基于卷积神经网络的农作物病虫害识别系统(pytorch框架,python源码)
更多图像分类、图像识别、目标检测等项目可从主页查看
功能演示:
基于卷积神经网络的农作物病虫害检测(pytorch框架)_哔哩哔哩_bilibili
(一)简介
基于卷积神经网络的农作物病虫害识别系统是在pytorch框架下实现的,系统中有两个模型可选resnet50模型和VGG16模型,这两个模型可用于模型效果对比,增加工作量。
该系统涉及的技术栈有,UI界面:python + pyqt5,前端界面:python + flask
该项目是在pycharm和anaconda搭建的虚拟环境执行,pycharm和anaconda安装和配置可观看教程:
超详细的pycharm+anaconda搭建python虚拟环境_pycharm配置anaconda虚拟环境-CSDN博客
pycharm+anaconda搭建python虚拟环境_哔哩哔哩_bilibili
(二)项目介绍
1. 项目结构

2. 数据集

部分数据展示:

3.GUI界面(技术栈:pyqt5+python)


4.前端界面(技术栈:python+flask)


5. 核心代码
class MainProcess:def __init__(self, train_path, test_path, model_name):self.train_path = train_pathself.test_path = test_pathself.model_name = model_nameself.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")def main(self, epochs):# 记录训练过程log_file_name = './results/vgg16训练和验证过程.txt'# 记录正常的 print 信息sys.stdout = Logger(log_file_name)print("using {} device.".format(self.device))# 开始训练,记录开始时间begin_time = time()# 加载数据train_loader, validate_loader, class_names, train_num, val_num = self.data_load()print("class_names: ", class_names)train_steps = len(train_loader)val_steps = len(validate_loader)# 加载模型model = self.model_load() # 创建模型# 网络结构可视化x = torch.randn(16, 3, 224, 224) # 随机生成一个输入model_visual_path = 'results/vgg16_visual.onnx' # 模型结构保存路径torch.onnx.export(model, x, model_visual_path) # 将 pytorch 模型以 onnx 格式导出并保存# netron.start(model_visual_path) # 浏览器会自动打开网络结构# load pretrain weights# download url: https://download.pytorch.org/models/vgg16-397923af.pthmodel_weight_path = "models/vgg16-pre.pth"assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)model.load_state_dict(torch.load(model_weight_path, map_location='cpu'))# 更改Vgg16模型的最后一层model.classifier[-1] = nn.Linear(4096, len(class_names), bias=True)# 将模型放入GPU中model.to(self.device)# 定义损失函数loss_function = nn.CrossEntropyLoss()# 定义优化器params = [p for p in model.parameters() if p.requires_grad]optimizer = optim.Adam(params=params, lr=0.0001)train_loss_history, train_acc_history = [], []test_loss_history, test_acc_history = [], []best_acc = 0.0for epoch in range(0, epochs):# 下面是模型训练model.train()running_loss = 0.0train_acc = 0.0train_bar = tqdm(train_loader, file=sys.stdout)# 进来一个batch的数据,计算一次梯度,更新一次网络for step, data in enumerate(train_bar):images, labels = data # 获取图像及对应的真实标签optimizer.zero_grad() # 清空过往梯度outputs = model(images.to(self.device)) # 得到预测的标签train_loss = loss_function(outputs, labels.to(self.device)) # 计算损失train_loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新网络参数# print statisticsrunning_loss += train_loss.item()predict_y = torch.max(outputs, dim=1)[1] # 每行最大值的索引# torch.eq()进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回Falsetrain_acc += torch.eq(predict_y, labels.to(self.device)).sum().item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,train_loss)# 下面是模型验证model.eval() # 不启用 BatchNormalization 和 Dropout,保证BN和dropout不发生变化val_acc = 0.0 # accumulate accurate number / epochtesting_loss = 0.0with torch.no_grad(): # 张量的计算过程中无需计算梯度val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = model(val_images.to(self.device))val_loss = loss_function(outputs, val_labels.to(self.device)) # 计算损失testing_loss += val_loss.item()predict_y = torch.max(outputs, dim=1)[1] # 每行最大值的索引# torch.eq()进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回Falseval_acc += torch.eq(predict_y, val_labels.to(self.device)).sum().item()train_loss = running_loss / train_stepstrain_accurate = train_acc / train_numtest_loss = testing_loss / val_stepsval_accurate = val_acc / val_numtrain_loss_history.append(train_loss)train_acc_history.append(train_accurate)test_loss_history.append(test_loss)test_acc_history.append(val_accurate)print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, train_loss, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(model.state_dict(), self.model_name)# 记录结束时间end_time = time()run_time = end_time - begin_timeprint('该循环程序运行时间:', run_time, "s")# 绘制模型训练过程图self.show_loss_acc(train_loss_history, train_acc_history,test_loss_history, test_acc_history)# 画热力图self.heatmaps(model, validate_loader, class_names)该系统可以训练自己的数据集,训练过程也比较简单,只需指定自己数据集中训练集和测试集的路径,训练后模型名称和指定训练的轮数即可

