Python并发编程——multiprocessing
目录
- 1. 引言
- 1.1 并发与并行的区别
- 2. 多进程开发
- 2.1 `Process` 类的常用方法
- 2.2 进程的生命周期与同步
- 3. 进程之间的数据共享
- 3.1 使用 `Value` 和 `Array`
- 3.2 使用 `Manager` 实现高级数据共享
- 4. 进程锁
- 4.1 更复杂的锁应用
- 4.2 锁的死锁与避免
- 4.3 信号量与条件变量
- 5. 进程池
- 5.1 imap与starmap
- 5.2 apply与apply_async
1. 引言
在当今计算密集型应用和数据密集型任务中,高效的并发处理能力显得尤为重要。Python 提供了多种并发编程的方式来提升程序性能,其中 multiprocessing 模块作为一种基于多进程的并行处理方案,受到了广泛关注和使用。与多线程不同,multiprocessing 能够在多核处理器上真正实现并行执行,突破了 Python 中因全局解释器锁(GIL)限制而导致的并发瓶颈。因此,multiprocessing 模块在处理需要充分利用 CPU 计算能力的任务时尤其高效。
1.1 并发与并行的区别
要理解 Python multiprocessing 模块的优势,首先需要区分并发和并行这两个概念。并发是指在同一时间段内处理多个任务,这些任务并不一定是同时运行的,而是交替执行的,主要用于提高程序响应能力。相较之下,并行意味着在同一时刻同时执行多个任务,通常运行在不同的 CPU 核心上,可以显著提升计算性能。multiprocessing 模块旨在通过创建独立的进程来实现并行计算,从而让程序能够同时执行多个任务,最大限度地利用多核处理器的性能。
2. 多进程开发
Python 的 multiprocessing 模块提供了强大的多进程支持,使得开发者能够充分利用现代多核 CPU 的处理能力。通过 multiprocessing 模块,开发者可以轻松地创建和管理多个独立运行的子进程,从而显著提高程序的并发性能。不同于多线程开发,multiprocessing 通过在操作系统层面创建进程来避免全局解释器锁(GIL)的限制,因此更适合 CPU 密集型任务。
multiprocessing 中的 Process 类是创建和控制子进程的核心工具。开发者可以将目标函数和其参数传递给 Process 对象,并通过调用其方法来启动、控制和管理进程的执行。下面是一个简单的示例,展示了如何使用 Process 类来创建和启动一个进程:
import multiprocessing
import os
import timedef worker_function(name, duration):print(f'Process {name} (PID: {os.getpid()}) started.')time.sleep(duration) # 模拟耗时任务print(f'Process {name} (PID: {os.getpid()}) finished.')if __name__ == "__main__":# 创建一个进程对象,并指定目标函数和参数process = multiprocessing.Process(target=worker_function, args=('TestProcess', 3))process.start() # 启动进程process.join() # 等待进程结束print("Main process continues after child process.")
在这段代码中,Process 对象被创建并传入 worker_function 作为目标函数。args 参数用来指定传递给目标函数的参数。start() 方法用于启动该进程,进程会在后台运行,主进程不会等待它结束而是继续执行。如果需要等待子进程完成,开发者可以使用 join() 方法。join() 会阻塞主进程,直到子进程完成,这对于需要保证执行顺序的场景非常有用。
2.1 Process 类的常用方法
Process 类不仅提供了创建和启动进程的基础方法,还包含其他一些有用的方法和属性,帮助开发者更好地控制和管理进程。
start()方法用于启动进程。调用该方法后,操作系统会为进程分配内存空间并开始执行target指定的函数。join()方法用于让主进程等待子进程的结束。如果不调用join(),主进程会继续执行而不管子进程的状态。is_alive()方法返回一个布尔值,指示进程是否仍在运行。这对于在程序中动态检查进程状态非常有用。terminate()方法用于立即结束进程。它会向操作系统发送信号终止进程,可能导致进程未完成清理任务时被强行结束,因此应谨慎使用。pid属性返回当前进程的 PID(进程 ID),可以用来唯一标识一个进程。name属性用于获取或设置进程的名称,便于调试和日志记录。
以下是一个更复杂的示例,展示了如何使用这些方法和属性来管理和跟踪多个进程:
import multiprocessing
import os
import timedef worker_function(name, duration):print(f'Process {name} (PID: {os.getpid()}) started.')time.sleep(duration)print(f'Process {name} (PID: {os.getpid()}) finished.')if __name__ == "__main__":processes = []for i in range(3):process = multiprocessing.Process(target=worker_function, args=(f'Worker-{i}', 2 + i))process.name = f'CustomProcess-{i}'processes.append(process)process.start()# 检查所有进程状态for process in processes:print(f'{process.name} (PID: {process.pid}) is_alive: {process.is_alive()}')# 等待所有进程结束for process in processes:process.join()print("All child processes have finished.")
我们创建了三个子进程,并将它们添加到 processes 列表中。每个进程在启动后会输出其名称和 PID,然后执行一个模拟的耗时任务。主进程使用 is_alive() 方法来检查每个子进程的状态,并在所有子进程结束后继续执行。通过这种方式,开发者可以轻松地在程序中管理多个并发任务。
2.2 进程的生命周期与同步
在多进程编程中,了解进程的生命周期非常重要。每个 Process 对象都经历以下几个阶段:
-
新建 (New):在创建进程时使用
multiprocessing.Process()方法,进程会处于新建状态。此时,进程对象已被创建但尚未启动。 -
就绪 (Ready):当调用
start()方法时,进程进入就绪状态。此时,进程等待操作系统的调度分配资源以准备运行。 -
运行 (Running):当进程被操作系统调度并获得 CPU 执行权限时,进入运行状态,开始执行其目标函数。
-
阻塞 (Blocked):进程在运行时若需要等待资源或 I/O 操作,会进入阻塞状态。进程在此状态暂停执行,直到资源变得可用。
-
终止 (Terminated):当进程完成其任务或调用
terminate()方法时,进入终止状态,结束其生命周期,释放资源。
进程的同步问题是多进程开发中需要重点考虑的内容。当多个进程同时访问共享资源时,可能会出现数据不一致或竞态条件。为了解决这个问题,可以使用 multiprocessing 提供的锁机制。Lock 对象允许开发者在需要的地方进行同步,确保同一时刻只有一个进程能够访问共享资源。
