做 SQL 性能优化真是让人干瞪眼
很多大数据计算都是用SQL实现的,跑得慢时就要去优化SQL,但常常碰到让人干瞪眼的情况。
比如,存储过程中有三条大概形如这样的语句执行得很慢:
select a,b,sum(x) from T group by a,b where …; select c,d,max(y) from T group by c,d where …; select a,c,avg(y),min(z) from T group by a,c where …;
这里的T是个有数亿行的巨大表,要分别按三种方式分组,分组的结果集都不大。
分组运算要遍历数据表,这三句SQL就要把这个大表遍历三次,对数亿行数据遍历一次的时间就不短,何况三遍。
这种分组运算中,相对于遍历硬盘的时间,CPU计算时间几乎可以忽略。如果可以在一次遍历中把多种分组汇总都计算出来,虽然CPU计算量并没有变少,但能大幅减少硬盘读取数据量,就能成倍提速了。
如果SQL支持类似这样的语法:
from T --数据来自T表 select a,b,sum(x) group by a,b where … --遍历中的第一种分组 select c,d,max(y) group by c,d where … --遍历中的第二种分组 select a,c,avg(y),min(z) group by a,c where …; --遍历中的第三种分组
能一次返回多个结果集,那就可以大幅提高性能了。
可惜, SQL没有这种语法,写不出这样的语句,只能用个变通的办法,就是用group a,b,c,d的写法先算出更细致的分组结果集,但要先存成一个临时表,才能进一步用SQL计算出目标结果。SQL大致如下:
create table T\_temp as select a,b,c,d, sum(case when … then x else 0 end) sumx, max(case when … then y else null end) maxy, sum(case when … then y else 0 end) sumy, count(case when … then 1 else null end) county, min(case when … then z else null end) minz group by a,b,c,d;select a,b,sum(sumx) from T\_temp group by a,b where …; select c,d,max(maxy) from T\_temp group by c,d where …; select a,c,sum(sumy)/sum(county),min(minz) from T\_temp group by a,c where …;
这样只要遍历一次了,但要把不同的WHERE条件转到前面的case when里,代码复杂很多,也会加大计算量。而且,计算临时表时分组字段的个数变得很多,结果集就有可能很大,最后还对这个临时表做多次遍历,计算性能也快不了。大结果集分组计算还要硬盘缓存,本身性能也很差。
还可以用存储过程的数据库游标把数据一条一条fetch出来计算,但这要全自己实现一遍WHERE和GROUP的动作了,写起来太繁琐不说,数据库游标遍历数据的性能只会更差!
只能干瞪眼!
TopN运算同样会遇到这种无奈。举个例子,用Oracle的SQL写top5大致是这样的:
select \* from (select x from T order by x desc) where rownum<=5
表T有10亿条数据,从SQL语句来看,是将全部数据大排序后取出前5名,剩下的排序结果就没用了!大排序成本很高,数据量很大内存装不下,会出现多次硬盘数据倒换,计算性能会非常差!
避免大排序并不难,在内存中保持一个5条记录的小集合,遍历数据时,将已经计算过的数据前5名保存在这个小集合中,取到的新数据如果比当前的第5名大,则插入进去并丢掉现在的第5名,如果比当前的第5名要小,则不做动作。这样做,只要对10亿条数据遍历一次即可,而且内存占用很小,运算性能会大幅提升。
这种算法本质上是把TopN也看作与求和、计数一样的聚合运算了,只不过返回的是集合而不是单值。SQL要是能写成这样,就能避免大排序了:
select top(x,5) from T
然而非常遗憾,SQL没有显式的集合数据类型,聚合函数只能返回单值,写不出这种语句!
不过好在全集的TopN比较简单,虽然SQL写成那样,数据库却通常会在工程上做优化,采用上述方法而避免大排序。所以Oracle算那条SQL并不慢。
