Hadoop(HDFS)
Hadoop是一个开源的分布式系统架构,旨在解决海量数据的存储和计算问题,Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)、MapReduce编程模型和YARN资源管理器,最近需求需要用到HDFS和YARN。
文章目录
- HDFS
- 优缺点
- HDFS的读写原理
- 常用命令
- HDFS 的 API 操作
HDFS
HDFS在Hadoop中负责数据的存储,是一个分布式文件系统。HDFS的主要角色包括以下几种:
- NameNode(nn):负责存储文件的元数据,包括文件名、目录结构、文件属性,此外还记录了每个文件的块列表以及这些块分别存储在哪些DataNode上。
- DataNode (dn):在本地文件系统中保存文件的实际数据块,客户端通过dn对数据块进行读/写操作,同时还存储这些数据块的校验和,以确保数据的完整性。
- Secondary NameNode (2nn):定期对NameNode的元数据进行备份操作,以防数据丢失。
- Client:客户端负责先与NameNode交互获取文件的位置信息后,再与DataNode交互,进行数据的读写操作。

优缺点
优点:
高容错性:数据会进行多个备份,当其中一个备份丢失时,系统能够自动进行恢复。
处理大规模数据:无论是大规模数据还是大量的文件,都能够有效地进行处理。
缺点:
延迟较高:不适用于快速响应的场景,例如毫秒级别的数据访问无法实现。
小文件存储效率低下:当存储大量小文件时,会大量占用NameNode的内存来记录文件目录和块信息,而NameNode的内存资源是有限的,并且小文件的寻址时间可能会超过实际的读取时间。
写入和修改的限制:不支持多个线程同时对同一个文件进行写入操作,且只能对文件进行追加操作,不能对文件内容进行随机修改。
文件块大小
在Hadoop 1.x版本里,默认的文件块大小为64MB,在2.x和3.x版本中为128MB,当寻址时间为传输时间的百分之一是最佳状态,如果单个文件块过小,那么大文件会被切割为很多块,从而增加寻址时间,反之,若文件块过大,那么传输时间会远大于寻址时间。
HDFS的读写原理
(1)文件写入原理

(2) 网络拓扑-节点距离计算
在HDFS进行数据写入时,NameNode会选择与待上传数据距离最近的DataNode来接收并存储这些数据。
节点距离的计算方式:两个节点到达最近的共同祖先的距离总和。

(3)机架感知原理-副本存储节点选择
副本节点选择:
- 第一个副本在Client所处的节点上;如果客户端在集群外,随机选一个。
- 第二个副本在另一个机架的随机一个节点。
- 第三个副本在第二个副本所在机架的随机节点

(4)读文件原理

(5)NN 和 2NN 工作原理
NameNode 中的元数据存放在内存中,当对元数据进行更新或者添加操作时,会修改内存中的元数据并追加到 edits log 中,为了防止edits log过大,导致查询效率低的问题,SecondaryNameNode会定时触发checkpoint操作,将NameNode的edits log和fs image合并,生成一个新的fs image,以减少edits log的大小,并将新的fs image传回给NameNode,以提高元数据的查询效率。
(6)DataNode工作原理

常用命令
(1)查看命令帮助
hadoop fs -help rm
(2)启动Hadoop集群
sbin/start-dfs.shsbin/start-yarn.sh

(3)创建文件夹
hadoop fs -mkdir /learn
 (4)上传文件
(4)上传文件
- -put:和copyFromLocal一样,生产环境更多用 put
vim a.txt
aaa
bbb
hadoop fs -put a.txt /learn


- -moveFromLocal:从本地移动到 HDFS
hadoop fs -moveFromLocal b.txt /learn
- -copyFromLocal:从本地文件拷贝文件到 HDFS
hadoop fs -copyFromLocal c.txt /learn
- -appendToFile:追加一个文件到HDFS已经存在的文件末尾
hadoop fs -appendToFile d.txt /learn/c.txt
(5)下载文件
- -get:和copyToLocal一样,生产环境更习惯用 get
hadoop fs -get /learn ./
- -copyToLocal:从 HDFS 拷贝到本地
hadoop fs -copyToLocal /data ./
(6)其他操作
- -mkdir:创建目录
hadoop fs -mkdir /file
- -ls: 显示目录信息
hadoop fs -ls /learn

