OpenAI大改下代大模型方向,scaling law撞墙?AI社区炸锅了
有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。
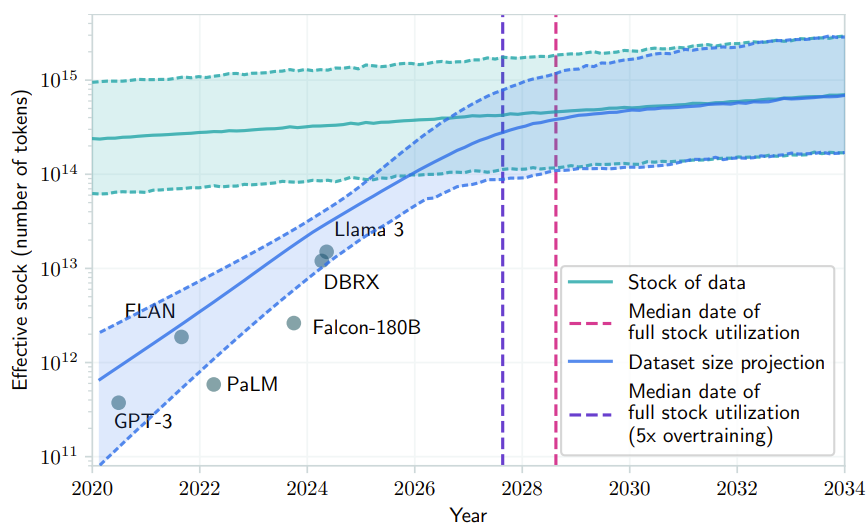
来自论文《Will we run out of data? Limits of LLM scaling based on human-generated data》
但似乎我们不必等到 2028 年了。昨天,The Information 发布了一篇独家报道《随着 GPT 提升减速,OpenAI 改变策略》,其中给出了一些颇具争议的观点:
-
OpenAI 的下一代旗舰模型的质量提升幅度不及前两款旗舰模型之间的质量提升;
-
AI 产业界正将重心转向在初始训练后再对模型进行提升;
-
OpenAI 已成立一个基础团队来研究如何应对训练数据的匮乏。
文章发布后,热议不断。OpenAI 著名研究科学家 Noam Brown 直接表示了反对(虽然那篇文章中也引用了他的观点)。他表示 AI 的发展短期内并不会放缓。并且他前些天还在另一篇 X 推文中表示,对于 OpenAI CEO 山姆・奥特曼的 AGI 发展路径已经清晰的言论(「事情的发展速度将比人们现在预想的要快得多」),OpenAI 的大多数研究者都表示比较认同。
著名 X 博主 @apples_jimmy 甚至直斥之为 Fake News,毕竟奥特曼说过 AGI 很快就要实现了。

OpenAI 的 Adam GPT 则给出了更详细的反对意见。他表示大模型的 scaling laws 和推理时间的优化是两个可以互相增益的维度。也就是说就算其中一个维度放缓,也不能得出 AI 整体发展放缓的结论。
OpenAI 产品副总裁 Peter Welinder 也认同上述看法。
当然,也有人认同 The Information 这篇文章的观点,比如一直有类似观点的 Gary Marcus 表示这篇文章宣告了自己的胜利。

