SQLAlchemy 介绍与实践
postgresql 实践
pydantic 实践
1. SQLAlchemy 介绍
SQLAlchemy 是一个 ORM 框架。SQLAlchemy 是一个用于 Python 的 SQL 工具和对象关系映射(ORM)库。它允许你通过 Python 代码来与关系型数据库交互,而不必直接编写SQL语句。
简单介绍一下对象关系映射吧,对象关系映射(英语:Object Relational Mapping,简称 ORM,或O/RM,或O/R mapping),是一种程序设计技术, 用于实现面向对象编程语言里不同类型系统的数据之间的转换。 从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。大白话:对象模型与数据库表的映射。
1.1. SQLAlchemy 使用场景
SQLAlchemy 是一个强大的 Python ORM 框架,主要应用于以下场景:
数据库访问和操作: SQLAlchemy 提供了高层抽象来操作数据库,可以避免写原生 SQL 语句。支持多种数据库后端(MySQL、MongoDB、SQLite、PostgreSQL)。
ORM映射: 建立 Python 类与数据库表的映射关系,简化数据模型的操作,支持声明式操作。
复杂查询: SQLAlchemy 提供丰富的查询方式,如过滤、分组、联结等,可以构建复杂查询。
异步查询: 基于Greenlet 等实现异步查询,提高查询效率。
事务控制: 通过 Session 管理数据库会话和事务。
工具集成: 如数据迁移工具 Alembic,可以实现 Schema 版本控制和迁移。
大数据集查询: 基于 Pagination 实现数据分页,避免大量数据查询内存溢出。
多数据库支持: 支持 Postgres、MySQL、Oracle 等主流数据库。
Web框架集成: 框架如 Flask 可以集成 SQLAlchemy,便于 Web 应用开发。
2. SQLAlchemy 基本用法
参考:
https://www.jb51.net/python/325524ud6.htm
https://blog.51cto.com/u_13019/12307379
2.1. 安装 SQLAlchemy
在使用 SQLAlchemy 之前,首先需要安装它。可以使用以下命令使用 pip 安装:
pip install sqlalchemy
pip install pymysql # 安装 MySQL
2.2. 连接数据库
使用 SQLAlchemy 连接到数据库,需要提供数据库的连接字符串,其中包含有关数据库类型、用户名、密码、主机和数据库名称的信息。
from sqlalchemy import create_engine# 例如,连接到 SQLite 数据库
engine = create_engine('sqlite:///example.db')# 例如,连接到 MySQL 数据库
username = 'your_mysql_username'
password = 'your_mysql_password'
host = 'your_mysql_host' # 例如:'localhost' 或 '127.0.0.1'
port = 'your_mysql_port' # 通常是 3306
database = 'your_database_name'
# 创建连接引擎
engine = create_engine(f'mysql+pymysql://{username}:{password}@{host}:{port}/{database}')
2.3. 定义数据模型
使用 SQLAlchemy 的 ORM 功能,可以定义 Python 类来映射数据库中的表。每个类对应数据库中的一张表,类的属性对应表中的列。
# 导入必要的模块
from sqlalchemy import Column, Integer, String, Sequence
from sqlalchemy.ext.declarative import declarative_base# 创建一个基类,用于定义数据模型的基本结构
Base = declarative_base()# 定义一个数据模型类,对应数据库中的 'users' 表
class User(Base):# 定义表名__tablename__ = 'users'# 定义列:id,是整数类型,主键(primary_key=True),并使用 Sequence 生成唯一标识id = Column(Integer, Sequence('user_id_seq'), primary_key=True)# 定义列:name,是字符串类型,最大长度为50name = Column(String(50))# 定义列:age,是整数类型age = Column(Integer)
2.4. 创建表
通过在代码中调用 create_all 方法,可以根据定义的模型创建数据库表。
Base.metadata.create_all(engine)
2.5. 插入数据
使用 SQLAlchemy 进行插入数据的操作,首先需要创建一个会话(Session)对象,然后使用该对象添加数据并提交。
# 导入创建会话的模块
from sqlalchemy.orm import sessionmaker# 使用 sessionmaker 创建一个会话类 Session,并绑定到数据库引擎(bind=engine)
Session = sessionmaker(bind=engine)# 创建一个实例化的会话对象 session
session = Session()# 创建一个新的 User 实例,即要插入到数据库中的新用户
new_user = User(name='John Doe', age=30)# 将新用户添加到会话中,即将其添加到数据库操作队列中
session.add(new_user)# 提交会话,将所有在此会话中的数据库操作提交到数据库
session.commit()
2.6. 使用事务添加数据
如果添加过程中发生任何错误,我们将回滚事务,确保数据库的一致性。
try:# 开始一个新的事务session.begin()# 创建新用户对象user1 = User(name='Alice', email='alice@example.com')user2 = User(name='Bob', email='bob@example.com')# 添加到会话中session.add(user1)session.add(user2)# 提交事务,将所有更改保存到数据库session.commit()print("Users added successfully.")
except Exception as e:# 如果在添加用户过程中发生错误,则回滚事务session.rollback()print(f"An error occurred: {e}")
finally:# 关闭会话session.close()
在这个示例中,我们使用 session.begin() 显式地开始了一个新的事务。然后,我们尝试添加两个新用户到会话中。如果在这个过程中没有发生任何错误,我们使用 session.commit() 提交事务,将所有更改保存到数据库中。但是,如果在添加用户的过程中发生了任何异常(例如,由于重复的电子邮件地址或数据库连接问题),我们将使用 session.rollback() 回滚事务,确保数据库的一致性。
2.7. 查询数据
使用 SQLAlchemy 进行查询数据的操作,可以通过查询语句或使用 ORM 查询接口。
# 使用查询语句
result = engine.execute('SELECT * FROM users')# 使用 ORM 查询接口
users = session.query(User).all()
3. 复杂查询条件
3.1. 连接查询(Join)
