LLaMA-Factory学习笔记(1)——采用LORA对大模型进行SFT并采用vLLM部署的全流程
该博客是我根据自己学习过程中的思考与总结来写作的,由于初次学习,可能会有错误或者不足的地方,望批评与指正。
1. 安装
1.1 LLaMA-Factory安装
安装可以参考官方 readme (https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md)
懒得跳转网页的也可以直接复制下面的内容:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
1.2 下载LLM
从huggingface或者镜像源(https://hf-mirror.com/)下载想要微调的模型。
PS:可以不用下载到本地,不过因为我们服务器不允许挂梯子,而且担心网络不稳定,所以我都是下载到本地的。
2. 准备训练数据
这应该是用LLaMA-Factory微调整个大模型中为数不多的需要写代码的部分。数据集的说明请参考:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md。
由于我们是采用SFT的方式来构建数据集,所以简单点可以直接看https://github.com/hiyouga/LLaMA-Factory/blob/main/data/alpaca_zh_demo.json 这个json文件的格式,将数据集构建为上述json格式即可,即:
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
数据为一个列表,列表中每个元素为一个字典。如果是单轮对话则无需 history。
当数据集构建完成后,可以放在data/路径下,也可以放在其他位置。
3. 配置dataset_info.json文件
将数据集构建完成后,需要在data/目录下找到dataset_info.json文件,并在这个文件中配置数据集的信息(个人觉得这一步类似于django中的注册url)。
假设构建的数据集名字为input_data.json,那么在dataset_info.json需要加如下的字典:
'数据集名称': {"file_name": "input_data.json","columns": {"prompt": "instruction","query": "input","response": "output"}},
这里数据集名称可以自行定义,只需要在后续写yaml文件时把这个名称写进去就行。这里的file_name要与数据集的名称相同,如果文件放在了data/路径下,只需要数据集名称就行,而如果文件没有放在该路径下,则需要在这里指定路径。
4. 微调模型
微调模型可以选用启动网页服务来进行微调,执行以下命令启动网页服务:
llamafactory-cli webui
当然我更喜欢用配置文件的方式来微调模型。新建一个 yaml 文件,假设名为train_qwen_lora_sft.yaml,可以在该文件中定义具体的训练设置。当然很多朋友不知道有哪些参数需要设置,可以查看github中的demo进行配置(https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/train_lora/llama3_lora_sft.yaml),具体而言:
### model
model_name_or_path: Qwen2-1.5B-Instruct### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all### dataset
dataset: input_data
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16### output
output_dir: saves/llama3-8b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
这里要注意的有几个参数:
model_name_or_path: 这个是需要微调的模型,如果下载到了本地,则指定本地路径;如果没有下载到本地,就在huggingface上找路径。dataset:这个是数据集的名称,即在第三步中配置的数据集名称。这里支持多个数据集进行微调,如果要设置多个数据集,那么用逗号隔开,即数据集名称1,数据集名称2。template: 用的什么模型就用什么模板,比如用的通义千问就设置qwen。template的名字可以参考https://zhuanlan.zhihu.com/p/689333581。output_dir:这里是输出的文件路径,需要注意的是,由于采用的是LORA进行微调,所以这里输出的文件是LORA的参数,在实际部署的时候最好将LORA参数和原模型参数进行合并。具体合并的方式下一步会讲。num_samples:如果想用数据集中所有数据进行训练,这个值可以设置的很大,比如999999,否则这个值如果小于数据集大小的话只会选择部分数据进行训练。learning_rate:不只是learning_rate,所有的数字都可能会面临一个问题,即如果采用科学计数法(如1e-6),会报错,详见:https://blog.csdn.net/qq_35357274/article/details/143615453,解决方式就是用1.0e-6或者0.000001。eval:如果不需要验证这一坨其实可以不需要的。
微调的时候有可能显卡被人占用了,需要指定在哪几张卡上进行微调,所以用如下的命令进行微调:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train yaml路径
微调完成后,在output_dir路径下会有个文件夹,即LORA的参数文件,接着需要合并文件。
5. 合并文件
合并文件的yaml文件(注意不是训练的yaml文件,需要新建一个,我最开始以为两个是一个文件)可以参考https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/merge_lora/qwen2vl_lora_sft.yaml,具体而言:
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters### model
model_name_or_path: Qwen/Qwen2-VL-7B-Instruct
adapter_name_or_path: saves/qwen2_vl-7b/lora/sft
template: qwen2_vl
finetuning_type: lora### export
export_dir: models/qwen2_vl_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
model_name_or_path:如上面一样是原始模型的路径。adapter_name_or_path:LORA的参数位置,即第四步中output_dir的路径。export_dir:合并后的文件路径。export_size:单个文件的最大大小(GB)。
运行命令:
llamafactory-cli export yaml路径
6. 部署
我这里选用的vLLM作为部署框架,有两种部署方式。如果是自己做实验的话可以离线部署,如果是上线的话建议用在线部署。
6.1 离线部署
离线部署即自己写个类或者方法,调用微调后的模型,代码如下:
import os
import torch
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from vllm import LLM, SamplingParamsclass Detect:def __init__(self, model_path, temperature=0.8, top_p=0.95):""":param model_path: str:param temperature: float取值范围: [0, +∞]- 当 temperature 设为 0 时,模型总是选择具有最高概率的单词,这会导致生成的结果非常确定性,缺乏随机变化。- 当 temperature 接近 1 时,模型的选择更加随机,这可以增加生成文本的多样性。- 高于 1 的值可能会导致生成的文本更加随机,有时可能失去连贯性- 注: 如果生成的内容太多就调低这个值:param top_p: float取值范围: (0, 1]- top_p 参数表示从候选词汇中选取累积概率总和达到或超过 p 的词汇集合,然后从中随机选取下一个词汇。这种方式可以减少 temperature 为高值时可能出现的无意义输出。- 当 top_p 设置为接近 1 的值时,几乎所有的候选词汇都会被考虑,这类似于 temperature 接近 1 的情况。- 当 top_p 设置为较低值时,只有最有可能出现的几个词汇会被选中,这样可以减少输出的不确定性。- 注: 如果生成的内容太多就调低这个值"""if not isinstance(temperature, (int, float)) or not isinstance(top_p, (int, float)):raise ValueError('变量 "temperature" 和 "top_p" 必须为整型或浮点数')if temperature < 0:raise ValueError('变量 "temperature" 的取值范围为[0, +∞]')if top_p <= 0 or top_p > 1:raise ValueError('变量 "top_p" 的取值范围为(0, 1]')self.template = 'hi'self.llm = LLM(model=model_path, dtype=torch.bfloat16)self.tokenizer = self.llm.get_tokenizer()self.sampling_params = SamplingParams(temperature=temperature, top_p=top_p)def detect(self, input_texts):prompts = []for input_text in input_texts:prompt = [{'role': 'system', 'content': self.template},{'role': 'user', 'content': input_text + '\n输出:'}]prompts.append(prompt)prompts = self.tokenizer.apply_chat_template(prompts, add_generation_prompt=True, tokenize=False)outputs = self.llm.generate(prompts, self.sampling_params)return [output.outputs[0].text for output in outputs]这里model_path即微调后的模型路径。还需注意的是,如果服务器足够垃圾,有可能self.llm = LLM(model=model_path, dtype=torch.bfloat16)会报错,因为老的服务器有可能不支持bfloat16,改为float16就行。
离线的代码如果部署到线上,在多线程调用的情况下,很有可能会触发cuda显存不够的错误,所以部署项目的时候通常采用在线部署的方式。
6.2 在线部署
与离线部署不同,采用在线部署首先需要启动服务。
CUDA_VISIBLE_DEVICES=2 python3 -m vllm.entrypoints.openai.api_server --model model_path --served-model-name qwen --trust-remote-code --host 0.0.0.0 --port 8080 --dtype bfloat16
这里model_path是微调后的模型路径;host是主机,默认为localhost,如果项目是在容器内的话,这里需要自行设置IP地址;port是端口号,默认为8000。
当启动服务后,会有这么一个提示信息:

这个IP地址即服务的地址,就可以采用访问http的形式来调用模型。
有的人会使用curl http的形式来调用接口,我选用的是采用python脚本实现,具体代码如下:
from openai import OpenAIdef detect(input_texts, template, port='http://localhost:8000/v1', temperature=0.8, top_p=0.95):""":param input_texts: list输入文本:param template: str提示模板:param port: str端口号:param temperature: float取值范围: [0, +∞]- 当 temperature 设为 0 时,模型总是选择具有最高概率的单词,这会导致生成的结果非常确定性,缺乏随机变化。- 当 temperature 接近 1 时,模型的选择更加随机,这可以增加生成文本的多样性。- 高于 1 的值可能会导致生成的文本更加随机,有时可能失去连贯性- 注: 如果生成的内容太多就调低这个值:param top_p: float取值范围: (0, 1]- top_p 参数表示从候选词汇中选取累积概率总和达到或超过 p 的词汇集合,然后从中随机选取下一个词汇。这种方式可以减少 temperature 为高值时可能出现的无意义输出。- 当 top_p 设置为接近 1 的值时,几乎所有的候选词汇都会被考虑,这类似于 temperature 接近 1 的情况。- 当 top_p 设置为较低值时,只有最有可能出现的几个词汇会被选中,这样可以减少输出的不确定性。- 注: 如果生成的内容太多就调低这个值:return:"""if not isinstance(temperature, (int, float)) or not isinstance(top_p, (int, float)):raise ValueError('变量 "temperature" 和 "top_p" 必须为整型或浮点数')if temperature < 0:raise ValueError('变量 "temperature" 的取值范围为[0, +∞]')if top_p <= 0 or top_p > 1:raise ValueError('变量 "top_p" 的取值范围为(0, 1]')openai_api_key = "EMPTY"openai_api_base = portclient = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)outputs = []for input_text in input_texts:chat_response = client.chat.completions.create(model="qwen",messages=[{"role": "system", "content": template},{"role": "user", "content": input_text},],temperature=temperature,top_p=top_p,)outputs.append(chat_response.choices[0].message.content)return outputs
这个代码里面port即上面控制台信息中返回的IP地址,传入即可。
7. 参考
[1] https://github.com/hiyouga/LLaMA-Factory/tree/main
[2] llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署
[3] VLLM 把模型部署成 openai API server 形式
[4] https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct
[5] https://github.com/echonoshy/cgft-llm/blob/master/llama-factory/README.md
相关文章:
LLaMA-Factory学习笔记(1)——采用LORA对大模型进行SFT并采用vLLM部署的全流程
该博客是我根据自己学习过程中的思考与总结来写作的,由于初次学习,可能会有错误或者不足的地方,望批评与指正。 1. 安装 1.1 LLaMA-Factory安装 安装可以参考官方 readme (https://github.com/hiyouga/LLaMA-Factory/blob/main/…...

