用 Python 从零开始创建神经网络(四):激活函数(Activation Functions)
激活函数(Activation Functions)
- 引言
- 1. 激活函数的种类
- a. 阶跃激活功能
- b. 线性激活函数
- c. Sigmoid激活函数
- d. ReLU 激活函数
- e. more
- 2. 为什么使用激活函数
- 3. 隐藏层的线性激活
- 4. 一对神经元的 ReLU 激活
- 5. 在隐蔽层中激活 ReLU
- 6. ReLU 激活函数代码
- 7. Softmax 激活函数
引言
在本章中,我们将讨论几种激活函数及其作用。我们会根据不同的情况使用不同的激活函数,了解它们的工作原理可以帮助你正确选择最适合你任务的激活函数。激活函数应用于神经元(或神经元层)的输出上,这会修改输出。我们使用激活函数是因为如果激活函数本身是非线性的,它允许通常有两层或更多隐藏层的神经网络来映射非线性函数。我们将在本章展示这是如何工作的。
一般来说,你的神经网络将有两种类型的激活函数。第一种将用于隐藏层,第二种将用于输出层。通常,用于隐藏神经元的激活函数对所有神经元都是相同的,但也不必须如此。
1. 激活函数的种类
a. 阶跃激活功能

b. 线性激活函数

c. Sigmoid激活函数

d. ReLU 激活函数

e. more
会有更多的激活函数
2. 为什么使用激活函数
现在我们了解了激活函数代表什么,它们的一些形状,以及它们返回什么,让我们讨论为什么我们首先要使用激活函数。在大多数情况下,为了让神经网络拟合非线性函数,我们需要它包含两个或更多隐藏层,并且需要这些隐藏层使用非线性激活函数。
首先,什么是非线性函数?非线性函数不能被直线很好地表示,例如正弦函数:

虽然生活中确实存在一些本质上是线性的问题,例如,试图计算一定数量衬衫的成本,我们知道单件衬衫的成本,并且没有批量折扣,那么计算这些产品任意数量的价格的方程是一个线性方程。但生活中的其他问题就没有那么简单了,比如房价。影响房价的因素有很多,如面积、位置、销售的时间、房间数量、院子、邻里等等,这些因素使得房屋定价成为一个非线性方程。我们时代许多更有趣和更困难的问题都是非线性的。神经网络的主要吸引力在于它们解决非线性问题的能力。首先,让我们考虑一种情况,即神经元没有激活函数,这与激活函数为 y = x y=x y=x 相同。在一个具有2个隐藏层,每层8个神经元的神经网络中使用这种线性激活函数,训练这个模型的结果将是这样的(红):

如果使用同样的 2 个隐藏层,每个隐藏层有 8 个神经元,并使用整流线性激活函数,训练后我们会看到以下结果:

3. 隐藏层的线性激活
既然你已经看到了这种情况,我们还是应该考虑一下为什么会出现这种情况。首先,让我们重温一下 y = x y=x y=x 的线性激活函数,并从单个神经元的层面来考虑这个问题。在给定权重和偏置值的情况下,具有 y = x y=x y=x 激活函数的神经元的输出会是什么?让我们来看几个例子——首先,让我们尝试用正值更新第一个权重:

我们继续调整权重,这次更新为负数:

更新权重并增加偏差:

无论我们如何处理该神经元的权重和偏置,该神经元的输出都将与激活函数的y=x完全线性。这种线性性质将贯穿整个网络:

无论我们做什么,无论我们有多少层,只有当我们使用线性激活函数时,这个网络才能描述线性关系。这一点应该相当明显,因为每一层中的每个神经元都是线性的,所以整个网络也是一个线性函数。
4. 一对神经元的 ReLU 激活
我们认为,对于一个勉强算得上非线性的激活函数,比如经过矫正的线性激活函数,我们是如何突然映射出非线性关系和函数的,这一点并不那么明显,所以现在让我们来讨论一下这个问题。让我们从一个神经元开始。权重为 0,偏置为 0:

在这种情况下,无论我们通过什么输入,这个神经元的输出都将是 0,因为权重是 0,而且没有偏差。让我们将权重设为 1:

现在,它看起来就像基本的整流线性函数,没有任何意外!现在我们将偏置值设置为 0.50:

我们可以看到,在这种情况下,通过单个神经元,偏置水平偏移了整个函数的激活点。通过增加偏置,我们使这个神经元提前激活。如果我们将权重降为-1.0,会发生什么情况呢?

当我们有一个负权重和这一个单一神经元时,问题变成了这个神经元何时停止活动。到目前为止,你已经看到我们如何使用偏置来水平偏移函数,以及权重如何影响激活的斜率。此外,我们还能控制函数是用来确定神经元何时激活还是停止活动。
当我们不仅有一个神经元,而是一对神经元时会发生什么?例如,假设我们有2个隐藏层,每层各有1个神经元。回想一下 y = x y=x y=x 激活函数,我们不出所料地发现,无论我们制造了什么样的神经元链,线性激活函数都产生线性结果。让我们看看使用整流线性函数作为激活时会发生什么。我们将从第一个神经元的最后值开始,对第二个神经元使用权重为1,偏置为0:

到目前为止,我们可以看到没有任何变化。这是因为第 2 个神经元的偏置没有做任何偏移,第 2 个神经元的权重只是将输出乘以 1,所以没有变化。现在让我们试着调整第 2 个神经元的偏置:

现在,我们看到了一些相当有趣的行为。第二个神经元的偏置确实移动了整个函数,但不是水平移动,而是垂直移动。那么,如果我们将第二个神经元的权重设置为-2 而不是 1,会出现什么情况呢?

