基于 EventBridge + DashVector 打造 RAG 全链路动态语义检索能力
作者:肯梦
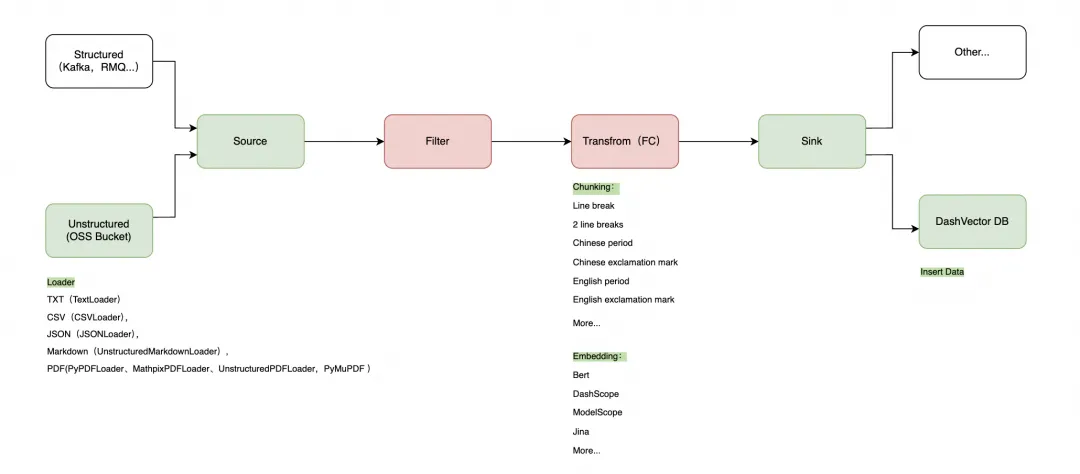
本文将演示如何使用事件总线(EventBridge),向量检索服务(DashVector),函数计算(FunctionCompute)结合灵积模型服务 [ 1] 上的 Embedding API [ 2] ,来从 0 到 1 构建基于文本索引的构建+向量检索基础上的语义搜索能力。具体来说,我们将基于 OSS 文本文档动态插入数据,进行实时的文本语义搜索,查询最相似的相关内容。
本文中将用到事件总线(EventBridge),它是阿里云提供的一款无服务器事件总线服务,支持阿里云服务、自定义应用、SaaS 应用以标准化、中心化的方式接入,并能够以标准化的 CloudEvents 1.0 协议在这些应用之间路由事件,帮助您轻松构建松耦合、分布式的事件驱动架构。
RAG 背景概述
大语言模型(LLM)作为自然语言处理领域的核心技术,具有丰富的自然语言处理能力。但其训练语料库具有一定的局限性,一般由普适知识、常识性知识,如维基百科、新闻、小说,和各种领域的专业知识组成。导致 LLM 在处理特定领域的知识表示和应用时存在一定的局限性,特别对于垂直领域内,或者企业内部等私域专属知识。
实现专属领域的知识问答的关键,在于如何让 LLM 能够理解并获取存在于其训练知识范围外的特定领域知识。同时可以通过特定 Prompt 构造,提示 LLM 在回答特定领域问题的时候,理解意图并根据注入的领域知识来做出回答。在通常情况下,用户的提问是完整的句子,而不像搜索引擎只输入几个关键字。这种情况下,直接使用关键字与企业知识库进行匹配的效果往往不太理想,同时长句本身还涉及分词、权重等处理。相比之下,倘若我们把提问的文本,和知识库的内容,都先转化为高质量向量,再通过向量检索将匹配过程转化为语义搜索,那么提取相关知识点就会变得简单而高效。
本文将介绍如何构建一个完全动态的 RAG 入库方案,通过 EventBridge 拉取 OSS 非结构化数据,同时将数据投递至 DashVector 向量数据库,从而实现完整的 RAG Ingestion 流程。
流程概述
数据集成(Ingestion)
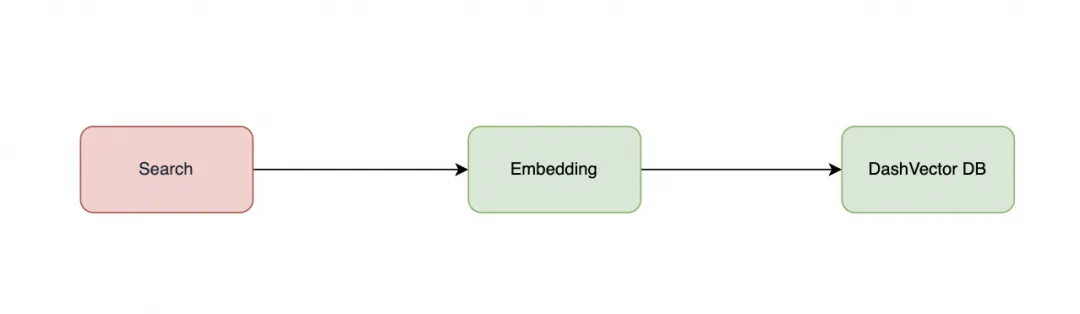
数据检索(Search)
操作流程
前提条件
- DashScope 控制台开通灵积模型服务,并获得 API-KEY 的获取与配置。
- 开通 DashVector 向量检索服务,并获得 API-KEY 的获取与配置。
- 开通 OSS 服务。
- 开通 FC 服务。
- 开通 EventBridge 服务。
开通灵积模型服务
- 点击进入 DashScope 控制台 [ 3] ,开通灵积相关服务
- 点击进入“API-KEY”管理,获取相关 KEY 信息
开通 DashVector 服务
- 若第一次配置,请点击“新建 DashVector Cluster [ 4] ”,跳转创建新的 Cluster;点击“创建免费 Cluster”快速体验创建向量数据库
2. 选择“立即购买”

