数据结构与算法分析:专题内容——动态规划2之例题讲解(代码详解+万字长文+算法导论+力扣题)
一、最长公共子序列
在生物应用中,经常需要比较两个(或多个)不同生物体的 DNA。一个 DNA 串由一串称为碱基(base)的分子组成,碱基有腺嘌呤、鸟嘌呤、胞嘧啶和胸腺嘧啶 4 种类型。我们用英文单词首字母表示 4 种碱基,这样就可以将一个 DNA 串表示为有限集{A,C,G,T}上的一个字符串(参见附录 C 中对字符串的定义)。例如,某种生物的 DNA 可能为 S i = S_{\mathrm{i}}= Si=ACCGGTOGAGTGCGGGAGCGGGGGGGGGGGGGGGGG 另一种生物的 DNA 可能为 S 2 = G T C G T T C G G A A T G C C G T T G C T C T G T A A A S_2=GTCGTTCGGAATGCCGTTGCTCTGTAAA S2=GTCGTTCGGAATGCCGTTGCTCTGTAAA。我们比较两个DNA串的一个原因是希望确定它们的“相似度”,作为度量两种生物相近程度的指标。我们可以用很多不同的方式来定义相似度,实际上也确实已经出现了很多相似度的定义。例如,如果一个DNA 串是另一个 DNA 串的子串,那么可以说它们是相似的(第 32 章讨论了如何求解此问题)。但在我们的例子中,S_1 和 S_2 都不是对方的子串。我们还可以这样来定义相似性:如果将一个串转换为另一个串所需的操作很少,那么可以说两个串是相似的(思考题 15-5 讨论了此概念)。另一种衡量串 S 1 S_1 S1和 S 2 S_2 S2的相似度的方式是:寻找第三个串 S 3 S_3 S3,它的所有碱基也都出现在 S 1 S_1 S1和 S 2 S_2 S2中,且在三个串中出现的顺序都相同,但在 S 1 S_1 S1和 S 2 S_2 S2中不要求连续出现。可以找到的 S 3 S_{3} S3越长,就可以认为 Si 和 S 2 S_{2} S2的相似度越高。在我们的例子中,最长的 S 3 S_{3} S3为 GTCGTCGGAAGCGGGCGAA。
我们将最后一种相似度的概念命名为最长公共子序列问题。一个给定序列的子序列,就是将给定序列中零个或多个元素去掉之后得到的结果。其形式化定义如下:给定一个序列 X = ⟨ x 1 , x 2 , ⋯ X=\langle x_1,x_2,\cdots X=⟨x1,x2,⋯, x m x_m xm〉,另一个序列 Z = ⟨ z 1 , z 2 , . . . , z k ⟩ Z=\langle z_1,z_2,...,z_k\rangle Z=⟨z1,z2,...,zk⟩满足如下条件时称为 X X X的子序列(subsequence),即存在一个严格递增的 X X X的下标序列 ⟨ i 1 , i 2 , . . . , i k ⟩ \langle i_1,i_2,...,i_k\rangle ⟨i1,i2,...,ik⟩,对所有 j = 1 , 2 , . . . , k j=1,2,...,k j=1,2,...,k,满足KaTeX parse error: Double subscript at position 4: x_i_̲j=z_j。例如, Z = ⟨ B Z=\langle B Z=⟨B, C , D , B ⟩ 是 X = ⟨ A , B , C , B , D , A , B ⟩ C,D,B\rangle 是X=\langle A,B,C,B,D,A,B\rangle C,D,B⟩是X=⟨A,B,C,B,D,A,B⟩的子序列,对应的下标序列为(2,3,5,7)。
给定两个序列 X X X和 Y Y Y,如果 Z Z Z既是 X X X的子序列,也是 Y Y Y的子序列,我们称它是 X X X和 Y 的公共子序列(common subsequence)。例如,如果 X = ⟨ A , B , C , B , D , A , B ⟩ , Y = ⟨ B , D , C X=\langle A,B,C,B,D,A,B\rangle,Y=\langle B,D,C X=⟨A,B,C,B,D,A,B⟩,Y=⟨B,D,C, A , B , A ⟩ , 那么序列 ⟨ B , C , A ⟩ A,B,A\rangle,那么序列\langle B,C,A\rangle A,B,A⟩,那么序列⟨B,C,A⟩就是 X X X 和 Y Y Y 的公共子序列。但它不是 X X X 和 Y Y Y 的最长公共子序列(LCS),因为它长度为 3,而〈 B , C , B , A B,C,B,A B,C,B,A〉也是 X X X 和 Y Y Y的公共子序列,其长度为 4。〈B,C, B , A ⟩ B,A\rangle B,A⟩是 X X X 和 Y Y Y的最长公共子序列, ⟨ B , D , A , B ⟩ \langle B,D,A,B\rangle ⟨B,D,A,B⟩也是,因为 X X X 和 Y Y Y不存在长度大于等于 5的公共子序列。
最长公共子序列问题(longest-common-subsequence problem)给定两个序列 X = ⟨ x 1 , x 2 , ⋯ X=\langle x_1,x_2,\cdots X=⟨x1,x2,⋯, x m x_m xm>和 Y = ⟨ y 1 , y 2 , ⋯ , y n ⟩ Y=\langle y_1,y_2,\cdots,y_n\rangle Y=⟨y1,y2,⋯,yn⟩,求 X X X和 Y Y Y长度最长的公共子序列。本节将展示如何用动态规划方法高效地求解 LCS 问题。
步骤 1: 刻画最长公共子序列的特征
如果用暴力搜索方法求解 LCS问题,就要穷举 X 的所有子序列,对每个子序列检查它是否也是 Y Y Y的子序列,记录找到的最长子序列。 X X X的每个子序列对应 X X X的下标集合 ⟨ 1 , 2 , ⋯ , m ⟩ \langle1,2,\cdots,m\rangle ⟨1,2,⋯,m⟩的一个子集,所以 X X X 有 2” 个子序列,因此暴力方法的运行时间为指数阶,对较长的序列是不实用的。
但是,如下面的定理所示,LCS 问题具有最优子结构性质。我们将看到,子问题的自然分类对应两个输人序列的“前缀”对。前缀的严谨定义如下:给定一个序列 X = ⟨ x 1 , x 2 , … , x m ⟩ X=\langle x_1,x_2,\ldots,x_m\rangle X=⟨x1,x2,…,xm⟩, 对 i = 0 , 1 , . . . , m i=0,1,...,m i=0,1,...,m,定义 X X X的第 i i i前缀为 X i = ⟨ x 1 , x 2 , . . . , x i ⟩ X_i=\langle x_1,x_2,...,x_i\rangle Xi=⟨x1,x2,...,xi⟩。例如,若 X = ⟨ A , B , C , B X=\langle A,B,C,B X=⟨A,B,C,B, D D D, A A A, B ⟩ B\rangle B⟩, 则 X 4 = ⟨ A X_{4}= \langle A X4=⟨A, B B B, C C C, B ⟩ B\rangle B⟩, X 0 X_{0} X0 为空串。
定理 15.1(LCS 的最优子结构)令 X = ⟨ x 1 , x 2 , ⋯ , x m ⟩ X=\langle x_1,x_2,\cdots,x_m\rangle X=⟨x1,x2,⋯,xm⟩和 Y = ⟨ y 1 , y 2 , ⋯ , y n ⟩ Y=\langle y_1,y_2,\cdots,y_n\rangle Y=⟨y1,y2,⋯,yn⟩为两个序
列, Z = ⟨ z 1 Z= \langle z_1 Z=⟨z1, z 2 z_2 z2, ⋯ \cdots ⋯, z k ⟩ z_k\rangle zk⟩为 X X X和Y的任意 LCS。
1.如果 x m = y n x_m=y_n xm=yn, 则 z k = x m = y n z_k=x_m=y_n zk=xm=yn 且 Z k − 1 Z_k-1 Zk−1是 X m − 1 X_m-1 Xm−1和 Y n − 1 Y_n-1 Yn−1的一个LCS。
2.如果 x m ≠ y n x_m\neq y_n xm=yn, 那么 z k ≠ x m z_k\neq x_m zk=xm 意味着 Z Z Z 是 X m − 1 X_m-1 Xm−1和 Y Y Y的一个LCS。
3.如果 x m ≠ y n x_m\neq y_n xm=yn, 那么 z k ≠ y n z_k\neq y_n zk=yn 意味着 Z Z Z 是 X X X 和 Y n − 1 Y_n-1 Yn−1的一个 LCS。
证明 :
(1)如果 z k ≠ x m z_k\neq x_m zk=xm,那么可以将 x m = y n x_m=y_n xm=yn追加到 Z Z Z的末尾,得到 X X X和 Y Y Y的一个长度为 k + 1 k+1 k+1的公共子序列,与 Z Z Z是 X X X 和 Y Y Y 的最长公共子序列的假设矛盾。因此,必然有 z k = x m = y n z_k=x_m=y_n zk=xm=yn。这样,前缀 Z k − 1 Z_{k-1} Zk−1是 X m − 1 X_{m-1} Xm−1 和 Y n − 1 Y_{n-1} Yn−1的一个长度为 k − 1 k-1 k−1 的公共子序列。我们希望证明它是一个 LCS。利用反证法,假设存在 X m − 1 X_{m-1} Xm−1和 Y n − 1 Y_{n-1} Yn−1的一个长度大于 k − 1 k-1 k−1 的公共子序列 W W W,则将 x m = y n x_m=y_n xm=yn 追加到 W W W的末尾会得到 X X X和 Y Y Y的一个长度大于 k k k的公共子序列,矛盾。
(2)如果 z k ≠ x m z_k\neq x_m zk=xm,那么 Z Z Z 是 X m − 1 X_m-1 Xm−1和 Y Y Y 的一个公共子序列。如果存在 X m − 1 X_m-1 Xm−1和 Y Y Y 的一个长度大于 k k k 的公共子序列 W W W,那么 W W W也是 X m X_m Xm 和 Y Y Y的公共子序列,与 Z Z Z 是 X X X 和 Y Y Y的最长公共子序列的假设矛盾。
(3)与情况(2)对称。
定理 15.1 告诉我们,两个序列的 LCS 包含两个序列的前缀的 LCS。因此,LCS 问题具有最
优子结构性质。我们马上还会看到,其递归算法也具有重叠子问题性质。
步骤2:一个递归解
定理 15. 1 意味着,在求 X = ⟨ x 1 , x 2 , ⋅ ⋅ ⋅ , x m ⟩ X=\langle x_1,x_2,\cdotp\cdotp\cdotp,x_m\rangle X=⟨x1,x2,⋅⋅⋅,xm⟩和 Y = ⟨ y 1 , y 2 , ⋅ ⋅ ⋅ , y n ⟩ Y=\langle y_1,y_2,\cdotp\cdotp\cdotp,y_n\rangle Y=⟨y1,y2,⋅⋅⋅,yn⟩的一个 LCS 时,我们需要求解一个或两个子问题。如果 x m = y n x_m=y_n xm=yn,我们应该求解 X m − 1 X_{m-1} Xm−1和 Y n − 1 Y_{n-1} Yn−1的一个 LCS。将 x m = y π x_m=y_\pi xm=yπ 追加到这个 LCS 的末尾,就得到 X X X 和 Y Y Y的一个 LCS。如果 x m ≠ y n x_m\neq y_n xm=yn,我们必须求解两个子问题: 求 X m − 1 X_{m-1} Xm−1和Y的一个LCS与 X X X 和 Y n − 1 Y_{n-1} Yn−1的一个LCS。两个 LCS 较长者即为 X X X 和 Y Y Y 的一个 LCS。由于这些情况覆盖了所有可能性,因此我们知道必然有一个子问题的最优解出现在 X X X和 Y 的 L C S 中 LCS中 LCS中。
我们可以很容易看出 LCS 问题的重叠子问题性质。为了求 X X X和 Y Y Y的一个 LCS,我们可能需要求 X X X 和 Y n − 1 Y_{n-1} Yn−1的一个 LCS 及 X m − 1 X_{m-1} Xm−1和 Y Y Y的一个 ICS。但是这几个子问题都包含求解 X m − 1 X_{m-1} Xm−1和 Y n − 1 Y_{n-1} Yn−1 的 LCS 的子子问题。很多其他子问题也都共享子子问题。
与矩阵链乘法问题相似,设计 LCS 问题的递归算法首先要建立最优解的递归式。我们定义 c [ i , j ] c[i,j] c[i,j]表示 X i X_i Xi和 Y j Y_j Yj的 LCS 的长度。如果 i = 0 i=0 i=0或 j = 0 j=0 j=0,即一个序列长度为 0,那么 ICS 的长度为0。根据 LCS问题的最优子结构性质,可得如下公式:
若 i = 0 i=0 i=0或 j = 0 j=0 j=0
c [ i , j ] = { 0 若 i = 0 或 j = 0 c [ i − 1 , j − 1 ] + 1 若 i , j > 0 且 x i = y j max ( c [ i , j − 1 ] , c [ i − 1 , j ] ) 若 i , j > 0 且 x i ≠ y j c[i,j]=\begin{cases}0&\text{若 }i=0\text{ 或 }j=0\\c[i-1,j-1]+1&\text{若 }i,j>0\text{ 且 }x_{i}=y_{j}\\\max(c[i,j-1],c[i-1,j])&\text{若 }i,j>0\text{ 且 }x_{i}\neq y_{j}\end{cases} c[i,j]=⎩ ⎨ ⎧0c[i−1,j−1]+1max(c[i,j−1],c[i−1,j])若 i=0 或 j=0若 i,j>0 且 xi=yj若 i,j>0 且 xi=yj
(15.9)
观察到在递归公式中,我们通过限制条件限定了需要求解哪些子问题。当 x i = y j x_i=y_j xi=yj时,我们可以而且应该求解子问题: X i − 1 X_{i-1} Xi−1和 Y j − 1 Y_{j-1} Yj−1的一个 LCS。否则,应该求解两个子问题: X i X_i Xi 和 Y j − 1 Y_{j-1} Yj−1的一个 LCS 及 X i − 1 X_{i-1} Xi−1和 Y j Y_j Yj 的一个 LCS。在之前讨论过的钢条切割问题和矩阵链乘法问题的动态规划算法中,根据问题的条件,我们没有排除任何子问题。不过,LCS 问题并非唯一根据条件排除子问题的动态规划算法。例如,编辑距离问题(见思考题 15-5)也具有这种特点。
步骤 3: 计算 LCS 的长度
根据公式(15.9),我们可以很容易地写出一个指数时间的递归算法来计算两个序列的 LCS 的长度。但是,由于 LCS 问题只有 Θ ( m n ) \Theta(mn) Θ(mn)个不同的子问题,我们可以用动态规划方法自底向上地计算。
过程 LCS LENGTH 接受两个序列 X = ⟨ x 1 , x 2 , ⋯ , x m ⟩ X=\langle x_1,x_2,\cdots,x_m\rangle X=⟨x1,x2,⋯,xm⟩和 Y = ⟨ y 1 , y 2 , ⋯ , y n ⟩ Y=\langle y_1,y_2,\cdots,y_n\rangle Y=⟨y1,y2,⋯,yn⟩为输入。它将 c [ i , j ] c[i,j] c[i,j]的值保存在表 c [ 0 … m , 0.. n ] c[0\ldots m,0..n] c[0…m,0..n]中,并按行主次序(row-major order)计算表项(即首先由左至右计算 c 的第一行,然后计算第二行,依此类推)。过程还维护一个表 b [ 1.. m , 1.. n ] b[1..m,1..n] b[1..m,1..n], 帮助构造最优解。 b [ i , j ] b[i,j] b[i,j]指向的表项对应计算 c [ i , j ] [i,j] [i,j]时所选择的子问题最优解。过程返回表 b b b

