大语言模型鼻祖Transformer的模型架构和底层原理


Transformer 模型的出现标志着自然语言处理(NLP)技术的一次重大进步。这个概念最初是针对机器翻译等任务而提出的,Transformer 后来被拓展成各种形式——每种形式都针对特定的应用,包括原始的编码器-解码器(encoder-decoder)结构,以及仅编码器(encoder-only)和仅解码器(decoder-only)等变体结构,满足不同的 NLP 任务。
本文将从基础的 encoder-decoder 架构开始介绍 Transformer 模型及其机制和能力。通过探索模型精巧的设计和计算过程,我们将揭秘为什么 Transformer 成为了现代 NLP 进步的基石。
01.
Transformer 简介
自问世以来,Transformer 模型在 NLP 领域一直是一个颠覆性的存在。它以三种变体出现:encoder-decoder、encoder-only 和 decoder-only。最初的模型是 encoder-decoder 形式,这为我们提供了 Transformer 模型基础设计的全面视图。
自注意力机制(Self-attention mechanism)是 Transformer 架构的核心,最初主要是为语言翻译而开发的。以下是它的工作原理:一个句子被分解成片段,又称为 Token。这些 Token 通过 encoder 中的多个层进行处理。每一层都从其他 Token 中提取信息,通过自注意力机制丰富信息,使其富有更多的上下文线索,从而细化这些 Token。这个过程产生了更深层次、更有意义的 Token 表示或者称为 Embedding。
增强后,就可以将这些 Embedding 传递给 decoder。Decoder 的结构与 encoder 类似,使用自注意力和另一种称为交叉注意力(cross-attention)的额外组件。交叉注意力机制使得 decoder 访问并整合 encoder 输出中的相关信息,确保翻译的词对齐源上下文。
在实践中,翻译一个词需要从源句子中确定相关细节——特别是与目标词密切相关的 Token。然后解码器一次生成目标语言中的一个词,使用正在构建的句子的上下文作为指导,直到它遇到一个表示句子结束的特殊 Token。这种基于注意力的方法使模型能够产生不仅准确而且能够把握上下文中细微差别的翻译文本。
02.
Transformer 模型架构
下图展示了 Transformer 模型的架构。
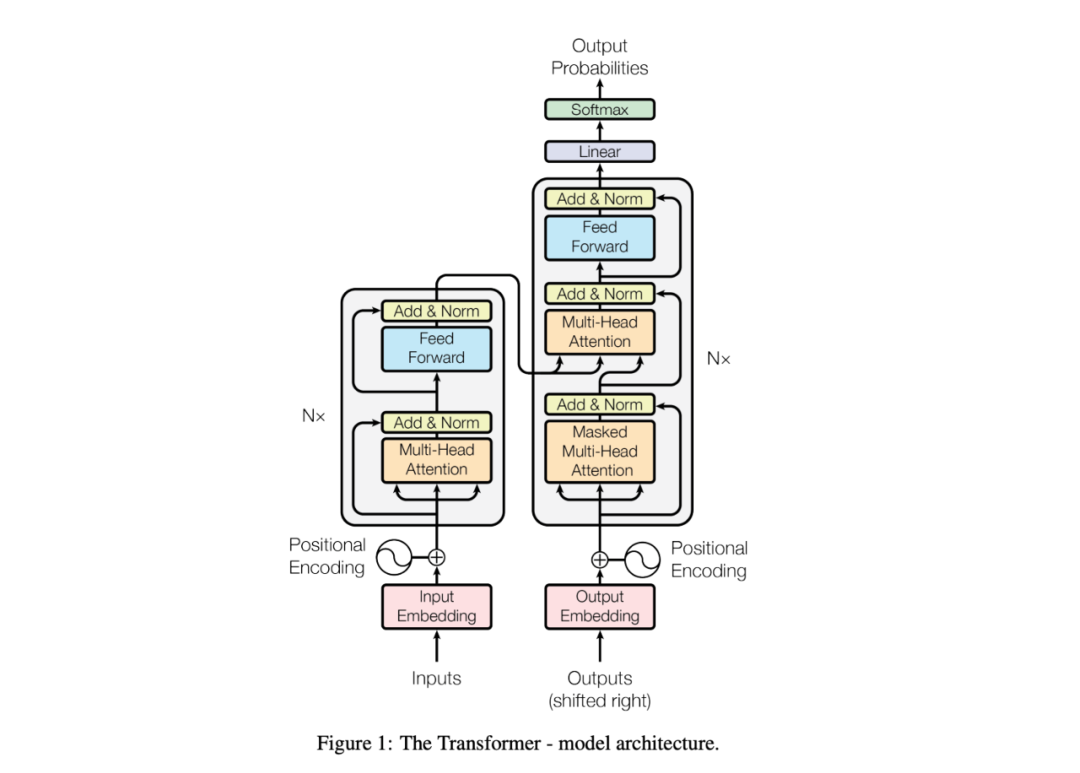
在图片的左下角,Input 代表输入的源文本,通过一个 embedding 层转换成输入 embedding。这个 embedding 层就像一个字典,为每个 token 查找一个对应的向量。获得 token embedding 之后,会加上位置编码(positional encoding)。这个位置编码帮助模型理解 token 的相对位置。这对于注意力机制至关重要,因为模型本身并不天生感知 token 顺序,而token顺序是处理语言的一个关键因素。
接下来,token embedding 和位置编码进入多头注意力(Multi-Head Attention)模块。这个模块允许模型同时关注输入序列的不同部分。在注意力机制之后应用了残差连接(residual connection)和 Add & Norm 层。这些结构和技术能够有效防止梯度消失从而帮助模型训练收敛,使得能够进行更深层的网络训练。你会注意到这些结构在模型的其他部分也同样出现。
多头注意力的输出随后通过前馈(Feed-Forward)模块。这个前馈网络对每个 embedding 单独地应用相同的非线性激活层,使 embedding 的表达能力更强,更适应当前处理的任务。Encoder 网络左侧的 "N×" 符号表示这是一个多层架构——每一层的输出成为下一层的输入。
在图片的右侧是 decoder,它与 encoder 采用类似的架构。然而,这里也有一些关键的不同点。decoder 包括一个遮蔽多头注意力(Masked Multi-Head Attention)层,确保每个 embedding 只能关注更早的位置,防止来自未来 token 的信息泄露到当前位置。此外,decoder 利用交叉注意力机制关注 encoder 输出的 embedding,从而对齐源语言的上下文与生成的目标语言。