PHP和Python脚本的性能监测方案
目录 1. 说明 2. PHP脚本性能监测方案 2.1 安装xdebug 2.2 配置xdebug.ini 2.3 命令行与VS Code中使用 - 命令行 - VS Code 2.4 QCacheGrind 浏览 3. Python脚本性能监测方案 3.1 命令行 4. 工具 5.参考 1. 说明 获取我们的脚本程序运行时的指标,对分析…...

C语言实现数据结构之堆
文章目录 堆一. 树概念及结构1. 树的概念2. 树的相关概念3. 树的表示4. 树在实际中的运用(表示文件系统的目录树结构) 二. 二叉树概念及结构1. 概念2. 特殊的二叉树3. 二叉树的性质4. 二叉树的存储结构 三. 二叉树的顺序结构及实现1. 二叉树的顺序结构2.…...

战略共赢 软硬兼备|云途半导体与知从科技达成战略合作
2024年11月5日,江苏云途半导体有限公司(以下简称“云途”或“云途半导体”)与上海知从科技有限公司(以下简称“知从科技”)达成战略合作,共同推动智能汽车领域高端汽车电子应用的开发。 云途半导体与知从科…...

python:用 sklearn 构建 K-Means 聚类模型
pip install scikit-learn 或者 直接用 Anaconda3 sklearn 提供了 preprocessing 数据预处理模块、cluster 聚类模型、manifold.TSNE 数据降维模块。 编写 test_sklearn_3.py 如下 # -*- coding: utf-8 -*- """ 使用 sklearn 构建 K-Means 聚类模型 "&…...
实现方案)
elementUI中2个日期组件实现开始时间、结束时间(禁用日期面板、控制开始时间不能超过结束时间的时分秒)实现方案
没有使用selectableRange 禁用时分秒,是因为他会禁止每天的时分秒。 我们需要解决的是当开始时间、结束时间是同一天时, 开始时间不能超过结束时间。 如果直接清空,用户体验不好。所以用watch监听赋值,当前操作谁,它不…...