假设我们有两个模型, User 和 Order ,并且一个用户可以有多个订单。
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class TUsers(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(32))orders = relationship("TOrders", back_populates="user") # 必须关联class TOrders(Base):__tablename__ = 'orders'id = Column(Integer, primary_key=True, autoincrement=True)user_id = Column(Integer, ForeignKey('users.id')) # 必须使用外键product = Column(String(32))quantity = Column(Integer)user = relationship("TUsers", back_populates="orders") # 必须关联
现在,如果我们想要查询所有下过订单的用户及其订单信息,我们可以进行连接查询:
from sqlalchemy.orm import joinedload
# 加载所有用户的订单信息
users_with_orders = session.query(TUsers).options(joinedload(TUsers.orders)).all()
for user in users_with_orders:print(f"User: {user.name}")for order in user.orders:print(f"Order: {order.product}, Quantity: {order.quantity}, Id: {order.id}")
3.1.1. 双向关系(relationship)
更多:
https://blog.csdn.net/JKQ8525350/article/details/139568447
3.2. 分组和聚合(Grouping and Aggregation)
假设我们想要统计每个用户下的订单总数。
from sqlalchemy import func
# 按用户分组,并计算每个用户的订单数量
order_count_by_user = session.query(User.id, User.name, func.count(Order.id).label('order_count')).\join(Order).group_by(User.id, User.name).all()
for user_id, user_name, order_count in order_count_by_user:print(f"User ID: {user_id}, Name: {user_name}, Order Count: {order_count}")
3.3. 子查询(Subquery)
如果我们想要找出订单数量超过平均订单数量的用户,我们可以使用子查询。
from sqlalchemy import func, select
# 计算平均订单数量作为子查询
avg_order_quantity = select([func.avg(Order.quantity).label('avg_quantity')]).select_from(Order).alias()
# 查询订单数量超过平均值的用户及其订单信息
users_above_avg = session.query(User, Order.product, Order.quantity).\join(Order).filter(Order.quantity > avg_order_quantity.c.avg_quantity).all()
for user, product, quantity in users_above_avg:print(f"User: {user.name}, Product: {product}, Quantity: {quantity}")
3.4. 复杂筛选条件(Complex Filtering)
假设我们想要找到名字以 “A” 开头的用户,并且他们的订单中包含 “apple” 这个产品。
# 查询名字以“A”开头的用户,且订单中包含“apple”产品的用户信息
users_with_apple = session.query(User).join(Order).\filter(User.name.startswith('A')).\filter(Order.product.contains('apple')).\distinct().all() # 使用distinct() 确保结果中的用户不重复
for user in users_with_apple:print(f"User: {user.name}")
3.5. 分页查询
3.5.1. limit
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine# 假设已经有了一个定义好的模型和数据库引擎
engine = create_engine('sqlite:///example.db')
Session = sessionmaker(bind=engine)
session = Session()# 分页查询函数
def paginate_query(page, page_size):# 计算跳过的记录数offset = (page - 1) * page_size# 执行分页查询results = session.query(YourModel).order_by(YourModel.id).offset(offset).limit(page_size).all()return results# 使用分页查询
page = 1
page_size = 10
records = paginate_query(page, page_size)
3.5.2. slice
total = session.query(YourModel).with_entities(func.count(YourModel.id)).scalar()
db_query = session.query(YourModel).slice(page_start, page_end)
4. SQLAlchemy 实践1
4.1. 定义数据模型类
我们定义三个数据模型类:User(用户)、Post(文章)和Comment(评论)。这些类之间通过外键和关系进行关联。
# 导入 SQLAlchemy 中所需的模块
from sqlalchemy import create_engine, Column, Integer, String, Text, ForeignKey
from sqlalchemy.orm import declarative_base, relationship# 创建一个基类,用于定义数据模型的基本结构
Base = declarative_base()# 定义数据模型类 User,对应数据库中的 'users' 表
class User(Base):__tablename__ = 'users'# 定义列:id,是整数类型,作为主键id = Column(Integer, primary_key=True)# 定义列:username,是字符串类型,最大长度为50,唯一且不可为空username = Column(String(50), unique=True, nullable=False)# 定义列:email,是字符串类型,最大长度为100,唯一且不可为空email = Column(String(100), unique=True, nullable=False)# 定义关系,与 Post 类的关系为一对多关系,通过 back_populates 指定反向关系属性名posts = relationship('Post', back_populates='author')# 定义数据模型类 Post,对应数据库中的 'posts' 表
