Elasticsearch集群和Kibana部署流程
搭建Elasticsearch集群
1. 进入Elasticsearch官网下载页面,下载Elasticsearch
在如下页面选择Elasticsearch版本,点击download按钮,进入下载页面

右键选择自己操作系统对应的版本,复制下载链接

然后通过wget命令下载Elasticsearch安装包,并通过tar解压
#进入根目录
cd /
#下载压缩包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.25-linux-aarch64.tar.gz
#解压
tar -xf /elasticsearch-7.17.25-linux-aarch64.tar.gz
#更改文件夹名称
mv elasticsearch-7.17.25 elasticsearch
进入解压后的/elasticsearch目录下,通过 ll 命令可以看到如下内容:

2. 修改配置文件
修改配置文件为如下内容(我是用的是虚拟机环境,只需要配置一份,并复制虚拟机,在逐一修改配置即可,如果不是虚拟机环境,则需要一一配置)。
# 集群名称
cluster.name: my-es-cluster# 节点名称(每个节点需唯一)
node.name: node-1 # 其他节点分别命名为 node-2、node-3# 数据和日志路径
path.data: /elasticsearch/data
path.logs: /elasticsearch/logs# 网络设置
network.host: 192.168.166.40 #配置为当前elasticsearch节点主机的ip# 端口
http.port: 9200# 集群节点发现(9300为默认的集群通信端口)
discovery.seed_hosts: ["192.168.166.40:9300", "192.168.166.41:9300", "192.168.166.42:9300"]# 初始主节点(第一次启动指定)
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
注意:
节点名称为集群节点的唯一标识,不能重复,可以不配置,elasticsearch也可以自动生成;
初始化主节点配置的节点,则是可以参与选举并任选主节点的节点,和Kafka的controller类似;
数据目录和日志路径默认是在elasticsearch的安装目录下;
3. 修改虚拟内存
虚拟内存是提高内存使用空间,让一个固定的内存,保存远大于他的容量的内容,其实现方式有多种,其中常见的包括交换区(具体可以看我的另一片帖子操作系统的内存管理策略)以及磁盘映射,其中es所使用的就是后者磁盘映射。
扩展内存的本质实际上就是划分一块磁盘区域给操作系统管理。如交换区就是划分一块磁盘区域作为交换区,对于不常用的内存页(操作系统对于内存的管理是基于分页存储,也就是说在操作系统的眼里,内存是一个一个的内存页),操作系统会将其存入磁盘,待使用时,在进行读取。而磁盘映射则是划分一块硬盘区域交给操作系统管理,并将普通磁盘区域中的文件或设备映射到操作系统管理的特殊区域,这样操作系统就能知道整个文件或设备全部的地址,不需要读取到内存中在进行使用,而是直接根据地址寻找到自己需要的内容。
elasticsearch要求能够进行映射数量最小需要达到262144(页),所以我们需要执行如下命令:
#将vm.max_map_count=262144,通过tee -a命令,追加到/etc/sysctl.conf文件结尾,持久化配置
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
#修改内核参数,修改当前启动状态,不执行重启也可以
sudo sysctl -w vm.max_map_count=262144
4. 修改jvm内存
根据情况而定,我的虚拟机环境,调整为2g。修改/elasticsearch/config/jvm.options配置文件中追加如下内容:
-Xms2g
-Xmx2g
5. 修改文件描述符数量
文件描述符是已打开文件的唯一表示,当进程对文件进行操作时,操作系统会分配给这个文件唯一的文件描述符。
由于Elasticsearch不允许root用户启动,而新建用户默认可以分配的文件描述符只有4096(也就是只能同时读取4096个资源),这对于Elasticsearch是完全不够用的,所以我们需要给新建的用户修改文件描述符数量(Elasticsearch要求最小的文件描述符数量为65535)。
#创建目录,用于存储用户数据
mkdir /elasticsearch/run-user
#创建运行用户elasticsearch,用于运行elasticsearch,elasticsearch不允许root用户运行
sudo useradd -r -d /elasticsearch/run-user/ -s /sbin/nologin elasticsearch
#赋予用户目录权限
sudo chown -R elasticsearch:elasticsearch /elasticsearch
#通过命令向/etc/security/limits.conf文件中追加文件描述符的软硬限制
echo "elasticsearch soft nofile 65535" | sudo tee -a /etc/security/limits.conf
echo "elasticsearch hard nofile 65535" | sudo tee -a /etc/security/limits.conf
如果是systemd启动Elasticsearch,还需要修改systemd的配置文件,这里就不细说了。
6. 启动Elasticsearch集群
完成了以上的准备工作,就可以通过如下命令启动所有节点,开启集群了
#zhi定用户启动elasticsearch
sudo -u elasticsearch /elasticsearch/bin/elasticsearch
#后台启动命令,第一次学习的话推荐前台启动,可以更直观的看见日志信息
nohup sudo -u elasticsearch /elasticsearch/bin/elasticsearch &
通过浏览器访问 任意node_ip:9200/_cluster/health?pretty,可以看到如下集群信息,证明集群启动成功:

Kibana(Elasticsearch可视化界面)部署
1. 进入Kinbana官网下载页面,下载Kinbana
选择和部署的Elasticsearch一样的版本,然后点击DownLoad

右键对应版本,复制下载链接

进入服务器,执行如下命令
cd /
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.25-linux-aarch64.tar.gz
tar -xf /kibana-7.17.25-linux-aarch64.tar.gz
mv ./kibana-7.17.25-linux-aarch64 kibana
2. 修改配置文件
修改kibana.yml文件内容
vim /kibana/config/kibana.yml
#在文件末尾添加如下内容#设置Kibana监听的主机名/IP地址
server.host: "0.0.0.0" # 0.0.0.0 表示允许所有IP地址访问,生产环境可指定特定IP
#Kibana服务端口(默认5601)
server.port: 5601
#elasticsearch集群地址
elasticsearch.hosts: ["http://192.168.166.40:9200","http://192.168.166.41:9200","http://192.168.166.42:9200"]
3. 启动Kibana
Kinbana同样不允许以root用户启动,所以我们要将Kibana的相关文件所属用户和用户组,交给elasticsearch,并由这个用户来启动Kibana,在确保elasticsearch集群启动的前提下,执行如下命令
#更改所属用户用户组
sudo chown -R elasticsearch:elasticsearch /kibana
#启动Kinbana
sudo -u elasticsearch /kibana/bin/kibana
#后台启动命令,第一次学习的话推荐前台启动,可以更直观的看见日志信息
nohup sudo -u elasticsearch /kibana/bin/kibana &
访问ip:5601,看到如下页面证明Kibana启动成功

我可以在Kibana提供的DevTool中执行相关指令

执行 GET /_cluster/health 可以看到如图所示,集群连接成功

相关文章:
Elasticsearch集群和Kibana部署流程
搭建Elasticsearch集群 1. 进入Elasticsearch官网下载页面,下载Elasticsearch 在如下页面选择Elasticsearch版本,点击download按钮,进入下载页面 右键选择自己操作系统对应的版本,复制下载链接 然后通过wget命令下载Elastics…...

丹摩征文活动 | 丹摩智算:大数据治理的智慧引擎与实践探索
丹摩DAMODEL|让AI开发更简单!算力租赁上丹摩! 目录 一、引言 二、大数据治理的挑战与重要性 (一)数据质量问题 (二)数据安全威胁 (三)数据管理复杂性 三、丹摩智算…...

