分布式唯一ID生成(二): leaf
文章目录
- 本系列
- 前言
- 号段模式
- 双buffer优化
- biz优化
- 动态step
- 源码走读
- 雪花算法
- 怎么设置workerId
- 解决时钟回拨
- 源码走读
- 总结
本系列
- 漫谈分布式唯一ID
- 分布式唯一ID生成(二):leaf(本文)
- 分布式唯一ID生成(三):uid-generator
- 分布式唯一ID生成(四):tinyid
前言
本文将介绍leaf号段模式和雪花算法模式的设计原理,并走读源码
源码地址:https://github.com/Meituan-Dianping/Leaf
leaf提供了 leaf server,业务只管调leaf server的接口获取ID,leaf serve内部根据号段或雪花算法生成ID,而不是业务服务自己去请求数据库生成id,或自己根据雪花算法生成id

号段模式
在使用db自增主键的基础上,从每次获取ID都要读写一次db,改成一次获取一批ID
各个业务的记录通过 biz_tag 区分,每个业务的ID上次分配到哪了,在一张表中用一条记录表示
表结构如下:
CREATE TABLE `leaf_alloc` (`biz_tag` varchar(128) NOT NULL DEFAULT '', -- your biz unique name`max_id` bigint(20) NOT NULL DEFAULT '1',`step` int(11) NOT NULL,`description` varchar(256) DEFAULT NULL,`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
重要字段为:
- biz_tag:标识业务
- max_id:目前分配到的最大值-1,也是
下一个号段的起始值 - step:每次分配号段的长度
如果step=1000,当这1000个ID消耗完后才会读写一次DB,对DB的压力降为原来的 1/1000
当缓存中没有ID时,需要从db获取号段,在事务中执行如下2条sql:
UPDATE leaf_alloc SET max_id = max_id + step WHERE biz_tag = #{tag}
SELECT biz_tag, max_id, step FROM leaf_alloc WHERE biz_tag = #{tag}
然后加载到本地
N个server执行上述操作,对外提供http接口用于生成id,整体架构如下图所示:

优点:
- Leaf服务可以很方便的线性扩展,例如按照biz_tag分库分表
- ID是趋势递增的64位数字,满足上述数据库存储的类型要求
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内仍能正常对外提供服务
- 易接入:可自定义初始max_id的值,方便业务从原有的ID方式上迁移过来
缺点:
-
业务上不够安全:ID近似于严格递增,会泄露发号数量的信息
-
TP999显著比其他TP值大:当号段使用完之后还是会hang在更新数据库的I/O上
- 以step=1000为例,99.9%的请求分配ID都非常快,0.1%的请求会比较慢(读写一次db平均5ms),如果恰好遇到db抖动,耗时能到几秒
-
单点问题:DB如果宕机会造成整个系统不可用
-
网络IO开销大:client每获取一个id,都要对leaf server发起一次http调用
双buffer优化
针对TP999大的问题,Leaf号段模式做了一些优化:在内存中维护两个号段,在当前号段消费到一定百分比时,就 异步去db加载下一个号段 到内存中
这样当前号段用完后,就能马上切换到下一个号段

