【大数据测试 Elasticsearch — 详细教程及实例】
大数据测试 Elasticsearch — 详细教程及实例
- 1. Elasticsearch 基础概述
- 核心概念
- 2. 搭建 Elasticsearch 环境
- 2.1 安装 Elasticsearch
- 2.2 配置 Elasticsearch
- 3. 大数据测试的常见方法
- 3.1 使用 Logstash 导入大数据
- 3.2 使用 Elasticsearch 的 Bulk API
- 3.3 使用 Benchmark 工具
- 4. 性能调优
- 4.1 增加分片数
- 4.2 配置硬件资源
- 4.3 使用 Bulk 索引
- 5. 常见问题与解决方案
- 5.1 索引速度慢
- 5.2 查询性能差
Elasticsearch 是一个开源的分布式搜索和分析引擎,广泛应用于日志分析、全文检索和大数据分析等领域。本文将介绍如何进行大数据量的测试,帮助您更好地理解 Elasticsearch 的性能表现,并通过实例演示相关操作。
1. Elasticsearch 基础概述
Elasticsearch 是基于 Lucene 构建的分布式搜索引擎,通常用作数据存储、索引和搜索的引擎。它支持高效的全文检索、聚合查询和多维度分析,能够处理 PB 级别的大数据量。
核心概念
- Index: 数据库类似的结构,包含一组文档。
- Document: 单条记录,相当于关系型数据库中的一行。
- Field: 文档中的字段,相当于关系型数据库中的列。
- Shard: 索引分片,Elasticsearch 将一个索引分为多个分片进行存储和计算。
- Replica: 副本,为了容错性,可以提高查询性能。
2. 搭建 Elasticsearch 环境
在进行大数据测试之前,首先需要搭建一个 Elasticsearch 环境。下面是一个基本的安装和配置过程。
2.1 安装 Elasticsearch
-
下载并解压 Elasticsearch
访问 Elasticsearch 官方下载页面,下载适合你系统的版本,并解压。tar -xzf elasticsearch-7.17.0-linux-x86_64.tar.gz cd elasticsearch-7.17.0 -
启动 Elasticsearch
执行以下命令启动 Elasticsearch 服务:
./bin/elasticsearch -
验证启动成功
在浏览器中访问
http://localhost:9200,如果成功启动,你应该会看到类似以下的响应:{"name" : "node-1","cluster_name" : "elasticsearch","cluster_uuid" : "QXt1DbR6QhuFU5fK3kpEhw","version" : {"number" : "7.17.0","build_flavor" : "default","build_type" : "tar","build_hash" : "47c6ff5","build_date" : "2021-10-05T08:21:09.741407Z","build_snapshot" : false,"lucene_version" : "8.9.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0"},"tagline" : "You Know, for Search" }
2.2 配置 Elasticsearch
配置文件位于 config/elasticsearch.yml,你可以根据需要修改如下参数:
cluster.name: 设置集群名称node.name: 设置节点名称network.host: 设置网络绑定地址discovery.seed_hosts: 设置集群发现的其他节点
3. 大数据测试的常见方法
大数据测试通常涉及对 Elasticsearch 集群的负载、吞吐量、延迟、资源消耗等方面进行压力测试。以下是几种常见的方法:
3.1 使用 Logstash 导入大数据
Logstash 是 Elastic Stack 的一部分,适用于从各种来源(如数据库、文件、消息队列等)导入数据。你可以使用 Logstash 导入大量数据,进行大数据测试。
-
安装 Logstash
从官网 Logstash 下载页面 下载并安装。
-
配置 Logstash 数据导入
创建一个简单的 Logstash 配置文件
logstash.conf:input {file {path => "/path/to/your/big_data_file.csv"start_position => "beginning"} }filter {csv {separator => ","columns => ["id", "name", "timestamp", "value"]} }output {elasticsearch {hosts => ["http://localhost:9200"]index => "big_data_index"} } -
运行 Logstash
执行以下命令启动 Logstash:
bin/logstash -f logstash.conf
通过这种方式,你可以轻松地将大量数据导入到 Elasticsearch 中,进行性能和查询测试。
3.2 使用 Elasticsearch 的 Bulk API
Elasticsearch 提供了 Bulk API 来进行批量插入操作,这对于大数据测试非常有用。以下是如何使用 Bulk API 导入数据:
-
构造 Bulk 请求
Bulk API请求由一系列操作组成,每个操作都是一个 JSON 格式的请求。下面是一个例子:{ "index": { "_index": "big_data_index", "_id": 1 } } { "name": "Alice", "age": 30, "city": "New York" } { "index": { "_index": "big_data_index", "_id": 2 } } { "name": "Bob", "age": 25, "city": "San Francisco" } -
执行 Bulk 请求
使用
curl或者通过客户端进行请求:curl -X POST "localhost:9200/_bulk" -H 'Content-Type: application/json' -d @bulk_data.json其中
bulk_data.json是上面构造的 JSON 请求文件。
3.3 使用 Benchmark 工具
Elasticsearch 自带一个性能测试工具叫做 Rally。通过 Rally 可以模拟各种负载进行性能测试。
-
安装 Rally
在 Elasticsearch 安装目录下运行以下命令安装 Rally:
bin/elasticsearch-plugin install org.elasticsearch.plugin:rally -
运行 Rally 测试
运行以下命令来启动一个简单的基准测试:
bin/elasticsearch-rally --track=geonames这将会模拟一组针对地理数据的查询和索引操作,来测试 Elasticsearch 的性能。
4. 性能调优
在进行大数据量测试时,你可能需要根据测试结果调整 Elasticsearch 的配置,以提高性能。以下是一些常见的优化方法:
4.1 增加分片数
默认情况下,Elasticsearch 为每个索引创建 5 个主分片(shards)。对于大数据量的索引,适当增加分片数可以提高索引和查询性能。
index:number_of_shards: 10 # 增加分片数量
4.2 配置硬件资源
- 内存:Elasticsearch 通常需要大量内存,可以通过调整
jvm.options文件中的堆内存大小来配置 JVM 的内存分配。 - 磁盘:确保使用 SSD 来提高磁盘 I/O 性能,尤其是在处理大数据时。
- 网络:Elasticsearch 是分布式的,节点之间的网络带宽非常重要。如果使用多节点集群,确保节点之间的网络速度足够快。
4.3 使用 Bulk 索引
Bulk 操作比单个文档的逐一插入更高效。尽量使用 Bulk API 或者 Logstash 批量导入数据。
5. 常见问题与解决方案
5.1 索引速度慢
如果你在导入大量数据时遇到索引速度慢,可以尝试以下方法:
-
关闭副本:临时关闭副本可以提高索引速度,待数据导入后再开启副本。
curl -X PUT "localhost:9200/index_name/_settings" -H 'Content-Type: application/json' -d '{"index": {"number_of_replicas": 0} }'
5.2 查询性能差
对于查询性能差的问题,你可以:
- 优化查询:避免使用不必要的复杂查询,简化查询逻辑。
- 调整映射:根据数据的使用模式调整字段类型和索引策略。
推荐阅读:《大数据 ETL + Flume 数据清洗 — 详细教程及实例》
相关文章:

【大数据测试 Elasticsearch — 详细教程及实例】
大数据测试 Elasticsearch — 详细教程及实例 1. Elasticsearch 基础概述核心概念 2. 搭建 Elasticsearch 环境2.1 安装 Elasticsearch2.2 配置 Elasticsearch 3. 大数据测试的常见方法3.1 使用 Logstash 导入大数据3.2 使用 Elasticsearch 的 Bulk API3.3 使用 Benchmark 工具…...
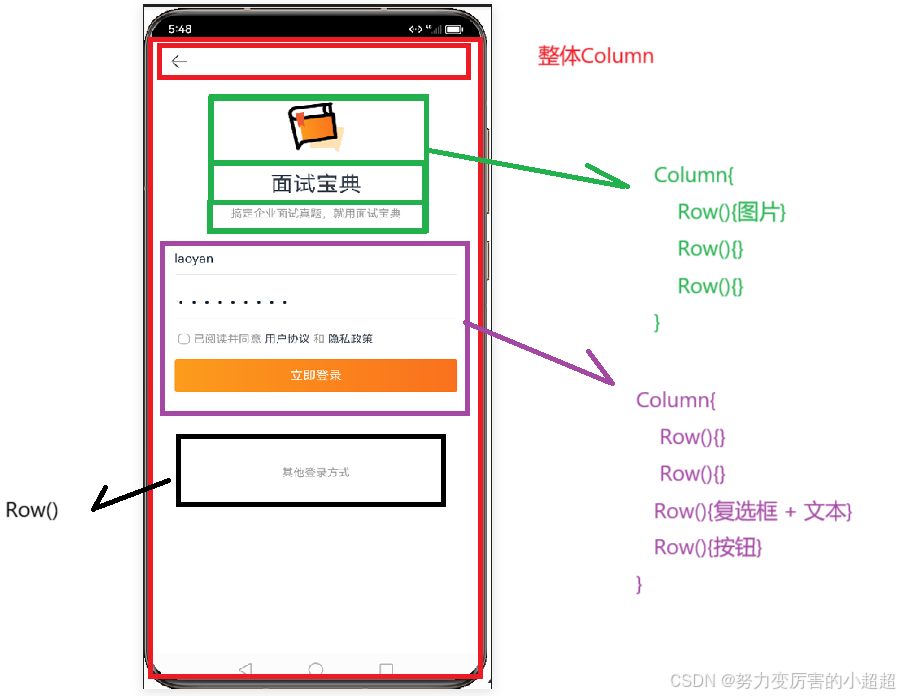
用ArkTS写一个登录页面(实现简单的逻辑)
登录页面 1.登录页面编码 Extend(TextInput) function customStyle(){.backgroundColor(#fff).border({width:{bottom:0.5},color:#e4e4e4}).borderRadius(1) //让圆角不明显.placeholderColor(#c3c3c5).caretColor(#fa711d) //input获取焦点样式 }Entry Component struct Log…...

