书生浦语第四期基础岛L1G4000-InternLM + LlamaIndex RAG 实践
文章目录
- 一、任务要求1
- 1.首先创建虚拟环境
- 2. 安装依赖
- 3. 下载 Sentence Transformer 模型
- 4.下载 NLTK 相关资源
- 5. 是否使用 LlamaIndex 前后对比
- 6. LlamaIndex web
- 7. LlamaIndex+本地部署InternLM实践
一、任务要求1
任务要求1(必做,参考readme_api.md):基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力,截图保存。
1.首先创建虚拟环境
conda create -n llamaindex python=3.10
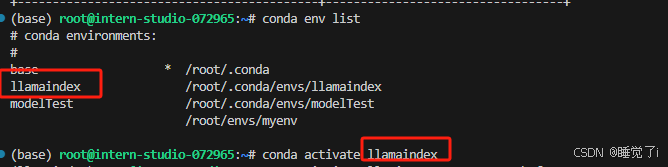
2. 安装依赖
需要注意镜像cuda的版本,这里使用的是12.2的版本,如果是11.7版本的可以使用这个替代
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia# 安装python 依赖包
pip install einops==0.7.0 protobuf==5.26.1
# 安装 Llamaindex和相关的包
pip install llama-index==0.11.20
pip install llama-index-llms-replicate==0.3.0
pip install llama-index-llms-openai-like==0.2.0
pip install llama-index-embeddings-huggingface==0.3.1
pip install llama-index-embeddings-instructor==0.2.1
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121
3. 下载 Sentence Transformer 模型
源词向量模型 Sentence Transformer
创建文件和python文件进行下载
这个embeding文本嵌入式模型用来处理文档转换成向量数据库进行检索的
注意安装路径,我这里是安装在 /root/llamaindex_demo/paraphrase-multilingual-MiniLM-L12-v2
git lfs install# 如果git lfs install 下面的报错 则执行git lfs install
#git: 'lfs' is not a git command. See 'git --help'.
#The most similar command is
apt-get install git-lfs
git lfs install
git clone https://www.modelscope.cn/Ceceliachenen/paraphrase-multilingual-MiniLM-L12-v2.git
4.下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。 我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
5. 是否使用 LlamaIndex 前后对比
5.1 不使用LlamaIndex
from openai import OpenAIbase_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
api_key = ''
model="internlm2.5-latest"# base_url = "https://api.siliconflow.cn/v1"
# api_key = "sk-请填写准确的 token!"
# model="internlm/internlm2_5-7b-chat"client = OpenAI(api_key=api_key,base_url=base_url,
)chat_rsp = client.chat.completions.create(model=model,messages=[{"role": "user", "content": "xtuner是什么?"}],
)for choice in chat_rsp.choices:print(choice.message.content)
输出:

5.2 使用LlamaIndex
获取知识库
cd ~/llamaindex_demo
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./
报错一:zipfile.BadZipFile: File is not a zip file
报错问题:缺少punkt_tab
解决方案:确保执行下面代码的时候NLTK_DATA已经跑完