最后,经过 decoder 后,输出 embedding 通过 softmax 层转换成概率,预测目标序列中的下一个词。这个生成过程一直重复生成一个个token,直到生成一个通常标志着句子结束的特殊 token。
03.
理解 Encoder 的核心概念
Encoder 中包含多个模块,让我们了解一下这些模块。
缩放点积注意力(Scaled Dot-Product Attention)
多头注意力(Multi-Head Attention, MHA)的核心是缩放点积注意力机制。为了更好地理解 MHA,我们需要先解释 Scaled Dot-Product Attention 这个概念。
从字面意义上,注意力意味着每个 embedding 需要关注相关的 embedding 从而收集上下文信息。在注意力计算中有三个角色:查询(Queries, Q)、键(Keys, K)和值(Values, V)。假设你有 N 个查询 embedding 和 M 对键值对。以下是注意力机制的计算方式:
相关性计算:计算每个查询 embedding 与每个键 embedding 的相关性。这通常是通过查询embedding和每个键embedding之间的点积(dot product)来完成的。
归一化:然后对这些计算结果进行归一化。这一步确保所有相关性得分的总和为一,从而得到比例表示,其中每个得分反映了查询与键之间的相关程度。
上下文表示:最后,每个查询 embedding 被重新组合成一个新的带有上下文信息的表示。这是通过结合与每个键相对应的值 embedding 来实现的,权重由归一化的相关性得分决定。
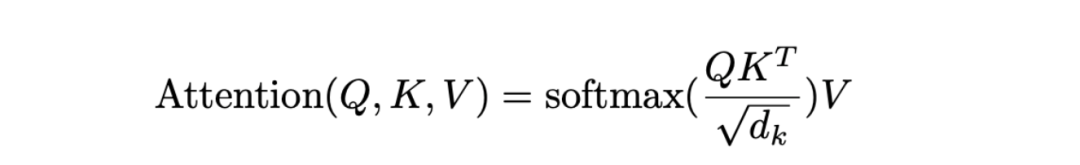
上述公式定义了缩放点积注意力(Scaled Dot-Product Attention):所有 N 个查询 embedding(维度为 d)被堆叠成一个 N×d 的矩阵 Q。同样,K 和 V 分别是 M×d 的矩阵,代表 M 个键 embedding 和值 embedding。通过矩阵乘法,我们得到一个 N×M的矩阵,其中每一行对应于一个查询 embedding 与所有 M 个键 embedding 的相关性。然后我们通过 softmax 操作来归一化这些行,确保每个查询的相关性得分总和为 1。接下来,我们将这个归一化的得分矩阵与 V 矩阵相乘,以获得上下文化的表示。
另外,需要注意的是,注意力得分通过 √dk 进行缩放。原作者解释说,维度越高,点积得分越大,这可能会使 softmax 函数不平均地给单个键分配过高的注意力。为了缓解这个问题,点积通过 √dk 进行缩放,从而得到更平衡的注意力权重。
多头注意力(Multi-Head Attention)
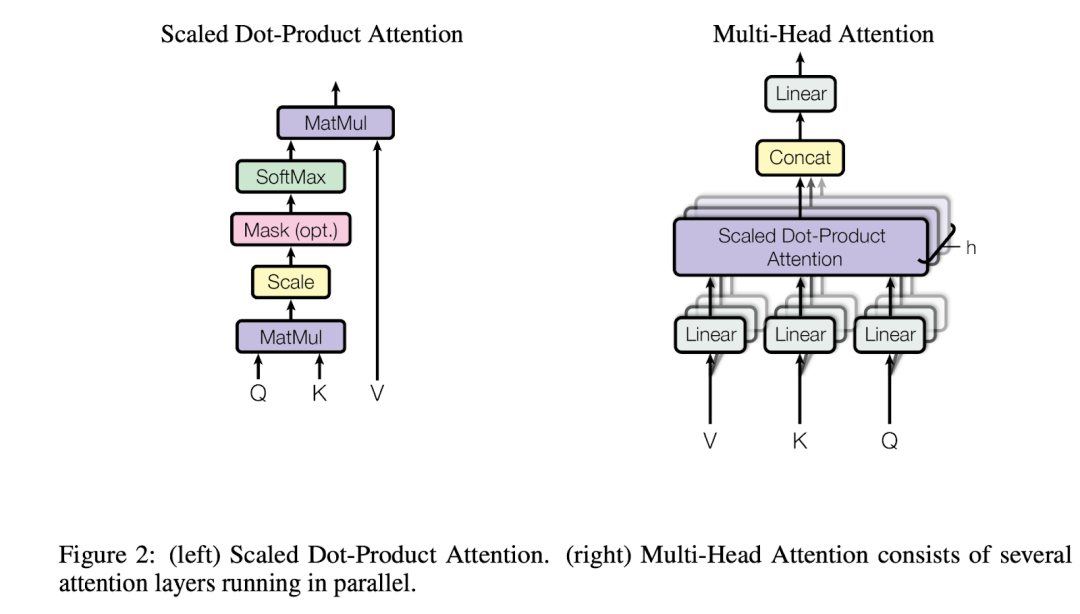
Transformer 模型采用了一种称为多头注意力的技术来增强其处理能力。这种机制首先通过线性层来转换注意力的组成部分——查询(Queries, Q)、键(Keys, K)和值(Values, V)。这种转换引入了额外的参数,增强了模型从更多数据中学习的能力,从而提高了其整体能力。
在多头注意力机制中,这些转换后的 Q、K 和 V 元素会经历缩放点积注意力(Scaled Dot-Product Attention)过程。原始设计规定了多个(通常是8个)并行的线性层和注意力层实例。这种并行处理不仅加快了计算速度,还引入了更多参数,进一步细化了 embedding。
每个并行实例为每个查询生成一个单独的转换后的 embedding,称为“头”(head)。有8个这样的头,假设每个头的维度为 ,所有头的输出组合结果在总维度上为 。为了将这些结果能够重新映射成为下一层的输入,另一个线性层使用投影矩阵 投影这个连接(concat)的输出,将其调整为模型指定的维度,。这种结构化的方法允许 Transformer 同时利用多个视角,显著增强了其识别和解释复杂数据的能力。