- -cat:显示文件内容

- -chgrp、-chmod、-chown:修改文件所属权限
hadoop fs -chmod 777 /learn/a.txt

- -cp:从 HDFS 的一个路径拷贝到 HDFS 的另一个路径
hadoop fs -cp /learn/a.txt /file
- -mv:在 HDFS 目录中移动文件
hadoop fs -mv /learn/b.txt /file2
- -tail:显示一个文件的末尾 1kb 的数据
hadoop fs -tail /learn/a.txt

- -rm:删除文件或文件夹
hadoop fs -rm /learn/a.txt

- -rm -r:递归删除目录及目录里面内容
hadoop fs -rm -r /learn
- -du 统计文件夹的大小信息
hadoop fs -du /file2

7 表示文件大小,21 表示 3个副本的总大小
- -setrep:设置 HDFS 中文件的副本数量
hadoop fs -setrep 10 /file2
目前只有3台节点,最多也就3个副本,当节点数增加到10时,副本数才能到10。

HDFS 的 API 操作
(1)创建目录
public class HdfsLearn {@Testpublic void testCreate() throws IOException, URISyntaxException, InterruptedException {Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.235.130:8020"), configuration, "liang");fs.mkdirs(new Path("/learn/file.txt"));fs.close();}
}
(2)上传文件
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {Configuration configuration = new Configuration();configuration.set("dfs.replication", "3");FileSystem fs = FileSystem.get(new URI("hdfs://192.168.235.130:8020"), configuration, "liang");fs.copyFromLocalFile(new Path("D:\\hadoop\\learn.txt"), new Path("/test/file4"));fs.close();
}
(3)下载文件
@Test
public void testCopyToLocalFile() throws IOException,InterruptedException, URISyntaxException{Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.235.130:8020"), configuration, "liang");// boolean delSrc 指是否将原文件删除// Path src 指要下载的文件路径// Path dst 指将文件下载到的路径// boolean useRawLocalFileSystem 是否开启文件校验fs.copyToLocalFile(false, new Path("/learn/a.txt"), new Path("D:\\hadoop\\b.txt"), true);fs.close();
}
(4)文件移动或者更名
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException {Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.235.130:8020"), configuration, "liang");fs.rename(new Path("/learn/a.txt"), new Path("/learn/b.txt"));fs.close();
}
(5)删除文件
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.235.130:8020"), configuration, "liang");fs.delete(new Path("/file2"), true);fs.close();
}
(6)文件详情查看
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException {Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.235.130:8020"), configuration, "liang");// 获取文件详情RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next();System.out.println(fileStatus.getPath());System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getGroup());System.out.println(fileStatus.getLen());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockSize());System.out.println(fileStatus.getPath().getName());// 获取块信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}fs.close();
}
(7)文件判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException {Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://192.168.235.130:8020"), configuration, "liang");// 判断是文件还是文件夹FileStatus[] listStatus = fs.listStatus(new Path("/"));for (FileStatus fileStatus : listStatus) {// 如果是文件if (fileStatus.isFile()) {System.out.println("f:" + fileStatus.getPath().getName());} else {System.out.println("d:" + fileStatus.getPath().getName());}}fs.close();
}
相关文章:
Hadoop(HDFS)
Hadoop是一个开源的分布式系统架构,旨在解决海量数据的存储和计算问题,Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)、MapReduce编程模型和YARN资源管理器,最近需求需要用到HDFS和YARN。 文章目录 HDFS优缺点HDFS的读写原理 常…...

机器学习系列----梯度下降算法
梯度下降算法(Gradient Descent)是机器学习和深度学习中最常用的优化算法之一。无论是在训练神经网络、线性回归模型,还是其他类型的机器学习模型时,梯度下降都是不可或缺的一部分。它的核心目标是最小化一个损失函数(…...

