大模型的常用指令格式 --> ShareGPT 和 Alpaca (以 llama-factory 里的设置为例)
- ShareGPT 格式
提出背景:ShareGPT 格式起初来自于用户在社交平台上分享与聊天模型的对话记录,这些记录涵盖了丰富的多轮对话内容。研究者们意识到,这类真实的对话数据可以帮助模型更好地学习多轮对话的上下文保持、回应生成等能力。因此,ShareGPT 格式逐渐被用于多轮对话的指令微调。
目标:帮助模型理解复杂的多轮交互,提升模型的对话连贯性、上下文一致性和信息检索能力。
主要应用:ShareGPT 格式应用于需要模拟自然对话流的场景,例如聊天机器人、客服问答、陪伴式 AI 助手等。其设计结构支持用户与助手之间交替对话的记录,适合训练多轮对话模型。 - Alpaca 格式
提出背景:Alpaca 格式由斯坦福大学的研究人员在 2023 年提出,他们旨在通过一种低成本的方式对大型语言模型进行指令微调。Alpaca 项目使用 OpenAI 的 GPT-3.5 模型生成了大量指令数据,并采用简化的格式——instruction、input 和 output 字段——来表述单轮任务。这个结构化的指令-响应格式使模型可以专注于对特定任务的理解。
目标:Alpaca 格式的设计重点在于让模型理解明确的任务指令,以便模型在接到特定任务时能生成更精确的响应。
主要应用:Alpaca 格式被广泛应用于以任务为导向的指令微调任务中,尤其适合单轮任务(如总结、翻译、问答等),并不依赖多轮对话上下文,结构简洁且任务导向清晰。
总结
ShareGPT:适用于多轮对话微调,背景是对多轮自然对话数据的需求。
Alpaca:适用于单轮指令微调,背景是低成本的指令微调需求,通过简单的指令-响应结构实现任务定向训练。
dataset_info.json 包含了所有经过处理的 本地数据集 和 在线数据集。如果使用本地数据集, 务必在 dataset_info.json 中添加对应数据集及其内容的定义
目前支持 Alpaca 格式 和 ShareGPT 的格式
1.Alpaca
针对不同任务,数据集格式要求如下:
- 指令监督微调
- 预训练
- 偏好训练
- KTO
- 多模态
1.指令监督微调
-
样例如下

-
解释
-
instruction对应的内容是人类指令 -
input对应内容是人类输入 -
output对应内容是模型回答在进行指令监督微调时, instruction 列的内容会与 input 列对应内容拼接后作为最终人类的输入,即人类输入为
instruction\ninput。而output为模型回答 -
如果指定
system列,对应内容将被作为系统提示词 -
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意,在指令监督微调时,历史消息中的回答内容也会被用于模型学习
-
-
最终指令微调的格式要求如下
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]} ]-
样例如下
[{"instruction": "今天的天气怎么样?","input": "","output": "今天的天气不错,是晴天。","history": [["今天会下雨吗?","今天不会下雨,是个好天气。"],["今天适合出去玩吗?","非常适合,空气质量很好。"]]} ]
-
-
对于上述的数据,dataset_info.json 的数据集描述应为
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"} }
2.预训练数据
-
样例如下