在 Transformer 的多头注意力机制中,层 、 和 (其中 i 表示 8 个实例中的一个)是三个线性层,专门用于转换注意力计算的查询(Queries, Q)、键(Keys, K)和值(Values, V)。这些层将 embedding 投影到维度 、 和 ,通常这些维度是相同的。
注意力机制的核心思想是通过整合周围单词的上下文信息来增强每个单词的 embedding。例如,在将英语句子“Apple company designed a great smartphone.”翻译成法语时,单词“Apple”需要吸收来自相邻单词“company”的上下文。这帮助模型理解“Apple”是一个商业公司实体,而不是苹果,从而不会翻译成为“pomme”,即字面上的水果。这个过程被称为自注意力(self-attention)。
另一方面,在 Transformer 的 decoder 部分,使用了一种称为交叉注意力的技术。其中 decoder 关注来自 encoder 输出的不同信息片段,从而将源文本中相关上下文信息整合到翻译输出中。这种交叉注意力机制帮助 Transformer 模型有效理解翻译的细微语境区别,从而帮助更好的翻译。
位置编码(Positional Encoding)
一旦你熟悉了 Transformer 模型中的注意力机制,位置编码的概念就会变得更加直观。多头注意力的一个关键挑战是它本身并不考虑句子中单词的顺序。
以一个简单的句子为例:“Tim gives Sherry a book.” 在 MHA 中,对于“Sherry”的查询(Q)embedding 与其对应的键(K)和值(V)embedding 进行交互时,并没有意识到其在句子中的位置,从而导致“Tim gives Sherry a book”与“Sherry gives Tim a book”从注意力计算角度上来说是一致的。因此,单词出现的顺序对于理解它们的含义至关重要。
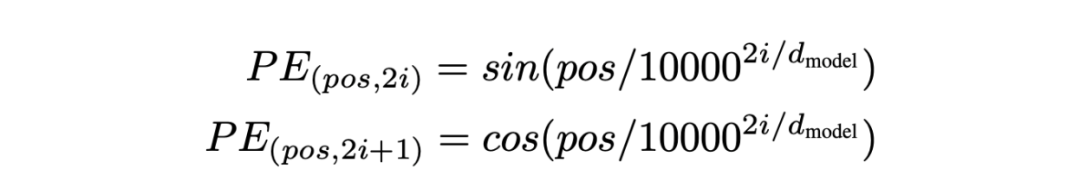
为了解决这个问题,作者修改了注意力计算,并引入了位置信息。例如,我们希望点积计算 能够反映它们的位置,变成 。
这种调整可以让模型识别并利用单词在句子中的位置。
位置编码是通过向每个 token 的 embedding 加上一个特殊的 embedding 来实现的。这个位置 embedding 具有相同的维度 ,并且为句子中的每个位置分配一个独特的编码。余弦和正弦函数分别为位置embedding的奇数和偶数索引的维度生成对应的值。这种方法确保了位置信息能够无缝地集成到基础 embedding 中,增强了模型根据单词顺序解释和生成文本的能力。
前馈网络(Feed Forward Network)
在多头注意力阶段之后,embedding 通过交互被精炼成包含上下文的表示,然后这些 embedding 会通过前馈网络(FFN)进行处理,以进一步增强它们的表示能力。
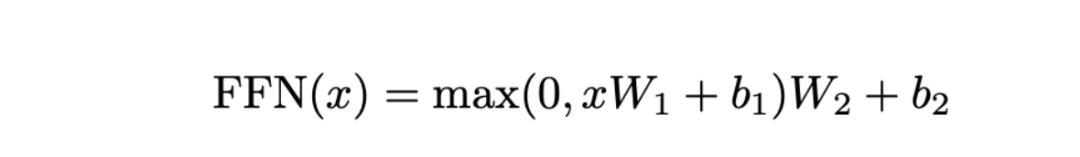
前馈网络(FFN)以一个输入开始,记作 ,这是一个维度为 的 embedding,通常设置为 512。FFN 的第一个组成部分是一个线性层,其特征参数为 和 。这个层将 embedding 从 512 维扩展到一个 2048 维的空间。在这个扩展之后,应用了 ReLU 激活函数,定义为 。ReLU 是引入非线性的主流选择,这对于增强模型捕捉数据中的复杂规律至关重要。
接下来,是另一个线性层,配备有参数 和 ,将 embedding 投影回原始的 512 维。这个两个包含非线性的过程是必不可少的,否则整个操作将是线性的,从而可以融合进前面的 MHA 层,从而失去模型的灵活性。
通过这个前馈层后,embedding 被转换成一个具有高度表达能力的、富含上下文的表示。当几个(通常是6个)Transformer 层堆叠时,每一层都以这种方式丰富 embedding,最终为原始 token embedding 提供更深度、丰富的抽象表示。这些增强的 embedding带有了细粒度而又全面的上下文信息, 之后将被解码成目标语言。
04.
Decoder
Transformer 模型中的解码器也由多个层组成,与编码器的主要区别在于包含了一个遮蔽的多头注意力(masked Multi-Head Attention, MHA)机制。与编码器不同,解码器中的这个 MHA 模块与交叉注意力模块配对,后者与编码器的输出进行交互,这对于将输入序列翻译成目标语言至关重要。
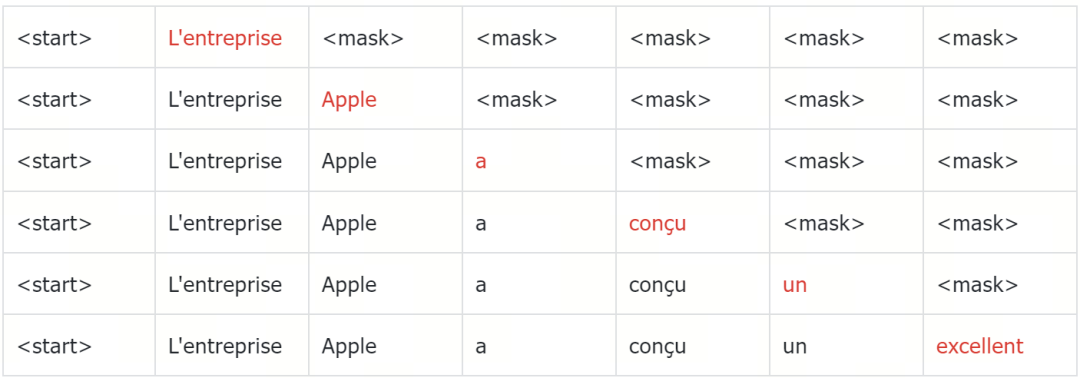
解码过程以一个特殊的 token 开始,标志着目标序列翻译的开始。以一个英语句子为例,“Apple company designed a great smartphone.”被翻译成法语为“L'entreprise Apple a conçu un excellent smartphone。”
