:
SELECT user_id FROM orders GROUP BY user_id;
原因: DISTINCT 会进行额外的排序和去重操作,影响性能。如果只需要去重,可以使用 GROUP BY。
29. 使用 PARTITION PRUNING 优化分区表查询
例子:
SELECT * FROM sales WHERE sale_date BETWEEN '2023-01-01' AND '2023-12-31';
原因: PARTITION PRUNING 可以显著提高分区表的查询性能,因为它可以跳过不需要的分区。
四. 补充
1. 合理利用视图(View)进行复杂查询
正例:
CREATE VIEW view_user_orders AS
SELECT u.id, u.name, o.order_id, o.amount
FROM user u JOIN orders o ON u.id = o.user_id;-- 使用视图查询
SELECT * FROM view_user_orders WHERE amount > 100;
2. 使用表分区(Partitioning)优化大表性能
正例:
CREATE TABLE sales (sale_id INT,sale_date DATE,amount DECIMAL(10,2)
) PARTITION BY RANGE (YEAR(sale_date)) (PARTITION p2019 VALUES LESS THAN (2020),PARTITION p2020 VALUES LESS THAN (2021),PARTITION p2021 VALUES LESS THAN (2022)
);
3. 合理使用存储过程(Stored Procedure)来减少多次 SQL 交互
正例:
CREATE PROCEDURE update_and_select(IN user_id INT)
BEGINUPDATE users SET last_login = NOW() WHERE id = user_id;SELECT * FROM users WHERE id = user_id;
END;
4. 使用临时表(Temporary Tables)处理复杂查询
正例:
CREATE TEMPORARY TABLE temp_users AS
SELECT id FROM users WHERE status = 'active';SELECT * FROM orders WHERE user_id IN (SELECT id FROM temp_users);
原因: 临时表可以在处理复杂查询时提高性能,特别是在多次使用相同子查询结果的情况下。
5. 使用适当的隔离级别
原因: 在高并发环境中选择适当的事务隔离级别(如 READ COMMITTED),可以避免不必要的锁竞争和阻塞,提升并发效率。
6. 避免在事务中执行非必要的操作
原因: 在事务中应避免执行耗时操作,比如网络请求或复杂计算,以减少锁的持有时间。优先确保事务操作集中在必要的数据变更上。
7. 使用批量更新或删除
正例:
-- 分批删除
DELETE FROM orders WHERE status = 'obsolete' LIMIT 1000;
相关文章:

[笔记] SQL 优化
一. 数据库设计优化 1. 选择合适的字段类型 设计表时,尽量选择存储空间小的字段类型: 整型字段:从TINYINT、SMALLINT、INT到BIGINT。小数类型:对于金额等需精确计算的数值使用DECIMAL,避免使用FLOAT和DOUBLE。字符串…...

【InfluxDB】InfluxDB 2.x基础概念及原理
InfluxDB简介 什么是时序数据库 时序数据库,全称时间序列数据库(Time Series Database,TSDB),用于存储大量基于时间的数据。时序数据库支持时序数据的快速写入、持久化,多维度查询、聚合等操作࿰…...

.net Core 使用Panda.DynamicWebApi动态构造路由
我们以前是通过创建controller来创建API,通过controller来显示的生成路由,这里我们讲解下如何不通过controller,构造API路由 安装 Panda.DynamicWebApi 1.2.2 1.2.2 Swashbuckle.AspNetCore 6.2.3 6.2.3添加ServiceAction…...

Spring框架和Spring Boot框架都使用注解来简化配置和提高开发效率,但它们之间存在一些区别
Spring框架和Spring Boot框架都使用注解来简化配置和提高开发效率,但它们之间存在一些区别: Spring框架注解: Autowired:自动导入对象到类中,被注入的类需要被Spring容器管理。Component、Repository、Service、Contro…...