-
大语言模型通过学习未被标记的文本进行预训练,从而学习语言的表征。通常,预训练数据集从互联网上获得,因为互联网上提供了大量的不同领域的文本信息,有助于提升模型的泛化能力。 预训练数据集文本描述格式如下:
[{"text": "document"},{"text": "document"} ] -
在预训练的时候,只有 text 列中的内容(document)会用于模型学习
-
对于上述数据,dataset_info.json 的数据集描述为
"数据集名称": {"file_name": "data.json","columns": {"prompt": "text"} }
3.偏好数据集
偏好数据集用于奖励模型训练、DPO训练 和 ORPO 训练。对于系统指令和人类输入,偏好数据集给出了一个更优的回答和一个更差的回答。
一些研究 表明通过让模型学习“什么更好”可以使得模型更加迎合人类的需求。 甚至可以使得参数相对较少的模型的表现优于参数更多的模型。
-
偏好数据集需要在 chosen 列中提供更优的回答,并在 rejected 中提供更差的回答,在一轮问答中,格式如下
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","chosen": "优质回答(必填)","rejected": "劣质回答(必填)"} ] -
dataset_info.json 的数据集描述为:
"数据集名称": {"file_name": "data.json","ranking": true,"columns": {"prompt": "instruction","query": "input","chosen": "chosen","rejected": "rejected"} }
DPO(Direct Preference Optimization)和 ORPO(Off-Policy Preference Optimization)是两种用于偏好优化的训练方法,主要用于提升语言模型对用户偏好的响应能力。它们在强化学习(RLHF, Reinforcement Learning with Human Feedback)框架下使用。
1. DPO(Direct Preference Optimization):
- 目标: 直接通过用户反馈优化模型输出的偏好,使模型更加符合用户的选择。
- 方法: 不使用强化学习的奖励建模,而是直接在训练数据中根据人类偏好来优化。通过给定两种生成结果,用户给出偏好,模型学习去优化自己生成更符合偏好的结果。
- 优点: 不依赖复杂的奖励函数设计,直接根据人类偏好进行优化,训练过程简单且高效。
- 适用场景: 适合场景是有明确的偏好数据并且希望快速迭代和调整模型的偏好输出。
2. ORPO(Off-Policy Preference Optimization):
- 目标: 在偏离当前策略的数据上,使用偏好信息优化模型,使其在长期上更加符合用户的期望。
- 方法: 利用“离线”策略的偏好反馈,通过基于强化学习的优化手段来调整模型。 ORPO 使用先前收集的数据进行优化,而不需要像 DPO 那样直接使用偏好进行梯度优化。它与 DPO 不同的是,模型可以在已经采集好的数据上进行偏好训练,不需要实时获取偏好反馈。
- 优点: 更适合在大规模历史数据上进行训练,训练更为稳健,可以更好地处理复杂的偏好优化问题。
- 适用场景: 适合有大量历史偏好数据的情况,尤其是难以获取实时偏好反馈的场景。
两者主要区别在于:
- DPO 是一种直接基于偏好梯度进行优化的策略,而 ORPO 通过强化学习的方式,在离线数据上进行优化。
4.KTO 数据集
KTO 数据集与偏好数据集类似,但不同于给出一个更优的回答和一个更差的回答,KTO 数据集对每一轮问答只给出一个 true/false 的 label。除了 instruction 以及 input 组成的人类最终输入和模型回答 output,KTO 数据集还需要一个额外的 kto_tag 列(true/false) 来表示人类反馈
-
一轮问答中的格式如下
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","kto_tag": "人类反馈 [true/false](必填)"} ] -
dataset_info.json"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","kto_tag": "kto_tag"} }
KTO 在这里指的是 “Knowledge Transfer Optimization”(知识迁移优化)相关的数据集。它用于优化模型在知识迁移过程中的能力,特别是在人机交互场景中,评估模型生成的答案是否符合人类的预期。
主要内容:
KTO 数据集不仅包含模型的生成结果,还包括人类的反馈,用来优化模型的响应能力。这种数据集设计类似于偏好优化数据集(Preference Optimization),但区别在于,KTO 不是让人类对两种回答进行排序,而是对每一轮问答通过 true/false 的标签直接评估模型的回答是否合格。
数据集结构:
- Instruction: 人类的指令或提问。
- Input: 人类最终的输入内容。
- Output: 模型生成的回答。
- kto_tag: 人类反馈(true/false),用于标注该模型的回答是否符合预期。
应用场景:
KTO 数据集特别适合用于模型优化,尤其是在模型需要从训练数据中学习如何更好地回应人类问题时。通过这种数据集,模型能够更高效地识别正确的反馈模式,从而提升在实际应用中的表现。这类数据集常用于大语言模型的强化学习阶段,用来替代复杂的奖励建模过程。
5.多模态数据集
多模态数据集需要额外添加一个 images 列,包含输入图像的路径。目前仅支持单张图像输入。
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","images": ["图像路径(必填)"]}
]
dataset_info.json 描述为
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","images": "images"}
}
2.ShareGPT 格式
Note:
- ShareGPT 格式中的 KTO数据集(样例)和多模态数据集(样例) 与 Alpaca 格式的类似。
- 预训练数据集不支持 ShareGPT 格式。
1.指令监督微调数据集
与 alpaca 格式相比,sharegpt 格式支持更多的角色种类,如 human、gpt、observation、function 等。他们构成一个对象列表呈现在 conversations 列中。
样例如下:
{"conversations": [{"from": "human","value": "你好,我出生于1990年5月15日。你能告诉我我今天几岁了吗?"},{"from": "function_call","value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"},{"from": "observation","value": "{\"age\": 31}"},{"from": "gpt","value": "根据我的计算,你今天31岁了。"}],"tools": "[{\"name\": \"calculate_age\", \"description\": \"根据出生日期计算年龄\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}
Note:
human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置
dataset_info.json 描述为
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","system": "system","tools": "tools"}
}
2.偏好数据集
与 alpaca 类似
{"conversations": [{"from": "human","value": "老虎会吃哪一个,草还是树叶?"}],"chosen": {"from": "gpt","value": "我很高兴能帮助你解答问题!不过,我必须指出,这个问题本身可能没有意义。老虎是食肉动物,通常不吃草或树叶。它们的饮食主要包括大型有蹄动物、小型哺乳动物和鸟类。\n\n如果你提出这个问题是出于好奇或有特定原因,我很乐意帮助你找到更多关于老虎饮食习惯的信息,或者建议资源让你更多了解这些壮丽的生物。请告诉我如何进一步协助你!"},"rejected": {"from": "gpt","value": "一只老虎是食肉动物,这意味着它的饮食主要是肉类。老虎主要猎捕和吃其他动物,如鹿和野猪。它们不会选择吃草或树叶,因为这些不是它们自然饮食的一部分。"}
}
格式如下
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "gpt","value": "模型回答"},{"from": "human","value": "人类指令"}],"chosen": {"from": "gpt","value": "优质回答"},"rejected": {"from": "gpt","value": "劣质回答"}}
]
dataset_info.json 的描述为
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","ranking": true,"columns": {"messages": "conversations","chosen": "chosen","rejected": "rejected"}
}
3.OpenAI 格式
OpenAI 格式仅仅是 sharegpt 格式的一种特殊情况,其中第一条消息可能是系统提示词
[{"messages": [{"role": "system","content": "系统提示词(选填)"},{"role": "user","content": "人类指令"},{"role": "assistant","content": "模型回答"}]}
]
dataset_info.json
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "messages"},"tags": {"role_tag": "role","content_tag": "content","user_tag": "user","assistant_tag": "assistant","system_tag": "system"}
}
相关文章:
大模型的常用指令格式 --> ShareGPT 和 Alpaca (以 llama-factory 里的设置为例)
ShareGPT 格式 提出背景:ShareGPT 格式起初来自于用户在社交平台上分享与聊天模型的对话记录,这些记录涵盖了丰富的多轮对话内容。研究者们意识到,这类真实的对话数据可以帮助模型更好地学习多轮对话的上下文保持、回应生成等能力。因此&…...

