Spark 中的 RDD 分区的设定规则与高阶函数、Lambda 表达式详解
Spark 的介绍与搭建:从理论到实践_spark环境搭建-CSDN博客
Spark 的Standalone集群环境安装与测试-CSDN博客
PySpark 本地开发环境搭建与实践-CSDN博客
Spark 程序开发与提交:本地与集群模式全解析-CSDN博客
Spark on YARN:Spark集群模式之Yarn模式的原理、搭建与实践-CSDN博客
Spark 中 RDD 的诞生:原理、操作与分区规则-CSDN博客
目录
一、RDD 分区的设定规则
(一)parallelize 获取 rdd 时的分区设定
(二)通过外部读取数据 - textFile 时的分区设定
(三)子 RDD 分区数
(四)RDD分区的设定规则
二、高阶函数及 Lambda 表达式
(一)复习 Python 函数语法
(二)需求示例与高阶函数概念引入
一个简单的需求场景
高阶函数的定义
(三)Lambda 表达式与高阶函数的结合使用
使用 Lambda 表达式优化代码
更复杂的需求示例
在集合操作中的应用
三、总结
在大数据处理领域,Apache Spark 是一个强大的开源分布式计算框架。它提供了丰富的功能和灵活的编程接口,其中弹性分布式数据集(RDD)是其核心概念之一。RDD 的分区设定规则对于数据处理的性能和资源利用至关重要,同时,高阶函数和 Lambda 表达式的运用能让我们在 Spark 编程中更加简洁高效地处理数据。本文将深入探讨 RDD 分区的设定规则以及高阶函数和 Lambda 表达式的相关知识。
一、RDD 分区的设定规则
(一)parallelize 获取 rdd 时的分区设定
方式一:并行化集合:parallelize
没有指定:spark.default.parallelism参数值决定
指定分区:指定几个,就是几个分区
list_rdd = sc.parallelize(data,numSlices=2)总结:假如指定了分区数,分区数就是这个,假如没有指定spark.default.parallelism。
(二)通过外部读取数据 - textFile 时的分区设定
没有指定:spark.default.parallelism和2取最小值,具体计算并行度的公式:
min(spark.default.parallelism,2)
指定分区:最小分区数,最少有这么多分区,具体的分区数可以根据HDFS分片规则来
hdfs的一片是128M或者128*1.1 = 140.8M
file_rdd =sc.textFile("../datas/function_data/filter.txt", minPartitions=2)# 假如你这个data.txt = 500M ,此时的分区数是:4 因为 500 = 128+ 128+ 128+ 116
rdd3 = sc.textFile("hdfs://bigdata01:9820/datas/wordcount/data.txt", minPartitions=2)
rdd3.foreach(lambda x: print(x))
spark.default.parallelism 参数
这个参数在 RDD 分区设定中起着关键作用,它用于指定没有父 RDD 的 RDD 的分区数。在不同的运行模式下,其取值规则有所不同。
Local mode(本地模式)
在本地模式下,分区数取决于本地机器的 CPU 核数。这是因为在本地环境中,资源主要受限于本地计算机的硬件配置。例如,如果本地机器是 4 核,那么分区数可能就是 4(具体可能还会受到其他相关设置的微调)。这种基于本地 CPU 核数的分区设定,能够充分利用本地计算资源,实现一定程度的并行计算。
Mesos fine grained mode(Mesos 细粒度模式)
在 Mesos 细粒度模式下,分区数的默认值是 8。Mesos 是一种集群资源管理框架,在这种特定的模式下,Spark 有其默认的分区设定策略。这个默认值 8 是经过实践和设计考虑的,旨在在 Mesos 细粒度管理环境下平衡数据处理的效率和资源利用。
其他模式(Others)
在其他模式下,分区数是集群中所有参与运算的设备的所有核数与 2 相比较,取较大值。这种设定方式考虑了集群的整体计算能力。例如,如果集群中有 10 个节点,每个节点有 2 核,那么总核数是 20,大于 2,所以分区数就是 20。这种策略保证了在不同规模的集群中都能有合适的并行度,避免了因核数过少而导致的处理效率低下问题,同时也防止了因核数过多而可能引起的资源过度分配问题。
