Keras 3 示例:开启深度学习之旅
Keras 3 示例:开启深度学习之旅
一、Keras 3 简介
Keras 3是一个强大的深度学习框架,它为开发者提供了简洁、高效的方式来构建和训练神经网络。它在之前版本的基础上进行了改进和优化,具有更好的性能、兼容性和功能扩展性。无论是初学者还是经验丰富的研究人员,都可以利用 Keras 3快速实现自己的深度学习想法。
二、环境搭建与安装示例
(一)安装 Keras 3
首先,确保已经安装了合适版本的 Python(建议使用 Python 3.7 及以上版本)。然后,可以使用以下命令安装 Keras 3:
pip install keras
如果要在特定的虚拟环境中安装,可以先激活虚拟环境,再执行上述安装命令。
(二)安装相关依赖
Keras 3通常依赖于后端计算引擎,如 TensorFlow。如果还未安装 TensorFlow,可以使用以下命令安装:
pip install tensorflow
这样就完成了基本的环境搭建,可以开始使用 Keras 3进行开发。
三、图像分类示例
(一)使用 MNIST 数据集
- 数据加载
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
这简单的几行代码就可以加载著名的 MNIST 手写数字数据集,其中 x_train 和 x_test 分别是训练集和测试集的图像数据,y_train 和 y_test 是对应的标签。
2. 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0from keras.utils import to_categorical
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
这里将图像数据重塑为合适的形状,并进行归一化处理,同时将标签进行 one - hot 编码,以便模型更好地处理。
3. 构建模型
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Densemodel = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
这个简单的卷积神经网络模型先使用卷积层提取特征,然后通过池化层减少数据维度,再将数据展平后连接全连接层,最后输出每个数字类别的概率。
4. 模型编译与训练
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=128, validation_data=(x_test, y_test))
这里指定了优化器为 Adam,损失函数为交叉熵损失,并使用准确率作为评估指标。然后训练模型,指定训练轮数和批次大小,并在测试集上进行验证。
5. 模型评估
loss, accuracy = model.evaluate(x_test, y_test)
print(f"Test loss: {loss}, Test accuracy: {accuracy}")
这可以得到模型在测试集上的损失和准确率,评估模型的性能。
(二)使用 CIFAR - 10 数据集
- 数据加载与预处理
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
加载 CIFAR - 10 图像数据集,并进行类似的归一化和标签编码操作。
2. 构建更复杂的模型
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=(32, 32, 3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(10, activation='softmax'))
这个模型在 CIFAR - 10 数据集上构建了一个更深的卷积神经网络,包含更多的卷积层和池化层,以提取更复杂的图像特征。
3. 编译、训练和评估
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test))
loss, accuracy = model.evaluate(x_test, y_test)
print(f"Test loss: {loss}, Test accuracy: {accuracy}")
同样地,编译模型、进行训练并评估其在测试集上的性能。
四、目标检测示例
(一)简单目标检测模型框架
- 数据准备(模拟数据生成)
import numpy as np
# 模拟生成一些简单的图像数据和目标框数据
num_images = 100
image_width, image_height = 64, 64
num_objects_per_image = 2
images = np.random.rand(num_images, image_width, image_height, 3).astype('float32')
boxes = []
for i in range(num_images):image_boxes = []for j in range(num_objects_per_image):x1, y1 = np.random.randint(0, image_width - 10), np.random.randint(0, image_height - 10)x2, y2 = x1 + np.random.randint(5, 10), y1 + np.random.randint(5, 10)class_id = np.random.randint(0, 5) # 假设 5 种目标类别image_boxes.append([x1, y1, x2, y2, class_id])boxes.append(np.array(image_boxes))
boxes = np.array(boxes)
这里模拟生成了一些简单的图像和目标框数据,用于示例目的。在实际应用中,可以使用真实的目标检测数据集。
2. 模型构建(基于卷积神经网络)
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Denseimage_input = Input(shape=(image_width, image_height, 3))
x = Conv2D(32, (3, 3), activation='relu')(image_input)
x = MaxPooling2D((2, 2))(x)
x = Conv2D(64, (3, 3), activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
box_output = Dense(5 * (4 + 1))(x) # 假设每个目标用 (x1,y1,x2,y2,class_id) 表示,5 种目标类别
model = Model(image_input, box_output)
这个模型基于卷积神经网络,接受图像输入,最后输出目标框的预测信息。
3. 模型编译与训练(简单示例)
model.compile(optimizer='adam', loss='mse') # 使用均方误差作为损失函数,这里只是简单示例
model.fit(images, boxes, epochs=5, batch_size=8)
编译模型并使用模拟数据进行简单的训练,在实际应用中,需要更复杂的损失函数和训练策略。
(二)使用预训练模型进行目标检测(以 YOLO 风格为例)
- 加载预训练模型(假设已经有预训练权重)
from keras.models import load_model