import multiprocessingdef critical_section(lock, shared_list, item):with lock:shared_list.append(item)print(f'Item {item} added by {multiprocessing.current_process().name}')if __name__ == "__main__":lock = multiprocessing.Lock()manager = multiprocessing.Manager()shared_list = manager.list()processes = [multiprocessing.Process(target=critical_section, args=(lock, shared_list, i)) for i in range(5)]for p in processes:p.start()for p in processes:p.join()print("Final shared list:", list(shared_list))
我们创建了一个 Lock 对象并在多个进程中共享。当进程试图访问共享资源 shared_list 时,必须先获取锁,这样可以防止多个进程同时修改数据而导致的数据竞争问题。with lock: 确保锁在代码块执行完成后自动释放,从而实现了进程的同步。
3. 进程之间的数据共享
在多进程开发中,进程之间的数据共享是一个常见且重要的需求。由于每个进程都有自己独立的内存空间,因此在子进程之间共享数据需要借助一些特殊的工具。multiprocessing 模块提供了 Value 和 Array 这两种共享内存对象,使开发者能够在进程之间共享数据。
3.1 使用 Value 和 Array
Value 和 Array 是 multiprocessing 提供的两种基础共享内存对象。Value 允许不同进程共享单个值,而 Array 则用于共享一个数组。在创建这些对象时,需要指定数据类型代码,如 i 表示整数,d 表示双精度浮点数。
以下示例展示了如何在多个进程之间共享和修改数据:
from multiprocessing import Process, Value, Arraydef modify_data(val, arr):val.value += 1for i in range(len(arr)):arr[i] += 1if __name__ == "__main__":shared_val = Value('i', 0)shared_arr = Array('i', [0, 1, 2, 3])process = Process(target=modify_data, args=(shared_val, shared_arr))process.start()process.join()print("Value:", shared_val.value)print("Array:", list(shared_arr))
Value 和 Array 允许子进程访问和修改数据,并在主进程中查看修改结果。shared_val 是一个共享的整数值,shared_arr 是一个共享的整数数组。modify_data 函数中对它们进行了简单的加操作,并通过 process.join() 确保主进程在子进程完成后再输出最终结果。
3.2 使用 Manager 实现高级数据共享
除了 Value 和 Array,multiprocessing 还提供了 Manager 对象,用于实现更复杂的数据共享,如字典和列表。Manager 提供了高层次的接口,允许多个进程共享数据结构,如列表、字典等。
下面是一个简单示例,展示如何使用 Manager 实现共享列表的修改:
from multiprocessing import Process, Managerdef modify_shared_data(shared_list):shared_list.append('item')if __name__ == "__main__":with Manager() as manager:shared_list = manager.list()process = Process(target=modify_shared_data, args=(shared_list,))process.start()process.join()print("Shared list:", shared_list)
通过 Manager,我们可以创建一个共享的列表 shared_list 并传递给子进程进行修改。with Manager() as manager: 语句确保 Manager 对象在使用结束后自动释放资源。
4. 进程锁
在多进程开发中,数据竞争是开发者需要解决的一个重要问题。当多个进程同时访问和修改同一资源时,可能会导致数据不一致或出现不可预见的行为,特别是在涉及共享资源的情况下。这种现象被称为竞态条件,它会导致程序出现错误,难以复现和调试。为了防止数据竞争的发生,multiprocessing 模块提供了 Lock 对象,这是一种简单却非常有效的同步机制,能够确保在任意时刻,只有一个进程可以访问共享资源。
Lock 的概念类似于现实生活中的钥匙。只有持有锁的进程才能访问共享资源,而其他试图获取该资源的进程必须等待锁被释放后才能继续。通过这种方式,可以保证多个进程在访问共享数据时不会发生冲突。
使用 Lock 的方式非常直观。开发者可以使用 with 语句来简化代码,这样在使用锁的代码块执行完毕后,锁会自动释放。下面的示例展示了如何使用 Lock 来确保多个进程访问共享资源时的同步性:
from multiprocessing import Process, Lockdef print_with_lock(lock, text):with lock:print(text)if __name__ == "__main__":lock = Lock()processes = [Process(target=print_with_lock, args=(lock, f'Process {i}')) for i in range(5)]for p in processes:p.start()for p in processes:p.join()
每个子进程在执行 print_with_lock 函数时都会尝试获取锁。只有在锁被获取的情况下,print() 函数才会被执行,从而保证了输出的顺序性和一致性。通过 with lock: 语句,锁在使用后会被自动释放,这样其他等待的进程就可以继续运行,避免了因忘记释放锁而导致的死锁问题。
4.1 更复杂的锁应用
在某些情况下,开发者可能需要更复杂的同步控制。例如,当多个进程需要同时读取共享资源但只有在写操作时需要锁定资源时,就需要一种更加灵活的锁策略。Python 的 multiprocessing 模块不仅提供了简单的 Lock,还提供了其他高级锁机制,如 RLock(可重入锁)和 Semaphore(信号量)。
RLock 是一种可重入锁,允许同一个进程在持有锁的情况下多次获取锁而不会陷入死锁。它特别适用于递归调用的场景,当递归调用中需要多次获取锁时,普通的 Lock 会导致死锁,而 RLock 可以解决这个问题。以下是一个使用 RLock 的示例:
from multiprocessing import Process, RLockdef recursive_task(lock, depth):with lock:print(f'Depth {depth} acquired lock')if depth > 0:recursive_task(lock, depth - 1)if __name__ == "__main__":lock = RLock()process = Process(target=recursive_task, args=(lock, 3))process.start()process.join()
recursive_task 是一个递归函数,每次递归调用都会尝试获取锁。如果使用普通的 Lock,在第二次获取锁时会导致死锁。而使用 RLock,同一进程可以多次获取锁,从而顺利完成任务。
4.2 锁的死锁与避免
使用锁虽然能够避免数据竞争,但也会引入死锁的风险。死锁是一种常见的并发问题,当两个或多个进程彼此等待对方释放锁时,就会陷入死锁,导致程序无法继续执行。
