NPU 可不可以代替 GPU
结论
先说结论,GPU分为可以做图形处理的传统意义上的真GPU,做HPC计算的GPGPU和做AI加速计算的GPGPU,所以下面分别说:
- 对于做图形处理的GPU,这个就和NPU 一样,属于DSA,没有替代性。当然,相信题主问的也不是这个
- 对于做HPC计算的GPGPU,需要的是通用的64位浮点的乘加运算能力,一般NPU为了追求AI计算性能,对64位浮点一般也是不支持,或者支持有限,所以这块也是不能替代的;题主关心的应该也不是这块
- 最后就是专门用于AI加速的GPGPU,这块由于数据精度要求相对有限,而且主要计算是矩阵,如果不考虑软件框架支持程度,在同一工艺制程其实各类NPU应该是优于GPGPU的,所以这类是肯定可以替代的
下面以华为昇腾芯片 和英伟达的芯片为例,来了解两者在架构上区别。昇腾910 (Ascend 910 ) 是华为2019年发布产品,计算部分采用达芬奇架构。NVIDIA对应的是2020年发布的Ampere系列A100。
Ascend 910
昇腾910采用chiplet方案,一共8个die,4个HBM,2个dummy die,1个soc die,一个NIMBUS die;其中两个dummy die用来保持芯片整体机械应力平衡; 四个HBM总带宽为 1.2TB/s;昇腾910整体布局如下图所示:
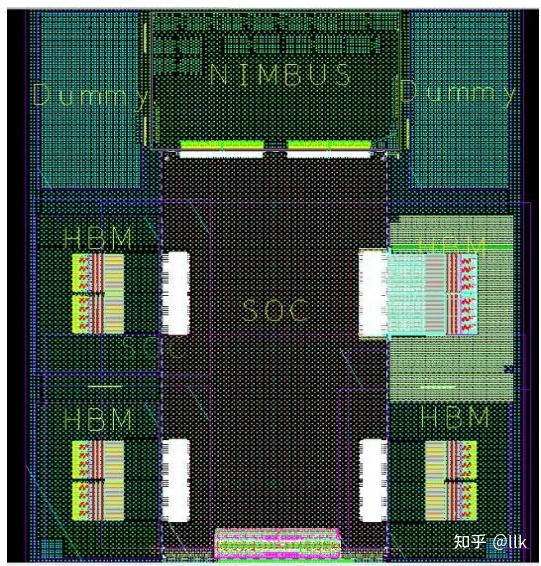
不同die的面积如下所示:
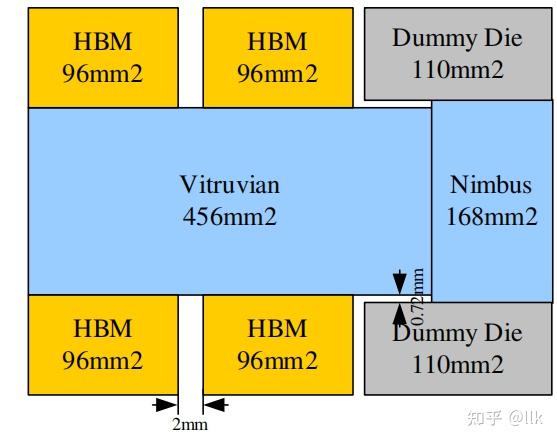
其中soc die主要用来计算,采用台积电7nm工艺,面积456mm^2,可以提供512TOPS的INT8性能;soc die的物理规划如下所示:
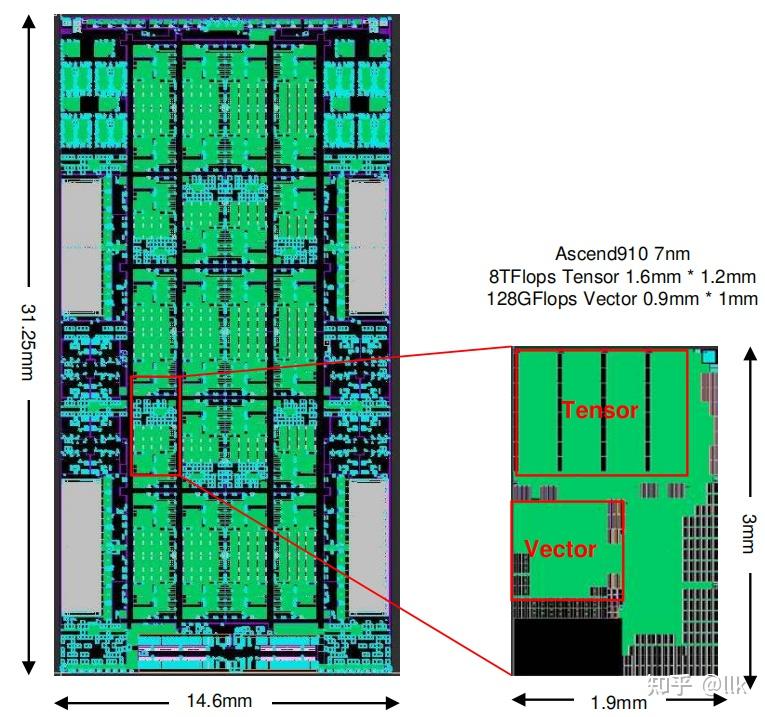
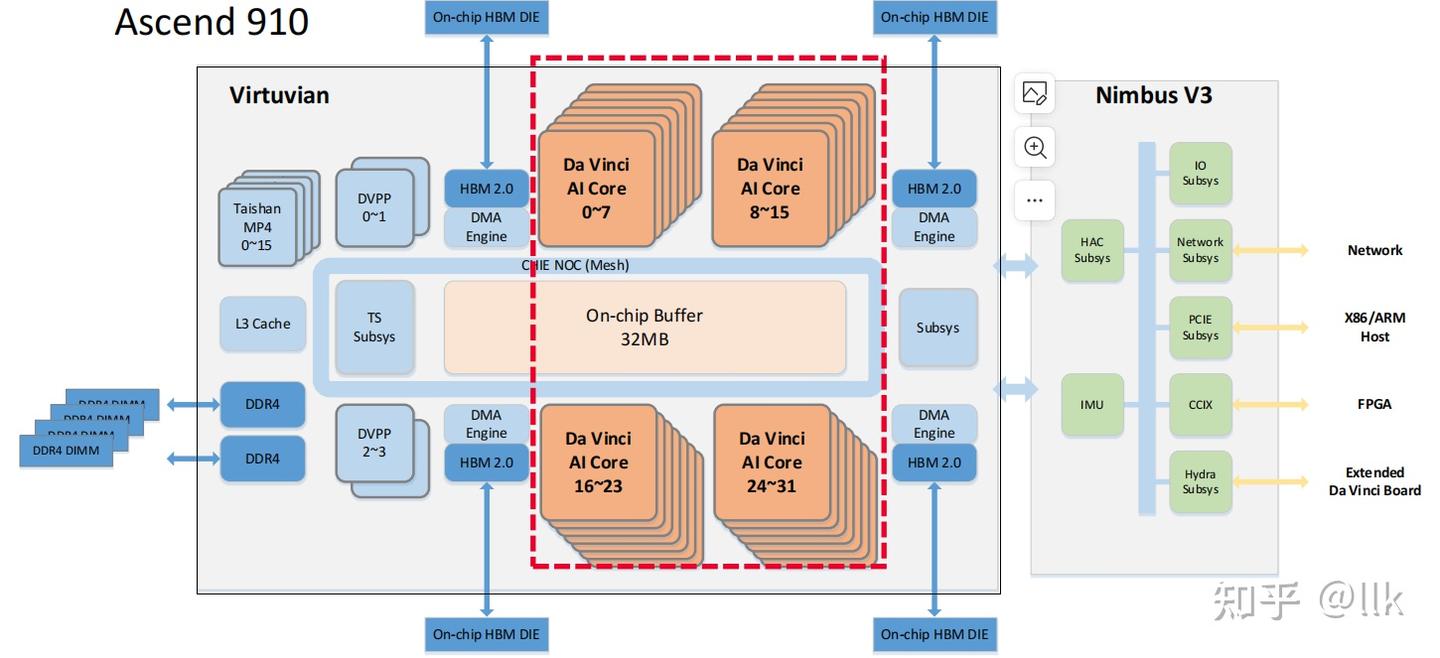
SoC die包含 32 个 Ascend-Max 内核、16 个 Arm V8 TaiShan CPU 内核和 CPU LLC、视频编解码器(Digital Vision Pre-Processor),支持128路的全高清视频解码,以及一个连接上述组件的片上网络 (NoC)。NoC采用4x6的mesh拓扑,以提供统一且可扩展的通信网络;两个相邻节点之间的链路工作频率为 2GHz,数据位宽为 1024 位,可以提供256GB/S 的带宽。NoC不使用缓冲,减少 NoC 的面积开销。SoC die和Nimbus die架构框图如下所示:
DaVinci
DaVinci核由三种计算单元、多级片上存储器和相应的加载/存储单元、指令管理单元等组成;DaVinci核是异构架构,结合了标量、向量和张量计算单元;总线接口单元(BIU)在昇腾内核和外部组件之间传输数据/指令;DaVinci架构框图如下所示:
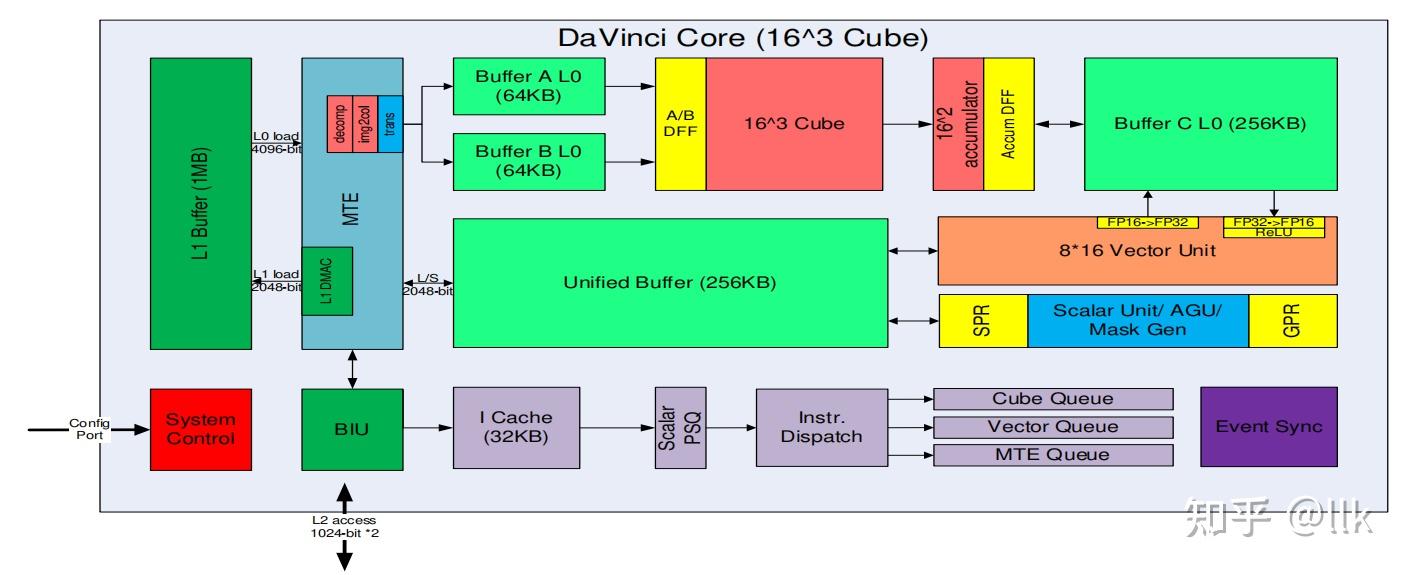
下表列出了三种计算单元支持的典型操作:

- 标量计算单元主要负责地址等标量计算
- 向量计算单元可以进行归一化,激活等计算;向量单元还负责数据精度转换,例如 int32、fp16 和 int8 之间的量化和解量化操作;向量单元还可以实现 fp32 操作
- 张量计算单元主要是矩阵计算,包括卷积,全连接,矩阵乘等;张量计算中矩阵的典型尺寸为 16 x 16 x 16。因此,张量计算单元配备了 4096 个乘法器和 4096 个累加器。矩阵计算中的每个操作数被重复使用 16 次。因此,与向量单元相比,将操作数加载到张量单元的能耗降低到 1/16
DaVinci核包括多个缓冲区,分成不同层次。L0 缓冲区专用于张量计算单元,分成三个单独的 L0 缓冲区,分别是缓冲区 A L0、缓冲区 B L0 和缓冲区 C L0。它们分别用于保存输入特征数据、权重和输出特征数据。缓冲区 A L0 和缓冲区 B L0 中的数据从 L1 缓冲区加载。L0 缓冲区和 L1 缓冲区之间的通信由内存传输引擎MTE(Memory Transfer Engine) 管理。MTE 中有几个功能模块:
- decomp 模块借助零值压缩的算法来解压缩稀疏网络的数据
- img2col 模块用于将卷积转换成矩阵乘法
- trans 模块用于矩阵转置
缓冲区 C L0 中的输出结果可以由向量单元处理(例如归一化或激活)。向量单元的输出结果被分配到统一缓冲区Unified Buffer中,该缓冲区与标量单元共享。数据存储在 L1 缓冲区中,指令存储在指令缓存中。指令执行流程如下:
- 指令首先由PSQ (Program Sequence Queue) 排序
- 根据指令类型,分别分发到三个队列,即多维数据集队列(cube queue)、向量队列和 MTE 队列
- 指令分别由相应的计算单元处理
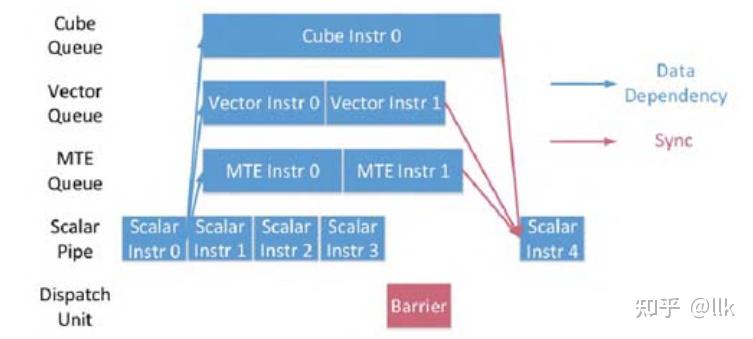
由于三个计算单元和 MTE 并行工作,因此需要显式同步来确保不同执行单元之间的数据依赖关系。下图展示了相应流程,PSQ 不断向不同的单元发送指令,这些指令可以并行处理,直到遇到显式同步信号(屏障);屏障由编译器或程序员生成。
系统扩展
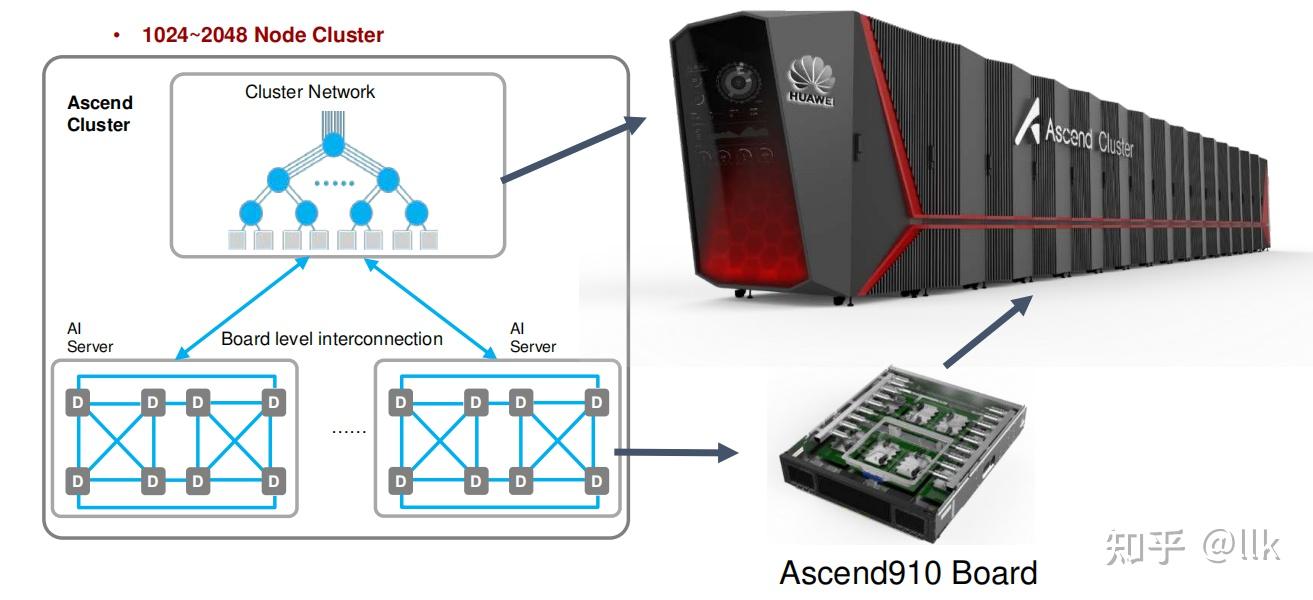