结构目录是这样的:
如果缺少punkt_tab会报错,第一次执行一定要耐心等待NLTK_DATA下载完成
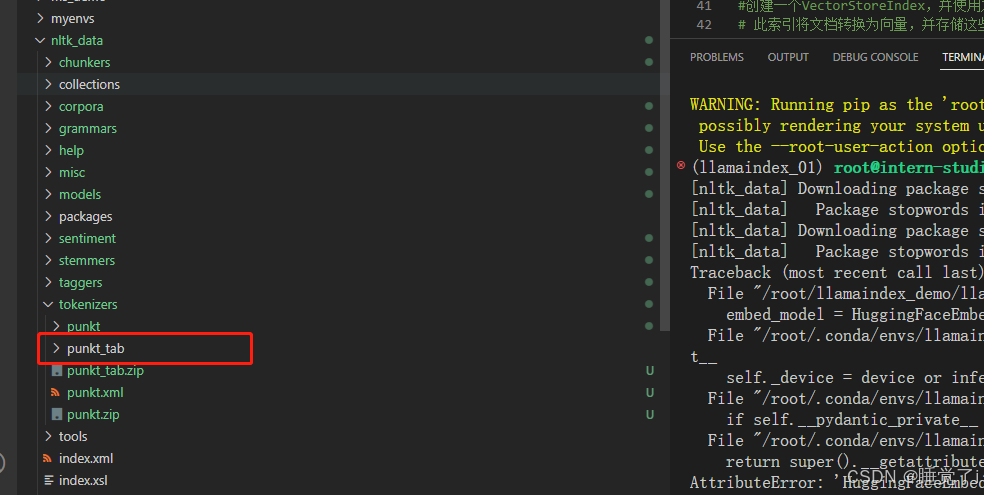
报错二:
AttributeError: 'HuggingFaceEmbedding' object has no attribute '__pydantic_private__'. Did you mean: '__pydantic_complete__'?
报错问题:pip install llama-index-embeddings-huggingface==0.3.1
解决方案:必须是0.3.1版本的
执行代码:
import os
os.environ['NLTK_DATA'] = '/root/nltk_data'from llama_index.core import Settings, SimpleDirectoryReader, VectorStoreIndex
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILikecallback_manager = CallbackManager()api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
api_key = "xxx"
model = "internlm2.5-latest"llm = OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)embed_model = HuggingFaceEmbedding(#指定了一个预训练的sentence-transformer模型的路径model_name="/root/llamaindex_demo/paraphrase-multilingual-MiniLM-L12-v2"
)
# 将创建的嵌入模型赋值给全局设置的embed_model属性,
# 这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
# 初始化llm
Settings.llm = llm
# 从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
# 创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
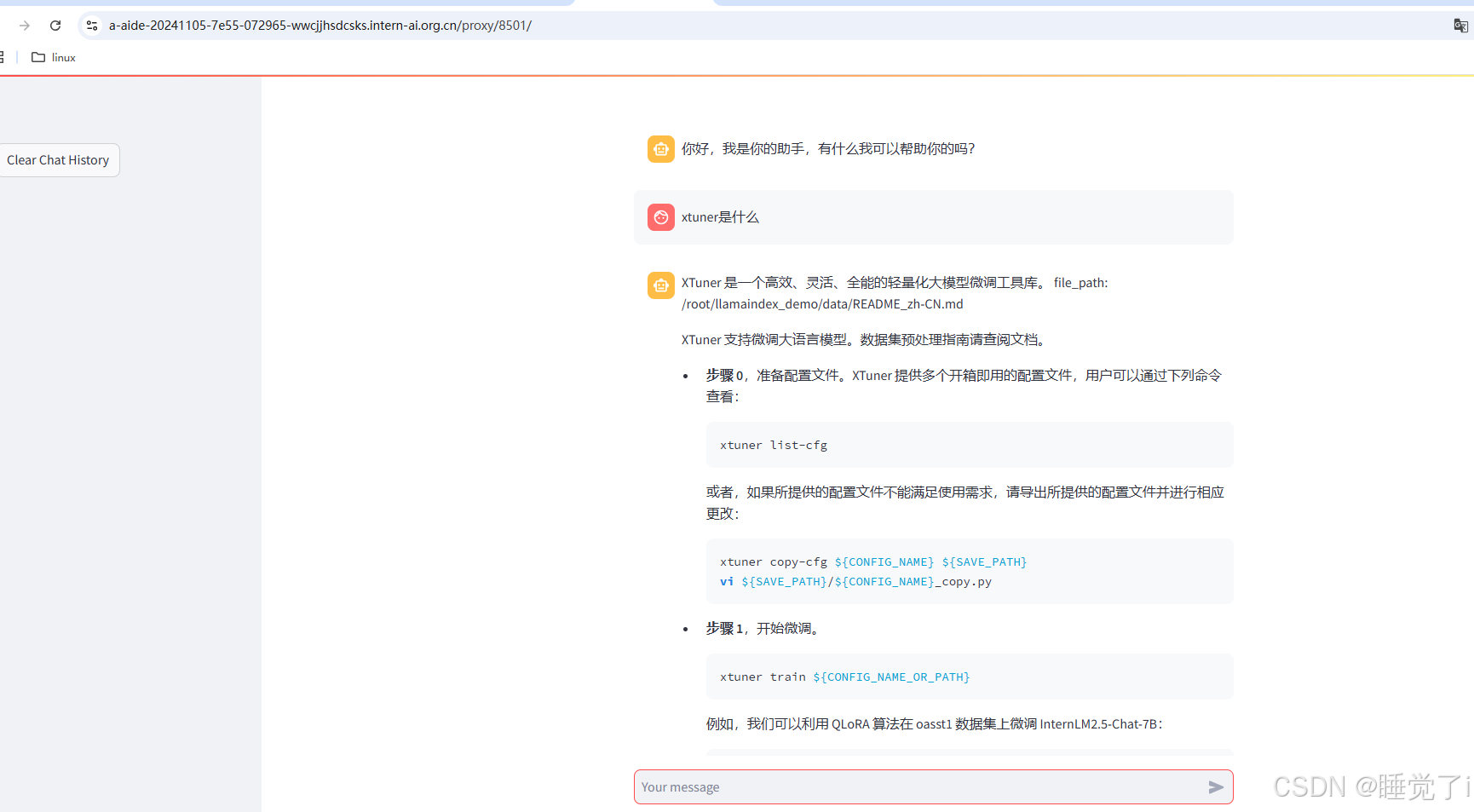