但是,如果TopN的情况复杂了,用到子查询中或者和JOIN混到一起的时候,优化引擎通常就不管用了。比如要在分组后计算每组的TopN,用SQL写出来都有点困难。Oracle的SQL写出来是这样:
select \* from (select y,x,row\_number() over (partition by y order by x desc) rn from T) where rn<=5
这时候,数据库的优化引擎就晕了,不会再采用上面说的把TopN理解成聚合运算的办法。只能去做排序了,结果运算速度陡降!
假如SQL的分组TopN能这样写:
select y,top(x,5) from T group by y
把top看成和sum一样的聚合函数,这不仅更易读,而且也很容易高速运算。
可惜,不行。
还是干瞪眼!
关联计算也是很常见的情况。以订单和多个表关联后做过滤计算为例,SQL大体是这个样子:
select o.oid,o.orderdate,o.amount
from orders o left join city ci on o.cityid = ci.cityid left join shipper sh on o.shid=sh.shid left join employee e on o.eid=e.eid left join supplier su on o.suid=su.suid
where ci.state='New York' and e.title='manager' and ...
订单表有几千万数据,城市、运货商、雇员、供应商等表数据量都不大。过滤条件字段可能会来自于这些表,而且是前端传参数到后台的,会动态变化。
SQL一般采用HASH JOIN算法实现这些关联,要计算 HASH 值并做比较。每次只能解析一个JOIN,有N个JOIN要执行N遍动作,每次关联后都需要保持中间结果供下一轮使用,计算过程复杂,数据也会被遍历多次,计算性能不好。
通常,这些关联的代码表都很小,可以先读入内存。如果将订单表中的各个关联字段预先做序号化处理,比如将雇员编号字段值转换为对应雇员表记录的序号。那么计算时,就可以用雇员编号字段值(也就是雇员表序号),直接取内存中雇员表对应位置的记录,性能比HASH JOIN快很多,而且只需将订单表遍历一次即可,速度提升会非常明显!
也就是能把SQL写成下面的样子:
select o.oid,o.orderdate,o.amount
from orders o left join city c on o.cid = c.# --订单表的城市编号通过序号#关联城市表 left join shipper sh on o.shid=sh.# --订单表运货商号通过序号#关联运货商表 left join employee e on o.eid=e.# --订单表的雇员编号通过序号#关联雇员表 left join supplier su on o.suid=su.#--订单表供应商号通过序号#关联供应商表
where ci.state='New York' and e.title='manager' and ...
可惜的是,SQL 使用了无序集合概念,即使这些编号已经序号化了,数据库也无法利用这个特点,不能在对应的关联表这些无序集合上使用序号快速定位的机制,只能使用索引查找,而且数据库并不知道编号被序号化了,仍然会去计算 HASH 值和比对,性能还是很差!
有好办法也实施不了,只能再次干瞪眼!
还有高并发帐户查询,这个运算倒是很简单:
select id,amt,tdate,… from T
where id='10100' and tdate>= to\_date('2021-01-10','yyyy-MM-dd') and tdate<to_date('2021-01-25','yyyy-mm-dd') and="" …="" <p="">
在T表的几亿条历史数据中,快速找到某个帐户的几条到几千条明细,SQL写出来并不复杂,难点是大并发时响应速度要达到秒级甚至更快。为了提高查询响应速度,一般都会对 T 表的 id 字段建索引:
create index index_T_1 on T(id)
在数据库中,用索引查找单个帐户的速度很快,但并发很多时就会明显变慢。原因还是上面提到的SQL无序理论基础,总数据量很大,无法全读入内存,而数据库不能保证同一帐户的数据在物理上是连续存放的。硬盘有最小读取单位,在读不连续数据时,会取出很多无关内容,查询就会变慢。高并发访问的每个查询都慢一点,总体性能就会很差了。在非常重视体验的当下,谁敢让用户等待十秒以上?!
