MySQL45讲 第十六讲 “order by”是怎么工作的?
文章目录
- MySQL45讲 第十六讲 “order by”是怎么工作的?
- 一、引言
- 二、全字段排序
- (一)索引创建与执行情况分析
- (二)执行流程
- (三)查看是否使用临时文件
- 三、rowid 排序
- (一)参数控制与算法改变
- (二)执行流程
- (三)全字段排序和rowid 排序性能对比
- 四、利用联合索引避免排序
- (一)创建联合索引
- (二)执行流程简化
- (三)覆盖索引优化
- 五、总结与思考
MySQL45讲 第十六讲 “order by”是怎么工作的?
一、引言
在应用开发中,经常需要根据指定字段排序显示结果。本文以查询城市为 “杭州” 的市民信息并按姓名排序为例,深入探讨 MySQL 中 “order by” 语句的执行流程、不同算法以及相关优化策略,避免在开发中出现性能问题。
例子:假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回 前1000个人的姓名、年龄。
假设这个表的部分定义是这样的:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
这时,你的SQL语句可以这么写:
select city,name,age from t where city='杭州' order by name limit 1000;
二、全字段排序
(一)索引创建与执行情况分析
-
MySQL会给每个线程分配一块内存用于排序,这块内存称为
sort_buffer。为避免全表扫描,需在city字段创建索引。
-
使用
explain命令查看执行情况,Extra字段中的Using filesort表示需要排序,MySQL 会为每个线程分配sort_buffer内存用于排序。

(二)执行流程
- 初始化
sort_buffer,确定放入name、city、age三个字段。 - 从
city索引找到满足条件的第一个主键id。 - 到主键
id索引取出整行,取相关字段值存入sort_buffer。 - 从
city索引取下一个记录的主键id,重复 3、4 步直到不满足条件。 - 对
sort_buffer中的数据按name字段做快速排序(可能在内存或使用外部排序,取决于sort_buffer_size参数和排序数据量)。 - 取前 1000 行返回给客户端。

(三)查看是否使用临时文件
-
通过设置
optimizer_trace为enabled=on,计算执行语句前后performance_schema.session_status中Innodb_rows_read的差值,并查看OPTIMIZER_TRACE结果中的number_of_tmp_files,可确定是否使用临时文件。若该值大于 0,表示使用了外部排序,MySQL 将数据分成多份排序后合并;若为0,表示可在内存中完成排序。 -
下图中的
number_of_tmp_files=12代表MySQL将需要排序的数据分成12份,每一份单独排序后存在这些临时文件中。然后把这12个有序文件再合并成一个有序的大文件。
三、rowid 排序
在全字段排序算法过程里面,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的。如果查询要返回的字段很多的话,那么sort_buffer里面要放的字段数太多,即行长度过长,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。这时候就需要使用rowid排序。
(一)参数控制与算法改变
SET max_length_for_sort_data = 16;
- 当
max_length_for_sort_data参数设置为较小值(如 16),且单行长度超过该值时,MySQL 采用rowid排序算法。此算法放入sort_buffer的字段只有要排序的列(如 “name”)和主键 id。
(二)执行流程
-
初始化
sort_buffer,确定放入name和id字段。 -
从
city索引找到满足条件的第一个主键id。 -
到主键
id索引取出整行,取name和id字段存入sort_buffer。 -
从
city索引取下一个记录的主键id,重复 3、4 步直到不满足条件。 -
对
sort_buffer中的数据按name排序。 -
遍历排序结果取前 1000 行,按
id值回原表取出city、name和age字段返回给客户端。此算法多了一次回表操作,但在单行数据较大时,可在排序过程中一次排序更多行。