matlab将INCA采集的dat文件多个变量批量读取到excel中
参考资料: MATLAB处理INCA采集数据(mdf,dat等)一 使用matlab处理INCF采集数据,mdf(.dat)格式文件,并将将其写入excel文件 这个资料只能一个变量一个变量的提取,本对其进…...

list集合常见去重方式以及效率对比
1.概述 list集合去重是开发中比较常用的操作,在面试中也会经常问到,那么list去重都有哪些方式?他们之间又该如何选择呢? 本文将通过LinkedHashSet、for循环、list流toSet、list流distinct等4种方式分别做1W数据到1000W数据单元测试…...

JavaWeb——Web入门(7/9)-Tomcat-介绍(Tomcat 的简介:轻量级Web服务器,支持Servlet/JSP少量JavaEE规范)
目录 Web服务器的作用 三个方面的讲解 Tomcat 的简介 小结 Web服务器的作用 封装 HTTP 协议操作:Web服务器是一个软件程序,对 HTTP 协议的操作进行了封装。这样开发人员就不需要再直接去操作 HTTP 协议,使得外部应用程序的开发更加便捷、…...

【SpringBoot】19 文件/图片下载(MySQL + Thymeleaf)
Git仓库 https://gitee.com/Lin_DH/system 介绍 从 MySQL 中,下载保存的 blob 格式的文件。 代码实现 第一步:配置文件 application.yml spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT8datasource:driver-class-name: com.mysql.…...