biz优化
对于每个请求,都需要校验参数中的biz是否合法。如果每次都去db查下biz在leaf_alloc表是否存在,性能开销大且没必要
leaf在实例启动时,将全量biz都查出来放到本地缓存中,之后每隔60s都会刷新一次,这样校验biz是否合法都用本地map判断,性能极高
缺点是最多延迟1分钟才新增的biz才生效
也就牺牲一点一致性换取超高的性能
动态step
如果每次获取号段的长度step是固定的,但流量不是固定的,如果流量增加 10 倍,每个号段很快就被用完了,仍然有可能导致数据库压力较大
同时也降低了可用性,例如本来能在DB不可用的情况下维持10分钟正常工作,那么如果流量增加10倍就只能维持1分钟正常工作了
因此leaf中每次从db加载号段时,加载多少ID并不是固定的
- 如果qps高,就可以一次多加载点,减少调db的次数
- 如果qps低,可以一次少加载点。否则在缓存中的号段迟迟消耗不完的情况下,会导致更新DB的新号段与前一次下发的号段ID跨度过大
leaf的策略为每次更新buffer时动态维护step,当需要从db加载号段时,计算距离上次从db加载过去了多久:
- 小于15mins:获取的号段长度翻倍
- 15~30mins:获取的号段长度和上次一样
- 大于30mins:获取的号段长度减半
源码走读
初始化:
public boolean init() {// 将所有biz加载到内存updateCacheFromDb();initOK = true;// 后台每1s刷新一次内存中的bizupdateCacheFromDbAtEveryMinute();return initOK;
}
获取ID流程如下:
public Result get(final String key) {if (!initOK) {return new Result(EXCEPTION_ID_IDCACHE_INIT_FALSE, Status.EXCEPTION);}// 校验biz是否合法if (cache.containsKey(key)) {SegmentBuffer buffer = cache.get(key);if (!buffer.isInitOk()) {synchronized (buffer) {if (!buffer.isInitOk()) {try {// 号段未初始化,从db加载号段updateSegmentFromDb(key, buffer.getCurrent());buffer.setInitOk(true);} catch (Exception e) {}}}}// 从号段获取IDreturn getIdFromSegmentBuffer(cache.get(key));}return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}
getIdFromSegmentBuffer方法:
public Result getIdFromSegmentBuffer(final SegmentBuffer buffer) {while (true) {buffer.rLock().lock();try {final Segment segment = buffer.getCurrent();// 如果当前号段已经用了10%,异步去加载下一个号段if (!buffer.isNextReady() && (segment.getIdle() < 0.9 * segment.getStep()) && buffer.getThreadRunning().compareAndSet(false, true)) {service.execute(new Runnable() {@Overridepublic void run() {// 加载下一个号段});}// 当前号段还没用完,从当前号段获取long value = segment.getValue().getAndIncrement();if (value < segment.getMax()) {return new Result(value, Status.SUCCESS);}} finally {buffer.rLock().unlock();}// 到这说明当前号段用完了waitAndSleep(buffer);buffer.wLock().lock();try {// 再次检查当前号段,因为可能别的线程加载了final Segment segment = buffer.getCurrent();long value = segment.getValue().getAndIncrement();if (value < segment.getMax()) {return new Result(value, Status.SUCCESS);}// 切换到下一个号段,重新执行while循环获取if (buffer.isNextReady()) {buffer.switchPos();buffer.setNextReady(false);} else {// 两个号段都不可用,报错return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);}} finally {buffer.wLock().unlock();}}}
最后看下怎么从db加载号段:
public void updateSegmentFromDb(String key, Segment segment) {SegmentBuffer buffer = segment.getBuffer();LeafAlloc leafAlloc;// ...// 动态调整下一次的steplong duration = System.currentTimeMillis() - buffer.getUpdateTimestamp();int nextStep = buffer.getStep();if (duration < SEGMENT_DURATION) {if (nextStep * 2 > MAX_STEP) {} else {nextStep = nextStep * 2;}} else if (duration < SEGMENT_DURATION * 2) {} else {nextStep = nextStep / 2 >= buffer.getMinStep() ? nextStep / 2 : nextStep;}LeafAlloc temp = new LeafAlloc();temp.setKey(key);temp.setStep(nextStep);// 从db获取下一个号段leafAlloc = dao.updateMaxIdByCustomStepAndGetLeafAlloc(temp);buffer.setUpdateTimestamp(System.currentTimeMillis());buffer.setStep(nextStep);buffer.setMinStep(leafAlloc.getStep());// 加载到内存中long value = leafAlloc.getMaxId() - buffer.getStep();segment.getValue().set(value);segment.setMax(leafAlloc.getMaxId());segment.setStep(buffer.getStep());
}
内存中Segment结构主要有以下字段:
- value:下一个要分配的ID
- max:当前号段的最大边界
每次从Segment中分配ID时,返回value的值即可,并把value++
雪花算法
号段模式的ID很接近严格递增,如果在订单场景,可以根据ID猜到一天的订单量。此时就可以用雪花算法模式
leaf在每一位的分配和标准snowflake一致:

-
最高位符号位为0
-
接下来41位:毫秒级时间戳
- 存储当前时间距离2010年某一天的差值
-
接下来10位:workerId
-
最后12位:每一毫秒内的序列号
每到新的毫秒时,每一毫秒内的序列号不是从0开始,而是从100以内的一个随机数开始
为啥这么设计?试想如果每一秒都从0开始,在qps低的情况下,每一毫秒只产生1个id,那么最末尾永远是0。如果对ID取模分表,就会永远在第0号表,造成数据分布不均
怎么设置workerId
对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。如果服务规模较大,动手配置成本太高。于是leaf用zookeeper 自动获取workerId,流程如下:
-
以自己的
ip:port为key,去zk建立持久顺序节点,以zk生成的自增序号为workerId- 创建的节点最后两级路径为:
/forever/ip:port-序列号
- 创建的节点最后两级路径为:
-
如果zk中已经有自己ip:port的节点,就
复用其workerId- 怎么判断?拉取/forever下所有节点,每个节点的格式为
ipport-序列号,判断每个节点中-前面的ipport是不是等于自己,如果等于取-后面的序列号作为workerId - 只有leaf server会创建zk节点,因此节点数量可控
- 为啥可以复用?不会在同一时刻,有相同ip:port的两个实例,因此复用一定不会发生冲突
- 怎么判断?拉取/forever下所有节点,每个节点的格式为
这种workerId分配策略能保证唯一性吗?能
- 如果
ip:port不同,在zk中一定是两个不同的序列号,因此不会冲突 - 一个集群中不可能同时存在ip:port相同的两个机器
每个leaf server的ip:port最好手动指定,或者部署在ip不会变化的环境中
高可用:workerId会存到本地文件,这样遇到极端情况:leaf server服务重启,且zk也宕机时,也不影响使用