(三)子 RDD 分区数
子 RDD 的分区数与父 RDD 以及所使用的转换操作有关。在一些转换操作中,分区数可能保持不变,而在另一些操作中,分区数可能会根据数据的重新分布规则而改变。比如,在某些聚合操作后,分区数可能会减少,而在数据拆分操作后,分区数可能会增加。了解子 RDD 分区数的变化规律对于优化 Spark 作业的性能和资源利用有着重要意义。
(四)RDD分区的设定规则
(1)local模式
默认并行度取决于本地机器的核数,即
local: 没有指定CPU核数,则所有计算都运行在一个线程当中,没有任何并行计算
local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
local[*]: 自动帮你按照CPU的核数来设置线程数。比如CPU有4核,Spark帮你自动设置4个线程计算
(2)集群模式
集群模式包含Stanalone、Yarn模式,Mesos的默认并行度为8
默认并行度取决于所有executor上的总核数与2的最大值,比如集群模式的设置如下:
--num-executors 5
--executor-cores 2
上面配置Executor的数量为5,每个Executor的CPU Core数量为2,
executor上的总核数10,则默认并行度为Max(10,2)=10。
注意,上面只是默认并行度(defaultParallelism)的取值,并不一定是RDD最终的分区数。具体来说,对于从集合中创建的RDD,其最终分区数等于defaultParallelism,但是从外部存储系统的数据集创建创建的RDD,其最终的分区数:需要文件的总大小计算得到。
二、高阶函数及 Lambda 表达式
(一)复习 Python 函数语法
在深入探讨高阶函数和 Lambda 表达式之前,我们先来复习一下 Python 函数的语法。函数是一段可重复使用的代码块,用于完成特定的任务。在 Python 中,我们使用def关键字来定义函数,例如:
创建
def 函数名(参数):代码逻辑返回值:return
调用
返回值 = 函数名(参数)def function_name(parameters):# 函数体return resultdef add(a,b)return a + bx = add(1,2)
print(x) # x = 3 函数可以接受参数,在函数体中进行计算,并返回一个结果。参数可以有默认值,函数也可以没有返回值(此时return语句可以省略)。
(二)需求示例与高阶函数概念引入
一个简单的需求场景
假设我们有一个列表list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],我们想要对这个列表中的每个元素进行平方和次方运算。我们可以定义一个函数,然后使用map函数来将函数应用到list1的每个元素上:
import mathlist1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(*list1)def pingFang(x):return x * xdef liFang(x):return math.pow(x, 3)def getNum(_list, flag):if flag == 2:return map(pingFang, _list)if flag == 3:return map(liFang, _list)# 此时的map是python的一个方法,不是spark里面一个算子RDD
# map(函数,后面是一个迭代器): 循环将一个迭代器中的元素拿过来,传递个前面的函数,计算得到一个map对象
# lambda 其实是一个匿名函数,主要用于一个方法中需要传递一个函数,这个函数只用一次,并且函数中的代码只有一行。
def getNum2(_list, flag):if flag == 2:return map(lambda x: x * x, _list)if flag == 3:return map(lambda x: math.pow(x, 3), _list)for e in getNum2(list1, 2):print(e)print("--" * 20)