图15-8显示了LCS-LENGTH对输入序列X=<A,B,C,D,A,B>和Y=<B,.D,C,A,B,A>生成的结果。过程的运行时间为 Θ ( m n ) \Theta(mn) Θ(mn),因为每个表项的计算时间为 Θ ( 1 ) \Theta(1) Θ(1)。

步骤4:构造LCS

算法改进
一旦设计出一个算法,通常情况下你都会发现它在时空开销上有改进的余地。一些改进可以简化代码,将性能提高常数倍,但除此之外不会产生性能方面的渐近性提升。而另一些改进可以带来时空上巨大的渐近性提升。
例如,对 ICS算法,我们完全可以去掉表 b b b。每个 c[ i , j ] i,j] i,j]项只依赖于表 c c c中的其他三项: c [ i − 1 , j ] c[i-1,j] c[i−1,j]、 c [ i , j − 1 ] c[i,j-1] c[i,j−1]和 c [ i − 1 , j − 1 ] c[i-1,j-1] c[i−1,j−1]。给定 c [ i , j ] c[i,j] c[i,j]的值,我们可以在 O(1)时间内判断出在计算 c [ i , j ] c[i,j] c[i,j]时使用了这三项中的哪一项。因此,我们可以用一个类似 PRINT-LCS 的过程在 O ( m + n ) O(m+n) O(m+n)时间内完成重构 LCS 的工作,而且不必使用表 b b b。但是,虽然这种方法节省了 Θ ( m n ) \Theta(mn) Θ(mn)的空间,但计算 LCS 所需的辅助空间并未渐近减少,因为无论如何表 c c c都需要 Θ ( m n ) \Theta(mn) Θ(mn)的空间。
不过,LCS-LENGTH 的空间需求是可以渐近减少的,因为在任何时刻它只需要表 c c c中的两行:当前正在计算的一行和前一行。如果我们只需计算 LCS 的长度,这一改进是有效的。但如果需要重构 LCS 中的元素,这么小的表空间所保存的信息不足以在 O ( m + n ) O(m+n) O(m+n)时间内完成重构工作。
二、最优二叉搜索树
假定我们正在设计一个程序,实现英语文本到法语的翻译。对英语文本中出现的每个单词, 我们需要查找对应的法语单词。为了实现这些查找操作,我们可以创建一棵二叉搜索树,将 n n n个英语单词作为关键字,对应的法语单词作为关联数据。由于对文本中的每个单词都要进行搜索, 我们希望花费在搜索上的总时间尽量少。通过使用红黑树或其他平衡搜索树结构,我们可以假定每次搜索时间为 O ( lg n ) O(\lg n) O(lgn)。但是,单词出现的频率是不同的,像“the”这种频繁使用的单词有可能位于搜索树中远离根的位置上,而像“machicolation”这种很少使用的单词可能位于靠近根的置上。这样的结构会减慢翻译的速度,因为在二叉树搜索树中搜索一个关键字需要访问的结点数等于包含关键字的结点的深度加 1。我们希望文本中频繁出现的单词被置于靠近根的位置 ⊖ ^{\ominus} ⊖。而且,文本中的一些单词可能没有对应的法语单词 5 ◯ ^{\textcircled{5}} 5◯,这些单词根本不应该出现在二叉搜索树中。在给定单词出现频率的前提下,我们应该如何组织一棵二叉搜索树,使得所有搜索操作访问的结点总数最少呢?
这个问题称为最优二叉搜索树(optimal binary search tree)问题。其形式化定义如下:给定一个 n n n个不同关键字的已排序的序列 K = ⟨ k 1 , k 2 , . . . , k n ⟩ ( K=\langle k_1,k_2,...,k_n\rangle( K=⟨k1,k2,...,kn⟩(因此 k 1 < k 2 < . . . < k n ) k_1<k_2<...<k_n) k1<k2<...<kn),我们希望用这些关键字构造一棵二叉搜索树。对每个关键字 k i k_i ki,都有一个概率 p i p_i pi表示其搜索频率。有些要搜索的值可能不在 K K K中,因此我们还有 n + 1 n+ 1 n+1 个 “ 伪 关 键 字 ” d 0 , d 1 , d 2 , . . . , d n d_0, d_1, d_2, . . . , d_n d0,d1,d2,...,dn表示不在 K K K中的值。 d 0 d_0 d0表示所有小于 k 1 k_1 k1的值, d n d_n dn表示所有大于 k n k_n kn的值,对 i = 1 , 2 , . . . , n − 1 i=1,2,...,n-1 i=1,2,...,n−1,伪关键字 d i d_i di表示所有在 k i k_\mathrm{i} ki 和 k i + 1 k_{i+1} ki+1之间的值。对每个伪关键字 d i d_i di,也都有一个概率 p i p_i pi 表示对应的搜索频率。图 15-9显示了对一个 n = 5 n=5 n=5个关键字的集合构造的两棵二叉搜索树。每个关键字 k i k_i ki是一个内部结点,而每个伪关键字 d i d_i di是一个叶结点。每次搜索要么成功(找到某个关键字 k i ) k_i) ki)要么失败(找到某个伪关键字 d i d_i di),因此有如下公式 : ∑ i = 1 n p i + ∑ i = 0 n q i = 1 :\\\sum_{i=1}^np_i+\sum_{i=0}^nq_i=1 :i=1∑npi+i=0∑nqi=1
(15.10)

由于我们知道每个关键字和伪关键字的搜索概率,因而可以确定在一棵给定的二叉搜索树T中进行一次搜索的期望代价。假定一次搜索的代价等于访问的结点数,即此次搜索找到的结点在T中的深度再加1。那么在T中进行一次搜索的期望代价为:
E[T中搜索代价] = ∑ i = 1 n ( d e p t h T ( k i ) + 1 ) ∙ p i + ∑ i = 0 n ( d e p t h T ( d i ) + 1 ) ∙ q i = 1 + ∑ i = 1 n d e p t h T ( k i ) ∙ p i + ∑ i = 0 n d e p t h T ( d i ) ∙ q i \begin{aligned} \text{E[T中搜索代价]}& =\sum_{i=1}^{n}(\mathrm{depth}_{T}(k_{i})+1)\bullet p_{i}+\sum_{i=0}^{n}(\mathrm{depth}_{T}(d_{i})+1)\bullet q_{i} \\ &=1+\sum_{i=1}^{n}\mathrm{depth}_{T}(k_{i})\bullet p_{i}+\sum_{i=0}^{n}\mathrm{depth}_{T}(d_{i})\bullet q_{i} \end{aligned} E[T中搜索代价]=i=1∑n(depthT(ki)+1)∙pi+i=0∑n(depthT(di)+1)∙qi=1+i=1∑ndepthT(ki)∙pi+i=0∑ndepthT(di)∙qi
其中 d e p t h r depth_r depthr表示一个结点在树T中的深度。最后一个等式是由公式(15.10)推导而来。在图15-9(a)中,我们逐个结点期望搜索代价:

对于一个给定的概率集合,我们希望构造一棵期望搜索代价最小的二叉搜索树,我们称之为最优二叉搜索树。图15-9(b)所示的二叉搜索树就是给定概率集合的最优二叉搜索树,其期望代价为2.75。这个例子显示,最优二叉搜索树不一定是高度最矮的。而且,概率最高的关键字也不一定出现在二叉搜索树的根结点。在此例中,关键字 k 5 k_{5} k5的搜索概率最高但最优二叉搜索树的根结点为 k 2 k_{2} k2(在所有以 k 5 k_{5} k5为根的二叉搜索树中,期望搜索代价最小者为2.85)。
与矩阵链乘法问题相似,对本问题来说,穷举并检查所有可能的二叉搜索树不是一个高效的算法。对任意一棵 n n n个结点的二叉树,我们都可以通过对结点标记关键字 k 1 , k 2 , . . . , k n k_1,k_2,...,k_n k1,k2,...,kn构造出一棵二叉搜索树,然后向其中添加伪关键字作为叶结点。在思考题 12-4 中,我们会看到 n n n个结点的二叉树的数量为 Ω ( 4 n / n 3 / 2 ) \Omega(4^n/n^{3/2}) Ω(4n/n3/2),因此穷举法需要检查指数棵二叉搜索树。不出意外,我们将使用动态规划方法求解此问题。
步骤 1:最优二叉搜索树的结构
为了刻画最优二叉搜索树的结构,我们从观察子树特征开始。考虑一棵二叉搜索树的任意子树。它必须包含连续关键字 k i , … , k j , 1 ⩽ i ⩽ j ⩽ n k_i,\ldots,k_j,1\leqslant i\leqslant j\leqslant n ki,…,kj,1⩽i⩽j⩽n,而且其叶结点必然是伪关键字 d i − 1 , … , d j d_i-1,\ldots,d_j di−1,…,dj。
我们现在可以给出二叉搜索树问题的最优子结构:如果一棵最优二叉搜索树 T T T有一棵包含关键字 k i , ⋯ , k j k_i,\cdots,k_j ki,⋯,kj 的子树 T ′ T^\prime T′, 那 么 T ′ T^{\prime } T′必然是包含关键字 k i , ⋯ , k j k_i,\cdots,k_j ki,⋯,kj 和伪关键字 d i − 1 , ⋯ , d j d_i-1,\cdots,d_j di−1,⋯,dj 的子问题的最优解。我们依旧用剪切一粘贴法来证明这一结论。如果存在子树 T ′ ′ T^{\prime\prime} T′′,其期望搜索代价比 T ′ T^{\prime} T′低,那么我们将 T ′ T^{\prime} T′从 T T T 中删除,将 T ′ ′ T^{\prime\prime} T′′粘贴到相应位置,从而得到一棵期望搜索代价低于 T T T的二叉搜索树,与 T T T最优的假设矛盾。
我们需要利用最优子结构性质来证明,我们可以用子问题的最优解构造原问题的最优解。给定关键字序列 k i , ⋯ , k j k_i,\cdots,k_j ki,⋯,kj,其中某个关键字,比如说 k , ( i ⩽ r ⩽ j ) k,(i\leqslant r\leqslant j) k,(i⩽r⩽j),是这些关键字的最优子树的根结点。那么 k k k,的左子树就包含关键字 k i , . . . , k r − 1 ( k_i,...,k_{r-1}( ki,...,kr−1(和伪关键字 d i − 1 , . . . , d r − 1 ) d_i-1,...,d_{r-1}) di−1,...,dr−1),而右子树包含关键字 k r + 1 , ⋯ , k j ( k_{r+1},\cdots,k_{j}( kr+1,⋯,kj(和伪关键字 d r , ⋯ , d j ) d_r,\cdots,d_j) dr,⋯,dj)。只要我们检查所有可能的根结点 k r ( i ⩽ r ⩽ j ) k_r(i\leqslant r\leqslant j) kr(i⩽r⩽j), 并对每种情况分别求解包含 k i , . . . , k r − 1 k_i,...,k_{r-1} ki,...,kr−1及包含 k r + 1 , . . . , k j k_r+1,...,k_j kr+1,...,kj 的最优二叉搜索树,即可保证找到原问题的最优解。
这里还有一个值得注意的细节——“空子树”。假定对于包含关键字 k i , . . . , k j k_i,...,k_j ki,...,kj 的子问题,我们选定 k i k_i ki为根结点。根据前文论证, k i k_i ki的左子树包含关键字 k i , . . . , k i − 1 k_i,...,k_{i-1} ki,...,ki−1。我们将此序列解释为不包含任何关键字。但请注意,子树仍然包含伪关键字。按照惯例,我们认为包含关键字序列 k i , ⋯ , k i − 1 k_i,\cdots,k_{i-1} ki,⋯,ki−1的子树不含任何实际关键字,但包含单一伪关键字 d i − 1 d_{i-1} di−1。对称地,如果选择 k j k_j kj为根结点,那么 k j k_j kj 的右子树包含关键字 k j + 1 , ⋯ , k j k_{j+1},\cdots,k_j kj+1,⋯,kj——此右子树不包含任何实际关键字,但包含伪关键字 d j . d_j. dj.
步骤2:一个递归算法
我们已经准备好给出最优解值的递归定义。我们选取子问题域为:求解包含关键字 k i , ⋯ k_i,\cdots ki,⋯, k j k_j kj 的最优二叉搜索树,其中 i ⩾ 1 , j ⩽ n i\geqslant 1, j\leqslant n i⩾1,j⩽n且 j ⩾ i − 1 ( j\geqslant i- 1( j⩾i−1(当 j = i − 1 j=i-1 j=i−1 时,子树不包含实际关键字,只包含伪关键字 d i − 1 d_i-1 di−1)。定义 e [ i , j ] e[i,j] e[i,j]为在包含关键字 k i , ⋯ , k j k_i,\cdots,k_j ki,⋯,kj的最优二叉搜索树中进行一次搜索的期望代价。最终,我们希望计算出 e [ 1 , n ] e[1,n] e[1,n]。
j = i − 1 j=i-1 j=i−1的情况最为简单,由于子树只包含伪关键字 d i − 1 d_{i-1} di−1,期望搜索代价为 e [ i , i − 1 ] = q i − 1 e[i,i-1]=q_{i-1} e[i,i−1]=qi−1。当 j ⩾ i j\geqslant i j⩾i 时,我们需要从 k i , ⋯ , k j k_i,\cdots,k_j ki,⋯,kj 中选择一个根结点 k r k_r kr,然后构造一棵包含关键字 k i , ⋯ k_i,\cdots ki,⋯,
k r − 1 k_{r-1} kr−1的最优二叉搜索树作为其左子树,以及一棵包含关键字 k r + 1 , ⋯ , k j k_{r+1},\cdots,k_j kr+1,⋯,kj 的二叉搜索树作为其右子树。当一棵子树成为一个结点的子树时,期望搜索代价有何变化?由于每个结点的深度都增加了1,根据公式(15.11),这棵子树的期望搜索代价的增加值应为所有概率之和。对于包含关键字 k i , ⋯ , k j k_i,\cdots,k_j ki,⋯,kj的子树,所有概率之和为
w ( i , j ) = ∑ l = i j p l + ∑ l = i − 1 j q l w(i,j)=\sum_{l=i}^jp_l+\sum_{l=i-1}^jq_l w(i,j)=l=i∑jpl+l=i−1∑jql
(15.12)
因此,若点 r _r r为包含关键字 k i , . . . , k j k_i,...,k_j ki,...,kj 的最优二叉搜索树的根结点,我们有如下公式:
e [ i , j ] = p r + ( e [ i , r − 1 ] + w ( i , r − 1 ) ) + ( e [ r + 1 , j ] + w ( r + 1 , j ) ) e[i,j]=p_r+(e[i,r-1]+w(i,r-1))+(e[r+1,j]+w(r+1,j)) e[i,j]=pr+(e[i,r−1]+w(i,r−1))+(e[r+1,j]+w(r+1,j))
注意
w ( i , j ) = w ( i , r − 1 ) + p r + w ( r + 1 , j ) w(i,j)=w(i,r-1)+p_r+w(r+1,j) w(i,j)=w(i,r−1)+pr+w(r+1,j)
因此 e [ i , j ] e[i,j] e[i,j]可重写为
(15.13)
e [ i , j ] = e [ i , r − 1 ] + e [ r + 1 , j ] + w ( i , j ) e[i,j]=e[i,r-1]+e[r+1,j]+w(i,j) e[i,j]=e[i,r−1]+e[r+1,j]+w(i,j)
递归公式(15.13)假定我们知道哪个结点 k k k应该作为根结点。如果选取期望搜索代价最低者
作为根结点,可得最终递归公式:
1 e [ i , j ] = { q i − 1 若 j = i − 1 min n ⩽ n ⩽ j { e [ i , r − 1 ] + e [ r + 1 , j ] + w ( i , j ) } 若 i ⩽ j \begin{aligned}&\text{1}\\&e[i,j]=\begin{cases}q_{i-1}&\text{若 }j=i-1\\\min_{n\leqslant n\leqslant j}\{e[i,r-1]+e[r+1,j]+w(i,j)\}&\text{若 }i\leqslant j\end{cases}\end{aligned} 1e[i,j]={qi−1minn⩽n⩽j{e[i,r−1]+e[r+1,j]+w(i,j)}若 j=i−1若 i⩽j
(15.14)
e [ i , j ] e[i,j] e[i,j]的值给出了最优二叉搜索树的期望搜索代价。为了记录最优二叉搜索树的结构,对于包含关键字 k i , . . . , k j ( 1 ⩽ i ⩽ j ⩽ n ) k_i,...,k_j(1\leqslant i\leqslant j\leqslant n) ki,...,kj(1⩽i⩽j⩽n)的最优二叉搜索树,我们定义 r o o t [ i , j ] root[i,j] root[i,j]保存根结点 k,的下标 r r r。虽然我们将看到如何计算 r o o t [ i , j ] root[i,j] root[i,j]的值,但是利用这些值来构造最优二叉搜索树的问题将留作练习(练习15.5-1)。
步骤 3: 计算最优二叉搜索树的期望搜索代价
现在,你可能已经注意到我们求解最优二叉搜索树和矩阵链乘法的一些相似之处。它们的子问题都由连续的下标子域组成。而公式(15.14)的直接递归实现,也会与矩阵链乘法问题的直接递归算法一样低效。因此,我们设计替代的高效算法,我们用一个表 e [ 1 … n + 1 , 0 … n ] e[1\ldots n+1,0\ldots n] e[1…n+1,0…n]来保存 e [ i , j ] e[i,j] e[i,j]值。第一维下标上界为 n + 1 n+1 n+1而不是 n n n,原因在于对于只包含伪关键字 d n d_n dn的子树,我们需要计算并保存 e[ n + 1 , n ] n+1,n] n+1,n]。第二维下标下界为 0,是因为对于只包含伪关键字 d o d_{\mathrm{o}} do的子树,我们需要计算并保存 e [ 1 , 0 ] e[1,0] e[1,0]。我们只使用表中满足 j ⩾ i − 1 j\geqslant i-1 j⩾i−1的表项 e [ i , j ] e[i,j] e[i,j]。我们还使用一个表 r o o t root root,表项 r o o t [ i , j ] root[i,j] root[i,j]记录包含关键字 k i , . . . , k j k_i,...,k_j ki,...,kj的子树的根。我们只使用此表中满足 1 ⩽ i ⩽ j ⩽ n \leqslant i\leqslant j\leqslant n ⩽i⩽j⩽n 的表项 r o o t [ i , j ] root[i,j] root[i,j]。
我们还需要另一个表来提高计算效率。为了避免每次计算 e [ i , j ] e[i,j] e[i,j]时都重新计算 w ( i , j ) w(i,j) w(i,j),我们将这些值保存在表 w [ 1 … n + 1 , 0 … n ] w[1\ldots n+1,0\ldots n] w[1…n+1,0…n]中,这样每次可节省 Θ ( j − i ) \Theta(j-i) Θ(j−i)次加法。对基本情况,令 w [ i w[ i w[i, i − 1 ] = q i − 1 ( 1 ⩽ i ⩽ n + 1 ) 。对 i- 1] = q_{i- 1}( 1\leqslant i\leqslant n+ 1) 。对 i−1]=qi−1(1⩽i⩽n+1)。对 j ⩾ i j\geqslant i j⩾i的情况,可如下计算:
w [ i , j ] = w [ i , j − 1 ] + p j + q j w[i,j]=w[i,j-1]+p_j+q_j w[i,j]=w[i,j−1]+pj+qj
(15.15)
这样,对 Θ ( n 2 ) \Theta(n^{2}) Θ(n2)个 w [ i , j ] w[i,j] w[i,j],每个的计算时间为 Θ ( 1 ) \Theta(1) Θ(1)。
下面的伪代码接受概率列表 p 1 , … , p n p_1,\ldots,p_n p1,…,pn和 q 0 , … , q n q_0,\ldots,q_n q0,…,qn及规模 n n n作为输人,返回表 e e e和root 。
OPTIMAL-BST( p , q , n ) p,q,n) p,q,n)
1 let e [ 1.. n + 1 , 0... n ] , w [ 1... n + 1 , 0.. n ] e[1..n+1,0...n],w[1...n+1,0..n] e[1..n+1,0...n],w[1...n+1,0..n],and r o o t [ 1... n , 1.. n ] root[1...n,1..n] root[1...n,1..n]be new tables
2 for i = 1 i=1 i=1 to n + 1 n+1 n+1
3 e [ i , i − 1 ] = q i − 1 e[i,i-1]=q_{i-1} e[i,i−1]=qi−1
4 w [ i , i − 1 ] = q i − 1 w[i,i-1]=q_{i-1} w[i,i−1]=qi−1
5 for l = 1 l=1 l=1 to n n n
6 for i = 1 i=1 i=1 to n − l + 1 n-l+1 n−l+1
7 j = i + l − 1 j=i+l-1 j=i+l−1
8 e [ i , j ] = ∞ e[i,j]=\infty e[i,j]=∞
9 w [ i , j ] = w [ i , j − 1 ] + p j + q j w[i,j]=w[i,j-1]+p_j+q_j w[i,j]=w[i,j−1]+pj+qj
10 for r = i \operatorname{for}r=i forr=i to j j j
11 t = e [ i , r − 1 ] + e [ r + 1 , j ] + w [ i , j ] t=e[i,r-1]+e[r+1,j]+w[i,j] t=e[i,r−1]+e[r+1,j]+w[i,j]
12 if t < e [ i , j ] \textbf{if }t< e[ i, j] if t<e[i,j]
13 e [ i , j ] = t e[i,j]=t e[i,j]=t
14 r o o t [ i , j ] = r root[i,j]=r root[i,j]=r
15 return e e e and root
根据前文的描述,以及与前面的算法 MATRIX-CHAIN-ORDER 的相似性,很容易理解此算法。第 2~4 行的 for 循环初始化 e[i, i − 1 ] i-1] i−1]和 w [ i , i − 1 ] w[i,i-1] w[i,i−1]的值。第 5~14 行的 for 循环利用递归式(15.14)和递归式(15.15)来对所有 1 ⩽ i ⩽ j ⩽ n 1\leqslant i\leqslant j\leqslant n 1⩽i⩽j⩽n计算 e [ i , j ] [i,j] [i,j]和 w [ i , j ] w[i,j] w[i,j]。在第一个循环步中, l = 1 l=1 l=1,循环对所有 i = 1 , 2 , ⋯ , n i=1,2,\cdots,n i=1,2,⋯,n计算e [ i , i ] [i,i] [i,i]和 w [ i , i ] w[i,i] w[i,i]。第二个循环步中, l = 2 l=2 l=2,对所有 i = 1 , 2 , ⋯ , n − 1 i=1,2,\cdots,n-1 i=1,2,⋯,n−1计算 e [ i , i + 1 ] e[i,i+1] e[i,i+1]和 w [ i , i + 1 ] w[i,i+1] w[i,i+1],依此类推。第 10~14 行的内层 for 循环,逐个尝试下标 r r r,确定哪个关键字 k k k, 作 为 根 结 点 可 以 得 到 包 含 关 键 字 k i , . . . , k j k_i, . . . , k_j ki,...,kj的最优二叉搜索树。这个 for 循环在找到更好的关键字作为根结点时,会将其下标 r r r 保存在 r o o t [ i , j ] root[i,j] root[i,j]中。
图 15-10 给出了 OPTIMAL-BST 输人图 15-9 中的关键字分布后计算出的表 e[i,j]、w[i,j]和 r o o t [ i , j ] root[i,j] root[i,j]。与图 15-5 中矩阵链乘法问题的输出结果一样,本图中的表也进行了旋转,对角线旋转到了水平方向。OPTIMAL-BST 按自底向上的顺序逐行计算,在每行中由左至右计算每个表项。

