【数据结构】堆和二叉树(2)
文章目录
- 前言
- 一、建堆和堆排序
- 1.堆排序
- 二、二叉树链式结构的实现
- 1.二叉树的遍历
- 三、链式二叉树的功能函数
- 1.二叉树结点个数
- 2.二叉树叶子结点个数
- 3.二叉树的高度
- 4.二叉树第k层结点个数
- 5. 二叉树查找值为x的结点
- 6.二叉树销毁
- 总结
前言
接着上一篇博客,我们继续分享关于堆和二叉树的知识,这里小编会跟大家分享关于如何建堆,堆排序,二叉树的链式结构以及相关知识。

一、建堆和堆排序
如果我们这里想要实现堆排序,那么我们就需要一个堆,在堆的基础之上实现排序。所以这里就需要建堆了。那这里就有一个问题了。
如果是升序的话我们该建大堆还是小堆呢?降序又该建大堆还是小堆呢?

这里我们可以得出结论了嘛!降序建小堆,升序建大堆
1.堆排序
1.建堆:
跟之前的堆的插入一样,但是这样有个弊端就是,每插入一个数据就要申请一个空间呀。大大地减低了代码的运行效率。那我们是数组的话那是不是太浪费时间了呀,还要一个个的插入。那有没有一种方法就是在不开辟新的空间的前提下让数组里面的数据有序呀?这里就要用到排序了呀。可以用冒号,选择。但是这两种的效率是不是很低呀?时间复杂度是O(N)^2。欧克,今天我们就要引入一个新的排序方法:堆排序。既然是堆排序,那是不是就需要一个堆呀?那怎样建堆呢?有两种建堆方式:
// 向上建堆
void HeapSort(int* arr, int n)
{for (int i = 0; i < n; i++){AdjustUp(arr, i);}int main()
{int arr[] = { 2,4,5,6,7 };HeapSort(arr, sizeof(arr) / sizeof(int));return 0;
}
//向下建堆
void HeapSort(int* arr, int n)
{for (int i = (n-1-1)/2; i >=0; i--){AdjustDowan(arr, n,i);}
}int main()
{int arr[] = { 2,4,5,6,7 };HeapSort(arr, sizeof(arr) / sizeof(int));return 0;
}
这里需要注意的是。向下调整是从最后一个父亲节点开始依次向下调整的。拿为什么不是从最后一个数据开始呢?因为最后一个数据已经有序了呀!那还需要调整吗?
这样建堆的话是不是就避免了要重新开辟一个新的空间呀?在原数组之上直接建堆。
2.向上调整建堆和向下调整建堆
// 向上调整建堆
void AdjustUp(int* arr, int chiled)
{int parent = (chiled - 1) / 2;while (chiled > 0){if (arr[chiled] < arr[parent]){Swap(&arr[chiled], &arr[parent]);chiled = parent;parent = (chiled - 1) / 2; }else{break;}}
}
// 向下调整建堆
void AdjustDown(int* arr, int n, int parent)
{int chiled = 2 * parent + 1;while (chiled < n){if (chiled + 1 < n && arr[chiled + 1] < arr[chiled]){++chiled;}if (arr[parent] >arr[chiled]){Swap(&arr[parent], &arr[chiled]);parent = chiled;chiled = 2 * parent + 1;}else{break;}}
}
这个就是向上和向下调整建堆,这个就是我们之前的堆的插入和堆删除那里的向上调整建堆是一样的。如果不知道的可以取看一下小编之前讲堆的那个章节:https://editor.csdn.net/md/articleId=142728291
void Swap(int* p1, int* p2)
{int* tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void AdjustUp(int* arr, int chiled)
{int parent = (chiled - 1) / 2;while (chiled > 0){if (arr[chiled] < arr[parent]){Swap(&arr[chiled], &arr[parent]);chiled = parent;parent = (chiled - 1) / 2; }else{break;}}
}
void AdjustDown(int* arr, int n, int parent)
{int chiled = 2 * parent + 1;while (chiled < n){if (chiled + 1 < n && arr[chiled + 1] < arr[chiled]){++chiled;}if (arr[parent] >arr[chiled]){Swap(&arr[parent], &arr[chiled]);parent = chiled;chiled = 2 * parent + 1;}else{break;}}
}
void HeapSort(int* arr, int n)
{for (int i = 0; i < n; i++){AdjustUp(arr, i);}int end = n - 1;//最后一个数据while (end > 0){Swap(&arr[0], &arr[end]);AdjustDown(arr, end, 0);--end; }for (int i = 0; i < n; i++){printf("%d ", arr[i]);}printf("\n");
}
int main()
{int arr[] = { 2,4,5,6,7 };HeapSort(arr, sizeof(arr) / sizeof(int));return 0;
}
大家可以看出我们我们这个代码则是一个建小堆的过程,建小堆是不是降序呀?我们来来看看这个代码的运行结果:

那如果是升序的话,只需要把向上和向下调整建堆哪里改一下就欧克了,改成大堆就行了,这回该知道为什么:降序建小堆,升序建大堆
以上就是关于建堆和堆排序的相关知识了。接下来我们来看看二叉树链式结构的实现
二、二叉树链式结构的实现
为了方便学习链式二叉树的知识,那我们必须要有一棵树呀!这里呢为了方便好理解,我这里呢就直接手搓一颗树用来分享:

这下面是他的代码实现:
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int BTDataType;
typedef struct BinaryTreeNode
{BTDataType data;struct BinaryTreeNode* left;struct BinaryTreeNode* right;
}BTNode;
BTNode* BuyNode(BTDataType x)
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("malloc fail");exit(1);}newnode->data = x;newnode->left = NULL;newnode->right = NULL;return newnode;
}
BTNode* CreatBinaryTree()
{BTNode* node1 = BuyNode(1);BTNode* node2 = BuyNode(2);BTNode* node3 = BuyNode(3);BTNode* node4 = BuyNode(4);BTNode* node5 = BuyNode(5);BTNode* node6 = BuyNode(6);node1->left = node2;node1->right = node4;node2->left = node3;node4->left = node5;node4->right = node6;return node1;
}
int main()
{CreatBinaryTree();return 0;
}
注意:上述代码并不是创建二叉树的方式,真正创建二叉树方式后序详解重点讲解。
1.二叉树的遍历
二叉树的遍历呢分为前序遍历,中序遍历,后序遍历按照规则,每种遍历的顺序是不一样的。
前序遍历:根—>左子树—>右子树
中序遍历:左子树—>根—>右子树
后序遍历:左子树—>右子树—>根
我们拿第一种来说,他的意思就是先访问根节点,然后在访问左子树,最后才右子树

首先我们先访问的是1,然后在访问1节点的左子树,1的左子树不为空,所以访问2,在访问2的左子树,2的左子树不为空,所以访问3,然后在访问3的左子树,3的左子树为空,返回到3,在访问3的右子树,3的右子树为空 ,返回到3,然后3访问完了就返回到2,在访问2的右子树。右子树为空,返回到2,2也访问完了返回到1,1的左子树全部访问完毕,接下来就访问右子树4,4的左子树不为空,所以访问5,在访问5的左子树,5的左子树为空,返回到5,在访问5的右子树,右子树为空返回到5,5访问完了在返回到4,在访问4的右子树,右子树不位空,所以访问6,在访问6的左子树,左子树为空,返回到6,在访问6的右子树,右子树为空,返回到6,6已经被访问完,返回到4,4的已经被访问完,在返回到1,1也被访问完了,所以跳出。
注意:不管怎样访问,我们都把二叉树分为根,左子树和右子树三部分。
一般的情况从逻辑的角度的方面来说,逻辑上我们就是将一棵树的前序遍历分为根的访问和左右子树的遍历。左右子树的遍历我们又可以看成一棵树的前序遍历。所以这里要用到了递归。
代码实现:我们现在已经了解前序遍历。那我们要怎样才能实现代码呢?
void PreOrder(BTNode* root)//前序遍历
{if (root == NULL){printf("N");return;}printf("%d", root->data);PreOrder(root->left);PreOrder(root->right );
}
void InOrder(BTNode* root)//中序遍历
{if (root == NULL){printf("N");return;}InOrder(root->left);printf("%d", root->data); InOrder(root->right);
}
void PostOrder(BTNode* root)//后序遍历
{if (root == NULL){printf("N");return;}PostOrder(root->left); PostOrder(root->right);printf("%d", root->data);
}
由于前序,中序,后序遍历大同小异,所以我这里就全部写出来了。

