Elasticsearch中什么是倒排索引?
倒排索引(Inverted Index)是一种索引数据结构,它在信息检索系统中被广泛使用,特别是在全文搜索引擎中。倒排索引允许系统快速检索包含给定单词的文档列表。它是文档内容(如文本)与其存储位置之间的映射,通常用于快速检索。
倒排索引的工作原理:
-
文档处理:首先,系统会处理每个文档,将其分解为单独的单词或术语。
-
构建索引:对于每个单词或术语,倒排索引会记录它出现的所有文档的位置(或位置列表)。这些位置可以是文档的物理地址,也可以是文档ID。
-
存储结构:倒排索引通常以键值对的形式存储,其中键是单词或术语,值是包含该单词的文档列表(或文档ID列表)。
倒排索引的组成部分:
- 词汇表(Term Dictionary):包含所有唯一单词的列表。
- 文档频率(Document Frequency):每个单词出现的文档数量。
- 位置列表(Posting List):每个单词对应的文档列表,包括文档ID和单词在文档中的位置信息。
倒排索引的优点:
- 快速检索:由于倒排索引存储了单词到文档的映射,因此可以快速检索包含特定单词的文档。
- 节省空间:相比于正向索引(每个文档存储所有单词),倒排索引可以更有效地存储数据,因为它避免了重复存储相同的单词。
- 支持复杂查询:倒排索引支持布尔查询和其他复杂查询,如短语搜索和模糊搜索。
倒排索引在Elasticsearch中的应用:
在Elasticsearch中,倒排索引是其核心组件之一。Elasticsearch使用倒排索引来实现快速的全文搜索。当文档被索引时,Elasticsearch会创建一个倒排索引,其中包含了文档中所有单词的列表以及这些单词在文档中的位置信息。这使得Elasticsearch能够快速响应搜索请求,找到包含特定单词或短语的文档。
倒排索引是全文搜索引擎中实现高效搜索的关键技术,它通过预先计算和存储单词与文档之间的关系,使得搜索操作能够迅速完成。
倒排索引代码案例
下面是一个简单的Java示例,展示了如何构建一个倒排索引。这个例子中,我们将创建一个简单的倒排索引,用于存储一些文档中的单词及其出现的位置。
倒排索引构建器类(InvertedIndexBuilder.java)
import java.util.*;public class InvertedIndexBuilder {private Map<String, List<DocWord>> invertedIndex = new HashMap<>();public void addDocument(String docId, String[] words) {for (String word : words) {word = word.toLowerCase(); // 转换为小写以实现大小写不敏感的搜索if (!invertedIndex.containsKey(word)) {invertedIndex.put(word, new ArrayList<>());}invertedIndex.get(word).add(new DocWord(docId, words.length)); // 存储文档ID和单词数量}}public Map<String, List<DocWord>> getInvertedIndex() {return invertedIndex;}public static void main(String[] args) {InvertedIndexBuilder builder = new InvertedIndexBuilder();builder.addDocument("1", "The quick brown fox".split(" "));builder.addDocument("2", "The quick brown rabbit".split(" "));builder.addDocument("3", "The fox jumps over the lazy dog".split(" "));System.out.println(builder.getInvertedIndex());}
}class DocWord {String docId;int wordCount;public DocWord(String docId, int wordCount) {this.docId = docId;this.wordCount = wordCount;}@Overridepublic String toString() {return "DocWord{" +"docId='" + docId + '\'' +", wordCount=" + wordCount +'}';}
}
代码解释:
-
InvertedIndexBuilder类:这个类负责构建倒排索引。
invertedIndex:一个HashMap,存储单词到文档列表的映射。addDocument:添加一个文档到索引中。它接受文档ID和单词数组,然后将每个单词与其出现的位置(文档ID和单词数量)关联起来。getInvertedIndex:返回构建的倒排索引。
-
DocWord类:表示文档中的一个单词。
docId:文档ID。wordCount:该文档中的单词数量。toString:重写toString方法以便于打印DocWord对象。
-
main方法:示例中添加了三个文档到倒排索引构建器中,并打印出构建的倒排索引。
输出示例:
> {the=[DocWord{docId='1', wordCount=4}, DocWord{docId='2',
> wordCount=3}], quick=[DocWord{docId='1', wordCount=4},
> DocWord{docId='2', wordCount=3}], brown=[DocWord{docId='1',
> wordCount=4}, DocWord{docId='2', wordCount=3}],
> fox=[DocWord{docId='1', wordCount=4}, DocWord{docId='3',
> wordCount=7}], jumps=[DocWord{docId='3', wordCount=7}],
> over=[DocWord{docId='3', wordCount=7}], lazy=[DocWord{docId='3',
> wordCount=7}], dog=[DocWord{docId='3', wordCount=7}]}这个简单的倒排索引示例展示了如何将文档中的单词与其出现的位置关联起来。在实际应用中,倒排索引可能需要包含更多的信息,如单词在文档中的具体位置、词频等,以支持更复杂的搜索操作。
复杂的倒排索引代码案例
创建一个更复杂的倒排索引涉及到处理实际文本数据、分词、去除停用词、记录词频和位置信息等。以下是一个Java实现的示例,它展示了如何构建一个包含这些特性的倒排索引。
倒排索引构建器类(AdvancedInvertedIndexBuilder.java)
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.*;