每台昇腾910服务器 包含8个昇腾910芯片,并分为两组;组内连接基于高速缓存一致性网络HCCS (high-speed cache coherence network),提供30GB/S带宽 。两个组使用 PCI-E 总线相互通信,提供32GB/S带宽。整体形成hyper cube mesh网络拓扑。多台昇腾910服务器可以通过fat-tree 的网络拓扑组织成一个集群。下图展示了一个 2048 节点的集群,可以提供512 Peta FLOPS的 fp16 总计算能力,包含 256 台服务器,服务器之间的链路带宽为 100Gbps。
编程模型
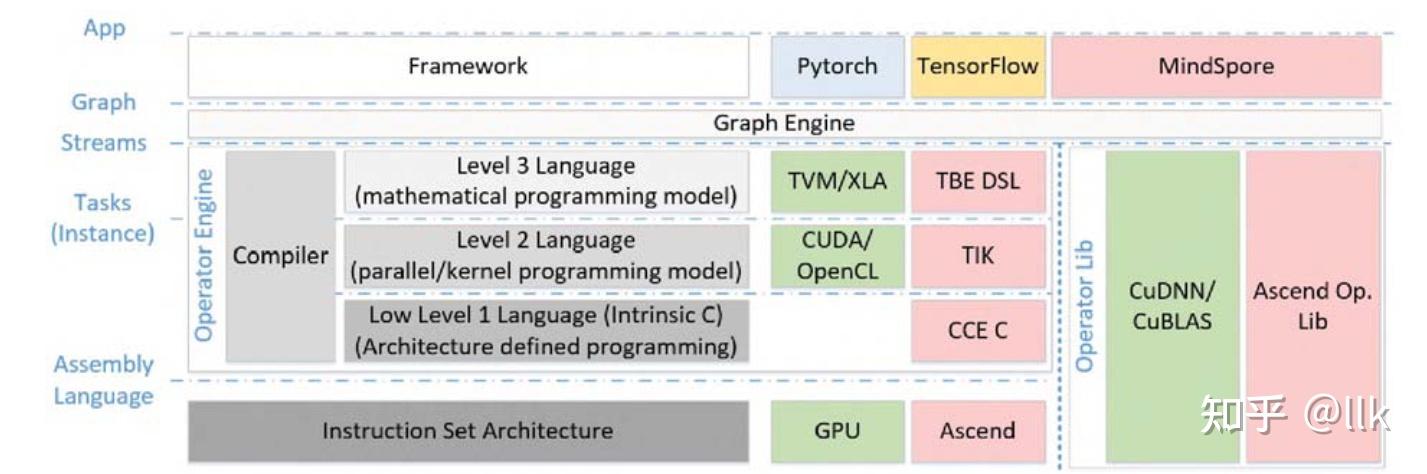
PyTorch、TensorFlow、MindSpore 等DNN模型开发框架位于顶端,输出“Graph”,表示算法中的粗粒度关系。然后,在图引擎的帮助下,“Graph”被转换为“Stream”,由几个按顺序排列的“Task”组成。“Streams”/“Tasks”可以直接从Operator Lib调用,也可以由程序员借助Operator Engine 用不同级别的语言描述。TBE(Tensor Boost Engine )DSL(Domain Specific Language)是用Level-3编程模型开发的,称为数学编程级别,针对不了解硬件知识的用户。借助编译器,可以从 TBE DSL 描述中自动生成实例“Tasks”。程序员还可以在并行/内核级别(2 级)编程模型中开发实例“Task”,类似于 GPU 的 CUDA 或 OpenCL,并引入了张量迭代器核 TIK(Tensor Iterator Kernel)接口,可以使用 Python 进行并行编程。专用的编译器技术“Auto Tiling ”,用于将大任务切割以适应 Ascend 架构。在强化学习算法的帮助下,该技术通过智能搜索合法的映射空间,为程序提供最佳的tiling和调度。编程模型的最低级别(级别 1)是 C 编程,也称为 CCE-C(Cube-based Compute Engine)。在此级别中,每个体系结构的所有设计细节都暴露给程序员。程序员可以嵌入类似汇编的代码。整体结构如下所示:
Ampere
2020年,NVIDIA推出Ampere架构,采用TSMC 7nm FFN工艺,面积826mm^2,一共542亿晶体管;完整GA100物理版图如下所示:
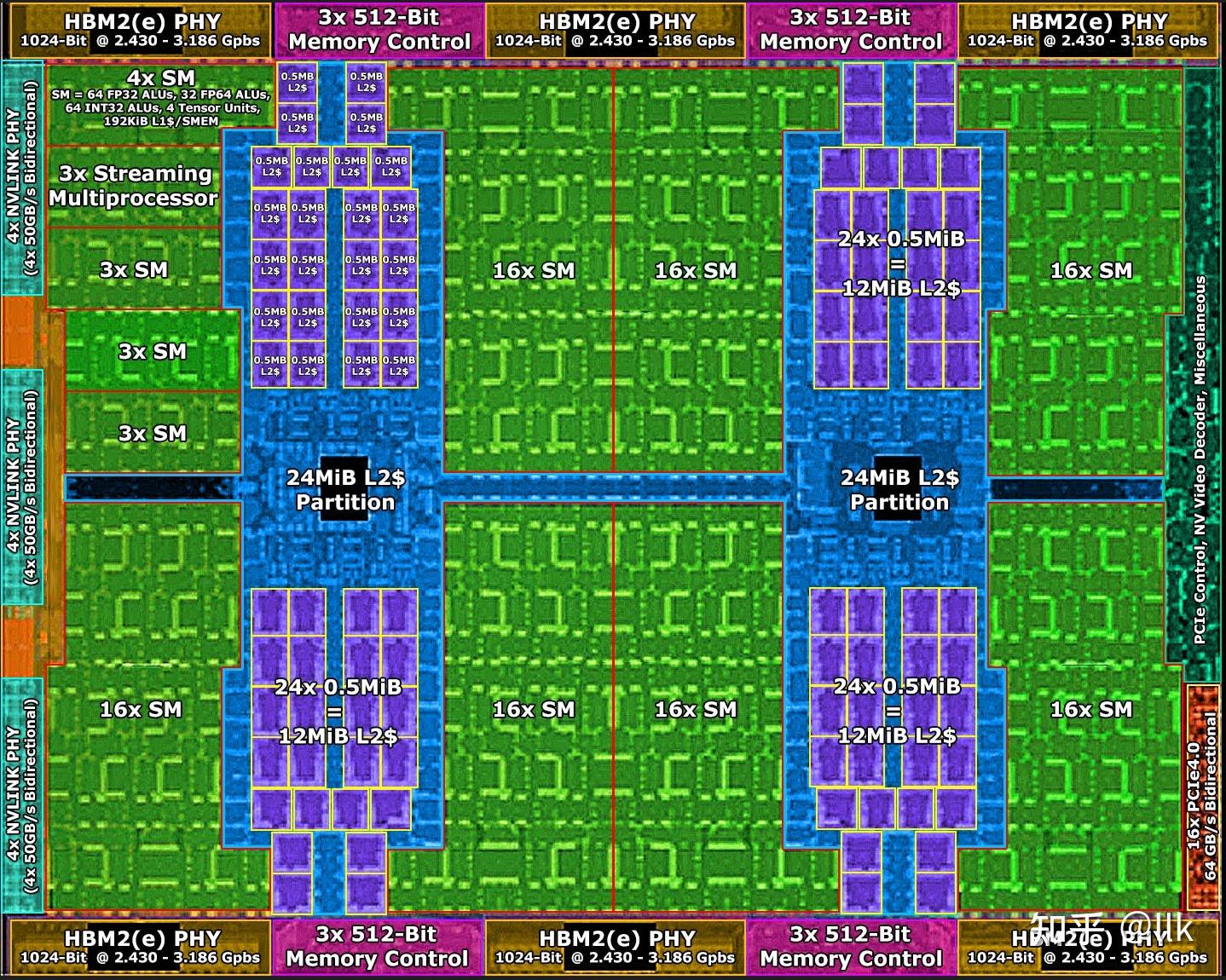
Ampere GPU 中两个 SM 共同组成一个纹理处理器集群TPC,其中 8 个 TPC组成了一个GPU 处理集群(GPC);一共 8 个GPC。因此,GA100 GPU 的完整实现包括以下单元:
- 8 个 GPC,每个GPC有8 个 TPC,每个TPC有2 个 SM,一共128 个 SM