层序遍历:
从字面意思来理解就是一层一层的遍历嘛。确实,它的确是一层一层的遍历。首先访问第一层的根节点,然后在从左到右访问第二层,这样依次类推。那样怎样代码实现,这里就要借助我们之前学的队列了 。利用队列先进先出的规则来实现。

void TreeLevelOrder(BTNode* p)//层序遍历
{Queue pq;QueueInit(&pq);//初始化队列if(p)QueuePush(&pq, p);//第一层入队列while (!QueueEmpty(&pq))//队列不为空{BTNode* head = QueueFron(&pq);//取出队头数据QueuePop(&pq);//出队列printf("%d ", head->a);//访问if (head->left){QueuePush(&pq, head->left);//左孩子入队列}if (head->right){QueuePush(&pq, head->right);//右孩子入队列}}QueueDestroy(&pq);//销毁队列
}
这里需要注意的是:我们这里存储的是结点指针,因为我们要访问左右子树。
三、链式二叉树的功能函数
1.二叉树结点个数
想要算出二叉树的个数,大多数情况我们会想到在遍历的时候用一个变量来表示节点的个数:就像这样:
int TreeSize(BTNode* root)
{int size = 0;if (root == NULL){return 0;}size++;TreeSize(root->left); TreeSize(root->right);return size;
}
int main()
{BTNode *root= CreatBinaryTree();printf("节点的个数:");int ret = TreeSize(root); printf("%d", ret);
}

但是这里的结果却是1呀?为什么呢?其实呀?这里的size是一个局部变量,每次调用呢都会被置为0,所以后面最多只能自加一次,所以结果是1,那我们把这里改为静态的使他的生命周期变为全局变量呢?
int TreeSize(BTNode* root)
{static int size = 0;if (root == NULL){return 0;}size++;TreeSize(root->left);TreeSize(root->right);return size;
}
int main()
{int size = 0;BTNode *root= CreatBinaryTree();printf("节点的个数:");int ret = TreeSize(root); printf("%d", ret);printf("\n");printf("节点的个数:"); int ret1 = TreeSize(root);printf("%d", ret1);
}

这里呢我们可以看见第一次呢是没有问题的,但是第二次调用为什么就是12了呢?因为这里的局部的静态变量只会初始化一次,但你第二次调用的是它初始化的值是上一次调用的结果。所以这里就是6+6=12了。那要这样解决呢?这里我们只需要在第二次调用之前重新把size置为0就行了。
int size=0;
int TreeSize(BTNode* root)
{if (root == NULL){return 0;}size++;TreeSize(root->left);TreeSize(root->right);return size;
}
int main()
{BTNode *root= CreatBinaryTree();printf("节点的个数:%d\n",TreeSize(root));size = 0;printf("节点的个数:%d", TreeSize(root));printf("\n");
}

当然还有一种就是传一个形参,从外边传一个变量的形参过来。
int TreeSaze(BTNode*root,int* k)
{if (root == NULL){return 0;}(*k)++;;TreeSaze(root->left,k); TreeSaze(root->right,k); return (*k);
}
这里的返回值其实要不要都无所谓的,返回也行,不返回也行。
这里呢以上的就是算二叉树节点的代码了,其实还有一种更简单的思路:分治递归
我们把二叉树的所有的节点都看成左子树+右子树+根