3. 点击创建“Collection”
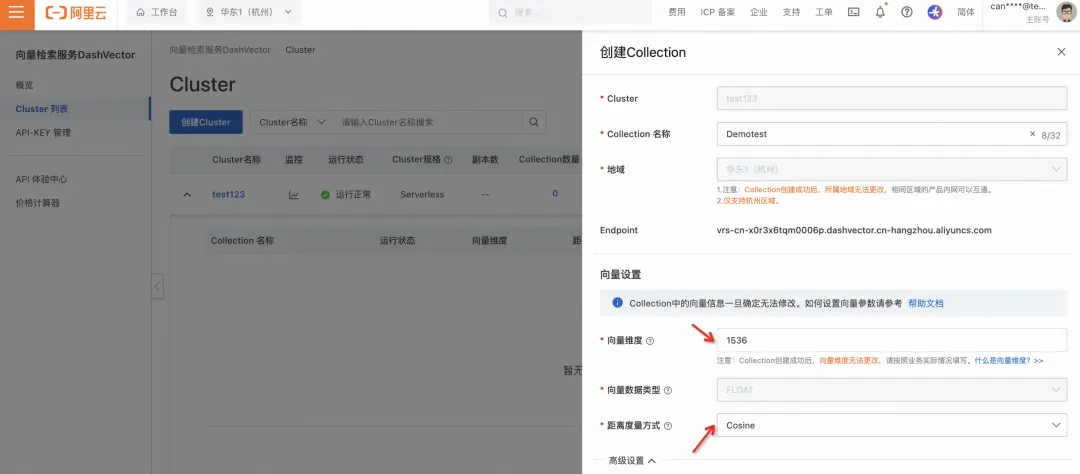
4. 填写纬度为“1536”,距离度量方式“Cosine”,点击“确认”
5. 点击“API-KEY 管理”,获取 DashVector 的 API KEY
创建 Ingestion 数据集成任务
1.1 进入 EventBridge 控制台 [ 5]
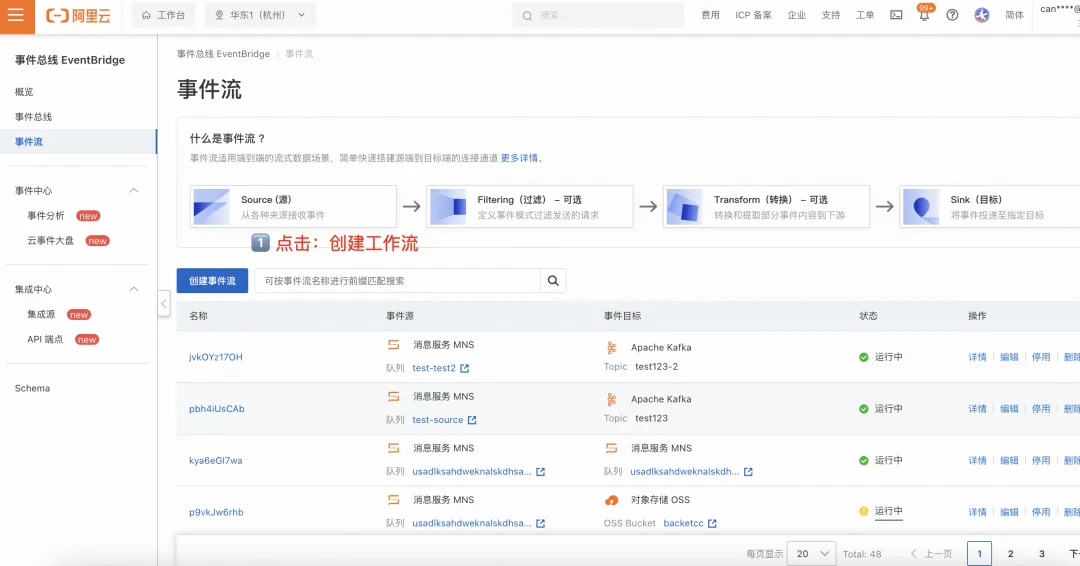
1.2 配置 OSS 源
- OSS Bucket:选择空白存储桶实验,若无请自行创建;
- OSS 前缀:该项可根据诉求填写,若无前缀 EB 将拉取整个 Bucket 内容;本次演示不配置;
- 文档加载:目前支持解析 TextLoder 作为文档加载器;
- 加载模式:“单文档加载”单个文件作为一条数据加载,“分块加载”按照分隔符加载数据;本次演示使用单文档加载。
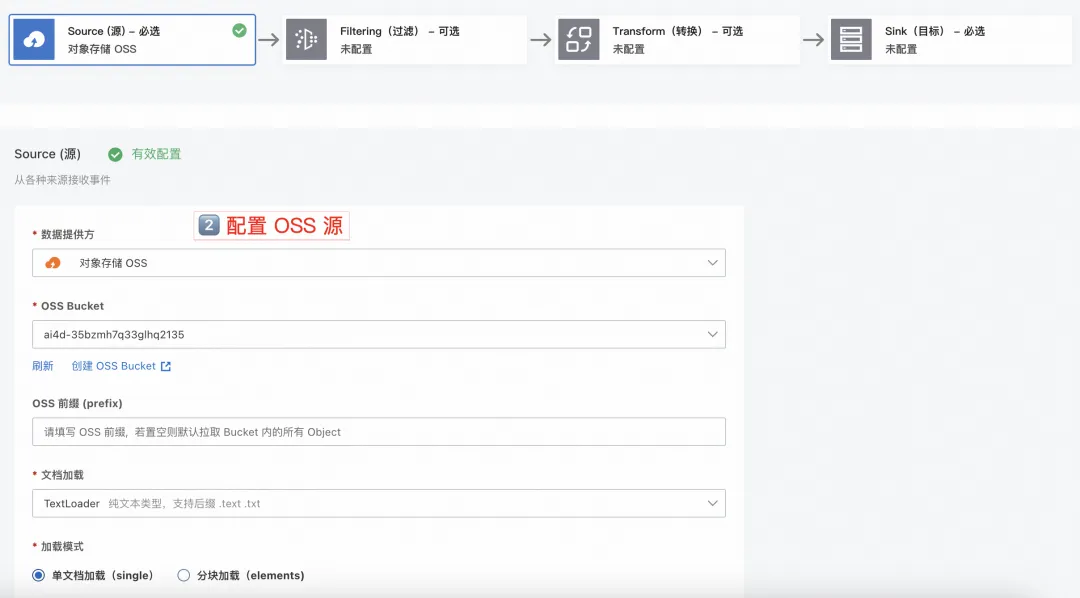
1.3 配置过滤
可根据诉求添加过滤规则,本次演示使用“匹配全部事件”。
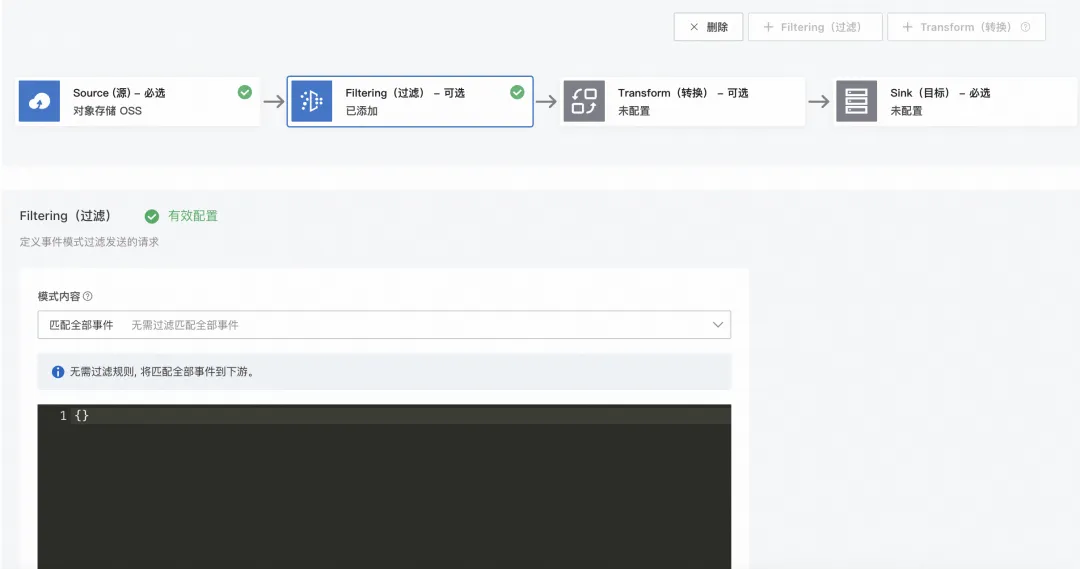
1.4 配置转换
转换部分主要是将原始数据转成向量化数据,为投递至 DashVector 做数据准备。
