语义分割实战——基于PSPnet神经网络动物马分割系统源码
第一步:准备数据
动物马分割数据,总共有328张图片,里面的像素值为0和1,所以看起来全部是黑的,不影响使用

第二步:搭建模型
psp模块的样式如下,其psp的核心重点是采用了步长不同,pool_size不同的平均池化层进行池化,然后将池化的结果重新resize到一个hw上后,再concatenate。
即:
红色:这是在每个特征map上执行全局平均池的最粗略层次,用于生成单个bin输出。
橙色:这是第二层,将特征map划分为2×2个子区域,然后对每个子区域进行平均池化。
蓝色:这是第三层,将特征 map划分为3×3个子区域,然后对每个子区域进行平均池化。
绿色:这是将特征map划分为6×6个子区域的最细层次,然后对每个子区域执行池化。

第三步:代码
1)损失函数为:交叉熵损失函数
2)网络代码:
import torch
import torch.nn.functional as F
from torch import nnfrom nets.mobilenetv2 import mobilenetv2
from nets.resnet import resnet50class Resnet(nn.Module):def __init__(self, dilate_scale=8, pretrained=True):super(Resnet, self).__init__()from functools import partialmodel = resnet50(pretrained)#--------------------------------------------------------------------------------------------## 根据下采样因子修改卷积的步长与膨胀系数# 当downsample_factor=16的时候,我们最终获得两个特征层,shape分别是:30,30,1024和30,30,2048#--------------------------------------------------------------------------------------------#if dilate_scale == 8:model.layer3.apply(partial(self._nostride_dilate, dilate=2))model.layer4.apply(partial(self._nostride_dilate, dilate=4))elif dilate_scale == 16:model.layer4.apply(partial(self._nostride_dilate, dilate=2))self.conv1 = model.conv1[0]self.bn1 = model.conv1[1]self.relu1 = model.conv1[2]self.conv2 = model.conv1[3]self.bn2 = model.conv1[4]self.relu2 = model.conv1[5]self.conv3 = model.conv1[6]self.bn3 = model.bn1self.relu3 = model.reluself.maxpool = model.maxpoolself.layer1 = model.layer1self.layer2 = model.layer2self.layer3 = model.layer3self.layer4 = model.layer4def _nostride_dilate(self, m, dilate):classname = m.__class__.__name__if classname.find('Conv') != -1:if m.stride == (2, 2):m.stride = (1, 1)if m.kernel_size == (3, 3):m.dilation = (dilate//2, dilate//2)m.padding = (dilate//2, dilate//2)else:if m.kernel_size == (3, 3):m.dilation = (dilate, dilate)m.padding = (dilate, dilate)def forward(self, x):x = self.relu1(self.bn1(self.conv1(x)))x = self.relu2(self.bn2(self.conv2(x)))x = self.relu3(self.bn3(self.conv3(x)))x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x_aux = self.layer3(x)x = self.layer4(x_aux)return x_aux, xclass MobileNetV2(nn.Module):def __init__(self, downsample_factor=8, pretrained=True):super(MobileNetV2, self).__init__()from functools import partialmodel = mobilenetv2(pretrained)self.features = model.features[:-1]self.total_idx = len(self.features)self.down_idx = [2, 4, 7, 14]#--------------------------------------------------------------------------------------------## 根据下采样因子修改卷积的步长与膨胀系数# 当downsample_factor=16的时候,我们最终获得两个特征层,shape分别是:30,30,320和30,30,96#--------------------------------------------------------------------------------------------#if downsample_factor == 8:for i in range(self.down_idx[-2], self.down_idx[-1]):self.features[i].apply(partial(self._nostride_dilate, dilate=2))for i in range(self.down_idx[-1], self.total_idx):self.features[i].apply(partial(self._nostride_dilate, dilate=4))elif downsample_factor == 16:for i in range(self.down_idx[-1], self.total_idx):self.features[i].apply(partial(self._nostride_dilate, dilate=2))def _nostride_dilate(self, m, dilate):classname = m.__class__.__name__if classname.find('Conv') != -1:if m.stride == (2, 2):m.stride = (1, 1)if m.kernel_size == (3, 3):m.dilation = (dilate//2, dilate//2)m.padding = (dilate//2, dilate//2)else:if m.kernel_size == (3, 3):m.dilation = (dilate, dilate)m.padding = (dilate, dilate)def forward(self, x):x_aux = self.features[:14](x)x = self.features[14:](x_aux)return x_aux, xclass _PSPModule(nn.Module):def __init__(self, in_channels, pool_sizes, norm_layer):super(_PSPModule, self).