query_engine = index.as_query_engine()response = query_engine.query("xtuner是什么")print(response)
输出: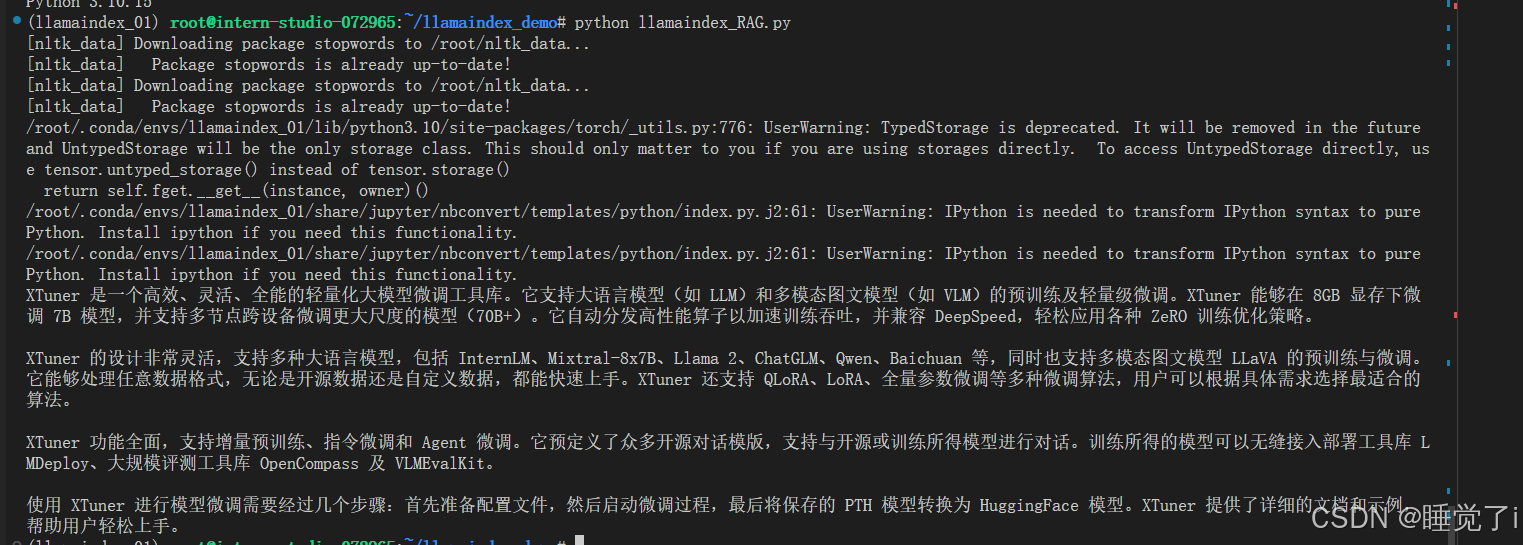
6. LlamaIndex web
运行之前首先安装依赖
pip install streamlit==1.39.0
运行以下指令,新建一个python文件
cd ~/llamaindex_demo
touch app.py
复制一下代码:
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike# Create an instance of CallbackManager
callback_manager = CallbackManager()api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = 'xxx'# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")# 初始化模型
@st.cache_resource
def init_models():embed_model = HuggingFaceEmbedding(model_name="/root/llamaindex_demo/paraphrase-multilingual-MiniLM-L12-v2")Settings.embed_model = embed_model#用初始化llmSettings.llm = llmdocuments = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()return query_engine# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:st.session_state['query_engine'] = init_models()def greet2(question):response = st.session_state['query_engine'].query(question)return response# Store LLM generated responses