pretrained_model = load_model('pretrained_yolo_style_model.h5')
这里假设已经有一个预训练的类似 YOLO 风格的目标检测模型的权重文件。
2. 数据预处理(与预训练模型匹配)
# 假设需要将输入图像调整到模型所需的特定尺寸,并进行归一化等操作
test_image = np.random.rand(1, 416, 416, 3).astype('float32') # 以 416x416 为例,实际根据模型调整
test_image = test_image / 255.0
根据预训练模型的要求对输入图像进行预处理。
3. 目标检测推理
detections = pretrained_model.predict(test_image)
# 对检测结果进行后处理,例如解析出目标框、类别和置信度等信息
# 这里省略具体的后处理代码,不同的模型有不同的后处理方式
使用预训练模型对输入图像进行目标检测推理,并得到检测结果,然后需要进行后处理来得到有意义的目标信息。
五、自然语言处理示例
(一)文本分类(使用 IMDB 影评数据集)
- 数据加载与预处理
from keras.datasets import imdb
from keras.preprocessing.sequence import pad_sequences
vocab_size = 10000
max_length = 200
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=vocab_size)
x_train = pad_sequences(x_train, maxlen=max_length)
x_test = pad_sequences(x_test, maxlen=max_length)
加载 IMDB 影评数据集,并将文本数据转换为固定长度的序列,只保留最常见的 vocab_size 个单词。
2. 构建模型(基于循环神经网络)
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Densemodel = Sequential()
model.add(Embedding(vocab_size, 128, input_length=max_length))
model.add(LSTM(64))
model.add(Dense(1, activation='sigmoid'))
这个模型先使用嵌入层将单词索引转换为向量,然后使用 LSTM 层处理序列信息,最后通过一个全连接层输出文本属于正面或负面评价的概率。
3. 模型编译、训练与评估
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=128, validation_data=(x_test, y_test))
loss, accuracy = model.evaluate(x_test, y_test)
print(f"Test loss: {loss}, Test accuracy: {accuracy}")
编译模型,使用二元交叉熵损失函数进行训练,并评估模型在测试集上的性能。
(二)文本生成(基于字符级 RNN)
- 数据准备(以一段文本为例)
text = "This is a sample text for text generation example. We will use this text to train a character - level RNN."
# 创建字符到索引和索引到字符的映射
chars = sorted(list(set(text)))
char_to_idx = {char: idx for idx, char in enumerate(chars)}
idx_to_char = {idx: char for char, idx in char_to_idx.items()}
# 将文本转换为序列
maxlen = 40
step = 3
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):sentences.append(text[i : i + maxlen])next_chars.append(text[i + maxlen])
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):for t, char in enumerate(sentence):x[i, t, char_to_idx[char]] = Truey[i, char_to_idx[next_chars[i]]] = True
这里准备了一段文本,创建了字符映射,并将文本转换为模型可接受的输入和输出格式,用于字符级的文本生成。
2. 构建模型(简单的 RNN)
from keras.models import Sequential
from keras.layers import LSTM, Densemodel = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars))))
model.add(Dense(len(chars), activation='softmax'))
构建一个简单的 LSTM 模型,接受字符序列作为输入,输出下一个字符的概率分布。
3. 模型编译与训练
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit(x, y, epochs=20, batch_size=128)
编译模型并进行训练,训练完成后可以使用模型进行文本生成。
4. 文本生成
import random
start_index = random.randint(0, len(text) - maxlen - 1)
generated_text = text[start_index : start_index + maxlen]
for i in range(400):x_pred = np.zeros((1, maxlen, len(chars)))for t, char in enumerate(generated_text):x_pred[0, t, char_to_idx[char]] = Truepreds = model.predict(x_pred)[0]next_char_idx = np.random.choice(len(chars), p=preds)next_char = idx_to_char[next_char_idx]generated_text += next_chargenerated_text = generated_text[1:]
print(generated_text)
从文本中随机选择一个起始点,然后根据模型预测的概率逐个生成字符,得到新的文本。
六、序列到序列学习示例(机器翻译)
(一)数据准备(模拟英法翻译数据)
# 模拟一些简单的英法单词对
data = [('hello', 'bonjour'),('world', 'monde'),('how are you', 'comment allez - vous'),('I am fine', 'je vais bien'),('thank you', 'merci')
]
# 构建源语言和目标语言的词汇表
source_vocab = sorted(list(set([word for word, _ in data])))
target_vocab = sorted(list(set([word for _, word in data])))