容易想到的办法是,把几亿数据预先按照帐户排序,保证同一帐户的数据连续存储,查询时从硬盘上读出的数据块几乎都是目标值,性能就会得到大幅提升。
但是,采用SQL体系的关系数据库并没有这个意识,不会强制保证数据存储的物理次序!这个问题不是SQL语法造成的,但也和SQL的理论基础相关,在关系数据库中还是没法实现这些算法。
那咋办?只能干瞪眼吗?
不能再用SQL和关系数据库了,要使用别的计算引擎。
开源的集算器SPL基于创新的理论基础,支持更多的数据类型和运算,能够描述上述场景中的新算法。用简单便捷的SPL写代码,在短时间内能大幅提高计算性能!
上面这些问题用SPL写出来的代码样例如下:
- 一次遍历计算多种分组
| A | B | |
|---|---|---|
| 1 | =file(“T.ctx”).open().cursor(a,b,c,d,x,y,z | |
| 2 | cursor A1 | =A2.select(…).groups(a,b;sum(x)) |
| 3 | //定义遍历中的第一种过滤、分组 | |
| 4 | cursor | =A4.select(…).groups(c,d;max(y)) |
| 5 | //定义遍历中的第二种过滤、分组 | |
| 6 | cursor | =A6.select(…).groupx(a,c;avg(y),min(z)) |
| 7 | //定义遍历中的第三种过滤、分组 | |
| 8 | … | //定义结束,开始计算三种方式的过滤、分组 |
- 用聚合的方式计算Top5
全集Top5(多线程并行计算)
| A | |
|---|---|
| 1 | =file(“T.ctx”).open() |
| 2 | =A1.cursor@m(x).total(top(-5,x),top(5,x)) |
| 3 | //top(-5,x) 计算出 x 最大的前 5 名,top(5,x) 是 x 最小的前 5 名。 |
分组Top5(多线程并行计算)
| A | |
|---|---|
| 1 | =file(“T.ctx”).open() |
| 2 | =A1.cursor@m(x,y).groups(y;top(-5,x),top(5,x)) |
- 用序号做关联的SPL代码:
系统初始化
| A | |
|---|---|
| 1 | >env(city,file(“city.btx”).import@b()),env(employee,file(“employee.btx”).import@b()),… |
| 2 | //系统初始化时,几个小表读入内存 |
查询
| A | |
|---|---|
| 1 | =file(“orders.ctx”).open().cursor(cid,eid,…).switch(cid,city:#;eid,employee:#;…) |
| 2 | =A1.select(cid.state==“New York” && eid.title==“manager”…) |
| 3 | //先序号关联,再引用关联表字段写过滤条件 |
- 高并发帐户查询的SPL代码:
数据预处理,有序存储
| A | B | |
|---|---|---|
| 1 | =file(“T-original.ctx”).open().cursor(id,tdate,amt,…) | |
| 2 | =A1.sortx(id) | =file(“T.ctx”) |
| 3 | =B2.create@r(#id,tdate,amt,…).append@i(A2) | |
| 4 | =B2.open().index(index_id;id) | |
| 5 | //将原数据排序后,另存为新表,并为帐号建立索引 |
帐户查询
| A | |
|---|---|
| 1 | =T.icursor(;id==10100 && tdate>=date(“2021-01-10”) && tdate<date(“2021-01-25”) && …,index_id).fetch() |
| 2 | //查询代码非常简单 |
除了这些简单例子,SPL还能实现更多高性能算法,比如有序归并实现订单和明细之间的关联、预关联技术实现多维分析中的多层维表关联、位存储技术实现上千个标签统计、布尔集合技术实现多个枚举值过滤条件的查询提速、时序分组技术实现复杂的漏斗分析等等。
正在为SQL性能优化头疼的小伙伴们,可以和我们一起探讨:
http://www.raqsoft.com.cn/wx/Query-run-batch-ad.html
SPL资料
- SPL官网
- SPL下载
- SPL源代码
相关文章:

做 SQL 性能优化真是让人干瞪眼
很多大数据计算都是用SQL实现的,跑得慢时就要去优化SQL,但常常碰到让人干瞪眼的情况。 比如,存储过程中有三条大概形如这样的语句执行得很慢: select a,b,sum(x) from T group by a,b where …; select c,d,max(y) from T grou…...

SpringBoot(3)之包结构
根据spring可知道,注解之所以可以使用,是因为通过包扫描器,扫描包,然后才能通过注解开发。 那么springboot需要扫描哪里呢? springboot的默认包扫描器,扫描的是自己所在的包和子包,例子如下 我…...

test2
物理层故障分析 一、传输介质故障 a.主要用途简述 传输介质主要分为 导向传输介质和非导向传输介质。前者包括双绞线(两根铜线并排绞合,距离过远会失真)、同轴电缆(铜质芯线屏蔽层,抗干扰性强,传输距离更…...

LoadRunner安装教程
备注:电脑最好安装有IE浏览器或者360极速版浏览器 一、下载安装包 提前下载安装文件,必须下载。 链接: https://pan.baidu.com/s/1blFiMIJcoE8s3uVhAxdzdA?pwdqhpt 提取码: qhpt 包含的文件有: 二、安装loadrunner 注意,以…...
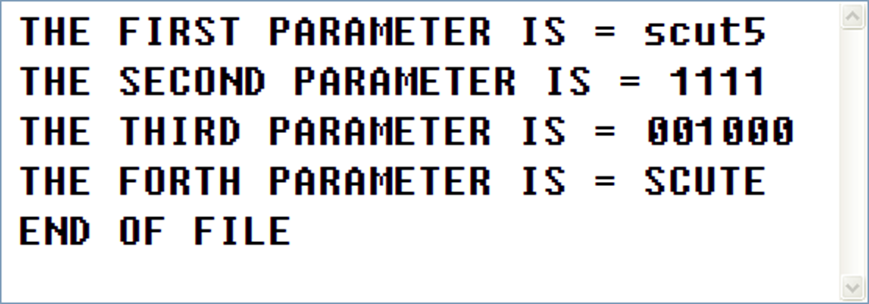
VHDL语言基础-Testbech
目录 VHDL仿真概述: 基本结构: VHDL一般仿真过程: 仿真测试平台文件: 编写测试平台文件的语言: 一个测试平台文件的基本结构如下: 测试平台文件包含的基本语句: 产生激励信号的方式: 时钟信号: 复位信号: 周期信性信号: 使用延迟DELAYD: 一般的激励信号…...
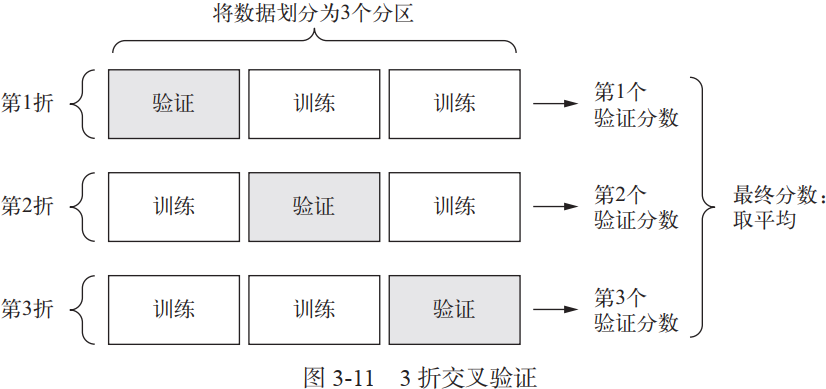
机器学习基础总结
一,机器学习系统分类 机器学习系统分为三个类别,如下图所示: 二,如何处理数据中的缺失值 可以分为以下 2 种情况: 缺失值较多:直接舍弃该列特征,否则可能会带来较大噪声,从而对结果造成不良影…...
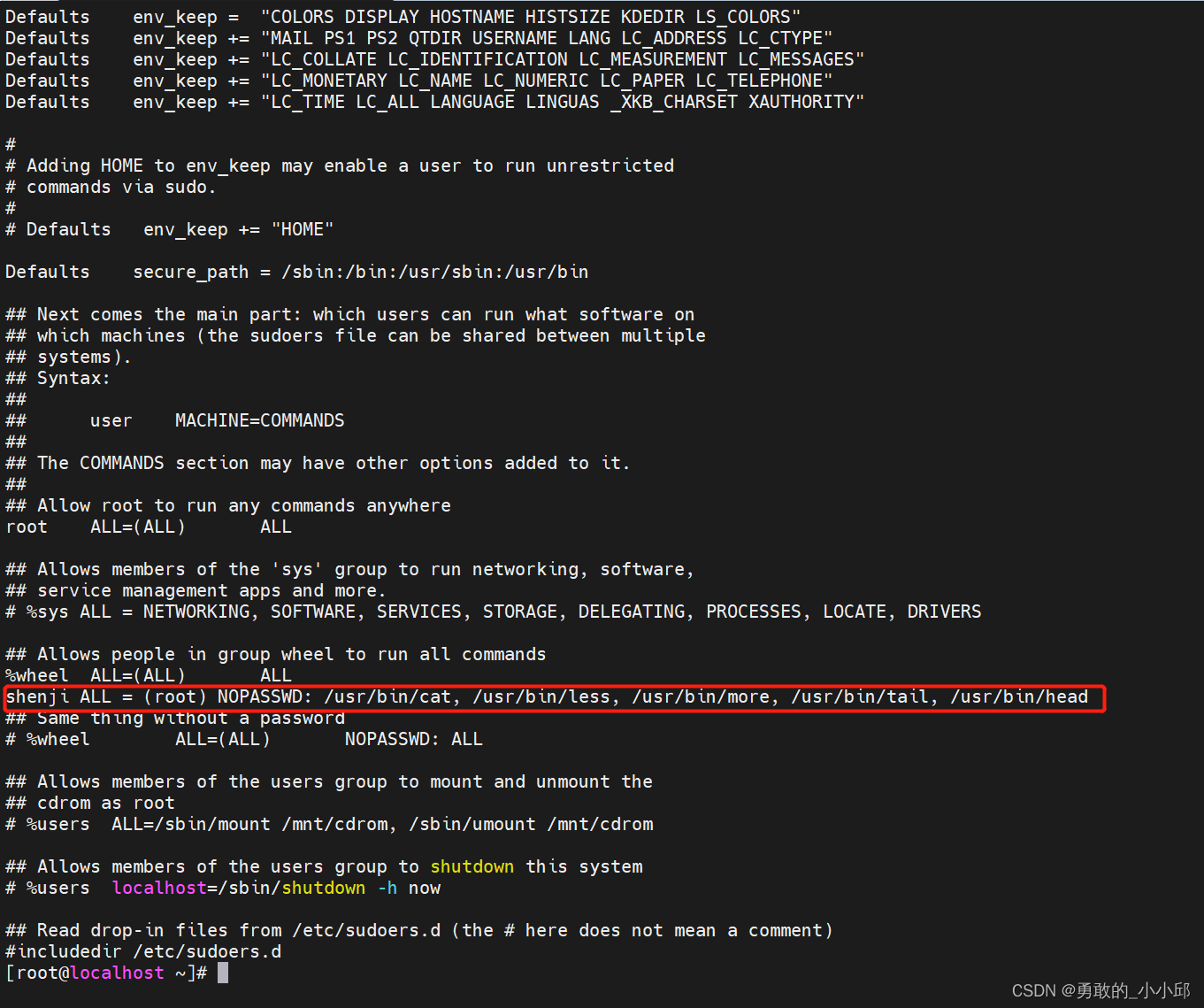
linux的三权分立设计思路和用户创建(安全管理员、系统管理员和审计管理员)
目录 一、三权分立设计思路 1、什么是三权 2、三员及权限的理解 3、三员之三权 4、权限划分 5、“三员”职责 6、“三员”配置要求 二、linux三权分立的用户创建 1、系统管理员 2、安全管理员 3、审计管理员 一、三权分立设计思路 1、什么是三权 三权指的是配置、…...