Oracle 聚集因子factor clustering
文章目录 聚集因子(Factor clustering)举例说明查询聚集因子聚集因子的优化结论 最近发现突然忘记聚集因子的原理了,故整理记录一下 聚集因子(Factor clustering) 在Oracle中,聚集因子(Clustering Factor)用于衡量数据在表中存储…...

【大数据学习 | kafka高级部分】kafka的快速读写
1. 追加写 根据以上的部分我们发现存储的方式比较有规划是对于后续查询非常便捷的,但是这样存储是不是会更加消耗存储性能呢? 其实kafka的数据存储是追加形式的,也就是数据在存储到文件中的时候是以追加方式拼接到文件末尾的,这…...

云技术基础
学习视频笔记均来自B站UP主" 泷羽sec",如涉及侵权马上删除文章 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负 https://space.bilibili.com/350329294* 为什么要学云技术? 无论是防御还是…...
)
字节序(Byte Order)
这里写自定义目录标题 有两种主要的字节序:字节序与平台字节序转换 字节序(Byte Order)是指数据在内存中存储时字节的排列顺序。由于不同的计算机体系结构可能采用不同的字节序,因此理解字节序非常重要,特别是在处理多…...

融云:社交泛娱乐出海机会尚存,跨境电商异军突起
近年来,直播、语聊房、游戏社区,这些中国网友熟悉的网络社交形式,正在海外市场爆发出新的生命力。无论是被炒到几百人民币一个的 Clubhouse 邀请码,还是先后登顶中东下载榜的 Yalla、JACO,这些快速掀起体验浪潮的社交娱…...

django博客项目实现站内搜索功能
Django博客站内搜索功能实现 1. 准备工作 确保Django项目已经创建好,并且有一个用于存储博客文章的模型(例如Post)。 2. 定义搜索表单 在应用目录下创建一个forms.py文件,定义一个搜索表单。 from django import formsclass …...

蓝桥杯c++算法学习【1】之枚举与模拟(卡片、回文日期、赢球票、既约分数:::非常典型的比刷例题!!!)
别忘了请点个赞收藏关注支持一下博主喵!!! 关注博主,更多蓝桥杯nice题目静待更新:) 枚举与模拟 一、卡片: 【问题描述】 小蓝有很多数字卡片,每张卡片上都是一个数字(0到9)。 小蓝…...

Android 延时操作的常用方法
一、简介 在Android开发中我们可能会有延时执行某个操作的需求,例如我们启动应用的时候,一开始呈现的是引导页面,3秒后进入主界面,这就是一个延时操作。还有一种是执行某些接口任务时,需要有超时机制。下面介绍常用的…...
AI驱动的轻量级笔记应用Blinko
什么是 Blinko ? Blinko 是一个创新的开源项目,专为想要快速捕捉和整理瞬间想法的个人而设计。Blinko 允许用户在灵感迸发的瞬间无缝记录想法,确保不会错过任何创意火花。 Blinko 的设计初衷是让笔记记录变得更简单,让用户专注于内…...
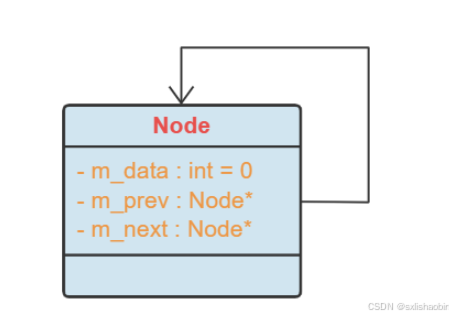
一文搞懂 UML 类图
面向对象设计 主要就是使用UML的类图,类图用于描述系统中所包含的类以及它们之间的相互关系,帮助人们简化对系统的理解,它是系统分析和设计阶段的重要产物,也是系统编码和测试的重要模型依据 一、UML类图简介 统一建模语言 UML …...

Zabbix 7 最新版本安装 Rocky Linux 8
前言 本实验主要在Rocky Linux 中安装Zabbix,其他centos8、Debian、Ubuntu、Alma Linux都可以安装,就是在中间件有点不同。Nginx就要配置一下,官网给的教程也算是很规范的,就是在MySQL上要自己安装,他没有告诉我们&am…...