source_to_idx = {word: idx for idx, word in enumerate(source_vocab)}
target_to_idx = {word: idx for idx, word in enumerate(target_vocab)}
# 将单词对转换为索引序列
max_source_length = max([len(word) for word, _ in data])
max_target_length = max([len(word) for _, word in data])
source_sequences = np.zeros((len(data), max_source_length), dtype='int32')
target_sequences = np.zeros((len(data), max_target_length), dtype='int32')
for i, (source_word, target_word) in enumerate(data):for j, char in enumerate(source_word):source_sequences[i, j] = source_to_idx[char]for j, char in enumerate(target_word):target_sequences[i, j] = target_to_idx[char]
这里模拟了一些简单的英法单词对,并构建了词汇表和将单词对转换为索引序列,用于序列到序列学习的示例。在实际应用中,可以使用大规模的翻译数据集。
(二)构建序列到序列模型
from keras.models import Model
from keras.layers import Input, LSTM, Dense# 编码器
encoder_inputs = Input(shape=(max_source_length,))
encoder_embedding = Embedding(len(source_vocab), 64)(encoder_inputs)
encoder_lstm = LSTM(64, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(encoder_embedding)
encoder_states = [state_h, state_c]# 解码器
decoder_inputs = Input(shape=(max_target_length,))
decoder_embedding = Embedding(len(target_vocab), 64)
decoder_embedding_layer = decoder_embedding(decoder_inputs)
decoder_lstm = LSTM(64, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_embedding_layer, initial_state=encoder_states)
decoder_dense = Dense(len(target_vocab), activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)# 构建模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
这个序列到序列模型包括编码器和解码器。编码器将源语言序列编码为状态,解码器使用这些状态和目标语言的输入序列来生成翻译结果。
(三)模型编译与训练
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')
model.fit([source_sequences, target_sequences[:, :-1]], target_sequences[:, 1:],epochs=100, batch_size=1)
编译模型:我们使用rmsprop优化器来调整模型的权重,以最小化损失函数。
训练模型:通过多次迭代训练,模型会逐渐学习到源语言和目标语言之间的映射关系,从而提高翻译的准确性。在实际应用中,对于大规模的机器翻译任务,我们需要使用更丰富的数据集、更复杂的模型结构和更合适的训练策略来获得更好的翻译效果
七、以下是一些 Keras 3 的其他示例:
(一)、图像生成(使用生成对抗网络 - GAN)
- 生成器模型构建
from keras.models import Sequential
from keras.layers import Dense, Reshape, Conv2DTranspose, BatchNormalization, LeakyReLUgenerator = Sequential()
generator.add(Dense(256 * 4 * 4, input_dim=100))
generator.add(Reshape((4, 4, 256)))
generator.add(Conv2DTranspose(128, (4, 4), strides=(2, 2), padding='same'))
generator.add(BatchNormalization())
generator.add(LeakyReLU(alpha=0.2))
generator.add(Conv2DTranspose(64, (4, 4), strides=(2, 2), padding='same'))
generator.add(BatchNormalization())
generator.add(LeakyReLU(alpha=0.2))
generator.add(Conv2DTranspose(3, (4, 4), strides=(2, 2), padding='same', activation='tanh'))
这里构建了一个生成器模型,它接受一个 100 维的随机噪声向量作为输入,并通过一系列的全连接层、转置卷积层、批归一化层和激活函数,逐步将其转换为一个 64x64x3 的图像(假设生成图像的尺寸为 64x64,3 通道表示 RGB)。
- 判别器模型构建
from keras.models import Sequential
from keras.layers import Conv2D, Flatten, Dense, LeakyReLUdiscriminator = Sequential()
discriminator.add(Conv2D(64, (4, 4), strides=(2, 2), padding='same', input_shape=(64, 64, 3)))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Conv2D(128, (4, 4), strides=(2, 2), padding='same'))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Conv2D(256, (4, 4), strides=(2, 2), padding='same'))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
判别器模型用于区分输入的图像是真实图像还是由生成器生成的假图像。它通过一系列的卷积层和激活函数来提取图像特征,最后通过一个全连接层输出一个概率值,表示输入图像为真实图像的可能性。
- 组合 GAN 模型并训练
from keras.models import Model
import numpy as np# 组合生成器和判别器
