list集合常见去重方式以及效率对比
1.概述
list集合去重是开发中比较常用的操作,在面试中也会经常问到,那么list去重都有哪些方式?他们之间又该如何选择呢?
本文将通过LinkedHashSet、for循环、list流toSet、list流distinct等4种方式分别做1W数据到1000W数据单元测试,对比去重效率
2.代码实现
2.1准备工作
构建list集合,往里面插入数据,在插入几条重复数据,用jdk自带的System.currentTimeMillis()做计时器。
import java.util.ArrayList;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.stream.Collectors;public class Test {public static void main(String[] args) {List<String> list1 = initList(10000);test(list1);List<String> list2 = initList(50000);test(list2);List<String> list3 = initList(100000);test1(list3);List<String> list4 = initList(500000);test1(list4);List<String> list5 = initList(1000000);test1(list5);List<String> list6 = initList(2000000);test1(list6);List<String> list7 = initList(3000000);test1(list7);List<String> list8 = initList(5000000);test1(list8);List<String> list9 = initList(10000000);test1(list9);}public static List<String> initList(int num){System.out.println("--------------------------");final List<String> list = new ArrayList<>();for (int i = 0; i < num; i++) {list.add("haha-"+ i);}list.add("haha-"+ 1000);list.add("haha-"+ 2000);list.add("haha-"+ 3000);System.out.println("list 初始化完毕 size = " + list.size());return list;}public static void test(List<String> list){long startLong = System.currentTimeMillis();List<String> list1 = removeDuplicate(list);System.out.println("去重后,集合元素个数 :" + list1.size());long endLong = System.currentTimeMillis();System.out.println("LinkedHashSet 测试完毕,实际耗时:"+ (endLong-startLong) +" ,ms");long startLong1 = System.currentTimeMillis();List<String> list2 = removeDuplicate1(list);System.out.println("去重后,集合元素个数 :" + list2.size());long endLong1 = System.currentTimeMillis();System.out.println("for增强型循环 测试完毕,实际耗时:"+ (endLong1-startLong1) +" ,ms");long startLong2 = System.currentTimeMillis();List<String> list3 = removeDuplicate2(list);System.out.println("去重后,集合元素个数 :" + list3.size());long endLong2 = System.currentTimeMillis();System.out.println("list流toSet方式 测试完毕,实际耗时:"+ (endLong2-startLong2) +" ,ms");long startLong3 = System.currentTimeMillis();List<String> list4 = removeDuplicate3(list);System.out.println("去重后,集合元素个数 :" + list4.size());long endLong3 = System.currentTimeMillis();System.out.println("list流distinct方式 测试完毕,实际耗时:"+ (endLong3-startLong3) +" ,ms");System.out.println("--------------------------");}public static void test1(List<String> list){long startLong = System.currentTimeMillis();List<String> list1 = removeDuplicate(list);System.out.println("去重后,集合元素个数 :" + list1.size());long endLong = System.currentTimeMillis();System.out.println("LinkedHashSet 测试完毕,实际耗时:"+ (endLong-startLong) +" ,ms");long startLong2 = System.currentTimeMillis();List<String> list3 = removeDuplicate2(list);System.out.println("去重后,集合元素个数 :" + list3.size());long endLong2 = System.currentTimeMillis();System.out.println("list流toSet方式 测试完毕,实际耗时:"+ (endLong2-startLong2) +" ,ms");long startLong3 = System.currentTimeMillis();List<String> list4 = removeDuplicate3(list);System.out.println("去重后,集合元素个数 :" + list4.size());long endLong3 = System.currentTimeMillis();System.out.println("list流distinct方式 测试完毕,实际耗时:"+ (endLong3-startLong3) +" ,ms");System.out.println("--------------------------");}private static List<String> removeDuplicate(List<String> list) {return new ArrayList<>(new LinkedHashSet<>(list));}private static List<String> removeDuplicate1(List<String> list) {List<String> result = new ArrayList<String>(list.size());for (String str : list) {if (!result.contains(str)) {result.add(str);}}return result;}private static List<String> removeDuplicate2(List<String> list) {return list.stream().collect(Collectors.toSet()).stream().collect(Collectors.toList());}private static List<String> removeDuplicate3(List<String> list) {return list.stream().distinct().collect(Collectors.toList());}}2.2输出结果
--------------------------
list 初始化完毕 size = 10003
去重后,集合元素个数 :10000
LinkedHashSet 测试完毕,实际耗时:7 ,ms
去重后,集合元素个数 :10000
for增强型循环 测试完毕,实际耗时:342 ,ms
去重后,集合元素个数 :10000
list流toSet方式 测试完毕,实际耗时:89 ,ms
去重后,集合元素个数 :10000
list流distinct方式 测试完毕,实际耗时:5 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 50003
去重后,集合元素个数 :50000
LinkedHashSet 测试完毕,实际耗时:12 ,ms
去重后,集合元素个数 :50000
for增强型循环 测试完毕,实际耗时:6059 ,ms
去重后,集合元素个数 :50000
list流toSet方式 测试完毕,实际耗时:12 ,ms
去重后,集合元素个数 :50000
list流distinct方式 测试完毕,实际耗时:5 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 100003
去重后,集合元素个数 :100000
LinkedHashSet 测试完毕,实际耗时:14 ,ms
去重后,集合元素个数 :100000
list流toSet方式 测试完毕,实际耗时:13 ,ms
去重后,集合元素个数 :100000
list流distinct方式 测试完毕,实际耗时:13 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 500003
去重后,集合元素个数 :500000
LinkedHashSet 测试完毕,实际耗时:101 ,ms
去重后,集合元素个数 :500000
list流toSet方式 测试完毕,实际耗时:40 ,ms
去重后,集合元素个数 :500000
list流distinct方式 测试完毕,实际耗时:34 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 1000003
去重后,集合元素个数 :1000000
LinkedHashSet 测试完毕,实际耗时:75 ,ms
去重后,集合元素个数 :1000000
list流toSet方式 测试完毕,实际耗时:93 ,ms
去重后,集合元素个数 :1000000
list流distinct方式 测试完毕,实际耗时:162 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 2000003
去重后,集合元素个数 :2000000
LinkedHashSet 测试完毕,实际耗时:140 ,ms
去重后,集合元素个数 :2000000
list流toSet方式 测试完毕,实际耗时:2807 ,ms
去重后,集合元素个数 :2000000
list流distinct方式 测试完毕,实际耗时:231 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 3000003
去重后,集合元素个数 :3000000
LinkedHashSet 测试完毕,实际耗时:177 ,ms
去重后,集合元素个数 :3000000
list流toSet方式 测试完毕,实际耗时:654 ,ms
去重后,集合元素个数 :3000000
list流distinct方式 测试完毕,实际耗时:417 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 5000003
去重后,集合元素个数 :5000000
LinkedHashSet 测试完毕,实际耗时:307 ,ms
去重后,集合元素个数 :5000000
list流toSet方式 测试完毕,实际耗时:6364 ,ms
去重后,集合元素个数 :5000000
list流distinct方式 测试完毕,实际耗时:711 ,ms
--------------------------
--------------------------
list 初始化完毕 size = 10000003
去重后,集合元素个数 :10000000
LinkedHashSet 测试完毕,实际耗时:738 ,ms
去重后,集合元素个数 :10000000
list流toSet方式 测试完毕,实际耗时:1790 ,ms
去重后,集合元素个数 :10000000
list流distinct方式 测试完毕,实际耗时:1746 ,ms
--------------------------3.总结
3.1 for循环方式去重(谨慎使用)
原因有2点:1.代码不简洁;2.耗时随着数据增大性能显著增高
3.2 LinkedHashSet(推荐)
LinkedHashSet是jdk自带的,所以jdk所有版本都支持使用,按照测试结果来说,对于方便和性能要求不那么极限的来说无脑使用LinkedHashSet是最方便的的。list流distinct在70w数据以下都会比LinkedHashSet效率高。
3.3 list流toSet(不推荐)
按照测试结果,list流的toSet方式在不同数据量的效率有很大的波动,且在任意测试节点都没有LinkedHashSet或者list流distinct效率高,所以也不推荐使用。
3.4 list流distinct(推荐)
list流是jdk8及以上提供的特性,在实际场景中,去重数据量超过10W基本没有,只要jdk支持list流那么使用list流distinct
综上:遵循jdk8以下用LinkedHashSet,jdk8及以上用list流distinct
相关文章:

list集合常见去重方式以及效率对比
1.概述 list集合去重是开发中比较常用的操作,在面试中也会经常问到,那么list去重都有哪些方式?他们之间又该如何选择呢? 本文将通过LinkedHashSet、for循环、list流toSet、list流distinct等4种方式分别做1W数据到1000W数据单元测试…...

JavaWeb——Web入门(7/9)-Tomcat-介绍(Tomcat 的简介:轻量级Web服务器,支持Servlet/JSP少量JavaEE规范)
目录 Web服务器的作用 三个方面的讲解 Tomcat 的简介 小结 Web服务器的作用 封装 HTTP 协议操作:Web服务器是一个软件程序,对 HTTP 协议的操作进行了封装。这样开发人员就不需要再直接去操作 HTTP 协议,使得外部应用程序的开发更加便捷、…...

【SpringBoot】19 文件/图片下载(MySQL + Thymeleaf)
Git仓库 https://gitee.com/Lin_DH/system 介绍 从 MySQL 中,下载保存的 blob 格式的文件。 代码实现 第一步:配置文件 application.yml spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT8datasource:driver-class-name: com.mysql.…...

陪诊问诊APP开发实战:基于互联网医院系统源码的搭建详解
时下,开发一款功能全面、用户体验良好的陪诊问诊APP成为了医疗行业的一大热点。本文将结合互联网医院系统源码,详细解析陪诊问诊APP的开发过程,为开发者提供实用的开发方案与技术指导。 一、陪诊问诊APP的背景与功能需求 陪诊问诊APP核心目…...

Spark 中 RDD 的诞生:原理、操作与分区规则
Spark 的介绍与搭建:从理论到实践-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式之Yarn模式的原…...

c++构造与析构
构造函数特性 名称与类名相同:构造函数的名称必须与类名完全相同,并且不能有返回值类型(包括void)。 自动调用:构造函数在对象实例化时自动调用,不需要手动调用。 初始化成员变量:构造函数的主…...

C++(函数重载,引用,nullptr)
1.函数重载 C⽀持在同⼀作⽤域中出现同名函数,但是要求这些同名函数的形参不同,可以是参数个数不同或者类型不同。传参时会自动匹配传入的参数,对应该函数的形参类型,进行函数调用,这样C函数调⽤就表现出了多态⾏为&a…...

django+postgresql
PostgreSQL概述 PostgreSQL 是一个功能强大的开源关系数据库管理系统(RDBMS),以其高度的稳定性、扩展性和社区支持而闻名。PostgreSQL 支持 SQL 标准并具有很多先进特性,如 ACID 合规、复杂查询、外键支持、事务处理、表分区、JS…...
)
前端滚动锚点(点击后页面滚动到指定位置)
三个常用方案:1.scrollintoView 把调用该方法的元素滚动到屏幕的指定位置,中间,底部,或者顶部 优点:方便,只需要获取元素然后调用 缺点:不好精确控制,只能让元素指定滚动到中间&…...

使用SSL加密465端口发送邮件
基于安全考虑,云虚拟主机的25端口默认封闭,如果您有发送邮件的需求,建议使用SSL加密端口(465端口)来对外发送邮件。本文通过提供.NET、PHP和ASP样例来介绍使用SSL加密端口发送邮件的方法,其他语言的实现思路…...
一些面试题总结(一)
1、string为什么是不可变的,有什么好处 原因: 1、因为String类下的value数组是用final修饰的,final保证了value一旦被初始化,就不可改变其引用。 2、此外,value数组的访问权限为 private,同时没有提供方…...

