AscendC从入门到精通系列(二)基于Kernel直调开发AscendC算子
本次主要讨论下AscendC算子的开发流程,基于Kernel直调工程的算子开发。
1 AscendC算子开发的基本流程
使用Ascend C完成Add算子核函数开发;
使用ICPU_RUN_KF CPU调测宏完成算子核函数CPU侧运行验证;
使用<<<>>>内核调用符完成算子核函数NPU侧运行验证。
在正式的开发之前,还需要先完成环境准备和算子分析工作,开发Ascend C算子的基本流程如下图所示:

2 核函数开发
本次以add_custom.cpp作为参考用例。Gitee也有对应工程和完整代码。
operator/AddCustomSample/KernelLaunch/AddKernelInvocationNeo · Ascend/samples - 码云 - 开源中国 (gitee.com)
2.1 核函数定义
首先要根据核函数定义 核函数-编程模型-Ascend C算子开发-算子开发-开发指南-CANN社区版8.0.RC3.alpha003开发文档-昇腾社区 (hiascend.com) 的规则进行核函数的定义,并在核函数中调用算子类的Init和Process函数。
// 给CPU调用
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{KernelAdd op;op.Init(x, y, z);op.Process();
}// 给NPU调用
#ifndef ASCENDC_CPU_DEBUG
void add_custom_do(uint32_t blockDim, void *stream, uint8_t *x, uint8_t *y, uint8_t *z)
{add_custom<<<blockDim, nullptr, stream>>>(x, y, z);
}
#endif
2.2 算子类定义
根据矢量编程范式实现算子类,本样例中定义KernelAdd算子类,其具体成员如下:
class KernelAdd {
public:__aicore__ inline KernelAdd(){}// 初始化函数,完成内存初始化相关操作__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){}// 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作__aicore__ inline void Process(){}private:// 搬入函数,完成CopyIn阶段的处理,被核心Process函数调用__aicore__ inline void CopyIn(int32_t progress){}// 计算函数,完成Compute阶段的处理,被核心Process函数调用__aicore__ inline void Compute(int32_t progress){}// 搬出函数,完成CopyOut阶段的处理,被核心Process函数调用__aicore__ inline void CopyOut(int32_t progress){}private:AscendC::TPipe pipe; //Pipe内存管理对象AscendC::TQue<AscendC::QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; //输入数据Queue队列管理对象,QuePosition为VECINAscendC::TQue<AscendC::QuePosition::VECOUT, BUFFER_NUM> outQueueZ; //输出数据Queue队列管理对象,QuePosition为VECOUTAscendC::GlobalTensor<half> xGm; //管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出AscendC::GlobalTensor<half> yGm;AscendC::GlobalTensor<half> zGm;
};
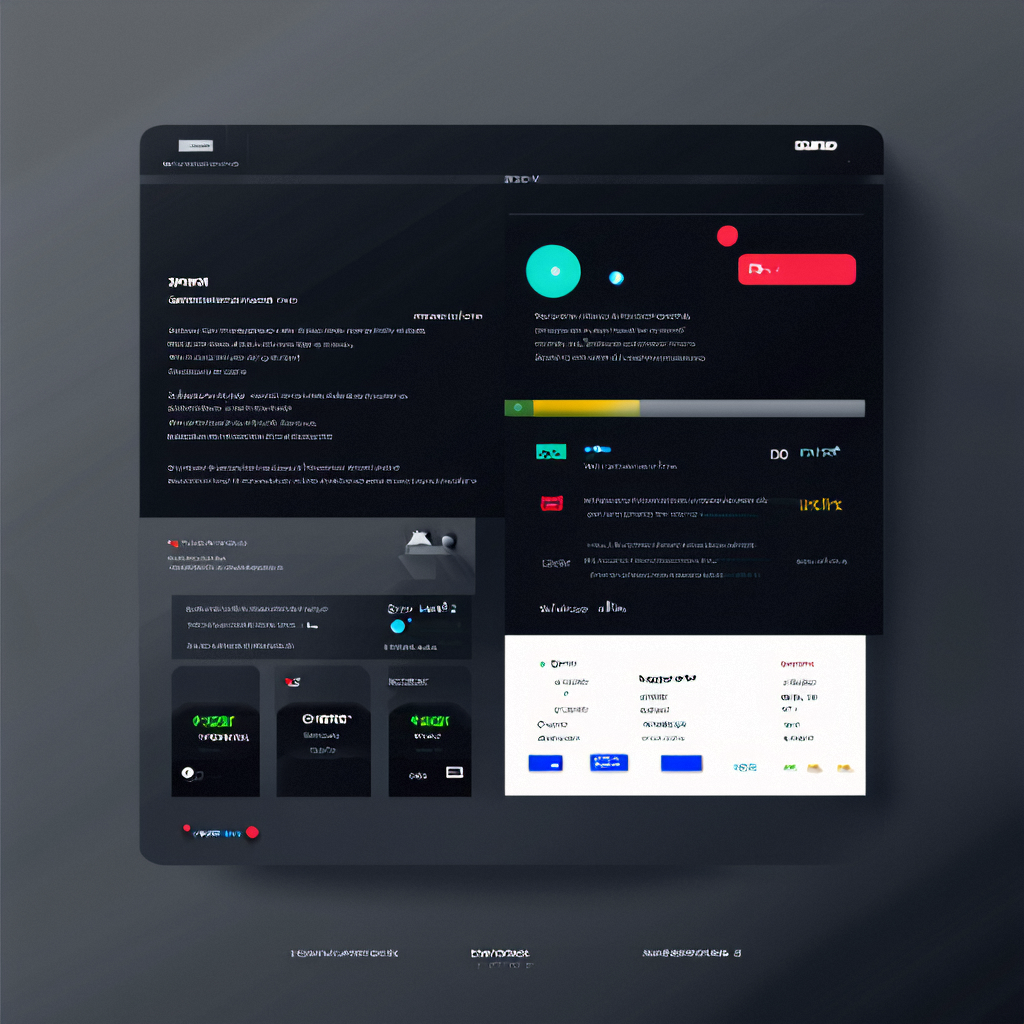
核函数调用关系图