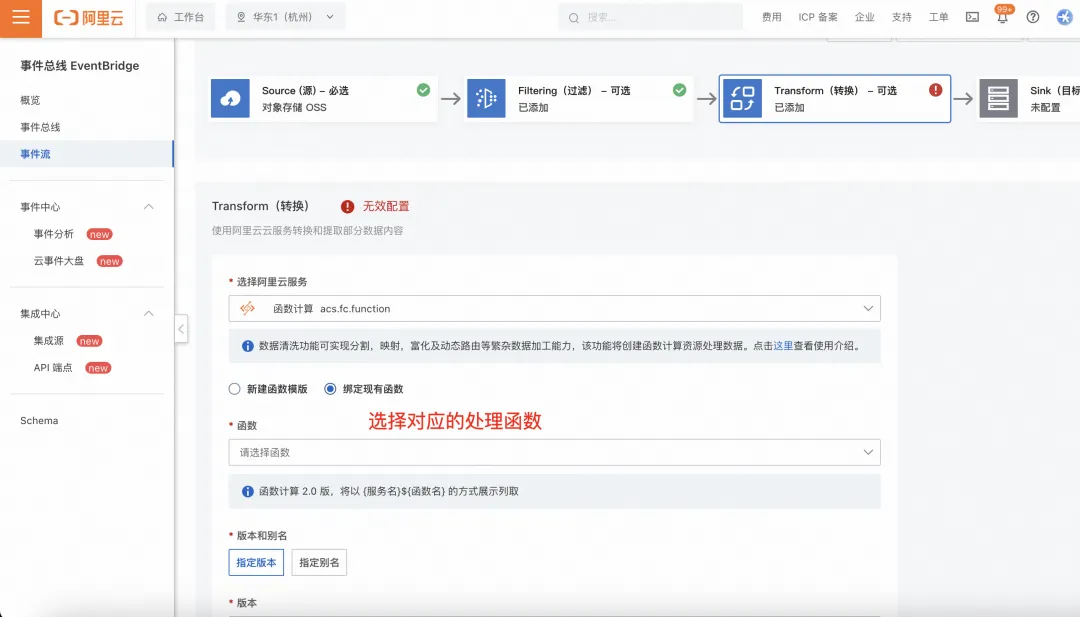
函数代码如下,函数环境为 Python 3.10:
# -*- coding: utf-8 -*-
import os
import ast
import copy
import json
import logging
import dashscope
from dashscope import TextEmbedding
from http import HTTPStatuslogger = logging.getLogger()
logger.setLevel(level=logging.INFO)dashscope.api_key='Your-API-KEY'def handler(event, context):evt = json.loads(event)evtinput = evt['data']resp = dashscope.TextEmbedding.call(model=dashscope.TextEmbedding.Models.text_embedding_v1,api_key=os.getenv('DASHSCOPE_API_KEY'), input= evtinput )if resp.status_code == HTTPStatus.OK:print(resp)else:print(resp)return resp