revit中如何创建有坡度的排水沟及基坑?
一、revit中如何创建有坡度的排水沟? 先分享一张有坡度排水沟的族的照片给大家加深一下印象,有了一个粗略的直观认识,小编就来说说做这个族的前期思路吧。 一、前期思路: 1、 用拼接的方式把这个族形状拼出来,先用放样࿰…...

Web自动化测试——selenium篇(一)
文章目录一、环境准备二、Web 自动化测试 Demo三、元素定位常用方法四、元素定位失败可能原因五、测试对象操作六、等待操作七、信息打印在学习 Web 自动化测试的过程中,selenium 是其中的常用工具。除了其开源免费,包含丰富的 API 以外,它还…...

认识 CSS pointer-events 属性
pointer-events 的基本信息 pointer-events 属性用来控制一个元素能否响应鼠标操作,常用的关键字有 auto 和 none pointer-events: none; // 让一个元素忽略鼠标操作 pointer-events: auto; // 还原浏览器设定的默认行为 规范定义 条目状态初始值auto可用值适用所…...

【java】springboot和springcloud区别
文章目录1、含义不同2、作用不同3、使用方式不同4、特征不同5、注释不同6、优势不同7、组件不同8、设计目的不同1、含义不同 springboot:一个快速开发框架,它简化了传统MVC的XML配置,使配置变得更加方便、简洁。 springcloud:是…...
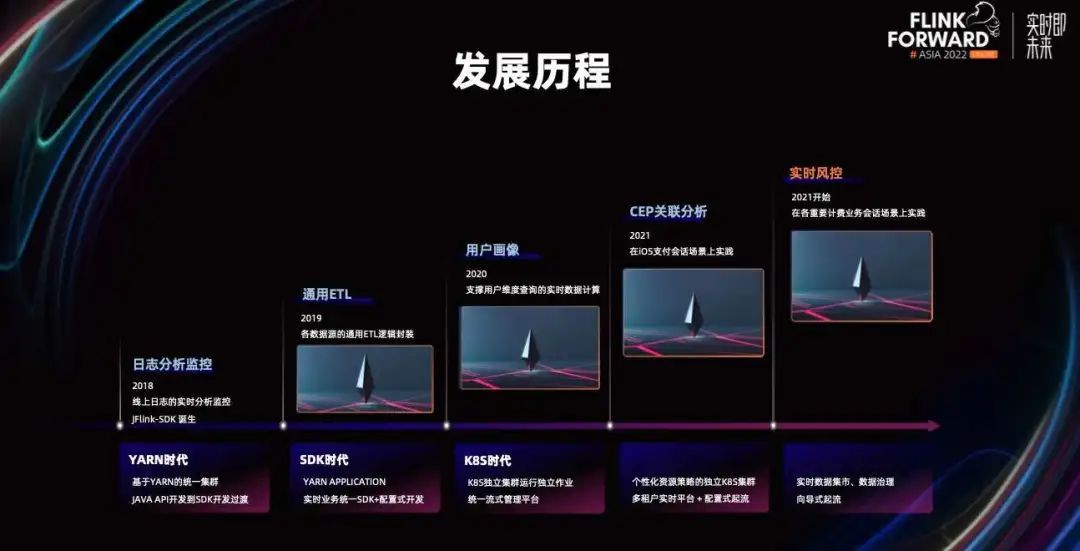
网易游戏实时 HTAP 计费风控平台建设
本文整理自网易互娱资深工程师, Flink Contributor, CDC Contributor 林佳,在 FFA 实时风控专场的分享。本篇内容主要分为五个部分: 实时风控业务会话会话关联的 Flink 实现HTAP 风控平台建设提升风控结果数据能效发展历程与展望未来 众所周知ÿ…...
vue组件
文章目录1.vue组件2.非单文件组件2.1组件创建2.2祖册组件2.3使用组件3.组件的嵌套3.1 school组件嵌套student3.2 app组件嵌套school和hellozujain3.3 vm里面引入app组件4.VueCompent5.单文件组件1.vue组件 组件是实现应用中功能的局部代码和资源的集合 2.非单文件组件 2.1组件…...

让mybatis-plus支持null字段全量更新
文章目录背景方案一使用方案二方案二原理介绍背景 如果仅仅只是标题所列的目标,那么mybatis-plus 中可以通过设置 mybatis-plus.global-config.db-config.field-strategyignored 来忽略null判断,达到实体字段为null时也可以更新数据为null 但是一旦使用…...