数据科学家 Yam Peleg 也表示某前沿实验室的 scaling laws 出现了巨大的(HUGE)受益递减问题。

大多数吃瓜群众基本认同 OpenAI 相关人士公开发布的意见,毕竟该公司虽然存在无数的争议和八卦,但目前仍旧是当之无愧的行业领导者。也就是说,相比于媒体揣测,OpenAI 的话会更可信一些。
不过有意思的是,The Information 这篇报道也宣称很多信息来自 OpenAI 内部员工和研究者。当然,该媒体没有给出具体的信息源。下面我们就来看看这篇引发广泛的争议的报道究竟说了什么。
使用 ChatGPT 和其他人工智能产品的人数正在飙升。不过,支撑这些产品的基本构建模块的改进速度似乎正在放缓。
为了弥补这种减速,OpenAI 正在开发新技术来增强这些构建模型,即大型语言模型。
据一位知情人士透露,尽管 OpenAI 只完成了 Orion 训练过程的 20%,但奥特曼表示,在智能和完成任务和回答问题的能力方面,它已经与 GPT-4 不相上下。
据一些使用或测试过 Orion 的 OpenAI 员工称,虽然 Orion 的性能最终会超过之前的型号,但相比于该公司发布的最新两款旗舰模型 GPT-3 和 GPT-4 之间的飞跃,质量的提升要小得多。
据这些员工称,该公司的一些研究者认为,在处理某些任务方面,Orion 并不比其前代模型更好。据 OpenAI 的一名员工称,Orion 在语言任务上表现更好,但在编程等任务上可能不会胜过之前的模型。其中一位员工表示,这可能是一个问题,因为与 OpenAI 之前发布的其他模型相比,Orion 在 OpenAI 数据中心运行的成本可能更高。
Orion 的情况可以检验人工智能领域的一个核心假设,即 scaling laws:只要有更多数据可供学习,并有更多的计算能力来促进训练过程,LLM 就能继续以相同的速度提升性能。
为了应对近期 GPT 提升放缓对基于训练的 scaling laws 带来的挑战,AI 行业似乎正在将精力转向训练后对模型进行改进,这可能会产生不同类型的 scaling laws。
包括 Meta 的马克・扎克伯格在内的一些 CEO 表示,在最坏的情况下,即使当前技术没有进步,仍有很大空间在现有技术的基础上构建消费者和企业产品。
例如,OpenAI 正忙于将更多的编程功能融入其模型中,以抵御来自竞争对手 Anthropic 的重大威胁。后者正在开发一种软件,其可以接管用户电脑,通过像人类一样执行点击、光标移动、文本输入来使用不同的应用程序,从而完成涉及网络浏览器活动或应用程序的白领工作。
这些产品是向处理多步骤任务的 AI 智能体迈进的一部分,可能与 ChatGPT 最初发布时一样具有革命性。
此外,扎克伯格、奥特曼和其他 AI 开发商的首席执行官也公开表示,他们尚未达到传统 scaling laws 的极限。因此,OpenAI 等公司仍在开发昂贵的、价值数十亿美元的数据中心,以尽可能多地提升预训练模型的性能。
然而,OpenAI 研究者 Noam Brown 上个月在 TEDAI 大会上表示,更先进的模型可能在经济上不可行。
「毕竟,我们真的要花费数千亿美元或数万亿美元训练模型吗?」 Brown 说。「在某个时候,scaling 范式会崩溃。」
OpenAI 尚未完成对 Orion 的安全性的漫长测试过程。其员工们表示,OpenAI 明年初发布 Orion 时,可能不再采用其旗舰模型的传统「GPT」命名惯例,进一步凸显 LLM 改进方式的变化。(OpenAI 发言人没有对此发表评论。)
撞上数据南墙
OpenAI 员工和研究者表示,GPT 速度放缓的原因之一是高质量文本和其他数据的供应量正在减少,而这些数据是 LLM 预训练所必需的。
他们表示,在过去几年中,LLM 使用来自网站、书籍和其他来源的公开文本和其他数据进行预训练,但模型开发者基本上已经从这类数据中榨干了尽可能多的资源。
作为回应,OpenAI 成立了一个基础团队,由之前负责预训练的 Nick Ryder 领导。他们表示,该团队将研究应对训练数据的匮乏,以及大模型的扩展定律将持续到什么时候。
据 OpenAI 的一名员工称,Orion 部分接受了 AI 生成的数据的训练,这些数据由其他 OpenAI 模型生成,包括 GPT-4 和最近发布的推理模型。然而,这位员工表示,这种合成数据导致了一个新问题,即 Orion 最终可能会在某些方面与那些旧模型相似。