🔔 注意: 需手动安装相关函数环境,相关文档参考《为函数安装第三方依赖》 [ 6] 。
pip3 install dashvector dashscope -t .
返回样例:
{"code": "","message": "","output": {"embeddings": [{"embedding": [-2.192838430404663,-0.703125,... ...-0.8980143070220947,-0.9130208492279053,-0.520526111125946,-0.47154948115348816],"text_index": 0}]},"request_id": "e9f9a555-85f2-9d15-ada8-133af54352b8","status_code": 200,"usage": {"total_tokens": 3}
}
1.5 配置向量数据库 Dashvector
选择创建好的向量数据库。
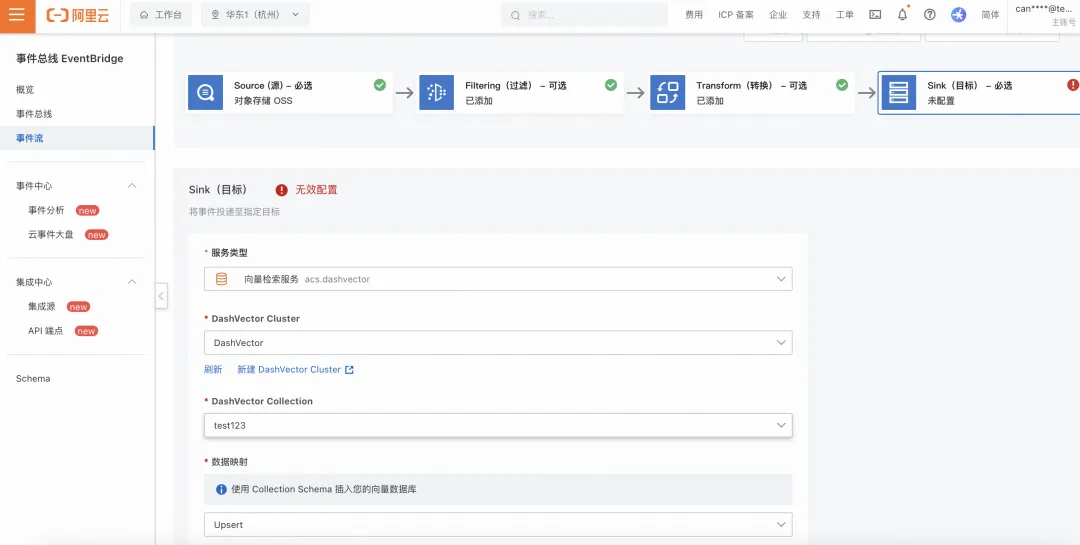
- 数据映射:选择 Upsert 方式插入;
- 向量:填写上游 Dashscope 的 TextEmbedding 投递的向量信息 $.output. embeddings[0].embedding;
- 鉴权配置:获取的 DashVector API-KEY 参数。