令人兴奋的事情发生了!我们这里的神经元既有激活点,也有失活点。当这两个神经元都激活时,当它们的 “作用区域 ”发挥作用时,它们就会产生颗粒、变量和输出范围内的数值。如果这对神经元中的任何一个处于非激活状态,这对神经元将产生非变量输出:

5. 在隐蔽层中激活 ReLU
现在让我们利用这个概念,使用两个隐藏层,每层8个神经元,来拟合正弦波函数,并手动调整值以适应曲线。我们将通过一次处理一对神经元来做到这一点,这意味着单独从每层中选取一个神经元。为了简化,我们还将假设层之间不是密集连接的,第一个隐藏层的每个神经元只连接到第二个隐藏层的一个神经元。通常情况下真实模型并非如此,但我们希望这种简化是为了这次演示的目的。此外,这个示例模型将一个单一值作为输入,即正弦函数的输入,并输出一个类似正弦函数的单一值。输出层使用线性激活函数,隐藏层将使用ReLU激活函数。
首先,我们将所有权重设置为0,并从第一对神经元开始工作:

接下来,我们可以将隐藏层神经元和输出神经元的权重设置为 1,然后就能看到这对输出的影响了:

在这种情况下,我们可以看到整个函数的斜率受到了影响。我们可以将第一层第一个神经元的权重调整为 6.0,从而进一步提高斜率:

现在我们可以看到,例如,这个函数的初始斜率是我们想要的,但我们有一个问题。当前这个函数永远不会结束,因为这对神经元从未停止活动。我们可以直观地看到我们希望停止活动发生的地方。就是红色拟合线(我们当前神经网络的输出)最初偏离绿色正弦波的地方。所以现在,虽然我们有了正确的斜率,我们需要将这个点设置为我们的停止活动点。为了做到这一点,我们首先将隐藏层对中第二个神经元的偏置增加到0.70。回想一下,这会垂直偏移整个函数:

现在,我们可以将第 2 个神经元的权重设置为-1,这样就会在我们想要的位置出现一个失活点,至少是水平失活点:

现在,我们想把这个斜率翻转回来。我们该如何翻转这两个神经元的输出呢?似乎我们可以将输出神经元的连接权重(目前为 1.0)翻转为-1,这样就可以翻转函数了:

当然,我们已经越来越接近让第一部分符合我们的要求了。现在,我们需要做的就是将其偏移一点点。在这个手工优化的例子中,我们将使用隐藏层中的前 7 对神经元来创建正弦波的形状,然后使用最下面的一对神经元来垂直偏移所有内容。如果我们将最下面一对神经元中第二个神经元的偏置设置为 1.0,输出神经元的权重设置为 0.7,就可以像这样垂直移动直线:

至此,我们已经完成了第一部分,“影响区域 ”是正弦波的第一个上升部分。我们可以开始下一个要做的部分。首先,我们可以将第二对神经元的所有权重设置为 1,包括输出神经元:

此时,这第二对神经元的激活开始得太早了,这影响了我们已经对齐的顶部一对的“影响区域”。为了解决这个问题,我们希望这第二对在第一对停止活动的地方开始影响输出,所以我们需要水平调整函数。正如你之前记得的,我们调整这对神经元中第一个神经元的偏置来实现这一点。此外,为了修改斜率,我们将设置进入这第二对中第一个神经元的权重,设为3.5。这和我们用来为第一部分设置斜率的方法相同,该部分由隐藏层中的顶部一对神经元控制。在这些调整之后:

现在,我们将使用与第一对神经元相同的方法来设置停用点。我们将隐藏层中第二个神经元的权重设为-1,偏置设为 0.27。

然后,我们可以翻转这部分的函数,方法与第一个函数相同,将输出神经元的权重从 1.0 设置为-1.0:

同样,就像第一对一样,我们将使用最下面的一对来固定垂直偏移:

然后,我们继续采用这种方法。我们将在顶部部分保持平缓,这意味着只有当我们希望斜坡开始下降时,才会开始激活第三对隐藏层神经元:

每个部分都重复这一过程,最终得出结果:

然后,我们就可以开始传递数据,看看这些神经元的作用区域是如何发挥作用的——只有当这两个神经元都根据输入被激活时才能发挥作用:

在这种情况下,如果输入值为 0.08,我们可以看到被激活的只有最上面的一对,因为这是它们的作用区域。继续看另一个例子:

在这种情况下,只有第四对神经元被激活。正如你所看到的,即使没有任何其他权重,我们也利用了一对神经元的一些粗略特性和整流线性激活函数,很好地拟合了这个正弦波。如果我们现在启用所有权重,让数学优化器进行训练,我们可以看到更好的拟合效果:

代码的可视化:https://nnfs.io/mvp
现在你应该明白,更多的神经元可以产生更独特的效果,为什么我们需要两个或更多的隐藏层,为什么我们需要非线性激活函数来映射非线性问题。举个更进一步的例子,我们可以把上面的例子中的 2 个隐藏层,每个隐藏层 8 个神经元,改为每个隐藏层使用 64 个神经元,这样就能看到更大的持续改进:

代码的可视化:https://nnfs.io/moo
6. ReLU 激活函数代码
尽管名字听起来很华丽,但整流线性激活函数的编码却很简单。最接近它的定义:
inputs = [0, 2, -1, 3.3, -2.7, 1.1, 2.2, -100]
output = []for i in inputs:if i > 0:output.append(i)else:output.append(0)print(output)
>>>
[0, 2, 0, 3.3, 0, 1.1, 2.2, 0]
我们先创建了一个值列表。这段代码中的 ReLU 是一个循环,我们在其中检查当前值是否大于 0,如果大于 0,我们就将其追加到输出列表中,如果不大于 0,我们就将其追加到输出列表中: 0 或神经元值。例如:
inputs = [0, 2, -1, 3.3, -2.7, 1.1, 2.2, -100]
output = []for i in inputs:output.append(max(0, i))print(output)
>>>
[0, 2, 0, 3.3, 0, 1.1, 2.2, 0]
NumPy 包含一个等价函数——np.maximum():
import numpy as npinputs = [0, 2, -1, 3.3, -2.7, 1.1, 2.2, -100]
output = np.maximum(0, inputs)print(output)
print("Type:", type(output))
>>>
[0. 2. 0. 3.3 0. 1.1 2.2 0. ]
Type: <class 'numpy.ndarray'>
该方法会比较输入列表(或数组)中的每个元素,并返回一个填充了新值的相同形状的对象。我们将在新的整流线性激活类中使用它:
import numpy as np# ReLU activation
class Activation_ReLU:# Forward passdef forward(self, inputs):# Calculate output values from inputself.output = np.maximum(0, inputs)
让我们在代码中将此激活函数应用于密集层的输出:
import numpy as np
import nnfs
from nnfs.datasets import spiral_datannfs.init()class Layer_Dense:# Layer initializationdef __init__(self, n_inputs, n_neurons):# Initialize weights and biasesself.weights = 0.01 * np.random.randn(n_inputs, n_neurons)self.biases = np.zeros((1, n_neurons))# Forward passdef forward(self, inputs):# Calculate output values from inputs, weights and biasesself.output = np.dot(inputs, self.weights) + self.biases# ReLU activation
class Activation_ReLU:# Forward passdef forward(self, inputs):# Calculate output values from inputself.output = np.maximum(0, inputs)# Create dataset
X, y = spiral_data(samples=100, classes=3)# Create Dense layer with 2 input features and 3 output values
dense1 = Layer_Dense(2, 3)# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()# Make a forward pass of our training data through this layer
dense1.forward(X)# Forward pass through activation func.
# Takes in output from previous layer
activation1.forward(dense1.output)# Let's see output of the first few samples:
print(activation1.output[:5])
>>>
[[0. 0. 0. ][0. 0.00011395 0. ][0. 0.00031729 0. ][0. 0.00052666 0. ][0. 0.00071401 0. ]]
>>> 没有应用ReLU激活函数的输出:
[[ 0.0000000e+00 0.0000000e+00 0.0000000e+00][-1.0475188e-04 1.1395361e-04 -4.7983500e-05][-2.7414842e-04 3.1729150e-04 -8.6921798e-05][-4.2188365e-04 5.2666257e-04 -5.5912682e-05][-5.7707680e-04 7.1401405e-04 -8.9430439e-05]]
正如你所看到的,负值已被削去(修改为零)。这就是隐藏层中使用的整流线性激活函数的全部内容。下面我们来谈谈最后一层输出所使用的激活函数。
7. Softmax 激活函数
在我们的案例中,我们希望这个模型成为一个分类器,因此我们需要一个适用于分类的激活函数。其中之一是Softmax激活函数。首先,为什么我们要费心使用另一个激活函数呢?这完全取决于我们的总体目标。在这种情况下,修正线性单元是无界的,不与其他单元标准化,并且是独立的。"不标准化"意味着值可以是任何数,比如输出 [ 12 , 99 , 318 ] [12, 99, 318] [12,99,318] 是没有上下文的,而"独立的"意味着每个输出都与其他输出无关。为了解决这种缺乏上下文的问题,softmax激活函数可以接收非标准化或未校准的输入,并为我们的类别产生一个标准化的概率分布。在分类的情况下,我们希望看到的是网络“认为”输入代表哪个类的预测。由softmax激活函数返回的这个分布表示每个类的置信度得分,并且总和为1。预测的类别与返回最大置信度得分的输出神经元相关联。然而,我们还可以在使用这个网络的总体算法/程序中注意到其他的置信度得分。例如,如果我们的网络对两个类的置信度分布是 [ 0.45 , 0.55 ] [0.45, 0.55] [0.45,0.55],预测结果是第二个类,但这个预测的置信度不是很高。也许在这种情况下,由于不太自信,我们的程序可能不会采取行动。
以下是Softmax函数:
S i , j = e z i , j ∑ l = 1 L e z i , l S_{i,j} = \frac{e^{z_{i,j}}}{\sum_{l=1}^L e^{z_{i,l}}} Si,j=∑l=1Lezi,lezi,j
这看起来可能令人生畏,但我们可以将其分解成简单的部分,用 Python 代码来表达,你可能会发现这比上面的公式更容易理解。首先,下面是一个神经网络层的输出示例:
layer_outputs = [4.8, 1.21, 2.385]
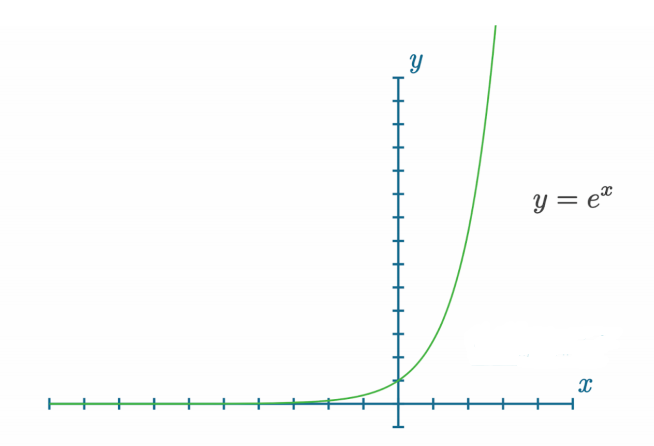
我们的第一步是将输出 “指数化”。我们使用欧拉数 e e e 来实现这一过程, e e e 约为2.71828182846,被称为 “指数增长 ”数。指数化就是将这个常数乘以给定参数的幂:
y = e x y=e^x y=ex
Softmax 函数的分子和分母都包含 e e e 升至 z z z 的幂,其中给定指数的 z z z 表示奇异输出值——指数 i i i 表示当前样本,指数 j j j 表示该样本中的当前输出。分子将当前的输出值指数化,分母则是给定样本中所有指数化输出的总和。然后,我们需要计算这些指数值才能继续:
# Values from the previous output when we described
# what a neural network is
layer_outputs = [4.8, 1.21, 2.385]# e - mathematical constant, we use E here to match a common coding
# style where constants are uppercased
E = 2.71828182846 # you can also use math.e# For each value in a vector, calculate the exponential value
exp_values = []
for output in layer_outputs:exp_values.append(E ** output) # ** - power operator in Pythonprint('exponentiated values:')
print(exp_values)
>>>
exponentiated values:
[121.51041751893969, 3.3534846525504487, 10.85906266492961]
幂级数有多种用途。为了计算概率,我们需要非负值。想象一下输出结果是 [4.8, 1.21, -2.385] —— 即使经过归一化处理,最后一个值仍然是负数,因为我们只是用所有值除以它们的总和。负概率(或置信度)没有太大意义。任何数字的指数值总是非负的–负无穷时返回 0,输入 0 时返回 1,正值时返回正数:
指数函数是一个单调函数。这意味着,随着输入值的增加,输出值也会增加,因此在确保我们得到非负值的同时,应用它不会改变预测的类别。它还增加了结果的稳定性,因为归一化的指数化更多地关注数字之间的差异而非它们的大小。一旦我们进行了指数化,我们希望将这些数字转换为概率分布(将值转换为每个类别的置信度向量,向量中的所有置信度加起来为1)。这意味着我们即将进行归一化,其中我们将给定值除以所有值的总和。对于我们此阶段指数化的输出,这就是Softmax函数方程接下来描述的内容 —— 将给定的指数化值除以所有指数化值的总和。由于每个输出值都归一化为总和的一部分,所有的值现在都在0到1的范围内,并且总和为1 —— 它们之间共享1的概率。让我们在代码中添加总和和归一化:
# Values from the previous output when we described
# what a neural network is
layer_outputs = [4.8, 1.21, 2.385]# e - mathematical constant, we use E here to match a common coding
# style where constants are uppercased
E = 2.71828182846 # you can also use math.e# For each value in a vector, calculate the exponential value
exp_values = []
for output in layer_outputs:exp_values.append(E ** output) # ** - power operator in Pythonprint('exponentiated values:')
print(exp_values)# Now normalize values
norm_base = sum(exp_values) # We sum all values
norm_values = []for value in exp_values:norm_values.append(value / norm_base)print('Normalized exponentiated values:')
print(norm_values)
print('Sum of normalized values:', sum(norm_values))
>>>
exponentiated values:
[121.51041751893969, 3.3534846525504487, 10.85906266492961]
Normalized exponentiated values:
[0.8952826639573506, 0.024708306782070668, 0.08000902926057876]
Sum of normalized values: 1.0
我们可以使用 NumPy 以下面的方式执行相同的操作:
import numpy as np# Values from the earlier previous when we described