我们结合代码来看。
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}return BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
}
int main()
{BTNode* root = CreatBinaryTree();printf("节点的个数是:");printf("%d\n", BinaryTreeSize(root));return 0;
}
这样子是不是就简单多了呀?只是这个比较难理解。不过只要你熟练掌握递归就可以很轻松的理解了。
2.二叉树叶子结点个数
二叉树的叶子是不是度为0的节点。叶子节点的个数=左子树+右子树。所以这里又要用到分治递归了。
int TreeLeafSize(BTNode* root)//叶子节点
{if (root == NULL){return 0;}if (root->left == NULL && root->right == NULL){return 1;}return TreeLeafSize(root->left) + TreeLeafSize(root->right);
}这里要注意的是要考虑如果树是空树的情况
3.二叉树的高度
想要算出二叉树的高度,是不是要算出左右子树的高度呀?然后选择高度最高的来加上根的高度呀?
要是是一个空树的话,那就返回0。
int TreeHight(BTNode* root)//高度
{if (root == NULL){return 0;}return TreeHight(root->left)> TreeHight(root->right) ? TreeHight(root->left)+1: TreeHight(root->right)+1;
}
int main()
{BTNode* root = CreatBinaryTree();printf("节点的个数是:");printf("%d\n", TreeHight(root));return 0;
}
这样可不可以呢?由于我们这里给的数据太少了,所以代码就能跑过。但是这里存在一个效率问题。

int TreeHight(BTNode* root)//高度
{if (root == NULL){return 0;}int LeftHight = TreeHight(root->left);int RightHight = TreeHight(root->right);return LeftHight > RightHight ? LeftHight + 1: RightHight+1;
}
int main()
{BTNode* root = CreatBinaryTree();printf("节点的个数是:");printf("%d\n", TreeHight(root));return 0;
}
像这样把访问的数据储存起来。
4.二叉树第k层结点个数

int TreeLeveKsize(BTNode* root,int k)
{if (root == NULL)return 0;if (k == 1)return 1;return TreeLeveKsize(root->left,k-1) + TreeLeveKsize(root->right,k-1);
}
5. 二叉树查找值为x的结点
查找x的节点其实是一个看似很简单。实则不简单的一个代码,思路好理解,但是要写出正确的代码就得要仔细思考了
BTNode* TreeFind(BTNode* root, BTDataType x)
{if (root == NULL)return NULL; if (root->data == x)return root ;TreeFind(root->left,x);TreeFind(root->right, x);
}
来看看这个代码是不是正确的。其实这里有两个问题,第一个就是如果我找到要找的数据。那我是不是要返回上一个栈帧呀,但是这里数据没有被接收呀。那我们返回的是什么?就不知道了是吧。第二呢就是。如果在左子树已经找到了,那是不是就不需要再找了呀?那万一右子树也有一个要找的数据怎么办?这时候直接返回第一次找到的数据就ok,原因就是函数返回值只能返回一个。不能返回多个数据。
那正确的代码就是:
BTNode* TreeFind(BTNode* root, BTDataType x)
{if (root == NULL)return NULL;
if (root->data == x)return root;BTNode* ret1 = TreeFind(root->left, x); if (ret1){return ret1;}BTNode* ret2 = TreeFind(root->right, x); { return ret2;}return NULL;
}
BTNode* TreeFind(BTNode* root, BTDataType x)//优化代码
{if (root == NULL)return NULL;if (root->data == x)return root;BTNode* ret1 = TreeFind(root->left, x);if (ret1){return ret1;}return TreeFind(root->right, x);}
这两种代码都是可以的。
6.二叉树销毁
二叉树的销毁跟其他的销毁有点不一样哦。这里要用到后序遍历来销毁。那为什么要用后序遍历呢而不用前序遍历和中序遍历呢?这里其实都可以。但是这个时候我们就要一个变量来储存左孩子和有孩子(前序遍历销毁)。如果直接释放掉根节点,不然就找不到根的左右孩子了
void BinaryTreeDestory1(BTNode* root)//前序遍历销毁
{if (root == NULL)return;BTNode* newnode = root->left;BTNode* newnode1 = root->right;free(root);BinaryTreeDestory1(newnode);BinaryTreeDestory1(newnode1);//root=NULL;
}
void BinaryTreeDestory2(BTNode* root)//中序遍历销毁
{if (root == NULL)return;BTNode* newnode1 = root->right;BinaryTreeDestory2(root->left );free(root);BinaryTreeDestory2(newnode1);//root=NULL;
}
void BinaryTreeDestory(BTNode*root)//后序遍历销毁
{if (root == NULL)return;BinaryTreeDestory(root->left);BinaryTreeDestory(root->right );free(root);//root=NULL;
}
int main()
{BTNode* root = CreatBinaryTree();BinaryTreeDestory(root);root = NULL;return 0;
}
那我们这里在释放后要不要把root置为空呢?这里置不置空都行,因为传的是一级指针呀。形参的改变不会改变外边的实参。所以这里可以置可不置。正常使用呢是在主函数哪里当我要用的时候在置为空
总结
今天的分享就到这里吧。再见咯,各位!