要避免死锁,开发者需要遵循一些基本原则,比如避免嵌套获取锁或者使用超时参数来获取锁。例如,可以使用 acquire() 方法来尝试获取锁,并设置超时时间。如果在超时时间内未获取到锁,程序可以选择放弃或采取其他措施:
from multiprocessing import Process, Lock
import timedef safe_task(lock, name):if lock.acquire(timeout=2): # 尝试在2秒内获取锁try:print(f'Process {name} acquired the lock')time.sleep(1) # 模拟任务处理finally:lock.release()print(f'Process {name} released the lock')else:print(f'Process {name} could not acquire the lock')if __name__ == "__main__":lock = Lock()processes = [Process(target=safe_task, args=(lock, f'P{i}')) for i in range(3)]for p in processes:p.start()for p in processes:p.join()
每个进程在尝试获取锁时会等待最多 2 秒。如果超时仍未获取到锁,进程将放弃尝试并输出提示。这样可以防止进程陷入长时间等待,避免死锁的发生。
4.3 信号量与条件变量
除了锁机制,multiprocessing 模块还提供了 Semaphore 和 Condition 对象,以实现更复杂的进程同步。Semaphore 用于控制对共享资源的访问数量。例如,如果一个资源最多允许同时被两个进程访问,就可以用一个计数为 2 的信号量来控制。
Condition 对象则用于实现复杂的条件同步,可以让一个线程等待特定条件的满足后再继续执行。以下是一个使用 Semaphore 的示例,演示如何限制同时访问共享资源的进程数:
from multiprocessing import Process, Semaphore
import timedef limited_access_task(semaphore, name):with semaphore: # 获取信号量print(f'Process {name} is running')time.sleep(1)print(f'Process {name} has finished')if __name__ == "__main__":semaphore = Semaphore(2) # 最多允许两个进程同时访问processes = [Process(target=limited_access_task, args=(semaphore, f'P{i}')) for i in range(5)]for p in processes:p.start()for p in processes:p.join()
在这个例子中,同时只有两个进程能够进入 limited_access_task 中的临界区,确保了对共享资源的受控访问。
5. 进程池
在实际应用中,尤其是在需要处理大量任务的场景下,逐个创建和管理进程是一个耗时且不够高效的过程。multiprocessing 模块通过提供 Pool 类,使开发者能够更加高效地管理多个并发任务。使用 Pool,程序可以在后台自动管理进程的创建、销毁和任务分发,让开发者更专注于业务逻辑的实现。
Pool 类的核心思想是创建一个预定义数量的工作进程池,所有的任务都在这些进程中并行执行。当任务数量超过可用进程数时,Pool 会将多余的任务排队,待有空闲进程时再继续执行。这样,开发者无需手动跟踪每个进程的状态,从而简化了代码编写和维护。
在 multiprocessing.Pool 中,最常用的方法之一是 map()。map() 方法会将输入的可迭代对象中的每个元素传递给目标函数,并在多个进程中并行执行。以下示例展示了如何使用 map() 方法来并行计算一组数的平方:
from multiprocessing import Pooldef square(x):return x * xif __name__ == "__main__":with Pool(4) as pool: # 创建包含4个进程的进程池results = pool.map(square, [1, 2, 3, 4, 5])print("Squared results:", results)
在这个示例中,Pool 会根据指定的进程数(此处为 4)创建工作进程,并将输入数据 [1, 2, 3, 4, 5] 中的每个元素分配给其中的一个进程来进行计算。map() 会在所有任务完成后将结果以列表形式返回给主进程。
5.1 imap与starmap
除了 map() 方法,Pool 还提供了其他强大的方法来满足不同的需求。例如,当任务的分发和收集结果需要更精细的控制时,imap() 方法会更加合适。与 map() 不同,imap() 会以迭代器的形式返回结果,这样当结果生成时主进程可以立即消费,而无需等待所有任务结束。以下代码演示了如何使用 imap():
from multiprocessing import Pool
import timedef slow_square(x):time.sleep(1) # 模拟耗时任务return x * xif __name__ == "__main__":with Pool(4) as pool:for result in pool.imap(slow_square, [1, 2, 3, 4, 5]):print("Result received:", result)
在这个示例中,slow_square() 函数模拟了一个较为耗时的计算任务。imap() 方法在任务完成时会逐个返回结果,因此在每个结果生成后,主进程可以立即处理它。这样可以提高程序的响应速度,尤其在需要逐步处理结果的场景下非常实用。
starmap() 方法是 map() 的变体,它允许将多个参数传递给目标函数。对于接受多个参数的函数,starmap() 可以将输入解包后分配给目标函数。例如,有一个计算两数相加的函数,我们希望并行执行多个二元计算任务:
from multiprocessing import Pooldef add(a, b):return a + bif __name__ == "__main__":with Pool(4) as pool:results = pool.starmap(add, [(1, 2), (3, 4), (5, 6), (7, 8)])print("Addition results:", results)
starmap() 会将输入的每个元组 (a, b) 解包,并分别传递给目标函数 add(),从而实现对多个参数的并行处理。
5.2 apply与apply_async
如果需要在任务之间进行更灵活的控制,apply() 和 apply_async() 方法也非常有用。apply() 会阻塞主进程直到任务执行完成,而 apply_async() 则会异步执行任务并返回 AsyncResult 对象,该对象可以用于检查任务的状态或获取结果:
from multiprocessing import Pool
import timedef delayed_square(x):time.sleep(2)return x * xif __name__ == "__main__":with Pool(2) as pool:result = pool.apply_async(delayed_square, (4,))print("Task submitted.")# 检查任务是否完成while not result.ready():print("Waiting for result...")time.sleep(1)print("Result received:", result.get())
apply_async() 提交任务后会立即返回,而主进程可以继续执行其他任务或通过 ready() 方法检查任务的完成状态。通过 get() 方法可以获取任务结果并阻塞,直到结果可用为止。
相关文章:

Python并发编程——multiprocessing
目录 1. 引言1.1 并发与并行的区别 2. 多进程开发2.1 Process 类的常用方法2.2 进程的生命周期与同步 3. 进程之间的数据共享3.1 使用 Value 和 Array3.2 使用 Manager 实现高级数据共享 4. 进程锁4.1 更复杂的锁应用4.2 锁的死锁与避免4.3 信号量与条件变量 5. 进程池5.1 imap…...

智能家居的未来:AI让生活更智能还是更复杂?
内容概要 智能家居的概念源于将各种家居设备连接到互联网,并通过智能技术进行控制和管理。随着人工智能的迅速发展,这一领域也迎来了前所未有的机遇。从早期简单的遥控器到如今可以通过手机应用、语音助手甚至是环境感应进行操作的设备,智能…...
通信——TCP数据透传)
【物联网技术】ESP8266 WIFI模块在AP模式下作为TCP服务器与多个电脑/手机网络助手(TCP客户端)通信——TCP数据透传
前言:完成ESP8266 WIFI模块在AP模式下作为TCP服务器与多个电脑/手机网络助手(TCP客户端)通信——实现TCP数据透传 AP模式,通俗来说模块可以发出一个WIFI热点提供给电脑/手机连接。 TCP服务端,通俗来说就是模块/单片机作为服务器,可以接收多个客户通道的连接。 本…...

