sklearn红酒数据集分类器的构建和评估
实验目的: 1. 掌握sklearn科学数据包中决策树和神经网络分类器的构建 2. 掌握对不同分类器进行综合评估
实验数据: 红酒数据集
红酒数据集利用红酒的化学特征来描述三种不同类型的葡萄酒。
实验内容与要求:
- 解压文件得到wine数据。利用pandas的read excel方法读取数据,注意保留数据的每一行数据。读取结束打印前两行
- 正确划分特征值矩阵X和分类目标向量y,打印数据大小(使用shape属性)
- 准备训练集和测试集(7:3)
- 利用sklearn构建神经网络分类器模型,在训练集上完成训练,观察在训练集、测试集上模型性能(如准确率、分类报告和混淆矩阵)。对参数进行调整,记录2组参数(例如不同隐藏层层数或大小设置)下的分类性能对比,讨论是否隐层数目越多越好。
- 准备决策树模型,在训练集上完成训练,对比决策树模型和神经网络的调试过程和训练结果,说明有何不同。
ModuleNotFoundError: No module named ‘sklearn’
pip install scikit-learn
1. 读取数据
用pandas的read excel方法读取wine.xlsx的数据,注意保留数据的每一行数据,读取结束打印前两行
import pandas as pd# df = pd.read_excel('wine.xlsx', nrows=2) # 读取wine.xlsx文件的前两行
# print(df) # 打印读取到的数据(显示数据帧内容)
data = pd.read_excel('wine.xlsx') # 读取Excel文件
print(data.head(2)) # 打印前2行数据
2. 划分数据
假设数据的最后一列是目标变量(分类目标),其余列是特征。
# 特征值和目标值的划分
X = data.iloc[:, :-1] # 去掉最后一列作为特征矩阵
y = data.iloc[:, -1] # 最后一列作为目标向量# 打印数据的大小
print('X shape:', X.shape) # X shape: (177, 13)
print('y shape:', y.shape) # y shape: (177,)
3. 准备训练集和测试集
使用sklearn的 train_test_split 方法进行数据划分,比例为7:3。
from sklearn.model_selection import train_test_split# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)print('Training set shape:', X_train.shape) # Training set shape: (123, 13)
print('Testing set shape:', X_test.shape) # Testing set shape: (54, 13)
4. 构建神经网络分类器模型
利用sklearn构建神经网络分类器模型,在训练集上完成训练,观察在训练集、测试集上模型性能(如准确率、分类报告和混淆矩阵)。对参数进行调整,记录2组参数(例如不同隐藏层层数或大小设置)下的分类性能对比,讨论是否隐层数目越多越好。
用scikit-learn的 MLPClassifier 构建神经网络分类器,并观察模型性能。
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 参数调整示例1
model1 = MLPClassifier(hidden_layer_sizes=(50,), max_iter=1000, random_state=42)
model1.fit(X_train, y_train)# 在训练集上预测
y_train_pred_1 = model1.predict(X_train)
# 在测试集上预测
y_test_pred_1 = model1.predict(X_test)# 结果评估
print('Model 1 - Training accuracy:', accuracy_score(y_train, y_train_pred_1))
print('Model 1 - Testing accuracy:', accuracy_score(y_test, y_test_pred_1))
print('Model 1 - Classification Report:\n', classification_report(y_test, y_test_pred_1))
print('Model 1 - Confusion Matrix:\n', confusion_matrix(y_test, y_test_pred_1))# 参数调整示例2
model2 = MLPClassifier(hidden_layer_sizes=(100, 50), max_iter=1000, random_state=42)
model2.fit(X_train, y_train)# 在训练集上预测
y_train_pred_2 = model2.predict(X_train)
# 在测试集上预测
y_test_pred_2 = model2.predict(X_test)# 结果评估
print('Model 2 - Training accuracy:', accuracy_score(y_train, y_train_pred_2))
print('Model 2 - Testing accuracy:', accuracy_score(y_test, y_test_pred_2))
print('Model 2 - Classification Report:\n', classification_report(y_test, y_test_pred_2))
print('Model 2 - Confusion Matrix:\n', confusion_matrix(y_test, y_test_pred_2))屏蔽FutureWarning等
import warnings
warnings.filterwarnings('ignore')
运行结果:


Model 1 - Training accuracy: 0.967479674796748
Model 1 - Testing accuracy: 0.018518518518518517
Model 1 - Classification Report:precision recall f1-score support278 0.00 0.00 0.00 0290 0.00 0.00 0.00 0342 0.00 0.00 0.00 1372 0.00 0.00 0.00 1378 0.00 0.00 0.00 0380 0.00 0.00 0.00 1385 0.00 0.00 0.00 1406 0.00 0.00 0.00 1407 0.00 0.00 0.00 1410 0.00 0.00 0.00 0415 0.00 0.00 0.00 0434 0.00 0.00 0.00 0438 0.00 0.00 0.00 0450 0.00 0.00 0.00 2463 0.00 0.00 0.00 0470 0.00 0.00 0.00 1480 0.00 0.00 0.00 1488 0.00 0.00 0.00 0495 0.33 1.00 0.50 1500 0.00 0.00 0.00 1502 0.00 0.00 0.00 1510 0.00 0.00 0.00 1515 0.00 0.00 0.00 2520 0.00 0.00 0.00 0550 0.00 0.00 0.00 1560 0.00 0.00 0.00 0562 0.00 0.00 0.00 2564 0.00 0.00 0.00 1570 0.00 0.00 0.00 1580 0.00 0.00 0.00 0600 0.00 0.00 0.00 1607 0.00 0.00 0.00 1620 0.00 0.00 0.00 1625 0.00 0.00 0.00 1630 0.00 0.00 0.00 1640 0.00 0.00 0.00 1660 0.00 0.00 0.00 0675 0.00 0.00 0.00 1680 0.00 0.00 0.00 2685 0.00 0.00 0.00 0695 0.00 0.00 0.00 0710 0.00 0.00 0.00 0718 0.00 0.00 0.00 1720 0.00 0.00 0.00 0735 0.00 0.00 0.00 0750 0.00 0.00 0.00 2760 0.00 0.00 0.00 1780 0.00 0.00 0.00 2795 0.00 0.00 0.00 0830 0.00 0.00 0.00 2840 0.00 0.00 0.00 0845 0.00 0.00 0.00 1880 0.00 0.00 0.00 1920 0.00 0.00 0.00 0970 0.00 0.00 0.00 1985 0.00 0.00 0.00 0990 0.00 0.00 0.00 11020 0.00 0.00 0.00 01035 0.00 0.00 0.00 01045 0.00 0.00 0.00 01065 0.00 0.00 0.00 11080 0.00 0.00 0.00 01095 0.00 0.00 0.00 11120 0.00 0.00 0.00 01130 0.00 0.00 0.00 11150 0.00 0.00 0.00 11190 0.00 0.00 0.00 11270 0.00 0.00 0.00 11280 0.00 0.00 0.00 11285 0.00 0.00 0.00 21320 0.00 0.00 0.00 01450 0.00 0.00 0.00 01480 0.00 0.00 0.00 11510 0.00 0.00 0.00 11515 0.00 0.00 0.00 1accuracy 0.02 54macro avg 0.00 0.01 0.01 54
weighted avg 0.01 0.02 0.01 54Model 1 - Confusion Matrix:[[0 0 0 ... 0 0 0][0 0 0 ... 0 0 0][0 0 0 ... 0 0 0]...[0 0 0 ... 0 0 0][0 0 0 ... 0 0 0][0 0 0 ... 0 0 0]]
Model 2 - Training accuracy: 1.0
Model 2 - Testing accuracy: 0.05555555555555555