解码器的第一个任务是预测紧随其后的 token。在这种情况下,token “L'entreprise” 应该具有最高的概率,这由编码器对英语句子 embedding 提供的上下文线索引导。这种预测能力源于模型在大量双语文本语料库上的训练。
从初始 token “L'entreprise” 开始,解码器继续预测后续的 token。例如,在“L'entreprise”之后,预测的下一个 token 具有最高概率的是“Apple”。这种逐步的 token 生成持续进行,直到解码器生成一个 特殊的结束token。在我们的例子中,这个过程涉及按顺序预测每个法语单词,直到句子完全形成,并在第七个 token 后结束。
解码器还包含一个最终层,该层计算潜在下一个 token 的概率,有效地确定序列每一步最可能延续出来的 token。这个层对于确保最终输出至关重要,因为对于翻译任务不仅需要生成语法正确的句子,同时也要根据编码器的输出产生语义一致的句子。
遮蔽多头注意力(Masked Multi-Head Attention)
解码和编码在收集每个 embedding 的上下文信息方面的最大区别在于如何进行这个过程。在编码过程中,每个 embedding 都可以访问所有其他 embedding(这意味着它从整个序列中收集上下文的相关信息)。然而,在解码过程中,模型只能从前面的文本中收集信息,而不能提前获取尚未生成的未来信息。这在语言模型中被称为因果关系。
 ....
....
在遮蔽多头注意力过程中,高亮的 token 是查询 embedding,同一行中的 token 代表其注意力范围。"L'entreprise" 不应该使用 "Apple" 的信息;否则,这将导致解码过程中的不一致性。这确保了每个生成的 token 都基于它所接收到的信息是具有最高概率的 token。否则,如果一个生成的 token 后来变成了中间 token 并且能够接收到在它之后生成的 token 的信息,那么它可能会做出与最初生成时不同的选择,这可能会导致解码过程变得混乱。实际的方法是对每个 token 应用一个遮蔽。例如,在多头注意力机制中,从序列 "L'entreprise Apple a conçu un excellent" 生成 token "smartphone" 时,会应用一个遮蔽到查询上,使得所有查询 token 之后的 token 都不能与之交互。每个查询 token 将有不同的遮蔽,确保维持因果关系(查询 token 只能关注它之前的键 token)。
多头交叉注意力(Multi-Head Cross Attention)
为了确保解码器准确地将英语句子转换为连贯的法语翻译,它采用了多头交叉注意力。如果没有这个机制,解码器可能只会生成无关的法语短语,缺乏对原始英语的语义一致性。交叉注意力通过将编码器的输出(也就是编码后的英语句子 embedding) 整合到解码过程中来解决这个问题。
交叉注意力机制类似于自注意力(self-attention),序列中的每个法语 token 从之前生成的法语 token 中构建上下文,允许这些 token 也访问编码后的整个范围内的英语 token 。但与自注意力机制不同的地方在于,注意力机制中的键(keys)和值(values)来自这些最终编码的英语 embedding,并且不需要遮蔽,因为整个英语句子都是可用且相关的。
这种架构确保每个生成的法语 token 都受到对应英语句子的丰富上下文的影响,从而保持翻译的语义完整性和逻辑一致性。
此外,这种方法体现了生成式 AI 的一个广泛原则:将特定条件(比如指令、遮蔽或标签)嵌入到潜在 embedding 中,并利用交叉注意力将这些条件整合到生成模型的工作流程中。这种方法提供了一种基于预定义条件控制和引导数据生成过程的方式,从而根据给定的条件控制生成式模型的输出。由于不同类型的数据都可以表示为 embedding,交叉注意力是跨各种数据类型连接和整合信息的有效工具,增强了模型生成感知上下文和控制输出的能力。
最终预测头(Final Prediction Head)
经过 Nx 个解码器处理后,我们需要将 embedding 解码回法语 token。最终预测头接收解码器生成的序列中的最后一个 embedding,并将其转换为法语词汇表上的概率分布。这是通过一个线性层后跟一个 softmax 函数来完成的。线性层为每个可能的下一个 token 打分,而 softmax 将这些分数转换为概率,来让模型预测序列中下一个最可能的词。
05.
使用 Transformer 模型推理的示例
我们已经描述了 Transformer 中涉及的模块。为了说明 Transformer 模型的工作原理,让我们从数据流的角度,梳理一下将英语句子 "Apple company designed a great smartphone." 翻译到法语的过程:
Tokenization 和 Embedding:
-
句子被标记成离散的元素——单词或短语——这些元素从一个预定义的词汇表中索引。