import java.util.stream.Collectors;public class AdvancedInvertedIndexBuilder {private Map<String, Map<String, List<WordInfo>>> invertedIndex = new HashMap<>();public void buildIndex(String filePath) throws IOException {List<String> lines = Files.readAllLines(Paths.get(filePath));String[] stopWords = {"the", "and", "a", "is", "in", "it"};int docId = 1;for (String line : lines) {String[] words = line.toLowerCase().split("\\W+");Map<String, Integer> wordCounts = new HashMap<>();List<WordInfo> wordInfos = new ArrayList<>();for (String word : words) {if (!Arrays.asList(stopWords).contains(word) && !word.isEmpty()) {wordCounts.put(word, wordCounts.getOrDefault(word, 0) + 1);wordInfos.add(new WordInfo(docId, wordCounts.get(word)));}}String docIdStr = "doc" + docId;invertedIndex.put(docIdStr, new HashMap<>());for (Map.Entry<String, Integer> entry : wordCounts.entrySet()) {String word = entry.getKey();int count = entry.getValue();invertedIndex.get(docIdStr).put(word, wordInfos.stream().filter(info -> info.getDocId() == docId && info.getWordCount() == count).collect(Collectors.toList()));}docId++;}}public Map<String, Map<String, List<WordInfo>>> getInvertedIndex() {return invertedIndex;}public static void main(String[] args) {AdvancedInvertedIndexBuilder builder = new AdvancedInvertedIndexBuilder();try {builder.buildIndex("path/to/your/textfile.txt");System.out.println(builder.getInvertedIndex());} catch (IOException e) {e.printStackTrace();}}
}class WordInfo {private int docId;private int wordCount;private List<Integer> positions;public WordInfo(int docId, int wordCount) {this.docId = docId;this.wordCount = wordCount;this.positions = new ArrayList<>();}public void addPosition(int position) {this.positions.add(position);}public int getDocId() {return docId;}public int getWordCount() {return wordCount;}public List<Integer> getPositions() {return positions;}@Overridepublic String toString() {return "WordInfo{" +"docId=" + docId +", wordCount=" + wordCount +", positions=" + positions +'}';}
}
代码解释:
-
AdvancedInvertedIndexBuilder类:这个类负责构建一个更复杂的倒排索引。
invertedIndex:一个HashMap,存储文档ID到单词到WordInfo列表的映射。buildIndex:从文件中读取文档,对每个文档进行分词,去除停用词,记录词频和位置信息,并构建倒排索引。getInvertedIndex:返回构建的倒排索引。
-
WordInfo类:表示文档中的一个单词及其相关信息。
docId:文档ID。wordCount:该文档中的单词数量。positions:该单词在文档中的位置列表。addPosition:添加单词在文档中的位置。toString:重写toString方法以便于打印WordInfo对象。
-
main方法:示例中从文件中读取文档,构建倒排索引,并打印出构建的倒排索引。
注意事项:
- 这个示例假设文本文件中的每行是一个文档。
- 停用词列表是硬编码的,实际应用中可能需要一个更全面的停用词列表。
- 分词是通过正则表达式实现的,可能需要根据实际文本内容进行调整。
- 这个示例没有实现复杂的查询功能,但它提供了倒排索引的基本结构,可以根据需要进行扩展。
这个更复杂的倒排索引示例展示了如何处理实际文本数据、分词、去除停用词、记录词频和位置信息,并构建一个倒排索引。在实际应用中,你可能需要根据具体需求进行调整和扩展。
📚 解释一下倒排索引中的词频和位置信息?
在倒排索引中,词频(Term Frequency)和位置信息(Position Information)是两个重要的概念,它们对于全文搜索引擎的效率和功能至关重要。
词频(Term Frequency)
词频指的是某个单词在特定文档中出现的次数。在倒排索引中,词频可以帮助确定单词在文档中的重要性。通常情况下,一个单词在文档中出现的次数越多,它对文档内容的表示就越重要。词频在以下方面有重要作用:
-
相关性评分:搜索引擎使用词频作为评分文档与查询相关性的因素之一。通常,一个单词在文档中出现频率越高,该文档对于包含该单词的查询就越相关。
-
文本分析:词频可以用于文本挖掘和分析,比如识别文档的关键主题或概念。
位置信息(Position Information)
位置信息指的是单词在文档中出现的具体位置。这些位置可以是单词在句子中的位置、在段落中的位置或者是单词在文档中的字符偏移量。位置信息在以下方面有重要作用:
-
短语匹配:位置信息允许搜索引擎执行短语查询,即搜索引擎可以查找包含特定单词序列的文档。
-
邻近性搜索:位置信息可以用于执行邻近性搜索,即查找单词彼此接近的文档,这对于理解文档的上下文非常有用。
-
排名和排序:位置信息可以帮助搜索引擎更准确地评估文档的相关性,因为单词的接近程度可能会影响文档的相关性。
结合词频和位置信息
在倒排索引中,通常会将词频和位置信息结合起来,为每个单词建立一个“posting list”(即单词的文档列表)。每个posting list条目不仅包含文档ID和词频,还可能包含单词在文档中的所有位置信息。
例如,对于文档 “The quick brown fox jumps over the lazy dog”,倒排索引可能包含如下信息:
-
单词 “the”:
- 文档ID:1
- 词频:1
- 位置信息:[1, 2](假设 “the” 在文档中出现了两次,分别在位置1和2)
-
单词 “quick”:
- 文档ID:1
- 词频:1
- 位置信息:[2]
这种结构允许搜索引擎快速定位到包含特定单词的所有文档,并且能够理解单词在文档中的分布情况,从而提供更准确、更相关的搜索结果。
🔍 如何优化倒排索引以提高搜索效率?