Model 2 - Classification Report:precision recall f1-score support290 0.00 0.00 0.00 0325 0.00 0.00 0.00 0342 0.00 0.00 0.00 1345 0.00 0.00 0.00 0372 0.00 0.00 0.00 1378 0.00 0.00 0.00 0380 1.00 1.00 1.00 1385 0.00 0.00 0.00 1406 0.00 0.00 0.00 1407 0.00 0.00 0.00 1420 0.00 0.00 0.00 0428 0.00 0.00 0.00 0438 0.00 0.00 0.00 0450 0.00 0.00 0.00 2463 0.00 0.00 0.00 0470 0.00 0.00 0.00 1480 0.00 0.00 0.00 1495 0.50 1.00 0.67 1500 0.00 0.00 0.00 1502 0.00 0.00 0.00 1510 0.00 0.00 0.00 1515 0.00 0.00 0.00 2520 0.00 0.00 0.00 0550 0.00 0.00 0.00 1560 0.00 0.00 0.00 0562 0.00 0.00 0.00 2564 0.00 0.00 0.00 1570 0.00 0.00 0.00 1580 0.00 0.00 0.00 0600 0.00 0.00 0.00 1607 0.00 0.00 0.00 1620 0.00 0.00 0.00 1625 0.00 0.00 0.00 1630 0.00 0.00 0.00 1640 0.00 0.00 0.00 1660 0.00 0.00 0.00 0675 0.00 0.00 0.00 1680 0.00 0.00 0.00 2685 0.00 0.00 0.00 0695 0.00 0.00 0.00 0718 0.00 0.00 0.00 1720 0.00 0.00 0.00 0750 0.00 0.00 0.00 2760 0.00 0.00 0.00 1770 0.00 0.00 0.00 0780 0.00 0.00 0.00 2795 0.00 0.00 0.00 0830 0.00 0.00 0.00 2840 0.00 0.00 0.00 0845 0.00 0.00 0.00 1880 0.00 0.00 0.00 1970 0.00 0.00 0.00 1985 0.00 0.00 0.00 0990 0.00 0.00 0.00 11035 0.00 0.00 0.00 01050 0.00 0.00 0.00 01060 0.00 0.00 0.00 01065 0.00 0.00 0.00 11080 0.00 0.00 0.00 01095 0.00 0.00 0.00 11120 0.00 0.00 0.00 01130 0.00 0.00 0.00 11150 1.00 1.00 1.00 11190 0.00 0.00 0.00 11270 0.00 0.00 0.00 11280 0.00 0.00 0.00 11285 0.00 0.00 0.00 21295 0.00 0.00 0.00 01375 0.00 0.00 0.00 01450 0.00 0.00 0.00 01480 0.00 0.00 0.00 11510 0.00 0.00 0.00 11515 0.00 0.00 0.00 11547 0.00 0.00 0.00 0accuracy 0.06 54macro avg 0.03 0.04 0.04 54
weighted avg 0.05 0.06 0.05 54Model 2 - Confusion Matrix:[[0 0 0 ... 0 0 0][0 0 0 ... 0 0 0][0 0 0 ... 0 0 0]...[0 0 0 ... 0 0 0][0 0 0 ... 0 0 0][0 0 0 ... 0 0 0]]
讨论:
记录了两组不同的参数下的分类性能。
- 模型1:使用一个隐藏层,包含50个神经元。
- 模型2:使用两个隐藏层,分别包含100和50个神经元。
通过对比可以发现:通常,更复杂的模型(更多的隐层和神经元)能够捕捉数据中的更多特征,但也可能导致过拟合。因此,在选用模型时需要进行适当的验证,观察在测试集上的表现,并合理选择模型的复杂度。
5. 构建决策树模型
准备决策树模型,在训练集上完成训练,对比决策树模型和神经网络的调试过程和训练结果,说明有何不同。
接下来,使用决策树进行分类,并对比其与神经网络的性能。
from sklearn.tree import DecisionTreeClassifier# 决策树模型
tree_model = DecisionTreeClassifier(random_state=42)
tree_model.fit(X_train, y_train)# 在训练集上预测
y_train_pred_tree = tree_model.predict(X_train)
# 在测试集上预测
y_test_pred_tree = tree_model.predict(X_test)# 结果评估
print('Decision Tree - Training accuracy:', accuracy_score(y_train, y_train_pred_tree))
print('Decision Tree - Testing accuracy:', accuracy_score(y_test, y_test_pred_tree))
print('Decision Tree - Classification Report:\n', classification_report(y_test, y_test_pred_tree))
print('Decision Tree - Confusion Matrix:\n', confusion_matrix(y_test, y_test_pred_tree))运行结果:

Decision Tree - Training accuracy: 1.0
Decision Tree - Testing accuracy: 0.0
Decision Tree - Classification Report:precision recall f1-score support290 0.00 0.00 0.00 0.0342 0.00 0.00 0.00 1.0352 0.00 0.00 0.00 0.0372 0.00 0.00 0.00 1.0378 0.00 0.00 0.00 0.0380 0.00 0.00 0.00 1.0385 0.00 0.00 0.00 1.0406 0.00 0.00 0.00 1.0407 0.00 0.00 0.00 1.0415 0.00 0.00 0.00 0.0428 0.00 0.00 0.00 0.0438 0.00 0.00 0.00 0.0450 0.00 0.00 0.00 2.0470 0.00 0.00 0.00 1.0480 0.00 0.00 0.00 1.0488 0.00 0.00 0.00 0.0495 0.00 0.00 0.00 1.0500 0.00 0.00 0.00 1.0502 0.00 0.00 0.00 1.0510 0.00 0.00 0.00 1.0515 0.00 0.00 0.00 2.0520 0.00 0.00 0.00 0.0550 0.00 0.00 0.00 1.0560 0.00 0.00 0.00 0.0562 0.00 0.00 0.00 2.0564 0.00 0.00 0.00 1.0570 0.00 0.00 0.00 1.0590 0.00 0.00 0.00 0.0600 0.00 0.00 0.00 1.0607 0.00 0.00 0.00 1.0615 0.00 0.00 0.00 0.0620 0.00 0.00 0.00 1.0625 0.00 0.00 0.00 1.0630 0.00 0.00 0.00 1.0640 0.00 0.00 0.00 1.0650 0.00 0.00 0.00 0.0675 0.00 0.00 0.00 1.0680 0.00 0.00 0.00 2.0695 0.00 0.00 0.00 0.0718 0.00 0.00 0.00 1.0720 0.00 0.00 0.00 0.0725 0.00 0.00 0.00 0.0740 0.00 0.00 0.00 0.0750 0.00 0.00 0.00 2.0760 0.00 0.00 0.00 1.0770 0.00 0.00 0.00 0.0780 0.00 0.00 0.00 2.0795 0.00 0.00 0.00 0.0830 0.00 0.00 0.00 2.0845 0.00 0.00 0.00 1.0870 0.00 0.00 0.00 0.0880 0.00 0.00 0.00 1.0886 0.00 0.00 0.00 0.0970 0.00 0.00 0.00 1.0985 0.00 0.00 0.00 0.0990 0.00 0.00 0.00 1.01035 0.00 0.00 0.00 0.01045 0.00 0.00 0.00 0.01065 0.00 0.00 0.00 1.01080 0.00 0.00 0.00 0.01095 0.00 0.00 0.00 1.01105 0.00 0.00 0.00 0.01130 0.00 0.00 0.00 1.01150 0.00 0.00 0.00 1.01185 0.00 0.00 0.00 0.01190 0.00 0.00 0.00 1.01260 0.00 0.00 0.00 0.01265 0.00 0.00 0.00 0.01270 0.00 0.00 0.00 1.01280 0.00 0.00 0.00 1.01285 0.00 0.00 0.00 2.01310 0.00 0.00 0.00 0.01480 0.00 0.00 0.00 1.01510 0.00 0.00 0.00 1.01515 0.00 0.00 0.00 1.01547 0.00 0.00 0.00 0.0accuracy 0.00 54.0macro avg 0.00 0.00 0.00 54.0
weighted avg 0.00 0.00 0.00 54.0Decision Tree - Confusion Matrix:[[0 0 0 ... 0 0 0][1 0 0 ... 0 0 0][0 0 0 ... 0 0 0]...[0 0 0 ... 0 0 0][0 0 0 ... 0 0 0][0 0 0 ... 0 0 0]]
比较神经网络和决策树
- 训练过程:神经网络通常需要更多的训练时间和调整超参数(如学习率、隐藏层大小),而决策树参数较少,训练速度快。
- 性能:根据输出的准确率、分类报告和混淆矩阵,比较两个模型的表现。神经网络可能在某些复杂模式中表现更好,而决策树在处理缺失值和解释性方面更具优势。
- 复杂性与可解释性:神经网络更复杂,难以解释,而决策树的结果易于解释。
6. 总结
通过以上步骤,我们成功地读取了酒的数据集,训练了神经网络和决策树分类模型,并对比了它们的性能。在参数调整的过程中,我们讨论了隐藏层数量与模型性能之间的关系,并观察了不同模型在处理相同数据时的表现差异。
相关文章:
sklearn红酒数据集分类器的构建和评估
实验目的: 1. 掌握sklearn科学数据包中决策树和神经网络分类器的构建 2. 掌握对不同分类器进行综合评估 实验数据: 红酒数据集 红酒数据集利用红酒的化学特征来描述三种不同类型的葡萄酒。 实验内容与要求: 解压文件得到wine数据。利用pa…...