2.3 实现Init,CopyIn,Compute,CopyOut这个4个关键函数
Init函数初始化输入资源
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){xGm.SetGlobalBuffer((__gm__ half *)x + BLOCK_LENGTH * AscendC::GetBlockIdx(), BLOCK_LENGTH);yGm.SetGlobalBuffer((__gm__ half *)y + BLOCK_LENGTH * AscendC::GetBlockIdx(), BLOCK_LENGTH);zGm.SetGlobalBuffer((__gm__ half *)z + BLOCK_LENGTH * AscendC::GetBlockIdx(), BLOCK_LENGTH);pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));}
Process函数中通过如下方式调用这三个:__aicore__ inline void Process(){// loop count need to be doubled, due to double bufferconstexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;// tiling strategy, pipeline parallelfor (int32_t i = 0; i < loopCount; i++) {CopyIn(i);Compute(i);CopyOut(i);}}
CopyIn函数中通过如下方式调用这三个:
1、使用DataCopy接口将GlobalTensor数据拷贝到LocalTensor。
2、使用EnQue将LocalTensor放入VecIn的Queue中。
__aicore__ inline void CopyIn(int32_t progress){// alloc tensor from queue memoryAscendC::LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();AscendC::LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();// copy progress_th tile from global tensor to local tensorAscendC::DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH);AscendC::DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH);// enque input tensors to VECIN queueinQueueX.EnQue(xLocal);inQueueY.EnQue(yLocal);}
Compute函数实现。
1、使用DeQue从VecIn中取出LocalTensor。
2、使用Ascend C接口Add完成矢量计算。
3、使用EnQue将计算结果LocalTensor放入到VecOut的Queue中。
4、使用FreeTensor将释放不再使用的LocalTensor。
__aicore__ inline void Compute(int32_t progress)
{// deque input tensors from VECIN queueAscendC::LocalTensor<half> xLocal = inQueueX.DeQue<half>();AscendC::LocalTensor<half> yLocal = inQueueY.DeQue<half>();AscendC::LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();// call Add instr for computationAscendC::Add(zLocal, xLocal, yLocal, TILE_LENGTH);// enque the output tensor to VECOUT queueoutQueueZ.EnQue<half>(zLocal);// free input tensors for reuseinQueueX.FreeTensor(xLocal);inQueueY.FreeTensor(yLocal);
}
CopyOut函数实现。
1、使用DeQue接口从VecOut的Queue中取出LocalTensor。
2、使用DataCopy接口将LocalTensor拷贝到GlobalTensor上。
3、使用FreeTensor将不再使用的LocalTensor进行回收。
__aicore__ inline void CopyOut(int32_t progress)
{// deque output tensor from VECOUT queueAscendC::LocalTensor<half> zLocal = outQueueZ.DeQue<half>();// copy progress_th tile from local tensor to global tensorAscendC::DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH);// free output tensor for reuseoutQueueZ.FreeTensor(zLocal);
}
3 核函数的运行验证
异构计算架构中,NPU(kernel侧)与CPU(host侧)是协同工作的,完成了kernel侧核函数开发后,即可编写host侧的核函数调用程序,实现从host侧的APP程序调用算子,执行计算过程。
3.1 编写CPU侧调用程序