for e in getNum2(list1, 3):print(e)高阶函数的定义
高阶函数是一种特殊的函数,它的某个参数是一个函数。就像我们上面提到的map函数,它接受一个函数(这里是comp)和一个可迭代对象(这里是list1)作为参数。一般来说,作为参数的函数(这里的comp)被称为参数函数。
函数和算子在概念上有一些区别,函数通常是指一般的方法,它们在单机环境下执行,不能并行执行。而算子在分布式计算环境中,如 Spark 中,数据是分布式存储的,计算也是分布式进行的。
(三)Lambda 表达式与高阶函数的结合使用
使用 Lambda 表达式优化代码
对于前面的平方运算示例,我们可以使用 Lambda 表达式来简化代码。Lambda 表达式是一种匿名函数,它的语法形式为lambda parameters: expression。使用 Lambda 表达式来实现列表元素平方运算的代码如下:
# 举例说明:
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def comp(x):return x*x
rs = map(comp, list1)
print(*rs)# 使用lambda 优化一下:
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
rs = map(lambda x: x*x, list1)
print(*rs)这里的lambda x: x * x就是一个匿名函数,它替代了我们之前定义的comp函数。
更复杂的需求示例
我们来看一个更复杂一点的需求。给定一个值,我们可以求这个值的 2 次方或者 3 次方。首先是正常的写法:
# 正常思路
import mathdef getPingFang(num):return num ** 2def getLiFang(num):return math.pow(num, 3)def getNum(num, flat):if flat == 2:return getPingFang(num)if flat == 3:return getLiFang(num)print(getNum(10, 2))
print(getNum(10, 3))
这种写法相对比较繁琐,尤其是当函数体比较简单的时候。我们可以使用高阶函数和 Lambda 表达式来优化。我们定义一个高阶函数getNum2:
def getNum2(fun, num):return fun(num)
然后我们可以这样使用它:
print(getNum2(getPingFang, 10))
print(getNum2(getLiFang, 10))
我们还可以使用 Lambda 表达式:
print(getNum2(lambda x: x ** 2, 10))
print(getNum2(lambda x: math.pow(x, 3), 10))
在集合操作中的应用
假设我们有一个列表list = [1, 3, 4, 45, 56, 8],我们想要求这个列表中每个数的平方和立方。我们可以使用map这个高阶函数结合 Lambda 表达式来实现:
a = map(lambda x: math.pow(x, 2), list)
b = map(lambda x: math.pow(x, 3), list)
print(*a)
print(*b)
这里map函数将 Lambda 表达式所定义的函数应用到列表的每个元素上,分别得到平方和立方的结果集。
三、总结
在 Spark 编程中,理解 RDD 分区的设定规则对于优化数据处理性能至关重要。不同的获取 RDD 方式和运行模式下,分区数的设定都有其特定的规则。同时,高阶函数和 Lambda 表达式是提高代码简洁性和效率的有力工具。通过合理运用高阶函数和 Lambda 表达式,我们可以在处理数据集合时更加灵活和高效。无论是简单的数学运算还是复杂的数据分析场景,这些知识都能帮助我们更好地利用 Spark 的强大功能。在实际的大数据处理项目中,深入掌握这些概念并灵活运用,可以使我们的 Spark 作业更加高效地运行,提高数据处理的速度和质量,为企业和组织从海量数据中获取有价值的信息提供有力支持。希望本文能帮助读者更好地理解和应用这些重要的 Spark 编程知识点。
相关文章:

Spark 中的 RDD 分区的设定规则与高阶函数、Lambda 表达式详解
Spark 的介绍与搭建:从理论到实践_spark环境搭建-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式…...

redis十大数据类型
文章目录 一、redis字符串(String)set key value同时获取或设置多个键值获取指定区间范围内的值数字增减获取字符串长度和内容追加分布式锁getset(先get再set) 二、redis列表(List)通过索引获取列表中的元素…...

国内AI工具复现GPTs效果详解
国内AI工具复现GPTs效果详解 引言 近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)逐渐成为研究和应用的热点。GPTs(Generative Pre-trained Transformer)系列模型,特别是GPT-4的推出&a…...
【INTO语句】)
【学习笔记】SAP ABAP——OPEN SQL(一)【INTO语句】
【INTO语句】 结构体插入(插入一条语句时) SELECT...INTO [CORRESPONDING FIELDS OF] <wa> FROM <db> WHERE <condition>.内表插入(插入多条语句时) SELECT...INTO|APPENDING [CORRESPONDING FIELDS OF] TABLE <itab>FROM <db> WHERE <con…...

vscode使用之vscode-server离线安装
最近因为想要使用AI工具开始使用vscode,但是在内网使用vscode通过SSH连接虚拟机的centos远程目录却出现了问题,始终连不上,查看原因是centos没有安装vscode-server,网上找各个教程离线安装vscode-code除了浪费时间没有任何收获&am…...
字符编码和字符集
1. 字符编码和字符集 1.1. 字符编码 编码:字符 –>字节解码:字节 –>字符字符编码Character Encoding : 就是一套自然语言的字符与二进制数之间的对应规则。 1.2. 字符集 字符集 Charset:是一个系统支持的所有字符的集合࿰…...

【WRF理论第七期】WPS预处理
【WRF理论第七期】WPS预处理 运行WPS(Running the WPS)步骤1:Define model domains with geogrid步骤2:Extracting meteorological fields from GRIB files with ungrib步骤3:Horizontally interpolating meteorologic…...

Flutter鸿蒙next中的按钮封装:自定义样式与交互
在Flutter应用开发中,按钮是用户界面中不可或缺的组件之一。它不仅用于触发事件,还可以作为视觉元素增强用户体验。Flutter提供了多种按钮组件,如ElevatedButton、TextButton、OutlinedButton等,但有时这些预制的按钮样式无法满足…...
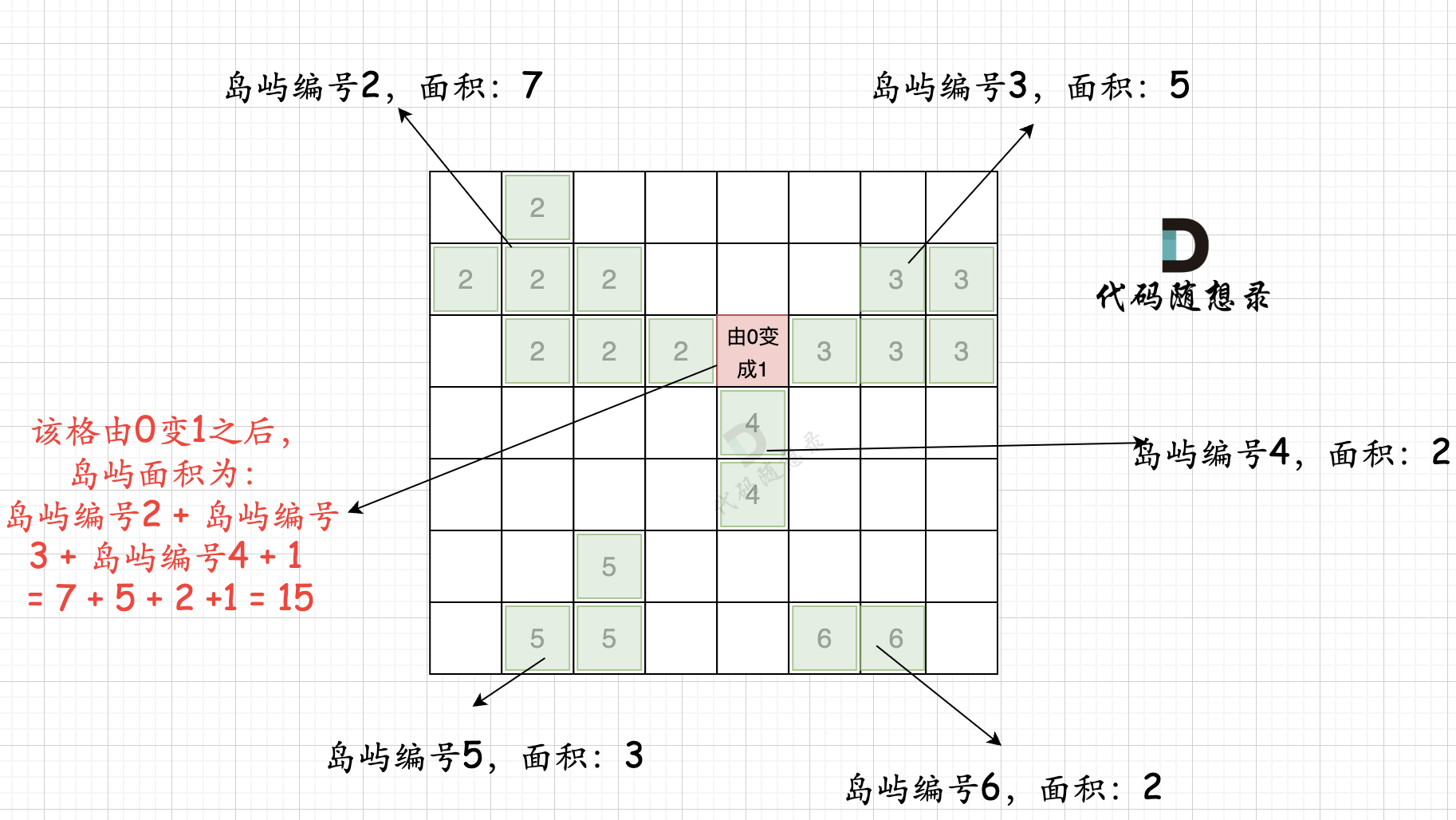
代码随想录算法训练营Day57 | 卡玛网 101.孤岛的总面积、卡玛网 102.沉没孤岛、卡玛网 103. 水流问题、卡玛网 104.建造最大岛屿
目录 卡玛网 101.孤岛的总面积 卡玛网 102.沉没孤岛 卡玛网 103. 水流问题 卡玛网 104.建造最大岛屿 卡玛网 101.孤岛的总面积 题目 101. 孤岛的总面积 思路 代码随想录:101.孤岛的总面积 重点: 首先遍历图的四条边,把其中的陆地及…...