discriminator.trainable = False
gan_input = Input(shape=(100,))
generated_image = generator(gan_input)
gan_output = discriminator(generated_image)
gan = Model(gan_input, gan_output)# 编译 GAN 模型和判别器模型
gan.compile(loss='binary_crossentropy', optimizer='adam')
discriminator.compile(loss='binary_crossentropy', optimizer='adam')# 训练数据(这里假设已经有真实图像数据 real_images)
batch_size = 32
for epoch in range(100):# 训练判别器noise = np.random.normal(0, 1, (batch_size, 100))generated_images = generator.predict(noise)real_labels = np.ones((batch_size, 1))fake_labels = np.zeros((batch_size, 1))d_loss_real = discriminator.train_on_batch(real_images[:batch_size], real_labels)d_loss_fake = discriminator.train_on_batch(generated_images, fake_labels)d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)# 训练 GAN(即训练生成器)noise = np.random.normal(0, 1, (batch_size, 100))g_loss = gan.train_on_batch(noise, np.ones((batch_size, 1)))
首先,我们将生成器和判别器组合成一个 GAN 模型。在训练过程中,先固定判别器的权重,训练生成器,然后再训练判别器。通过多次迭代,生成器逐渐学会生成更逼真的图像,以欺骗判别器。
(二)音频分类(使用 librosa 库加载音频数据)
- 数据加载与预处理
import librosa
import numpy as np# 加载音频文件
audio_path = 'example_audio.wav'
audio_data, sample_rate = librosa.load(audio_path)# 提取音频特征(这里使用梅尔频谱特征)
mel_spectrogram = librosa.feature.melspectrogram(y=audio_data, sr=sample_rate)
mel_spectrogram = librosa.power_to_db(mel_spectrogram)# 对特征进行归一化处理
mel_spectrogram = (mel_spectrogram - np.min(mel_spectrogram)) / (np.max(mel_spectrogram) - np.min(mel_spectrogram))# 假设我们有多个音频文件,将它们的特征存储在一个列表中
audio_features = []
audio_labels = [] # 对应的音频标签
# 这里省略了加载多个音频文件和标签的循环audio_features = np.array(audio_features)
audio_labels = np.array(audio_labels)
这里使用librosa库加载音频文件,并提取梅尔频谱特征。然后对特征进行归一化处理,以便于模型训练。在实际应用中,我们会处理多个音频文件,并将它们的特征和标签整理成合适的格式。
- 构建模型
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Densemodel = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=mel_spectrogram.shape))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax')) # num_classes 是音频类别数
构建一个基于卷积神经网络的音频分类模型。模型通过卷积层和池化层提取音频特征中的局部模式,然后通过全连接层进行分类。
- 模型编译与训练
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(audio_features, audio_labels, epochs=10, batch_size=32)
编译模型,指定优化器、损失函数和评估指标。然后使用音频特征和标签数据训练模型,经过多次训练轮数,模型可以学习到音频特征与类别之间的关系,从而实现对新音频的分类。
(三)时间序列预测(使用股票价格数据)
- 数据加载与预处理(假设已经有股票价格数据)
import pandas as pd
import numpy as np# 加载股票价格数据(这里假设是一个 CSV 文件,包含日期和价格列)
stock_data = pd.read_csv('stock_prices.csv')
prices = stock_data['price'].values# 对数据进行归一化处理
prices = (prices - np.min(prices)) / (np.max(prices) - np.min(prices))# 构建时间序列数据
time_steps = 10 # 使用过去 10 个时间步的数据来预测下一个时间步的价格
X = []
y = []
for i in range(len(prices) - time_steps):X.append(prices[i : i + time_steps])y.append(prices[i + time_steps])
X = np.array(X).reshape(-1, time_steps, 1)
y = np.array(y)
这里加载股票价格数据,并对价格数据进行归一化处理。然后通过构建时间序列数据,将连续的time_steps个价格数据作为输入特征X,下一个时间步的价格作为目标y。
- 构建模型(使用长短期记忆网络 - LSTM)
from keras.models import Sequential
from keras.layers import LSTM, Densemodel = Sequential()
model.add(LSTM(64, input_shape=(time_steps, 1)))
model.add(Dense(1))
构建一个基于 LSTM 的时间序列预测模型。LSTM 层能够处理时间序列数据中的长期依赖关系,模型最后输出一个预测的价格值。
- 模型编译与训练
model.compile(optimizer='adam', loss='mse')
model.fit(X, y, epochs=50, batch_size=32)
编译模型,使用均方误差(MSE)作为损失函数,因为这是一个回归问题。然后使用构建好的时间序列数据进行训练,经过多次训练轮数,模型可以学习到股票价格的时间序列模式,用于预测未来价格。
这些示例展示了 Keras 3 在不同领域的应用,包括图像生成、音频分类和时间序列预测等,希望能帮助你更好地理解和使用 Keras 3。
相关文章:

Keras 3 示例:开启深度学习之旅
Keras 3 示例:开启深度学习之旅 一、Keras 3 简介 Keras 3是一个强大的深度学习框架,它为开发者提供了简洁、高效的方式来构建和训练神经网络。它在之前版本的基础上进行了改进和优化,具有更好的性能、兼容性和功能扩展性。无论是初学者还是…...

鸿蒙Next如何接入微信支付
大家好,这是我工作中接触到的鸿蒙Next接入微信支付,有使用到,分享给大家,轻松便捷 前提:你已有鸿蒙版本的微信,并且微信余额或绑定银行卡有钱,因为内测的微信暂不支持收红包和转账,2.你的应用已…...

nginx(五):关于location匹配规则那些事
关于location匹配规则那些事 1 概述2 语法3 匹配规则说明3.1 精确匹配3.2 前缀匹配(^~)3.3 正则表达式匹配(\~和\~*)3.4 普通前缀匹配 4 匹配优先级5 注意事项6 总结 大家好,我是欧阳方超,可以我的公众号“…...

【论文阅读】Associative Alignment for Few-shot Image Classification
用于小样本图像分类的关联对齐 引用:Afrasiyabi A, Lalonde J F, Gagn C. Associative alignment for few-shot image classification[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16. Spri…...