// 使用GmAlloc分配共享内存,并进行数据初始化uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize);uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize);uint8_t* z = (uint8_t*)AscendC::GmAlloc(outputByteSize);ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize);// 调用ICPU_RUN_KF调测宏,完成核函数CPU侧的调用AscendC::SetKernelMode(KernelMode::AIV_MODE);ICPU_RUN_KF(add_custom, blockDim, x, y, z); // use this macro for cpu debug// 输出数据写出WriteFile("./output/output_z.bin", z, outputByteSize);// 调用GmFree释放申请的资源AscendC::GmFree((void *)x);AscendC::GmFree((void *)y);AscendC::GmFree((void *)z);
3.2 编写NPU侧运行算子的调用程序

// AscendCL初始化CHECK_ACL(aclInit(nullptr));// 运行管理资源申请int32_t deviceId = 0;CHECK_ACL(aclrtSetDevice(deviceId));aclrtStream stream = nullptr;CHECK_ACL(aclrtCreateStream(&stream));// 分配Host内存uint8_t *xHost, *yHost, *zHost;uint8_t *xDevice, *yDevice, *zDevice;CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize));// 分配Device内存CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));// Host内存初始化ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));// 用内核调用符<<<>>>调用核函数完成指定的运算,add_custom_do中封装了<<<>>>调用add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice);CHECK_ACL(aclrtSynchronizeStream(stream));// 将Device上的运算结果拷贝回HostCHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));WriteFile("./output/output_z.bin", zHost, outputByteSize);// 释放申请的资源CHECK_ACL(aclrtFree(xDevice));CHECK_ACL(aclrtFree(yDevice));CHECK_ACL(aclrtFree(zDevice));CHECK_ACL(aclrtFreeHost(xHost));CHECK_ACL(aclrtFreeHost(yHost));CHECK_ACL(aclrtFreeHost(zHost));// AscendCL去初始化CHECK_ACL(aclrtDestroyStream(stream));CHECK_ACL(aclrtResetDevice(deviceId));CHECK_ACL(aclFinalize());
3.3 完整main.cpp
/*** @file main.cpp** Copyright (C) 2024. Huawei Technologies Co., Ltd. All rights reserved.** This program is distributed in the hope that it will be useful,* but WITHOUT ANY WARRANTY; without even the implied warranty of* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.*/
#include "data_utils.h"
#ifndef ASCENDC_CPU_DEBUG
#include "acl/acl.h"
extern void add_custom_do(uint32_t blockDim, void *stream, uint8_t *x, uint8_t *y, uint8_t *z);
#else
#include "tikicpulib.h"
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z);
#endifint32_t main(int32_t argc, char *argv[])