MASA Stack 1.0 发布会讲稿——生态篇
2022年运营回顾 贡献者 首先感谢贡献者们为MASA Stack社区所作的积极贡献,这些贡献者给我们提出了很多宝贵的建议,更是积极的提交PR帮助我们一起让产品更健壮,更完善,还在各种场合推广我们的解决方案,非常给力&#x…...
| 真题+思路++考点+代码)
华为OD机试 - 火星文计算2(JS)| 真题+思路++考点+代码
火星文计算2 题目 已知火星人使用的运算符号为#;$ 其与地球人的等价公式如下 x#y4*x3*y2 x$y2*xy3 x y是无符号整数 地球人公式按照c语言规则进行计算 火星人公式中#符优先级高于$ 相同的运算符按从左到右的顺序运算 输入 火星人字符串表达式结尾不带回车换行 输入的字符串…...
从春节后央行的首批罚单,看金融反欺诈反洗钱的复杂性
目录 个人信息保护的问题 征信管理的问题 反洗钱与反欺诈的问题 金融欺诈愈加复杂多变 金融机构如何增强反欺诈反洗钱 春节后,央行公示首批罚单。其中,厦门银行被中国人民银行福州中心支行给予警告,并没收违法所得767.17元,处…...
【Hello Linux】Linux工具介绍 (yum vim)
作者:小萌新 专栏:Linux 作者简介:大二学生 希望能和大家一起进步! 本篇博客简介:介绍Linux的常用工具 yum和vim Linux工具介绍Linux中的软件管理工具 -- yum在windows下安装软件的方式在Linux下安装软件的方式认识yum…...

多种充电模式_手持无线充气泵方案
一、手持无线充气泵手持无线充气泵是一个通过锂电池供电达到无需插电就能使用的便携式充气泵,它的适用场景大部分是为身处户外没有办法接通电源的人而设计的,方便人们的出行也可解燃眉之急。不仅如此,为预防手持无线充气泵的锂电池电量用完而…...
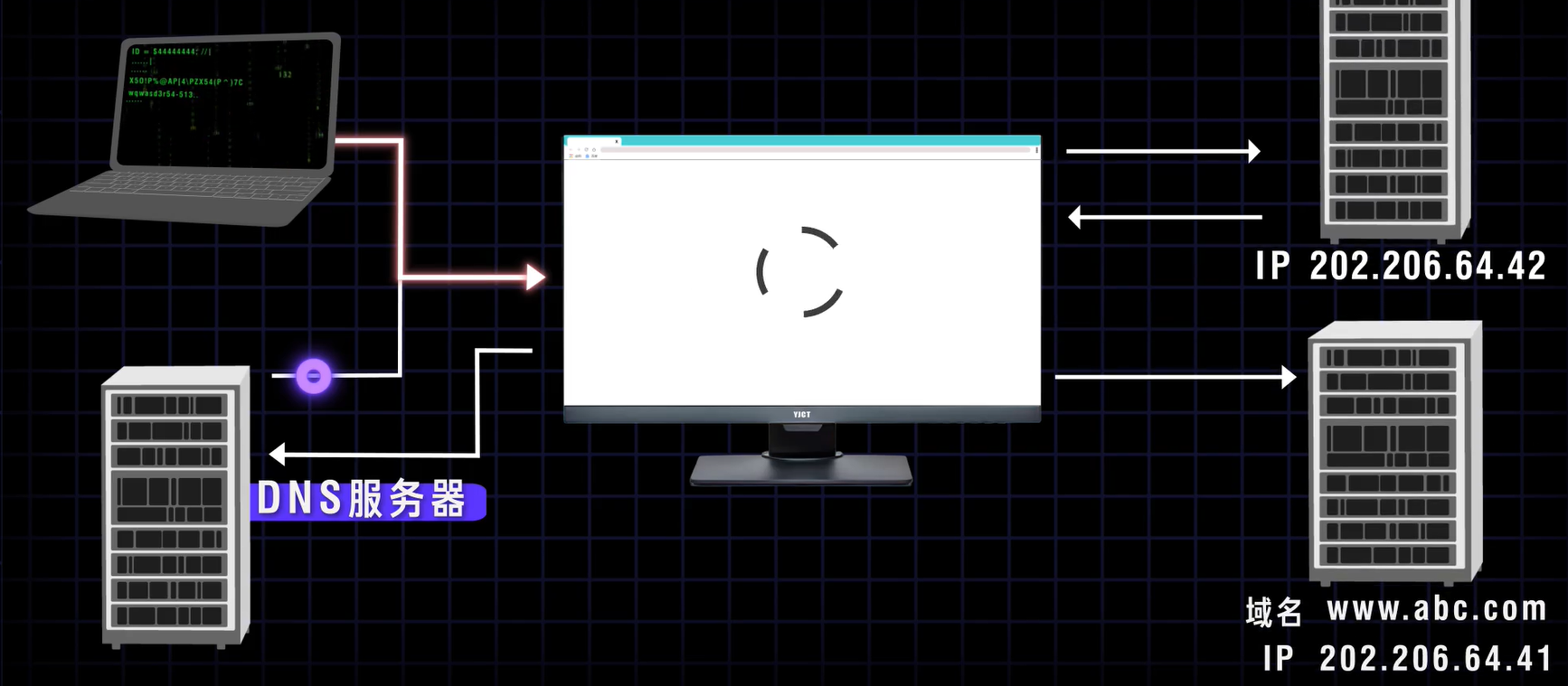
【网络基础】DNS是什么
本文不会直接引入复杂枯燥概念,用形象例子通俗讲解,旨在入门理解。 DNS作用 DNS是用来做域名解析的。 相当于把网址翻译成实际ip地址,供其他设备访问。 一个例子 有一个网站的服务器IP地址为1.1.1.1,用电脑访问该网站的话只需…...