【论文阅读】火星语义分割的半监督学习
【论文阅读】火星语义分割的半监督学习 文章目录 【论文阅读】火星语义分割的半监督学习一、介绍二、联系工作3.1Deep Learning for Mars3.2 数据集可以分为三类:3.3 半监督学习 三、提出的火星图像分割数据集四、方法四、实验 S 5Mars: Semi-Supervised Learning …...
)
ACM社团第一次测试题解(禁止直接复制粘贴提交)
第一题:中位数 思路: 解法一:暴力比较,两个数之间一直比较得出中位数 解法二:快排函数,数组中间值即为中位数 代码: 1.c语言版: #include <stdio.h> int arr[10010]; vo…...

redis:zset有序集合命令和内部编码
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》《Linux》《网络》 《redis学习笔记》 文章目录 前言命令ZADDZRANGEZREVRANGEZCARDZCOUNTZPOPMAXBZPOPMAXZPOPMINBZPOPMINZRANKZSCOREZREMZREMRANGEBYRANKZREMRANGEBYSCOREZINCRBY集合间操作…...

Day107:代码审计-PHP模型开发篇MVC层RCE执行文件对比法1day分析0day验证
知识点: 1、PHP审计-MVC开发-RCE&代码执行 2、PHP审计-MVC开发-RCE&命令执行 3、PHP审计-MVC开发-RCE&文件对比 MVC 架构 MVC流程: Controller截获用户发出的请求;Controller调用Model完成状态的读写操作;Contr…...

Web服务nginx实验1访问特定目录
启动服务: 创建haha目录,并且在里面创建index.html文件,往里面写东西: 让客户端访问haha目录:(默认只会读取里面的index.html文件) 目录后面加/显示的是内容,不加则是代码࿱…...