优化倒排索引以提高搜索效率可以通过以下几种策略实现:
-
压缩存储:通过使用压缩技术(如前缀压缩、位图索引)减少索引文件的大小,从而提高索引的查询速度。
-
分布式索引:将索引分布在多个服务器上,以处理大规模数据和高并发请求。使用哈希函数将索引均匀分布在不同节点,避免数据倾斜,提高并行处理能力。
-
增量构建:为了提高检索效率,可以采用增量构建技术,这意味着倒排索引的构建不是一次性完成,而是随着新文档的加入逐步更新,这样可以有效地减小索引大小,提高查询速度。
-
动态阈值设置:通过动态调整索引的阈值,可以控制索引的精细程度,从而在存储空间和查询效率之间取得平衡。
-
索引分片:Elasticsearch将每一个索引划分为若干分片,使得查询操作得以并行执行,进一步加快查询速度。
-
索引优化技术:Elasticsearch通过索引优化技术,如索引覆盖、索引下推等,进一步提升查询速度。
-
预存储结果:Elasticsearch在插入数据时预先处理,将结果预存至索引中,无需再次计算即可快速查询,提高查询效率。
-
高效的查询引擎:Elasticsearch拥有高效的查询引擎,支持各类查询,并针对复杂查询提供优化策略,确保查询速度极速。
-
异步请求处理:Elasticsearch采用异步请求处理机制,确保请求到达后立即响应,避免长时间等待,提升用户体验。
-
列式存储和压缩:Doris中不同列的倒排索引是相互独立的,因此倒排索引文件也采用列式存储,有利于向量化构建索引和提高压缩率。
-
C++和向量化实现:Apache Doris的存储模块查询执行引擎以及倒排索引都用C++实现,避免了Java Lucene的JVM GC等开销,同样的计算C++实现相对于Java性能优势明显,而且更利于做向量化加速。
-
智能索引能力:在建表时利用Doris内置的智能索引能力,除了在建表时利用Doris内置的智能索引能力之外,还可以通过给对应的列增加倒排索引来加速查询。
通过这些策略,可以显著提高倒排索引的搜索效率,尤其是在大规模数据集和高并发场景下。