- 每个SM有64 个 FP32 CUDA 核,每个完整 GPU 8192 个 FP32 CUDA 核
- 每个SM有4 个第三代 Tensor Core,每个完整 GPU 512 个 Tensor Core
- 6 个 HBM2 ,12 个 512 位内存控制器
A100 基于 GA100,有 108 个 SM;A100 Tensor Core GPU 实现包括以下单元:
- 7 个 GPC,每个GPC有7 或 8 个 TPC,每个TPC有2 个 SM,最多108 个 SM
- 每个 GPU有 64 个 FP32 CUDA 核,一共6912 个 FP32 CUDA 核
- 每个SM有4 个第三代 Tensor Core,每个 GPU 432 个Tensor Core
- 5 个 HBM2,10 个 512 位内存控制器
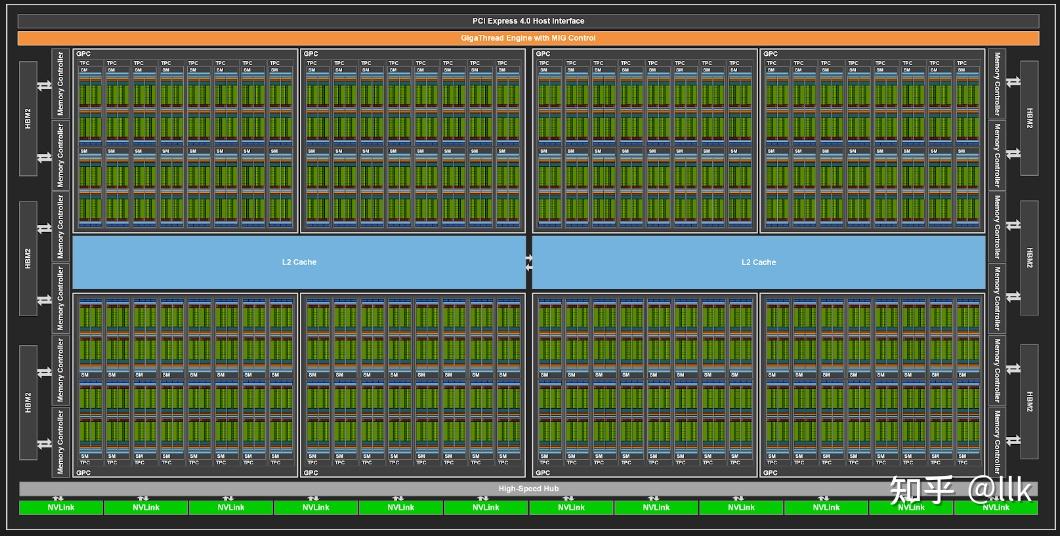
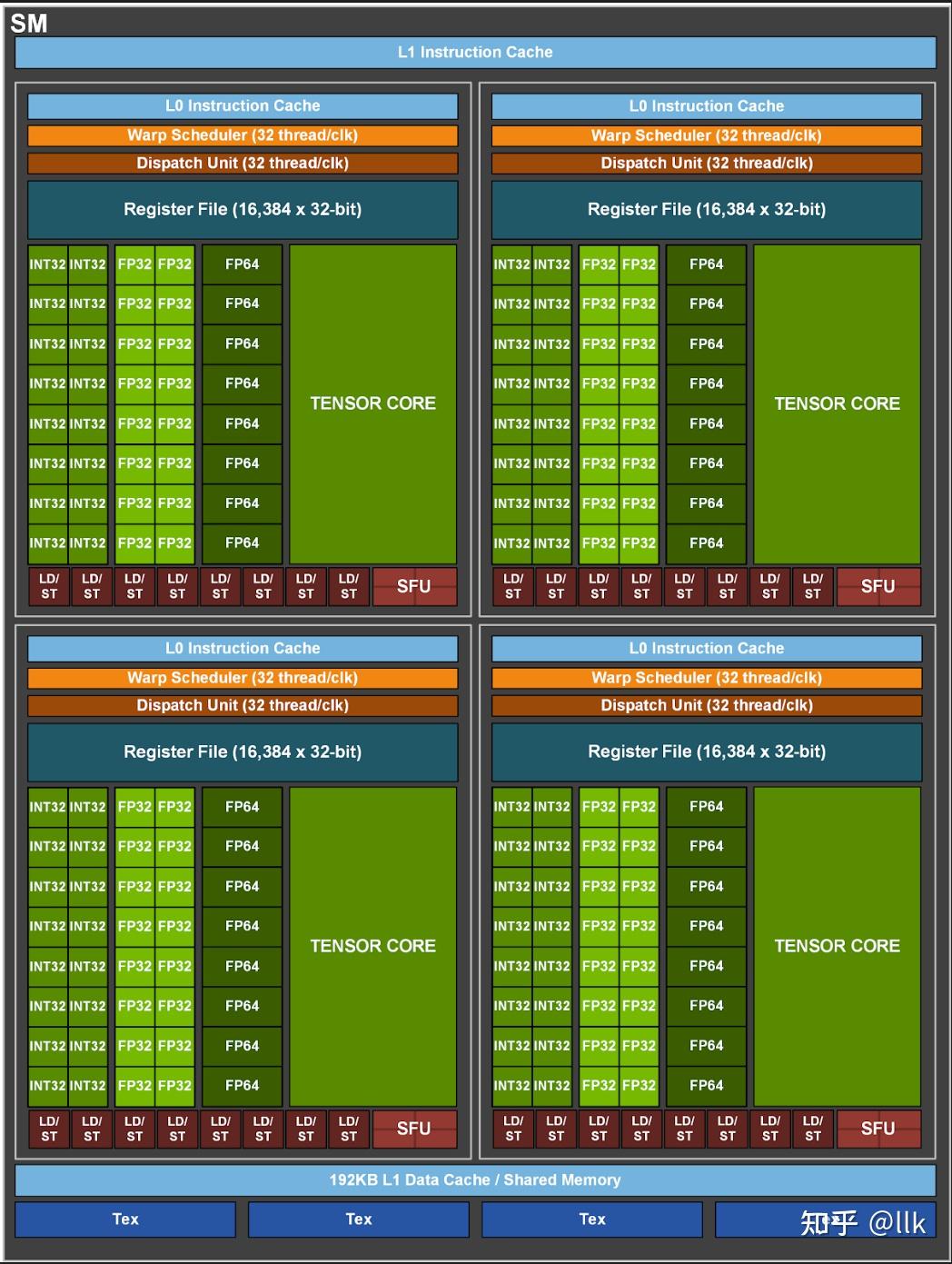
A100 SM 包括新的第三代 Tensor Core,每个核每个时钟执行 256 个 FP16/FP32 FMA 操作。A100 每个 SM 有四个 Tensor Core,每个时钟总共提供 1024 次密集的 FP16/FP32 FMA 操作。
DGX
下图展示了DGX A100 系统网络拓扑:
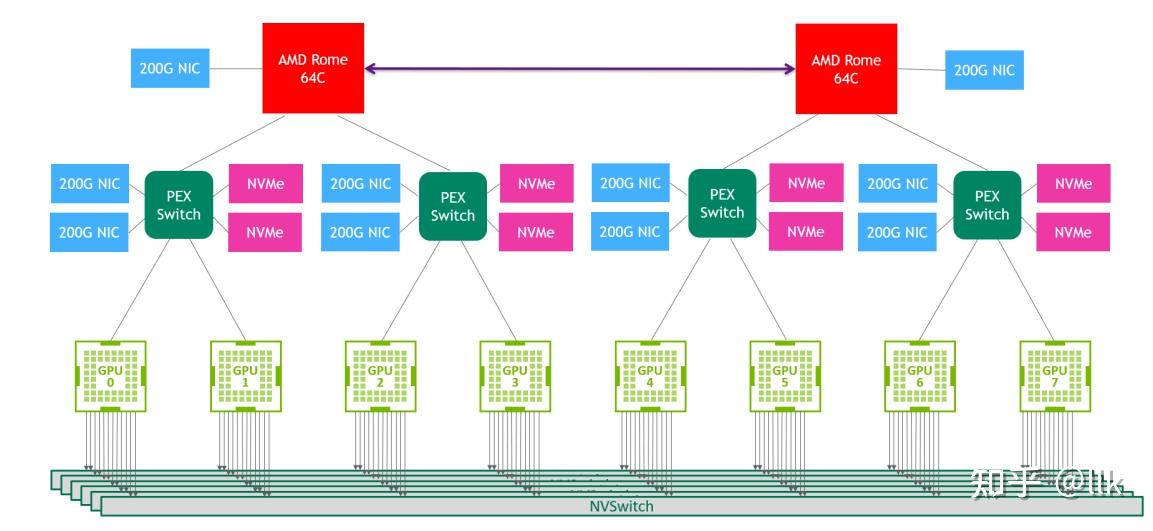
DGX A100 系统包含6个NVSwitch 2.0,每个 A100 GPU 使用 12 个 NVLink 与 6 个 NVSwitch 进行互联通信,因此每个 GPU 到每个交换机都有两条链路。
NVIDIA DGX SuperPOD
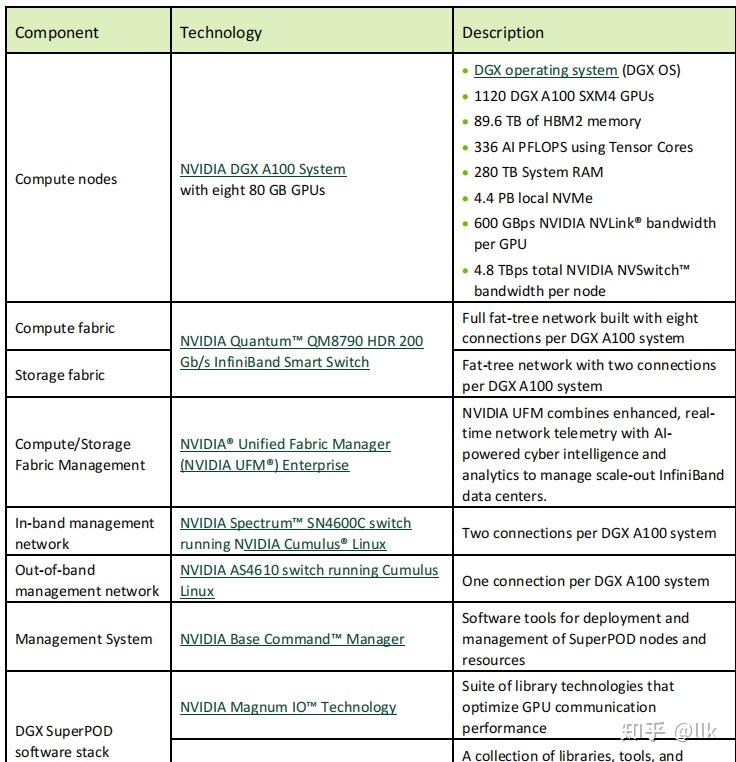
NVIDIA DGX SuperPOD是由DGX A100 组成的集群系统,包括:
- 140 个 DGX A100 系统
- 1,120 个 NVIDIA A100 GPU
- 170 个 Mellanox Quantum 200G InfiniBand 交换机
- 15Km光缆
- 4PB 高性能存储
具体硬件参数如下:
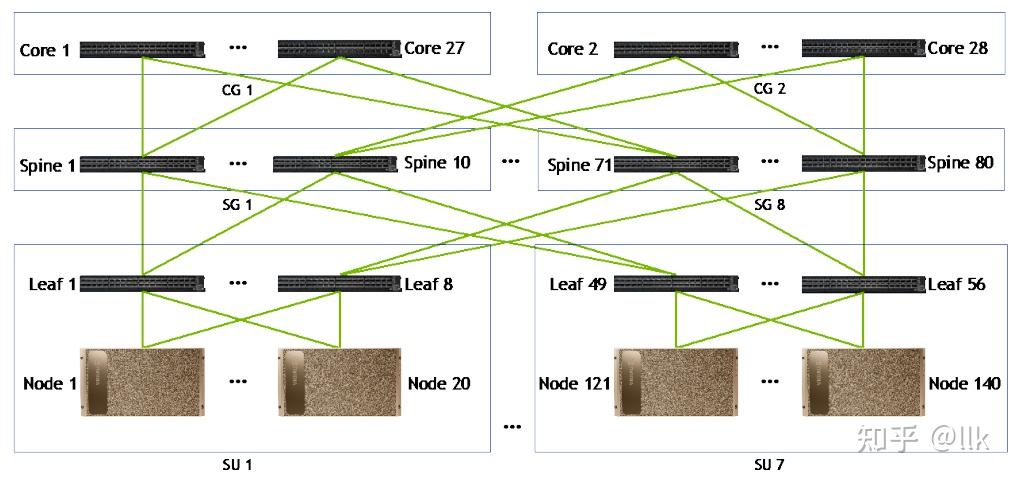
下图展示了140 节点 DGX SuperPOD 的计算拓扑结构:
参考文献