创建 Search 数据检索任务
在进行数据检索时,需要首先对数据进行 embedding,然后将 embedding 后的向量值与数据库值做检索排序。最后填写 prompt 模版,通过自然语言理解和语义分析,理解数据检索意图。
该任务可以部署在云端函数计算,或者直接在本地环境执行;首先,我们创建 embedding.py,将需要检索的问题进行文本向量化,代码如下所示:
embedding.py
import os
import dashscope
from dashscope import TextEmbeddingdef generate_embeddings(news):rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,input=news)embeddings = [record['embedding'] for record in rsp.output['embeddings']]return embeddings if isinstance(news, list) else embeddings[0]if __name__ == '__main__':dashscope.api_key = '{your-dashscope-api-key}'
然后,创建 search.py 文件,并将如下示例代码复制到 search.py 文件中,通过 DashVector 的向量检索能力来检索相似度的最高的内容。search.py
from dashvector import Clientfrom embedding import generate_embeddingsdef search_relevant_news(question):# 初始化 dashvector clientclient = Client(api_key='{your-dashvector-api-key}',endpoint='{your-dashvector-cluster-endpoint}')# 获取存入的集合collection = client.get('news_embedings')assert collection# 向量检索:指定 topk = 1 rsp = collection.query(generate_embeddings(question), output_fields=['raw'],topk=1)assert rspreturn rsp.output[0].fields['raw']
创建 answer.py 文件,我们就可以按照特定的模板作为 prompt 向 LLM 发起提问了,在这里我们选用的 LLM 是通义千问(qwen-turbo),代码示例如下:
answer.py
from dashscope import Generationdef answer_question(question, context):prompt = f'''请基于```内的内容回答问题。"```{context}```我的问题是:{question}。'''rsp = Generation.call(model='qwen-turbo', prompt=prompt)return rsp.output.text
最后,创建 run.py 文件,并将如下示例代码复制到 run.py 文件中,并最终执行 run.py 文件。(验证时,可在绑定的 OSS Bucket 上传需要被检索的知识库信息。)
import dashscopefrom search import search_relevant_news
from answer import answer_questionif __name__ == '__main__':dashscope.api_key = '{your-dashscope-api-key}'question = 'EventBridge 是什么,它有哪些能力?'context = search_relevant_news(question)answer = answer_question(question, context)print(f'question: {question}\n' f'answer: {answer}')
总结
从本文的范例中,我们可以比较方便的使用 EventBridge 提供的 OSS To DashVector 离线数据流导入能力,开箱即用的构建强大向量检索服务能力,这些能力和各个 AI 模型结合,能够衍生多样的 AI 应用的可能。同样,Transform 部分使用了函数计算能力,可以更灵活的制定想要的 Split 切分算法,提供更灵活且具备生产力的 RAG 方案。
相关链接:
[1] 灵积模型服务
https://dashscope.aliyun.com/
[2] Embedding API
https://help.aliyun.com/zh/dashscope/developer-reference/text-embedding-api-details
[3] DashScope 控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fdashscope.console.aliyun.com%2Foverview&clearRedirectCookie=1&lang=zh
[4] 新建 DashVector Cluster
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fdashvector.console.aliyun.com%2Fcn-hangzhou%2Fcluster&clearRedirectCookie=1&lang=zh
[5] EventBridge 控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Feventbridge.console.aliyun.com%2F&clearRedirectCookie=1&lang=zh
[6] 《为函数安装第三方依赖》
https://help.aliyun.com/zh/functioncompute/fc-3-0/user-guide/install-third-party-dependencies-for-a-function
相关文章:
基于 EventBridge + DashVector 打造 RAG 全链路动态语义检索能力
作者:肯梦 本文将演示如何使用事件总线(EventBridge),向量检索服务(DashVector),函数计算(FunctionCompute)结合灵积模型服务 [ 1] 上的 Embedding API [ 2] ࿰…...