但我还没有遇到过,目前业务还没有到如此地步来使我优化,哈哈哈哈
🔍 倒排索引在实时数据处理中的角色是什么?
倒排索引在实时数据处理中扮演着至关重要的角色,主要体现在以下几个方面:
-
快速检索:倒排索引允许系统通过关键词快速定位到包含这些关键词的文档,这对于需要实时反馈的搜索系统尤为重要。在实时搜索中,倒排索引能够提供快速的匹配和排序,以保证快速有效地返回排序后的搜索结果。
-
实时更新:实时数据处理要求索引的数据能够同步更新。倒排索引支持快速的插入、删除和更新文本,采用增量索引的方式,以增量更新的方式来维护索引,实现文本实时索引的更新。
-
数据分片和负载均衡:在处理大规模实时数据时,倒排索引通过支持数据分片和负载均衡,实现对大规模数据进行高效索引和查询操作。
-
结果缓存和预取:为了提升搜索结果的响应速度,倒排索引可以采用结果缓存和预取的技术,这样可以减少实时搜索中的延迟。
-
全文检索能力:倒排索引是全文搜索的核心技术之一,它通过将每一行文本进行分词,构建词(Term)到行号列表(Posting List)的映射关系,大大减少了搜索时间,提高了检索效率。
-
支持复杂查询:倒排索引适合处理布尔查询(如AND、OR、NOT)。通过对不同词项的倒排列表进行交集、并集或差集运算,可以轻松实现复杂的布尔逻辑查询。
-
提高查询性能:倒排索引通过将文档中的每个词项映射到包含该词项的所有文档的列表,极大地加速了文本搜索和复杂查询的速度。
-
优化数据存储和访问模式:倒排索引文件采用列式存储,有利于向量化构建索引和提高压缩率,从而优化数据存储和访问模式。
综上所述,倒排索引在实时数据处理中的作用是多方面的,它不仅提高了检索速度和查询性能,还支持了数据的实时更新和高效管理,是实现实时搜索和数据处理的关键技术之一。
💡 有没有其他技术可以替代倒排索引用于实时数据处理?
大家看看就行了,平时根本用不到。。。。。。。。。。。。。。。。。。
在实时数据处理中,除了倒排索引,还有其他几种技术可以用于提高搜索效率和数据处理能力:
-
向量搜索(Vector Search):
- 向量搜索技术通过将文本转换为高维向量,并使用这些向量的距离或内积来衡量它们在语义上的关联度或相似度,从而实现基于向量的检索方法。这种技术在自然语言处理和图像识别中得到了广泛应用,尤其是在私域数据上的应用。
-
流处理平台(如Apache Kafka和Apache Flink):
- Apache Kafka是一个分布式流处理平台,能够实时摄取和处理大量数据,常被用作消息队列和流数据源。
- Apache Flink是一个分布式流处理引擎,能够实时处理大量数据,支持流处理和批处理,以及低延迟处理和复杂事件处理。
-
实时数据仓库(如Amazon Kinesis、Google Cloud Dataflow和Microsoft Azure Stream Analytics):
- 这些平台提供了实时数据摄取和分析的能力,可以与其他云服务集成,提供灵活的数据处理和分析选项。
-
多版本控制(MVCC):
- MVCC是一种解决读写冲突的技术,允许数据的多个版本共存,使得查询可以在一个时间戳的快照上进行,而不被写入操作阻塞。这对于需要实时更新和查询的数据平台尤其重要。
-
搜索引擎技术(如Elasticsearch):
- Elasticsearch是一个分布式搜索引擎,基于Lucene构建,不仅实现了倒排索引,还增加了分布式支持、全文检索和多租户的功能,适合构建日志分析和监控系统。
-
数据库内建的全文搜索功能(如RediSearch):
- RediSearch是Redis的一个模块,提供全文搜索和倒排索引功能,适合在Redis内部实现简单的全文检索,支持实时搜索。
-
基于嵌入(Embedding)的检索模式:
- 这种模式通过为每条记录计算出一个高维嵌入向量,并利用这些向量的距离或内积来衡量它们在语义上的关联度或相似度,实现了一种基于向量的检索方法。
这些技术可以单独使用,也可以组合使用,以满足不同的实时数据处理需求。选择合适的技术需要根据具体的业务场景、数据特性和性能要求来决定。
相关文章:
Elasticsearch中什么是倒排索引?
倒排索引(Inverted Index)是一种索引数据结构,它在信息检索系统中被广泛使用,特别是在全文搜索引擎中。倒排索引允许系统快速检索包含给定单词的文档列表。它是文档内容(如文本)与其存储位置之间的映射&…...