class Post(Base):__tablename__ = 'posts'# 定义列:id,是整数类型,作为主键id = Column(Integer, primary_key=True)# 定义列:title,是字符串类型,最大长度为100,不可为空title = Column(String(100), nullable=False)# 定义列:content,是文本类型,不可为空content = Column(Text, nullable=False)# 定义列:user_id,是整数类型,外键关联到 'users' 表的 id 列user_id = Column(Integer, ForeignKey('users.id'))# 定义关系,与 User 类的关系为多对一关系,通过 back_populates 指定反向关系属性名author = relationship('User', back_populates='posts')# 定义关系,与 Comment 类的关系为一对多关系,通过 back_populates 指定反向关系属性名comments = relationship('Comment', back_populates='post')# 定义数据模型类 Comment,对应数据库中的 'comments' 表
class Comment(Base):__tablename__ = 'comments'# 定义列:id,是整数类型,作为主键id = Column(Integer, primary_key=True)# 定义列:text,是文本类型,不可为空text = Column(Text, nullable=False)# 定义列:user_id,是整数类型,外键关联到 'users' 表的 id 列user_id = Column(Integer, ForeignKey('users.id'))# 定义列:post_id,是整数类型,外键关联到 'posts' 表的 id 列post_id = Column(Integer, ForeignKey('posts.id'))# 定义关系,与 User 类的关系为多对一关系author = relationship('User')# 定义关系,与 Post 类的关系为多对一关系,通过 back_populates 指定反向关系属性名post = relationship('Post', back_populates='comments')
4.2. 创建数据库引擎和会话
这里我们选择了 SQLite 数据库,并使用 create_all 创建相应的表。
# 导入 SQLAlchemy 中所需的模块
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 创建一个 SQLite 数据库引擎,连接到名为 'blog.db' 的数据库文件
engine = create_engine('sqlite:///blog.db')# 使用 Base 对象的 metadata 属性,创建数据库中定义的所有表
Base.metadata.create_all(engine)# 使用 sessionmaker 创建一个会话类 Session,并将其绑定到上面创建的数据库引擎
Session = sessionmaker(bind=engine)# 创建一个实例化的会话对象 session,用于进行数据库操作
session = Session()
4.3. 进行数据库操作
这段代码演示了如何使用 SQLAlchemy 对数据库进行插入和查询操作。首先,创建了一个用户、一篇文章和一条评论,然后通过查询用户的方式,打印出该用户的所有文章及评论。
# 创建一个新用户对象并设置其属性
user1 = User(username='john_doe', email='john@example.com')# 将新用户对象添加到会话,表示要进行数据库插入操作
session.add(user1)# 提交会话,将所有在此会话中的数据库操作提交到数据库
session.commit()# 创建一篇新文章对象并设置其属性
post1 = Post(title='Introduction to SQLAlchemy', content='SQLAlchemy is a powerful ORM for Python.')# 将文章的作者关联到之前创建的用户
post1.author = user1# 将新文章对象添加到会话,表示要进行数据库插入操作
session.add(post1)# 提交会话,将所有在此会话中的数据库操作提交到数据库
session.commit()# 创建一条新评论对象并设置其属性
comment1 = Comment(text='Great article!', author=user1, post=post1)# 将评论对象添加到会话,表示要进行数据库插入操作
session.add(comment1)# 提交会话,将所有在此会话中的数据库操作提交到数据库
session.commit()# 查询用户名为 'john_doe' 的用户,并打印其所有文章及评论
user = session.query(User).filter_by(username='john_doe').first()
print(f"User: {user.username}")# 遍历用户的所有文章
for post in user.posts:print(f"Post: {post.title}")# 遍历文章的所有评论for comment in post.comments:print(f"Comment: {comment.text}")
5. SQLAlchemy 实践2 数据库初始化操作
入口 main.py
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, database_existsfrom database import Base
from schemas import UserBase, OrderBasedef is_db_exist(db_url: str):engine = create_engine(db_url, max_overflow=0, pool_size=16, pool_timeout=5, pool_recycle=-1)if not database_exists(engine.url):create_database(engine.url)return Falseelse: return Truedef init_database(db_url: str):# 设置连接池的大小engine = create_engine(db_url, max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=16, # 连接池大小pool_timeout=5, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置))# 创建数据库Base.metadata.create_all(engine)if __name__ == '__main__':# 数据库参考db_host = "127.0.0.1"db_user = "root"db_password = "lianap"db_url = '%s%s:%s@%s/%s' % ("mysql+pymysql://", db_user, db_password, db_host, "local_db")if not is_db_exist(db_url):init_database(db_url)from alchemy import AlchemyToolalchemytool = AlchemyTool(db_url=db_url)db_user = alchemytool.create_user("test_user")alchemytool.create_order(db_user.id)alchemytool.select()