AI大模型:软件开发的未来之路
随着AI技术的快速发展,AI大模型正在对软件开发流程产生深远的影响。从代码自动生成到智能测试,AI大模型正在重塑软件开发的各个环节,为软件开发者、企业和整个产业链带来新的流程和模式变化。 首先,AI大模型的定义是指通过大规模…...
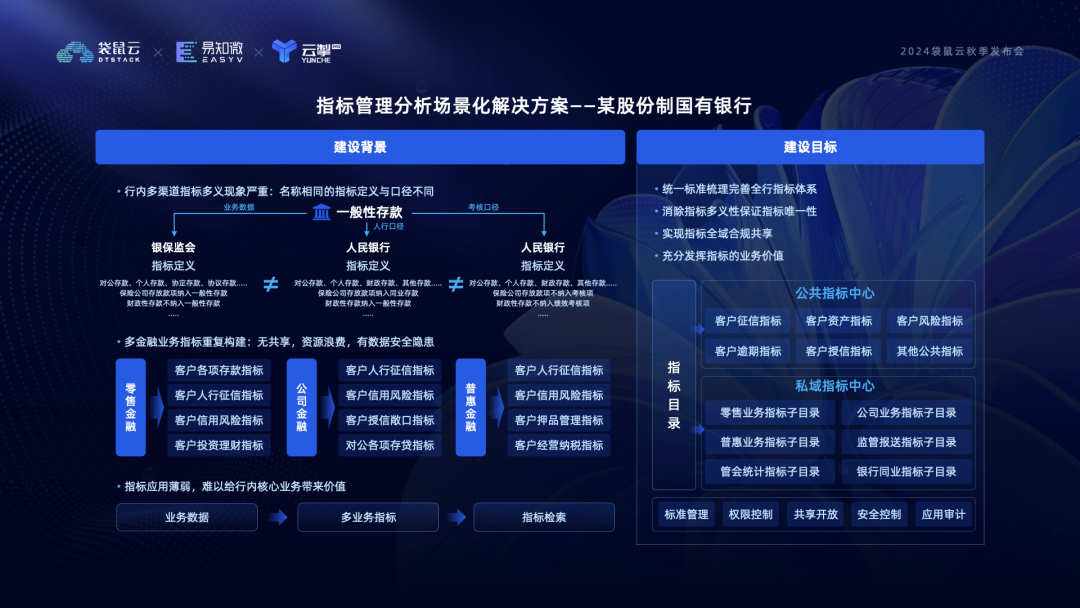
指标+AI+BI:构建数据分析新范式丨2024袋鼠云秋季发布会回顾
10月30日,袋鼠云成功举办了以“AI驱动,数智未来”为主题的2024年秋季发布会。大会深度探讨了如何凭借 AI 实现新的飞跃,重塑企业的经营管理方式,加速数智化进程。 作为大会的重要环节之一,袋鼠云数栈产品经理潮汐带来了…...

2024年第四届“网鼎杯”网络安全比赛---朱雀组Crypto- WriteUp
2024年第四届“网鼎杯”网络安全比赛---朱雀组Crypto-WriteUp Crypto:Crypto-2:Crypto-3: 前言:本次比赛已经结束,用于赛后复现,欢迎大家交流学习! Crypto: Crypto-2: …...

关于Markdown的一点疑问,为什么很多人说markdown比word好用?
markdown和word压根不是一类工具,不存在谁比谁好,只是应用场景不一样。 你写博客、写readme肯定得markdown,但写合同、写简历肯定word更合适。 markdown和word类似邮箱和微信的关系,这两者都可以通信,但微信因为功能…...
绪论)
NoSQL大数据存储技术测试(1)绪论
写在前面:未完成测试的同学,请先完成测试,此博文供大家复习使用,(我的答案)均为正确答案,大家可以放心复习 单项选择题 第1题 以下不属于云计算部署模型的是( ) 公…...

Linux命令学习,git命令
Linux系统,Git是一个强大的版本管理系统,允许用户跟踪代码的更改、管理项目历史以及与他人协作。 Linux Git命令: 初始化仓库:当前目录创建一个Git仓库,生成.git隐藏目录存储版本历史和其他Git相关的元数据。 git init 克隆仓库…...

【AI大模型】Transformer中的编码器详解,小白必看!!
前言 Transformer中编码器的构造和运行位置如下图所示,其中编码器内部包含多层,对应下图encoder1…encoder N,每个层内部又包含多个子层:多头自注意力层、前馈神经网络层、归一化层,而最关键的是多头自注意力层。 自注…...

PostgreSQL 字段按逗号分隔成多条数据的技巧与实践 ️
全文目录: 开篇语前言 📚1. PostgreSQL 字段拆分的基本概念 🎯2. 使用 string_to_array 函数拆分字段 💬示例:使用 string_to_array 拆分字段结果: 3. 使用 unnest 和 string_to_array 结合拆分 ǵ…...
)
设计模式学习总结(一)
设计模式学习笔记 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象 现在,主流的编程范式或者是编程风格有三种:面向过程、面向对象和函数式编程。 需要掌握七大知识点&#…...