美团代付微信小程序系统 read.php 任意文件读取漏洞复现
0x01 产品简介 美团代付微信小程序系统是美团点评旗下的一款基于微信小程序技术开发的应用程序功能之一,它允许用户方便快捷地请求他人为自己支付订单费用。随着移动支付的普及和微信小程序的广泛应用,美团作为中国领先的本地生活服务平台,推出了代付功能,以满足用户多样化…...

Windows安装tensorflow的GPU版本
前言 首先本文讨论的是windows系统,显卡是英伟达(invida)如何安装tensorflow-gpu。一共需要安装tensorflow-gpu、cuDNN、CUDA三个东西。其中CUDA是显卡的驱动库,cuDNN是深度学习加速库。 安装开始前,首先需要安装好c…...

2021-04-22 51单片机玩转点阵
理论就不赘述了,网络上多得很,直接从仿真软件感性上操作认识点阵,首先打开ISIS仿真软件,放置一个点阵和电源与地线就可以开始了;由点阵任何一脚连线到地线,另一边对应的引脚就连接到电源,如图:点击运行看是否点亮?看到蓝色与红色的点表示电源正常但是没有任何亮点,这时对调一下…...

lua入门教程:数字
在Lua中,数字(number)是一种基本数据类型,用于表示数值。以下是对Lua中数字的详细教程: 一、数字类型概述 Lua中的数字遵循IEEE 754双精度浮点标准,可以表示非常大的正数和负数,以及非常小的正…...

[CKS] K8S ServiceAccount Set Up
最近准备花一周的时间准备CKS考试,在准备考试中发现有一个题目关于Rolebinding的题目。 Question 1 The buffy Pod in the sunnydale namespace has a buffy-sa ServiceAccount with permissions the Pod doesn’t need. Modify the attached Role so that it onl…...