相关文章:
【数据结构】堆和二叉树(2)
文章目录 前言一、建堆和堆排序1.堆排序 二、二叉树链式结构的实现1.二叉树的遍历 三、链式二叉树的功能函数1.二叉树结点个数2.二叉树叶子结点个数3.二叉树的高度4.二叉树第k层结点个数5. 二叉树查找值为x的结点6.二叉树销毁 总结 前言 接着上一篇博客,我们继续分…...

Oracle分区技术特性
Oracle 的分区是一种“分而治之”的技术,通过将大表、索引分成可以独立管理的、小的 Segment,从而避免了对每个对象作为一个大的、单独的 Segment 进行管理,为海量数据访问提供了可伸缩的性能。自从 Oracle 引入分区技术以来,Orac…...

Hive操作库、操作表及数据仓库的简单介绍
数据仓库和数据库 数据库和数仓区别 数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别 操作型处理(数据库),叫联机事务处理OLTP(On-Line Transaction Processing),也可以称面向用户交易的处理系统,它是针对具体业务…...

智能网联汽车:人工智能与汽车行业的深度融合
内容概要 在这个快速发展的时代,智能网联汽车已经不再是科幻电影的专利,它正在悄然走进我们的日常生活。如今,人工智能(AI)技术与汽车行业的结合犹如一场科技盛宴,让我们看到了未来出行的新方向。通过自动…...

VUE 循环的使用方法集锦
vue---循环方式以及跳出循环 在做VUE项目开发过程中,数据循环是常见的操作方式,以下是几种常见的数据循环方式: 一、for循环 let data [1,2,3,4,5,6,7,8,9,10]; for(let i0; i<data.length; i){console.log(data[i]);if(i>5){break;…...

Centos部署资料
1. 离线rpm 1.1 下载地址: 阿里云rpmfind 1.2 本地安装: [rootlocalhost ~]# yum localinstall unzip-6.0-21.el7.x86_64.rpm2. 服务器操作 2.1 修改网络ip [rootlocalhost ~]# cd /etc/sysconfig/network-scripts/ [rootlocalhost network-script…...

AI之硬件对比:据传英伟达Nvidia2025年将推出RTX 5090-32GB/RTX 5080-24GB、华为2025年推出910C/910D
AI之硬件对比:据传英伟达Nvidia2025年将推出RTX 5090-32GB/RTX 5080-24GB、华为2025年推出910C/910D 目录 Nvidia的显卡 Nvidia的5090/5080/4090/4080:据传传英伟达Nvidia RTX 5090后续推出32GB版且RTX 5080后续或推出24GB版 RTX 5090相较于RTX 4090&…...

其他节点使用kubectl访问集群,kubeconfig配置文件 详解
上述两种方式:可使用kubectl连接k8s集群。 $HOME/.kube/config 是config文件默认路径,要么直接定义环境变量,要么就直接把文件拷过去 config文件里面,定义了context,里面指定了用户和对应的集群信息: ku…...

【鉴权】深入解析OAuth 2.0:访问令牌与刷新令牌的安全管理
目录 引言一、访问令牌(Access Token)1.1 访问令牌概述1.2 访问令牌的格式1.2.1 JWT(JSON Web Token)1.2.1.1 JWT 结构1.2.1.2 示例 JWT 1.2.2 Bearer Token 1.3 访问令牌的有效期1.4 访问令牌的工作流程 二、刷新令牌(…...