解决时钟回拨
雪花算法严格依赖时间,如果发生了时钟回拨,就可能导致ID重复,因此需要监测是否发生了时钟回拨并处理,在服务启动和运行时都会检测
在服务启动时检测时间是否回退:
- leaf server运行时,每隔3s会上自己的当前时间到zk节点中
- 启动时,校验当前时间不能小于 zk中最近一次上报的时间
官方文档还提到如果是第一次启动,还会和其他leaf server校准时间。但源码中没找到这部分,应该是不需要做这个校准,已删除
在运行时检测时间是否回退:
-
全局维护了上次获取ID时的时间戳:
lastTimestamp -
如果当前时间
now < lastTimestamp,说明发生了时钟回拨- 回拨了超过5ms,返回报错
- 回拨了5ms内,sleep一会,直到赶上上次时间
如果zk宕机导致定时上报没有成功,同时又发生了时钟回拨,且leaf server宕机。此时leaf server启动时可能产生和之前重复的ID。因此需要做好监控告警,zk的高可用
如果3s内没上报,leaf server宕机了,然后时钟回退了2s,此时根据zk的时间检测不出来发生了时钟回退,也会造成ID重复。解决方法就是等一段时间才重启机器,保证等待的时间比回拨的时间长就行
源码走读
初始化:
public boolean init() {try {CuratorFramework curator = createWithOptions(connectionString, new RetryUntilElapsed(1000, 4), 10000, 6000);curator.start();Stat stat = curator.checkExists().forPath(PATH_FOREVER);if (stat == null) {//不存在根节点,机器第一次启动,创建/snowflake/ip:port-000000000,并上传数据zk_AddressNode = createNode(curator);//worker id 默认是0,存到本地文件updateLocalWorkerID(workerID);//每3s上报本机时间给forever节点ScheduledUploadData(curator, zk_AddressNode);return true;} else {Map<String, Integer> nodeMap = Maps.newHashMap();//ip:port->00001Map<String, String> realNode = Maps.newHashMap();//ip:port->(ipport-000001)//存在根节点,先检查是否有属于自己的节点List<String> keys = curator.getChildren().forPath(PATH_FOREVER);for (String key : keys) {String[] nodeKey = key.split("-");realNode.put(nodeKey[0], key);nodeMap.put(nodeKey[0], Integer.parseInt(nodeKey[1]));}Integer workerid = nodeMap.get(listenAddress);if (workerid != null) {//有自己的节点,zk_AddressNode=ip:portzk_AddressNode = PATH_FOREVER + "/" + realNode.get(listenAddress);workerID = workerid;//启动worder时使用会使用// 当前时间不能小于 zk中最近一次上报的时间if (!checkInitTimeStamp(curator, zk_AddressNode)) {throw new CheckLastTimeException("init timestamp check error,forever node timestamp gt this node time");}// 每3s上报时间doService(curator);// 将workerId写到本地updateLocalWorkerID(workerID);} else {//新启动的节点,创建持久节点 ,不用check时间String newNode = createNode(curator);zk_AddressNode = newNode;String[] nodeKey = newNode.split("-");workerID = Integer.parseInt(nodeKey[1]);doService(curator);updateLocalWorkerID(workerID);}}} catch (Exception e) {// zk不可用,从本地文件加载workerIdtry {Properties properties = new Properties();properties.load(new FileInputStream(new File(PROP_PATH.replace("{port}", port + ""))));workerID = Integer.valueOf(properties.getProperty("workerID"));} catch (Exception e1) {return false;}}return true;}
获取ID:
public synchronized Result get(String key) {long timestamp = timeGen();// 发生了时钟回拨if (timestamp < lastTimestamp) {long offset = lastTimestamp - timestamp;// 回拨了5ms内,sleep一会if (offset <= 5) {try {wait(offset << 1);timestamp = timeGen();if (timestamp < lastTimestamp) {return new Result(-1, Status.EXCEPTION);}} catch (InterruptedException e) {return new Result(-2, Status.EXCEPTION);}// 回拨了超过5ms,返回报错} else {return new Result(-3, Status.EXCEPTION);}}// 和上次在同一毫秒if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {//seq 为0表示是当前ms已经超过4096个ID了// 需要sleep一会,下一毫秒时间开始对seq做随机sequence = RANDOM.nextInt(100);timestamp = tilNextMillis(lastTimestamp);}} else {//如果是新的ms, 对seq做随机sequence = RANDOM.nextInt(100);}lastTimestamp = timestamp;long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;return new Result(id, Status.SUCCESS);}
总结
leaf提供两种分布式ID生成策略:
-
号段模式:
- 每次从db获取一批ID,而不是一个ID,减少调DB的频率
- 用双buffer解决TP999耗时高的问题
- 在内存判断参数biz是否合法,提高校验性能
- 使用动态step,解决突发流量造成对db压力仍然大的问题
-
雪花算法模式:
- 配合ZK做到动态获取workerId,解决海量机器的 workId 维护问题,也能保证正确性:同时不会有两个leaf server拥有相同的workerId
- 在服务启动时和运行时都校验是否发生了时钟回拨。不过服务启动时的校验有时会失效,最好sleep一段时间再重启,这段时间要大于时钟回拨的时间
相关文章:
分布式唯一ID生成(二): leaf
文章目录 本系列前言号段模式双buffer优化biz优化动态step源码走读 雪花算法怎么设置workerId解决时钟回拨源码走读 总结 本系列 漫谈分布式唯一ID分布式唯一ID生成(二):leaf(本文)分布式唯一ID生成(三&am…...

【开发工具】Git
目录 核心概念基本命令工作流程Commit message Git 是一个分布式版本控制系统,用于跟踪在软件开发过程中对文件的修改。它允许多个开发者协作处理项目,并且可以有效地管理代码的历史记录。以下是 Git 的一些核心概念和功能: 核心概念 仓库 (R…...

【go从零单排】结构嵌套struct embedding
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 在Go语言中,结构体嵌套(struct embedding)是一…...

Django 详细入门介绍
Django 详细入门介绍 1. 什么是 Django? Django 是一个开源的、用 Python 编写的 Web 框架。它遵循了“快速开发”和“不要重复自己”(DRY)的设计原则,旨在简化复杂的 Web 开发。Django 提供了多种强大的功能模块,如…...

万字长文解读深度学习——循环神经网络RNN、LSTM、GRU、Bi-RNN
🌺历史文章列表🌺 深度学习——优化算法、激活函数、归一化、正则化深度学习——权重初始化、评估指标、梯度消失和梯度爆炸深度学习——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总万字长文解读…...