陪诊问诊APP开发实战:基于互联网医院系统源码的搭建详解
时下,开发一款功能全面、用户体验良好的陪诊问诊APP成为了医疗行业的一大热点。本文将结合互联网医院系统源码,详细解析陪诊问诊APP的开发过程,为开发者提供实用的开发方案与技术指导。 一、陪诊问诊APP的背景与功能需求 陪诊问诊APP核心目…...

Spark 中 RDD 的诞生:原理、操作与分区规则
Spark 的介绍与搭建:从理论到实践-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式之Yarn模式的原…...

c++构造与析构
构造函数特性 名称与类名相同:构造函数的名称必须与类名完全相同,并且不能有返回值类型(包括void)。 自动调用:构造函数在对象实例化时自动调用,不需要手动调用。 初始化成员变量:构造函数的主…...

C++(函数重载,引用,nullptr)
1.函数重载 C⽀持在同⼀作⽤域中出现同名函数,但是要求这些同名函数的形参不同,可以是参数个数不同或者类型不同。传参时会自动匹配传入的参数,对应该函数的形参类型,进行函数调用,这样C函数调⽤就表现出了多态⾏为&a…...

django+postgresql
PostgreSQL概述 PostgreSQL 是一个功能强大的开源关系数据库管理系统(RDBMS),以其高度的稳定性、扩展性和社区支持而闻名。PostgreSQL 支持 SQL 标准并具有很多先进特性,如 ACID 合规、复杂查询、外键支持、事务处理、表分区、JS…...
)
前端滚动锚点(点击后页面滚动到指定位置)
三个常用方案:1.scrollintoView 把调用该方法的元素滚动到屏幕的指定位置,中间,底部,或者顶部 优点:方便,只需要获取元素然后调用 缺点:不好精确控制,只能让元素指定滚动到中间&…...

使用SSL加密465端口发送邮件
基于安全考虑,云虚拟主机的25端口默认封闭,如果您有发送邮件的需求,建议使用SSL加密端口(465端口)来对外发送邮件。本文通过提供.NET、PHP和ASP样例来介绍使用SSL加密端口发送邮件的方法,其他语言的实现思路…...
一些面试题总结(一)
1、string为什么是不可变的,有什么好处 原因: 1、因为String类下的value数组是用final修饰的,final保证了value一旦被初始化,就不可改变其引用。 2、此外,value数组的访问权限为 private,同时没有提供方…...