【AI视频换脸整合包及教程】AI换脸新星:Rope——让换脸变得如此简单
在数字技术迅猛发展的今天,人工智能(AI)的应用已经渗透到了我们生活的方方面面,从日常的语音助手到复杂的图像处理,无不体现着AI技术的魅力。特别是在娱乐和创意领域,AI技术更是展现出了惊人的潜力。其中&a…...
)
限界上下文(Bounded Context)
限界上下文(Bounded Context):领域驱动设计中的重要概念 在领域驱动设计(Domain-Driven Design, DDD)中,限界上下文(Bounded Context)是一个非常重要的概念。限界上下文定义了一个特定领域模型的边界,确保在这个边界内,领域模型的术语、规则和逻辑是一致的。通过明确…...

20241105专家访谈学习资料
“两性一度” 即高阶性、创新性、挑战度。“三性一度”是指教学目标的适应性、教学内容的先进性、教学实施的实践性及教学评价的有效度。“四性一度”是指系统性、层次性、前瞻性、专业性以及培养目标达成度。“二性一度”用词比较规范、标准统一,“三性一度”和“四…...

Docling:开源的文档解析工具,支持多种格式的解析和转换,可与其他 AI 工具集成
❤️ 如果你也关注大模型与 AI 的发展现状,且对大模型应用开发非常感兴趣,我会快速跟你分享最新的感兴趣的 AI 应用和热点信息,也会不定期分享自己的想法和开源实例,欢迎关注我哦! 🥦 微信公众号ÿ…...

oracle如何在不同业务场景下正确使用聚合查询、联合查询及分组查询?
引言 在数据库管理系统中,SQL(结构化查询语言)是用于与数据库进行交互的标准语言。 Oracle数据库作为一种广泛使用的关系数据库管理系统,提供了丰富的SQL功能,包括聚合查询、联合查询和分组查询等。 这些功能在数据…...

Hearts of Iron IV 之 Archive Modification
存档位置 C:\Users\XXX\Documents\Paradox Interactive\Hearts of Iron IV\save games 打开文档 打开C:\Users\XXX\Documents\Paradox Interactive\Hearts of Iron IV\settings.txt,将save_as_binaryyes 改成save_as_binaryno,然后退出游戏重新存档&a…...

python manage.py下的命令及功能
python manage.py 是 Django 框架中用于管理 Django 项目的命令行工具 1、startapp: 功能:创建一个新的 Django 应用程序。 用法:python manage.py startapp appname 示例:python manage.py startapp blog 2、startproject&a…...

建筑行业员工离职SOP的数字化管理
在建筑行业,随着数字化转型的深入,对员工离职的标准操作程序(SOP)进行数字化管理变得尤为重要。这不仅有助于提高管理效率,还能确保离职流程的规范性和合规性。本文将探讨建筑行业如何通过数字化手段管理员工离职SOP&a…...
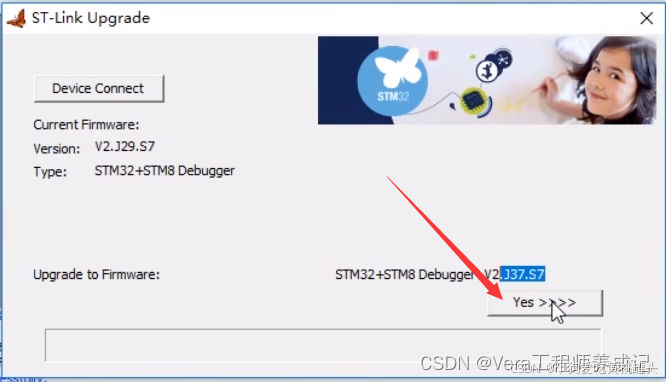
江协科技STM32学习- P30 FlyMCU串口下载STLink Utility
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...