每个 token 随后被转换成一个向量,使用 embedding 层将单词转换成模型可以处理的形式。
位置编码:
-
为每个 token 生成位置编码,以提供模型关于句子中每个单词位置的信息。这些编码信息被添加到 token embedding 中,从而让注意力机制感知到单词的顺序关系。
编码器处理:
-
与位置编码相加后的 embedding 进入编码器,首先通过一个自注意力多头注意力(MHA)层,其中多个并行的线性变换将输入转换成查询(Q)、键(K)和值(V)的embedding序列。它们经过注意力计算进行交互,从而为每个 token 提供丰富的上下文信息。
这种交互的输出随后通过一个前馈网络(FFN)处理,引入非线性和额外的参数,进一步增强 embedding 表示信息的能力。
多层计算:
-
一个编码器层的输出进入下一个层,逐步增强 embedding 的上下文信息。经过几个层后,编码器输出一组高度信息化的 embedding,每个 embedding 对应输入句子中的一个 token。
解码器初始化:
-
翻译开始于解码器接收一个起始 token "<start>"。这个 token 也被转换成 embedding 并编码位置信息。
解码器处理这个初始输入,首先通过一个遮蔽 MHA。在这个阶段,由于 "<start>" 是唯一的 token,它基本上只关注自己。
顺序解码:
-
随着更多 token 被生成(例如 "L'entreprise Apple a"),解码器中的每个新 token 只能关注之前生成的 token,以保持语言的逻辑顺序。
解码器中的交叉注意力:
-
交叉注意力 MHA 层使解码器中的每个新 token 也能关注所有编码器产生的 embedding。这一步至关重要,因为它能够让解码器访问原始英语句子的全部上下文,确保翻译在语义和句法上对齐。
预测和标记生成:
-
最终的解码器层输出下一个 token 的概率。在这种情况下,选择概率最高的 token "L'entreprise" 并追加到已解码的序列中。
重复这个过程,基于已产生的法语 token 和全部英语输入生成一个个新 token,直到最终生成一个终止 token "<end>",标志着翻译的完成。
这个示例详细展示了 Transformer 如何整合复杂的机制,如自注意力和交叉注意力,逐步高效地进行语言翻译。
06.
总结
Transformer 论文是深度学习研究中的一个里程碑。更重要的是,与此前的 RNN 方法相比,它能够引入更多的参数和进行高效的训练,从而实现进一步扩展,催生了如今的大语言模型(LLM)。它的 encoder-decoder 和自注意力、交叉注意力机制的设计也启发了我们使用一系列 embedding 以统一的形式表示不同模态的数据,从而实现多模态学习。希望这篇文章能够帮助您充分了解相关概念。此外,我们还提供了一系列资源供您深度阅读。
更多资源
论文:Attention Is All You Need (https://arxiv.org/abs/1706.03762)
Sentence Transformers for Long-Form Text (https://zilliz.com/learn/Sentence-Transformers-for-Long-Form-Text)
Transforming Text: The Rise of Sentence Transformers in NLP (https://zilliz.com/learn/transforming-text-the-rise-of-sentence-transformers-in-nlp)
What are Vision Transformers (ViT)? (https://zilliz.com/learn/understanding-vision-transformers-vit)
What is Detection Transformers (DETR)? (https://zilliz.com/learn/detection-transformers-detr-end-to-end-object-detection-with-transformers)
What is BERT (Bidirectional Encoder Representations from Transformers)? (https://zilliz.com/learn/what-is-bert)
Vector Database Stories (https://zilliz.com/blog)
What are Vector Databases and How Do They Work? (https://zilliz.com/learn/what-is-vector-database)
What is RAG? (https://zilliz.com/learn/Retrieval-Augmented-Generation)
作者介绍