2026年图片换背景免费工具完全指南:一键抠图软件推荐
现在是5月,我想很多人都在为各种证件照、商品图、头像等需要换背景的图片犯愁。前两天有朋友问我"哪个软件可以给图片换背景",我才意识到很多人还在用古老的PS或者繁琐的在线工具。今天就来给大家分享一下2026年最好用的图片换背景工具&#x…...

游戏开发资源宝库:从计算机图形学到Unity生态的全栈知识索引
1. 项目概述:一份游戏开发者的“藏宝图”如果你是一名游戏开发者,无论是刚入行的新人,还是摸爬滚打多年的老兵,大概都经历过这样的时刻:为了实现一个特定的效果,或是解决一个棘手的技术难题,在搜…...

半导体产业3000亿美元背后的冷思考:成本高墙、利润悖论与创新挑战
1. 行业现状:跨越3000亿美元门槛后的冷思考 又到了一年一度回顾过去、展望未来的时刻。对于我们这些在半导体行业摸爬滚打了十几年甚至几十年的老工程师来说,每年的这个时候心情总是复杂的。今年有个标志性的消息:全球半导体产业营收终于再次…...

Fast-GitHub:3个技巧让国内开发者告别GitHub龟速时代
Fast-GitHub:3个技巧让国内开发者告别GitHub龟速时代 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾经因为Gi…...
)
保姆级教程:在Windows 10/11上从源码编译Groops(含Qt环境变量避坑指南)
从零构建Groops编译环境:Windows系统下的完整避坑指南 当你在GNSS数据处理领域深耕时,一款强大的开源工具能让你事半功倍。Groops作为重力场恢复和精密定轨的瑞士军刀,其功能强大但编译过程却可能让新手望而却步。本文将带你一步步穿越编译迷…...

探索Windows平台智能PPT演示计时器的实现与实践
探索Windows平台智能PPT演示计时器的实现与实践 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 在技术分享或学术汇报场景中,时间管理常常成为影响演示效果的关键因素。演讲者需要同时关注内容表达…...

Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南
Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南 当你面对一个加密的网络流量时,是否曾感到无从下手?无论是调试HTTPS API调用、分析SSH连接问题,还是研究QUIC协议的行为,加密流量总是像一…...

GetQzonehistory:3步搞定QQ空间历史说说备份的终极方案
GetQzonehistory:3步搞定QQ空间历史说说备份的终极方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾想过要备份自己在QQ空间发布的那些珍贵回忆?那些…...

VirtualBox 6.1+ 搭配Win10:除了装系统,这些高效设置让你的虚拟机真正好用起来
VirtualBox 6.1 与Win10深度整合:解锁专业级虚拟化生产力的5个关键策略 当你已经成功在VirtualBox中安装好Windows 10虚拟机,这仅仅是虚拟化旅程的起点。真正的高手懂得如何将这个看似隔离的环境转变为无缝融入日常工作流的生产力引擎。本文将揭示那些鲜…...

STM32CubeMX外部中断实战:从按键消抖到LED状态切换
1. STM32CubeMX外部中断基础配置 第一次用STM32CubeMX配置外部中断时,我盯着那一堆选项有点懵。后来发现其实只要抓住几个关键点,整个过程就像搭积木一样简单。这里以最常见的按键控制LED为例,带你一步步实现这个功能。 首先打开CubeMX新建…...