acmessl.cn提供接口API方式申请免费ssl证书
目录 一、前沿 二、API接口文档 1、证书可申请列表 简要描述 请求URL 请求方式 返回参数说明 备注 2、证书申请 简要描述 请求URL 请求方式 业务参数 返回示例 返回参数说明 备注 3、证书查询 简要描述 请求URL 请求方式 业务参数 返回参数说明 备注 4、证…...
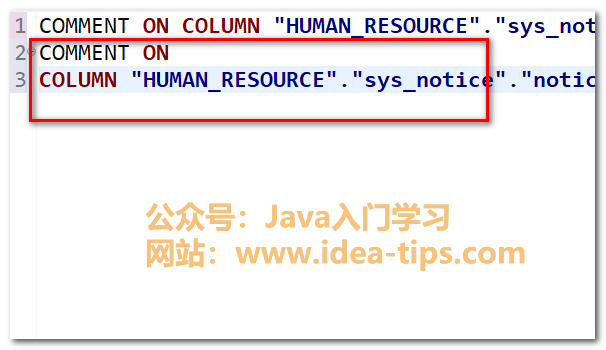
DBeaver如何快速格式化sql语句,真简单!
前言 我之前在使用DBeaver的时候,一直不知道其可以格式化sql语句,导致sql语句看起来比较杂乱,今天就来介绍下DBeaver如何格式化sql语句。 如何格式化sql语句 首先,我们打开一个sql窗口,在里面输入我们要查询的sql语…...
)
OpenCV C++ 计算两幅图像之间的多尺度结构相似性(MSSIM)
目录 一、定义与背景 二、计算流程 三、性质与特点 四、应用场景 五、代码实现 多尺度结构相似性(MSSIM)是一种用于衡量两幅图像之间相似度的指标,它基于结构相似性(SSIM)指数进行扩展,通过在不同尺度上计算SSIM来评估图像的整体质量。以下是对MSSIM的详细介…...

代码随想录第二十二天
回溯算法理论介绍 回溯算法是一种基于递归思想的算法设计技术,适用于解决需要构造所有解或找到特定解的组合问题。回溯的基本思路是通过系统地搜索所有可能的解决方案,然后逐步撤销不符合要求的选择,回到上一步继续尝试。这种算法最适合应用…...

【k8s】ClusterIP能http访问,但是不能ping 的原因
ClusterIP 服务在 Kubernetes 中是可以访问的,但通常无法通过 ping 命令来测试连通性。这主要是因为 ClusterIP 是一个虚拟 IP 地址,而不是实际分配给某个网络接口的 IP 地址。以下是一些原因和解释: 1. 虚拟 IP 地址 ClusterIP 是一个虚拟…...

【力扣打卡系列】单调栈
坚持按题型打卡&刷&梳理力扣算法题系列,语言为go,Day20 单调栈 题目描述 解题思路 单调栈 后进先出 记录的数据加在最上面丢掉数据也先从最上面开始 单调性 记录t[i]之前会先把所有小于等于t[i]的数据丢掉,不可能出现上面大下面小的…...

使用docker安装zlmediakit服务(zlm)
zlmediakit安装 zlmediakit安装需要依赖环境和系统配置,所以采用docker的方式来安装不容易出错。 docker pull拉取镜像(最新) docker pull zlmediakit/zlmediakit:master然后先运行起来 sudo docker run -d -p 1935:1935 -p 80:80 -p 8554:554 -p 10000:10000 -p …...

SOLID原则-单一职责原则
转载请注明出处:https://blog.csdn.net/dmk877/article/details/143447010 作为一名资深程序员越来越感觉到基础知识的重要性,比如设计原则、设计模式、算法等,这些知识的长期积累会让你突破瓶颈实现质的飞跃。鉴于此我决定写一系列与此相关的博客&…...

Transformer究竟是什么?预训练又指什么?BERT
目录 Transformer究竟是什么? 预训练又指什么? BERT的影响力 Transformer究竟是什么? Transformer是一种基于自注意力机制(Self-Attention Mechanism)的神经网络架构,它最初是为解决机器翻译等序列到序列(Seq2Seq)任务而设计的。与传统的循环神经网络(RNN)或卷…...

Jdbc批处理功能和MybatisPlus
文章目录 1. 序言2. JDBC批处理功能和rewriteBatchedStatements3. JDBC批量插入的测试4. MybatisPlus#ServiceImpl.saveBatch()5. 结语:如果对大家有帮助,请点赞支持。如果有问题随时在评论中指出,感谢。 1. 序言 MybatisPlus的ServiceImpl类…...

对于相对速度的重新理解
狭义相对论速度合成公式如下, 现在让我们尝试用另一种方式把它推导出来。 我们先看速度的定义, 常规的速度合成方式如下, 如果我们用速度的倒数来理解速度, 原来的两个相对速度合成, 是因为假定了时间单位是一样的&am…...
默认访问权限)
Scala的属性访问权限(一)默认访问权限
//eg:银行账户存钱取钱 // 账户类: // -balance() 余额 // -deposit() 存钱 // -withdraw() 取钱 // -transfer(to:账户,amount:Dobule)转账 package Test1104 //银行账户class BankAccount(private var balance:Int){def showMoney():Unit {println(s"…...