泄露的文档显示 Google 似乎意识到了 Tensor 处理器存在过热问题
Google 知道其 Tensor 芯片存在一些问题,尤其是在过热和电池寿命方面,显然他们正在努力通过即将推出的代号为"Malibu"的 Tensor G6 来解决这一问题。 Android Authority 泄露的幻灯片显示,过热是基于 Tensor 的 Pixel 手机退换货的…...
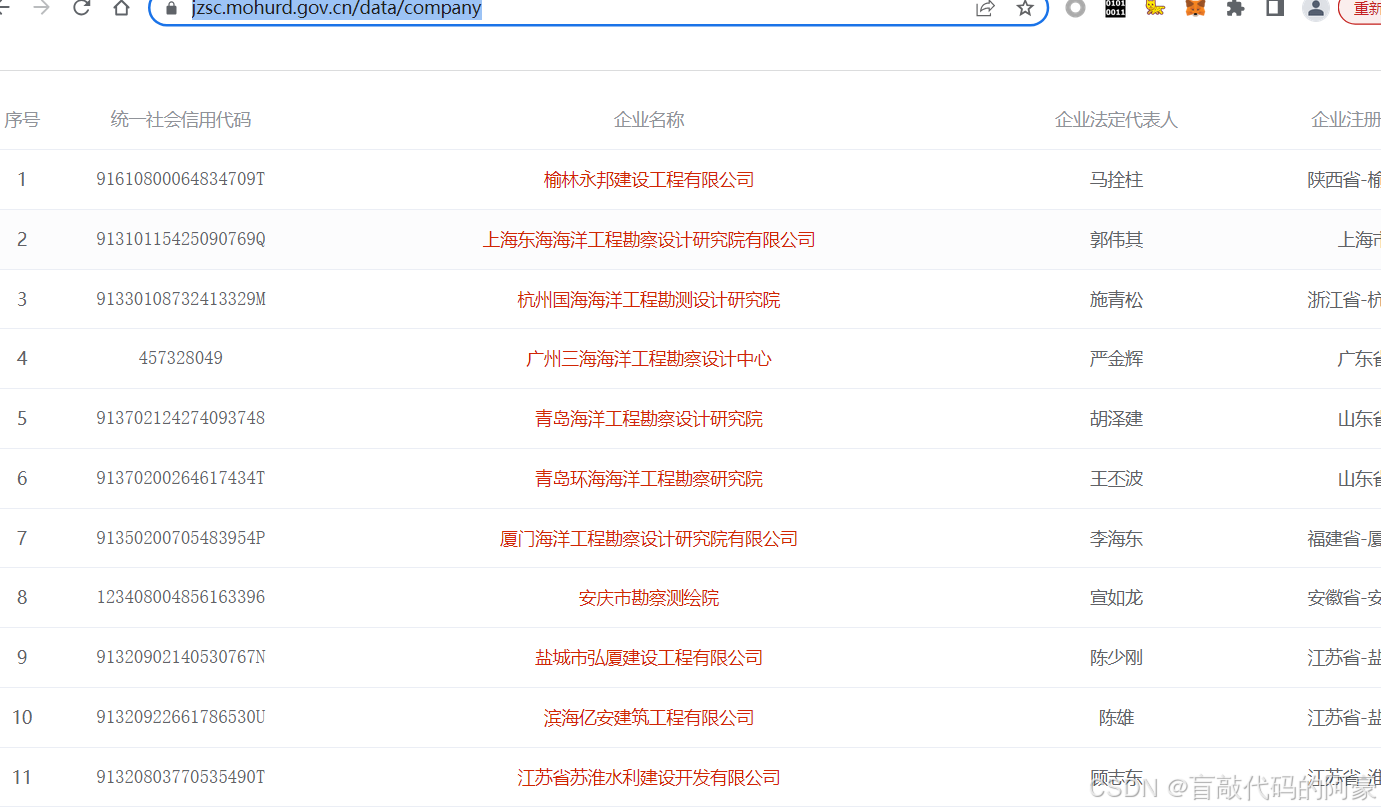
python爬虫案例——网页源码被加密,解密方法全过程
文章目录 1、任务目标2、网页分析3、代码编写1、任务目标 目标网站:https://jzsc.mohurd.gov.cn/data/company,该网站的网页源码被加密了,用于本文测验 要求:解密该网站的网页源码,请求网站并返回解密后的明文数据,网页内容如下: 2、网页分析 进入网站,打开开发者模式,…...

2.4_SSRF服务端请求伪造
SSRF服务端请求伪造 定义:服务端请求伪造。是一种攻击者构造请求后,交由服务端发起请求的漏洞; 产生原理:该服务器提供了从其他服务器获取数据的功能,但没有对用户提交的数据做严格校验; 利用条件&#…...

数据分析反馈:提升决策质量的关键指南
内容概要 在当今快节奏的商业环境中,数据分析与反馈已成为提升决策质量的重要工具。数据分析不仅能为企业提供全面的市场洞察,还能帮助管理层深入了解客户需求与行为模式。掌握数据收集的有效策略和工具,企业能够确保获得准确且相关的信息&a…...

一步步安装deeponet的详细教学
1.deepoent官网如下: https://github.com/lululxvi/deeponet 需要下载依赖 1.python3 2.DeepXDE(这里安装DeepXDE<0.11.2,这个最方便) Optional: For CNN, install Matlab and TensorFlow 1; for Seq2Seq, install PyTorch࿰…...