QML:Menu详细使用方法
目录 一.性质 二.作用 三.方法 四.使用 1.改变标签 2.打开本地文件 3.退出程序 4.打开Dialog 五.效果 六.代码 在 QML 中,Menu 是一个用于创建下拉菜单或上下文菜单的控件。它通常由多个 MenuItem 组成,每个 MenuItem 可以包含文本、图标和快捷…...

时间复杂度和空间复杂度 part2
一,空间复杂度 空间复杂度是衡量一个算法在执行过程中所需内存空间的量度。它反映了算法随着输入数据规模(通常是 nn)的增加,所消耗的内存量如何变化。空间复杂度是分析算法效率的一个重要方面,尤其是在内存资源有限的…...

【电机控制器】STC8H1K芯片——UART串口通信
【电机控制器】STC8H1K芯片——UART串口通信 文章目录 [TOC](文章目录) 前言一、UART1.串口初始化2.串口中断3.发送一个字节 二、实验1.原理图2.实验现象 三、参考资料总结 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、UART 1.串口初始化 …...

STM32移植RT-Thread---时钟管理
一RTT时钟节拍概念 RT-Thread的时钟节拍(Tick)是操作系统用于管理时间和任务调度的一个基本单位。它在实时操作系统中尤为关键,用于实现任务的延时、超时管理等功能。以下是关于RT-Thread时钟节拍的简单说明: 1.Tick定义&#x…...

Jasypt 实现 yml 配置加密
文章目录 前言一、集成 Jasypt1. pom 依赖2. yml 依赖 3. 加密工具类3. 使用二、常见问题1. application.yml 失效问题2. 配置热更新失败问题 前言 jasypt 官方地址:https://github.com/ulisesbocchio/jasypt-spring-boot Jasypt可以为Springboot加密的信息很多&a…...

uniapp—android原生插件开发(2原生插件开发)
本篇文章从实战角度出发,将UniApp集成新大陆PDA设备RFID的全过程分为四部曲,涵盖环境搭建、插件开发、AAR打包、项目引入和功能调试。通过这份教程,轻松应对安卓原生插件开发与打包需求! ***环境问题移步至:uniapp—an…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性 在个人开发项目中接入大模型时,开发者通常面临一个选择&am…...

百度网盘直链解析工具:3分钟突破限速实现满速下载
百度网盘直链解析工具:3分钟突破限速实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾为百度网盘的下载速度而烦恼?非会员用户经常…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换
VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA开发领域,VHDL和Verilog是两大主流硬件描述语言,但团队协作或项目迁移时经常…...

构建轻量级LLM工具集:模块化设计、多模型集成与本地化部署实践
1. 项目概述:一个面向日常的轻量级LLM工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Daily-LLM”。光看名字,你可能会觉得这又是一个庞大的、需要海量算力才能跑起来的“大模型”项目。但点进去仔细研究后,我…...

告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由
告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circuitjs1…...

U-Boot实战:FAT文件系统五大核心命令详解与应用
1. U-Boot与FAT文件系统基础认知 刚接触嵌入式开发时,我第一次在U-Boot环境下操作FAT文件系统就踩了个大坑——试图用ext4write命令操作FAT32格式的SD卡,结果系统直接报错"Unknown command"。这个经历让我深刻认识到:U-Boot对文件系…...

从肌电信号到Arduino控制:MyoWare传感器实战指南
1. 项目概述:当肌肉“说话”,我们如何“倾听”?如果你玩过一些体感游戏,或者看过科幻电影里用意念控制机械臂的场景,心里大概会闪过一个念头:这玩意儿到底是怎么做到的?其实,很多酷炫…...

苍穹外卖day11
概述项目步入尾声,进行商家数据统计开发分为营业额统计,用户统计,订单统计,销量排名 导航栏的内容为查询选定时间内的的数据统计 右上角的数据导出为下一天的内容 数据导出后形成的图表由Apache的Echarts生成,是开发中…...