与 MATRIX-CHAIN-ORDER 一样,OPTIMAL-BST 的时间复杂度也是 Θ ( n 3 ) \Theta(n^3) Θ(n3)。由于它包含三重 for 循环,而每层循环的下标最多取 n n n个值,因此很容易得出其运行时间为 O ( n 3 ) O(n^3) O(n3)。OPTIMAL-BST 的循环下标的范围与 MATRIX-CHAIN-ORDER 不完全一样,但每个方向最多相差 1。因此,与 MATRIX-CHAIN-ORDER 一样,OPTIMAL-BST 的运行时间为 Ω ( n 3 ) \Omega(n^3) Ω(n3)(从而得出运行时间为 Θ ( n 3 ) ) \Theta(n^3)) Θ(n3))。
三、问题分类
到达目标的最小(最大)路径
问题描述:
给定一个目标,找出达到目标的最小(最大)成本/路径/总和。
解决方法:
在当前状态之前的所有可能路径中选择最小(最大)路径,然后为当前状态添加值。
问题示例:
322.零钱兑换 (完全背包)中等
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3
输出:-1
示例 3:
输入:coins = [1], amount = 0
输出:0
提示:
1 <= coins.length <= 12
1 <= coins[i] <= 231 - 1
0 <= amount <= 104
解决方案
class Solution {
public:int coinChange(vector<int>& coins, int amount) {int n = coins.size();vector<int> dp(amount + 1, INT_MAX);dp[0] = 0;for(int i = 1; i <= amount; i++){for(int j : coins){if(i >= j && dp[i - j] != INT_MAX){dp[i] = min(dp[i], dp[i - j] + 1);} } }return dp[amount] == INT_MAX? -1 : dp[amount];}
};518.零钱兑换 II (完全背包-求方案数)中等
给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。
请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。
假设每一种面额的硬币有无限个。
题目数据保证结果符合 32 位带符号整数。
示例 1:
输入:amount = 5, coins = [1, 2, 5]
输出:4
解释:有四种方式可以凑成总金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
示例 2:
输入:amount = 3, coins = [2]
输出:0
解释:只用面额 2 的硬币不能凑成总金额 3 。
示例 3:
输入:amount = 10, coins = [10]
输出:1
提示:
1 <= coins.length <= 300
1 <= coins[i] <= 5000
coins 中的所有值 互不相同
0 <= amount <= 5000
解决方案
class Solution {public int change(int cnt, int[] cs) {int n = cs.length;int[][] f = new int[n + 1][cnt + 1];f[0][0] = 1;for (int i = 1; i <= n; i++) {int val = cs[i - 1];for (int j = 0; j <= cnt; j++) {f[i][j] = f[i - 1][j];for (int k = 1; k * val <= j; k++) {f[i][j] += f[i - 1][j - k * val]; }}}return f[n][cnt];}
}不同的方式——达到目标不同方式的总数
问题描述:
给定一个目标,找到许多不同的方法来达到目标。
解决方法:
求和所有可能达到当前状态的方法
问题示例:
935.骑士拨号器(递推型DP、状态压缩DP)中等
象棋骑士有一个独特的移动方式,它可以垂直移动两个方格,水平移动一个方格,或者水平移动两个方格,垂直移动一个方格(两者都形成一个 L 的形状)。
象棋骑士可能的移动方式如下图所示:
我们有一个象棋骑士和一个电话垫,如下所示,骑士只能站在一个数字单元格上(即蓝色单元格)。
给定一个整数 n,返回我们可以拨多少个长度为 n 的不同电话号码。
你可以将骑士放置在任何数字单元格上,然后你应该执行 n - 1 次移动来获得长度为 n 的号码。所有的跳跃应该是有效的骑士跳跃。
因为答案可能很大,所以输出答案模 109 + 7.
示例 1:
输入:n = 1
输出:10
解释:我们需要拨一个长度为1的数字,所以把骑士放在10个单元格中的任何一个数字单元格上都能满足条件。
示例 2:
输入:n = 2
输出:20
解释:我们可以拨打的所有有效号码为[04, 06, 16, 18, 27, 29, 34, 38, 40, 43, 49, 60, 61, 67, 72, 76, 81, 83, 92, 94]
示例 3:
输入:n = 3131
输出:136006598
解释:注意取模
提示:
1 <= n <= 5000


解决方案
class Solution {public int knightDialer(int n) {// dp[i][j] = \sum_{k=0}^{9} dp[i-1][k]int mod = 1000000000 + 7;int[][] dp = new int[n][10];for (int k = 0; k < 10; k++) {dp[0][k] = 1;}int[][] moves = new int[][]{{4, 6}, {6, 8}, {7, 9}, {4, 8}, {0, 3, 9}, {}, {0, 1, 7}, {2, 6}, {1, 3}, {2, 4}};for (int i = 1; i < n; i++) {for (int k = 0; k < 10; k++) {int[] mo = moves[k];for (int m : mo) {dp[i][k] = (dp[i][k] + dp[i-1][m]) % mod;}}}int res = 0;for (int k = 0; k < 10; k++) {res = (res + dp[n-1][k]) % mod;}return res;}
}576 出界的路径数(记忆化搜索)中等
给你一个大小为 m x n 的网格和一个球。球的起始坐标为 [startRow, startColumn] 。你可以将球移到在四个方向上相邻的单元格内(可以穿过网格边界到达网格之外)。你 最多 可以移动 maxMove 次球。
给你五个整数 m、n、maxMove、startRow 以及 startColumn ,找出并返回可以将球移出边界的路径数量。因为答案可能非常大,返回对 109 + 7 取余 后的结果。
示例 1:
输入:m = 2, n = 2, maxMove = 2, startRow = 0, startColumn = 0
输出:6
示例 2:
输入:m = 1, n = 3, maxMove = 3, startRow = 0, startColumn = 1
输出:12
提示:
1 <= m, n <= 50
0 <= maxMove <= 50
0 <= startRow < m
0 <= startColumn < n
解决方案
记忆化搜索:
const int mod = 1e9 + 7;
class Solution {map<pair<pair<int,int>, int>, long> ret;
public:int findPaths(int m, int n, int maxMove, int startRow, int startColumn) {return dfs(m, n, startRow, startColumn,maxMove);}int dfs(int m, int n, int i, int j, int num){//当前位置出界,说明找到一条路径if (i< 0 || j< 0 || i>= m || j>= n)return 1;//判断当前位置的结果是否求出if (ret.find({{ i,j }, num}) != ret.end())return ret[{ {i, j}, num}];//如果当前可移动次数小于等于0,并且还没有出界,那么则不算一条路径if (num<=0)return 0;//当前位置的路径和等于来自他四个方向之和int sum = 0;sum += dfs(m, n, i + 1, j, num - 1);sum %= mod;sum += dfs(m, n, i - 1, j, num - 1);sum %= mod;sum += dfs(m, n, i, j + 1, num - 1);sum %= mod;sum += dfs(m, n, i, j - 1, num - 1);sum %= mod;return ret[{ {i, j}, num}]=sum ;}
};
动态规划:
class Solution {int mod = (int)1e9+7;int m, n, N;public int findPaths(int _m, int _n, int _N, int _i, int _j) {m = _m; n = _n; N = _N;// f[i][j] 代表从 idx 为 i 的位置出发,移动步数不超过 j 的路径数量int[][] f = new int[m * n][N + 1];// 初始化边缘格子的路径数量for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {if (i == 0) add(i, j, f);if (i == m - 1) add(i, j, f);if (j == 0) add(i, j, f);if (j == n - 1) add(i, j, f);}}// 定义可移动的四个方向int[][] dirs = new int[][]{{1,0},{-1,0},{0,1},{0,-1}};// 从小到大枚举「可移动步数」for (int step = 1; step <= N; step++) {// 枚举所有的「位置」for (int k = 0; k < m * n; k++) {int x = parseIdx(k)[0], y = parseIdx(k)[1];for (int[] d : dirs) {int nx = x + d[0], ny = y + d[1];// 如果位置有「相邻格子」,则「相邻格子」参与状态转移if (nx >= 0 && nx < m && ny >= 0 && ny < n) {f[k][step] += f[getIndex(nx, ny)][step - 1];f[k][step] %= mod;}}}}// 最终结果为从起始点触发,最大移动步数不超 N 的路径数量return f[getIndex(_i, _j)][N];}// 为每个「边缘」格子,添加一条路径void add(int x, int y, int[][] f) {int idx = getIndex(x, y);for (int step = 1; step <= N; step++) {f[idx][step]++;}}// 将 (x, y) 转换为 indexint getIndex(int x, int y) {return x * n + y;}// 将 index 解析回 (x, y)int[] parseIdx(int idx) {return new int[]{idx / n, idx % n};}
} 动态规划套壳法
const int mod = 1e9 + 7;
class Solution {
public:int findPaths(int m, int n, int maxMove, int startRow, int startColumn) {//f[i][j][num]从(i,j)出发第num步出界的路径总数,等价于从外界出发第num步走到(i,j)的路径总数vector<vector<vector<int>>> dp(m + 2, vector<vector<int>>(n + 2,vector<int>(maxMove+1,0)));//外部一圈初始化for (int i = 0; i < n + 2; i++)//第一行和最后一行同时进行初始化{dp[0][i][0] = 1;dp[m + 1][i][0] = 1;}for (int j = 1; j < m+2; j++)//左右两列初始化{dp[j][0][0] = 1;dp[j][n + 1][0] = 1;}for (int k = 1; k <= maxMove; k++){for (int i = 1; i < m + 1; i++){for (int j = 1; j < n + 1; j++){dp[i][j][k] += dp[i - 1][j][k - 1];dp[i][j][k] %= mod;dp[i][j][k] += dp[i + 1][j][k - 1];dp[i][j][k] %= mod;dp[i][j][k] += dp[i][j - 1][k - 1];dp[i][j][k] %= mod;dp[i][j][k] += dp[i][j + 1][k - 1];dp[i][j][k] %= mod;}}}//计算起点出界路径总和int sum = 0;for (int k = 1; k <=maxMove; k++){sum=(sum+dp[startRow+1][startColumn+1][k])%mod;}return sum;}
};808 分汤(概率型DP)中等
有 A 和 B 两种类型 的汤。一开始每种类型的汤有 n 毫升。有四种分配操作:
提供 100ml 的 汤A 和 0ml 的 汤B 。
提供 75ml 的 汤A 和 25ml 的 汤B 。
提供 50ml 的 汤A 和 50ml 的 汤B 。
提供 25ml 的 汤A 和 75ml 的 汤B 。
当我们把汤分配给某人之后,汤就没有了。每个回合,我们将从四种概率同为 0.25 的操作中进行分配选择。如果汤的剩余量不足以完成某次操作,我们将尽可能分配。当两种类型的汤都分配完时,停止操作。
注意 不存在先分配 100 ml 汤B 的操作。
需要返回的值: 汤A 先分配完的概率 + 汤A和汤B 同时分配完的概率 / 2。返回值在正确答案 10-5 的范围内将被认为是正确的。
示例 1:
输入: n = 50
输出: 0.62500
解释:如果我们选择前两个操作,A 首先将变为空。
对于第三个操作,A 和 B 会同时变为空。
对于第四个操作,B 首先将变为空。
所以 A 变为空的总概率加上 A 和 B 同时变为空的概率的一半是 0.25 *(1 + 1 + 0.5 + 0)= 0.625。
示例 2:
输入: n = 100
输出: 0.71875
提示:
0 <= n <= 109
解决方案
class Solution {
public:double soupServings(int N) {unordered_map<int,unordered_map<int,double>> dp, temp;if(N >= 4800) return 1;//经过计算 N=4800时,prob = 0.99999,误差小于1e-6dp[N][N] = 1.0;double prob = 0.0, p;vector<vector<int>> delta = {{100,0},{75,25},{50,50},{25,75}};int A, B, nA, nB, i;while(!dp.empty()){for(auto& item1 : dp){ A = item1.first;for(auto& item2 : item1.second){B = item2.first;p = item2.second;if(A == 0)//A喝完了{if(B == 0)//AB同时喝完prob += p/2.0;else if(B > 0)//A先喝完prob += p;}else//A没完{if(B == 0)//B先喝完,不在答案考虑范围内continue;for(i = 0; i < 4; i++)//4种情况{nA = max(0, A-delta[i][0]);//不够,直接全部喝完,为0nB = max(0, B-delta[i][1]);temp[nA][nB] += p*0.25;}}}}dp.swap(temp);//更新dptemp.clear();}return prob;}
};62 不同路径(计数型DP)中等
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
输入:m = 3, n = 7
输出:28
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
1.向右 -> 向下 -> 向下
2.向下 -> 向下 -> 向右
3.向下 -> 向右 -> 向下
示例 3:
输入:m = 7, n = 3
输出:28
示例 4:
输入:m = 3, n = 3
输出:6
提示:
1 <= m, n <= 100
题目数据保证答案小于等于 2 * 109