训练结束后可输出以下结果:
a. 训练过程的损失曲线

b. 模型训练过程记录,模型每一轮训练的损失和精度数值记录

c. 模型结构

模型评估可输出:
a. 混淆矩阵

b. 测试过程和精度数值

c. 准确率、精确率、召回率、F1值

(三)总结
以上即为整个项目的介绍,整个项目主要包括以下内容:完整的程序代码文件、训练好的模型、数据集、UI界面和各种模型指标图表等。
整个项目包含全部资料,一步到位,省心省力
项目运行过程如出现问题,请及时交流!
相关文章:
基于卷积神经网络的农作物病虫害识别系统(pytorch框架,python源码)
更多图像分类、图像识别、目标检测等项目可从主页查看 功能演示: 基于卷积神经网络的农作物病虫害检测(pytorch框架)_哔哩哔哩_bilibili (一)简介 基于卷积神经网络的农作物病虫害识别系统是在pytorch框架下实现的…...
ETLCloud异常问题分析ai功能
在数据处理和集成的过程中,异常问题的发生往往会对业务运营造成显著影响。为了提高ETL(提取、转换、加载)流程的稳定性与效率,ETLCloud推出了智能异常问题分析AI功能。这一创新工具旨在实时监测数据流动中的潜在异常,自…...

【1】 Kafka快速入门-从原理到实践
文章目录 🔍 一、引言📜 二、Kafka 的历史🏗️ 三、Kafka 的核心结构🖥️ (一)Broker📋 (二)Topic📄 (三)Partition📤 (四)Producer📥 (五)Consumer🐒 (六)Zookeeper💡 四、Kafka 的重点概念📨 (一)消息📏 (二)偏移量(Offset)🔄 (…...

go语言中的map类型详解
在Go语言中,map是一种内建的数据结构,提供了键值对(key-value)的存储方式。map通常用于实现快速的查找和关联数组,适合在需要根据键来高效查找值的场景下使用。 基本概念 map是一个无序的集合,它存储了键…...

GBase 8a MPP Cluster V9安装部署
GBase 8a MPP Cluster V9安装部署 安装环境准备 节点角色操作系统地址配置GBASE版本gbase01.gbase.cnGCWARE,COOR,DATACentOS 7.9192.168.20.1422C4GGBase 8a MPP Cluster V9 9.5.3.28.12gbase02.gbase.cnGCWARE,COOR,DATACentOS 7.9192.168.20.1432C4GGBase 8a MPP Cluster …...

静态库、动态库、framework、xcframework、use_frameworks!的作用、关联核心SDK工程和测试(主)工程、设备CPU架构
1.1库的概念 库:程序代码的集合,编译好的二进制文件加上头文件供使用,共享程序代码的一种方式。 1.2库的分类 根据开源情况分为:开源库(能看到具体实现)、闭源库(只公开调用的的接口…...

C++ | Leetcode C++题解之第552题学生出勤记录II
题目: 题解: class Solution { public:static constexpr int MOD 1000000007;vector<vector<long>> pow(vector<vector<long>> mat, int n) {vector<vector<long>> ret {{1, 0, 0, 0, 0, 0}};while (n > 0) {…...

网站架构知识之Ansible(day020)
1.Ansible架构 Inventory 主机清单:被管理主机的ip列表,分类 ad-hoc模式: 命令行批量管理(使用ans模块),临时任务 playbook 剧本模式: 类似于把操作写出脚本,可以重复运行这个脚本 2.修改配置 配置文件:/etc/ansible/ansible.cfg 修改配置文件关闭主机Host_key…...