王翔宇
Zilliz 算法工程师
2024年非结构化数据峰会的报名通道现已开启!
作为备受瞩目的年度重磅盛会,本次大会以“数绘万象,智联八方”为主题,邀请广大AI产业伙伴,从生态构建、客户案例、技术前瞻、商业化落地等多个角度共同研讨智能化的新未来。
如果您对AI产业化落地充满热情,渴望加入这场智慧的盛宴,请移步至文章末尾,扫描二维码即刻报名参与!



相关文章:
大语言模型鼻祖Transformer的模型架构和底层原理
Transformer 模型的出现标志着自然语言处理(NLP)技术的一次重大进步。这个概念最初是针对机器翻译等任务而提出的,Transformer 后来被拓展成各种形式——每种形式都针对特定的应用,包括原始的编码器-解码器(encoder-de…...

GB/T 43206—2023信息安全技术信息系统密码应用测评要求(五)
文章目录 附录AA.1 概述A.2 密钥产生A.3 密钥分发A.4 密钥存储A.5 密钥使用A.6 密钥更新A.7 密钥归档A. 8 密钥撤销A.9 密钥备份A.10 密钥恢复A.11 密钥销毁 附录B附录C 附录A A.1 概述 密钥管理对于保证密钥全生存周期的安全性至关重要 ,可以保证密钥(除公开密钥外) 不被非授…...