05LangChain实战课 - 提示工程与FewShotPromptTemplate的应用
LangChain实战课 - 提示工程与FewShotPromptTemplate的应用 提示工程的重要性 在LangChain框架中,提示工程是构建有效大模型应用的关键。通过精心设计的提示,我们可以引导大语言模型(LLM)生成预期的输出。本节课深入探讨了如何利…...

【数据处理】数据预处理·数据变换(熵与决策树)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀软件开发必备知识_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前…...

Saleor:应对现代电商架构挑战的无头商业引擎解决方案
Saleor:应对现代电商架构挑战的无头商业引擎解决方案 【免费下载链接】saleor Saleor Core: the high performance, composable, headless commerce API. 项目地址: https://gitcode.com/gh_mirrors/sa/saleor 在数字化转型浪潮中,电商平台面临的…...

数据治理:数据质量与元数据管理
数据治理:数据质量与元数据管理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊数据治理这个重要话题。作为一个全栈开发者,数据治理是确保数据资产价值的关键。今天就来分享一下数据质量和元数据管理的实战经验。 数…...

Perseus:5分钟解锁碧蓝航线全皮肤的神奇补丁
Perseus:5分钟解锁碧蓝航线全皮肤的神奇补丁 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 还在为碧蓝航线中那些精美皮肤需要付费而烦恼吗?想免费体验所有舰娘的不同外观吗&…...

CTF流量分析实战:从协议层还原攻击链
1. 这不是“看图说话”,而是网络攻防现场的证据链重建CTF流量分析题,很多人第一反应是打开Wireshark点开pcap文件,扫一眼HTTP请求、找找base64字符串、翻翻DNS查询——然后卡在第3个包就停了。我带过三届校队,每年都有至少一半选手…...
作用与上市,全球首个犬用 JAK 抑制剂)
爱波克 Apoquel(奥拉替尼)作用与上市,全球首个犬用 JAK 抑制剂
奥拉替尼是全球首个获批用于兽医的 JAK 抑制剂,2013 年 5 月美国 FDA 获批,2023 年 6 月推出咀嚼片剂型,提升用药依从性Zoetis。其作用机制为选择性抑制 JAK1,阻断 IL-4、IL-13、IL-31 等关键致痒与促炎细胞因子信号,从…...

QTTabBar终极指南:5分钟掌握Windows文件管理标签页神器
QTTabBar终极指南:5分钟掌握Windows文件管理标签页神器 【免费下载链接】qttabbar QTTabBar is a small tool that allows you to use tab multi label function in Windows Explorer. https://www.yuque.com/indiff/qttabbar 项目地址: https://gitcode.com/gh_m…...

甲骨文免费服务器到手后,用Xshell连接不上?这份SSH密钥配置避坑指南请收好
甲骨文云SSH连接全攻略:从密钥解析到Xshell实战配置 密钥管理的核心逻辑与常见误区 初次接触甲骨文云免费实例的用户,90%的SSH连接问题都源于密钥处理不当。与常规密码登录不同,甲骨文云强制采用密钥对认证机制,这种设计虽然提升了…...

别再复制粘贴了!Element Plus 表格组件与SpringBoot后端数据联调实战
别再复制粘贴了!Element Plus 表格组件与SpringBoot后端数据联调实战 在前后端分离的开发模式中,前端表格组件与后端数据的动态联调是每个开发者必须掌握的技能。Element Plus作为Vue3生态中最受欢迎的UI组件库之一,其表格组件(el-table)的灵…...

DLSS版本管理器:5分钟掌握游戏性能优化终极指南
DLSS版本管理器:5分钟掌握游戏性能优化终极指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾因游戏帧数不稳定而烦恼?是否想体验最新DLSS技术带来的性能提升却不知从何入手ÿ…...

LeetCode 409:最长回文串 | 哈希表统计字符频率
LeetCode 409:最长回文串 | 哈希表统计字符频率 引言 最长回文串(Longest Palindrome)是 LeetCode 第 409 题,难度为 Easy。题目要求在给定字符串中构造最长的回文串,返回其长度。这道题虽然简单,但蕴含了回…...