十五:java web(7)-- Spring Boot
目录 1. Spring Boot 简介 1.1 简介 1.2 Spring Boot 的特点 1.3 Spring Boot 和 Spring 的关系 2. Spring Boot 快速入门 2.1 创建第一个 Spring Boot 项目 3. Spring Boot 配置管理 3.1 application.properties 和 application.yml 配置 这两种都可以 好像现在更推荐…...

洛谷每日一题——P1036 [NOIP2002 普及组] 选数、P1045 [NOIP2003 普及组] 麦森数(高精度快速幂)
P1036 [NOIP2002 普及组] 选数 题目描述 [NOIP2002 普及组] 选数 - 洛谷 运行代码 #include <stdio.h> int n, k, a[25], t; int ss(int b) {int i;if (b < 2)return 0;for (i 2; i * i < b; i)if (b % i 0)return 0;return 1; } void dfs(int num, int sum, …...

OpenHarmony开源鸿蒙
OpenHarmony_百度百科 2024年4 月 1 日,开源鸿蒙 OpenHarmony 4.1 Release 版本于昨日发布,开发套件同步升级到 API 11 Release...

2024.11.4 STM32点灯和简单的数据收发
1.发送函数 HAL_StatusTypeDef HAL_UART_Transmit(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size, uint32_t Timeout); 参数1: UART 处理结构体的指针,该结构体包含了 UART 的所有配置参数。 参数2:要发送的数据指针 参数3&…...

Android Studio jcenter 停止服务,改用mavenCentral
随着jcenter在2021年2月28日停止服务,Android和Java开发者需寻找替代方案。推荐使用MavenCentral,可借助国内镜像加速。此外,jitpack.io也是一个选项,但对于大型项目,自建Nexus或MavenCentral更合适。迁移步骤包括更新…...