软考中级 软件设计师 上午考试内容笔记(个人向)Part.1
软考上午考试内容 1. 计算机系统 计算机硬件通过高/低电平来模拟1/0信息;【p进制】: K n K n − 1 . . . K 2 K 1 K 0 K − 1 K − 2... K − m K n r n . . . K 1 r 1 K 0 r 0 K − 1 r − 1 . . . K − m r − m K_nK_{n-1}...K_2K_1K_0K…...

PHP API的数据交互类型设计
PHP API的数据交互类型设计涉及多个方面,包括请求方法、数据格式、安全性考虑等。以下是对PHP API数据交互类型设计的详细探讨: 一、请求方法 在PHP API中,常见的请求方法包括GET、POST、PUT、DELETE等。这些方法在数据交互中各有其用途和特…...

【EFK】Linux集群部署Elasticsearch最新版本8.x
【EFK】Linux集群部署Elasticsearch最新版本8.x 摘要环境准备环境信息系统初始化启动先决条件 下载&安装修改elasticsearch.yml控制台启动Linux服务启动访问验证查看集群信息查看es健康状态查看集群节点查询集群状态 生成service token验证service tokenIK分词器下载 摘要 …...

【大数据测试 Elasticsearch — 详细教程及实例】
大数据测试 Elasticsearch — 详细教程及实例 1. Elasticsearch 基础概述核心概念 2. 搭建 Elasticsearch 环境2.1 安装 Elasticsearch2.2 配置 Elasticsearch 3. 大数据测试的常见方法3.1 使用 Logstash 导入大数据3.2 使用 Elasticsearch 的 Bulk API3.3 使用 Benchmark 工具…...
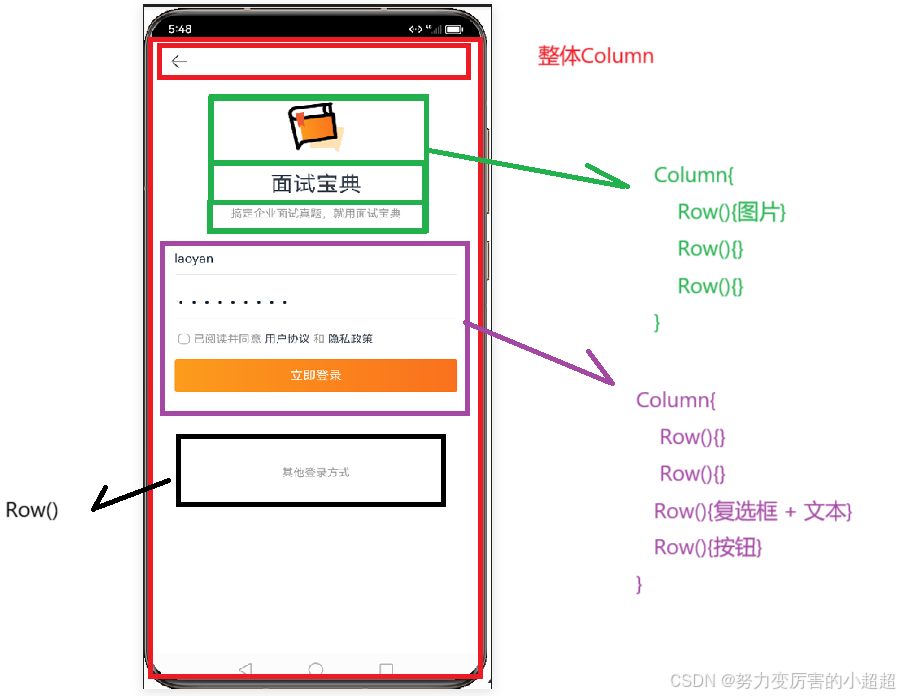
用ArkTS写一个登录页面(实现简单的逻辑)
登录页面 1.登录页面编码 Extend(TextInput) function customStyle(){.backgroundColor(#fff).border({width:{bottom:0.5},color:#e4e4e4}).borderRadius(1) //让圆角不明显.placeholderColor(#c3c3c5).caretColor(#fa711d) //input获取焦点样式 }Entry Component struct Log…...

matlab将INCA采集的dat文件多个变量批量读取到excel中
参考资料: MATLAB处理INCA采集数据(mdf,dat等)一 使用matlab处理INCF采集数据,mdf(.dat)格式文件,并将将其写入excel文件 这个资料只能一个变量一个变量的提取,本对其进…...

list集合常见去重方式以及效率对比
1.概述 list集合去重是开发中比较常用的操作,在面试中也会经常问到,那么list去重都有哪些方式?他们之间又该如何选择呢? 本文将通过LinkedHashSet、for循环、list流toSet、list流distinct等4种方式分别做1W数据到1000W数据单元测试…...