{uint32_t blockDim = 8;size_t inputByteSize = 8 * 2048 * sizeof(uint16_t);size_t outputByteSize = 8 * 2048 * sizeof(uint16_t);#ifdef ASCENDC_CPU_DEBUGuint8_t *x = (uint8_t *)AscendC::GmAlloc(inputByteSize);uint8_t *y = (uint8_t *)AscendC::GmAlloc(inputByteSize);uint8_t *z = (uint8_t *)AscendC::GmAlloc(outputByteSize);ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize);AscendC::SetKernelMode(KernelMode::AIV_MODE);ICPU_RUN_KF(add_custom, blockDim, x, y, z); // use this macro for cpu debugWriteFile("./output/output_z.bin", z, outputByteSize);AscendC::GmFree((void *)x);AscendC::GmFree((void *)y);AscendC::GmFree((void *)z);
#elseCHECK_ACL(aclInit(nullptr));int32_t deviceId = 0;CHECK_ACL(aclrtSetDevice(deviceId));aclrtStream stream = nullptr;CHECK_ACL(aclrtCreateStream(&stream));uint8_t *xHost, *yHost, *zHost;uint8_t *xDevice, *yDevice, *zDevice;CHECK_ACL(aclrtMallocHost((void **)(&xHost), inputByteSize));CHECK_ACL(aclrtMallocHost((void **)(&yHost), inputByteSize));CHECK_ACL(aclrtMallocHost((void **)(&zHost), outputByteSize));CHECK_ACL(aclrtMalloc((void **)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));CHECK_ACL(aclrtMalloc((void **)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));CHECK_ACL(aclrtMalloc((void **)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));add_custom_do(blockDim, stream, xDevice, yDevice, zDevice);CHECK_ACL(aclrtSynchronizeStream(stream));CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));WriteFile("./output/output_z.bin", zHost, outputByteSize);CHECK_ACL(aclrtFree(xDevice));CHECK_ACL(aclrtFree(yDevice));CHECK_ACL(aclrtFree(zDevice));CHECK_ACL(aclrtFreeHost(xHost));CHECK_ACL(aclrtFreeHost(yHost));CHECK_ACL(aclrtFreeHost(zHost));CHECK_ACL(aclrtDestroyStream(stream));CHECK_ACL(aclrtResetDevice(deviceId));CHECK_ACL(aclFinalize());
#endifreturn 0;
}
整体运行起来,请参考operator/AddCustomSample/KernelLaunch/AddKernelInvocationNeo · Ascend/samples - 码云 - 开源中国 (gitee.com)
相关文章:
AscendC从入门到精通系列(二)基于Kernel直调开发AscendC算子
本次主要讨论下AscendC算子的开发流程,基于Kernel直调工程的算子开发。 1 AscendC算子开发的基本流程 使用Ascend C完成Add算子核函数开发; 使用ICPU_RUN_KF CPU调测宏完成算子核函数CPU侧运行验证; 使用<<<>>>内核调用符…...

DAO模式的理解
目录 DAO模式 含义 DAO模式 的理解 分层思维 分层含义 分层目的 dao层 dao包(对接的是操作数据库的接口) dao包下lmpl 包(dao包中接口的实现类) 补充 1 你创建的实体类需要和数据库中建的表一一对应。 总结 DAO模式 含义…...
使用GitHub Actions实现CI/CD流程
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用GitHub Actions实现CI/CD流程 GitHub Actions 简介 创建仓库 配置工作流 示例工作流文件 触发和运行工作流 部署应用 最佳实…...

机器人助力Bridge Champ游戏:1.4.2版本如何提升玩家体验
在Bridge Champ游戏中,机器人扮演着桥牌游戏的“无名英雄”角色,默默地提升玩家体验。凭借智能化的设计,这些机器人不仅能够陪练,也大大提升了比赛的流畅度与趣味性。 Bridge Champ是什么 Bridge Champ是一个基于Ignis公链的在线…...