【算法】(Python)贪心算法
贪心算法: 又称贪婪算法,greedy algorithm。贪心地追求局部最优解,即每一步当前状态下最优选择。试图通过各局部最优解达到最终全局最优解。但不从整体最优上考虑,不一定全局最优解。步骤:从初始状态拆分成一步一步的…...

条件logistic回归原理及案例分析
前面介绍的二元、多分类、有序Logistic回归都属于非条件Logistic回归,每个个案均是相互独立关系。在实际研究中,还有另外一种情况,即个案间存在配对关系,比如医学研究中配对设计的病例对照研究,此时违反了个案相互独立…...
redis7学习笔记
文章目录 1. 简介1.1 功能介绍1.1.1 分布式缓存1.1.2 内存存储和持久化(RDBAOF)1.1.3 高可用架构搭配1.1.4 缓存穿透、击穿、雪崩1.1.5 分布式锁1.1.6 队列 1.2 数据类型StringListHashSetZSetGEOHyperLogLogBitmapBitfieldStream 2. 命令2.1 通用命令copydeldumpexistsexpire …...
)
重学Android:自定义View基础(一)
前言 作为一名安卓开发,也被称为大前端,做一个美观的界面,是我们必备的基础技能,可能在开发中我们最常用的是系统自带的View,因为他能满足绝大部分需求,难一点的我们也可以上Github上找个三方库使用&#…...

抖音下载终极指南:免费无水印批量保存完整方案
抖音下载终极指南:免费无水印批量保存完整方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音…...

终极指南:3分钟在Windows上安装苹果USB驱动和iPhone网络共享
终极指南:3分钟在Windows上安装苹果USB驱动和iPhone网络共享 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/…...

微软逐步淘汰 SMS 身份验证,通行密钥带来更强安全保障!
ZDNET 要点总结微软正在逐步淘汰将 SMS 作为身份验证方式,因为 SMS 消息未加密,易受黑客攻击。微软账户所有者将被提示设置通行密钥。通常登录或找回在线账户时会收到 SMS 验证短信,但这并非安全的身份验证方式,如今微软对使用微软…...
)
无人超市|基于Java+vue的无人超市管理系统(源码+数据库+文档)
无人超市管理系统 基于SprinBootvue的无人超市管理系统 一、前言 二、系统设计 三、系统功能设计 系统功能实现 后台管理员模块实现 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂…...

多模型选型实验场景下Taotoken模型广场的价值与应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型选型实验场景下Taotoken模型广场的价值与应用 在模型技术快速迭代的今天,无论是学术研究还是产品开发࿰…...

在OpenClaw Agent工作流中无缝接入Taotoken调用多模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw Agent工作流中无缝接入Taotoken调用多模型能力 对于使用OpenClaw构建智能体工作流的开发者而言,能够灵活调…...

Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单
Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为想玩Steam创意工坊的模组却没有Steam账号…...

毕业论文格式反复返工?paperxie 智能排版教你一键通过导师审核
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 作为毕业季最耗时耗力的 “机械劳动”,论文格式调整往往比正文写作更磨人。字号、行距、页眉页…...

Agent Skills 万千应用 · 第04篇 Excel 分析 Skill:让 Agent 会整理表格、建公式、画图表
Agent Skills 万千应用 第04篇 Excel 分析 Skill:让 Agent 会整理表格、建公式、画图表01|场景痛点开场📊 周一早上,老板丢过来一份 Excel:销售流水 8000 行、客户名称有重复、日期格式不统一、金额里还混着“元”和空…...

Airflow Maintenance Dags:7个关键维护工作流彻底解决Airflow运维难题
Airflow Maintenance Dags:7个关键维护工作流彻底解决Airflow运维难题 【免费下载链接】airflow-maintenance-dags A series of DAGs/Workflows to help maintain the operation of Airflow 项目地址: https://gitcode.com/gh_mirrors/ai/airflow-maintenance-dag…...