从数据提取到管理:TextIn平台的全面解析与产品体验
一、引言 在现代信息时代,文档解析和管理已经成为企业和开发者不可或缺的工具。TextIn是合合信息旗下的一款智能文档处理平台,为开发者和企业提供高效、精准的文档解析工具,帮助用户轻松应对各种复杂的文档处理需求。本文将深入探讨TextIn的…...

2024 Rust现代实用教程 Error错误处理
文章目录 一、错误处理之:Result、Option以及panic!宏1.Result2.Option3.panic! 二、错误处理之:unwrap()与?1.unwrap()2.?运算符 三、自定义一个Error类型参考 一、错误处理之:Result、Option以及panic!宏 Rust中的错误可以分为…...
)
android 逆向破解360加固(MT管理器反编译)
1.需要准备的环境MT管理器 2.一台root手机 3,需要给app脱壳https://nop.gs/在这里脱壳 4.将脱壳的文件解压之后解压 5.用MT管理器打开需要反编译破解的app 6.然后把脱壳的classes.dex添加到破解的app里面删除原来的classes.dex 7.删除360加固的so,so在assets文件里面删除libjia…...

使用 SSH 蜜罐提升安全性和记录攻击活动
文章目录 使用 SSH 蜜罐提升安全性和记录攻击活动前言整体逻辑讲解安全最佳实践蜜罐的类型与选择数据分析与响应进一步学习资源修改 SSH 服务端口部署 FakeSSHFakeSSH 简介部署步骤记录攻击 部署 SSHSameSSHSame 简介部署步骤观察攻击行为 总结 使用 SSH 蜜罐提升安全性和记录攻…...

无人机拦截捕获/直接摧毁算法详解!
一、无人机拦截捕获算法 网捕技术 原理:抛撒特殊设计的网具,捕获并固定无人机。 特点: 适用于小型无人机。 对无人机的损害较小,基本不影响其后续使用。 捕获成功率较高,且成本相对较低。 应用实例:…...

后端eclipse——文字样式:UEditor富文本编辑器引入
目录 1.富文本编辑器的优点 2.文件的准备 3.文件的导入 导入到项目: 导入到html文件: 编辑 4.富文本编辑器的使用 1.富文本编辑器的优点 我们从前端写入数据库时,文字的样式具有局限性,不能存在换行,更改字体…...
)
thinkphp6 redis 哈希存储方式以及操作函数(笔记)
逻辑:如果redis里没有指定表数据就进行存储再输出,如果有就直接输出,代码优化后几万条数据从数据库入redis也是三四秒的时间,数据以json方式存储:key用于数据ID 跟数据库数据ID同步,value用于存储整个字段包…...
「Mac畅玩鸿蒙与硬件28」UI互动应用篇5 - 滑动选择器实现
本篇将带你实现一个滑动选择器应用,用户可以通过滑动条选择不同的数值,并实时查看选定的值和提示。这是一个学习如何使用 Slider 组件、状态管理和动态文本更新的良好实践。 关键词 UI互动应用Slider 组件状态管理动态数值更新用户交互 一、功能说明 在…...

【嵌入式】STM32中的SPI通信
SPI是由摩托罗拉公司开发的一种通用数据总线,其中由四根通信线,支持总线挂载多设备(一主多从),是一种同步全双工的协议。主要是实现主控芯片和外挂芯片之间的交流。这样可以使得STM32可以访问并控制各种外部芯片。本文…...

后端:Spring、Spring Boot-配置、定义bean
文章目录 1. 什么是Bean,如何配置2. 如何配置bean2.1 使用注解Bean2.2 使用注解Import 1. 什么是Bean,如何配置 被spring容器所管理的对象被称为bean,管理方式可以有纯xml文件方式、注解方式进行管理(比如注解Component)。 在Spring Boot中&…...