- H. Liao, J. Tu, J. Xia and X. Zhou, “DaVinci: A Scalable Architecture for Neural Network Computing,” 2019 IEEE Hot Chips 31 Symposium (HCS), Cupertino, CA, USA, 2019, pp. 1-44, doi: 10.1109/HOTCHIPS.2019.8875654.
- Liao, H., Tu, J., Xia, J., Liu, H., Zhou, X., Yuan, H., Hu, Y., 2021. Ascend: a Scalable and Unified Architecture for Ubiquitous Deep Neural Network Computing : Industry Track Paper, in: 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). Presented at the 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), IEEE, Seoul, Korea (South), pp. 789–801. https://doi.org/10.1109/HPCA51647.2021.00071
- NVIDIA Ampere Architecture In-Depth [WWW Document], 2020. . NVIDIA Technical Blog. URL [NVIDIA Ampere Architecture In-Depth | NVIDIA Technical Blog](NVIDIA Ampere Architecture In-Depth | NVIDIA Technical Blog) .
- Choquette J. et al., “NVIDIA A100 tensor core GPU: Performance and innovation,” IEEE Micro, vol. 41, no. 2, pp. 29–35, Mar./Apr. 2021, doi: 10.1109/MM.2021.3061394.
相关文章:
NPU 可不可以代替 GPU
结论 先说结论,GPU分为可以做图形处理的传统意义上的真GPU,做HPC计算的GPGPU和做AI加速计算的GPGPU,所以下面分别说: 对于做图形处理的GPU,这个就和NPU 一样,属于DSA,没有替代性。当然…...