【IC验证面试常问-4】
IC验证面试常问-4 1.11 struct和union的异同1.13 rose 和posedge 的区别?1.14 semaphore的用处是什么?1.15 类中的静态方法使用注意事项有哪些?1.16 initial和final的区别? s t o p , stop, stop,finish的区别1.17 logic,wire和re…...

【数据集】【YOLO】【目标检测】交通事故识别数据集 8939 张,YOLO道路事故目标检测实战训练教程!
数据集介绍 【数据集】道路事故识别数据集 8939 张,目标检测,包含YOLO/VOC格式标注。数据集中包含2种分类:{0: accident, 1: non-accident}。数据集来自国内外图片网站和视频截图。检测范围道路事故检测、监控视角检测、无人机视角检测、等&…...
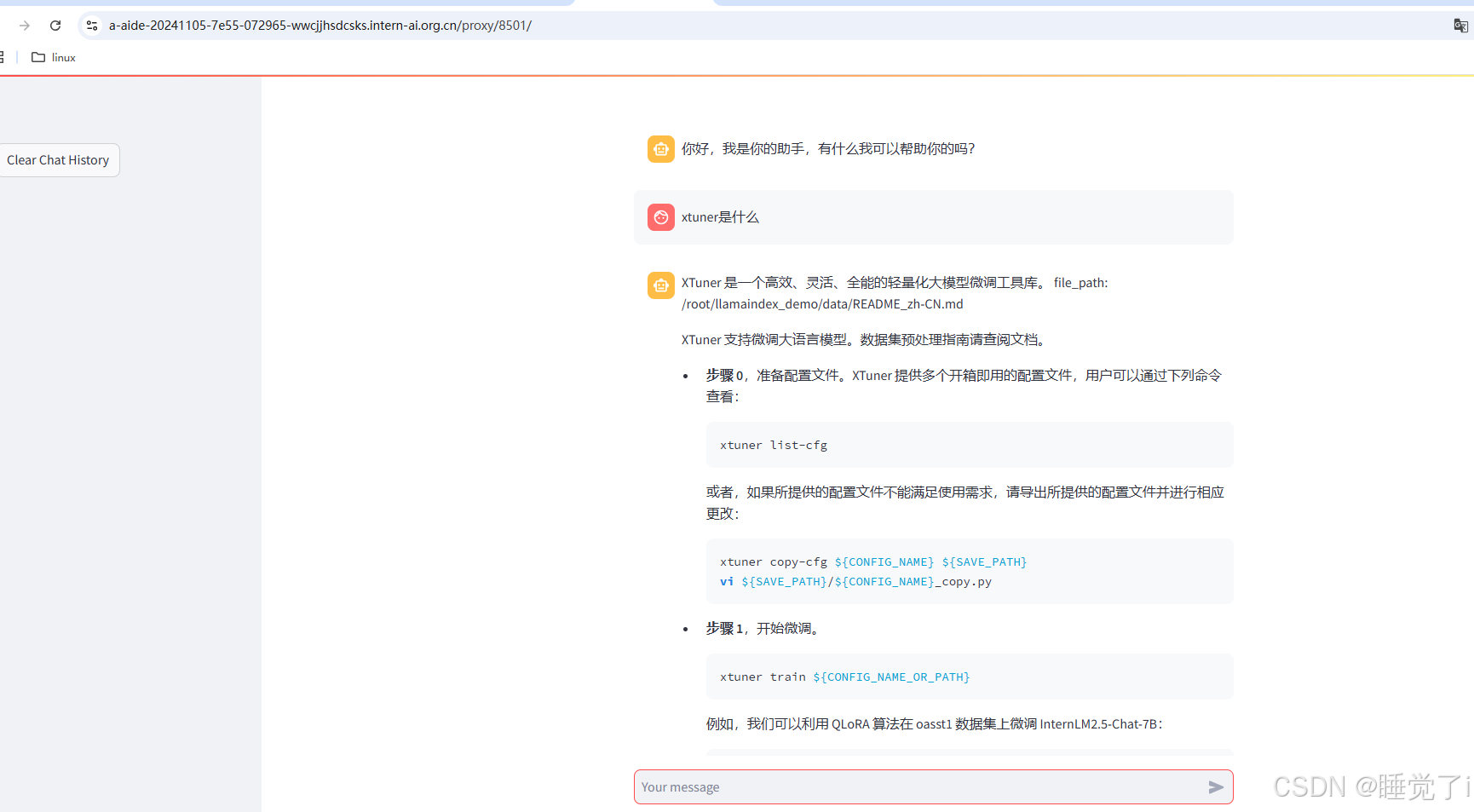
书生浦语第四期基础岛L1G4000-InternLM + LlamaIndex RAG 实践
文章目录 一、任务要求11.首先创建虚拟环境2. 安装依赖3. 下载 Sentence Transformer 模型4.下载 NLTK 相关资源5. 是否使用 LlamaIndex 前后对比6. LlamaIndex web7. LlamaIndex本地部署InternLM实践 一、任务要求1 任务要求1(必做,参考readme_api.md&…...