EasyPOI使用详解
EasyPOI 简介 easypoi功能如同名字easy,主打的功能就是容易,让一个没见接触过poi的人员 就可以方便的写出Excel导出,Excel模板导出,Excel导入,Word模板导出,通过简单的注解和模板 语言(熟悉的表达式语法),完成以前复杂的写法 文档:http://easypoi.mydoc.io/#categor…...

【云原生开发】K8S多集群资源管理平台架构设计
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

基于SpringBoot的城镇住房保障系统开发
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...
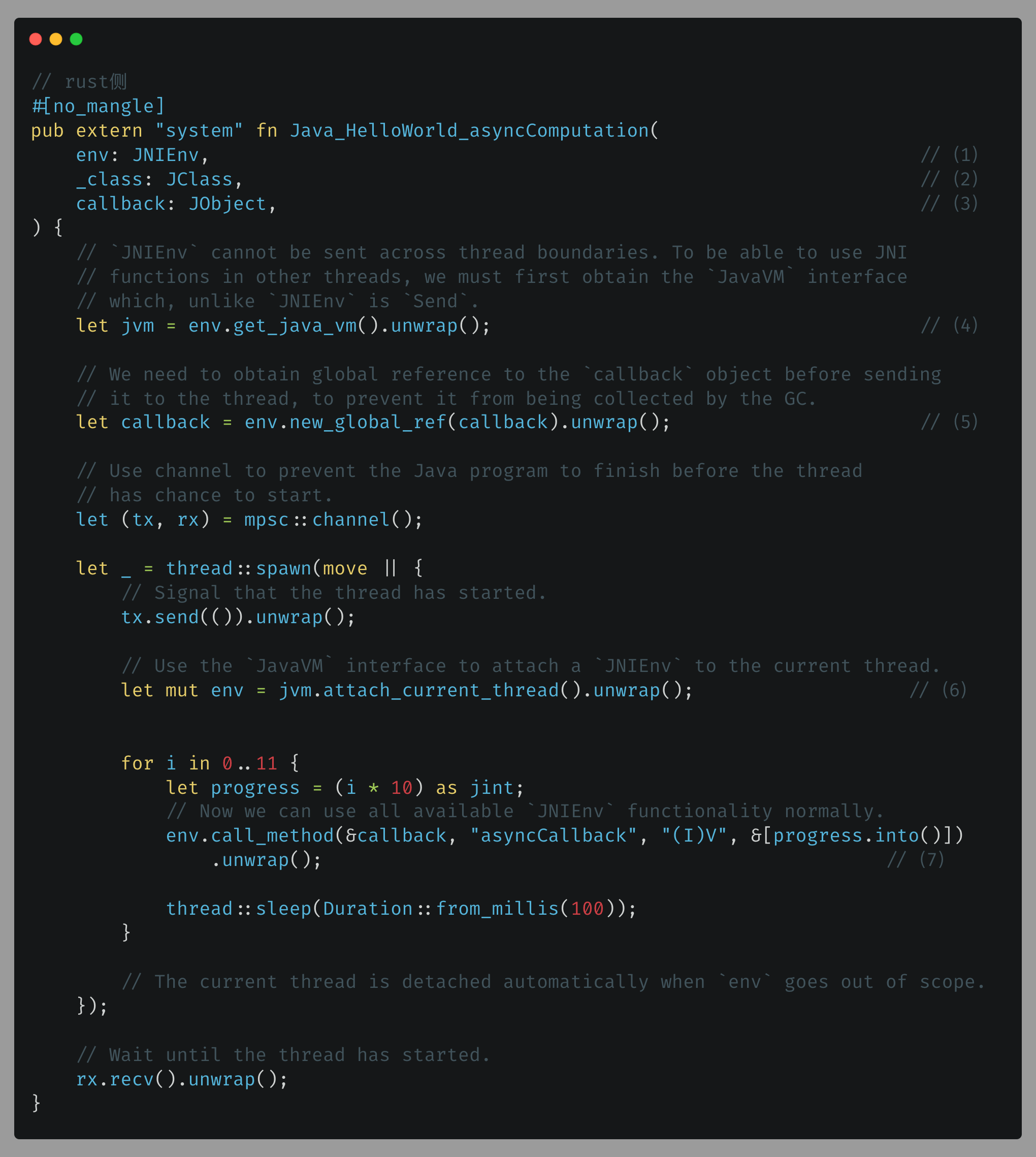
一文解秘Rust如何与Java互操作
本博客所有文章除特别声明外,均采用CC BY-NC-SA 4.0许可协议。转载请注明来自 唯你 使用场景 JAVA 与 Rust 互操作让 Rust 可以背靠 Java 大生态来做更多事情,而 Java 也可以享受 Rust 语言特性的内存安全,所有权机制,无畏并发。…...

