大数据-214 数据挖掘 机器学习理论 - KMeans Python 实现 算法验证 sklearn n_clusters labels
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(正在更新…)
章节内容
上节我们完成了如下的内容:
- KMeans Python 实现
- 距离计算函数
- 质心函数
- 聚类函数

算法验证
函数编写完成后,先以 testSet 数据集测试模型运行效果(为了可以直观看出聚类效果,此处采用一个二维数据集进行验证)。testSet 数据集是一个二维数据集,每个观测值都只有两个特征,且数据之间采用空格进行分隔,因此可以使用 pd.read_table() 函数进行读取。
testSet = pd.read_table('testSet.txt', header=None)
testSet.head()
testSet.shape
执行结果如下图是:

然后利用二维平面图观察其分布情况:
plt.scatter(testSet.iloc[:,0], testSet.iloc[:,1]);
执行结果如下图所示:

可以大概看出数据大概分布在空间的四个角上,后续我们对此进行验证。然后利用我们刚才编写的 K-Means 算法对其进行聚类,在执行算法之前需要添加一列虚拟标签列(算法是从倒数第二列开始计算特征值,因此这里需要人为增加多一列到最后)
label = pd.DataFrame(np.zeros(testSet.shape[0]).reshape(-1, 1))
test_set = pd.concat([testSet, label], axis=1, ignore_index = True)
test_set.head()
执行结果如下图所示:

带入算法进行计算,根据二维平面坐标点的分布特征,我们可以考虑设置四个质心,即将其分为四个簇,并简单的查看运算结果:
test_cent, test_cluster = kMeans(test_set, 4)
test_cent
test_cluster.head()
执行结果如下图所示:

将分类结果进行可视化展示,使用 scatter 函数绘制不同分类点不同颜色的散点图,同时将质心也放入同一张图中进行观察:
import matplotlib.pyplot as plt# 绘制聚类点
plt.scatter(test_cluster.iloc[:, 0], test_cluster.iloc[:, 1], c=test_cluster.iloc[:, -1], cmap='viridis')# 绘制聚类中心
plt.scatter(test_cent[:, 0], test_cent[:, 1], color='red', marker='x', s=100)# 设置图形的标题和轴标签
plt.title('Cluster Plot with Centroids')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')# 显示图形
plt.show()执行结果如下图所示:

生成的图片如下所示:

sklearn实现 K-Means
from sklearn.cluster import KMeans# KMeans 初始化示例
kmeans = KMeans(n_clusters=8, # 聚类数量init='k-means++', # 初始化质心的方法n_init=10, # KMeans 算法重新运行的次数(初始质心选择不同)max_iter=300, # 最大迭代次数tol=0.0001, # 容忍度,控制收敛的阈值verbose=0, # 控制输出日志的详细程度random_state=None, # 随机种子控制聚类的随机性copy_x=True, # 是否复制 X 数据algorithm='auto' # 使用的 KMeans 算法,'auto' 已弃用,建议使用 'lloyd'
)# 执行示例数据集上的 KMeans
# 例如,假设你有一个数据集 X:
# kmeans.fit(X)n_clusters
n_clusters 是 K-Means 中的 k ,表示着我们告诉模型我们要分几类,这是 K-Means当中唯一一个必填的参数,默认为 8 类,但通常我们聚类结果是一个小于 8 的结果,通常,在开始聚类的之前,我们并不知道 n_clusters 究竟是多少,因此我们要对它进行探索。
当我们拿到一个数据集,如果可能的话,我们希望能够通过绘图先观察一下这个数据集的数据分布,以此来为我们聚类时输入的 n_clusters 做一个参考。
首先,我们来自己创建一个数据集,这样的数据集是我们自己创建的,所以是有标签的。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs# 创建数据集
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)# 可视化数据集
plt.figure(figsize=(6, 6))
plt.scatter(X[:, 0], X[:, 1], marker='o', s=8) # s=8 表示点的大小
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatter plot of generated blobs')
plt.show()对应结果如下图所示:

生成的图片如下所示:

查看分布的情况:
import matplotlib.pyplot as plt# 查看数据分布
color = ["red", "pink"]
for i in range(2): # 由于 y 只有 0 和 1 两类,因此只需要两个循环plt.scatter(X[y == i, 0], X[y == i, 1], marker='o', # 点的形状s=8, # 点的大小c=color[i]) # 颜色plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatter Plot of Two Classes')
plt.show()执行结果如下图所示:

对应的图片如下所示:

基于这个分布,我们来使用 K-Means 进行聚类。
首先,我们要猜测一下,这个数据中有几个簇?
cluster.labels
重要属性 labels_,查看聚好的类别,每个样本所对应的类
from sklearn.cluster import KMeans
from sklearn.datasets import load_breast_cancer
import numpy as np# 加载数据集
data = load_breast_cancer()
X = data.data# 定义聚类的簇数
n_clusters = 3# 使用KMeans进行聚类
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)# 获取聚类结果的标签
y_pred = cluster.labels_# 输出聚类的标签
print(y_pred)- K-Means 因此并不需要建立模型或者预测结果,因此我们只需要 fit 就能够得到聚类结果了
- K-Means 也有接口 predict 和 fit_predict
- predict 表示学习数据 X 并对 X 的类进行预测(对分类器 fit 之后,再预测)
- fit_predict 不需要分类器.fit()之后都可以预测
- 对于全数据而言,分类器 fit().predict 的结果 = 分类器.fit_predict(X) = cluster.labels
执行结果如下图所示:

我们什么时候需要 predict?当数据量太大的时候,当我们数据量非常大,我们可以使用部分数据来帮助我们确认质心。
剩下的数据的聚类结果,使用 predict 来调用:
cluster_smallsub = KMeans(n_clusters=3, random_state=0).fit(X[:200])
sample_pred = cluster_smallsub.predict(X)
y_pred == sample_pred
执行结果如下图所示:

但这样的结果,肯定与直接 fit 全部数据会不一致,有时候,当我们不要求那么精确,或者我们的数据量实在太大,那我们可以使用这样的做法。
相关文章:
大数据-214 数据挖掘 机器学习理论 - KMeans Python 实现 算法验证 sklearn n_clusters labels
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

算法通关(3) -- kmp算法
KMP算法的原理 从题目引出 有两个字符串s1和s2,判断s1字符串是否包含s2字符串,如果包含返回s1包含s2的最左开头位置,不包含返回-1,如果是按照暴力的方法去匹配,以s1的每个字符作为开头,用s2的整体去匹配,…...

5G网卡network connection: disconnected
日志 5G流程中没有报任何错误,但是重新拿地址了,感觉像是驱动层连接断开了,dmesg中日志如下: [ 1526.558377] ippassthrough:set [ ip10.108.40.47 mask27 ip_net10.108.40.32 router10.108.40.33 dns221.12.1.227 221.12.33.227] br-lan […...

微积分复习笔记 Calculus Volume 1 - 4.9 Newton’s Method
4.9 Newton’s Method - Calculus Volume 1 | OpenStax...

Flutter自定义矩形进度条实现详解
在Flutter应用开发中,进度条是一个常见的UI组件,用于展示任务的完成进度。本文将详细介绍如何实现一个支持动画效果的自定义矩形进度条。 功能特点 支持圆角矩形外观平滑的动画过渡效果可自定义渐变色可配置边框宽度和颜色支持进度更新动画 实现原理 …...

如何设置 TORCH_CUDA_ARCH_LIST 环境变量以优化 PyTorch 性能
引言 在深度学习领域,PyTorch 是一个广泛使用的框架,它允许开发者高效地构建和训练模型。为了充分利用你的 GPU 硬件,正确设置 TORCH_CUDA_ARCH_LIST 环境变量至关重要。这个变量告诉 PyTorch 在构建过程中应该针对哪些 CUDA 架构版本进行优…...

CSS的三个重点
目录 1.盒模型 (Box Model)2.位置 (position)3.布局 (Layout)4.低代码中的这些概念 在学习CSS时,有三个概念需要重点理解,分别是盒模型、定位、布局 1.盒模型 (Box Model) 定义: CSS 盒模型是指每个 HTML 元素在页面上被视为一个矩形盒子。…...