数据结构之二叉树前序,中序,后序习题分析(递归图)
1.比较相同的树 二叉树不能轻易用断言,因为树一定有空 2.找结点值 3.单值二叉树 4.对称二叉树 5.前序遍历...
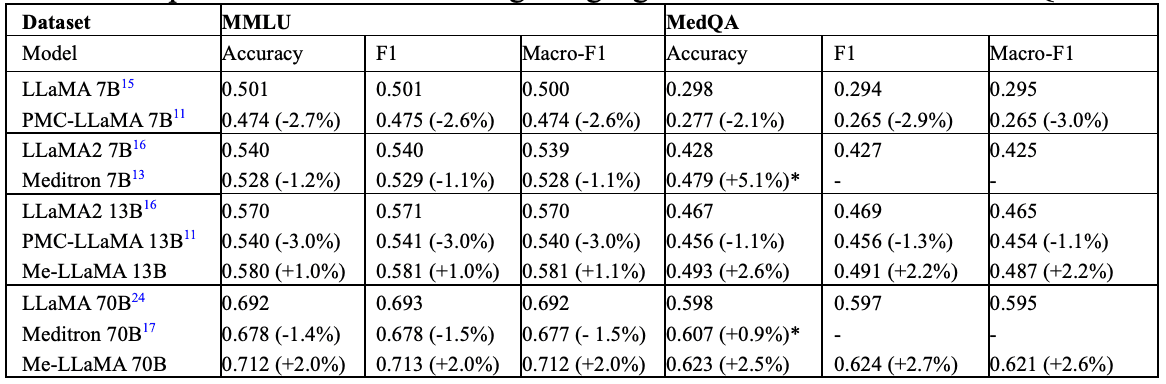
Me-LLaMA——用于医疗领域的新型开源大规模语言模型
摘要 大规模语言模型的出现是提高病人护理质量和临床操作效率的一个重大突破。大规模语言模型拥有数百亿个参数,通过海量文本数据训练而成,能够生成类似人类的反应并执行复杂的任务。这在改进临床文档、提高诊断准确性和管理病人护理方面显示出巨大的潜…...
C#-常见异常的处理方式(持续更新)
1、从网络位置加载程序集失败,默认不启用CAS策略 错误原因:使用 Assembly.LoadFile(dllPath) 加载外部Dll时,DotNET安全机制阻止加载一个本地网或互联网上的程序集。 解决方案: ①配置app.config文件,在runtime节点…...

「Mac玩转仓颉内测版2」入门篇2 - 编写第一个Cangjie程序
本篇详细介绍在Mac系统上创建首个Cangjie项目并编写、运行第一个Cangjie程序的全过程。内容涵盖项目创建、代码编写、程序运行与调试,以及代码修改后的重新运行。通过本篇,掌握Cangjie项目的基本操作,进一步巩固开发环境的配置,迈…...

注册登录学生管理系统小项目
头文件 #ifndef _LOGINLINK_H_ #define _LOGINLINK_H_ #include<myhead.h> typedef struct {int id;char name[20];int age; }stu,*Pstu; typedef struct node {union{int len;stu data;};struct node *next; }node,*Pnode; int regist(); int login(); Pnode create()…...

qt QCompleter详解
1、概述 QCompleter是Qt框架中的一个类,用于为文本输入提供自动完成功能。它可以与Qt的输入控件(如QLineEdit、QTextEdit等)结合使用,根据用户的输入实时过滤数据源,并在输入控件下方或内部显示补全建议列表。用户可以…...

YOLOv11融合特征细化前馈网络 FRFN[CVPR2024]及相关改进思路
YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程 一、 模块介绍 论文链接:Adapt or Rerish 代码链接:https://github.com/joshyZhou/AST 论文速览:基于 transformer 的方法在图像恢复任务中取得了有希望的性能,因为…...

【前端知识】JS模块规范
JS模块规范 概述CommonJS 规范 代码示例AMD 规范 代码示例ES6 Module 规范 代码示例IIFE 规范 代码示例全局变量 代码示例 CommonJS 模块和 ES6 模块有什么区别?1. 语法和声明方式2. 动态和静态导入3. 循环依赖4. 默认导出和命名导出5. 文件扩展名6. 环境和应用7. 工…...

vue3展示pag格式动态图
提示:如果是webpack环境的,参考:Pag格式在vue3中的简单使用方法_pag文件-CSDN博客 下面展示的是在vite环境下配置pag 1、安装libpag npm i libpag --save 2、安装rollup-plugin-copy npm i rollup-plugin-copy --save 3、封装pag组件 下…...

代码随想录算法训练营第三十九天|Day39 动态规划
198.打家劫舍 视频讲解:https://www.bilibili.com/video/BV1Te411N7SX https://programmercarl.com/0198.%E6%89%93%E5%AE%B6%E5%8A%AB%E8%88%8D.html 思路 #define max(a, b) ((a) > (b) ? (a) : (b)) int rob(int* nums, int numsSize) {if(numsSize 0){ret…...
qt QMovie详解
1、概述 QMovie 是 Qt 框架中用于处理动画文件的类。它支持多种动画格式,包括 GIF 和一些常见的视频格式(尽管对视频格式的支持依赖于底层平台)。QMovie 类主要用于在 QLabel 或 QGraphicsView 等控件中显示动画。通过加载动画文件ÿ…...