Vue3版本的uniapp项目运行至鸿蒙系统
新建Vue3版本的uniapp项目 注意,先将HbuilderX升级至最新版本,这样才支持鸿蒙系统的调试与运行; 按照如下图片点击,快速升级皆可。 通过HbuilderX创建 官方文档指导链接 点击HbuilderX中左上角文件->新建->项目 创建vue3…...

部署stable-diffusion3.5 大模型,文生图
UI 使用推荐的ComfyUI,GitHub 地址,huggingface 需要注册登录,需要下载的文件下面有说明 Dockerfile 文件如下: FROM nvidia/cuda:12.4.0-base-ubuntu22.04 RUN apt-get update && apt-get install python3 pip git --n…...

数据采集之selenium模拟登录
使用Cookijar完成模拟登录 本博文爬取实例为内部网站,请sduter使用本人账号替换*********(学号),***(姓名)进行登录 from selenium import webdriver from selenium.webdriver.common.by import By from…...

机器学习中的两种主要思路:数据驱动与模型驱动
在机器学习的研究和应用中,如何从数据中提取有价值的信息并做出准确预测,是推动该领域发展的核心问题之一。在这个过程中,机器学习方法主要依赖于两种主要的思路:数据驱动与模型驱动。这两种思路在不同的应用场景中发挥着至关重要…...
)
【计算机网络】TCP协议面试常考(一)
三次握手和四次挥手是TCP协议中非常重要的机制,它们在多种情况下确保了网络通信的可靠性和安全性。以下是这些机制发挥作用的一些关键场景: 三次握手的必要性: 同步序列号: 三次握手确保了双方的初始序列号(ISN&#…...