深度学习:BERT 详解
BERT 详解 为了全面详细地解析BERT(Bidirectional Encoder Representations from Transformers),我们将深入探讨它的技术架构、预训练任务、微调方法及其在各种自然语言处理(NLP)任务中的应用。 一、BERT的技术架构 …...

智能的编织:C++中auto的编织艺术
在C的世界里,auto这个关键字就像是一个聪明的助手,它能够自动帮你识别变量的类型,让你的代码更加简洁和清晰。下面,我们就来聊聊auto这个关键字的前世今生,以及它在C11标准中的新用法。 auto的前世 在C11之前&#x…...

订单分库分表
一、引言 在当今互联网时代,随着电商、金融等行业的快速发展,订单数量呈爆炸式增长。传统的单一数据库存储订单信息的方式面临着巨大的挑战,如数据存储容量有限、查询性能下降、数据备份和恢复困难等。为了解决这些问题,分库分表技…...

【温度表达转化】
【温度表达转化】 C语言代码C代码Java代码Python代码 💐The Begin💐点点关注,收藏不迷路💐 利用公式 C5∗(F−32)/9 (其中C表示摄氏温度,F表示华氏温度) 进行计算转化。 输出 输出一行&#x…...

封装一个web Worker 处理方法实现多线程
背景: 开启多线程处理一段耗时的逻辑 简化Worker使用 直接上代码: 以下是封装的函数直接复制即可 /*** 封装一个worker的启动函数 用于开启一个新的线程 来处理一些耗时的操作* param {object} paremdata 传递给worker的参数* param {function} call…...

unity3d————屏幕坐标,GUI坐标,世界坐标的基础注意点
在Unity3D中,GUI控件的起始坐标与屏幕坐标的起始点并不完全相同,具体说明如下: GUI控件的起始坐标 绘制GUI界面时使用的坐标以屏幕的左上角为(0,0)点,右下角为(Screen.width, Screen.Height)。不过,对于GUI控件的具体…...

MySQL基础-单表查询
语法 select [distinct] 列名1,列名2 as 别名... from数据表名 where组前筛选 group by分组字段 having组后筛选 order by排序的列 [asc | desc] limit 起始索引,数据条数 测试数据 # 建测试表 create table products (id int primary key a…...

Web安全之SQL注入---基础
文章目录 SQL注入简介SQL注入基础SQL注入分类SQL注入流程 SQL注入简介 什么是SQL注入? SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理…...

MongoDB笔记03-MongoDB索引
文章目录 一、前言1.1 概述1.2 MongoDB索引使用B-Tree还是BTree?1.3 B 树和 B 树的对比1.4 总结 二、索引的类型2.1 单字段索引2.2 复合索引2.3 其他索引 三、索引的管理操作3.1 索引的查看3.2 索引的创建3.2.1 单字段索引3.2.2 复合索引 3.3 索引的移除3.3.1 指定索…...

Docker基础(一)
Docker 简介 常用命令 镜像 #搜索镜像 docker search nginx #下载镜像 docker pull nginx #下载指定版本镜像 docker pull nginx:1.26.0 #查看所有镜像 docker images #删除指定id的镜像 docker rmi e784f4560448 # 删除多个镜像 docker rmi bde7d154a67f 94543a6c1aef e784…...

解决 IntelliJ IDEA Maven 项目 JDK 版本自动变为 1.5 的问题
一、问题描述 在使用 IntelliJ IDEA 创建 Maven 项目时,经常会遇到一个问题:项目的默认编译版本被设置为 JDK 1.5,即使系统中安装的是更高版本的 JDK。这不仅会导致编译时出现警告,还可能引起兼容性问题。每次手动修改编译版本后…...

SDL事件相关
文章目录 事件相关的函数和数据结构用户自定义事件代码相关: 事件相关的函数和数据结构 SDL_WaitEvent :等待一个事件SDL_PushEvent 发送一个事件SDL_PumpEvents(): 将硬件设备产生的时间放入事件队列 ,用于读取事件,在调用该函数之前&#…...

探索App Intents:让你的应用与Siri无缝互动的新方式
苹果推出了一个新框架——App Intents,使开发者可以在iOS 18.2、macOS 15.2等平台上集成Siri和Apple Intelligence,实现对应用内容的读取和操作。 App Intents使应用的功能和内容能无缝融入系统体验中,例如Siri、Spotlight搜索、快捷指令和小…...

冒泡排序法
编写程序实现冒泡排序。 相关知识 为了完成本关任务,要了解冒泡法排序的算法思想: 对所有相邻记录的关键字值进行比较,如果是逆序则将其交换,最终达到有序化,其处理过程为: 将整个待排序的记录序列划分成…...

MATLAB 将fig格式另存为可编辑的eps格式,但乱码问题解决
fig格式图像正常,但通过手动导出后的eps格式图像导入到AI中会乱码,如下图所示 一、主要问题应该是: 文件名中的字符和格式受到了操作系统和文件系统的限制,具体而言是 figure 的Name 属性中包含了特殊字体或字符(如逗号ÿ…...