【Django】Clickjacking点击劫持攻击实现和防御措施
Clickjacking点击劫持 1、clickjacking攻击2、clickjacking攻击场景 1、clickjacking攻击 clickjacking攻击又称为点击劫持攻击,是一种在网页中将恶意代码等隐藏在看似无害的内容(如按钮)之下,并诱使用户点击的手段。 2、clickj…...
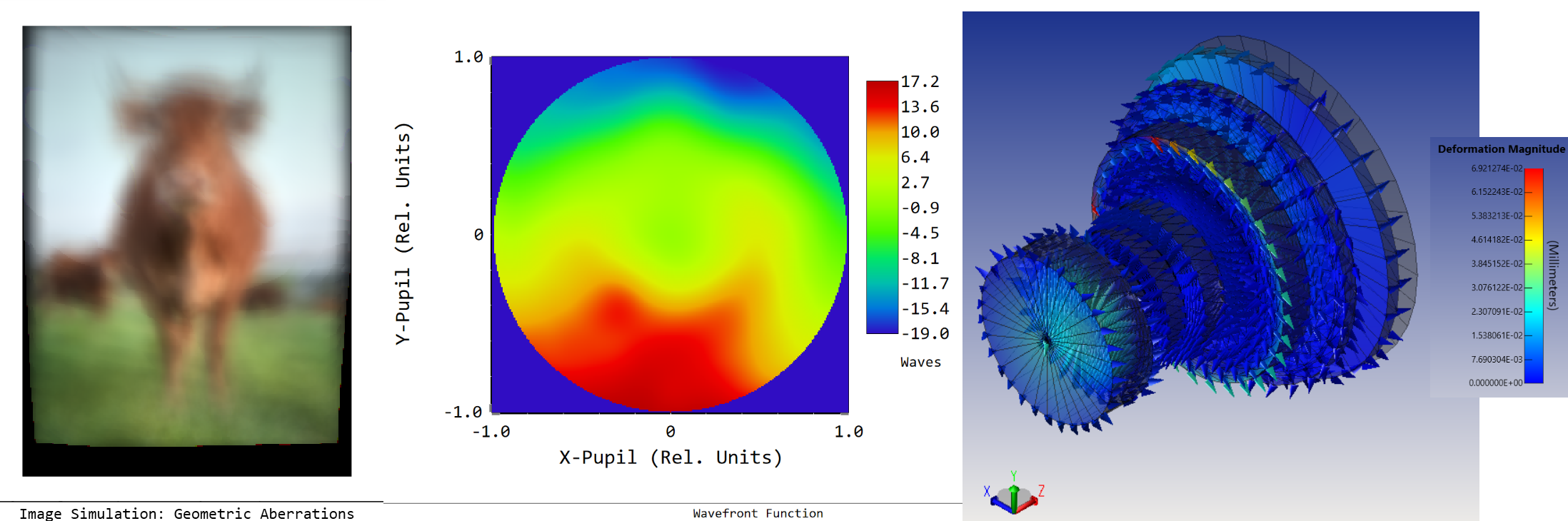
Ansys Zemax | 手机镜头设计 - 第 4 部分:用LS-DYNA进行冲击性能分析
该系列文章将讨论智能手机镜头模组设计的挑战,从概念和设计到制造和结构变形分析。本文是四部分系列中的第四部分,它涵盖了相机镜头的显式动态模拟,以及对光学性能的影响。使用Ansys Mechanical和LS-DYNA对相机在地板上的一系列冲击和弹跳过程…...

工具收集 - java-decompiler / jd-gui
工具收集 - java-decompiler / jd-gui 参考资料 用法:拖进来就行了 参考资料 https://github.com/java-decompiler/jd-gui 脚本之家:java反编译工具jd-gui使用详解...

《无线重构世界》射频模组演进
射频前端四大金刚 射频前端由PA、LNA、滤波器、开关“四大金刚” 不同的模块有自己的工艺和性能特点 分层设计 射频前端虽然只由PA、LNA、开关、混频器4个模块构成,但不同模块之间相互连接且相互影响。如果将射频系统当成一个整体来理解,其中的细节和…...

渗透测试---docker容器
声明:学习素材来自b站up【泷羽Sec】,侵删,若阅读过程中有相关方面的不足,还请指正,本文只做相关技术分享,切莫从事违法等相关行为,本人一律不承担一切后果 目录 一、Docker的作用与优势 二、docker的核心…...