# what a neural network is
layer_outputs = [4.8, 1.21, 2.385]# For each value in a vector, calculate the exponential value
exp_values = np.exp(layer_outputs)print('exponentiated values:')
print(exp_values)# Now normalize values
norm_values = exp_values / np.sum(exp_values)print('normalized exponentiated values:')
print(norm_values)
print('sum of normalized values:', np.sum(norm_values))
exponentiated values:
[121.51041752 3.35348465 10.85906266]
normalized exponentiated values:
[0.89528266 0.02470831 0.08000903]
sum of normalized values: 0.9999999999999999
请注意,计算结果与 NumPy 类似,但计算速度更快,代码也更易于阅读。我们只需调用一次 np.exp(),就能对所有值进行指数化,然后立即用总和对它们进行归一化。为了进行分批训练,我们需要将此功能转换为分批接受层输出。具体操作如下:
# Get unnormalized probabilities
exp_values = np.exp(inputs)# Normalize them for each sample
probabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True)
我们有了一些新函数。具体来说,np.exp() 可以完成 E** 输出部分。我们还应该讨论一下上面提到的 axis 和 keepdims 的含义。我们先讨论一下轴线。坐标轴更容易显示,但在二维数组/矩阵中,坐标轴 0 指的是行,坐标轴 1 指的是列。让我们举例说明轴如何影响 NumPy 的求和。首先,我们只显示默认值,即无:
import numpy as nplayer_outputs = np.array([[4.8, 1.21, 2.385],[8.9, -1.81, 0.2],[1.41, 1.051, 0.026]])print('Sum without axis')
print(np.sum(layer_outputs))
print('This will be identical to the above since default is None:')
print(np.sum(layer_outputs, axis=None))
>>>
Sum without axis
18.172
This will be identical to the above since default is None:
18.172
如果没有指定轴(axis),我们只是将所有的值求和,即使它们在不同的维度中。接下来,axis=0。这意味着沿着轴0按行求和。换句话说,输出的大小与这个轴一样,因为在这个输出的每个位置,该位置的所有其他维度的值都被求和以形成它。在我们的2D数组中,我们只有一个其他维度,即列,输出向量将求和这些列。这意味着我们将执行4.8+8.9+1.41等操作:
import numpy as nplayer_outputs = np.array([[4.8, 1.21, 2.385],[8.9, -1.81, 0.2],[1.41, 1.051, 0.026]])print('Sum without axis')
print(np.sum(layer_outputs))
print('This will be identical to the above since default is None:')
print(np.sum(layer_outputs, axis=None))print('Another way to think of it w/ a matrix == axis 0: columns:')
print(np.sum(layer_outputs, axis=0))
>>>
Sum without axis
18.172
This will be identical to the above since default is None:
18.172Another way to think of it w/ a matrix == axis 0: columns:
[15.11 0.451 2.611]
但这并不是我们想要的。我们要的是各行的总和。你也许能猜到如何用 NumPy 实现这一功能,但我们还是要展示一下 “从零开始 ”的版本:
import numpy as nplayer_outputs = np.array([[4.8, 1.21, 2.385],[8.9, -1.81, 0.2],[1.41, 1.051, 0.026]])print('Sum without axis')
print(np.sum(layer_outputs))
print('This will be identical to the above since default is None:')
print(np.sum(layer_outputs, axis=None))print('Another way to think of it w/ a matrix == axis 0: columns:')
print(np.sum(layer_outputs, axis=0))print('But we want to sum the rows instead, like this w/ raw py:')
for i in layer_outputs:print(sum(i))
>>>
Sum without axis
18.172
This will be identical to the above since default is None:
18.172Another way to think of it w/ a matrix == axis 0: columns:
[15.11 0.451 2.611]But we want to sum the rows instead, like this w/ raw py:
8.395
7.29
2.4869999999999997
有了上述方法,我们就能以任何方式将这些数据追加到某个列表中。因此,我们将使用 NumPy。正如你可能猜到的,我们将沿着轴 1 求和:
import numpy as nplayer_outputs = np.array([[4.8, 1.21, 2.385],[8.9, -1.81, 0.2],[1.41, 1.051, 0.026]])print('Sum without axis')
print(np.sum(layer_outputs))
print('This will be identical to the above since default is None:')
print(np.sum(layer_outputs, axis=None))print('Another way to think of it w/ a matrix == axis 0: columns:')
print(np.sum(layer_outputs, axis=0))print('But we want to sum the rows instead, like this w/ raw py:')
for i in layer_outputs:print(sum(i))print('So we can sum axis 1, but note the current shape:')
print(np.sum(layer_outputs, axis=1))
>>>
Sum without axis
18.172
This will be identical to the above since default is None:
18.172Another way to think of it w/ a matrix == axis 0: columns:
[15.11 0.451 2.611]But we want to sum the rows instead, like this w/ raw py:
8.395
7.29
2.4869999999999997So we can sum axis 1, but note the current shape:
[8.395 7.29 2.487]
正如 “注意当前形状 ”所指出的,我们确实得到了预期的总和,但实际上,我们希望将输出简化为每个样本的单一值。我们正试图将一个层中每个样本的所有输出相加;将该层的输出数组(行长等于层中神经元的数量)转换为一个值。我们需要一个包含这些值的列向量,因为它可以让我们通过一次计算,对整批样本进行样本归一化处理:
import numpy as nplayer_outputs = np.array([[4.8, 1.21, 2.385],[8.9, -1.81, 0.2],[1.41, 1.051, 0.026]])print('Sum without axis')
print(np.sum(layer_outputs))
print('This will be identical to the above since default is None:')
print(np.sum(layer_outputs, axis=None))print('Another way to think of it w/ a matrix == axis 0: columns:')
print(np.sum(layer_outputs, axis=0))print('But we want to sum the rows instead, like this w/ raw py:')
for i in layer_outputs:print(sum(i))print('So we can sum axis 1, but note the current shape:')
print(np.sum(layer_outputs, axis=1))print('Sum axis 1, but keep the same dimensions as input:')
print(np.sum(layer_outputs, axis=1, keepdims=True))
>>>
Sum without axis
18.172
This will be identical to the above since default is None:
18.172Another way to think of it w/ a matrix == axis 0: columns:
[15.11 0.451 2.611]But we want to sum the rows instead, like this w/ raw py:
8.395
7.29
2.4869999999999997So we can sum axis 1, but note the current shape:
[8.395 7.29 2.487]Sum axis 1, but keep the same dimensions as input:
[[8.395][7.29 ][2.487]]
这样,我们就能保持与输入相同的维数。现在,如果我们将包含一批输出的数组与该数组相除,NumPy 将按抽样方式执行。这意味着,它会将每行输出的所有值除以总和数组中的相应行。由于每一行中的和都是单个值,因此它将用于与相应输出行中的每个值进行除法)。我们可以将所有这些合并到一个 softmax 类中,例如:
# Softmax activation
class Activation_Softmax:# Forward passdef forward(self, inputs):# Get unnormalized probabilitiesexp_values = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))# Normalize them for each sampleprobabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True)self.output = probabilities
最后,在进行指数运算之前,我们还对最大输入值进行了减法运算。神经网络普遍面临两大挑战: “死神经元 “和极大的数字(称为 ”爆炸 "值)。“死亡 "神经元和巨大的数字会造成严重破坏,使网络长期失去作用。softmax 激活中使用的指数函数就是爆炸值的来源之一。让我们举例说明这种情况如何以及为何容易发生:
import numpy as npprint(np.exp(1))
print(np.exp(10))
print(np.exp(100))
print(np.exp(1000))
>>>
2.718281828459045
22026.465794806718
2.6881171418161356e+43
inf
RuntimeWarning: overflow encountered in expprint(np.exp(1000))
在这种情况下,一个并不非常大的数字,仅仅是1000,就足以引起溢出错误。我们知道,随着输入值趋近于负无穷,指数函数趋向于0,而当输入为0时输出为1(如之前的图表所示):
import numpy as npprint(np.exp(-np.inf), np.exp(0))
>>>
0.0 1.0
我们可以利用这一性质来防止指数函数溢出。假设我们从一系列输入值中减去最大值。我们将会改变输出值,使其总是在从某个负数值到0的范围内,因为最大数减去它自身得到0,任何较小的数减去它将得到一个负数 — 正是上述讨论的范围。在Softmax中,由于归一化的原因,我们可以从所有输入中减去任何值,这不会改变输出结果:
import numpy as np# Softmax activation
class Activation_Softmax:# Forward passdef forward(self, inputs):# Get unnormalized probabilitiesexp_values = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))# Normalize them for each sampleprobabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True)self.output = probabilitiessoftmax = Activation_Softmax()
softmax.forward([[1, 2, 3]])
print(softmax.output)
>>>
[[0.09003057 0.24472847 0.66524096]]
import numpy as np# Softmax activation
class Activation_Softmax:# Forward passdef forward(self, inputs):# Get unnormalized probabilitiesexp_values = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))# Normalize them for each sampleprobabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True)self.output = probabilitiessoftmax = Activation_Softmax()
softmax.forward([[1, 2, 3]])
print(softmax.output)softmax.forward([[-2, -1, 0]]) # subtracted 3 - max from the list
print(softmax.output)
>>>
[[0.09003057 0.24472847 0.66524096]]
[[0.09003057 0.24472847 0.66524096]]
这是指数化和归一化函数的另一个有用特性。除了这些计算之外,还有一点需要提及。例如,如果我们将层的输出数据 [1, 2, 3] 除以2会发生什么?
import numpy as np# Softmax activation
class Activation_Softmax:# Forward passdef forward(self, inputs):# Get unnormalized probabilitiesexp_values = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))# Normalize them for each sampleprobabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True)self.output = probabilitiessoftmax = Activation_Softmax()
softmax.forward([[1, 2, 3]])
print(softmax.output)softmax.forward([[-2, -1, 0]]) # subtracted 3 - max from the list
print(softmax.output)softmax.forward([[0.5, 1, 1.5]])
print(softmax.output)
>>>
[[0.09003057 0.24472847 0.66524096]]
[[0.09003057 0.24472847 0.66524096]]
[[0.18632372 0.30719589 0.50648039]]
输出置信度由于指数化的非线性特性而发生了变化。这是一个例子,说明为什么我们需要以相同的方式缩放所有输入到神经网络的数据,我们将在第22章中进一步详细解释。
现在,我们可以添加另一个密集层作为输出层,设置它包含与前一层输出数量相同的输入和与我们数据包含的类别数量相同的输出。然后我们可以将softmax激活应用到这个新层的输出上:
import numpy as np
import nnfs
from nnfs.datasets import spiral_datannfs.init()##NN
class Layer_Dense:# Layer initializationdef __init__(self, n_inputs, n_neurons):# Initialize weights and biasesself.weights = 0.01 * np.random.randn(n_inputs, n_neurons)self.biases = np.zeros((1, n_neurons))# Forward passdef forward(self, inputs):# Calculate output values from inputs, weights and biasesself.output = np.dot(inputs, self.weights) + self.biases# ReLU activation
class Activation_ReLU:# Forward passdef forward(self, inputs):# Calculate output values from inputself.output = np.maximum(0, inputs)# Softmax activation
class Activation_Softmax:# Forward passdef forward(self, inputs):# Get unnormalized probabilitiesexp_values = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))# Normalize them for each sampleprobabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True)self.output = probabilities# Create dataset
X, y = spiral_data(samples=100, classes=3)# Create Dense layer with 2 input features and 3 output values
dense1 = Layer_Dense(2, 3)# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()# Create second Dense layer with 3 input features (as we take output
# of previous layer here) and 3 output values
dense2 = Layer_Dense(3, 3)# Create Softmax activation (to be used with Dense layer):
activation2 = Activation_Softmax()# Make a forward pass of our training data through this layer
dense1.forward(X)# Make a forward pass through activation function
# it takes the output of first dense layer here
activation1.forward(dense1.output)# Make a forward pass through second Dense layer
# it takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)# Make a forward pass through activation function
# it takes the output of second dense layer here
activation2.forward(dense2.output)# Let's see output of the first few samples:
print(activation2.output[:5])
>>>
[[0.33333334 0.33333334 0.33333334][0.3333332 0.3333332 0.33333364][0.3333329 0.33333293 0.3333342 ][0.3333326 0.33333263 0.33333477][0.33333233 0.3333324 0.33333528]]
正如你所看到的,预测的分布几乎是相等的,因为每个样本对每个类的预测大约是33%(0.33)。这是由于权重的随机初始化(来自正态分布的抽取,不是每次随机初始化都会得到这个结果)和偏置归零造成的。这些输出也是我们的“置信度得分”。为了确定模型选择的预测分类,我们对这些输出执行 argmax 操作,它检查输出分布中哪个类别的置信度最高,并返回其索引 - 预测的类别索引。也就是说,置信度得分可以和类别预测本身一样重要。例如,[0.22, 0.6, 0.18] 的 argmax 与 [0.32, 0.36, 0.32] 的 argmax 相同。在这两种情况下,argmax 函数都会返回索引值 1(在Python的从零开始的索引系统中是第二个元素),但显然,60%的置信度比36%的置信度要好得多。
import numpy as npa = [0.22, 0.6, 0.18]
b = [0.32, 0.36, 0.32]print(np.argmax(a))
print(np.argmax(b))
>>>
1
1
我们已经完成了通过我们的模型进行前向传递数据所需的步骤。我们在隐藏层使用了整流线性(ReLU)激活函数,它是基于每个神经元工作的。我们还在输出层使用了Softmax激活函数,因为它接受非标准化的值作为输入,并输出概率分布,我们将其用作每个类别的置信度得分。回想一下,尽管神经元是相互连接的,它们各自拥有各自的权重和偏置,并且彼此之间不是“标准化”的。
正如你所见,我们的示例模型目前是随机的。为了解决这个问题,我们需要一种方法来计算神经网络在当前预测中的错误程度,并开始调整权重和偏置以随时间减少错误。因此,我们的下一步是通过所定义的损失函数来量化模型的错误程度。
代码的可视化:https://nnfs.io/ch4
相关文章:
用 Python 从零开始创建神经网络(四):激活函数(Activation Functions)
激活函数(Activation Functions) 引言1. 激活函数的种类a. 阶跃激活功能b. 线性激活函数c. Sigmoid激活函数d. ReLU 激活函数e. more 2. 为什么使用激活函数3. 隐藏层的线性激活4. 一对神经元的 ReLU 激活5. 在隐蔽层中激活 ReLU6. ReLU 激活函数代码7. …...
使用 Flask 和 ONLYOFFICE 实现文档在线编辑功能
提示:CSDN 博主测评ONLYOFFICE 文章目录 引言技术栈环境准备安装 ONLYOFFICE 文档服务器获取 API 密钥安装 Flask 和 Requests 创建 Flask 应用项目结构编写 app.py创建模板 templates/index.html 运行应用功能详解文档上传生成编辑器 URL显示编辑器回调处理 安全性…...