【Git】Git 远程仓库命令详解
目录 引言1. Git Fetch、Git Pull 和 Git Push 简介1.1 概念总结1.2 图示概念 2. 分支的概念2.1 分支定义2.2 分支的特点2.3 分支示例2.4 基本操作命令2.5 分支的使用场景 3. Git Fetch 用法3.1 基本命令3.2 获取特定分支3.3 查看更新内容3.4 使用示例3.5 适用场景 4. Git Pull…...

html简易流程图
效果图 使用htmlcssjs,无图片,没用Canvas demo: <!DOCTYPE html> <html> <head><link href"draw.css" rel"stylesheet" /><script src"draw.js" type"text/javascript"></…...
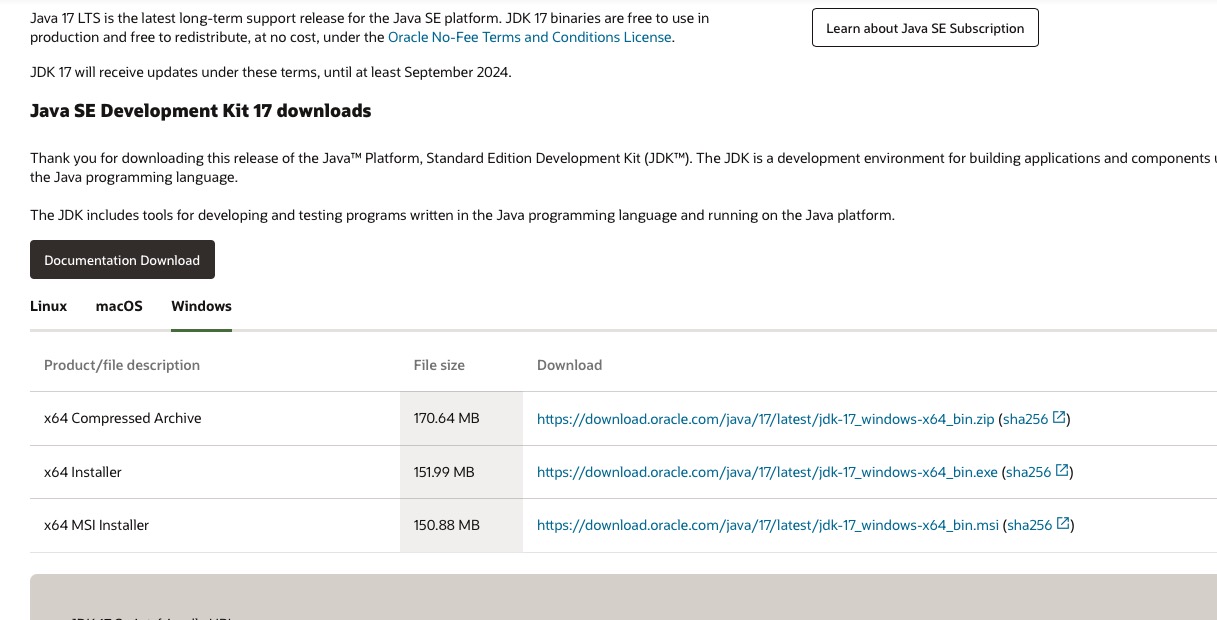
Java 入门
目录 Java简介 Java JDK开发环境配置 第一个Java程序 Java标识符与关键字 Java注释 Java常量 Java变量的定义和使用 Java简介 Java简介: Java是由Sun Microsystems公司于1995年推出的一门面向对象的高级程序设计语言,可以运行于多个平台,其…...

JVM基本结构和垃圾回收机制
一、JVM基本结构 Java虚拟机(JVM, Java Virtual Machine)是Java程序执行的环境,其基本结构可以分为以下几个主要部分: 类加载器子系统(Class Loader Subsystem): 负责加载Java类文件到内存中。…...