解决方案
class Solution {public int uniquePaths(int m, int n) {int[] dp = new int[n];Arrays.fill(dp, 1);for (int i = 1; i < m; i++) {for (int j = 1; j < n; j++) {dp[j] = dp[j-1] + dp[j];}}return dp[n - 1];}
}区间合并
问题描述:
给定一组数字,根据当前数字以及你能从左右两边得到的最好结果,找到问题的最优解。
解决方法:
找到每个区间的所有最优解,并返回最佳答案。
问题示例:
1039 多边形三角剖分的最低得分(区间DP)中等
你有一个凸的 n 边形,其每个顶点都有一个整数值。给定一个整数数组 values ,其中 values[i] 是第 i 个顶点的值(即 顺时针顺序 )。
假设将多边形 剖分 为 n - 2 个三角形。对于每个三角形,该三角形的值是顶点标记的乘积,三角剖分的分数是进行三角剖分后所有 n - 2 个三角形的值之和。
返回 多边形进行三角剖分后可以得到的最低分 。
示例 1:
输入:values = [1,2,3]
输出:6
解释:多边形已经三角化,唯一三角形的分数为 6。
示例 2:
输入:values = [3,7,4,5]
输出:144
解释:有两种三角剖分,可能得分分别为:375 + 457 = 245,或 345 + 347 = 144。最低分数为 144。
示例 3:
输入:values = [1,3,1,4,1,5]
输出:13
解释:最低分数三角剖分的得分情况为 113 + 114 + 115 + 111 = 13。
提示:
n == values.length
3 <= n <= 50
1 <= values[i] <= 100