HDR视频技术之二:光电转换与 HDR 图像显示
将自然界中的真实场景转换为屏幕上显示出来的图像,往往需要经过两个主要的步骤:第一个是通过摄影设备,将外界的光信息转换为图像信息存储起来,本质上是存储为数字信号;第二个是通过显示设备,将图像信息转换…...
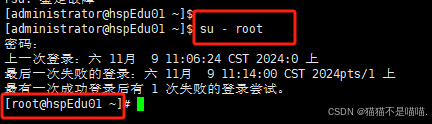
【Linux】Linux入门实操——vim、目录结构、远程登录、重启注销
一、Linux 概述 1. 应用领域 服务器领域 linux在服务器领域是最强的,因为它免费、开源、稳定。 嵌入式领域 它的内核最小可以达到几百KB, 可根据需求对软件剪裁,近些年在嵌入式领域得到了很大的应用。 主要应用:机顶盒、数字电视、网络…...

Redis的缓存问题与应对策略
Redis 作为一种高效的缓存系统,在高并发环境下应用广泛,但也面临一些缓存问题,以下是常见问题及其应对策略。 1. 缓存穿透 问题描述 缓存穿透是指请求的数据在缓存和数据库中都不存在,但大量请求直接到达数据库,从而给…...

Java项目实战II基于Spring Boot的智慧生活商城系统的设计与实现(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。 一、前言 随着科技的飞速发展,人们的…...

每日一题之成绩排序
在N(N<30)名运动员参加的体操比赛中,有K(K<10)名裁判给每位运动员分别打分, 按规则每名运动员最后得分需去掉一个最高分和一个最低分, 然后把其他裁判的打分相加,计算得出该运…...

QT Widget:使用技巧
1、Qt中的QString和const char *之间转换,最好用toStdString().c_str()而不是toLocal8Bit().constData(),比如在setProperty中如果用后者,字符串中文就会不正确,英文正常。 2、数据库处理一般建议在主线程,如果非要在…...

深入Zookeeper节点操作:高级功能与最佳实践
Zookeeper之节点基本操作(二) 在《Zookeeper之节点基本操作(一)》中,我们介绍了如何创建、读取、更新、删除节点的基本操作。接下来将进一步探讨Zookeeper中节点的进阶操作和更多细节,包括节点的监视&…...

【C++】map和set的介绍及使用
前言: map和 set 是 C STL(标准模板库)中的两种非常重要的容器,它们基于一种叫做平衡二叉搜索树(通常是红黑树)的数据结构来实现。在 C 中,map 是一个键值对容器,set 只存储唯一的键…...

从0开始搭建一个生产级SpringBoot2.0.X项目(十)SpringBoot 集成RabbitMQ
前言 最近有个想法想整理一个内容比较完整springboot项目初始化Demo。 SpringBoot集成RabbitMQ RabbitMQ中的一些角色: publisher:生产者 consumer:消费者 exchange个:交换机,负责消息路由 queue:队列…...

GNU/Linux - /proc/sys/vm/drop_caches
/proc/sys/vm/drop_caches 是 Linux 中的一个特殊文件,允许用户释放系统内存中的各种缓存。让我们深入了解一下这项功能的细节: The /proc/sys/vm/drop_caches is a special file in Linux that allows users to free up various caches in the systems …...

ubuntu 22.04 如何调整进程启动后能打开的文件数限制
在 Ubuntu 22.04 中,可以通过修改系统配置来调整进程启动后能够打开的文件数软限制。软限制是指操作系统允许单个进程打开的文件描述符的最大数量。以下是调整该限制的方法: 1. 查看当前限制 首先,你可以通过 ulimit 命令查看当前的软限制和…...
linux基础-完结(详讲补充)
linux基础-完结 一、Linux目录介绍 二、基础命令详细讲解 1. ls(列出目录内容) 2. cd(更改目录) 3. clear(清除终端屏幕) 4. pwd(显示你当前所在的目录) 5. vim(文本编辑器) 6. touch(创…...

LoRA:大型语言模型(LLMs)的低秩适应;低秩调整、矩阵的低秩与高秩
目录 LoRA:大型语言模型(LLMs)的低秩适应 一、LoRA的基本原理 二、LoRA的举例说明 三、LoRA的优势 低秩调整、矩阵的低秩与高秩 一、低秩调整(LoRA) 二、矩阵的低秩 三、矩阵的高秩 LoRA:大型语言模型(LLMs)的低秩适应 LoRA(Low-Rank Adaptation of LLMs),…...