手机发展史介绍
手机,这个曾经在电影和科幻小说中出现的高科技产品,如今已经渗透进了我们生活的每个角落。从单纯的通讯工具到如今集成了通讯、娱乐、工作、社交等多种功能的智能终端,手机的发展史也是人类科技进步的缩影。本文将从手机的发展历程、技术革新…...

【ArcGISPro】单次将自己建立的工具箱添加至Arcpy中
新建工具箱 添加至Arcpy中 调用刚添加的工具箱...

docker镜像仓库常用命令
docker镜像仓库常用命令 docker logindocker logoutdocker pulldocker pushdocker searchdocker imagesdocker image inspectdocker tagdocker rmidocker image prunedocker savedocker loaddocker history docker login 语法: docker login [options] [server] 功能ÿ…...

springboot 传统应用程序,适配云原生改造
概述 2024年传统应用程序上云,改造方案 1、mysql 云环境高可用方案 2、redis 云环境高可用方案 3、nginx 云环境高可用方案 4、应用 云环境高可用方案1、mysql 云环境高可用方案 1.1 你先了解 1.1.1 你先了解“mysql高可用方案” 主从复制(Master-S…...
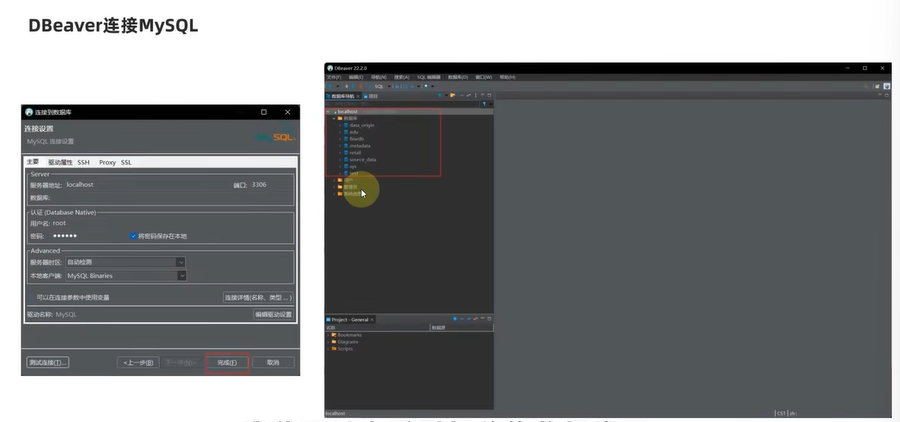
D61【python 接口自动化学习】- python基础之数据库
day61 数据库定义 学习日期:20241107 学习目标:MySQL数据库-- 130:MySQL入门使用 学习笔记: 在命令提示符内先试用MySQL 使用图形化工具操作MySQL DBeaver安装 DBeaver连接MySQL 总结 MySQL安装成功后,可以使用命…...

数据库期末考试简答题
1.试述数据、数据库、数据库管理系统、数据库系统的概念。 答:(1)数据是数据库中存储的基本对象,是描述事物的符号记录。数据有多种表现形式,它们都可以经过数字化后存入计算机。数据的种类有数字、文字、…...

Java[面试题]-真实面试
1.什么是IOC和AOP?了解么? IOC(控制反转)和AOP(面向切面编程) 1. IOC(控制反转) 概念 IOC(Inversion of Control)是面向对象编程中的一个设计原则…...

HTML5新增多媒体支持
一、引言 在当今数字化时代,丰富的多媒体内容对于网页的吸引力和用户体验至关重要。HTML5 的出现为网页带来了强大的多媒体支持,尤其是在音频和视频方面,为开发者和用户带来了全新的可能性。 二、音频audio标签 2.1 定义与属性详解 <a…...