K8s使用nfs
改动点 ip和路径改为自己的 --- apiVersion: v1 kind: ServiceAccount metadata:name: nfs-client-provisioner# replace with namespace where provisioner is deployednamespace: nfs-client --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata:nam…...

【大数据学习 | kafka高级部分】kafka的kraft集群
首先我们分析一下zookeeper在kafka中的作用 zookeeper可以实现controller的选举,并且记录topic和partition的元数据信息,帮助多个broker同步数据信息。 在新版本中的kraft模式中可以这个管理和选举可以用kafka自己完成,而不再依赖zookeeper。…...

爬虫策略规避:Python爬虫的浏览器自动化
网络爬虫作为一种自动化获取网页数据的技术,被广泛应用于数据挖掘、市场分析、竞争情报等领域。然而,随着反爬虫技术的不断进步,简单的爬虫程序往往难以突破网站的反爬虫策略。因此,采用更高级的爬虫策略,如浏览器自动…...

Hive 实现查询用户连续三天登录记录
标题:Hive 实现查询用户连续三天登录记录 在数据分析和处理中,经常会遇到需要查询特定条件数据的情况。本文将介绍如何使用 Hive 来查询用户连续三天登录的所有数据记录。 一、问题背景 我们有一个用户登录记录表,其中包含用户的登录日期信…...

OceanBase 4.3.3 功能解析:列存副本
OceanBase 从4.3.0 版本开始,引入了列式存储的支持。用户可以根据业务的具体需求,选择创建列存表、行存表或是行列混存表。无论选择哪种表类型,在不同的Zone内,租户使用的副本模式都是一致的。详见官网文档: https://w…...

2.Python解释器
python解释器程序,用来翻译python代码,并提交给计算机执行。 上一篇博客就是安装了python解释器程序 写一个python文件,在文件中写入多行代码并执行: 进入python后,输入exit()命令退出...

鸿蒙与团结引擎c#与ts简单交互
目录 团结中调用ts代码 鸿蒙中调用团结代码 首先在团结创建代码,需要将代码添加到场景物体中 devecoStudio端编写ts代码 在index页面添加一个测试按钮 团结中调用ts代码 团结引擎 - 手册: Call TypeScript plug-in code from C# scripts 注册函数要跟文件名一致 在u…...

Any 的原理以及实现
序言 在 C17 的更新中引入了一个特别有意思的类型,它提供了一种通用的方式来存储任何类型的数据而不需要提前指定类型, 该类型就是 any。 any 允许你将任意类型的数据存储在一个容器中,并且能够在运行时动态地访问该数据。话不多说…...

SQLI LABS | Less-35 GET-Bypass Add Slashes (we dont need them) Integer Based
关注这个靶场的其它相关笔记:SQLI LABS —— 靶场笔记合集-CSDN博客 0x01:过关流程 输入下面的链接进入靶场(如果你的地址和我不一样,按照你本地的环境来): http://localhost/sqli-labs/Less-35/ 话不多说…...

RNN(循环神经网络)详解
1️⃣ RNN介绍 前馈神经网络(CNN,全连接网络)的流程是前向传播、反向传播和参数更新,存在以下不足: 无法处理时序数据:时序数据长度一般不固定,而前馈神经网络要求输入和输出的维度是固定的&a…...