C#/.NET/.NET Core学习路线集合,学习不迷路!
前言 C#、.NET、.NET Core、WPF、WinForm、Unity等相关技术的学习、工作路线集合(持续更新)!!! 全面的C#/.NET/.NET Core学习、工作、面试指南:https://github.com/YSGStudyHards/DotNetGuide C#/.NET/.N…...

使用哈希表做计数排序js
function hashSort(arr) {// 创建一个哈希表(对象),统计每个数字出现的次数let hashMap {};arr.forEach(num > {if (hashMap[num]) {hashMap[num] 1;} else {hashMap[num] 1;}});// 根据哈希表的键值对构建排序后的数组let sortedArr …...

京津冀自动驾驶技术行业盛会|2025北京自动驾驶技术展会
“自动驾驶技术”已经成为全球汽车产业的焦点之一。在这个充满创新与变革的时代,“2025北京国际自动驾驶技术展览会”拟定于6月份在北京亦创国际会展中心盛大开幕,为全球自动驾驶技术领域的专业人士、企业以及爱好者们提供了一个交流与展示的平台。作为一…...

Chrome与火狐哪个浏览器的隐私追踪功能更好
当今数字化时代,互联网用户越来越关注在线隐私保护。浏览器作为我们探索网络世界的重要工具,其隐私追踪功能的强弱直接影响到个人信息的安全。本文将对比Chrome和Firefox这两款流行的浏览器,在隐私追踪防护方面的表现,并探讨相关优…...

探索 Python 图像处理的瑞士军刀:Pillow 库
文章目录 探索 Python 图像处理的瑞士军刀:Pillow 库第一部分:背景介绍第二部分:Pillow库是什么?第三部分:如何安装这个库?第四部分:简单的库函数使用方法第五部分:结合场景使用库第…...