泄露的文档显示 Google 似乎意识到了 Tensor 处理器存在过热问题
Google 知道其 Tensor 芯片存在一些问题,尤其是在过热和电池寿命方面,显然他们正在努力通过即将推出的代号为"Malibu"的 Tensor G6 来解决这一问题。 Android Authority 泄露的幻灯片显示,过热是基于 Tensor 的 Pixel 手机退换货的…...
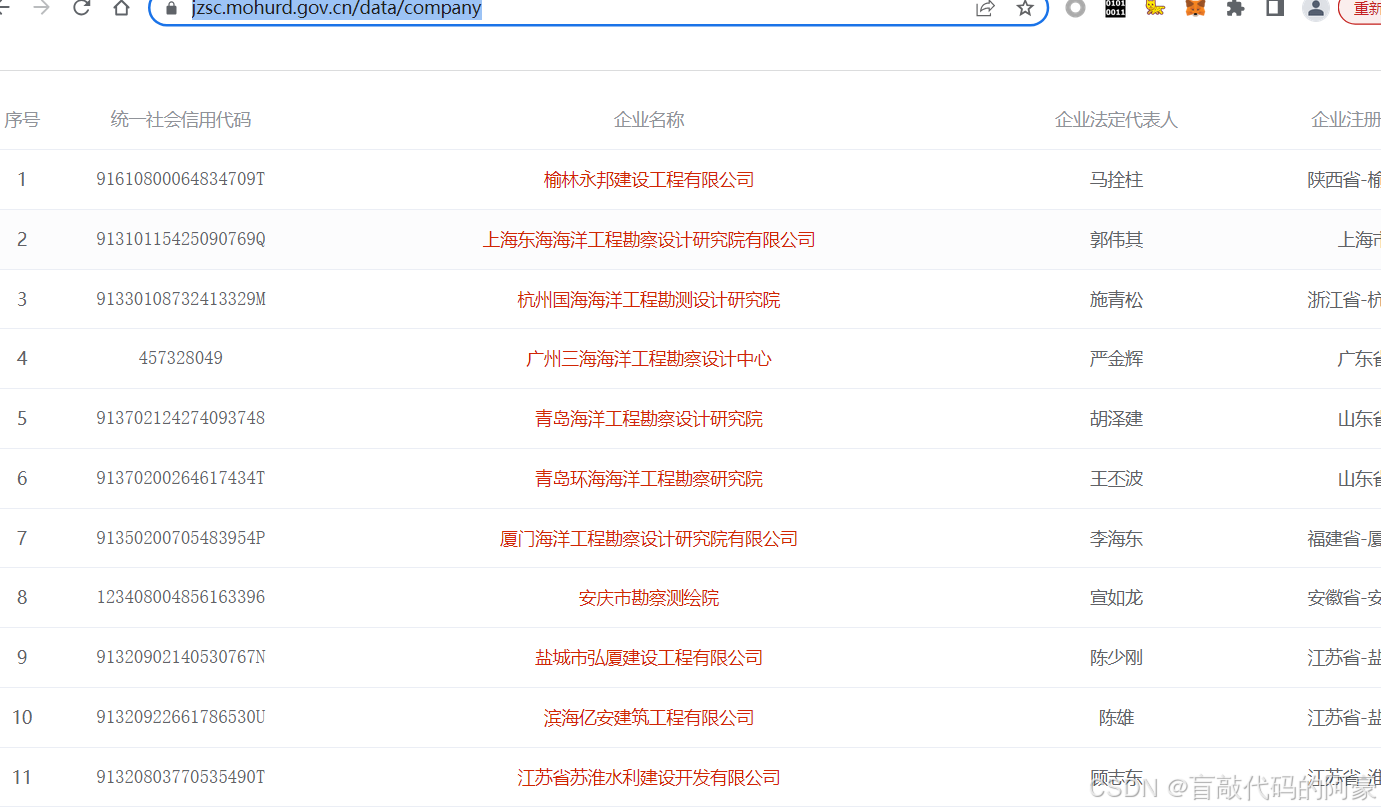
python爬虫案例——网页源码被加密,解密方法全过程
文章目录 1、任务目标2、网页分析3、代码编写1、任务目标 目标网站:https://jzsc.mohurd.gov.cn/data/company,该网站的网页源码被加密了,用于本文测验 要求:解密该网站的网页源码,请求网站并返回解密后的明文数据,网页内容如下: 2、网页分析 进入网站,打开开发者模式,…...

2.4_SSRF服务端请求伪造
SSRF服务端请求伪造 定义:服务端请求伪造。是一种攻击者构造请求后,交由服务端发起请求的漏洞; 产生原理:该服务器提供了从其他服务器获取数据的功能,但没有对用户提交的数据做严格校验; 利用条件&#…...

数据分析反馈:提升决策质量的关键指南
内容概要 在当今快节奏的商业环境中,数据分析与反馈已成为提升决策质量的重要工具。数据分析不仅能为企业提供全面的市场洞察,还能帮助管理层深入了解客户需求与行为模式。掌握数据收集的有效策略和工具,企业能够确保获得准确且相关的信息&a…...

一步步安装deeponet的详细教学
1.deepoent官网如下: https://github.com/lululxvi/deeponet 需要下载依赖 1.python3 2.DeepXDE(这里安装DeepXDE<0.11.2,这个最方便) Optional: For CNN, install Matlab and TensorFlow 1; for Seq2Seq, install PyTorch࿰…...

Devops业务价值流:版本发布最佳实践
敏捷开发中,版本由多个迭代构建而成,每个迭代都是产品进步的一环。当版本最后一个迭代完成时,便启动了至关重要的上线流程。版本发布流程与规划流程相辅相成,确保每个迭代在版本中有效循环执行,最终达成产品目标。 本…...

背包问题(三)
文章目录 一、二维费用的背包问题二、潜水员三、机器分配四、开心的金明五、有依赖的背包问题 一、二维费用的背包问题 题目链接 #include<iostream> #include<algorithm> using namespace std; const int M 110; int n,m,kg; int f[M][M];int main() {cin >…...

linux之调度管理(2)-调度器 如何触发运行
一、调度器是如何在程序稳定运行的情况下进行进程调度的 1.1 系统定时器 因为我们主要讲解的是调度器,而会涉及到一些系统定时器的知识,这里我们简单讲解一下内核中定时器是如何组织,又是如何通过通过定时器实现了调度器的间隔调度。首先我们…...