滑动窗口(单调队列维护窗口)-acwing
题目: 154. 滑动窗口 - AcWing题库 代码(删除队列窗口多余的>单调队列) 判断最值是否滑出窗口可以放在 入队的后面。 但是,判断,准备入队元素比前面小,要从队尾出队,放在入队前。 总之&a…...

ALB搭建
ALB: 多级分发、消除单点故障提升应用系统的可用性(健康检查)。 海量微服务间的高效API通信。 自带DDoS防护,集成Web应用防火墙 配置: 1.创建ECS实例 2.搭建应用 此处安装的LNMP 3.创建应用型负载均衡ALB实例 需要创建服务关联角…...

c# 动态lambda实现二级过滤(支持多种参数类型和模糊查询)
效果 调用方法 实体类(可以根据需求更换) public class ToolStr50 {public bool isSelected { get; set; }public string toolStr1 { get; set; }public string toolStr2 { get; set; }public string toolStr3 { get; set; }public string toolStr4 { …...

第J5周:DenseNet+SE-Net实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 任务: ●1. 在DenseNet系列算法中插入SE-Net通道注意力机制,并完成猴痘病识别 ●2. 改进思路是否可以迁移到其他地方呢 ●3. 测试集acc…...

Intern大模型训练营(五):书生大模型全链路开源体系笔记
观看视频,可以比较详细地了解到书生大模型全链路开源体系。 其中有几个印象比较深的点: 这张图讲述了书生浦语大模型开源的发展史,同时与主流的llama和Chatgpt模型进行比较,可以看出在参数上,InterLM在努力追赶甚至超…...

聚观早报 | 比亚迪腾势D9登陆泰国;苹果 iOS 18.2 将发布
聚观早报每日整理最值得关注的行业重点事件,帮助大家及时了解最新行业动态,每日读报,就读聚观365资讯简报。 整理丨Cutie 11月5日消息 比亚迪腾势D9登陆泰国 苹果 iOS 18.2 将发布 真我GT7 Pro防尘防水细节 小米15 Ultra最快明年登场 …...

微信小程序开发,诗词鉴赏app,诗词搜索实现(三)
微信小程序开发,诗词鉴赏app(一): https://blog.csdn.net/jky_yihuangxing/article/details/143501681微信小程序开发,诗词鉴赏app,诗词推荐实现(二):https://blog.csdn.net/jky_yih…...
Kotlin 协程使用及其详解
Kotlin协程,好用,但是上限挺高的,我一直感觉自己就处于会用,知其然不知其所以然的地步。 做点小总结,比较浅显。后面自己再继续补充吧。 一、什么是协程? Kotlin 协程是一种轻量级的并发编程方式&#x…...

计算机组成原理--三章四章
这里写目录标题 第三章:存储系统3.1 存储系统基本概念引入存储器的层次结构简介产品 存储器的分类按层次分类按照介质分类按照存取方式分类按照信息的可更改性按照信息的可保护性 存储器的性能指标存储容量单位成本存储速度 总结 3.2主存储器的基本组成半导体元器件…...

单片机工程使用链接优化-flto找不到定义_链接静态库
IDE: CLion HOST: Windows 11 MinGW:x86_64-14.2.0-release-posix-seh-ucrt-rt_v12-rev0 GCC: arm-gnu-toolchain-13.3.rel1-mingw-w64-i686-arm-none-eabi 示例工程:https://github.com/ichliebedich-DaCapo/STM…...

UniTask/Unity的PlayerLoopTiming触发顺序
开始尝试在项目中使用UniTask,发现其中的UniTask.Yield确实很好用,还可以传入PlayerLoopTiming来更细致的调整代码时机,不过平常在Mono中接触的只有Awake,Start,Update等常用Timing,其他的就没怎么接触了&a…...

【报错记录】Steam迁移(移动)游戏报:移动以下应用的内容失败:XXX: 磁盘写入错误
前言 由于黑神话悟空,导致我的2TB的SSD系统盘快满了,我又买了一块4TB的SSD用来存放游戏,我就打算把之前C盘里的游戏移动到D盘,结果Steam移动游戏居然报错了,报的还是“磁盘写入错误”,如下图所示ÿ…...