数据表结构 database.py
from sqlalchemy import Column, Integer, String, DateTime, Text, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship# sqlalchemy
Base = declarative_base()class TUsers(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(32))orders = relationship("TOrders", back_populates="user") # 必须使用class TOrders(Base):__tablename__ = 'orders'id = Column(Integer, primary_key=True, autoincrement=True)user_id = Column(Integer, ForeignKey('users.id')) # 必须使用外键product = Column(String(32))quantity = Column(Integer)user = relationship("TUsers", back_populates="orders") # 必须使用
数据结构体 schemas.py
from pydantic import BaseModel, Field
from typing import Union, Optional, Literal, List, Dict## 任务基础结构体
class OrderBase(BaseModel):id: intuser_id: intproduct: strquantity: intclass Config:from_attributes=Trueclass UserBase(BaseModel):id: int name: strorders: List[OrderBase]class Config:from_attributes=True
数据库操作 alchemy.py
from sqlalchemy import create_engine, and_, or_, func
from sqlalchemy.exc import SQLAlchemyError
from sqlalchemy.orm import sessionmaker, joinedload
from sqlalchemy.pool import SingletonThreadPoolfrom database import Base
from database import TUsers, TOrders
from schemas import UserBase, OrderBaseclass AlchemyTool(object):def __init__(self, db_url: str):print("AlchemyTool init")# 设置连接池的大小db_config = {"pool_size": 10}#engine = create_engine(SQLALCHEMY_DATABASE_URL, **db_config)# engine = create_engine(db_url, # #poolclass = SingletonThreadPool,# connect_args = {'check_same_thread': False}# )engine = create_engine(db_url, max_overflow=0, pool_size=16, pool_timeout=5, pool_recycle=-1)# # 创建数据库# Base.metadata.create_all(engine)# 创建数据库连接self.__session = sessionmaker(autocommit=False, autoflush=False, bind=engine)()# ############################### User ###############################def create_user(self, name:str):db_location = Nonetry:db_location = TUsers(name=name)self.__session.add(db_location)self.__session.commit()except SQLAlchemyError as e:print(f"Error.AlchemyTool.create_user SQLAlchemyError:{str(e)}")self.__session.rollback()finally:passreturn db_locationdef create_order(self, user_id: int=1):db_location = Nonetry:# self.__session.begin()for index in range(5):db_location = TOrders(user_id=user_id, product=f"product{index}", quantity=index)self.__session.add(db_location)self.__session.commit()except SQLAlchemyError as e:print(f"Error.AlchemyTool.create_order SQLAlchemyError:{str(e)}")self.__session.rollback()finally:passreturn db_locationdef select(self):users_with_orders = self.__session.query(TUsers).options(joinedload(TUsers.orders)).all()for user in users_with_orders:user_base = UserBase.from_orm(user) # 一次性转换成 UserBase(包含List[OrderBase])print(f"UserBase: {user_base}")for order in user.orders:# print(f"Order: {order.product}, Quantity: {order.quantity}, Id: {order.id}")pass
运行结果
> python.exe .\main.py
AlchemyTool init
UserBase: id=1 name='test_user' orders=[OrderBase(id=1, user_id=1, product='product0', quantity=0), OrderBase(id=2, user_id=1, product='product1', quantity=1), OrderBase(id=3, user_id=1, product='product2', quantity=2), OrderBase(id=4, user_id=1, product='product3', quantity=3), OrderBase(id=5, user_id=1, product='product4', quantity=4)]
相关文章:

SQLAlchemy 介绍与实践
postgresql 实践 pydantic 实践 1. SQLAlchemy 介绍 SQLAlchemy 是一个 ORM 框架。SQLAlchemy 是一个用于 Python 的 SQL 工具和对象关系映射(ORM)库。它允许你通过 Python 代码来与关系型数据库交互,而不必直接编写SQL语句。 简单介绍一下…...

docker进行SRS直播服务器搭建
docker进行SRS直播服务器搭建 docker构建参考地址: 地址: https://github.com/ossrs/srs https://ossrs.net/lts/zh-cn/docs/v5/doc/getting-started docker run --rm -it -p 1935:1935 -p 1985:1985 -p 8080:8080 \-p 8000:8000/udp -p 10080:10080/udp ossrs/sr…...

windows server2019下载docker拉取redis等镜像并运行项目
一、基本概念 1、windows server 指由微软公司开发的“Windows”系列中的“服务器”版本。这意味着它是基于Windows操作系统的,但专门设计用于服务器环境,而不是普通的桌面或个人用户使用。主要用途包括服务器功能、用户和资源管理、虚拟化等 2、dock…...

数据结构(8.7_2)——败者树
多路平衡归并带来的问题 什么是败者树 败者树的构造 败者树的使用 败者树在多路平衡归并中的应用 败者树的实现思路 总结...