风险投资人 Ben Horowitz 表示:「我们正在以同样的速度增加『用于训练 AI 的 GPU 数量』,但我们并没有从中获得任何智能改进。」
OpenAI 研究人员正在利用其他工具在训练后过程中改进 LLM,通过改进它们处理特定任务的方式。研究人员通过让模型从大量已被正确解决的问题(如数学或代码问题)中学习来实现这一目标,这一过程称为强化学习。
他们还要求人类评估人员在特定的代码或复杂问题任务上测试预训练模型,并对答案进行评分,这有助于研究人员调整模型以改进其对某些类型请求(例如写作或代码)的回答水平。这个过程称为带有人类反馈的强化学习(RLHF),也为较旧的人工智能模型提供了帮助。
为了处理这些评估,OpenAI 和其他人工智能开发人员通常依靠 Scale AI 和 Turing 等初创公司来管理数千名承包商。
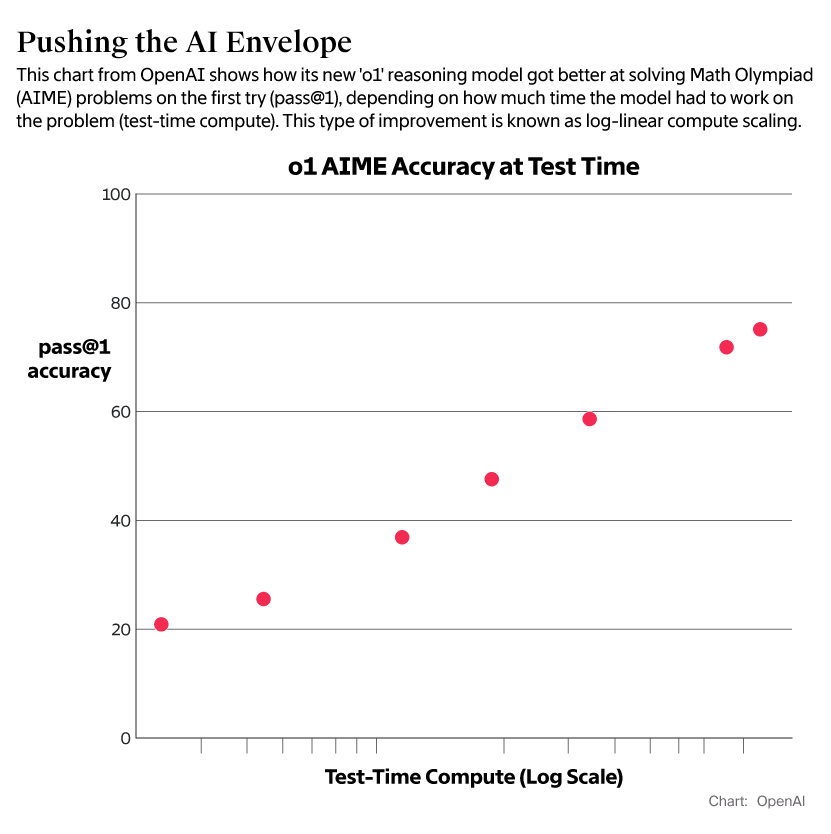
随着 OpenAI 技术的演进,研究人员继续开发出了名为 o1 的推理模型,该模型需要更多时间「思考」LLM 训练的数据,然后才能给出答案,这一概念称为测试时间计算。
这意味着,如果在模型回答用户问题时为其提供额外的计算资源,即使不更改底层模型,o1 的响应质量也可以继续提高。一位了解这一过程的人士表示,如果 OpenAI 能够不断提高底层模型的质量,即使速度较慢,也能产生更好的推理结果。
「这为大模型的扩展开辟了一个全新的维度,」Brown 在 TEDAI 会议上表示。研究人员可以通过将「每个查询花费一分钱提到每个查询花费一毛钱」来改善模型响应。
奥特曼也强调了 OpenAI 推理模型的重要性,它可以与 LLM 相结合。
「我希望推理能解锁很多我们等待多年的事情 —— 例如,像这样的模型能够为科学研究做出贡献,帮助编写更多非常困难的代码,」奥特曼在 10 月的一次应用开发者活动中说道。
在最近接受 Y Combinator 首席执行官 Garry Tan 采访时,奥特曼表示,「我们基本上知道该怎么做」才能实现通用人工智能,即与人类智力相当的技术 —— 其中的一部分涉及「以创造性的方式使用现有模型」。
数学家和其他科学家表示,o1 对他们的工作很有帮助,因为它可以充当可以提供反馈或想法的伙伴。但两位了解情况的员工表示,该模型目前的价格比非推理模型高出六倍,因此它还没有广泛的客户群。
「突破渐近线」
一些向人工智能开发者投入了数千万美元的投资者怀疑,大语言模型的进步速度是否开始趋于平稳。
Ben Horowitz 的风险投资公司已经投资了 OpenAI、Mistral 和 Safe Superintelligence 等公司,他在 YouTube 频道里表示:「我们正在以同样的速度增加『用于训练人工智能的 GPU』的数量,但我们根本没有从中获得智能改进。」
Horowitz 的同事 Marc Andreessen 在同一视频中则表示,「有很多聪明人正在努力突破渐近线,想办法达到更高水平的推理能力。」
企业软件公司 Databricks 的联合创始人兼主席联合开发者 Ion Stoica 表示,大模型的表现可能在某些方面已经停滞,但在其他方面仍在进步。
Stoica 表示,尽管大模型在代码和解决复杂、多步骤问题等任务方面不断改进,但其在执行通用任务(如分析一段文本的情感或描述医疗问题的症状)方面似乎进展缓慢。
「对于常识性问题,你可以说,目前我们看到 LLM 的表现停滞不前。我们需要 [更多] 事实数据,而合成数据没有太大帮助,」他说道。
你觉得 AI 发展的 scaling laws 速度放缓了吗?推理时间计算能否成为新的性能提升来源?请与我们分享你的观点。
参考链接:
https://www.theinformation.com/articles/openai-shifts-strategy-as-rate-of-gpt-ai-improvements-slows
https://www.youtube.com/watch?v=xXCBz_8hM9w
https://arxiv.org/abs/2211.04325
https://www.youtube.com/watch?v=hookUj3vkE4
相关文章:
OpenAI大改下代大模型方向,scaling law撞墙?AI社区炸锅了
有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。 来自论文《Will we run out of data? Limits of LLM scaling based on hum…...