【go从零单排】Atomic Counters原子计数
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 在 Go 语言中,原子计数器(Atomic Counters)是…...

VSCode中python插件安装后无法调试
问题 VSCode中python插件安装后无法调试,如下,点击调试,VScode中不报错,也没有调试 解决方法 1、查看配置 打开所在路径 2、拷贝 将整个文件夹拷贝到vscode默认路径下 3、问题解决 再次调试,可以正常使用了…...

用react实现radio同时关联proform组件
实现: <ProFormRadio.GroupradioType{button}name{[bodyConfig, format]}label"请求体格式"initialValue{json}options{createTabs}fieldProps{{buttonStyle: solid,wrapperMarginInlineEnd: 20,onChange: e > {let v e.target.value;databaseMod…...

Objective-C 1.0和2.0有什么区别?
Objective-C ObjC比较小众,在1980年左右由Stepstone公司的Brad Cox和Tom Love发明。后来NeXT公司获得ObjC语言使用权,再后来到1996年NeXT被苹果公司收购也变成苹果公司使用,Mac市场占有率本身就不高,ObjC没有太多程序员。在移动互…...

TCP连接如何保障数据传输安全
TCP连接保障数据传输安全主要通过以下几个机制实现: 1、建立连接:TCP通过三次握手过程建立连接,确保通信双方实体真实存在,为后续的可靠数据传输打下基础。 2、序号机制:TCP为每个传输的数据包分配一个序号ÿ…...

【论文复现】ChatGPT多模态命名实体识别
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ChatGPT ChatGPT辅助细化知识增强!1. 研究背景2. 模型结构和代码3. 任务流程第一阶段:辅助精炼知识启发式生成第二阶段…...

管理 Elasticsearch 变得更容易了,非常容易!
作者:来自 Elastic Ken Exner Elasticsearch 用户,我们听到了你的心声。管理 Elasticsearch 有时会变得很复杂,面临的挑战包括性能调整、问题检测和资源优化。我们一直致力于简化你的体验。今天,我们宣布了自收购 Opster 以来的一…...
 和 poll() 方法的超时控制及线程池的讨论)
SynchronousQueueworkQueue.offer() 和 poll() 方法的超时控制及线程池的讨论
2024.11.12 11:26 问:workQueue.offer(command) 这里 workQueue.poll(keepAlive, TimeUnit.NANOSECONDS) : 这里的 workQueue.offer(command) 没有超时时间控制? Claude 3.5 Haiku 非常好的问题!我来详细解释 offer() 和 poll() 方法的区别…...

自动驾驶---“火热的”时空联合规划
1 背景 早期的不少规划算法都是横纵分离的(比如Apollo),先求解path之后,依赖path的结果再进行speed的求解。这种横纵解耦的规划方式具有以下特点: 相对较为简单,计算量通常较小,容易实现实时性要求。但是由于分别规划横向和纵向运动,可能会忽略两者之间的耦合关系,导致…...

命令行工具进阶指南
🚀 命令行工具进阶指南:Git、Shell与效率工具的进阶之路 掌握命令行工具,让你的开发效率突飞猛进。本文将深入探讨 Git 高级技巧、Shell 脚本自动化以及各种效率倍增的 CLI 工具。 📑 目录 Git 高级技巧与工作流Shell 脚本自动化…...

扫雷游戏代码分享(c基础)
hi , I am 36. 代码来之不易👍👍👍 创建两个.c 一个.h 1:test.c #include"game.h"void game() {//创建数组char mine[ROWS][COLS] { 0 };char show[ROWS][COLS] { 0 };char temp[ROWS][COLS] { 0 };//初始化数…...

基于vue框架的的社区居民服务管理系统8w86o(程序+源码+数据库+调试部署+开发环境)系统界面在最后面。
系统程序文件列表 项目功能:居民,楼房信息,报修信息,缴费信息,维修进度 开题报告内容 基于Vue框架的社区居民服务管理系统开题报告 一、研究背景与意义 随着城市化进程的加速,社区居民数量激增,社区管理面临着前所未有的挑战。传统的社区…...