设计模式-七个基本原则之一-里氏替换原则
里氏替换原则(LSP)面向对象六个基本原则之一 子类与父类的替代性:子类应当能够替代父类出现的任何地方,且表现出相同的行为。行为的一致性:子类的行为必须与父类保持一致,包括输入和输出、异常处理等。接口…...

k8s中基于overlay网络和underlay网络的网络插件分别有哪些
在 Kubernetes 中,不同的网络插件会使用 overlay 或 underlay 网络来连接 Pod 和节点。以下是基于 overlay 网络和 underlay 网络的常见 Kubernetes 网络插件: 1. 基于 Overlay 网络的插件 这些插件通过隧道封装技术(如 VXLAN、GRE 等&#…...

一文详解java的数据类型
1. 题记 Java是一门对数据类型敏感的语言,本博文主要总结介绍java语言的数据类型。 2. java的数据类型 Java 的数据类型分为基本数据类型(Primitive Data Types)和引用数据类型(Reference Data Types)。 2.1 基本数…...

Flink API 的层次结构
Apache Flink 提供了多层 API,每层 API 针对不同的抽象层次和用途,使得开发者可以根据具体需求选择合适的 API 层次。以下是 Flink API 的层次结构及其简要说明:...

lua入门教程:math
在Lua中,math库是一个非常重要的内置库,它提供了许多用于数学计算的函数。这些函数可以处理各种数学运算,包括基本的算术运算、三角函数、对数函数、随机数生成等。结合你之前提到的Lua中的数字遵循IEEE 754双精度浮点标准,我们可…...

ROS2简介与Ubuntu24.04中安装指南
之前安装了一个版本,但是不愿意写blog,现在想想自己就是个沙子立个flag,每次配置项目,写流程blog ROS简介 ROS(Robot Operating System)是一个开源的机器人软件平台,提供了许多工具和库来帮助…...
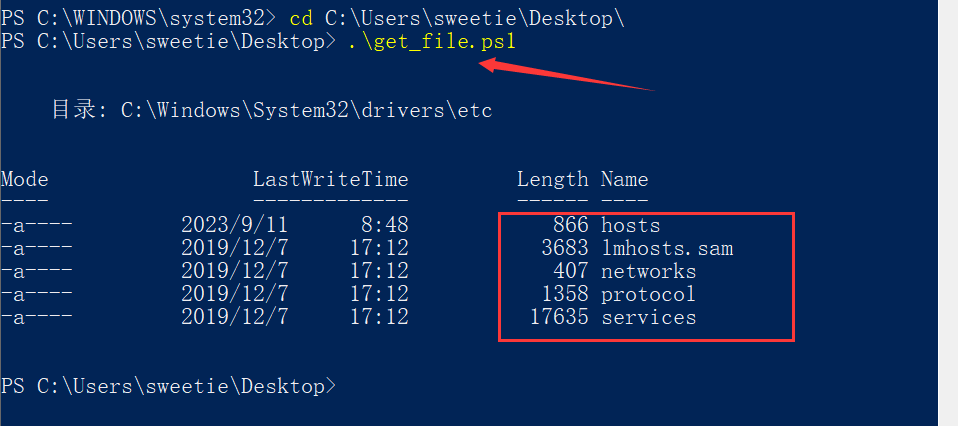
命令行工具PowerShell使用体验
命令行工具PowerShell使用 PowerShell是微软开发的一种面向对象的命令行Shell和脚本语言环境,它允许用户通过命令行的方式管理操作系统。相较于传统CMD,PowerShell增加了面向对象的程序设计框架,拥有更强大的功能和扩展性。使用PowerShell可…...