(三)全字段排序和rowid 排序性能对比
- 全字段排序在内存足够时优先选择,可直接从内存返回结果,减少磁盘访问;
- rowid 排序在内存较小时使用,虽排序时能处理更多行,但需回表取数据,增加磁盘读操作。
四、利用联合索引避免排序
(一)创建联合索引
-
创建
city和name的联合索引(如city_user (city, name)),可确保从该索引取出行时按name递增排序,无需再进行排序操作。
-
无需继续创建临时表和排序,使用
explain指令查看,Extra字段已经没有Using filesort,证明
(二)执行流程简化
-
从联合索引找到满足条件的第一个主键
id。 -
到主键
id索引取整行相关字段值直接返回。 -
从联合索引取下一个记录主键
id,重复 2 步直到满足条件结束。
(三)覆盖索引优化
-
进一步创建
city、name和age的联合索引(如city_user_age (city, name, age)),可利用覆盖索引,直接从索引获取数据返回,无需回表从主键索引取数据,性能更快,但需权衡索引维护代价。覆盖索引是指,索引上的信息足够满足查询请求,不需要回到主键索引上去取数据。 -
这样整个查询语句的执行流程就变成了:
- 从索引
(city,name,age)找到第一个满足city='杭州’条件的记录,取出其中的city、name和age这三个字段的值,作为结果集的一部分直接返回; - 从索引
(city,name,age)取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回; - 重复执行步骤2,直到查到第1000条记录,或者是不满足
city='杭州’条件时循环结束。

- 从索引
五、总结与思考
MySQL 中 order by 语句有多种执行算法,开发人员应清楚其排序逻辑和系统资源消耗,根据实际情况选择合适方案。
- 全字段排序可能需要使用临时表进行排序,在字段过多的情况下性能可能会很差。
- 为了减少字段过长导致的排序性能下降,rowid排序算法放入
sort_buffer的字段只有要排序的列(如 “name”)和主键 id。 - 如果需要进一步提高性能,可以采取联合索引乃至覆盖索引(字段已排序),这样就可以避免排序,但是需要消耗空间存储索引和维护索引为代价。
相关文章:
MySQL45讲 第十六讲 “order by”是怎么工作的?
文章目录 MySQL45讲 第十六讲 “order by”是怎么工作的?一、引言二、全字段排序(一)索引创建与执行情况分析(二)执行流程(三)查看是否使用临时文件 三、rowid 排序(一)参…...
智慧商城项目-VUE2
实现效果 项目收获 通过本项目的练习,可以掌握以下内容: 创建项目 ##基本创建 基于 VueCli 自定义创建项目架子,并对相关的配置进行选择 vue create demo-shopping调整目录 删除文件 删除初始化的一些默认文件 src/assets/logo.pngsrc/components…...

音视频入门基础:FLV专题(22)——FFmpeg源码中,获取FLV文件音频信息的实现(中)
本文接着《音视频入门基础:FLV专题(21)——FFmpeg源码中,获取FLV文件音频信息的实现(上)》,继续讲解FFmpeg获取FLV文件的音频信息到底是从哪个地方获取的。本文的一级标题从“四”开始。 四、音…...

Chrome与火狐哪个浏览器的性能表现更好
在数字时代,浏览器是我们日常生活中不可或缺的工具。无论是工作、学习还是娱乐,一个好的浏览器都能显著提高我们的效率和体验。市场上有许多优秀的浏览器,其中Google Chrome和Mozilla Firefox无疑是最受欢迎的两款。本文将比较这两款浏览器的…...
表中的用户id)
uniapp在js方法中,获取当前用户的uid(uni-id-user)表中的用户id
// 1.判断当前用的权限 let uid uniCloud.getCurrentUserInfo().uid //获取当前用户的uid // 用户uid等于发布者id或者用户权限等于admin或者用户角色等于webmaster if (uid this.item.user_id[0]._id || this.uniIDHasRole…...

影响神经网络速度的因素- FLOPs、MAC、并行度以及计算平台
影响神经网络速度的四个主要因素分别是 FLOPs(浮点操作数)、MAC(内存访问成本)、并行度以及计算平台。这些因素共同作用,直接影响到神经网络的计算速度和资源需求。 1. FLOPs(Floating Point Operations&a…...

【万字详解】如何在微信小程序的 Taro 框架中设置静态图片 assets/image 的 Base64 转换上限值
设置方法 mini 中提供了 imageUrlLoaderOption 和 postcss.url 。 其中: config.limit 和 imageUrlLoaderOption.limit 服务于 Taro 的 MiniWebpackModule.js , 值的写法要 ()KB * 1024。 config.maxSize 服务于 postcss-url 的…...
)
复合选择器,CSS特性,背景属性,显示模式(HTML)
目录 复合选择器,CSS特性,背景属性,显示模式知识点: 练习一: 练习二: 复合选择器,CSS特性,背景属性,显示模式知识点: 复合选择器:后代选择器 :父选择器 子选择器(中间用空格隔开) eg:对div中的span进行设置,会对后代中的所有span都进行设置 选中所有后代(后代选择器.html)…...