华为BGP路由实战:从原理到策略调优的深度解析
1. 华为BGP路由技术入门指南 第一次接触华为BGP路由配置时,我被那些专业术语搞得晕头转向。经过多次实战后才发现,BGP就像互联网世界的邮局系统,负责在不同自治系统(AS)之间传递路由信息。华为设备的BGP实现特别适合企…...

把ESP-01S变成智能开关:51单片机+ESP8266的简易物联网项目实战
从零打造智能灯控系统:51单片机ESP-01S物联网实战指南 项目背景与核心思路 在智能家居领域,远程控制灯光是最基础却最实用的功能之一。传统方案往往需要购买成套的智能家居设备,成本高昂且灵活性不足。而借助51单片机和ESP-01S WiFi模块的组合…...

一款面向高清多媒体应用的高性价比解决方案
Hi-CHIP C3100是一款面向高清多媒体应用的高性价比解决方案。它集成了高性能32位RISC CPU与强大的多媒体处理系统,支持2K视频解码和显示,并提供丰富的外设接口。主要规格与特性特性类别具体规格CPU双核高性能32位RISC CPU,性能达2000 DMIPS&a…...

【GitHub热门工具】TikTokDownloader深度体验:从零到一的抖音/TikTok视频下载实战
1. 为什么我们需要TikTokDownloader? 最近在社交媒体上看到一个超有趣的视频,想保存下来反复观看或者分享给朋友,却发现平台没有提供下载按钮?这种场景相信很多人都遇到过。TikTokDownloader就是为了解决这个痛点而生的开源工具&a…...

告别FTP!用Go写的Filebrowser,一个命令搞定Windows/Linux跨平台文件管理
告别FTP!用Go语言构建的Filebrowser,一条命令实现全平台文件管理革命 在服务器管理和跨平台文件共享的日常工作中,传统FTP工具早已显露出诸多不便:复杂的客户端配置、不直观的界面操作、安全隐患频发。而现代开发者需要的…...

基于 HarmonyOS 6.0 的家政服务预约页面实战开发:ArkUI 页面构建与跨端设计深度解析
基于 HarmonyOS 6.0 的家政服务预约页面实战开发:ArkUI 页面构建与跨端设计深度解析 前言 随着 HarmonyOS 生态逐渐成熟,HarmonyOS NEXT 与 HarmonyOS 6.0 的持续推进,越来越多开发者开始从传统 Android、Flutter、Web 技术栈逐步迁移到鸿蒙原…...
的演进与实战选择)
从U盘到高端SSD:一文搞懂FTL映射表(块/页/混合)的演进与实战选择
从U盘到高端SSD:一文搞懂FTL映射表(块/页/混合)的演进与实战选择 存储设备的性能差异往往隐藏在底层算法的设计哲学中。当你在电商平台对比两款SSD时,是否思考过为什么同样标称1TB容量的产品,价格能相差数倍ÿ…...

完整 Ubuntu 服务器 XFCE 桌面 + XRDP 远程桌面 部署使用全流程
一、系统初始化 & 基础依赖安装bash# 更新系统sudo apt update && sudo apt upgrade -y# 安装必备依赖sudo apt install wget curl libfuse2 libxcb-xinput0 libxkbfile1 libssl-dev lrzsz -y二、安装 XFCE 轻量图形桌面bash# 完整安装XFCE桌面环境sudo apt instal…...
)
保姆级教程:用Unity+OpenCVSharp插件实现摄像头实时轮廓检测与交互(附完整C#代码)
Unity与OpenCVSharp实战:从摄像头捕捉到交互式轮廓检测全流程解析 在游戏开发与计算机视觉的交叉领域,实时图像处理正成为增强玩家沉浸感的新 frontier。想象一下:玩家只需在摄像头前挥动手势,游戏中的角色就能同步做出反应&#…...

2026年传统视频vs数字人效率对比:差距让很多老板震惊
2026年传统视频vs数字人效率对比:差距让很多老板震惊 【导语】 传统视频制作要7天,AI数字人只要3-5分钟?效率差距到底有多大?今天用真实数据说话。01 效率差距有多大?先看一组数据 很多人对AI数字人的效率提升没有概念…...