CentOS 7 安装 ntp,自动校准系统时间
1、安装 ntp yum install ntp 安装好后,ntp 会自动注册成为服务,服务名称为 ntpd 2、查看当前 ntpd 服务的状态 systemctl status ntpd 3、启动 ntpd 服务、查看 ntpd 服务的状态 systemctl start ntpdsystemctl status ntpd 4、设置 ntpd 服务开机启…...

Spring Boot 配置文件启动加载顺序
前言 Spring Boot的启动加载顺序是一个涉及多个步骤和组件的过程。Spring Boot通过一系列默认设置简化了应用程序的配置,使得开发者能够快速地搭建和部署应用。为了实现这一目标,Spring Boot采用了一种分层和优先级机制来加载配置文件。 一、Spring Bo…...

亿万富翁不再相信比特币
亿万富翁首次公开称不再相信比特币的「数字黄金」叙事。对比特币而言,或许是一个重要转折点。5月22日,亿万富翁投资者马克库班表示, 在对比特币作为抵御法币疲软和地缘政治不稳定对冲工具的作用失去信心后, 他已经卖掉大部分比特币持仓。净资产约为100亿…...

AutoCAD字体缺失问题如何通过智能插件彻底解决?
AutoCAD字体缺失问题如何通过智能插件彻底解决? 【免费下载链接】FontCenter AutoCAD自动管理字体插件 项目地址: https://gitcode.com/gh_mirrors/fo/FontCenter 在AutoCAD设计工作中,字体缺失是每个CAD工程师都曾遭遇的噩梦。当打开同事发来的图…...

基于Arduino与ADXL335的自制地震预警系统:从传感器原理到多点联动实现
1. 项目概述与核心思路最近在捣鼓一个挺有意思的玩意儿——一个能自主工作的地震预警系统。这可不是什么高深莫测的科研项目,而是基于一些常见的电子模块,自己动手就能搭建起来的实用装置。它的核心目标很明确:当检测到建筑物出现异常振动时&…...

将 Claude Code 的 API 请求无缝迁移至 Taotoken 平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将 Claude Code 的 API 请求无缝迁移至 Taotoken 平台 如果你正在使用 Claude Code 作为编程助手,并且希望将其后端 AP…...
从主题到视频:Pixelle-Video如何用AI重构你的内容创作流程
从主题到视频:Pixelle-Video如何用AI重构你的内容创作流程 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 想象一下…...

如何在Blender中实现专业级MMD模型动画制作:5步完整解决方案
如何在Blender中实现专业级MMD模型动画制作:5步完整解决方案 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

猫抓:5步掌握网页资源嗅探工具,轻松下载全网视频
猫抓:5步掌握网页资源嗅探工具,轻松下载全网视频 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的精彩视频无…...

RL-ARM CAN迁移至CMSIS-RTOS的实践指南
1. 从RL-ARM CAN到CMSIS-RTOS的迁移背景在嵌入式开发领域,随着Keil MDK版本的迭代,RL-ARM库中的CAN组件逐渐向MDK Middleware过渡。许多基于MDK v4和早期v5版本开发的项目,都使用了RL-ARM库中的CAN驱动实现。当开发者需要将项目升级到较新的M…...

从lsusb输出到硬件信息库:如何查询Linux中USB设备的厂商和型号
从lsusb输出到硬件信息库:Linux下USB设备厂商与型号的深度解析 当你插入一个陌生的USB设备到Linux系统时,终端里 lsusb 命令输出的那一串神秘代码 ID xxxx:xxxx 往往让人摸不着头脑。这些十六进制数字背后隐藏着设备的真实身份——厂商和具体型号。本…...

Windows 11热键冲突别抓狂!用OpenArk一键揪出‘元凶’并释放你的Ctrl+C
Windows 11热键冲突终极排查指南:用OpenArk精准定位并解决问题每次按下CtrlC却毫无反应,或者发现AltTab突然失效时,那种挫败感简直让人抓狂。作为每天要与数十个软件打交道的设计师,我深刻理解热键冲突对工作效率的致命影响。本文…...