加密货币行业与2024年美国大选
加密货币行业经历了近十年的飞速发展,尤其是在比特币、以太坊等主要加密资产的兴起之后,越来越多的美国人开始将其视为一种财富积累或交易的工具。然而,尽管这一新兴行业的市场规模在持续扩大,但加密货币仍面临着重重监管难题&…...

Hive SQL中判断内容包含情况的全面指南
Hive SQL中判断内容包含情况的实用指南 在 Hive SQL 的数据处理与分析世界里,判断字段是否包含特定内容是一项非常重要的操作。今天,我将为大家详细介绍 Hive SQL 中实现这一功能的多种方法,并附上相应的表创建和数据插入语句。 一、准备工作 - 表创建与数据插入 首先,我…...

匿名管道 Linux
目录 管道 pipe创建一个管道 让子进程写入,父进程读取 如何把消息发送/写入给父进程 父进程该怎么读取呢 管道本质 结论:管道的特征: 测试管道大小 写端退了,测试结果 测试子进程一直写,父进程读一会就退出 …...
)
苍穹外卖WebSocket无法建立连接 (修改前端代码)
我在部署nginx 反向代理服务器时,把80端口改成了90端口(不与80端口的Tomcat冲突)。 但黑马的资料里定义了前端连接nginx的端口号默认为80,造成连接不上的问题,此时只需要修改前端的端口号,使其知道如何连接到修改后的后端端口。 …...

音频内容理解
音频内容理解是音频处理和理解领域的一个重要方向,它涉及到从环境声音中提取语义信息,并能够对这些声音进行解释和描述。以下是音频内容理解的几个关键应用: 1. 音频问答(Audio Question Answering, AQA) 在这个任务…...
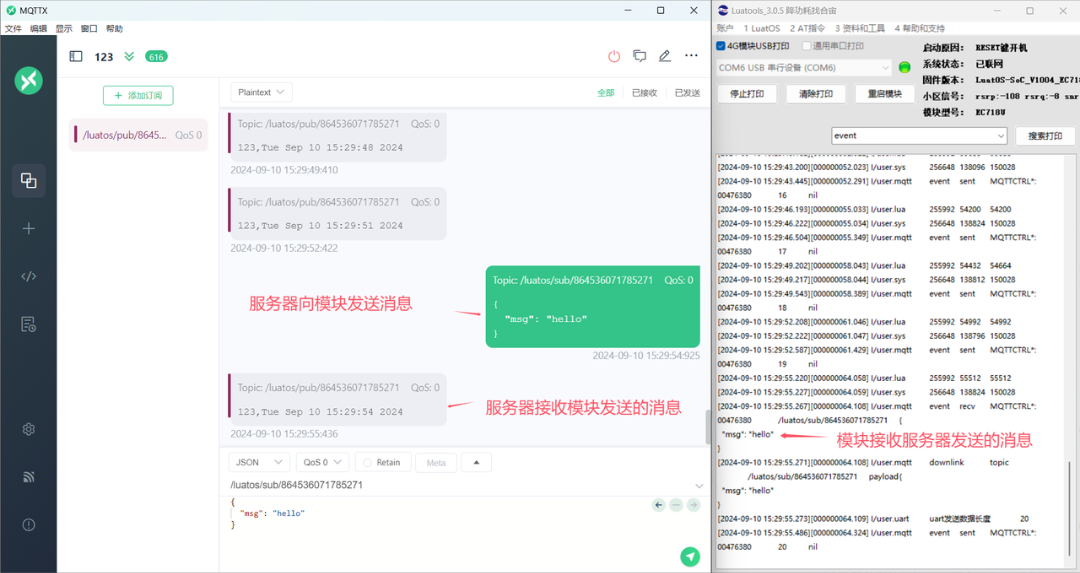
MQTT实用示例集:Air201版
今天贴出的是Air201版关于MQTT实用示例集,希望大家喜欢。 本示例教你通过使用脚本代码,对Air201模组进行MQTT链接操作。 操作例程包括: MQTT单链接 MQTT多链接 MQTT SSL不带证书链接 MQTT SSL带证书链接 大家可根据自身需求,…...