【笔记】前后端互通中前端登录无响应
后来的前情提要 : 后端的ip地址在本地测试阶段应该设置为localhost 前端中写cors的配置 后端也要写cors的配置 且两者的url都要为localhost 前端写的baseUrl是指定对应的后端的ip地址以及端口号 很重要 在本地时后端的IP的地址也必须为本地的 F12的网页报错是&a…...

AI引领PPT创作:迈向“免费”时代的新篇章?
AI引领PPT创作:迈向“免费”时代的新篇章? 在信息爆炸的时代,演示文稿(PPT)作为传递信息和展示观点的重要工具,其制作效率和质量直接关系到演讲者的信息传递效果。随着人工智能(AI)…...

HTB:Perfection[WriteUP]
目录 连接至HTB服务器并启动靶机 1.What version of OpenSSH is running? 使用nmap对靶机TCP端口进行开放扫描 2.What programming language is the web application written in? 使用浏览器访问靶机80端口页面,并通过Wappalyzer查看页面脚本语言 3.Which e…...

鸿蒙next打包流程
目录 下载团结引擎 添加开源鸿蒙打包支持 打包报错 路径问题 安装DevEcoStudio 可以在DevEcoStudio进行打包hap和app 包结构 没法直接用previewer运行 真机运行和测试需要配置签名,DevEcoStudio可以自动配置, 模拟器安装hap提示报错 安装成功,但无法打开 团结1.3版本新增工具…...

uni-app 实现自定义底部导航
原博:https://juejin.cn/post/7365533404790341651 在开发微信小程序,通常会使用uniapp自带的tabBar实现底部图标和导航,但现实有少量应用使用uniapp自带的tabBar无法满足需求,这时需要自定义底部tabBar功能。 例如下图的需求&am…...

Vue前端开发:animate.css第三方动画库
在实际的项目开发中,如果自定义元素的动画,不仅效率低下,代码量大,而且还存在浏览器的兼容性问题,因此,可以借助一些优秀的第三动画库来协助完成动画的效果,如animate.css和gsap动画库ÿ…...

Java中的I/O模型——BIO、NIO、AIO
1. BIO(Blocking I/O) 1. 1 BIO(Blocking I/O)模型概述 BIO,即“阻塞I/O”(Blocking I/O),是一种同步阻塞的I/O模式。它的主要特点是,当程序发起I/O请求(比如…...
)
【软考知识】敏捷开发与统一建模过程(RUP)
敏捷开发模式 概述敏捷开发的主要特点包括:敏捷开发的常见实践包括:敏捷开发的优势:敏捷开发的挑战:敏捷开发的方法论: ScrumScrum 的核心概念Scrum 的执行过程Scrum 的适用场景 极限编程(XP)核…...
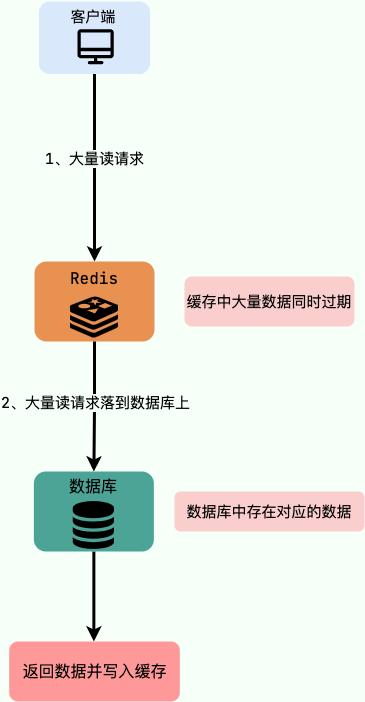
Redis常见面试题(二)
Redis性能优化 Redis性能测试 阿里Redis性能优化 使用批量操作减少网络传输 Redis命令执行步骤:1、发送命令;2、命令排队;3、命令执行;4、返回结果。其中 1 与 4 消耗时间 --> Round Trip Time(RTT,…...
业务模块部署
一、部署前端 1.1 window部署 下载业务模块前端包。 (此包为耐威迪公司发布,请联系耐威迪客服或售后获得) 包名为:业务-xxxx-business (注:xxxx为发布版本号) 此文件部署位置为:……...