__init__()out_channels = in_channels // len(pool_sizes)#-----------------------------------------------------## 分区域进行平均池化# 30, 30, 320 + 30, 30, 80 + 30, 30, 80 + 30, 30, 80 + 30, 30, 80 = 30, 30, 640#-----------------------------------------------------#self.stages = nn.ModuleList([self._make_stages(in_channels, out_channels, pool_size, norm_layer) for pool_size in pool_sizes])# 30, 30, 640 -> 30, 30, 80self.bottleneck = nn.Sequential(nn.Conv2d(in_channels + (out_channels * len(pool_sizes)), out_channels, kernel_size=3, padding=1, bias=False),norm_layer(out_channels),nn.ReLU(inplace=True),nn.Dropout2d(0.1))def _make_stages(self, in_channels, out_channels, bin_sz, norm_layer):prior = nn.AdaptiveAvgPool2d(output_size=bin_sz)conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)bn = norm_layer(out_channels)relu = nn.ReLU(inplace=True)return nn.Sequential(prior, conv, bn, relu)def forward(self, features):h, w = features.size()[2], features.size()[3]pyramids = [features]pyramids.extend([F.interpolate(stage(features), size=(h, w), mode='bilinear', align_corners=True) for stage in self.stages])output = self.bottleneck(torch.cat(pyramids, dim=1))return outputclass PSPNet(nn.Module):def __init__(self, num_classes, downsample_factor, backbone="resnet50", pretrained=True, aux_branch=True):super(PSPNet, self).__init__()norm_layer = nn.BatchNorm2dif backbone=="resnet50":self.backbone = Resnet(downsample_factor, pretrained)aux_channel = 1024out_channel = 2048elif backbone=="mobilenet":#----------------------------------## 获得两个特征层# f4为辅助分支 [30,30,96]# o为主干部分 [30,30,320]#----------------------------------#self.backbone = MobileNetV2(downsample_factor, pretrained)aux_channel = 96out_channel = 320else:raise ValueError('Unsupported backbone - `{}`, Use mobilenet, resnet50.'.format(backbone))#--------------------------------------------------------------## PSP模块,分区域进行池化# 分别分割成1x1的区域,2x2的区域,3x3的区域,6x6的区域# 30,30,320 -> 30,30,80 -> 30,30,21#--------------------------------------------------------------#self.master_branch = nn.Sequential(_PSPModule(out_channel, pool_sizes=[1, 2, 3, 6], norm_layer=norm_layer),nn.Conv2d(out_channel//4, num_classes, kernel_size=1))self.aux_branch = aux_branchif self.aux_branch:#---------------------------------------------------## 利用特征获得预测结果# 30, 30, 96 -> 30, 30, 40 -> 30, 30, 21#---------------------------------------------------#self.auxiliary_branch = nn.Sequential(nn.Conv2d(aux_channel, out_channel//8, kernel_size=3, padding=1, bias=False),norm_layer(out_channel//8),nn.ReLU(inplace=True),nn.Dropout2d(0.1),nn.Conv2d(out_channel//8, num_classes, kernel_size=1))self.initialize_weights(self.master_branch)def forward(self, x):input_size = (x.size()[2], x.size()[3])x_aux, x = self.backbone(x)output = self.master_branch(x)output = F.interpolate(output, size=input_size, mode='bilinear', align_corners=True)if self.aux_branch:output_aux = self.auxiliary_branch(x_aux)output_aux = F.interpolate(output_aux, size=input_size, mode='bilinear', align_corners=True)return output_aux, outputelse:return outputdef initialize_weights(self, *models):for model in models:for m in model.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight.data, nonlinearity='relu')elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1.)m.bias.data.fill_(1e-4)elif isinstance(m, nn.Linear):m.weight.data.normal_(0.0, 0.0001)m.bias.data.zero_()
第四步:统计一些指标(训练过程中的loss和miou)