【golang/navmesh】使用recast navigation进行寻路
目录 说在前面安装使用可视化 说在前面 go version:1.20.2 linux/amd64操作系统:wsl2detour-go版本:v0.2.0github:这里,求star! 安装 使用go mod安装即可go get github.com/o0olele/detour-go使用 使用场景模型构建n…...

【软考】Redis不同的数据类型和应用场景。
Redis的不同数据类型和对应的应用场景: Redis 数据类型及其应用场景 String(字符串) 特点:简单的值存储,支持二进制数据。应用场景: 缓存用户会话。缓存小的配置文件。缓存计数器。文章浏览量࿰…...

java 对人名和电话 脱敏-replaceAll
学习了《正则匹配人名》和《正则匹配电话号码》,如果要一起进行脱敏处理,改怎么做? 脱敏的,考虑配置规则,进行匹配的方式进行处理: 脱敏规则: DesensitizationRules Data public class Desens…...

计算机网络:网络层 —— 网络地址转换 NAT
文章目录 网络地址转换 NAT 概述最基本的 NAT 方法NAT 转换表的作用 网络地址与端口号转换 NAPTNAT 和 NAPT 的缺陷 网络地址转换 NAT 概述 尽管因特网采用了无分类编址方法来减缓 IPv4 地址空间耗尽的速度,但由于因特网用户数量的急剧增长,特别是大量小…...