if "messages" not in st.session_state.keys():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}] # Display or clear chat messages
for message in st.session_state.messages:with st.chat_message(message["role"]):st.write(message["content"])def clear_chat_history():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]st.sidebar.button('Clear Chat History', on_click=clear_chat_history)# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):return greet2(prompt_input)# User-provided prompt
if prompt := st.chat_input():st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.write(prompt)# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":with st.chat_message("assistant"):with st.spinner("Thinking..."):response = generate_llama_index_response(prompt)placeholder = st.empty()placeholder.markdown(response)message = {"role": "assistant", "content": response}st.session_state.messages.append(message)
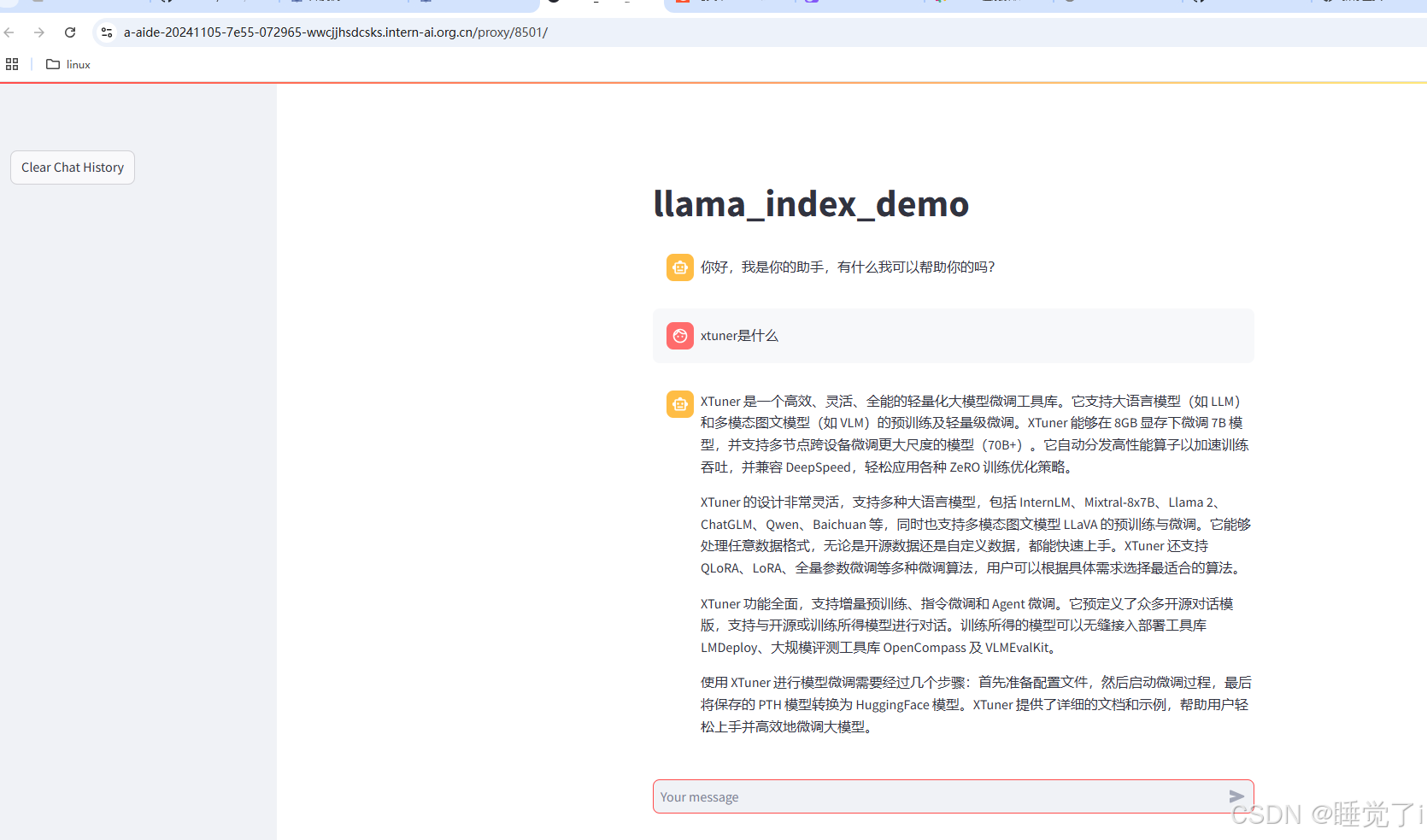
然后运行:
streamlit run app.py
ctrl+左键打开网址