【C++】【算法基础】序列编辑距离
编辑距离 题目 给定 n n n个长度不超过 10 10 10 的字符串以及 m m m 次询问,每次询问给出一个字符串和一个操作次数上限。 对于每次询问,请你求出给定的 n n n个字符串中有多少个字符串可以在上限操作次数内经过操作变成询问给出的字符串。 每个…...
【Android】轮播图——Banner
引言 Banner轮播图是一种在网页和移动应用界面设计中常见的元素,主要用于在一个固定的区域内自动或手动切换一系列图片,以展示不同的内容或信息。这个控件在软件当中经常看到,商品促销、热门歌单、头像新闻等等。它不同于ViewPgaer在于无需手…...
学SQL,要安装什么软件?
先上结论,推荐MySQLDbeaver的组合。 学SQL需要安装软件吗? 记得几年前我学习SQL的时候,以为像Java、Python一样需要安装SQL软件包,后来知道并没有所谓SQL软件,因为SQL是一种查询语言,它用来对数据库进行操…...

webstorm 设置总结
编辑器-》文件类型-》忽略的文件和文件夹-》加上node_modules 修改WebStorm 内存有两种方式。 1. 点击菜单中的Help -> change memory settings 弹出设置内存窗口,修改最大内存大小。然后点击Save and Restart 即可。 2. 点击菜单中的Help -> Edit Custom V…...
基于Spring Boot的养老保险管理系统的设计与实现,LW+源码+讲解
摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统养老保险管理系统信息管理难度大,容错率低&a…...