第五步:搭建GUI界面


第六步:整个工程的内容

整套算法系列:语义分割实战演练_AI洲抿嘴的薯片的博客-CSDN博客
项目源码下载地址:关注文末【AI街潜水的八角】,回复【动物马分割】即可下载
整套项目源码内容包含
有训练代码和训练好的模型以及训练过程,提供数据,提供GUI界面代码
相关文章:
语义分割实战——基于PSPnet神经网络动物马分割系统源码
第一步:准备数据 动物马分割数据,总共有328张图片,里面的像素值为0和1,所以看起来全部是黑的,不影响使用 第二步:搭建模型 psp模块的样式如下,其psp的核心重点是采用了步长不同,po…...
Python+Appium编写脚本
一、环境配置 1、安装JDK,版本1.8以上 2、安装Python,版本3.x以上,用来解释python 3、安装node.js,版本^14.17.0 || ^16.13.0 || >18.0.0,用来安装Appimu Server 4、安装npm,版本>8,用…...

RK3288 android7.1 适配 ilitek i2c接口TP
一,Ilitek 触摸屏简介 Ilitek 提供多种型号的触控屏控制器,如 ILI6480、ILI9341 等,采用 I2C 接口。 这些控制器能够支持多点触控,并具有优秀的灵敏度和响应速度。 Ilitek 的触摸屏控制器监测屏幕上的触摸事件。 当触摸发生时&am…...

C++ 越来越像函数式编程了!
C 越来越像函数式编程了 大家好,欢迎来到今天的博客话题。今天我们要聊的是 C 这门老牌的强类型语言是如何一步一步向函数式编程靠拢的。从最早的函数指针,到函数对象(Functor),再到 std::function 和 std::bind&…...

maven工程结构说明
1、maven工程文件目录 |-- pom.xml # Maven 项目管理文件 |-- src # 放项目源文件|-- main # 项目主要代码| |-- java # Java 源代码目录| | -- com/example/myapp…...
【GESP】C++一级真题练习(202312)luogu-B3921,小杨的考试
GESP一级真题练习。为2023年12月一级认证真题。逻辑计算问题。 题目题解详见:【GESP】C一级真题练习(202312)luogu-B3921,小杨的考试 | OneCoder 【GESP】C一级真题练习(202312)luogu-B3921,小杨的考试 | OneCoderGESP一级真题练习。为2023…...

游戏中Dubbo类的RPC设计时的注意要点
一.消费方 1.需要使用到动态代理,代理指定的接口,这样子接口被调用时,就可以拿到:"类名 方法名参数返回值" 这些类型。 2.既然是rpc,那么接口被调用时,肯定在动态代理中会进行网络消息的发送&a…...

ARXML汽车可扩展标记性语言规范讲解
ARXML: Automotive Extensible Markup Language (汽车可扩展标记语言) xmlns: Xml name space (xml 命名空间) xsd: Xml Schema Definition (xml 架构定义) 1、XML与HTML的区别,可扩展。 可扩展,主要是…...

Hadoop(HDFS)
Hadoop是一个开源的分布式系统架构,旨在解决海量数据的存储和计算问题,Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)、MapReduce编程模型和YARN资源管理器,最近需求需要用到HDFS和YARN。 文章目录 HDFS优缺点HDFS的读写原理 常…...

机器学习系列----梯度下降算法
梯度下降算法(Gradient Descent)是机器学习和深度学习中最常用的优化算法之一。无论是在训练神经网络、线性回归模型,还是其他类型的机器学习模型时,梯度下降都是不可或缺的一部分。它的核心目标是最小化一个损失函数(…...