MongoDB 详解:深入理解与探索
在当今的数据库领域,MongoDB 以其独特的特性和强大的功能,成为了众多开发者和企业的首选。本文将对 MongoDB 进行详细的介绍,包括其特点、应用场景、流程图以及源码分析。 一、MongoDB 概述 MongoDB 是一个基于分布式文件存储的开源数据库系…...

使用 Elasticsearch 构建食谱搜索(一)
作者:来自 Elastic Andre Luiz 了解如何使用 Elasticsearch 构建基于语义搜索的食谱搜索。 简介 许多电子商务网站都希望增强其食谱搜索体验。正确使用语义搜索可以让客户根据更自然的查询(例如 “something for Valentines Day - 情人节的礼物” 或 “…...

sealos部署K8s,安装docker时master节点突然NotReady
1、集群正常运行中,在集群master-1上安装了dockerharbor,却发现master-1节点NotReady,使用的网络插件为 Cilium #安装docker和harbor(docker运行正常) rootmaster-1:/etc/apt# apt install docker-ce5:19.03.15~3-0~u…...

使用vite+react+ts+Ant Design开发后台管理项目(五)
前言 本文将引导开发者从零基础开始,运用vite、react、react-router、react-redux、Ant Design、less、tailwindcss、axios等前沿技术栈,构建一个高效、响应式的后台管理系统。通过详细的步骤和实践指导,文章旨在为开发者揭示如何利用这些技术…...

Spring Boot实现多数据源连接和切换
文章目录 前言一、多数据源配置与切换方案二、实现步骤1. 创建多个 DataSource 配置类2. 创建 DataSource 配置类3. 创建动态数据源路由类4. 实现 DynamicDataSource 类5. 创建 DataSourceContextHolder 来存储当前的数据源标识6. AOP 方式切换数据源7. 自定义注解来指定数据源…...

发布 VectorTraits v3.0(支持 X86架构的Avx512系列指令集,支持 Wasm架构及PackedSimd指令集等)
文章目录 支持 X86架构的Avx512系列指令集支持Avx512时的输出信息 支持 Wasm架构及PackedSimd指令集支持PackedSimd时的输出信息VectorTraits.Benchmarks.Wasm 使用说明 新增了向量方法支持 .NET 8.0 新增的向量方法提供交织与解交织的向量方法YGroup3Unzip的范例代码 提供重新…...
详解如何创建SpringBoot项目
目录 点击New Project 选择依赖 简单使用SpringBoot 前面已经讲解了如何获取IDEA专业版,下面将以此为基础来讲解如何创建SpringBoot项目。 点击New Project 选择依赖 注意,在选择SpringBoot版本时,不要选择带SNAPSHOT的版本。 这样&#…...

IT架构管理
目录 总则 IT架构管理目的 明确组织与职责 IT架构管理旨在桥接技术实施与业务需求之间的鸿沟,通过深入理解业务战略和技术能力,推动技术创新以支持业务增长,实现技术投资的最大价值。 设定目标与范围 IT架构管理的首要目的是确立清晰的组织…...

Feign入门实践
引言 随着微服务架构的兴起,服务间的通信变得越来越频繁和复杂。为了简化服务之间的调用过程,提高开发效率和系统的可维护性,Spring Cloud 生态系统提供了多种解决方案,其中 OpenFeign 是一种声明式的 HTTP 客户端,它使…...