C 语言学习-04【结构化程序设计】
1、单分支结构语句 用单分支结构进行奇偶判断: #include <stdio.h>int main() {int num;printf("Please enter an integer: ");scanf("%d", &num);if (num % 2 ! 0) {printf("%d is odd! \n", num);}if (num % 2 0) {prin…...

机器视觉:轮廓匹配算法原理
轮廓匹配的模板变量主要包括模板图像(Template)和待检测图像(Source Image) 在轮廓匹配中,模板变量主要包括一下几个关键部分: 模板图像(Template):这是进行匹配的…...

动力商城-02 环境搭建
1.父工程必须满足:1.1删除src目录 1.2pom 2.依赖继承 //里面的依赖,后代无条件继承<dependencies></dependencies>//里面的依赖,后代想要继承,得自己声明需要使用,可以不写版本号,自动继承&l…...

【react】Redux基础用法
1. Redux基础用法 Redux 是一个用于 JavaScript 应用的状态管理库,它不依赖于任何 UI库,但常用于与 React 框架配合使用。它提供了一种集中式的状态管理方式,将应用的所有状态保存在一个单一的全局 Store(存储)中&…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

Vircadia Native Core:开源虚拟世界服务器核心架构与部署实战
1. 项目概述:一个开源虚拟世界的“引擎心脏”如果你对构建一个属于自己的、去中心化的虚拟世界(Metaverse)感兴趣,或者你正在寻找一个能支撑起大规模、高自由度社交与协作应用的底层平台,那么Vircadia Native Core绝对…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...

深入解析go-containerregistry:无守护进程的容器镜像操作利器
1. 项目概述:容器镜像的“瑞士军刀”如果你在容器化这条路上已经走了一段时间,那么对“镜像”这个概念一定不会陌生。无论是 Docker Hub 上的nginx:latest,还是你公司私有仓库里的myapp:v1.2.3,这些镜像都是容器世界的基石。但你是…...
)
【Midjourney数字艺术风格终极指南】:20年AI视觉专家亲授7大核心风格参数调优法则(含V6.1新增Realism Mode实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney数字艺术风格演进与V6.1核心变革 Midjourney自V1发布以来,其图像生成范式经历了从纹理模拟到语义理解、从风格模仿到跨模态协同的深层跃迁。V6.1标志着模型首次在原生架构中集成…...

ElevenLabs葡萄牙语语音优化黄金7步法:含音频波形对比图、MOS评分提升路径与合规性审查checklist
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs葡萄牙语语音优化的底层逻辑与技术边界 ElevenLabs 对葡萄牙语(尤其是巴西葡萄牙语,pt-BR)的语音合成并非简单地复用英语模型微调,而是基于多阶…...

物联网安防系统故障排查与ESP8266固件刷写实战指南
1. 物联网安防系统故障排查实战做物联网安防系统,最怕的就是“哑火”。你花了好几天时间,把ESP8266、Raspberry Pi、MQTT Broker、Adafruit.IO和IFTTT像搭积木一样连起来,满心期待它能在关键时刻给你发条短信。结果,门被推开了&am…...

AI编码工具选型指南:从原理到实践的全方位解析
1. 项目概述:为什么我们需要一份AI编码工具的“藏宝图”如果你是一名开发者,过去一年里,你的工作流可能已经被AI工具彻底重塑了。从最初用ChatGPT写几行注释,到后来用GitHub Copilot自动补全整段代码,再到如今各种能直…...
)
告别手动点点点:用CAPL脚本实现CANoe诊断自动化测试(附VIN码读取与文件写入完整代码)
告别手动点点点:用CAPL脚本实现CANoe诊断自动化测试(附VIN码读取与文件写入完整代码) 在汽车电子测试领域,诊断功能验证是每个测试工程师的日常必修课。想象一下这样的场景:你需要反复验证几十个ECU的VIN码读取功能&am…...