【Pikachu靶场:XSS系列】xss之过滤,xss之htmlspecialchars,xss之herf输出,xss之js输出通关啦
一、xss之过滤 <svg onloadalert("过关啦")> 二、xss之htmlspecialchars javascript:alert(123) 原理:输入测试文本为herf的属性值和内容值,所以转换思路直接变为js代码OK了 三、xss之href输出 JavaScript:alert(假客套) 原理&#x…...

面向制造和装配的产品设计指南(二):面向装配的设计指南
参考引用 面向制造和装配的产品设计指南 1. 概述 1.1 装配的概念 装配是指把多个零件组装成产品,使得产品能够实现相应的功能并体现产品的质量,装配包含三层含义 把零件组装在一起实现相应的功能体现产品的质量 1.2 最好和最差的装配工序 1.3 面向装…...

Python中的PDF处理工具:PyPDF2和ReportLab使用指南
Python中的PDF处理工具:PyPDF2和ReportLab使用指南 在日常工作和项目中,PDF 文件处理是个常见需求,不论是合并报告、加密文档、填充表单,还是生成发票。Python 中有许多用于操作 PDF 文件的库,其中 PyPDF2 和 ReportL…...

【vxe-table】多选筛选项对列表的列进行动态的显示与隐藏
需求: 列表的组成部分由:一些固定的列,如:姓名,工号,以及 需要动态显示与隐藏的列,如:出勤、旷工、事假、病假等假勤类型 1、通过多选框多选,展示选中的列,未选中的不展示…...

微信小程序uniapp+vue飞机订票航空售票系统
文章目录 项目介绍具体实现截图技术介绍mvc设计模式小程序框架以及目录结构介绍错误处理和异常处理java类核心代码部分展示详细视频演示源码获取 项目介绍 对于小程序飞机订票信息管理所牵扯的信息管理及数据保存都是非常多的,举例像所有的管理员;管理员…...

如何取消Outlook中的循环会议
如何取消Outlook中的循环会议 参考链接:https://iknow.lenovo.com.cn/detail/195430 1、打开Outlook,进入 日历 视图界面; 2、 选择并双击要取消的循环会议; 3、 在 打开定期项目 对话框中选择整个序列,然后单击 确…...

Docker-- cgroups资源控制实战
上一篇:容器化和虚拟化 什么是cgroups? cgroups是Linux内核中的一项功能,最初由Google的工程师提出,后来被整合进Linux内核; 它允许用户将一系列系统任务及其子任务整合或分隔到按资源划分等级的不同组内,从而为系统…...

使用Python和Vosk库实现语音识别
使用Python和Vosk库实现语音识别 在人工智能和机器学习领域,语音识别技术正变得越来越重要。Python作为一种强大的编程语言,拥有丰富的库和框架,可以方便地实现语音识别功能。今天,我们将介绍如何使用Python中的SpeechRecognitio…...

stm32使用串口的轮询模式,实现数据的收发
------内容以b站博主keysking为原型,整理而来,用作个人学习记录。 首先在STM32CubeMX中配置 前期工作省略,只讲重点设置。 这里我配置的是USART2的模式。 会发现,PA2和PA3分别是TX与RX,在连接串口时需要TX对RX&…...

105. UE5 GAS RPG 搭建主菜单
在这一篇,我们将实现对打开游戏显示的主菜单进行搭建,主菜单将显示游戏主角,游戏名称和进入游戏和退出游戏两个按钮。 搭建菜单场景 我们将主菜单设置为一个单独的场景,前面可以显示对应的UI控件,用于玩家操作&#…...

基于 JAVASSM(Java + Spring + Spring MVC + MyBatis)框架开发一个医院挂号系统
基于 JAVASSM(Java Spring Spring MVC MyBatis)框架开发一个医院挂号系统是一个实用的项目。 步骤一:需求分析 明确系统需要实现的功能,比如: 用户注册和登录查看医生列表预约挂号查看预约记录取消预约管理员管…...

Golang | Leetcode Golang题解之第540题有序数组中的单一元素
题目: 题解: func singleNonDuplicate(nums []int) int {low, high : 0, len(nums)-1for low < high {mid : low (high-low)/2mid - mid & 1if nums[mid] nums[mid1] {low mid 2} else {high mid}}return nums[low] }...