解决方案:
记忆化搜索:
class Solution {
public:int f[110][110];int minScoreTriangulation(vector<int>& values) {memset(f,0x3f3f3f3f,sizeof(f));function<int(int, int)> dfs = [&](int i,int j)->int{if(abs(i - j) <= 1){return 0;}if(f[i][j] != 0x3f3f3f3f) return f[i][j];for(int k = i + 1;k < j;k++){f[i][j] = min(f[i][j],dfs(i,k) + dfs(k,j) + values[i]*values[j]*values[k]);}return f[i][j];};dfs(0,values.size() - 1);return f[0][values.size() - 1];}
};
动态规划
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 70;int n;
int a[N];
__int128 f[N][N];
ostream &operator << (ostream &out,__int128 x) {if (!x) {out << 0;return out;}int stk[110],top = 0;while (x) stk[++top] = x % 10,x /= 10;for (int i = top;i >= 1;i--) out << stk[i];return out;
}
int main()
{cin>>n;for(int i = 1;i <= n;i++){cin>>a[i];}//memset(f,0x3f,sizeof f);for(int len = 1;len <= n;len++){for(int l = 1,r;r = l + len - 1,r <= n;l++){if(len < 3) f[l][r] = 0;else{f[l][r] = 1e29;for(int k = l + 1;k < r;k++){f[l][r] = min(f[l][r],f[l][k] + f[k][r] + (__int128)a[l] * a[k] * a[r]);}}}}cout<<f[1][n]<<endl;return 0;
}
312 戳气球(区间DP)困难
有 n 个气球,编号为0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。
现在要求你戳破所有的气球。戳破第 i 个气球,你可以获得 nums[i - 1] * nums[i] * nums[i + 1] 枚硬币。 这里的 i - 1 和 i + 1 代表和 i 相邻的两个气球的序号。如果 i - 1或 i + 1 超出了数组的边界,那么就当它是一个数字为 1 的气球。
求所能获得硬币的最大数量。
示例 1:
输入:nums = [3,1,5,8]
输出:167
解释:
nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> []
coins = 315 + 358 + 138 + 181 = 167
示例 2:
输入:nums = [1,5]
输出:10
提示:
n == nums.length
1 <= n <= 300
0 <= nums[i] <= 100
解决方案:
class Solution {public int maxCoins(int[] nums) {int n = nums.length;int[] newNums = new int[n + 2];newNums[0] = newNums[n + 1] = 1;for (int i = 0; i < n; i++) {newNums[i+1] = nums[i];}int[][] dp = new int[n + 2][n + 2];for (int i = n - 1; i >= 0; i--) {for (int j = i + 2; j < n + 2; j++) {for (int k = i + 1; k < j; k++) {dp[i][j] = Math.max(dp[i][j], newNums[i] * newNums[k] * newNums[j] + dp[i][k] + dp[k][j]);}}}return dp[0][n+1];}
}字符串——字符串上的动态规划
问题描述:
此模式的一般问题陈述可能会有所不同,但大多数情况下,你会得到两个字符串,这些字符串的长度并不大,返回两个字符串和一些其他的结果。
解决方法:
这种类型下的大多数问题都需要一个复杂度为 O ( n 2 ) O(n^2) O(n2)的解决方案。
问题示例:
1147 最长公共子序列(线性DP、最经典双串)中等
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,“ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = “abcde”, text2 = “ace”
输出:3
解释:最长公共子序列是 “ace” ,它的长度为 3 。
示例 2:
输入:text1 = “abc”, text2 = “abc”
输出:3
解释:最长公共子序列是 “abc” ,它的长度为 3 。
示例 3:
输入:text1 = “abc”, text2 = “def”
输出:0
解释:两个字符串没有公共子序列,返回 0 。
提示:
1 <= text1.length, text2.length <= 1000
text1 和 text2 仅由小写英文字符组成。
516 最长回文子序列(区间DP)中等
解决方案
class Solution {public int longestCommonSubsequence(String text1, String text2) {int m = text1.length(), n = text2.length();int[][] dp = new int[m+1][n+1];for (int i = 1; i <= m; i++) {char c1 = text1.charAt(i - 1);for (int j = 1; j <= n; j++) {if (c1 == text2.charAt(j - 1)) {dp[i][j] = dp[i-1][j-1] + 1;} else {dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1]);}}}return dp[m][n];}
}如果要求返回最长子序列:
public String LCS (String s1, String s2) {int m = s1.length(), n = s2.length();if (m == 0 || n == 0) {return "-1";}int[][] dp = new int[m + 1][n + 1];for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (s1.charAt(i - 1) == s2.charAt(j - 1)) {dp[i][j] = dp[i-1][j-1] + 1;} else {dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1]);}}}StringBuilder sb = new StringBuilder();int i = m, j = n;while (i > 0 && j > 0) {if (s1.charAt(i - 1) == s2.charAt(j - 1)) {sb.append(s1.charAt(i - 1));i--;j--;} else {if (dp[i][j-1] > dp[i-1][j]) {j--;} else {i--;}}}if (sb.length() == 0) {return "-1";}return sb.reverse().toString();
}516.最长回文子序列(区间DP)中等
给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。
子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
示例 1:
输入:s = “bbbab”
输出:4
解释:一个可能的最长回文子序列为 “bbbb” 。
示例 2:
输入:s = “cbbd”
输出:2
解释:一个可能的最长回文子序列为 “bb” 。
提示:
1 <= s.length <= 1000
s 仅由小写英文字母组成
解决方案
class Solution {public String longestPalindrome(String s) {int n = s.length();boolean[][] dp = new boolean[n][n];for (int i = 0; i < n; i++) {dp[i][i] = true;}int res = 1;int startId = 0, endId = 1;for (int i = 1; i < n; i++) {for (int j = 0; j < i; j++) {if (s.charAt(i) == s.charAt(j)) {if (j + 1 == i) {dp[j][i] = true;} else if (dp[j + 1][i - 1]) {dp[j][i] = true;}if (dp[j][i] && i - j + 1 > res) {res = i - j + 1;startId = j;endId = i + 1;}}}}return s.substring(startId, endId);}
}另一种写法:
public int getLongestPalindrome(String A, int n) {boolean[][] dp = new boolean[n][n];for (int i = 0; i < n; i++) {Arrays.fill(dp[i], true);}int maxLen = 0;for (int i = n - 2; i >= 0; i--) {for (int j = i + 1; j < n; j++) {dp[i][j] = A.charAt(i) == A.charAt(j) && dp[i+1][j-1];if (dp[i][j]) {maxLen = Math.max(maxLen, j - i + 1);}}}return maxLen;}72 编辑距离(线性DP)困难
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
插入一个字符
删除一个字符
替换一个字符
示例 1:
输入:word1 = “horse”, word2 = “ros”
输出:3
解释:
horse -> rorse (将 ‘h’ 替换为 ‘r’)
rorse -> rose (删除 ‘r’)
rose -> ros (删除 ‘e’)
示例 2:
输入:word1 = “intention”, word2 = “execution”
输出:5
解释:
intention -> inention (删除 ‘t’)
inention -> enention (将 ‘i’ 替换为 ‘e’)
enention -> exention (将 ‘n’ 替换为 ‘x’)
exention -> exection (将 ‘n’ 替换为 ‘c’)
exection -> execution (插入 ‘u’)
提示:
0 <= word1.length, word2.length <= 500
word1 和 word2 由小写英文字母组成
解决方案
class Solution {public int minDistance(String word1, String word2) {int m = word1.length(), n = word2.length();int[][] dp = new int[m+1][n+1];for (int i = 0; i <= m; i++) {for (int j = 0; j <= n; j++) {if (i == 0 || j == 0) {dp[i][j] = Math.max(i, j);} else {if (word1.charAt(i - 1) == word2.charAt(j - 1)) {dp[i][j] = dp[i - 1][j - 1];} else {dp[i][j] = Math.min(Math.min(dp[i - 1][j], dp[i][j - 1]), dp[i - 1][j - 1]) + 1;}}}}return dp[m][n];}
}决策——取舍决定(当前元素取或是不取)
问题描述:
此类型的一般问题描述可以在决定是否使用当前状态的情况下进行,所以,这个问题要求你在当前状态下做出决定。即给定一组值,找到带有选择或者忽略当前值的选项的答案。
解决方法:
如果您决定选择当前值,则使用先前忽略该值的结果;反之亦然,如果决定忽略当前值,则使用先前使用值的结果。
问题示例:
121 买卖股票的最佳时机(线性DP)简单
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
1 <= prices.length <= 105
0 <= prices[i] <= 104
解决方案
public class lc_121 {// 解法三:动态规划public static int maxProfit(int[] prices) {int n = prices.length;// dp[i]表示前i天的最大利润int dp[] = new int[n];// minPrice初始化为prices[0]int minPrice = prices[0];for (int i = 1; i < n; i++) {if (prices[i] < minPrice) {minPrice = prices[i];}// 前i天的最大收益 = max{ 前i-1天的最大收益,第i天的价格 - 前i-1天中的最小价格 }dp[i] = Math.max(dp[i - 1], prices[i] - minPrice);}return dp[n - 1];}public static void main(String[] args) {int prices1[] = {7, 1, 5, 3, 6, 4};int profit1 = maxProfit(prices1);System.out.println(profit1);int prices2[] = {7, 6, 4, 3, 1};int profit2 = maxProfit(prices2);System.out.println(profit2);int prices3[] = {1, 2};int profit3 = maxProfit(prices3);System.out.println(profit3);}
}123 买卖股票的最佳时机 III(线性DP)困难
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:prices = [3,3,5,0,0,3,1,4]
输出:6
解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这个情况下, 没有交易完成, 所以最大利润为 0。
示例 4:
输入:prices = [1]
输出:0
提示:
1 <= prices.length <= 105
0 <= prices[i] <= 105
解决方案
#include <vector>
#include <algorithm>
using namespace std;class Solution {
public:int maxProfit(vector<int>& prices) {if (prices.empty()) return 0;// 初始化四个状态int first_buy = -prices[0], first_sell = 0;int second_buy = -prices[0], second_sell = 0;for (int i = 1; i < prices.size(); ++i) {// 依次更新四个状态first_buy = max(first_buy, -prices[i]);first_sell = max(first_sell, first_buy + prices[i]);second_buy = max(second_buy, first_sell - prices[i]);second_sell = max(second_sell, second_buy + prices[i]);}// 返回最终状态的最大值return second_sell;}
};188 买卖股票的最佳时机 IV(线性DP)困难
给你一个整数数组 prices 和一个整数 k ,其中 prices[i] 是某支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。也就是说,你最多可以买 k 次,卖 k 次。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:k = 2, prices = [2,4,1]
输出:2
解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
示例 2:
输入:k = 2, prices = [3,2,6,5,0,3]
输出:7
解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。
随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
提示:
1 <= k <= 100
1 <= prices.length <= 1000
0 <= prices[i] <= 1000
解决方案
class Solution {
public:int maxProfit(int k, vector<int>& prices) {int n = prices.size();if (n == 0) return 0;// 当 k 大于等于 n/2 时,相当于可以进行无限次交易if (k >= n / 2) {int max_profit = 0;for (int i = 1; i < n; ++i) {if (prices[i] > prices[i - 1]) {max_profit += prices[i] - prices[i - 1];}}return max_profit;}// 初始化 dp 数组vector<vector<vector<int>>> dp(n, vector<vector<int>>(k + 1, vector<int>(2, 0)));// 初始化第一天的状态for (int j = 1; j <= k; ++j) {dp[0][j][1] = -prices[0];}// 动态规划状态转移for (int i = 1; i < n; ++i) {for (int j = 1; j <= k; ++j) {dp[i][j][0] = max(dp[i - 1][j][0], dp[i - 1][j][1] + prices[i]);dp[i][j][1] = max(dp[i - 1][j][1], dp[i - 1][j - 1][0] - prices[i]);}}// 返回结果return dp[n - 1][k][0];}
};309 买卖股票的最佳时机含冷冻期(线性DP)中等
给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: prices = [1,2,3,0,2]
输出: 3
解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
示例 2:
输入: prices = [1]
输出: 0
提示:
1 <= prices.length <= 5000
0 <= prices[i] <= 1000
解决方案
#include <vector>
#include <algorithm>
using namespace std;class Solution {
public:int maxProfit(vector<int>& prices) {if (prices.empty()) return 0;int n = prices.size();// 初始化第0天的状态int hold = -prices[0];int sell = 0;int cooldown = 0;for (int i = 1; i < n; ++i) {// 更新状态int new_hold = max(hold, sell - prices[i]);int new_cooldown = hold + prices[i];int new_sell = max(sell, cooldown);// 更新hold, cooldown, sellhold = new_hold;cooldown = new_cooldown;sell = new_sell;}// 返回sell和cooldown中的较大值return max(sell, cooldown);}
};714 买卖股票的最佳时机含手续费(线性DP)中等
给定一个整数数组 prices,其中 prices[i]表示第 i 天的股票价格 ;整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
示例 1:
输入:prices = [1, 3, 2, 8, 4, 9], fee = 2
输出:8
解释:能够达到的最大利润:
在此处买入 prices[0] = 1
在此处卖出 prices[3] = 8
在此处买入 prices[4] = 4
在此处卖出 prices[5] = 9
总利润: ((8 - 1) - 2) + ((9 - 4) - 2) = 8
示例 2:
输入:prices = [1,3,7,5,10,3], fee = 3
输出:6
提示:
1 <= prices.length <= 5 * 104
1 <= prices[i] < 5 * 104
0 <= fee < 5 * 104
解决方案
贪心算法:
class Solution {
public:int maxProfit(vector<int>& prices, int fee) {int n = prices.size(); // 获取价格数组的长度vector<vector<int>> dp(n,vector<int>(2,0)); // 创建二维数组dp,用于保存最大利润dp[0][0] -= prices[0]; // 初始化第一天持有股票的最大利润for(int i = 1;i<n;i++) // 遍历所有日期{// 在第i天不持有股票的最大利润为:昨天就没有持有股票的最大利润和昨天持有股票,今天卖掉的最大利润的较大值dp[i][0] = max(dp[i-1][0],dp[i-1][1] - prices[i]);// 在第i天持有股票的最大利润为:昨天就持有股票的最大利润和昨天没有持有股票,今天买入股票的最大利润的较大值dp[i][1] = max(dp[i-1][1],dp[i-1][0] + prices[i] - fee);}return dp[n-1][1]; // 返回最后一天不持有股票的最大利润// 可以返回最后一天持有股票的最大利润,两者取较大值即可// return max(dp[n-1][0],dp[n-1][1]);}
};
动态规划:
class Solution {
public:int maxProfit(vector<int>& prices, int fee) {int n = prices.size();int holdStock = (-1) * prices[0]; // 持股票int saleStock = 0; // 卖出股票for (int i = 1; i < n; i++) {int previousHoldStock = holdStock;holdStock = max(holdStock, saleStock - prices[i]);saleStock = max(saleStock, previousHoldStock + prices[i] - fee);}return saleStock;}
};
补充类型
294.翻转游戏 II(博弈型DP、记忆化递归)中等
你和朋友玩一个叫做「翻转游戏」的游戏。游戏规则如下:
给你一个字符串 currentState ,其中只含 ‘+’ 和 ‘-’ 。你和朋友轮流将 连续 的两个 “++” 反转成 “–” 。当一方无法进行有效的翻转时便意味着游戏结束,则另一方获胜。默认每个人都会采取最优策略。
请你写出一个函数来判定起始玩家 是否存在必胜的方案 :如果存在,返回 true ;否则,返回 false 。
示例 1:
输入:currentState = “++++”
输出:true
解释:起始玩家可将中间的 “++” 翻转变为 “±-+” 从而得胜。
示例 2:
输入:currentState = “+”
输出:false
提示:
1 <= currentState.length <= 60
currentState[i] 不是 ‘+’ 就是 ‘-’
解决方案
记忆化搜索:
class Solution {
public:bool canWin(string s) {const int N = s.size();if (N <= 1) return false;if (win_.count(s) && win_[s]) return true;for (int i = 0; i < N - 1; ++i) {if (s[i] == '+' && s[i + 1] == '+') {string flip = s.substr(0, i) + "--" + s.substr(i + 2);if (!canWin(flip)) {win_[s] = true;return true;}}}return false;}
private:unordered_map<string, bool> win_;
};
回溯:
class Solution {
public:bool canWin(string currentState) { //回溯string s = currentState; int n = s.size();for (int i = 0; i < n - 1; i ++){if (s[i] == '+' && s[i+1] == '+'){s[i] = '-';s[i+1] = '-';if (canWin (s) == false)return true;s[i] = '+'; s[i+1] = '+'; }}return false;}
};337.打家劫舍 III(树型DP)中等
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
示例 1:
输入: root = [3,2,3,null,3,null,1]
输出: 7
解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
示例 2:
输入: root = [3,4,5,1,3,null,1]
输出: 9
解释: 小偷一晚能够盗取的最高金额 4 + 5 = 9
提示:
树的节点数在 [1, 104] 范围内
0 <= Node.val <= 104
解决方案
public class Solution {public int rob(TreeNode root) {int[] res = dp(root);return Math.max(res[0], res[1]);}private int[] dp(TreeNode root) {if (root == null) {return new int[]{0, 0};}int[] left = dp(root.left);int[] right = dp(root.right);int selected = root.val + left[1] + right[1];int notSelected = Math.max(left[0], left[1]) + Math.max(right[0], right[1]);return new int[]{selected, notSelected};}
}902 最大为 N 的数字组合(数位DP)困难
给定一个按 非递减顺序 排列的数字数组 digits 。你可以用任意次数 digits[i] 来写的数字。例如,如果 digits = [‘1’,‘3’,‘5’],我们可以写数字,如 ‘13’, ‘551’, 和 ‘1351315’。
返回 可以生成的小于或等于给定整数 n 的正整数的个数 。
示例 1:
输入:digits = [“1”,“3”,“5”,“7”], n = 100
输出:20
解释:
可写出的 20 个数字是:
1, 3, 5, 7, 11, 13, 15, 17, 31, 33, 35, 37, 51, 53, 55, 57, 71, 73, 75, 77.
示例 2:
输入:digits = [“1”,“4”,“9”], n = 1000000000
输出:29523
解释:
我们可以写 3 个一位数字,9 个两位数字,27 个三位数字,
81 个四位数字,243 个五位数字,729 个六位数字,
2187 个七位数字,6561 个八位数字和 19683 个九位数字。
总共,可以使用D中的数字写出 29523 个整数。
示例 3:
输入:digits = [“7”], n = 8
输出:1
提示:
1 <= digits.length <= 9
digits[i].length == 1
digits[i] 是从 ‘1’ 到 ‘9’ 的数
digits 中的所有值都 不同
digits 按 非递减顺序 排列
1 <= n <= 109
解决方案
class Solution {public int atMostNGivenDigitSet(String[] digits, int n) {char[] nc = String.valueOf(n).toCharArray();int result = 0, ncl = nc.length, dl = digits.length;for (int i = 1; i < ncl; i++) result += Math.pow(dl, i); // 先对【非最高位】的其他位,可组装的数字进行统计for (int i = 0; i < ncl; i++) {boolean compareNext = false; // 是否需要对比下一个数字for (String digit : digits) {char dc = digit.charAt(0); // 将String转换为charif (dc < nc[i]) result += Math.pow(dl, ncl - i - 1);else {if (dc == nc[i]) compareNext = true; break;}}if (!compareNext) return result;}return ++result; // 如果到最后1位依然满足compareNext,因为最后1位无法再向后对比了,所以最终结果+1}
}
233 数字 1 的个数(数位DP)困难
给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。
示例 1:
输入:n = 13
输出:6
示例 2:
输入:n = 0
输出:0
提示:
0 <= n <= 109
解决方案
class Solution {public int countDigitOne(int n) {int high = n / 10, low = 0, digit = 1, cur = (n / digit) % 10, res = 0;while (high != 0 || cur != 0) {if (cur == 0) {res += (high * digit);} else if (cur == 1) {res += (high * digit + low + 1);} else {res += (high + 1) * digit;}low = cur * digit + low;cur = high % 10;digit *= 10;high /= 10;}return res;}}124 二叉树中的最大路径和(树形DP)困难
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:
输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:
输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
提示:
树中节点数目范围是 [1, 3 * 104]
-1000 <= Node.val <= 1000