Java | Leetcode Java题解之第541题反转字符串II
题目: 题解: class Solution {public String reverseStr(String s, int k) {int n s.length();char[] arr s.toCharArray();for (int i 0; i < n; i 2 * k) {reverse(arr, i, Math.min(i k, n) - 1);}return new String(arr);}public void reve…...

sql分区
将学员表student按所在城市使用PARTITION BY LIST 1、创建分区表。 CREATE TABLE public.student( sno numeric(4,0), sname character varying(20 char),gender character varying(2 char), phone numeric(11,0), …...

[OpenGL]使用OpenGL实现硬阴影效果
一、简介 本文介绍了如何使用OpenGL实现硬阴影效果,并在最后给出了全部的代码。本文基于[OpenGL]渲染Shadow Map,实现硬阴影的流程如下: 首先,以光源为视角,渲染场景的深度图,将light space中的深度图存储…...
嵌入式采集网关(golang版本)
为了一次编写到处运行,使用纯GO编写,排除CGO,解决在嵌入式中交叉编译难问题 硬件设备:移远EC200A-CN LTE Cat 4 无线通信模块,搭载openwrt操作系统,90M内存...
ctfshow(328)--XSS漏洞--存储型XSS
Web328 简单阅读一下页面。 是一个登录系统,存在一个用户管理数据库。 那么我们注册一个账号,在账号或者密码中植入HTML恶意代码,当管理员访问用户管理数据库页面时,就会触发我们的恶意代码。 思路 我们向数据库中写入盗取管理员…...

【C#】Thread.CurrentThread的用法
Thread.CurrentThread 是 System.Threading.Thread 类的一个静态属性,它返回当前正在执行的线程对象。通过 Thread.CurrentThread,可以访问和修改当前线程的各种属性和方法。 下面是一些常见的用法和示例: 1. 获取当前线程的信息 使用 Thr…...
简单分享一下淘宝商品数据自动化抓取的技术实现与挑战
在电子商务领域,数据是驱动决策的关键。淘宝作为国内最大的电商平台之一,其商品数据对电商从业者来说具有极高的价值。然而,从淘宝平台自动化抓取商品数据并非易事,涉及多重技术和法律挑战。本文将从技术层面分析实现淘宝商品数据…...
Netty篇(入门编程)
目录 一、Hello World 1. 目标 2. 服务器端 3. 客户端 4. 流程梳理 💡 提示 5. 运行结果截图 二、Netty执行流程 1. 流程分析 2. 代码案例 2.1. 引入依赖 2.2. 服务端 服务端 服务端处理器 2.3. 客户端 客户端 客户端处理器 2.4. 代码截图 一、Hel…...