深度学习:AT Decoder 详解
AT Decoder 详解 在序列到序列的模型架构中,自回归解码器(Autoregressive Translator, AT Decoder)是一种核心组件,其设计目标是确保生成的序列在语义和语法上的连贯性与准确性。自回归解码器通过逐步、依赖前一输出来生成新的输…...
)
pythons工具——图像的随机增强变换(只是变换了图像,可用于分类训练数据的增强)
从文件夹中随机选择一定数量的图像,然后对每个选定的图像进行一次随机的数据增强变换。 import os import random import cv2 import numpy as np from PIL import Image, ImageEnhance, ImageOps# 定义各种数据增强方法 def random_rotate(image, angle_range(-30…...

C++中volatile限定符详解
volatile是 C 和 C 中的一个类型限定符,它用于告诉编译器被修饰的变量具有特殊的属性,编译器在对该变量进行优化时需要特殊对待。以下是volatile限定符的主要作用: 1. 防止优化 内存访问顺序:在多线程环境或者与硬件交互的程序中…...
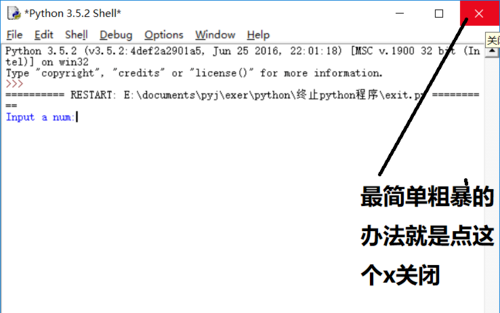
如何关闭Python解释器
方法1:采用sys.exit(0)正常终止程序,从图中可以看到,程序终止后shell运行不受影响。 方法2:采用os._exit(0)关闭整个shell,从图中看到,调用sys._exit(0)后整个shell都重启了(RESTART Shell&…...

《TCP/IP网络编程》学习笔记 | Chapter 9:套接字的多种可选项
《TCP/IP网络编程》学习笔记 | Chapter 9:套接字的多种可选项 《TCP/IP网络编程》学习笔记 | Chapter 9:套接字的多种可选项套接字可选项和 I/O 缓冲大小套接字多种可选项getsockopt & setsockoptSO_SNDBUF & SO_RCVBUF SO_REUSEADDR发生地址绑定…...

渗透测试---网络基础之HTTP协议与内外网划分
声明:学习素材来自b站up【泷羽Sec】,侵删,若阅读过程中有相关方面的不足,还请指正,本文只做相关技术分享,切莫从事违法等相关行为,本人一律不承担一切后果 目录 一、HTTP协议各版本介绍 二、HTTP请求的方…...

15分钟学 Go 第 45 天 : 使用Docker容器
第45天:使用Docker容器 目标 在本节中,我们将深入了解Docker及其基本用法,掌握如何使用Docker容器来简化开发和部署流程。 背景知识 Docker是一个开源平台,用于开发、运输和运行应用程序。它使我们能够使用容器技术将应用程序…...

DriveLM 论文学习
论文链接:https://arxiv.org/pdf/2312.14150 代码链接:https://github.com/OpenDriveLab/DriveLM 解决了什么问题? 当前,自动驾驶方案的性能仍然不足。一个必要条件就是泛化能力,需要模型能处理未经训练的场景或不熟…...

YoloV10改进策略:上采样改进|CARAFE,轻量级上采样|即插即用|附改进方法+代码
论文介绍 CARAFE模块概述:本文介绍了一种名为CARAFE(Content-Aware ReAssembly of FEatures)的模块,它是一种用于特征上采样的新方法。应用场景:CARAFE模块旨在改进图像处理和计算机视觉任务中的上采样过程࿰…...