游戏引擎学习第四天
视频参考:https://www.bilibili.com/video/BV1aDmqYnEnc/ BitBlt 是 Windows GDI(图形设备接口)中的一个函数,用于在设备上下文(device context, DC)之间复制位图数据。BitBlt 的主要用途是将一个图像区域从一个地方复…...

GIT GUI和 GIT bash区别
Git GUI 和 Git Bash 都是与 Git 版本控制工具相关的用户界面,但它们有不同的功能和用途。下面详细说明它们的区别及各自的作用: Git GUI 作用: Git GUI 是一个图形用户界面(GUI)工具,用于执行 Git 操作。…...

跨越系统边界:在Windows上体验Btrfs文件系统的5个关键优势
跨越系统边界:在Windows上体验Btrfs文件系统的5个关键优势 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs 当谈到高级文件系统时,Linux用户早已熟悉Btrfs的强大…...
、GELU激活函数与数据预处理那些事儿)
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿
BERT PyTorch实现避坑指南:torch.gather()、GELU激活函数与数据预处理那些事儿 当你第一次尝试在PyTorch中实现BERT模型时,可能会遇到一些令人困惑的技术细节。本文将从实际调试的角度,深入解析三个最容易卡住开发者的关键点:torc…...

2026年国内GEO优化服务商盘点:6家主流选择的实际情况
说明: 本文盘点基于各服务商官网、公开媒体报道、可查询的工商信息整理,所有"案例数据"均来自服务商自我披露。GEO行业整体处于早期阶段,市场上自我标榜"行业第一""全球最强"的说法普遍存在,本文尽…...

【建筑学研究降维打击】:为什么顶尖事务所已禁用传统文献管理?NotebookLM智能溯源+跨语言规范比对实战拆解
更多请点击: https://intelliparadigm.com 第一章:NotebookLM建筑学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于用户自有文档的 AI 助手,正悄然重塑建筑学研究的方法论边界。它不再依赖通用知识库的泛化回答,而是以建…...

Spring源码全家桶核心宝典,Java程序员提升基础内功必备!
Spring是我们Java程序员面试和工作都绕不开的重难点。很多粉丝就经常跟我反馈说由Spring衍生出来的一系列框架太多了,根本不知道从何下手;大家学习过程中大都不成体系,但面试的时候都上升到源码级别了,你不光要清楚了解Spring源码…...

RISC-V SoC上DNN加速的内存优化与FTL算法实践
1. RISC-V SoC上的DNN加速内存优化挑战在边缘计算场景下,深度神经网络(DNN)的部署面临严峻的内存带宽挑战。典型的RISC-V异构SoC(如Siracusa)采用多级软件管理内存架构,包含L1紧耦合存储器(32KB)、L2共享缓…...

量子退火误差缓解:经典阴影与局部虚拟纯化技术
1. 量子退火中的误差挑战与经典阴影方法量子退火(Quantum Annealing, QA)作为量子计算领域的重要算法,在优化问题求解中展现出独特优势。然而,实际硬件实现时面临的退相干问题严重制约了其计算精度。传统量子纠错方案需要大量物理…...

ARMv8 PMU架构与性能监控实战指南
1. ARMv8 PMU架构深度解析在ARMv8架构中,性能监控单元(Performance Monitor Unit, PMU)是处理器微架构层面的重要组件,它为开发者提供了硬件级别的性能数据采集能力。不同于传统的软件性能分析工具,PMU通过专用寄存器直接监控处理器内部事件&…...

Prometheus数据采集扩展:claw-prometheus项目详解与实战
1. 项目概述:一个为Prometheus量身定制的“数据抓取器”在云原生和微服务架构大行其道的今天,监控系统的地位不言而喻。Prometheus,作为这个领域的“事实标准”,以其强大的多维数据模型和灵活的查询语言(PromQL&#x…...

告别GBIF官网卡顿!用R语言raster/dismo包5分钟搞定物种分布数据下载与清洗
告别GBIF官网卡顿!用R语言raster/dismo包5分钟搞定物种分布数据下载与清洗 当你在深夜赶论文,急需下载某个物种的全球分布数据时,GBIF官网却不断弹出"503 Service Unavailable";当你终于打开页面,却发现每页…...