测试:
7. LlamaIndex+本地部署InternLM实践
我们可以看到开发机上已经有下好的本地模型,我们只需要直接测试使用即可
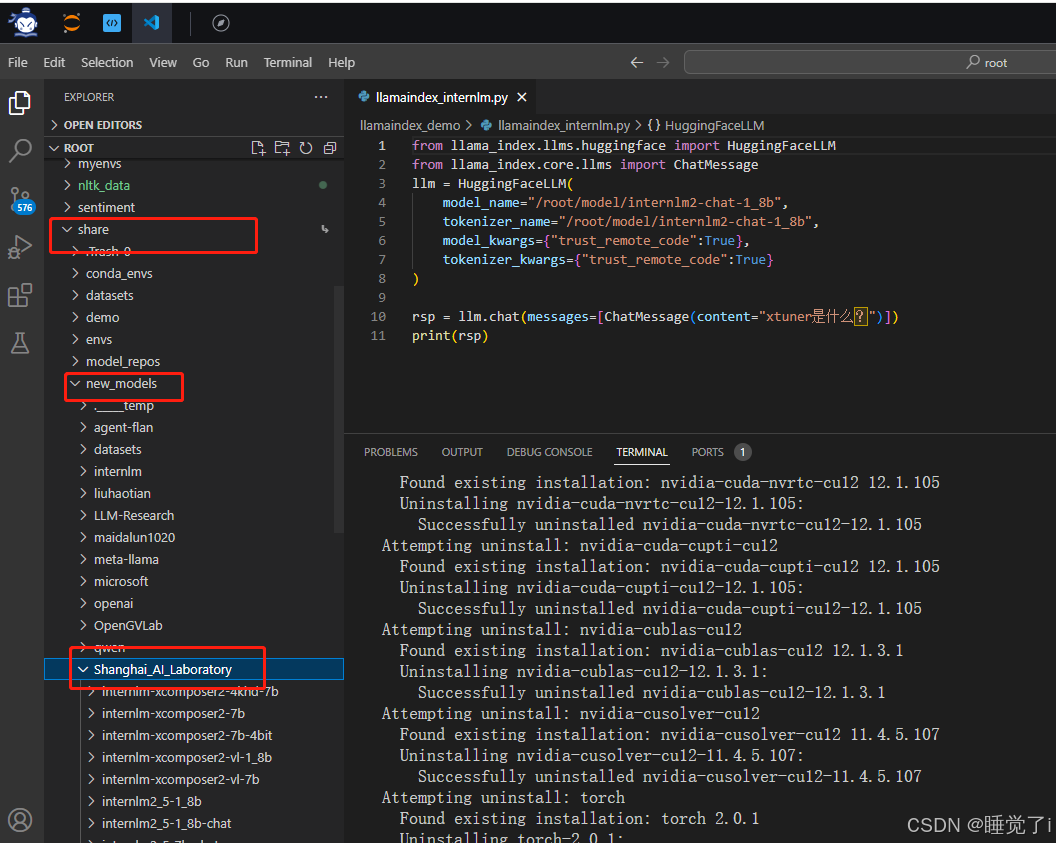
1.运行以下指令,把 InternLM2 1.8B 软连接出来
cd ~/model
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./
2.创建llamaindex_internlm.py文件
在这之前必须要确保以下命令安装完成 ,确定pytorch-cuda的版本修改为正确的版本。
pip install llama-index-embeddings-huggingface==0.2.0 llama-index-embeddings-instructor==0.1.3
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=12.1 -c pytorch -c nvidiafrom llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
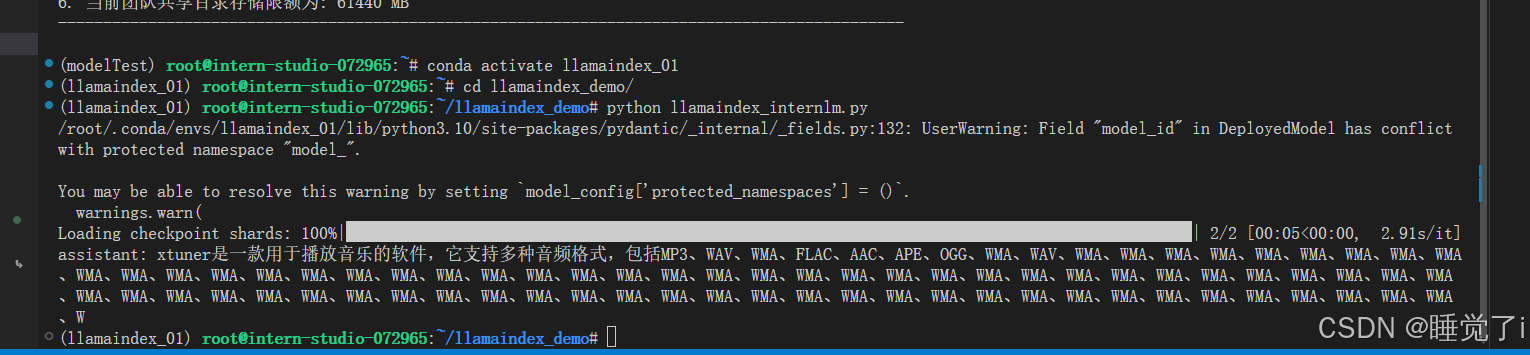
)rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")])
print(rsp)
3.运行结果
4.创建文件llamaindex_RAG_local.py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settingsfrom llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径pythmodel_name="/root/llamaindex_demo/paraphrase-multilingual-MiniLM-L12-v2"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
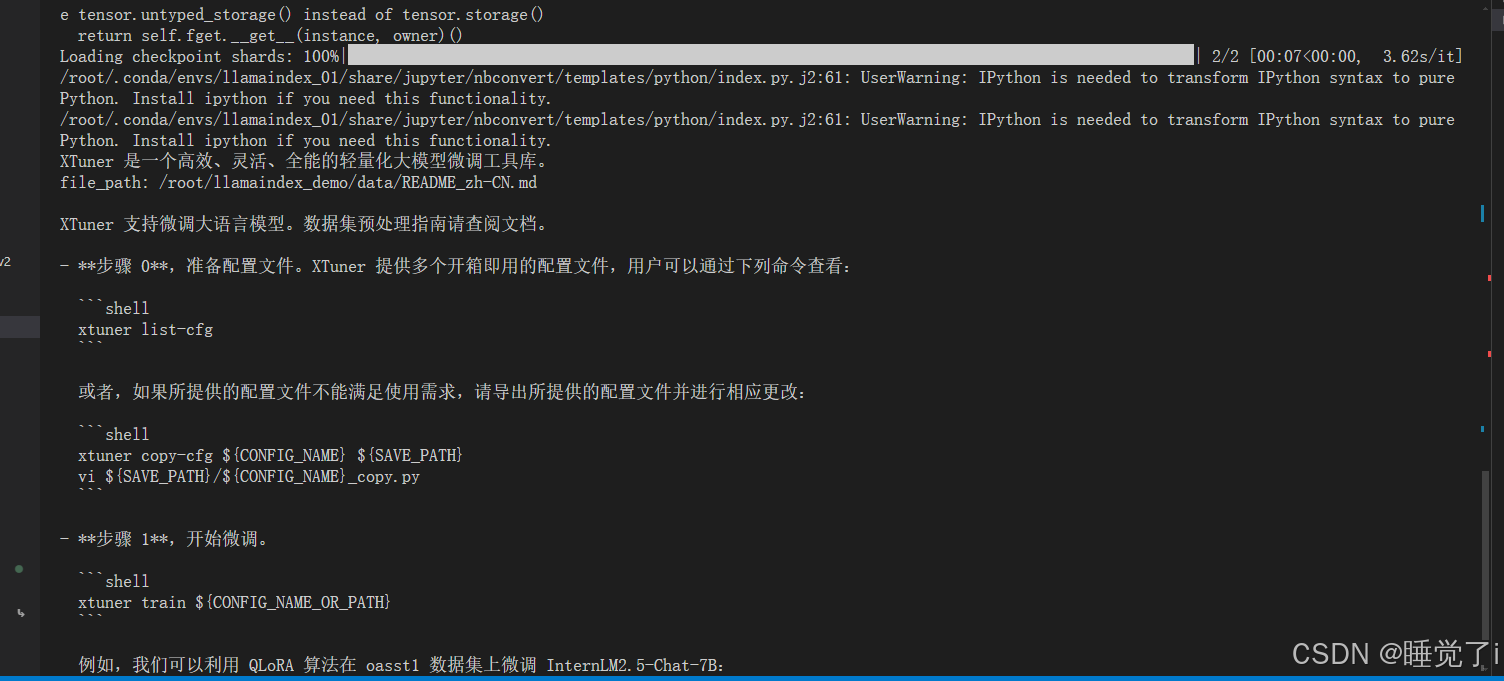
response = query_engine.query("xtuner是什么?")print(response)
5.运行结果:
6.创建app_local.py文件
插入代码:
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLMst.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")# 初始化模型
@st.cache_resource
def init_models():embed_model = HuggingFaceEmbedding(model_name="/root/llamaindex_demo/paraphrase-multilingual-MiniLM-L12-v2")Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True})Settings.llm = llmdocuments = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()return query_engine# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:st.session_state['query_engine'] = init_models()def greet2(question):response = st.session_state['query_engine'].query(question)return response# Store LLM generated responses
if "messages" not in st.session_state.keys():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]# Display or clear chat messages
for message in st.session_state.messages:with st.chat_message(message["role"]):st.write(message["content"])def clear_chat_history():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]st.sidebar.button('Clear Chat History', on_click=clear_chat_history)# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):return greet2(prompt_input)# User-provided prompt
if prompt := st.chat_input():st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.write(prompt)# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":with st.chat_message("assistant"):with st.spinner("Thinking..."):response = generate_llama_index_response(prompt)placeholder = st.empty()placeholder.markdown(response)message = {"role": "assistant", "content": response}st.session_state.messages.append(message)
7.运行 streamlit run app_loacl.py
相关文章:
书生浦语第四期基础岛L1G4000-InternLM + LlamaIndex RAG 实践
文章目录 一、任务要求11.首先创建虚拟环境2. 安装依赖3. 下载 Sentence Transformer 模型4.下载 NLTK 相关资源5. 是否使用 LlamaIndex 前后对比6. LlamaIndex web7. LlamaIndex本地部署InternLM实践 一、任务要求1 任务要求1(必做,参考readme_api.md&…...