AI大模型:软件开发的未来之路
随着AI技术的快速发展,AI大模型正在对软件开发流程产生深远的影响。从代码自动生成到智能测试,AI大模型正在重塑软件开发的各个环节,为软件开发者、企业和整个产业链带来新的流程和模式变化。 首先,AI大模型的定义是指通过大规模…...
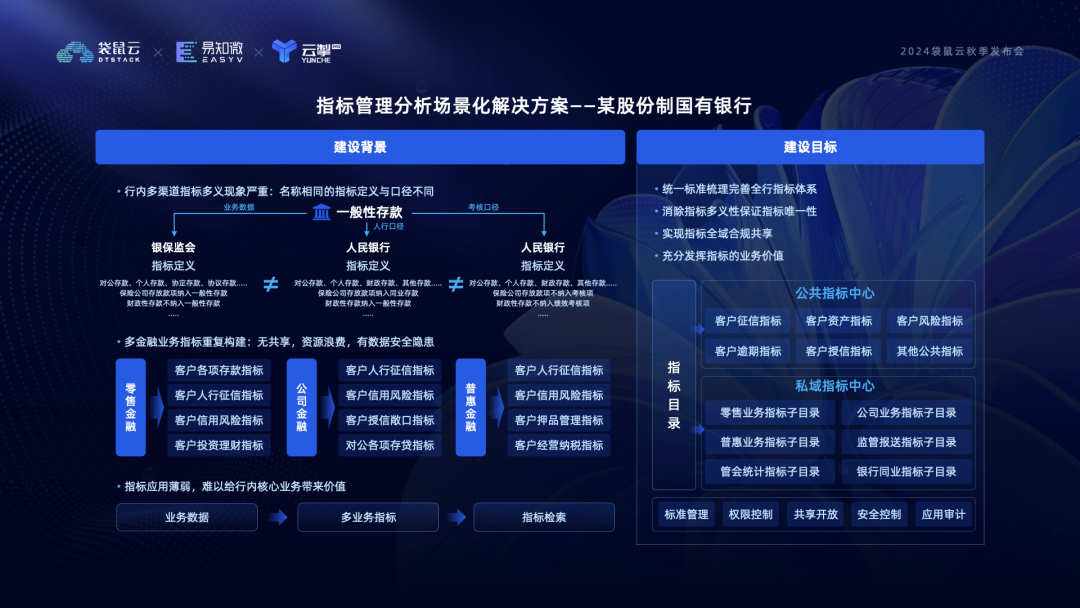
指标+AI+BI:构建数据分析新范式丨2024袋鼠云秋季发布会回顾
10月30日,袋鼠云成功举办了以“AI驱动,数智未来”为主题的2024年秋季发布会。大会深度探讨了如何凭借 AI 实现新的飞跃,重塑企业的经营管理方式,加速数智化进程。 作为大会的重要环节之一,袋鼠云数栈产品经理潮汐带来了…...

2024年第四届“网鼎杯”网络安全比赛---朱雀组Crypto- WriteUp
2024年第四届“网鼎杯”网络安全比赛---朱雀组Crypto-WriteUp Crypto:Crypto-2:Crypto-3: 前言:本次比赛已经结束,用于赛后复现,欢迎大家交流学习! Crypto: Crypto-2: …...

关于Markdown的一点疑问,为什么很多人说markdown比word好用?
markdown和word压根不是一类工具,不存在谁比谁好,只是应用场景不一样。 你写博客、写readme肯定得markdown,但写合同、写简历肯定word更合适。 markdown和word类似邮箱和微信的关系,这两者都可以通信,但微信因为功能…...
绪论)
NoSQL大数据存储技术测试(1)绪论
写在前面:未完成测试的同学,请先完成测试,此博文供大家复习使用,(我的答案)均为正确答案,大家可以放心复习 单项选择题 第1题 以下不属于云计算部署模型的是( ) 公…...

Linux命令学习,git命令
Linux系统,Git是一个强大的版本管理系统,允许用户跟踪代码的更改、管理项目历史以及与他人协作。 Linux Git命令: 初始化仓库:当前目录创建一个Git仓库,生成.git隐藏目录存储版本历史和其他Git相关的元数据。 git init 克隆仓库…...

【AI大模型】Transformer中的编码器详解,小白必看!!
前言 Transformer中编码器的构造和运行位置如下图所示,其中编码器内部包含多层,对应下图encoder1…encoder N,每个层内部又包含多个子层:多头自注意力层、前馈神经网络层、归一化层,而最关键的是多头自注意力层。 自注…...

PostgreSQL 字段按逗号分隔成多条数据的技巧与实践 ️
全文目录: 开篇语前言 📚1. PostgreSQL 字段拆分的基本概念 🎯2. 使用 string_to_array 函数拆分字段 💬示例:使用 string_to_array 拆分字段结果: 3. 使用 unnest 和 string_to_array 结合拆分 ǵ…...
)
设计模式学习总结(一)
设计模式学习笔记 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象 现在,主流的编程范式或者是编程风格有三种:面向过程、面向对象和函数式编程。 需要掌握七大知识点&#…...