Devops业务价值流:版本发布最佳实践
敏捷开发中,版本由多个迭代构建而成,每个迭代都是产品进步的一环。当版本最后一个迭代完成时,便启动了至关重要的上线流程。版本发布流程与规划流程相辅相成,确保每个迭代在版本中有效循环执行,最终达成产品目标。 本…...
:含12类建筑/机械/游戏资产等距规范库,仅限前500名开发者领取)
【稀缺首发】Midjourney等距视角工业设计协议(ISO/IEC 21827-2024兼容版):含12类建筑/机械/游戏资产等距规范库,仅限前500名开发者领取
更多请点击: https://intelliparadigm.com 第一章:等距视角工业设计协议的范式演进与ISO/IEC 21827-2024兼容性解析 等距视角工业设计协议(Isometric Industrial Design Protocol, IIDP)已从早期的CAD渲染辅助规范,逐…...

物业临时工排班管理的技术破局:栎偲考勤神器的AI与离线方案详解
物业行业临时工排班管理长期面临三大技术痛点:人员流动性大导致班制匹配混乱、多场景打卡数据碎片化、中小企业部署成本高。作为专注考勤工具实测的博主,今天拆解栎偲考勤神器如何通过AI算法与轻量化技术,针对性解决物业临时工排班管理的核心…...

深度解析DS4Windows:让PS4手柄在Windows平台重获新生
深度解析DS4Windows:让PS4手柄在Windows平台重获新生 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 你是否曾经为PS4手柄在PC上的兼容性问题而烦恼?游戏无法识别、…...

基于FET6254-C多核异构处理器的智能运动控制系统设计与实践
1. 项目概述:当运动控制遇上嵌入式智能最近在做一个智能运动控制的项目,从传统的PLC方案转向了更灵活、更智能的嵌入式平台。选型过程中,飞凌嵌入式的FET6254-C核心板进入了我的视野,经过一番深度评估和实际测试,它确实…...
引发的音素错位故障)
ElevenLabs旁遮普语TTS突然失真?3步定位Gurmukhi Unicode变体(U+0A02/U+0A3C/U+0A4D)引发的音素错位故障
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs旁遮普文语音合成异常现象综述 ElevenLabs 目前官方文档明确标注支持旁遮普语(Gurmukhi script, language code: pa),但在实际调用其 REST API 进行语音合…...
)
别再只抄电路图了!深入剖析DC-DC变换器电流采样与ADC保护的硬件细节(以国赛A题为例)
深入解析DC-DC变换器电流采样与ADC保护的硬件设计精髓 在功率电子系统的设计中,电流采样和ADC输入保护往往被视为"配角",但正是这些看似次要的环节,常常成为系统可靠性的致命弱点。我曾在一个工业电源项目中,因为忽视了…...

京东自动评价工具:Python智能购物助手终极指南
京东自动评价工具:Python智能购物助手终极指南 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 想要轻松完成京东购物后的评价任务吗?jd_AutoComment 是一款基于Python开…...

如何快速掌握Winhance中文版:Windows优化终极指南
如何快速掌握Winhance中文版:Windows优化终极指南 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_CN …...

Smithbox终极指南:如何轻松定制你的魂类游戏世界
Smithbox终极指南:如何轻松定制你的魂类游戏世界 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/gh_mi…...

【鸿蒙 HarmonyOS】从零到一:Node.js 环境配置与 DevEco Studio 无缝对接指南
1. 为什么需要Node.js环境? 如果你刚刚接触鸿蒙开发,可能对DevEco Studio里弹出的"Node.js not found"提示感到困惑。其实Node.js在鸿蒙生态中扮演着重要角色——它不仅是npm包管理器的运行环境,更是鸿蒙应用编译工具链的基础依赖。…...