JavaScript中的if、else if、else 和 switch
写在前面 在编程中,条件判断是控制程序流程的重要手段。JavaScript 提供了多种方式来进行条件判断,包括 if、else if、else 和 switch。本文将详细介绍这些语句的语法、用法以及一些相关的注意事项。 if、else if 和 else 语法 if、else if 和 else …...

Python 使用 langchain 过程中的错误总结
1. 环境 conda activate langchain pip install -U langchain$ pip show langchain Name: langchain Version: 0.3.7 Summary: Building applications with LLMs through composability Home-page: https://github.com/langchain-ai/langchain Author: Author-email: Licens…...

MySQL基础篇总结
基本SQL语句分类 DDL(数据定义语言) 数据定义语言,用来定义数据库对象(数据库、表、字段)。 数据控制语言,用来创建数据库用户、控制数据库的控制权限。 数据库操作 查询所有数据库: SHOW DATABASES; 查询当前数据库…...

全面解析:网络协议及其应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 # 全面解析:网络协议及其应用 文章目录 网络协议概述定义发展历程主要优势 主要网络协议应用层协议传输层协议网络层…...

一文了解Java序列化
Java 序列化(Serialization)是将对象的状态转换为字节流,以便将对象的状态保存到文件中或通过网络传输的过程。反序列化(Deserialization)则是将字节流恢复为原始对象。Java 序列化主要通过 Serializable 接口实现。 为…...

【前端基础】CSS基础
目标:掌握 CSS 属性基本写法,能够使用文字相关属性美化文章页。 01-CSS初体验 层叠样式表 (Cascading Style Sheets,缩写为 CSS),是一种 样式表 语言,用来描述 HTML 文档的呈现(美化内容&#…...

Linux之selinux和防火墙
selinux(强化的linux) 传统的文件权限与账号的关系:自主访问控制,DAC; 以策略规则制定特定程序读取特定文件:强制访问控制,MAC SELinux是通过MAC的方式来控制管理进程,它控制的主…...

架构零散知识点
1 数据库 1.1 数据库范式 有一个学生表,主键是学号,含有学生号、学生名、班级、班级名,违反了数据库第几范式? --非主属性不依赖于主键,不满足第二范式 有一个订单表,包含以下字段:订单ID&…...

【从零开始的LeetCode-算法】3254. 长度为 K 的子数组的能量值 I
给你一个长度为 n 的整数数组 nums 和一个正整数 k 。一个数组的 能量值 定义为: 如果 所有 元素都是依次 连续 且 上升 的,那么能量值为 最大 的元素。否则为 -1 。 你需要求出 nums 中所有长度为 k 的子数组的能量值。 请你返回一个长度为 n - k 1…...

Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具
Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具 【免费下载链接】wayback-machine-webextension A web browser extension for Chrome, Firefox, Edge, and Safari 14. 项目地址: https://gitcode.com/gh_mirrors/wa/wayback-machine-webextension…...

Whisky革新指南:在macOS上优雅运行Windows程序的全新体验
Whisky革新指南:在macOS上优雅运行Windows程序的全新体验 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 你是否曾经在macOS上渴望运行某个Windows专用软件,却…...

别再只把 AI 当聊天框了!探索 Google DeepMind 的 `agy` 命令行工具与人机协同新姿势
别再只把 AI 当聊天框了!探索 Google DeepMind 的 agy 命令行工具与人机协同新姿势 在 AI 辅助编程(AI Coding)卷到飞起的今天,大部分开发者最习惯的可能还是在 IDE 侧边栏里装个插件,或者在网页端和 AI 缝缝补补地复制…...

业务接口安全加固:杜绝恶意刷量与非法调用风险
业务接口安全加固方法输入验证与过滤 对所有传入参数进行严格校验,包括数据类型、长度、格式(如正则匹配)。对特殊字符进行转义或过滤,防止SQL注入、XSS等攻击。使用白名单机制限制可接受的输入范围。访问频率限制 基于IP、用户ID…...

Android屏幕共享技术方案如何实现跨设备实时传输?AndroidScreenShare项目深度解析
Android屏幕共享技术方案如何实现跨设备实时传输?AndroidScreenShare项目深度解析 【免费下载链接】AndroidScreenShare Android 屏幕共享, 共享你的屏幕和音频到另一台手机 Share your screen and voice to other phone 项目地址: https://gitcode.com/gh_mirro…...

数据库与仓储
数据库与仓储 位置:Source/DataBases 项目作用H.DataBases.Share数据库共享代码。H.DataBases.SqliteSqlite 支持。H.DataBases.SqlServerSQL Server 支持。 Repository 相关: H.Extensions.DataBase.Repository H.Presenters.Repository H.Controls.…...

视频高清直播点播/音视频点播/云点播/云直播EasyDSS交互升级解锁大型活动直播新体验
在数字化时代,大型活动直播已从“可选”变为“必需”,无论是政企发布会、行业峰会,还是跨区域学术论坛,都需要一套兼顾稳定、安全与高效的直播解决方案。EasyDSS私有化视频会议系统凭借高并发、低延迟的核心优势站稳市场ÿ…...

Obsidian Local REST API:解锁个人知识库的自动化编程接口
Obsidian Local REST API:解锁个人知识库的自动化编程接口 【免费下载链接】obsidian-local-rest-api A secure REST API and Model Context Protocol (MCP) server for your vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-local-rest-api 你…...

论文被吐槽逻辑乱?,有哪些真正值得入手的的AI智能降重工具推荐?
毕业论文降AIGC率,优先选语义重构 学术优化 去AI痕迹的工具,免费与付费结合更高效。下面按中文、英文、免费/付费分类推荐,附实测效果与适用场景。 一、中文论文降重工具(最常用) 1. 千笔AI(综合全能首选…...

STM32F427 平替方案全面解析:从性能到成本的最优选择
文章摘要STM32F427 作为意法半导体 (ST) 旗下高性能 Cortex-M4 内核 MCU 的代表产品,凭借其 180MHz 主频、丰富的外设接口和出色的浮点运算能力,长期占据工业控制、医疗设备、智能仪表等中高端嵌入式市场的核心地位。然而近年来,全球芯片供应…...