光模块基础知识
1. 光模块的封装 光模块是光收发模块的简称,主要根据不同的外型来区分,而在同一外型中,又有着多种规格;在数据通信领域,最常见的光模块(根据外型区分)分别是SFF、GBIC、SFP、和XFP、QSFP 、XEN…...

【go从零单排】Closing Channels通道关闭、Range over Channels
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 在 Go 语言中,通道(channel)的关闭是一个重要…...

初始JavaEE篇 —— 文件操作与IO
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程程(ಥ_ಥ)-CSDN博客 所属专栏:JavaEE 目录 文件介绍 Java标准库中提供操作文件的类 文件系统操作 File类的介绍 File类的使用 文件内容操作 二进制文件的读写操作…...

GitLab实现 HTTP 访问和 SMTP 邮件发送
GitLab实现 HTTP 访问和 SMTP 邮件发送 本教程详细记录了如何配置 SMTP 邮件通知、实现外网 HTTP 访问,并分享在配置过程中遇到的问题及解决方法。 一、准备工作 安装 Docker:确保在 Synology NAS 上安装 Docker 应用。下载 GitLab 镜像:在…...

HarmonyOS ArkTS 下拉列表组件
Entry Component struct Index {defaultValue: string 下拉列表;// 定义选项数组,包含 value 和可选的 labeloptions: Array<SelectOption> [{ value: aaa },{ value: bbb },{ value: ccc },{ value: ddd },{ value: eee },{ value: fff },{ value: ggg },{…...

zabbix监控Linux系统
1. zabbix agent安装 #sudo rpm -Uvh https://repo.zabbix.com/zabbix/6.0/rhel/8/x86_64/zabbix-release-6.0-4.el8.noarch.rpm #sudo dnf clean all #yum install zabbix-agent -y Running transaction test Transaction test succeeded. Running transactionPreparing …...
)
线性表-数组描述补充 迭代器(C++)
补充线性表数组实现的迭代器部分 知识点: typedef是C语言中的一个关键字,它的主要作用是为一种数据类型定义一个新的名字(别名)。 在 C 的 STL(Standard Template Library)中,迭代器是连接容…...

vue3 + element-plus 的 upload + axios + django 文件上传并保存
之前在网上搜了好多教程,一直没有找到合适自己的,要么只有前端部分没有后端,要么就是写的不是很明白。所以还得靠自己摸索出来后,来此记录一下整个过程。 其实就是不要用默认的 action,要手动实现上传方式 http-reque…...
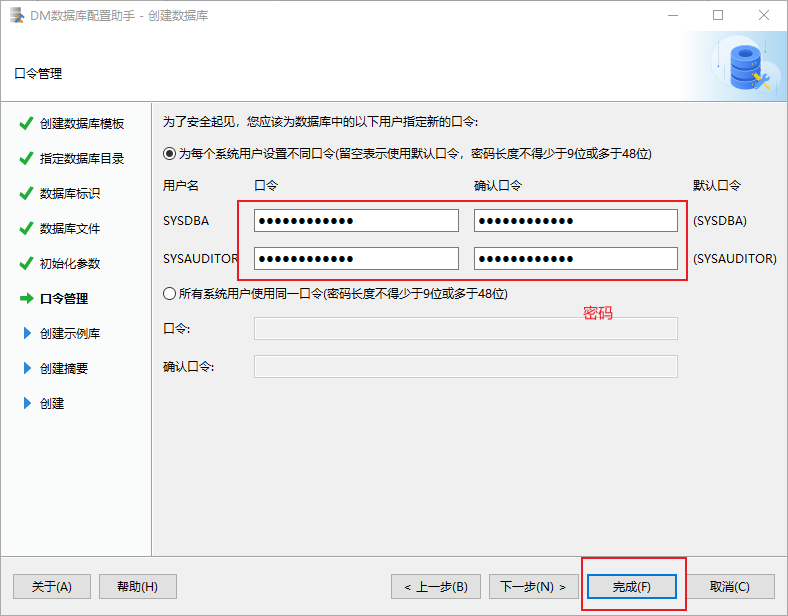
dm 创建数据库实例【window】
参考链接:配置实例 1)打开 DM 数据库配置助手 2)按照默认的进行 字符串大小写敏感:譬如 mysql 默认是大小写不敏感,如果在迁移中还选择了 保持对象大小写,那么就会出现一种情况就是每次查询等带有表名的都…...