解决方案
class Solution {private int res;public int maxPathSum(TreeNode root) {if (root == null) {return 0;}res = Integer.MIN_VALUE;dp(root);return res;}private int dp(TreeNode root) {if (root == null) {return 0;}// 左边的最大路径int left = Math.max(dp(root.left), 0);// 右边的最大路径int right = Math.max(dp(root.right), 0);// 更新当前节点root的最大路径和res = Math.max(res, root.val + left + right);// 返回当前节点root到叶子节点的最大路径return root.val + Math.max(left, right);}
}1349 参加考试的最大学生数(状态压缩DP)困难
给你一个 m * n 的矩阵 seats 表示教室中的座位分布。如果座位是坏的(不可用),就用 ‘#’ 表示;否则,用 ‘.’ 表示。
学生可以看到左侧、右侧、左上、右上这四个方向上紧邻他的学生的答卷,但是看不到直接坐在他前面或者后面的学生的答卷。请你计算并返回该考场可以容纳的同时参加考试且无法作弊的 最大 学生人数。
学生必须坐在状况良好的座位上。
示例 1:
输入:seats = [[“#”,“.”,“#”,“#”,“.”,“#”],
[“.”,“#”,“#”,“#”,“#”,“.”],
[“#”,“.”,“#”,“#”,“.”,“#”]]
输出:4
解释:教师可以让 4 个学生坐在可用的座位上,这样他们就无法在考试中作弊。
示例 2:
输入:seats = [[“.”,“#”],
[“#”,“#”],
[“#”,“.”],
[“#”,“#”],
[“.”,“#”]]
输出:3
解释:让所有学生坐在可用的座位上。
示例 3:
输入:seats = [[“#”,“.”,“.”,“.”,“#”],
[“.”,“#”,“.”,“#”,“.”],
[“.”,“.”,“#”,“.”,“.”],
[“.”,“#”,“.”,“#”,“.”],
[“#”,“.”,“.”,“.”,“#”]]
输出:10
解释:让学生坐在第 1、3 和 5 列的可用座位上。
提示:
seats 只包含字符 ‘.’ 和’#’
m == seats.length
n == seats[i].length
1 <= m <= 8
1 <= n <= 8

解决方案
记忆化搜索
class Solution {
public:
int f[8][1<<8] , valid[8];int dfs(int x , int y){int& res = f[x][y];if(~res) return res;if(!x){if(!y) return res = 0;int lb = y&-y;return res = dfs(x , (y & ~(lb*3))) + 1;}res = dfs(x - 1 , valid[x - 1]);for(int i = y ; i ; i = (i - 1) & y){if(!(i & (i >> 1))){int t = valid[x - 1] & ~((i << 1) | (i >> 1));res = max(res , dfs(x - 1, t) + __builtin_popcount(i));}}return res;}int maxStudents(vector<vector<char>>& seats) {int m = seats.size() , n = seats[0].size();memset(f , -1 , sizeof(f));memset(valid , 0 , sizeof(valid));for(int i = 0 ; i < m ; i++)for(int j = 0 ; j < n ; j++)if(seats[i][j] == '.') valid[i] |= (1 << j);return dfs(m - 1 , valid[m - 1]);}
};
递推:
class Solution {
public:
int f[8][1<<8] , valid[8];int maxStudents(vector<vector<char>>& seats) {int m = seats.size() , n = seats[0].size();memset(f , 0 , sizeof(f));memset(valid , 0 , sizeof(valid));for(int i = 0 ; i < m ; i++)for(int j = 0 ; j < n ; j++)if(seats[i][j] == '.') valid[i] |= (1 << j);for(int i = 1 ; i < (1 << n) ; i++){int lb = i&-i;f[0][i] = f[0][i & ~(lb * 3)] + 1;}for(int i = 1 ; i < m ; i++){for(int j = valid[i] ; j ; j = (j - 1) & valid[i]){f[i][j] = f[i - 1][valid[i - 1]];for(int k = j ; k ; k = (k - 1) & j){if(!(k & (k >> 1))){int t = valid[i - 1] & ~(k << 1 | k >> 1);f[i][j] = max(f[i][j] , f[i - 1][t] + f[0][k]);}}}f[i][0] = f[i - 1][valid[i - 1]];}return f[m - 1][valid[m - 1]];}
};
1259 不相交的握手(计数型DP)困难
偶数 个人站成一个圆,总人数为 num_people 。每个人与除自己外的一个人握手,所以总共会有 num_people / 2 次握手。
将握手的人之间连线,请你返回连线不会相交的握手方案数。
由于结果可能会很大,请你返回答案 模 10^9+7 后的结果。
示例 1:
输入:num_people = 2
输出:1
示例 2:
输入:num_people = 4
输出:2
解释:总共有两种方案,第一种方案是 [(1,2),(3,4)] ,第二种方案是 [(2,3),(4,1)] 。
示例 3:
输入:num_people = 6
输出:5
示例 4:
输入:num_people = 8
输出:14
提示:
2 <= num_people <= 1000
num_people % 2 == 0

解决方案
class Solution {public int numberOfWays(int numPeople) {int half = numPeople/2;long[] dp = new long[half+1];long MOD = (long) (1e9+7);dp[0]=1;for(int i = 1; i <= half; i++){for(int j = 0; j < i-j-1; j++){dp[i]+=dp[j]*dp[i-j-1]*2;dp[i] = dp[i]%MOD;}if(i%2!=0){dp[i]+=dp[i/2]*dp[i-i/2-1];dp[i] = dp[i]%MOD;}}return (int) dp[half];}}
664 奇怪的打印机(区间DP)困难
有台奇怪的打印机有以下两个特殊要求:
打印机每次只能打印由 同一个字符 组成的序列。
每次可以在从起始到结束的任意位置打印新字符,并且会覆盖掉原来已有的字符。
给你一个字符串 s ,你的任务是计算这个打印机打印它需要的最少打印次数。
示例 1:
输入:s = “aaabbb”
输出:2
解释:首先打印 “aaa” 然后打印 “bbb”。
示例 2:
输入:s = “aba”
输出:2
解释:首先打印 “aaa” 然后在第二个位置打印 “b” 覆盖掉原来的字符 ‘a’。
提示:
1 <= s.length <= 100
s 由小写英文字母组成
解决方案
class Solution {
public:int strangePrinter(string s) {int n = s.length();vector<vector<int>> f(n, vector<int>(n));for (int i = n - 1; i >= 0; i--) {f[i][i] = 1;for (int j = i + 1; j < n; j++) {if (s[i] == s[j]) {f[i][j] = f[i][j - 1];} else {int minn = INT_MAX;for (int k = i; k < j; k++) {minn = min(minn, f[i][k] + f[k + 1][j]);}f[i][j] = minn;}}}return f[0][n - 1];}
};
730 统计不同回文子字符串(区间DP)困难
给你一个字符串 s ,返回 s 中不同的非空回文子序列个数 。由于答案可能很大,请返回对 109 + 7 取余 的结果。
字符串的子序列可以经由字符串删除 0 个或多个字符获得。
如果一个序列与它反转后的序列一致,那么它是回文序列。
如果存在某个 i , 满足 ai != bi ,则两个序列 a1, a2, … 和 b1, b2, … 不同。
示例 1:
输入:s = ‘bccb’
输出:6
解释:6 个不同的非空回文子字符序列分别为:‘b’, ‘c’, ‘bb’, ‘cc’, ‘bcb’, ‘bccb’。
注意:‘bcb’ 虽然出现两次但仅计数一次。
示例 2:
输入:s = ‘abcdabcdabcdabcdabcdabcdabcdabcddcbadcbadcbadcbadcbadcbadcbadcba’
输出:104860361
解释:共有 3104860382 个不同的非空回文子序列,104860361 是对 109 + 7 取余后的值。
提示:
1 <= s.length <= 1000
s[i] 仅包含 ‘a’, ‘b’, ‘c’ 或 ‘d’
解决方案
/** 需求给定一个字符串 S,找出 S 中不同的非空回文子序列个数,并返回该数字与 10^9 + 7 的模。 通过从 S 中删除 0 个或多个字符来获得子字符序列。 如果一个字符序列与它反转后的字符序列一致,那么它是回文字符序列。 如果对于某个 i,A_i != B_i,那么 A_1, A_2, ... 和 B_1, B_2, ... 这两个字符序列是不同的。示例 1:输入:S = 'bccb'输出:6解释:6 个不同的非空回文子字符序列分别为:'b', 'c', 'bb', 'cc', 'bcb', 'bccb'。注意:'bcb' 虽然出现两次但仅计数一次。示例 2: 输入:S = 'abcdabcdabcdabcdabcdabcdabcdabcddcbadcbadcbadcbadcbadcbadcbadcba'输出:104860361解释:共有 3104860382 个不同的非空回文子字符序列,对 10^9 + 7 取模为 104860361。提示: 字符串 S 的长度将在[1, 1000]范围内。每个字符 S[i] 将会是集合 {'a', 'b', 'c', 'd'} 中的某一个。gcc countPalindromicSubsequences.c -g -o a.exe -DDEBUG*/
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>#ifdef DEBUG
#define LOG(fmt, args...) fprintf(stdout, fmt, ##args)
#define BREAKER(a, b, c) breaker(a, b, c)
#else
#define LOG(fmt,...)
#define BREAKER(a, b, c)
#endif#define TRUE 1
#define FALSE 0#define MAX(a, b) ((a) > (b) ? (a) : (b))
#define MIN(a, b) ((a) > (b) ? (b) : (a))int countPalindromicSubsequences(char * S){if(NULL == S){return 0;}int ** dp = NULL;int i = 0, j = 0;int size = strlen(S);int left = 0, right = 0;int ret = 0;int M = 1e9 + 7;dp = (int ** )malloc(size * (sizeof(int *)));for(i = 0; i < size; i++){dp[i] = (int *)malloc(size * sizeof(int)); } /*数组初始化都是0,这步骤很重要,因为dp算法,后面的计算要依赖前面的值和初始值*/for(i = 0; i < size; i++){for(j = 0; j < size; j++){dp[i][j] = 0;}}for(i = 0; i < size; i++){dp[i][i] = 1;}for(i = size - 2; i >= 0; i--){for(j = i + 1; j < size; j++){if(S[i] == S[j]) {left = i + 1;right = j - 1;while(left <= right && S[left] != S[i]){left++;}while(left <= right && S[right] != S[i]){right--;}if(left > right) { /*不包含s[i]*/dp[i][j] = dp[i + 1][j - 1] * 2 + 2;} else if (left == right){ /*包含1个s[i]*/dp[i][j] = dp[i + 1][j - 1] * 2 + 1;} else { /*包含2个以上s[i]*/dp[i][j] = dp[i + 1][j - 1] * 2 - dp[left + 1][right - 1];}} else {dp[i][j] = dp[i][j - 1] + dp[i + 1][j] - dp[i + 1][j - 1];}dp[i][j] = (dp[i][j] < 0) ? dp[i][j] + M : dp[i][j] % M;}}ret = dp[0][size - 1];free(dp);dp = NULL;return ret;
}void testcountPalindromicSubsequences(void){printf("\n************ testcountPalindromicSubsequences ************ \n");int ret = 0;#if 1char * str1 = "bccb";ret = countPalindromicSubsequences(str1);printf("The Palindromic Subsequences of str %s is %d\n", str1, ret);char * str2 = "abcdabcdabcdabcdabcdabcdabcdabcddcbadcbadcbadcbadcbadcbadcbadcba";ret = countPalindromicSubsequences(str2);printf("The Palindromic Subsequences of str %s is %d\n", str2, ret);#endifreturn; }int main(int argc, char ** argv){testcountPalindromicSubsequences();}引用和参考文献
1.《算法导论》
2. 力扣
相关文章:

数据结构与算法分析:专题内容——动态规划2之例题讲解(代码详解+万字长文+算法导论+力扣题)
一、最长公共子序列 在生物应用中,经常需要比较两个(或多个)不同生物体的 DNA。一个 DNA 串由一串称为碱基(base)的分子组成,碱基有腺嘌呤、鸟嘌呤、胞嘧啶和胸腺嘧啶 4 种类型。我们用英文单词首字母表示 4 种碱基,这样就可以将一个 DNA 串…...