基于ViT的无监督工业异常检测模型汇总
基于ViT的无监督工业异常检测模型汇总 论文1:VT-ADL: A Vision Transformer Network for Image Anomaly Detection and Localization(2021)1.1 主要思想1.2 系统框架 论文2:Inpainting Transformer for Anomaly Detection…...

数据库管理-第258期 23ai:Oracle Data Redaction(20241104)
数据库管理258期 2024-11-04 数据库管理-第258期 23ai:Oracle Data Redaction(20241104)1 简介2 应用场景与有点3 多租户环境4 特性与能力4.1 全数据编校4.2 部分编校4.3 正则表达式编校4.4 随机编校4.5 空值编校4.6 无编校4.7 不同数据类型上…...

运放进阶篇-多种波形可调信号发生器-产生方波-三角波-正弦波
引言:前几节我们已经说到硬件相关基础的电路,以及对于运放也讲到了初步的理解,特别是比较器的部分,但是放大器的部分我们对此并没有阐述,在这里通过实例进行理论结合实践的学习。而运放真正的核心,其实就是…...

CSS中的变量应用——:root,Sass变量,JavaScript中使用Sass变量
:root—— 原生CSS 自定义属性(变量) 在 SCSS 文件中定义 CSS 自定义属性。然后通过 JavaScript 读取这些属性。 // variables.scss :root { --login-bg-color: #293146;--left-menu-max-width: 200px;--left-menu-min-width: 64px;--left-menu-bg-…...

WPF+MVVM案例实战与特效(二十八)- 自定义WPF ComboBox样式:打造个性化下拉菜单
文章目录 1. 引言案例效果3. ComboBox 基础4. 自定义 ComboBox 样式4.1 定义 ComboBox 样式4.2 定义 ComboBoxItem 样式4.3 定义 ToggleButton 样式4.4 定义 Popup 样式5. 示例代码6. 结论1. 引言 在WPF应用程序中,ComboBox控件是一个常用的输入控件,用于从多个选项中选择一…...

速盾:怎么使用cdn加速?
CDN(Content Delivery Network)即内容分发网络,是一种通过在网络各处部署节点来缓存和传输网络内容的技术。通过使用CDN加速,可以提高网站的访问速度、减轻服务器负载、提供更好的用户体验。 使用CDN加速的步骤如下: …...

C++ 优先算法 —— 三数之和(双指针)
目录 题目:三数之和 1. 题目解析 2. 算法原理 ①. 暴力枚举 ②. 双指针算法 不漏的处理: 去重处理: 固定一个数 a 的优化: 3. 代码实现 Ⅰ. 暴力枚举(会超时 O(N)) Ⅱ.…...

YOLOv7-0.1部分代码阅读笔记-yolo.py
yolo.py models\yolo.py 目录 yolo.py 1.所需的库和模块 2.class Detect(nn.Module): 3.class IDetect(nn.Module): 4.class IAuxDetect(nn.Module): 5.class IBin(nn.Module): 6.class Model(nn.Module): 7.def parse_model(d, ch): 8.if __name__ __main__…...

【缓存与加速技术实践】Web缓存代理与CDN内容分发网络
文章目录 Web缓存代理Nginx配置缓存代理详细说明 CDN内容分发网络CDN的作用CDN的工作原理CDN内容的获取方式解决缓存集中过期的问题 Web缓存代理 作用: 缓存之前访问过的静态网页资源,以便在再次访问时能够直接从缓存代理服务器获取,减少源…...

MySQL的约束和三大范式
一.约束 什么是约束,为什么要用到约束? 约束就是用于创建表时,给对应的字段添加对应的约束 约束的作用就是当我们用insert into时,如果传入的数据有问题,不符合创建表时我们定的规定,这时MySQL就会自动帮…...

Unity网络通信(part7.分包和黏包)
目录 前言 概念 解决方案 具体代码 总结 分包黏包概念 分包 黏包 解决方案概述 前言 在探讨Unity网络通信的深入内容时,分包和黏包问题无疑是其中的关键环节。以下是对Unity网络通信中分包和黏包问题前言部分的详细解读。 概念 在网络通信中,…...

练习题 - DRF 3.x Overviewses 框架概述
Django REST Framework (DRF) 是一个强大的工具,用于构建 Web APIs。作为 Django 框架的扩展,DRF 提供了丰富的功能和简洁的 API,使得开发 RESTful Web 服务变得更加轻松。对于想要在 Django 环境中实现快速且灵活的 API 开发的开发者来说,DRF 是一个非常有吸引力的选择。学…...

Linux 经典面试八股文
快速鉴别十个题 1,你如何描述Linux文件系统的结构? 答案应包括对/, /etc, /var, /home, /bin, /lib, /usr, 和 /tmp等常见目录的功能和用途的描述。 2,在Linux中如何查看和终止正在运行的进程? 期望的答案应涵盖ps, top, htop, …...

Filter和Listener
一、Filter过滤器 1 概念 可以实现拦截功能,对于指定资源的限定进行拦截,替换,同时还可以提高程序的性能。在Web开发时,不同的Web资源中的过滤操作可以放在同一个Filter中完成,这样可以不用多次编写重复代码…...