【AI抠图整合包及教程】探索SAM 2:图像与视频分割领域的革新者
在人工智能的浩瀚星空中,Meta公司的Segment Anything Model 2(SAM 2)犹如一颗璀璨的新星,以其前所未有的图像与视频分割能力,照亮了计算机视觉领域的新航道。SAM 2不仅继承了其前身SAM在零样本分割领域的卓越表现&…...
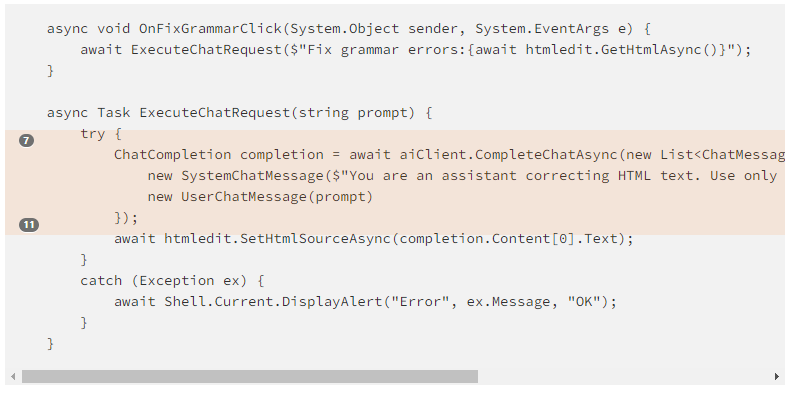
DevExpress中文教程 - 如何使用AI模型检查HTML编辑中的语法?
DevExpress .NET MAUI多平台应用UI组件库提供了用于Android和iOS移动开发的高性能UI组件,该组件库包括数据网格、图表、调度程序、数据编辑器、CollectionView和选项卡组件等。 目前许多开发人员正在寻找多种方法将AI添加到解决方案中(这通常比想象的要…...

鸿蒙 HarmonyOS 6.0 页面构建实践:跨端数字图书馆界面实现
鸿蒙 HarmonyOS 6.0 页面构建实践:跨端数字图书馆界面实现 前言 随着移动互联网和物联网的高速发展,跨端应用开发已成为现代软件开发的重要趋势。开发者不仅需要在手机端提供流畅的用户体验,还需要兼顾平板、电视等多终端的适配问题。在这样的…...

RCLI:统一AI开发环境的命令行工具设计与实战
1. 项目概述:一个面向AI应用开发的命令行利器如果你和我一样,经常在本地和云端服务器之间切换,调试各种AI模型,处理数据管道,那么你肯定对命令行(CLI)又爱又恨。爱的是它的高效和可编程性&#…...

ARM RealView开发套件实战指南与优化技巧
1. ARM RealView开发套件概述作为一名从事嵌入式开发多年的工程师,我深知一套优秀的开发工具对项目效率的影响。ARM RealView开发套件(RVDK)是ARM公司推出的专业级嵌入式开发解决方案,专为基于ARM架构的处理器设计。这套工具链在我…...

从零到一:手把手完成Keil5 MDK环境搭建与ST-LINK驱动配置
1. 开发环境搭建前的准备工作 第一次接触STM32开发的朋友们,看到各种专业术语可能会有点懵。别担心,我刚开始也是这样。咱们先理清几个基本概念:Keil MDK是ARM公司推出的专业嵌入式开发工具,ST-LINK则是ST官方推出的调试下载器。…...

智慧能耗管理系统:嵌入式工控机在工业节能中的核心应用
1. 工厂能耗管理的痛点与智能化转型契机 在制造业摸爬滚打十几年,我见过太多工厂在能耗管理上的“粗放式”经营。电费单是每个月固定的大额支出,但具体电用在了哪里,哪个车间、哪条产线、甚至哪台设备是“电老虎”,很多时候都是一…...

知识竞赛选手排位抽签系统使用全解析
🎲 知识竞赛选手排位抽签系统使用全解析公平 透明 高效 让每一场竞赛从起点就值得信赖🎯 引言:为何需要专业的抽签系统在知识竞赛活动中,选手的排位与分组抽签是确保竞赛公平、公正的起点。传统的人工抽签方式不仅效率低下&…...

Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器
Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器 在仓储巡检、展厅导览等场景中,机器人需要频繁执行多目标点任务序列。传统编程方式每次修改路径都需要重新编译代码,而Rviz的Publish Point功能配合定制化开发,可以将…...

在自动化工作流中集成Taotoken多模型聚合API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化工作流中集成Taotoken多模型聚合API 当开发者构建自动化脚本或智能体工作流时,一个常见的需求是能够灵活调用不…...

机器学习工作流编排利器:machiney-engine 轻量级流水线引擎详解
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫Reidston/machiney-engine。光看名字,你可能会觉得这又是一个“机器学习引擎”或者“AI框架”,市面上这类项目多如牛毛,从TensorFlow、PyTorch这样的巨头࿰…...

专业无人机日志分析工具:UAV Log Viewer 让飞行数据分析更简单高效
专业无人机日志分析工具:UAV Log Viewer 让飞行数据分析更简单高效 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer 无人机飞行日志分析是每个飞手和专业团队必须掌握的技能&a…...