【渗透测试】payload记录
Java开发使用char[]代替String保存敏感数据 Java Jvm会提供内存转储功能,当Java程序dump后,会生成堆内存的快照,保存在.hprof后缀的文件中,进而导致敏感信息的泄露。char[]可以在存储敏感数据后手动清零,String对象会…...

2024自动驾驶线控底盘行业研究报告
自动驾驶线控底盘是实现自动驾驶的关键技术之一,它通过电子信号来控制车辆的行驶,包括转向、制动、驱动、换挡和悬架等系统。线控底盘技术的发展对于自动驾驶汽车的实现至关重要,因为它提供了快速响应和精确控制的能力,这是自动驾驶系统所必需的。 线控底盘由五大系统组成…...

css3D变换用法
文章目录 CSS3D变换详解及代码案例一、CSS3D变换的基本概念二、3D变换的开启与景深设置三、代码案例 CSS3D变换详解及代码案例 CSS3D变换是CSS3中引入的一种强大功能,它允许开发者在网页上创建三维空间中的动画和交互效果。通过CSS3D变换,你可以实现元素…...

Rust:启动与关闭线程
在 Rust 编程中,启动和关闭线程是并发编程的重要部分。Rust 提供了强大的线程支持,允许你轻松地创建和管理线程。下面将详细解释如何在 Rust 中启动和关闭线程。 启动线程 在 Rust 中,你可以使用标准库中的 std::thread 模块来创建和启动新…...

Ubuntu 的 ROS 2 操作系统安装与测试
引言 机器人操作系统(ROS, Robot Operating System)是一种广泛应用于机器人开发的开源框架,提供了丰富的库和工具,支持开发者快速构建、控制机器人并实现智能功能。 当前,ROS 2 的最新长期支持版本为 Humble Hawksbil…...

[4G5G专题] RRU CFR技术:从“削峰”到“塑形”的算法演进与工程实践
1. 从“削峰”到“塑形”:CFR技术的本质蜕变 第一次接触CFR(Crest Factor Reduction)技术时,我把它简单理解为“信号削峰器”——就像用菜刀切掉蛋糕顶端多余的部分。早期在4G RRU(Remote Radio Unit)项目中…...

回流平台深耕闲置翡翠流通,以数字化服务激活珠宝产业新动能
据中国珠宝玉石首饰行业协会数据,我国珠宝玉石首饰产业市场规模持续扩大,翡翠玉石作为第二大珠宝消费品类,市场存量可观。与此同时,发达国家二手高端消费品交易占整个高端消费品市场的20%至30%,我国目前占比约5%&#…...

基于Taotoken构建每日大赛自动评分与反馈Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken构建每日大赛自动评分与反馈Agent工作流 对于编程大赛、算法竞赛或日常训练的组织者与教练而言,每日处理大…...

基于LangChain与本地LLM构建私有化知识库问答系统实践
1. 项目概述:从零构建一个垂直领域的知识库与问答系统最近在整理个人技术资料时,我遇到了一个非常典型的问题:手头积累了大量来自不同渠道的电子书、技术文档、知乎专栏文章以及各种开源项目的README,内容虽然优质,但过…...

NLP知识图谱构建实战:从文本到结构化知识的完整流程
1. 项目概述:当NLP遇上知识图谱如果你在NLP(自然语言处理)领域摸爬滚打了一段时间,或者对知识图谱(Knowledge Graph)这个听起来就很有“智慧感”的东西感兴趣,那么你大概率在GitHub上见过或搜索…...

从赛博朋克到量子有机体,未来主义风格演进全图谱,深度解析MJ 5.2→6.2→NijiV6的渲染范式跃迁
更多请点击: https://intelliparadigm.com 第一章:赛博朋克到量子有机体:未来主义视觉范式的哲学跃迁 当霓虹雨巷中的义体少女凝视全息广告牌,她瞳孔倒映的已不仅是资本编码的欲望图景,而是意识与拓扑量子态耦合的初始…...

如何用BilibiliDown轻松下载B站视频:3分钟掌握完整操作指南
如何用BilibiliDown轻松下载B站视频:3分钟掌握完整操作指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

COMET终极指南:5个实用技巧掌握神经机器翻译质量评估框架 [特殊字符]
COMET终极指南:5个实用技巧掌握神经机器翻译质量评估框架 🚀 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET COMET(A Neural Framework for MT Evaluation&#…...

告别轮询!用libhv的WebSocketClient类5分钟搞定C++实时通信客户端
告别轮询!用libhv的WebSocketClient类5分钟搞定C实时通信客户端 在物联网设备监控、多人在线游戏或金融行情推送等场景中,开发者常面临一个经典难题:如何实现毫秒级延迟的实时数据同步?传统HTTP轮询方案不仅浪费带宽,还…...

如何快速掌握Spinning Up超参数调优:提升深度强化学习性能的终极指南
如何快速掌握Spinning Up超参数调优:提升深度强化学习性能的终极指南 【免费下载链接】spinningup An educational resource to help anyone learn deep reinforcement learning. 项目地址: https://gitcode.com/gh_mirrors/sp/spinningup Spinning Up是一款…...