技术整合与生态构建:Lyft与Mobileye引领自动驾驶新纪元
在科技日新月异的今天,自动驾驶技术正逐渐从科幻电影走进现实生活,成为出行服务领域的一股不可忽视的力量。近日,北美网约车巨头Lyft与自动驾驶技术领先者Mobileye宣布联手合作,共同推动自动驾驶汽车出行服务的广泛商业化进程。此…...

利用huffman树实现对文件A先编码后解码
利用huffman树实现对文件A先编码后解码,范围为ASCII码0-255的值,如何解决特殊符号问题是一个难点,注意应使用unsigned char存储数据,否则ASCII码128-255的值可能会出问题: #define _CRT_SECURE_NO_WARNINGS 1 #includ…...

第三十九章 基于VueCli自定义创建项目
目录 1. 选择创建模式 2. 选择需要的功能 3. 选择历史模式还是哈希模式 4.CSS预处理器 5. 选择ESLint规则 6. 开始创建项目 7. 自定义项目最终结构 1. 选择创建模式 输入创建的项目名,创建项目: 这里选择自定义模式: 2. 选择需要…...

网页web无插件播放器EasyPlayer.js点播播放器遇到视频地址播放不了的现象及措施
在数字媒体时代,视频点播已成为用户获取信息和娱乐的重要方式。EasyPlayer.js作为一款流行的点播播放器,以其强大的功能和易用性受到广泛欢迎。然而,在使用过程中,用户可能会遇到视频地址无法播放的问题,这不仅影响用户…...

LLaMA-Factory学习笔记(1)——采用LORA对大模型进行SFT并采用vLLM部署的全流程
该博客是我根据自己学习过程中的思考与总结来写作的,由于初次学习,可能会有错误或者不足的地方,望批评与指正。 1. 安装 1.1 LLaMA-Factory安装 安装可以参考官方 readme (https://github.com/hiyouga/LLaMA-Factory/blob/main/…...

PHP和Python脚本的性能监测方案
目录 1. 说明 2. PHP脚本性能监测方案 2.1 安装xdebug 2.2 配置xdebug.ini 2.3 命令行与VS Code中使用 - 命令行 - VS Code 2.4 QCacheGrind 浏览 3. Python脚本性能监测方案 3.1 命令行 4. 工具 5.参考 1. 说明 获取我们的脚本程序运行时的指标,对分析…...