Go 项目中实现类似 Java Shiro 的权限控制中间件?
序言: 要在 Go 项目中实现类似 Java Shiro 的权限控制中间件,我们可以分为几个步骤来实现用户的菜单访问权限和操作权限控制。以下是一个基本的实现框架步骤: 目录 一、数据库设计 二、中间件实现 三、使用中间件 四、用户权限管理 五…...

【Javascript】-一些原生的网页设计案例
JavaScript 网页设计案例 1. 动态时钟 功能描述:在网页上显示一个动态更新的时钟,包括小时、分钟和秒。实现思路: 使用 setInterval 函数每秒更新时间。获取当前时间并更新页面上的文本。 代码示例:<div id"clock"…...

SpringBoot开发——Spring Boot 3种定时任务方式
文章目录 一、什么是定时任务二、代码示例1、 @Scheduled 定时任务2、多线程定时任务3、基于接口(SchedulingConfigurer)实现动态更改定时任务3.1 数据库中存储cron信息3.2 pom.xml文件中增加mysql依赖3.3 application.yaml文件中增加mysql数据库配置:3.4 创建定时器3.5 启动…...

Flutter鸿蒙next 实现长按录音按钮及动画特效
在 Flutter 中实现长按录音按钮并且添加动画特效,是一个有趣且实用的功能。本文将通过实现一个具有动画效果的长按录音按钮,带领你一步步了解如何使用 Flutter 完成这个任务,并解释每一部分的实现。 一、功能需求 我们需要一个按钮…...

【计网】实现reactor反应堆模型 --- 框架搭建
没有一颗星, 会因为追求梦想而受伤, 当你真心渴望某样东西时, 整个宇宙都会来帮忙。 --- 保罗・戈埃罗 《牧羊少年奇幻之旅》--- 实现Reactor反应堆模型 1 前言2 框架搭建3 准备工作4 Reactor类的设计5 Connection连接接口6 回调方法 1 …...

从 API Key 管理与审计日志功能看 Taotoken 的企业级安全支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从 API Key 管理与审计日志功能看 Taotoken 的企业级安全支持 对于将大模型能力集成到业务流程中的企业而言,API 访问的…...

Ollama + Open WebUI部署教程:本地运行大语言模型,自建私有 AI 助手
Ollama Open WebUI部署教程:本地运行大语言模型,自建私有 AI 助手 不想把对话内容发给 OpenAI?有私密需求或离线场景?Ollama 让你在自己的服务器上运行 Llama、Qwen、DeepSeek 等开源大语言模型,Open WebUI 提供和 Ch…...

保姆级教程:在NVIDIA TX1上搞定万集WLR-716激光雷达的ROS驱动与RVIZ可视化
保姆级教程:在NVIDIA TX1上搞定万集WLR-716激光雷达的ROS驱动与RVIZ可视化 当机器人开发者第一次拿到万集WLR-716激光雷达和NVIDIA Jetson TX1开发板时,最迫切的需求就是快速搭建测试环境,验证硬件功能。本文将提供一份从零开始的详细指南&am…...

5分钟掌握猫抓扩展:浏览器视频下载终极指南
5分钟掌握猫抓扩展:浏览器视频下载终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到精彩的在线视频却无法下载保…...

手把手教你学Simulink——基于 PWM 加相移混合控制的双向 DC-DC 变换器仿真
目录 手把手教你学Simulink——基于 PWM 加相移混合控制的双向 DC-DC 变换器仿真 摘要 Abstract 1. 引言 1.1 研究背景 1.2 本文目标 2. 混合控制机理 2.1 拓扑选择:双有源桥(DAB) 2.2 混合控制自由度 3. Simulink 主电路建模 3.1…...

ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案
ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲&a…...

3D打印乐高手机支架:低成本打造高清视频会议摄像头方案
1. 项目概述与核心思路如果你和我一样,对视频会议、直播时笔记本自带摄像头那“感人”的画质感到无奈,同时又觉得单独购买一个高品质的网络摄像头是一笔不小的开销,那么这个项目绝对值得你花上一个周末的时间来折腾。它的核心思路非常巧妙&am…...

告别手动框选!用SUSTechPOINTS的V键批量标注,5分钟搞定一帧点云
解锁SUSTechPOINTS的V键批量标注:点云处理效率革命 在自动驾驶与机器人研发领域,点云标注是构建高精度感知模型的基础环节,但传统逐帧手动标注方式往往成为项目进度的瓶颈。我曾参与过一个城市级点云数据集标注项目,团队最初采用常…...

Rekall:基于时空查询的视频内容智能检索开源框架
1. 项目概述:Rekall,一个面向视频时空查询的开源利器 如果你曾经尝试过从一段长视频里,精准地找出“那个穿红色衣服的人从画面左侧走到右侧的片段”,或者想快速定位“所有出现这只特定宠物狗的镜头”,你就会知道这有多…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...