数据集整理
系列博客目录 文章目录 系列博客目录1.Visual Genome数据集2.COCO数据集3.Flickr30k数据集10.集合多个数据集的网站 1.Visual Genome数据集 官网链接:https://homes.cs.washington.edu/~ranjay/visualgenome/index.html Visual Genome数据集梳理 Visual Genome数据…...

认证授权基础概念详解
目录 认证 (Authentication) 和授权 (Authorization)的区别是什么? RBAC 模型了解吗? 什么是 Cookie ? Cookie 的作用是什么? 如何在项目中使用 Cookie 呢? 如何在 Spring Boot 中创建和读取 Cookie 创建 Cookie Cookie 到期日期 安全…...

美国地址生成器站点
推荐一:fakexy 官网地址:https://www.fakexy.com 推荐二:好维持官网地址: https://www.dizhishengcheng.com 官网除了支持生成美国地址信息外,还支持生成英国、加拿大、日朩、澳大利亚、德国、法国、意大利、西班牙、巴…...

信步SV3b-19016EP嵌入式主板深度解析:从选型到实战应用
1. 项目概述:为什么是SV3b-19016EP?在嵌入式系统开发这个行当里,选型永远是项目成败的第一步。最近几年,随着边缘计算、工业自动化、智能零售这些场景的爆发,大家对嵌入式主板的性能、接口丰富度和可靠性要求越来越高。…...

单片机代码优化实战:从数据类型到算法与数据结构的效率提升
1. 项目概述:为什么单片机代码需要“斤斤计较”?如果你是从PC端或者服务器端开发转过来的朋友,第一次接触单片机编程,可能会觉得处处掣肘。在PC上,我们习惯了动辄几个G的内存,上百G的硬盘,CPU频…...

TPFanCtrl2:ThinkPad智能风扇控制终极指南,彻底解决过热与噪音问题
TPFanCtrl2:ThinkPad智能风扇控制终极指南,彻底解决过热与噪音问题 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经在安静的会议室中…...

性能优化实战:在Unity项目里管理多个Video Player,如何避免内存泄漏和卡顿?
Unity多视频管理实战:规避内存泄漏与卡顿的深度优化策略 在沉浸式游戏体验和交互式AR/VR应用中,视频内容已成为提升用户参与度的关键要素。但当场景中同时存在多个Video Player组件时,开发者往往会遭遇突如其来的性能断崖——内存占用飙升、播…...

Taskbar11完全指南:解锁Windows 11任务栏自定义的终极解决方案
Taskbar11完全指南:解锁Windows 11任务栏自定义的终极解决方案 【免费下载链接】Taskbar11 Change the position and size of the Taskbar in Windows 11 项目地址: https://gitcode.com/gh_mirrors/ta/Taskbar11 还在为Windows 11任务栏的严格限制感到困扰吗…...

3步高效下载抖音无水印视频:douyin_downloader专业解决方案完整指南
3步高效下载抖音无水印视频:douyin_downloader专业解决方案完整指南 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader …...

3分钟搞定!Blender 3MF插件让你的3D打印工作流飞起来 [特殊字符]
3分钟搞定!Blender 3MF插件让你的3D打印工作流飞起来 🚀 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D打印文件格式转换头疼吗…...

SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅
SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾想过,一张普通的图片如何能变成一个会思考、会对话、…...

从家庭网络到公网:一次完整的HTTP请求,在Wireshark中看清NAT的“魔术”
从家庭网络到公网:一次完整的HTTP请求,在Wireshark中看清NAT的“魔术” 清晨的阳光透过窗帘洒在书桌上,你像往常一样打开笔记本电脑,在浏览器地址栏输入"www.baidu.com"并按下回车。这个看似简单的动作背后,…...

Rime中州韵小狼毫 配置文档层级与补丁机制全解析 新手避坑指南
1. Rime配置体系的双层结构揭秘 第一次打开Rime的配置文件时,很多人会被各种yaml文件搞得晕头转向。我刚开始用中州韵小狼毫时,就曾经把用户配置直接改到程序文件夹里,结果更新输入法后所有修改都被覆盖了。其实理解Rime的配置结构࿰…...