C语言实现数据结构之堆
文章目录 堆一. 树概念及结构1. 树的概念2. 树的相关概念3. 树的表示4. 树在实际中的运用(表示文件系统的目录树结构) 二. 二叉树概念及结构1. 概念2. 特殊的二叉树3. 二叉树的性质4. 二叉树的存储结构 三. 二叉树的顺序结构及实现1. 二叉树的顺序结构2.…...

战略共赢 软硬兼备|云途半导体与知从科技达成战略合作
2024年11月5日,江苏云途半导体有限公司(以下简称“云途”或“云途半导体”)与上海知从科技有限公司(以下简称“知从科技”)达成战略合作,共同推动智能汽车领域高端汽车电子应用的开发。 云途半导体与知从科…...

python:用 sklearn 构建 K-Means 聚类模型
pip install scikit-learn 或者 直接用 Anaconda3 sklearn 提供了 preprocessing 数据预处理模块、cluster 聚类模型、manifold.TSNE 数据降维模块。 编写 test_sklearn_3.py 如下 # -*- coding: utf-8 -*- """ 使用 sklearn 构建 K-Means 聚类模型 "&…...
实现方案)
elementUI中2个日期组件实现开始时间、结束时间(禁用日期面板、控制开始时间不能超过结束时间的时分秒)实现方案
没有使用selectableRange 禁用时分秒,是因为他会禁止每天的时分秒。 我们需要解决的是当开始时间、结束时间是同一天时, 开始时间不能超过结束时间。 如果直接清空,用户体验不好。所以用watch监听赋值,当前操作谁,它不…...

Oracle 聚集因子factor clustering
文章目录 聚集因子(Factor clustering)举例说明查询聚集因子聚集因子的优化结论 最近发现突然忘记聚集因子的原理了,故整理记录一下 聚集因子(Factor clustering) 在Oracle中,聚集因子(Clustering Factor)用于衡量数据在表中存储…...

【大数据学习 | kafka高级部分】kafka的快速读写
1. 追加写 根据以上的部分我们发现存储的方式比较有规划是对于后续查询非常便捷的,但是这样存储是不是会更加消耗存储性能呢? 其实kafka的数据存储是追加形式的,也就是数据在存储到文件中的时候是以追加方式拼接到文件末尾的,这…...

云技术基础
学习视频笔记均来自B站UP主" 泷羽sec",如涉及侵权马上删除文章 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负 https://space.bilibili.com/350329294* 为什么要学云技术? 无论是防御还是…...
)
字节序(Byte Order)
这里写自定义目录标题 有两种主要的字节序:字节序与平台字节序转换 字节序(Byte Order)是指数据在内存中存储时字节的排列顺序。由于不同的计算机体系结构可能采用不同的字节序,因此理解字节序非常重要,特别是在处理多…...

融云:社交泛娱乐出海机会尚存,跨境电商异军突起
近年来,直播、语聊房、游戏社区,这些中国网友熟悉的网络社交形式,正在海外市场爆发出新的生命力。无论是被炒到几百人民币一个的 Clubhouse 邀请码,还是先后登顶中东下载榜的 Yalla、JACO,这些快速掀起体验浪潮的社交娱…...

django博客项目实现站内搜索功能
Django博客站内搜索功能实现 1. 准备工作 确保Django项目已经创建好,并且有一个用于存储博客文章的模型(例如Post)。 2. 定义搜索表单 在应用目录下创建一个forms.py文件,定义一个搜索表单。 from django import formsclass …...

蓝桥杯c++算法学习【1】之枚举与模拟(卡片、回文日期、赢球票、既约分数:::非常典型的比刷例题!!!)
别忘了请点个赞收藏关注支持一下博主喵!!! 关注博主,更多蓝桥杯nice题目静待更新:) 枚举与模拟 一、卡片: 【问题描述】 小蓝有很多数字卡片,每张卡片上都是一个数字(0到9)。 小蓝…...