Hadoop:单节点配置YARN
目录 一、Hadoop YARN介绍 二、单节点配置YARN 2.1 配置yarn-site.xml 文件 2.2 配置 mapred-site.xml 文件 2.3 启动 Hadoop 和 YARN 2.4 浏览器访问 三、YARN的常用命令 3.1 启动和停止 YARN 3.2 查看和管理应用程序 3.3 查看和管理节点 3.4 查看和管理队列 3.5 …...

【前端】Svelte:组件间通信
在 Svelte 中,组件间的通信主要通过 props 和事件机制来实现。父组件可以向子组件传递数据,子组件也可以通过事件将信息反馈给父组件。在本教程中,我们将深入了解 Svelte 的组件通信机制,包括 props 和事件的使用方法、事件监听、…...

数学建模-----假设性检验引入+三个经典应用场景(三种不同的假设性检验类型)
文章目录 1.假设检验的过程1.1问题的提出1.2证据的引入1.4做出结论 2.案例二:汽车引擎排放2.1进行假设2.2假设检验的类型2.3抽样分布的类型2.4单尾(双尾)检验2.5t检验 3.案例三:特鲁普效应3.1统计显著和效果显著3.2心理学现象3.3进…...

CryptoJS不同加密模式对比:AES-CBC vs GCM在前端安全中的选择指南
AES加密模式深度解析:CBC与GCM在前端安全中的实战抉择 前端开发者在处理用户敏感数据时,AES加密已成为标配技术方案。但在具体实施过程中,加密模式的选择往往成为决策难点——是选择经典的CBC模式,还是拥抱更现代的GCM模式&#x…...

k8s中部署prometheus并监控k8s集群以及nginx案例
4台主机 node1主机:k8s集群中的master node2主机:搭建了harbor仓库,存储所需的docker镜像 test3、4主机:k8s集群中的woker 搭建prometheus https://github.com/prometheus-operator/kube-prometheus 获取prometheus压缩包的…...

设备管理系统是什么?如何建立设备管理体系?
在现代企业的运转中,生产设备无疑是核心资产。无论是制造业的数控机床,还是建筑工地的重型机械,甚至是医疗机构的精密仪器,设备的稳定运行直接决定了企业的生产效率、产品质量和成本控制。然而,许多企业在设备管理上仍…...

3步搞定黑苹果配置:OpCore-Simplify自动化工具如何解决90%的安装难题
3步搞定黑苹果配置:OpCore-Simplify自动化工具如何解决90%的安装难题 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 开篇:黑苹…...

AI辅助开发进阶:让快马智能助手帮你设计与优化专业图像处理库
今天想和大家分享一个很实用的开发经验——如何用AI辅助工具来优化和扩展专业图像处理库的开发。最近我在做一个Python图像处理工具库,正好用InsCode(快马)平台的AI功能做了些尝试,效果出乎意料的好。 先说说背景。这个工具库最初只有基础的图片缩放和滤…...

Go Context 取消信号传播机制剖析
Go Context 取消信号传播机制剖析 在并发编程中,如何优雅地控制协程的生命周期是一个关键问题。Go语言通过Context机制提供了一种统一的取消信号传播方式,使得跨协程、跨层级的任务取消变得简单高效。本文将深入剖析Context的取消信号传播机制ÿ…...

Conda环境回滚实战:当安装新包搞崩base环境时如何一键恢复
Conda环境回滚实战:当安装新包搞崩base环境时如何一键恢复 在Python开发中,conda作为包管理和环境管理的利器,几乎成为数据科学家的标配工具。但越是频繁使用conda,越容易遇到一个令人头疼的问题——在base环境中安装新包后&#…...

玩转ESP32-S3调试:GDB高级命令与自定义调试技巧大全
玩转ESP32-S3调试:GDB高级命令与自定义调试技巧大全 调试嵌入式系统时,GDB的强大功能往往被低估。对于ESP32-S3开发者来说,掌握GDB的高级调试技巧可以显著提升解决复杂问题的效率。本文将深入探讨如何利用GDB的watch命令、自定义命令、跳转执…...
)
别再只会用AT指令了!用GD32F103驱动ESP8266实现MQTT连接阿里云(附完整源码)
从AT指令到MQTT协议:GD32F103ESP8266直连阿里云物联网平台实战 在物联网设备开发中,ESP8266作为性价比极高的Wi-Fi模块,常被用于实现设备联网功能。大多数开发者对它的认知停留在AT指令操作层面,通过串口发送简单的AT命令实现TCP连…...

[拆解LangChain执行引擎-07] 静态上下文在Pregel中的应用
在 Pregel 模型中,静态上下文是一个专门设计的依赖注入容器。它的出现是为了解决在复杂的图计算中,如何优雅地处理“不属于图状态,但Node运行又必须依赖的外部环境信息”这一痛点。这些数据具有一个共同的性质,那就是在整个运行生…...