【Qt】QTreeView 和 QStandardItemModel的关系
QTreeView 和 QAbstractItemModel(通常是其子类,如 QStandardItemModel 或自定义模型)是 Qt 框架中的两个关键组件,它们之间存在密切的关系。 关系概述 QTreeView: QTreeView 是一个用于显示和编辑层次数据的视图小部…...

containerd配置私有仓库registry
机器ip端口regtisry192.168.0.725000k8s-*-------k8s集群 1、镜像上传 rootadmin:~# docker push 192.168.0.72:5000/nginx:1.26.1-alpine The push refers to repository [192.168.0.72:5000/nginx] 6961f0b8531c: Pushed 3112cd521249: Pushed d3f50ce9b5b5: Pushed 9efaf2eb…...

深入解析语音识别中的关键技术:GMM、HMM、DNN和语言模型
目录 一、高斯混合模型(GMM)与期望最大化(EM)算法二、隐马尔可夫模型(HMM)三、深度神经网络(DNN)四、语言模型(LM)五、ASR系统的整体工作流程结论 在现代语音…...

C++循环引用
C循环引用指的是两个或多个类之间互相引用对方,形成一个循环的引用关系。 循环引用的问题: 编译错误:编译器在编译过程中会按照包含关系依次编译每个文件,当编译ClassA时,它会尝试包含ClassB.h文件,而…...

dayseven-因果分析-图模型与结构因果模型
在数学上,“图”(graph)是顶点(vertex,也可以称为节点)和边(edge)的集合,表示为图G(V,E),其中V是节点的集合,E是边的集合,图中的节点之间通过边相连(也可以不相连&…...

并发编程(8)—— std::async、std::future 源码解析
文章目录 八、day81. std::async2. std::future2.1 wait()2.2 get() 八、day8 之前说过,std::async内部的处理逻辑和std::thread相似,而且std::async和std::future有密不可分的联系。今天,通过对std::async和std::future源码进行解析&#x…...
)
稻米分类和病害检测数据集(猫脸码客 第237期)
稻米分类图像数据集:推动农业智能化发展的关键资源 在农业领域,稻米作为世界上最重要的粮食作物之一,其品种繁多,各具特色。然而,传统的稻米分类方法往往依赖于人工观察和经验判断,不仅耗时费力࿰…...

HANDLINK ISS-7000v2 网关 login_handler.cgi 未授权RCE漏洞复现
0x01 产品简介 瀚霖科技股份有限公司ISS-7000 v2网络网关服务器是台高性能的网关,提供各类酒店网络认证计费的完整解决方案。由于智慧手机与平板电脑日渐普及,人们工作之时开始使用随身携带的设备,因此无线网络也成为网络使用者基本服务的项目。ISS-7000 v2可登录300至1000…...

基于Multisim串联型连续可调直流稳压正电源电路设计与仿真
设计任务和要求: (1)输出直流电压 1.5∽10V 可调; (2)输出电流 IOm300mA;(有电流扩展功能) (3)稳压系数 Sr≤0.05; (4&…...

【QT】Qt文件和多线程
个人主页~ Qt系统内容 一、Qt文件1、文件读写读写 2、文件和目录信息 二、多线程1、线程使用timethread.hwidget.htimethread.cppwidget.cpp 2、线程安全(1)互斥锁QMutexQMutexLocker一个例子mythread.hmythread.cppwidget.cpp QReadWriteLocker、QReadL…...
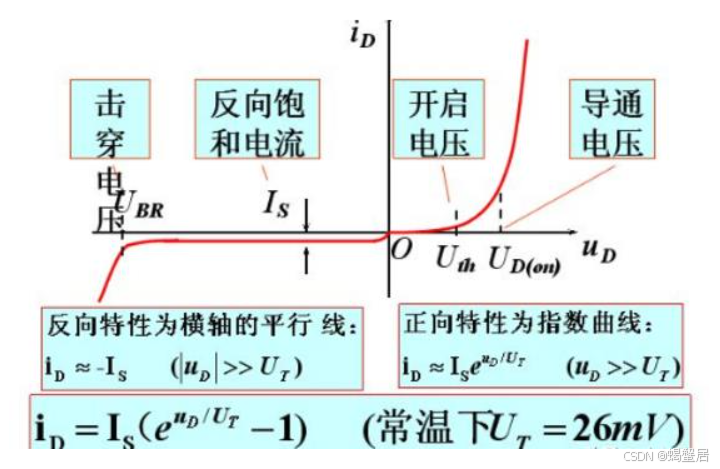
PN结如何实现不同反向耐压及达到高反向耐压
目录 1. PN结实现不同耐压值 2. PN如何达到高反向耐压 1. PN结实现不同耐压值 主要通过以下几个方面: • PN结设计:不同耐压值的二极管在PN结的设计上有所不同。通过调整PN结的宽度和深度,可以改变空间电荷区的大小,从而影响二极…...

【bug日志-水】解决本地开发下代理和url同名导致刷新404的问题
bug描述 在本地开发,并且路由是history的模式下,代理和url同名的情况下,刷新会404。 {path: /googleAds,//如果有个代理也叫googleAds,刷新时就会404name: googleAds,icon: sound,routes: [{path: /googleAds/GoogleAdsSettingPag…...

Hive面试题-- 查询各类型专利 top10 申请人及专利申请数
在数据处理中,尤其是涉及到专利信息等复杂数据时,Hive 是一个强大的工具。本文将详细介绍如何使用 Hive 查询语句来获取各类型专利 top10 申请人以及他们对应的专利申请数,以下是基于给定的 t_patent_detail 表结构的分析和查询步骤。 建表语…...

996引擎 - 活捉NPC
996引擎 - 活捉NPC 引擎触发 - 引擎事件(QF)事件处理模块 GameEvent测试文件参考资料 引擎触发 - 引擎事件(QF) cfg_game_data 配置 ShareNpc1 可以将QM和机器人的触发事件全部转到 QF 引擎触发是通用的,TXT的所有触发转换成小写后在LUA中就可使用,如说明书中缺省可反馈至对接群…...

航展畅想:从F35机载软件研发来看汽车车载软件研发
两款经典战机的机载软件 F-22和F-35战斗机的研制分别始于1980年代和1990年代末,F-22项目在1981年启动,主要由洛克希德马丁(Lockheed Martin)和波音公司(Boeing)合作开发,以满足美军“先进战术战…...

用Dify搭建AI知识库
Dify 可以上传各种格式文档和抓取网页数据训练自已的知识库 一 安装 1 Docker安装 我基于Docker来安装的,所以本机先装Docker Desktop, Docker 安装方法在这里 2 Dify 安装 git clone https://github.com/langgenius/dify.git cd dify/docker copy .env.exampl…...

架构师:如何提高web网站的请求并发响应量?
文章目录 一、提出问题二、相关概念三、如何提高网站请求响应能力?四、负载均衡有那些方式?五、常用微服务架构图及推荐书籍 一、提出问题 今天,突然想到一个问题,双十一,那些电商网站的并发量是多大? 简…...

图论基础--孤岛系列
孤岛系列有: 孤岛总面积求解(用了dfs、bfs两种方法)和沉没孤岛(这里只写了dfs一种) 简单解释一下: 题目中孤岛的定义是与边缘没有任何接触的(也就是不和二维数组的最外圈连接)&…...
Docker学习—Docker的安装与使用
Docker安装 1.卸载旧版 首先如果系统中已经存在旧的Docker,则先卸载: yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine2.配置Docker的yum库 首先…...

嵌入式按键事件处理框架:高可靠消抖与复合操作状态机
1. Button库深度解析:面向嵌入式系统的高可靠性按键事件处理框架1.1 设计定位与工程价值Button库并非简单的GPIO电平读取封装,而是一个面向工业级嵌入式应用的状态感知型按键事件引擎。其核心设计目标是解决传统按键处理中长期存在的三大工程痛点&#x…...

从逆向工程到实战:深度解析钉钉本地数据取证与加密对抗
1. 钉钉本地数据存储结构解析 第一次拆解钉钉的数据库文件时,我对着那堆加密的.sqlite文件发了半小时呆。作为国内用户量最大的企业通讯工具,钉钉在数据保护上确实下了狠功夫。Android和iOS两个平台的数据存储方式既有共性又存在微妙差异,这正…...

OpenClaw技能开发入门:为nanobot编写自定义QQ机器人插件
OpenClaw技能开发入门:为nanobot编写自定义QQ机器人插件 1. 为什么需要自定义OpenClaw技能 去年夏天,当我第一次接触OpenClaw时,就被它的自动化能力深深吸引。但很快发现,官方提供的技能虽然丰富,却无法满足我的特定…...

企业如何防御LockBit 3.0?从IOC到实战检测规则编写指南
企业级防御实战:LockBit 3.0勒索病毒全维度对抗指南 1. 勒索病毒威胁态势与企业防御挑战 2023年全球网络安全报告显示,勒索软件攻击同比增长47%,其中LockBit系列占比高达28%。不同于传统恶意软件,LockBit 3.0采用模块化设计&#…...

OpenClaw插件开发:为Qwen3.5-4B-Claude添加Excel处理能力
OpenClaw插件开发:为Qwen3.5-4B-Claude添加Excel处理能力 1. 为什么需要开发Excel处理插件 上周我需要处理一批销售数据报表时,突然意识到一个痛点:虽然Qwen3.5-4B-Claude模型在结构化分析上表现优异,但要让它真正帮我完成Excel…...

2026年各高校论文AI率新规汇总:双一流和普通院校标准差异
2026年各高校论文AI率新规汇总:双一流和普通院校标准差异 同一篇论文,知网52%,维普38%,万方21%。 为什么差这么多?不是平台乱搞,而是检测算法和判断标准不一样。理解了高校AI率新规背后的逻辑,…...

DownKyi如何成为B站视频下载的智能管家?8K高清+批量处理全解析
DownKyi如何成为B站视频下载的智能管家?8K高清批量处理全解析 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等…...

BULLM_ExtendMotor:8通道I²C电机驱动Arduino HAL库
1. 项目概述BULLM_ExtendMotor 是专为牛明工作室(BULLM Studio)8通道电机驱动扩展板设计的嵌入式控制库。该扩展板采用 IC 总线通信,集成 8 路独立可逆直流电机驱动通道,每通道支持 PWM 调速与方向控制,适用于多轴运动…...

Web3j区块链开发实战:Java开发者的以太坊交互指南
Web3j区块链开发实战:Java开发者的以太坊交互指南 【免费下载链接】web3j Lightweight Java and Android library for integration with Ethereum clients 项目地址: https://gitcode.com/gh_mirrors/we/web3j 1. 核心价值解析:Web3j为何成为Java…...

供应链需求预测系统:Granite TimeSeries FlowState R1助力库存优化
供应链需求预测系统:Granite TimeSeries FlowState R1助力库存优化 每次大促过后,仓库里总是一片狼藉。畅销品早早断货,客服电话被打爆;而另一堆商品却纹丝不动,占满了宝贵的库位,资金就这么被“冻”在了货…...