软考中级 软件设计师 上午考试内容笔记(个人向)Part.1
软考上午考试内容 1. 计算机系统 计算机硬件通过高/低电平来模拟1/0信息;【p进制】: K n K n − 1 . . . K 2 K 1 K 0 K − 1 K − 2... K − m K n r n . . . K 1 r 1 K 0 r 0 K − 1 r − 1 . . . K − m r − m K_nK_{n-1}...K_2K_1K_0K…...
)
STM32单片机如何用IRIG-B解码模块实现10ns级高精度授时(附完整驱动代码)
STM32单片机如何用IRIG-B解码模块实现10ns级高精度授时(附完整驱动代码) 在工业自动化、电力系统同步、通信基站等对时间精度要求苛刻的领域,微秒级甚至毫秒级的时钟同步已经无法满足需求。IRIG-B作为一种标准时间码格式,通过解码…...

【ArcGIS实战指南】利用属性连接与符号化,一键生成柱状图与饼状图
1. 从零开始:理解ArcGIS图表制作的核心逻辑 第一次接触ArcGIS的图表功能时,我也被各种专业术语搞得晕头转向。直到在西北农业干旱评估项目中,我才真正搞明白属性连接和符号化的配合使用逻辑。简单来说,这就像给地图数据"穿衣…...

【ElevenLabs语音伦理合规白皮书】:面向银发群体的AI语音生成必须绕开的4类GDPR/《互联网信息服务深度合成管理规定》雷区
更多请点击: https://intelliparadigm.com 第一章:银发群体AI语音服务的伦理合规必要性 随着智能语音助手在居家养老、远程问诊、紧急呼叫等场景中的深度部署,面向60岁以上用户的AI语音服务已从“可选功能”演变为“关键基础设施”。然而&am…...

OpenWrt嵌入式Linux开发入门:从编译到部署的完整实践指南
1. 项目概述:为什么选择OpenWrt作为嵌入式开发的起点 如果你对Linux系统有一定了解,并且想踏入嵌入式开发的大门,或者你是一个网络爱好者,想让家里的路由器“脱胎换骨”,那么OpenWrt绝对是一个绕不开的名字。它不是一…...

别再傻傻分不清了!Numpy里ndarray和array到底啥区别?新手避坑指南
别再傻傻分不清了!Numpy里ndarray和array到底啥区别?新手避坑指南 刚接触Numpy的Python开发者,几乎都会在ndarray和array()这两个概念上栽跟头。明明看起来都能创建数组,为什么文档里一会儿用np.array(),一会儿又冒出个…...

终极NDS游戏资源提取器:Tinke如何让你免费解锁任天堂DS游戏文件
终极NDS游戏资源提取器:Tinke如何让你免费解锁任天堂DS游戏文件 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经好奇过任天堂DS游戏中的精美图像、动听音乐和独特字体是如何…...

揭秘高效磁盘空间管理:专业磁盘分析工具WinDirStat完全指南
揭秘高效磁盘空间管理:专业磁盘分析工具WinDirStat完全指南 【免费下载链接】windirstat WinDirStat is a disk usage statistics viewer and cleanup tool for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/wi/windirstat 你是否曾为Window…...

Taotoken用量看板如何帮助开发者洞察API消费明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助开发者洞察API消费明细 对于依赖大模型API进行开发的团队或个人而言,清晰、透明地掌握资源消…...

智能车竞赛实战:用3块钱的HIP6601驱动MOS半桥,搞定无线信标线圈供电
智能车竞赛实战:3元HIP6601驱动半桥电路全解析 全国大学生智能车竞赛中,无线信标组的线圈驱动一直是技术难点。传统方案要么成本高昂,要么效率不足。而一颗仅售3元的HIP6601芯片,配合合适的MOS管,却能构建出稳定高效的…...
)
别再乱写Flash了!W25Q128JV SPI Flash寿命管理与日志记录实战(附STM32代码)
W25Q128JV SPI Flash寿命优化与高可靠日志系统设计实战 在嵌入式设备开发中,数据持久化存储是确保设备可靠运行的关键环节。W25Q128JV作为128Mbit容量的SPI Flash存储器,凭借其高性价比和易用性,成为众多嵌入式项目的首选。然而,许…...