Day23 opencv图像预处理
图像预处理 在计算机视觉和图像处理领域,图像预处理是一个重要的步骤,它能够提高后续处理(如特征提取、目标检测等)的准确性和效率。OpenCV 提供了许多图像预处理的函数和方法,常见的操作包括图像空间转换、图像大小调…...

优化模型训练过程中的显存使用率、GPU使用率
参考:https://blog.51cto.com/u_16099172/7398948 问题:用小数据集训练显存使用率、GPU使用率正常,但是用大数据集训练GPU使用率一直是0. 小数据: 大数据: 1、我理解GPU内存占用率显存使用率,由模型的大小…...
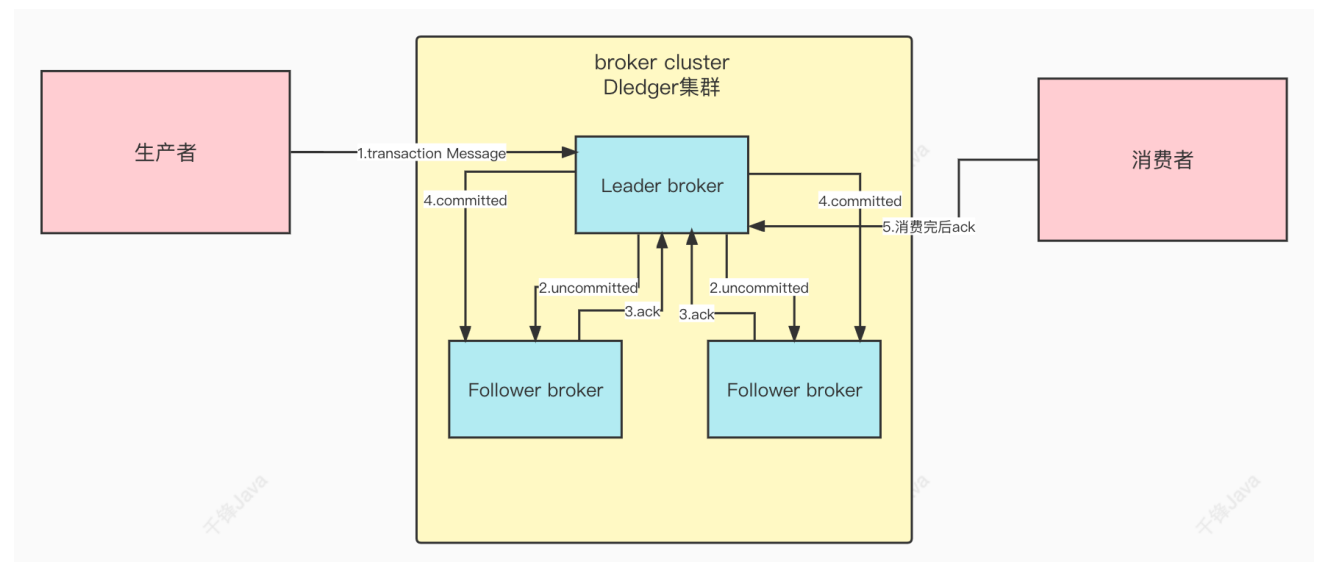
RocketMQ学习笔记
RocketMQ笔记 文章目录 一、引言⼆、RocketMQ介绍RocketMQ的由来 三、RocketMQ的基本概念1 技术架构2 部署架构 四、快速开始1.下载RocketMQ2.安装RocketMQ3.启动NameServer4.启动Broker5.使⽤发送和接收消息验证MQ6.关闭服务器 五、搭建RocketMQ集群1.RocketMQ集群模式2.搭建主…...