基于ViT的无监督工业异常检测模型汇总
基于ViT的无监督工业异常检测模型汇总 论文1:VT-ADL: A Vision Transformer Network for Image Anomaly Detection and Localization(2021)1.1 主要思想1.2 系统框架 论文2:Inpainting Transformer for Anomaly Detection…...

数据库管理-第258期 23ai:Oracle Data Redaction(20241104)
数据库管理258期 2024-11-04 数据库管理-第258期 23ai:Oracle Data Redaction(20241104)1 简介2 应用场景与有点3 多租户环境4 特性与能力4.1 全数据编校4.2 部分编校4.3 正则表达式编校4.4 随机编校4.5 空值编校4.6 无编校4.7 不同数据类型上…...

运放进阶篇-多种波形可调信号发生器-产生方波-三角波-正弦波
引言:前几节我们已经说到硬件相关基础的电路,以及对于运放也讲到了初步的理解,特别是比较器的部分,但是放大器的部分我们对此并没有阐述,在这里通过实例进行理论结合实践的学习。而运放真正的核心,其实就是…...

CSS中的变量应用——:root,Sass变量,JavaScript中使用Sass变量
:root—— 原生CSS 自定义属性(变量) 在 SCSS 文件中定义 CSS 自定义属性。然后通过 JavaScript 读取这些属性。 // variables.scss :root { --login-bg-color: #293146;--left-menu-max-width: 200px;--left-menu-min-width: 64px;--left-menu-bg-…...

WPF+MVVM案例实战与特效(二十八)- 自定义WPF ComboBox样式:打造个性化下拉菜单
文章目录 1. 引言案例效果3. ComboBox 基础4. 自定义 ComboBox 样式4.1 定义 ComboBox 样式4.2 定义 ComboBoxItem 样式4.3 定义 ToggleButton 样式4.4 定义 Popup 样式5. 示例代码6. 结论1. 引言 在WPF应用程序中,ComboBox控件是一个常用的输入控件,用于从多个选项中选择一…...

速盾:怎么使用cdn加速?
CDN(Content Delivery Network)即内容分发网络,是一种通过在网络各处部署节点来缓存和传输网络内容的技术。通过使用CDN加速,可以提高网站的访问速度、减轻服务器负载、提供更好的用户体验。 使用CDN加速的步骤如下: …...

C++ 优先算法 —— 三数之和(双指针)
目录 题目:三数之和 1. 题目解析 2. 算法原理 ①. 暴力枚举 ②. 双指针算法 不漏的处理: 去重处理: 固定一个数 a 的优化: 3. 代码实现 Ⅰ. 暴力枚举(会超时 O(N)) Ⅱ.…...

YOLOv7-0.1部分代码阅读笔记-yolo.py
yolo.py models\yolo.py 目录 yolo.py 1.所需的库和模块 2.class Detect(nn.Module): 3.class IDetect(nn.Module): 4.class IAuxDetect(nn.Module): 5.class IBin(nn.Module): 6.class Model(nn.Module): 7.def parse_model(d, ch): 8.if __name__ __main__…...

【缓存与加速技术实践】Web缓存代理与CDN内容分发网络
文章目录 Web缓存代理Nginx配置缓存代理详细说明 CDN内容分发网络CDN的作用CDN的工作原理CDN内容的获取方式解决缓存集中过期的问题 Web缓存代理 作用: 缓存之前访问过的静态网页资源,以便在再次访问时能够直接从缓存代理服务器获取,减少源…...

MySQL的约束和三大范式
一.约束 什么是约束,为什么要用到约束? 约束就是用于创建表时,给对应的字段添加对应的约束 约束的作用就是当我们用insert into时,如果传入的数据有问题,不符合创建表时我们定的规定,这时MySQL就会自动帮…...