深入理解 Vue 3 中的 Props
深入理解 Vue 3 中的 Props Vue 3 引入了 Composition API 等新特性,组件的定义和使用也变得更为灵活。而在组件通信中,Props(属性)扮演了重要角色,帮助父组件向子组件传递数据,形成单向的数据流动&#x…...
和滚动统计为预测模型打好基础)
你的时间序列真的平稳吗?手把手教你用ADF检验(Dickey-Fuller)和滚动统计为预测模型打好基础
时间序列平稳性诊断实战:从理论到Python实现 时间序列分析中,平稳性检验是建模前的关键步骤。许多经典预测模型(如ARIMA)都建立在数据平稳的假设之上。但现实中的时间序列往往带有趋势或季节性,直接建模会导致预测失效…...

边缘计算中的3D占据映射技术与Gleanmer SoC优化
1. 边缘计算时代的3D占据映射技术革新在自动驾驶汽车穿越复杂城市道路时,在AR眼镜试图将虚拟物体精准叠加到现实场景时,设备都需要实时理解周围环境的3D结构。传统解决方案如激光雷达点云只能提供稀疏的空间采样,而基于体素的OctoMap虽然能构…...

[Deep Agents:LangChain的Agent Harness-07]利用PatchToolCallsMiddleware修复错乱的消息结构
作为LLM提示词的一个重要组成部分,表示对话历史的消息列表在结构上有一个基本的要求:如果LLM返回的AIMessage包含ToolCall对象,那么Agent会期望每个ToolCall对象都有对应的ToolMessage。但是Agent在执行过程会因为一些异常导致LLM返回的AIMes…...

Neo4j 实战:手把手构建电影知识图谱
1. 为什么选择Neo4j构建电影知识图谱 第一次接触Neo4j时,我就被它处理复杂关系的能力惊艳到了。相比传统的关系型数据库,用图数据库来存储电影数据简直是天作之合。想象一下,当我们需要查询"汤姆汉克斯出演过哪些科幻电影"或者&quo…...

企者不立,跨者不行,SAP UI5 开发里的克制、分寸与长久之道
老子这句话放到 SAP UI5 开发里看,并不是在劝开发者不进取,也不是叫我们少写功能、少做创新。它真正提醒的是,企业级前端开发最怕一种姿态,脚尖踮得很高,步子跨得很大,心里急着证明自己聪明,手上急着把每一个需求都做成个性化杰作。SAP UI5 最终运行在 SAP Fiori Launch…...

基于MCP协议的Burp Suite AI安全测试插件部署与应用实战
1. 项目概述:当Burp Suite遇见MCP,安全测试的“智能副驾”来了如果你是一名Web安全测试工程师或者渗透测试人员,Burp Suite这个名字对你来说,就像木匠手里的锤子一样熟悉。它几乎是手动安全测试的代名词,从拦截代理到漏…...

AI智能体技能管理:MCP服务器安装配置与实战指南
1. 项目概述:一个为AI智能体管理“技能”的MCP服务器 最近在折腾AI智能体(Agent)开发的朋友,应该都遇到过同一个痛点:想让你的Claude、GPT或者Gemini去执行一些特定的、复杂的任务,比如调用某个API、处理特…...

使用 Python 快速接入 Taotoken 并调用多模型 API 的完整指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Python 快速接入 Taotoken 并调用多模型 API 的完整指南 对于希望快速集成大模型能力的 Python 开发者而言,逐一对…...

【实战】C#集成SM4国密算法:从原理到安全通信应用
1. SM4国密算法基础认知 第一次接触SM4算法时,我被它简洁而强大的设计所吸引。作为我国自主设计的商用分组密码标准,SM4与AES有着相似的定位,但采用了完全不同的技术路线。它的分组长度和密钥长度都是128位,这个设计让我想起平时用…...

无实景不建模 孪生自生成:无改造无感追踪技术路径,重构数字孪生与视频孪生交付逻辑
数字孪生长期深陷建模依赖的行业困局,传统技术路径均以人工建模、激光点云扫描、第三方测绘为前置核心环节,不仅带来高昂的资金投入、漫长的实施周期,更存在模型更新滞后、实景适配性差、运维成本高企等难以破解的行业顽疾。同时,…...