安卓蓝牙开发避坑指南:Bluedroid初始化流程中的5个关键细节
安卓蓝牙开发避坑指南:Bluedroid初始化流程中的5个关键细节 在安卓蓝牙协议栈开发中,Bluedroid的初始化流程是系统与蓝牙硬件建立通信的基础桥梁。许多看似随机的蓝牙功能异常,往往源于初始化阶段某些参数的微妙配置差异。本文将深入剖析五个…...

Qwen3-Reranker-8B企业落地:保险条款智能比对系统重排模块部署
Qwen3-Reranker-8B企业落地:保险条款智能比对系统重排模块部署 1. 项目背景与需求场景 保险行业每天需要处理大量的条款文档比对工作,比如新老条款对比、不同产品条款差异分析、合规性检查等。传统的人工比对方式效率低下,容易出错…...

Suricata在CentOS7上的性能优化:如何配置网卡混杂模式与端口聚合
Suricata在CentOS7上的性能优化:网卡混杂模式与端口聚合实战指南 当企业网络流量突破千兆级别时,传统单网卡监控方案往往力不从心。我曾为某金融客户部署Suricata时,单台服务器每天要处理超过2TB的流量数据,正是通过下文介绍的网卡…...

Vue项目里用Frappe-Gantt 0.6.1做项目管理甘特图,我踩过的坑都在这了
Vue项目中集成Frappe-Gantt的避坑指南与工程化实践 在最近的一个敏捷开发项目中,我们需要为产品团队提供一个直观的任务进度管理工具。经过几轮技术选型,最终选择了Frappe-Gantt 0.6.1作为基础组件。这个选择并非一帆风顺——从最初的简单集成到最终形成…...

OpenClaw极简部署:Qwen3-VL:30B镜像+飞书5分钟接入
OpenClaw极简部署:Qwen3-VL:30B镜像飞书5分钟接入 1. 为什么选择这个组合? 上周我在测试各种开源模型与自动化工具的搭配方案时,发现了一个效率极高的组合:星图平台的Qwen3-VL:30B镜像OpenClaw框架。这个方案最吸引我的地方在于…...

避坑指南:Pyannote3.1+Whisper本地部署的5个常见报错解决方案
避坑指南:Pyannote3.1Whisper本地部署的5个常见报错解决方案 语音处理技术正在重塑教育、会议记录和客服质检等场景的交互方式。当开发者尝试将Whisper的精准语音识别与Pyannote的说话人分离能力结合时,常会在环境配置环节遭遇"拦路虎"。本文…...

QobuzDownloaderX-MOD:一站式高品质音乐下载解决方案
QobuzDownloaderX-MOD:一站式高品质音乐下载解决方案 【免费下载链接】QobuzDownloaderX-MOD Downloads streams directly from Qobuz. Experimental refactoring of QobuzDownloaderX by AiiR 项目地址: https://gitcode.com/gh_mirrors/qo/QobuzDownloaderX-MOD…...

无人机控制中的模糊控制:一维与二维模糊控制及其实现要点
无人机 控制方面 模糊控制 有一维模糊和二维模糊两种,文字说明资料已遗失,数学模型可以根据仿真图推导,直接运维simulink会报错,是因为没有导入模糊规则,在运行simulink之前需要在命令窗口输入workreadfis work.fis ,这…...

背包问题Ⅱ与二分问题
今天我对背包问题有了更深的理解,我一定要写下来,巩固自己的思路并且,遇到新的难题二分,不管了,干就完了!!!完全背包以今天写的代码展开详细描述与解释,并附上题目#define N 1001 in…...

Leather Dress Collection惊艳效果:Leather_Romper皮连体衣+户外场景自然光渲染
Leather Dress Collection惊艳效果:Leather_Romper皮连体衣户外场景自然光渲染 1. 项目介绍 Leather Dress Collection 是一个基于Stable Diffusion 1.5的LoRA模型集合,专门用于生成各种皮革服装风格的图像。这个系列由Stable Yogi开发,包含…...