Unity网络通信(part7.分包和黏包)
目录 前言 概念 解决方案 具体代码 总结 分包黏包概念 分包 黏包 解决方案概述 前言 在探讨Unity网络通信的深入内容时,分包和黏包问题无疑是其中的关键环节。以下是对Unity网络通信中分包和黏包问题前言部分的详细解读。 概念 在网络通信中,…...

练习题 - DRF 3.x Overviewses 框架概述
Django REST Framework (DRF) 是一个强大的工具,用于构建 Web APIs。作为 Django 框架的扩展,DRF 提供了丰富的功能和简洁的 API,使得开发 RESTful Web 服务变得更加轻松。对于想要在 Django 环境中实现快速且灵活的 API 开发的开发者来说,DRF 是一个非常有吸引力的选择。学…...

Linux 经典面试八股文
快速鉴别十个题 1,你如何描述Linux文件系统的结构? 答案应包括对/, /etc, /var, /home, /bin, /lib, /usr, 和 /tmp等常见目录的功能和用途的描述。 2,在Linux中如何查看和终止正在运行的进程? 期望的答案应涵盖ps, top, htop, …...

Filter和Listener
一、Filter过滤器 1 概念 可以实现拦截功能,对于指定资源的限定进行拦截,替换,同时还可以提高程序的性能。在Web开发时,不同的Web资源中的过滤操作可以放在同一个Filter中完成,这样可以不用多次编写重复代码…...

Go 项目中实现类似 Java Shiro 的权限控制中间件?
序言: 要在 Go 项目中实现类似 Java Shiro 的权限控制中间件,我们可以分为几个步骤来实现用户的菜单访问权限和操作权限控制。以下是一个基本的实现框架步骤: 目录 一、数据库设计 二、中间件实现 三、使用中间件 四、用户权限管理 五…...

【Javascript】-一些原生的网页设计案例
JavaScript 网页设计案例 1. 动态时钟 功能描述:在网页上显示一个动态更新的时钟,包括小时、分钟和秒。实现思路: 使用 setInterval 函数每秒更新时间。获取当前时间并更新页面上的文本。 代码示例:<div id"clock"…...

WinForm用户控件调试踩坑记:从‘无法试运行’到完美模块测试的完整流程
WinForm用户控件调试实战:从模块移植到精准测试的完整指南 引言:为什么需要独立的控件测试环境? 在WinForm开发中,用户控件(UserControl)的复用与调试一直是让开发者头疼的问题。当你在主项目中直接测试一个复杂控件时,…...

深度剖析APK Installer:Windows平台Android应用安装的专业解决方案
深度剖析APK Installer:Windows平台Android应用安装的专业解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK Installer是一款专为Windows平台设计…...

工业多串口通信实战:基于EM9170的8串口方案设计与优化
1. 项目概述:为什么8串口在今天依然重要?在物联网、工业自动化、智能楼宇这些领域里摸爬滚打久了,你会发现一个有趣的现象:那些看似“古老”的通信接口,生命力往往比我们想象的要顽强得多。串口,或者说RS-2…...

ThinkPad风扇控制终极指南:TPFanCtrl2完全使用教程
ThinkPad风扇控制终极指南:TPFanCtrl2完全使用教程 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾被ThinkPad风扇的突然加速打扰了工作专注&#…...

基于Go与Croc构建Telegram文件传输机器人:原理、部署与优化
1. 项目概述:一个基于Go的轻量级文件传输机器人 如果你经常需要在不同的设备、服务器或者聊天群组之间快速分享文件,并且对安全性、速度和便捷性有一定要求,那么你很可能已经厌倦了那些需要注册账号、上传到第三方服务器、或者操作繁琐的命令…...

企业内网应用安全调用外部大模型的Taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网应用安全调用外部大模型的Taotoken接入方案 应用场景类,探讨具有安全合规要求的企业如何安全地引入AI能力&…...

UE5 产品三维交互展示 创意实现
1. UE5产品三维交互展示的核心价值 想象一下,你正在向客户展示一款全新的无人机产品。传统的二维图片和视频已经无法满足需求,客户希望全方位了解产品细节,甚至能亲手"拆解"查看内部构造。这正是UE5三维交互展示的用武之地。 UE5…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...

AI智能体任务编排框架:从概念到实战的Mission Control指南
1. 项目概述:为AI智能体打造一个“任务控制中心”最近在折腾AI智能体(Agent)的开发,发现一个挺普遍的问题:当你想让多个智能体协同工作,或者想让单个智能体执行一系列复杂、有依赖关系的任务时,…...

Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生!
Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Wind…...