影刀RPA实战:嵌入python,如虎添翼
1. 影刀RPA与Python的关系 影刀RPA与Python的关系可以从以下几个方面来理解: 技术互补:影刀RPA是一种自动化工具,它允许用户通过图形化界面创建自动化流程,而Python是一种编程语言,常用于编写自动化脚本。影刀RPA可以…...

es 数据清理delete_by_query
POST /索引名/_delete_by_query?conflictsproceed&scroll_size2000&wait_for_completionfalse&slices36 {"size": 2000, "query": {"bool": { "must": [{"terms": {"rule_id": [800007]}}]}} }slice…...

【每日 C/C++ 问题】
一、C 中类的三大特性是什么?请简要解释。 封装、继承、多态 封装:将事物的属性(成员变量)和行为(成员函数)封装在一起形成一个类。并且可以设置相应的访问权限(私有的 受保护的 公有的&#…...

Keil MDK中自定义CMSIS代码模板实战指南
1. 自定义CMSIS用户代码模板的完整指南作为一名嵌入式开发老手,我经常需要在Keil MDK环境中创建各种RTOS任务模板。官方提供的模板虽然好用,但实际项目中我们往往需要根据公司编码规范或特定硬件平台定制专属模板。今天我就来分享如何在CMSIS环境中添加自…...

微生物代谢建模与优化:从GEMs构建到工业应用
1. 微生物代谢建模与优化的协同设计方法在工业生物技术领域,微生物代谢建模已成为优化生物转化过程的核心工具。通过构建基因组尺度代谢模型(GEMs),研究人员能够系统分析微生物细胞内数百至数千个酶催化反应的相互作用网络。以丁酸…...
)
openEuler 22.03 LST上安装RealVNC 6.11,我踩过的那些依赖坑(附离线包下载方法)
在openEuler 22.03 LST离线环境中部署RealVNC 6.11的完整指南当我们需要在隔离网络的生产环境中部署远程桌面服务时,依赖管理往往成为最棘手的挑战。本文将分享我在openEuler 22.03 LST系统上安装RealVNC 6.11时积累的实战经验,特别是如何处理复杂的离线…...

大气层Atmosphere系统深度解析:解锁Switch潜能的终极技术指南
大气层Atmosphere系统深度解析:解锁Switch潜能的终极技术指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable Atmosphere大气层系统作为Nintendo Switch最稳定、功能最丰富的定…...

大模型底座的技术路线
主流大模型目前以token为单位处理文本,因其算力效率高、生态成熟。但byte-level/tokenizer-free路线正快速发展,它更端到端、跨语言统一且对噪声文本鲁棒。未来几年,外部接口可能仍用token,内部却将更多采用byte、patch或latent s…...

深度揭秘:如何在Mac上无痛备份微信聊天记录
深度揭秘:如何在Mac上无痛备份微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因微信聊天记录丢失而懊恼?那些珍贵的对话、重…...

效率直接起飞!2026年最值得信赖的专业AI论文软件
2026年AI论文写作工具已从“内容生成”升级为智能学术辅助系统,核心评价维度包括文献真实性、格式合规性、长文本逻辑、查重降重、AIGC合规与多语言支持。本次测评覆盖6款主流工具,测试场景涵盖中英文论文、全流程与专项功能、免费与付费版本,…...
分辨率。——如果采用扩展屏复制笔记本电脑分辨率,发现那个投影仪投影出的字很小,且看不清。 将笔记本电脑的)
投影仪的分辨率不高,仅为1024*768的分辨率,而笔记本电脑2560×1600(2.5K)分辨率。——如果采用扩展屏复制笔记本电脑分辨率,发现那个投影仪投影出的字很小,且看不清。 将笔记本电脑的
投影仪的分辨率不高,仅为1024*768的分辨率,而笔记本电脑25601600(2.5K)分辨率。——如果采用扩展屏复制笔记本电脑分辨率,发现那个投影仪投影出的字很小,且看不清。 将笔记本电脑的分辨率也改为1024*768的分辨率,投影仪字体大小会放大才看的清楚,但是软件无法全部显…...

矿山灾害应急回溯:UWB离线即失联,无感定位全程轨迹留存
矿山灾害应急回溯:UWB离线即失联,无感定位全程轨迹留存矿山井下塌方、瓦斯超限、透水、顶板垮落等突发性灾害具备极强不可预判性,灾害发生后极易伴随断电断网、通信中断、组网瘫痪等状况。应急轨迹回溯、人员位置核查、救援路线规划ÿ…...

免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力
免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/…...