Android 延时操作的常用方法
一、简介 在Android开发中我们可能会有延时执行某个操作的需求,例如我们启动应用的时候,一开始呈现的是引导页面,3秒后进入主界面,这就是一个延时操作。还有一种是执行某些接口任务时,需要有超时机制。下面介绍常用的…...
AI驱动的轻量级笔记应用Blinko
什么是 Blinko ? Blinko 是一个创新的开源项目,专为想要快速捕捉和整理瞬间想法的个人而设计。Blinko 允许用户在灵感迸发的瞬间无缝记录想法,确保不会错过任何创意火花。 Blinko 的设计初衷是让笔记记录变得更简单,让用户专注于内…...

AssetStudio深度原理与Unity资源逆向实战指南
1. 这不是“又一个Unity资源提取教程”,而是我三年里反复重装AssetStudio的总结AssetStudio、Unity资源提取、Unity游戏逆向、Unity AssetBundle解析——这几个词,几乎是我过去三年在独立游戏开发、MOD社区支持和老游戏存档修复工作中出现频率最高的关键…...

告别昂贵定位器!用Python和PyTorch复现DCL-Net,实现无传感器3D超声重建
告别昂贵定位器!用Python和PyTorch复现DCL-Net实现无传感器3D超声重建在医学影像领域,3D超声重建技术正逐步改变传统诊断方式。想象一下,医生只需手持普通超声探头自由扫描,AI系统就能自动将二维切片合成为三维立体图像——这正是…...

【企业级长文本AI落地红线】:金融/法律/医疗场景中超过64K tokens必踩的4类合规与事实性崩塌风险
更多请点击: https://intelliparadigm.com 第一章:【企业级长文本AI落地红线】:金融/法律/医疗场景中超过64K tokens必踩的4类合规与事实性崩塌风险 在金融、法律与医疗等强监管垂直领域,当AI系统处理超长文档(如IPO招…...

构建高效的 Agent 任务队列
构建高效Agent任务队列:从第一性原理到生产级落地全指南 关键词 Agent任务队列、多智能体调度、优先级抢占、延迟敏感任务、分布式一致性、负载均衡、容错机制 摘要 随着大模型驱动的多Agent系统在企业服务、具身智能、自动驾驶等领域的规模化落地,传统消息队列与批处理调…...

贝叶斯网络基本概念 CS188 Note12 学习笔记
更好的阅读体验 问题引入 在Note11中我们提及到了联合分布,我们先要想的就是一个问题:如果我们有n个变量,每个变量有d种取值,那联合概率表一共需要dnd^ndn行,这是一个非常庞大的数据量,这时候就引入了贝叶斯网络。贝…...

2026年横评10款降AI率软件:只选真正管用的那一款!
随着AI写作工具的广泛应用,论文写作和内容创作效率得到了显著提升,许多学生和职场人士都开始依赖这些工具来完成繁重的文字任务。然而,随着各大高校、期刊平台对AIGC内容检测技术的不断升级,AI生成内容的痕迹越来越容易被识别。不…...

2026照片去水印免费软件App推荐,详细教程一看就会
你是不是也遇到过这种情况?刷到一张特别喜欢的照片想保存当壁纸,结果右下角一个巨大的水印直接毁了整张图;或者做PPT需要用到某张素材图,翻遍了相册发现都有平台Logo,怎么裁都裁不掉。想找免费的去水印工具,…...

技术人的职业规划:打造成功的职业生涯
技术人的职业规划:打造成功的职业生涯 引言 作为一名技术人,职业规划是实现职业目标的关键。在快速变化的技术领域,一个清晰的职业规划可以帮助我们明确方向,抓住机会,实现个人价值。 回顾我的职业历程,从一…...

AI 时代产品经理生存与进化指南
AI 时代产品经理生存与进化指南 三重知识体系的交汇:NPDP产品开发 PMP项目管理 AI原生方法论 本文档整合了 NPDP(新产品开发专业人士认证)、PMP(项目管理专业人士认证)与 Anthropic 产品负责人 Catherine Wu…...

LinkSwift网盘直链下载助手:一站式解决9大网盘下载难题
LinkSwift网盘直链下载助手:一站式解决9大网盘下载难题 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...