【LeetCode】【算法】48. 旋转图像
LeetCode 48. 旋转图像 题目描述 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 思路 思路:再次拜见K神…...

【STM32F1】——9轴姿态模块JY901与串口通信(上)
【STM32F1】——9轴姿态模块JY901与串口通信(上) 一、简介 本篇主要对调试JY901模块的过程进行总结,实现了以下功能。 串口普通收发:使用STM32F103C8T6的USART2实现9轴姿态模块JY901串口数据的读取,并利用USART1发送到串口助手。 串口DMA收发:使用STM32F103C8T6的USART…...

Docker网络概述
1. Docker 网络概述 1.1 网络组件 Docker网络的核心组件包括网络驱动程序、网络、容器以及IP地址管理(IPAM)。这些组件共同工作,为容器提供网络连接和通信能力。 网络驱动程序:Docker支持多种网络驱动程序,每种驱动程…...

Ship-Score:自动化项目健康度评估工具的设计、实现与工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫cwklurks/ship-score。乍一看这个标题,你可能会有点摸不着头脑,这“ship-score”到底是个啥?是给船打分?还是某种评分系统?作为一个在软件开…...

基于LabVIEW与麦克风阵列的实时噪声源定位系统设计与实践
1. 项目概述:从“听见”到“看见”噪声在工业现场、产品研发或环境监测中,我们常常遇到一个棘手的问题:噪声到底是从哪里来的?传统的单点声压级测量只能告诉我们“这里有多吵”,却无法回答“是谁在吵”以及“它在哪里吵…...

如何快速下载Fansly内容:完整Fansly Downloader使用指南
如何快速下载Fansly内容:完整Fansly Downloader使用指南 【免费下载链接】fansly-downloader Easy to use fansly.com content downloading tool. Written in python, but ships as a standalone Executable App for Windows too. Enjoy your Fansly content offlin…...

蓝桥杯嵌入式:从零到一的考场环境搭建与避坑指南
1. 蓝桥杯嵌入式开发环境概述 参加蓝桥杯嵌入式比赛,环境搭建是第一个需要攻克的难关。很多同学第一次参赛时,往往把大量时间花在调试环境上,等到真正开始写代码时已经手忙脚乱。我在担任多届蓝桥杯志愿者时,见过太多选手因为环境…...

从ChatGPT插件到自主Agent工作流:2026年AI工具栈跃迁的4个关键断点及突破路径
更多请点击: https://codechina.net 第一章:2026年AI工具栈搭建完整指南 构建面向生产环境的AI工具栈,需兼顾前沿性、稳定性与可扩展性。2026年主流实践已从单点模型调用转向模块化、可观测、可编排的智能工作流基础设施。以下为推荐技术选型…...
——MS MARCO 实战指南)
IR 召回评测基准(英文数据集)——MS MARCO 实战指南
1. MS MARCO数据集全景解读 第一次接触MS MARCO时,我和大多数开发者一样困惑:这个号称"信息检索领域ImageNet"的数据集到底强在哪里?经过三个实际项目的验证,我发现它的价值在于完美复现了真实搜索场景的复杂性。想象你…...

如何高效管理光盘镜像:WinCDEmu虚拟光驱专业使用指南
如何高效管理光盘镜像:WinCDEmu虚拟光驱专业使用指南 【免费下载链接】WinCDEmu 项目地址: https://gitcode.com/gh_mirrors/wi/WinCDEmu WinCDEmu是一款功能强大的开源虚拟光驱软件,专为Windows系统设计,提供高效的光盘镜像挂载与管…...
是否足够)
现有基准任务(如操纵、导航)是否足够
在人工智能与机器人技术飞速迭代的今天,基准任务作为衡量模型与系统能力的核心标尺,贯穿于技术研发、性能评估与落地应用的全流程。操纵、导航作为两类最基础、最核心的基准任务,长期以来支撑着机器人、具身智能等领域的进步,成为…...

5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐
5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...
)
NotebookLM审稿意见回复全链路避坑清单,含8个高频雷区+对应话术库(限时开放2024最新版PDF)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM审稿意见回复全链路避坑清单导论 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,在学术协作与论文修订场景中展现出独特优势,但其在处理审稿意见回复时存在隐…...