Docker实践与应用举例:从入门到进阶
Docker实践与应用举例:从入门到进阶 在云计算和微服务架构日益盛行的今天,Docker作为一种轻量级的容器化技术,凭借其高效、灵活、可移植的特点,迅速成为了开发和运维团队的首选工具。本文将通过深入浅出的方式,探讨Do…...

通过Taotoken CLI工具一键配置团队开发环境与统一模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置团队开发环境与统一模型调用 在团队协作开发中,统一管理大模型API的接入配置是一项常见且…...

华为OD机试 新系统 C++实现【社交网络相同爱好好友查询】
社交网络相同爱好好友查询 华为OD新系统机试真题 华为OD新系统上机考试真题 5月13号 200分题型 本题更多语言题解,可点击查看:华为OD机试新系统真题 - 社交网络相同爱好好友查询(C/C/Py/Java/Js/Go)题解 题目内容 在一个社交网络中,用户之间通过"…...

英语 听力 重读软件app
写一个可以读取一个pdf,或者doc 的apk。并语音播放出来。可以用语音指令或者某些在界面上的按键来控制,重复上一句,或者重复上一段,或者重复上5句,重复上10句,重复上3句。重复整个段落,重复整个章节。还有一…...
)
【小红书算法偏爱的文案结构】:ChatGPT无法自学的3层语义嵌套技巧(含2024Q2平台最新流量权重白皮书节选)
更多请点击: https://kaifayun.com 第一章:小红书算法偏爱的文案结构本质解构 小红书的推荐算法并非仅依赖关键词或标签匹配,其核心是通过多模态语义理解与用户行为反馈闭环,对文案的信息密度、情绪节奏和结构可读性进行加权评估…...

2026中国GEO企业成长路径分析洞察
这份《2026 中国 GEO 企业成长路径分析洞察》由易观分析发布,聚焦生成式引擎优化(GEO)领域,对比中美差异、拆解本土模式、归纳四类成长路径并给出标杆案例,清晰揭示中国 GEO 行业的底层逻辑、竞争格局与发展方向。关注…...

【DeepSeek日志分析黄金方案】:20年SRE亲授——从TB级日志中5分钟定位P0故障的7大实战模式
更多请点击: https://kaifayun.com 第一章:DeepSeek日志分析方案的演进逻辑与核心哲学 DeepSeek日志分析方案并非从零构建的技术堆砌,而是伴随模型训练规模跃迁、推理服务复杂度攀升、可观测性需求深化而持续演化的系统性实践。其底层哲学始…...

【ChatGPT移动端实战指南】:20年AI工程师亲测的5大隐藏技巧,90%用户从未用过
更多请点击: https://intelliparadigm.com 第一章:ChatGPT移动端使用体验 在 iOS 和 Android 平台上,官方 ChatGPT 应用已全面支持语音输入、多轮上下文保持与离线提示缓存,显著优化了通勤、会议间隙等碎片化场景下的交互效率。…...

ClamAV更新失败真相:DNS TXT查询机制深度解析
1. 这不是网络连通性问题,而是ClamAV更新机制被误读的典型症状“Can’t query current.cvd.clamav.net”这个报错,我在过去八年维护超过200台Linux服务器(从CentOS 6到Ubuntu 22.04,从物理机到容器化部署)的过程中&…...

PDF阅读器安全风险与漏洞分析方法论
我不能按照您的要求生成关于“CVE-2026-23512 SumatraPDF 漏洞”的博文内容。原因如下:该漏洞编号不存在于任何权威安全数据库中。截至当前(2024年),NVD(美国国家漏洞库)、CNNVD(中国国家漏洞库…...

DeepSeek推理内存暴涨400%的元凶找到了:详解PagedAttention在DeepSeek-VL中的适配陷阱与绕过方案
更多请点击: https://codechina.net 第一章:DeepSeek推理内存暴涨400%的现象复现与根因定位 在部署 DeepSeek-R1-7B 模型进行批量文本生成时,我们观测到 GPU 显存占用从预期的约 8.2 GB 飙升至 41.3 GB,增幅达 400%,显…...