JavaWeb——Web入门(7/9)-Tomcat-介绍(Tomcat 的简介:轻量级Web服务器,支持Servlet/JSP少量JavaEE规范)
目录 Web服务器的作用 三个方面的讲解 Tomcat 的简介 小结 Web服务器的作用 封装 HTTP 协议操作:Web服务器是一个软件程序,对 HTTP 协议的操作进行了封装。这样开发人员就不需要再直接去操作 HTTP 协议,使得外部应用程序的开发更加便捷、…...

【SpringBoot】19 文件/图片下载(MySQL + Thymeleaf)
Git仓库 https://gitee.com/Lin_DH/system 介绍 从 MySQL 中,下载保存的 blob 格式的文件。 代码实现 第一步:配置文件 application.yml spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT8datasource:driver-class-name: com.mysql.…...

Vivado HLS数据流优化技术与FPGA性能提升实践
1. Vivado HLS数据流优化核心原理 在FPGA设计领域,数据流优化是提升系统性能的关键技术。传统FPGA开发需要手动设计数据路径和状态机,而Vivado HLS的数据流优化允许我们在C/C抽象层级实现高性能设计。其核心思想是将算法分解为多个独立阶段,通…...

如何用Untrunc开源工具快速修复损坏视频:完整操作指南
如何用Untrunc开源工具快速修复损坏视频:完整操作指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 你是否曾…...

基于有限状态机的LLM智能体:Haath架构解析与工程实践
1. 项目概述:一个基于状态机的自主LLM智能体如果你正在构建或使用LLM智能体,大概率遇到过这样的困境:你把所有能调用的工具、API、函数都一股脑儿塞给模型,然后满怀期待地发出指令。结果呢?模型要么在几十个选项里犹豫…...

KMS智能激活终极指南:5分钟永久激活Windows和Office全系列
KMS智能激活终极指南:5分钟永久激活Windows和Office全系列 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变…...

ARMv8地址转换机制与TCR_EL2寄存器详解
1. ARMv8地址转换机制概述在ARMv8架构中,地址转换是连接虚拟地址空间和物理内存的核心机制。这种转换通过多级页表结构实现,允许操作系统和hypervisor灵活地管理内存资源。作为系统程序员,理解这个机制的工作原理对开发高效可靠的系统软件至关…...

CANN/ops-nn: 原位加法RMS归一化算子
InplaceAddRmsNorm 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atlas A3 推理系…...
04)
【审计专栏-监督监管领域】【信息科学与工程学】【社会科学】第十篇 社会底层核心规则(核心权力、核心利益、核心资源绑定、私下运作、关键价值交换、上下博弈)04
模型046:企业复杂利益链与多方利益博弈模型 1. 模型概述 项目 内容 模型名称 企业复杂利益链与多方利益博弈模型 核心场景 一家大型建筑企业“宏建集团”中标某市的地铁延长线建设项目。项目涉及总包方(宏建)、多个分包商(土建、机电、装修等)、材料供应商、监理…...

如何用python函数制作一个计算工具
大家好,这里是junlang的python文章 今天教大家如何用python函数做一个计算器,希望大家好好学习哦 如何制作 首先我们先定义4个函数,其中除法计算代码请看下面: def add (a,b,c):return (a b - c) def sub (x,y):return(x - y) def mulpl…...

从零到一:基于iSYSTEM winIDEA与IC5000的嵌入式程序烧写与调试实战指南
1. 环境准备:搭建你的嵌入式开发工作台 第一次接触iSYSTEM工具链时,我完全被各种专业术语搞懵了。后来才发现,只要把环境搭好,后面的操作就像拼乐高一样简单。这里我会手把手带你配置好winIDEA和IC5000调试器,避开那些…...

JetBrains IDE重置插件:终极免费解决方案告别30天试用期限制
JetBrains IDE重置插件:终极免费解决方案告别30天试用期限制 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然被JetBrains IDE弹出的"试用期已到期…...