使用HTML、CSS和JavaScript创建动态雪人和雪花效果
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 ✨特色专栏:…...

redis bind 127.0.0.1和bind 10.34.56.78的区别
绑定到 127.0.0.1,默认情况下,Redis 只会接受来自本地主机的连接。其他地址的则无法成功连接。如果绑定到主机的IP地址,则是可以被其他主机连接的。 可以通过iptables规则,进一步限制对redis的访问。 1、允许本地回环接口链接 …...

基于点云的 3D 目标检测模型 PointPillars 部署 tensorRT
PointPillars 3D 目标检测模型部署 tensorRT 一直想折腾一下基于点云的目标检测模型,但由于没有实际项目或工作需要,搞也搞的不够深入,把开源的模型跑一下似乎好像做过又好像没有做过。内心一直想搞一下,选定了 PointPillars 这个…...
)
逆向分析第一步:手把手教你搭建WinDbg+VMware双机调试环境(含问题排查)
逆向工程实战:从零构建WinDbg与VMware双机调试环境调试器与虚拟机的组合是安全研究人员分析软件行为、挖掘漏洞的必备工具链。想象一下,当你需要观察一个可疑驱动程序如何与操作系统内核交互,或是追踪某个恶意样本在系统底层的活动轨迹时&…...

通过Taotoken CLI工具一键配置团队开发环境与统一模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置团队开发环境与统一模型调用 在团队协作开发中,统一管理大模型API的接入配置是一项常见且…...

【信息科学与工程学】计算机科学与自动化——第六十二篇 虚拟化算法02
虚拟化领域核心算法详解(续) 算法19: 虚拟机快照与还原算法 编号: 19 类型: 快照管理算法 虚拟化领域: 存储虚拟化 算法声明: 虚拟机快照算法用于创建虚拟机在某一时间点的完整状态,包括内存、磁盘和CPU寄存器状态,支持增量快照、差异快照和快照链管理,实现快…...
代码实现)
CPT 强化学习(Cumulative Prospect Theory Reinforcement Learning)代码实现
✅ CPT 强化学习(Cumulative Prospect Theory Reinforcement Learning)代码实现 以下提供实用、可运行的 Python 实现,结合 Cumulative Prospect Theory (CPT) 与强化学习。 1. 核心概念回顾 在传统 RL 中,目标是最大化期望回报&a…...

Google 广告场景下 Uniswap 钓鱼攻击机理与 Web3 防御体系研究
摘要 2026 年 5 月 22 日,GoPlus 安全团队发布预警,针对 Web3 领域头部去中心化交易平台 Uniswap 的搜索引擎钓鱼攻击呈规模化爆发态势。攻击者通过购买 Google Ads 关键词广告,将高仿钓鱼网站置顶于搜索结果前列,结合视觉相似域名…...

CleanMyWechat:一键解放你的PC微信存储空间
CleanMyWechat:一键解放你的PC微信存储空间 【免费下载链接】CleanMyWechat 自动删除 PC 端微信缓存数据,包括从所有聊天中自动下载的大量文件、视频、图片等数据内容,解放你的空间。 项目地址: https://gitcode.com/gh_mirrors/cl/CleanMy…...

从零开始在个人项目中接入Taotoken并完成首次计费消费
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始在个人项目中接入Taotoken并完成首次计费消费 作为一名个人开发者,在尝试将大模型能力集成到自己的项目中时&a…...

如何在3分钟内将视频压缩90%?免费开源神器CompressO完全指南
如何在3分钟内将视频压缩90%?免费开源神器CompressO完全指南 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/co/compr…...

告别TeamViewer!在Ubuntu 22.04上安装向日葵远程控制的完整保姆级教程
告别TeamViewer!在Ubuntu 22.04上安装向日葵远程控制的完整保姆级教程 远程协作已成为现代开发者和运维人员的日常刚需。当TeamViewer频繁弹出商业使用提醒或遭遇连接不稳定时,许多技术从业者开始寻找更轻量、更自由的替代方案。作为国内领先的远程控制…...

DeepSeek推理内存暴涨400%的元凶找到了:详解PagedAttention在DeepSeek-VL中的适配陷阱与绕过方案
更多请点击: https://codechina.net 第一章:DeepSeek推理内存暴涨400%的现象复现与根因定位 在部署 DeepSeek-R1-7B 模型进行批量文本生成时,我们观测到 GPU 显存占用从预期的约 8.2 GB 飙升至 41.3 GB,增幅达 400%,显…...