一分钟快速熟悉makedown
Markdown 是一种轻量级标记语言,广泛用于编写文档、撰写博客、创建 README 文件等。它的语法简单易学,能够快速生成格式化的文本。以下是 Markdown 的一些常用语法和示例: 1. 标题 Markdown 支持六级标题,使用 # 符号表示。 # …...

联想拯救者15ISK加装NVMe SSD实战:从硬件兼容到系统部署的避坑指南
1. 联想拯救者15ISK加装NVMe SSD前的准备工作 我手上这台联想拯救者15ISK已经陪伴我征战了五年多,最近明显感觉到系统响应变慢,游戏加载时间变长。经过一番排查,发现瓶颈主要出在机械硬盘上。于是决定给它加装一块NVMe SSD,让老战…...

离线环境下的高效远程开发:手把手搭建VS Code Remote-SSH离线开发环境
1. 为什么需要离线远程开发环境 在不少企业研发场景中,开发机往往处于严格的内网隔离环境。我去年参与过一个军工项目,所有开发设备都禁止连接互联网,第一次遇到这种情况时,传统在线安装方式完全失效,团队花了整整两天…...

大语言模型不确定性量化与可靠性评估:从理论到工程实践
1. 项目概述与核心价值最近在整理大语言模型落地应用中的一些棘手问题时,我反复被一个词绊住脚:不确定性。无论是让模型生成一份市场分析报告,还是回答一个具体的编程问题,我们得到的答案看起来总是那么“自信满满”,但…...

《Web前端实战:从零构建“漫步时尚广场”电商后台管理系统》
1. 电商后台管理系统前端架构设计 第一次接触电商后台管理系统开发时,我被各种功能模块搞得晕头转向。直到把整个系统拆解成几个核心部分,才真正理清思路。"漫步时尚广场"这个案例就很典型,我们可以把它看作由三大结构层组成&#…...
04)
【审计专栏-监督监管领域】【信息科学与工程学】【社会科学】第十篇 社会底层核心规则(核心权力、核心利益、核心资源绑定、私下运作、关键价值交换、上下博弈)04
模型046:企业复杂利益链与多方利益博弈模型 1. 模型概述 项目 内容 模型名称 企业复杂利益链与多方利益博弈模型 核心场景 一家大型建筑企业“宏建集团”中标某市的地铁延长线建设项目。项目涉及总包方(宏建)、多个分包商(土建、机电、装修等)、材料供应商、监理…...

AI应用安全实战:使用SecurityLayer构建防护中间件
1. 项目概述:一个为AI应用量身定制的安全防护层最近在折腾AI应用开发,特别是那些需要调用外部API或者处理敏感用户输入的场景,安全问题总是让人头疼。你辛辛苦苦搭了个智能客服,结果用户输入一串精心构造的恶意提示词,…...

Flutter 性能优化完全指南
Flutter 性能优化完全指南 引言 性能优化是移动应用开发中至关重要的一环。Flutter 虽然天生具有较好的性能表现,但在复杂应用中仍需要开发者进行针对性优化。本文将深入探讨 Flutter 性能优化的各种技巧和最佳实践。 性能问题定位 使用 DevTools // 在 pubspec.yam…...

利用 Taotoken 统一接口简化多模型 A B 测试流程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 统一接口简化多模型 A/B 测试流程 对于算法工程师和开发者而言,评估不同大语言模型在特定任务上的表现是…...

【通信】D2D通信中基于Qlearning强化学习算法的联合资源分配与功率控制算法matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

英伟达巨额投资,四大云巨头财报亮眼,半导体产业扩张背后隐忧浮现
物理世界产能成为瓶颈云收入快速增长支撑巨头大规模投资。2026年第一季度,谷歌云、微软Azure、亚马逊AWS云业务表现出色,四家公司云业务合计季度营收超700亿美元,同比增长超40%。但物理世界产能受限,谷歌、微软、亚马逊订单积压严…...