Linux第三讲:环境基础开发工具使用
Linux第三讲:环境基础开发工具使用 1.Linux软件包管理器yum1.1什么是软件包管理器1.2操作系统生态问题1.3什么是yum源 2.vim详解2.1什么是vim2.2vim的多模式讲解2.2.1命令模式的诸多指令2.2.1.1gg和nshiftg2.2.1.2shift$和shift^2.2.1.3上、下、左、右2.2.1.4w和b2.…...

日本TikTok直播的未来:专线网络助力创作者突破极限
近年来,随着短视频平台的崛起,尤其是TikTok(国际版抖音)成为全球范围内广受欢迎的社交娱乐平台,直播功能的加入无疑为内容创作者提供了更广阔的展示舞台。在日本,TikTok直播不仅使得年轻人能够实时与粉丝互…...

如何在家庭网络中设置静态IP地址:一份实用指南
在家庭网络环境中,IP地址扮演着至关重要的角色。大多数家庭用户依赖路由器的DHCP(动态主机配置协议)来自动分配IP地址,但在某些情况下,手动设置静态IP地址能为家庭网络带来更多的便利性与稳定性,尤其是在涉…...
)
告别闪烁!用STM32和Simulink搞定LED的PWM调光(附仿真文件)
告别闪烁!用STM32和Simulink搞定LED的PWM调光(附仿真文件) LED照明在医疗设备、植物工厂等场景中,对光源稳定性要求极高。传统调光方案常因电路噪声或控制算法缺陷导致肉眼可见的闪烁,这不仅影响用户体验,更…...

Bebas Neue:现代几何字体的开源革命与专业应用指南
Bebas Neue:现代几何字体的开源革命与专业应用指南 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue Bebas Neue 是一款备受全球设计师推崇的开源几何字体,以其简洁有力的线条和卓越的视觉冲…...

如何快速部署大麦自动抢票工具:面向开发者的完整技术指南
如何快速部署大麦自动抢票工具:面向开发者的完整技术指南 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 在热门演出票务市场中…...

洛雪音乐音源配置完全指南:免费搭建个人音乐库的终极方案
洛雪音乐音源配置完全指南:免费搭建个人音乐库的终极方案 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 洛雪音乐作为一款强大的音乐播放工具,提供了全网最新最全的音源资…...

5个关键步骤:使用SUMO-RL构建城市智能交通信号控制系统
5个关键步骤:使用SUMO-RL构建城市智能交通信号控制系统 【免费下载链接】sumo-rl Reinforcement Learning environments for Traffic Signal Control with SUMO. Compatible with Gymnasium, PettingZoo, and popular RL libraries. 项目地址: https://gitcode.co…...

终极指南:如何用Word Checker轻松实现中英文拼写自动纠正
终极指南:如何用Word Checker轻松实现中英文拼写自动纠正 【免费下载链接】word-checker 🇨🇳🇬🇧Chinese and English word spelling corrector.(中文易错别字检测,中文拼写检测纠正。英文单词拼写校验工具…...

X-TRACK开源GPS自行车码表深度解析:从嵌入式架构到离线地图的完全实战指南
X-TRACK开源GPS自行车码表深度解析:从嵌入式架构到离线地图的完全实战指南 【免费下载链接】X-TRACK A GPS bicycle speedometer that supports offline maps and track recording 项目地址: https://gitcode.com/gh_mirrors/xt/X-TRACK X-TRACK是一款基于A…...

RK3568播放RTSP摄像头实测:软解1080P直接CPU跑满,降到360P才流畅,硬解到底怎么搞?
RK3568 RTSP摄像头解码实战:从软解瓶颈到硬解优化全解析 最近在调试RK3568开发板的RTSP摄像头播放功能时,遇到了一个典型问题:1080P软解直接让CPU跑满,降到360P才能勉强流畅。这让我开始深入探索瑞芯微平台的硬解方案,…...

spring源码bean生命周期篇 五 如何解决循环依赖
一.spring循环依赖 1. 什么是循环依赖? bean的生命周期前面的章节我们有讲解过大量的源码,我们粗略的分为这几步 spring扫描class获取BeanDefintionspring根据BeanDefintion实例化bean创建bean之前需要实例化对象,实例化后填充原始对象中的属…...

Poppler Windows版:PDF处理的终极简单方案
Poppler Windows版:PDF处理的终极简单方案 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上的PDF处理工具而烦恼吗&…...