linux安装zookeeper和kafka集群
linux安装zookeeper和kafka集群
- 一、Zookeeper集群部署
- 安装zookeeper
- 1. 下载
- 2. 上传, 解压
- 3. 配置 Zookeeper 节点
- 4. 创建 myid 文件
- 5. 启动参数更改
- 6. sh文件授权
- 7. 启动集群
- 8. 防火墙开启端口
- 验证集群
- 二、kafka集群安装
- 安装Kafka
- 1. 下载Kafka安装包
- 2. 上传到服务器,并解压到指定目录。
- 3. 创建目录用于存放数据
- 4. 修改配置文件
- 5. 启动参数更改
- 6. sh文件授权
- 7. 启动集群
- 8. 防火墙开启端口
- 9. 创建主题
- 10. 验证主题配置
- 11. 查看主题列表
- 12. 删除指定主题
- 安装kafka可视化管理工具(可选)
- 1. 上传,并解压。
- 2. 修改配置文件
- 3. 启动kafka-ui-lite
- 4.日志输出
- 5. 防火墙开启端口
- 测试
- 1. 进入kafka管理页面
- 2. 添加配置
- 3. 生产、消费消息
- 4. 模拟节点宕机
一、Zookeeper集群部署
安装zookeeper
1. 下载
- 检查jdk版本, Zookeeper 依赖于 Java8 以上环境
java -version
- 下载zk, 我这里下载的是3.6.4
https://archive.apache.org/dist/zookeeper/
2. 上传, 解压
tar -zxvf apache-zookeeper-3.6.4-bin.tar.gz -C /opt/app/apache-zookeeper-3.6.4
3. 配置 Zookeeper 节点
- 复制zoo_sample.cfg为zoo.cfg, 然后编辑
# tickTime 是一个核心配置参数,定义了 Zookeeper 的基本时间单位。
# 它用于控制和影响其他一些时间相关的配置,例如会话超时、Leader 与 Follower 之间的心跳检测等。
tickTime=2000# initLimit 指定了 Follower 从服务器在启动时与 Leader 服务器进行数据同步的最大时间。
# 如果从服务器在规定的 initLimit 时间内未完成与 Leader 的同步,则 Zookeeper 会认为该从服务器无法正常加入集群。
# 如果 tickTime=2000 毫秒(2 秒),那么 initLimit=10 就表示允许的初始化同步时间为 10 * 2000 = 20000 毫秒(即 20 秒)。
initLimit=10# syncLimit 指定了 Leader 和 Follower 之间心跳消息的超时时间。
# 如果一个 Follower 在规定的 syncLimit 时间内无法收到 Leader 的消息,
# Zookeeper 会认为该 Follower 已失效并从集群中剔除。
syncLimit=5# 在 Zookeeper 中,快照是指当前节点数据的备份。
# Zookeeper 会定期将内存中的数据状态保存为一个快照文件,存储在指定的目录中,
# 以便在服务器重启或崩溃时可以从快照恢复数据。
dataDir=/opt/app/apache-zookeeper-3.6.4/data# 客户端连接的地址
clientPort=8111# 每个客户端(根据客户端的 IP 地址区分)对单个 Zookeeper 服务器的最大连接数。
maxClientCnxns=60# 用于自动清理旧数据的配置参数。它控制 Zookeeper 定期清理旧的快照(snapshot)文件和事务日志的频率
# 默认情况下,autopurge.purgeInterval 为 0,表示不启用自动清理功能。在这里先用默认的。
autopurge.purgeInterval=0# 集群节点信息
# 8112 端口:用于 Follower 和 Leader 之间的通信。
# 8113 端口:用于 Leader 选举。
server.1=192.168.0.170:8112:8113
server.2=192.168.0.171:8112:8113
server.3=192.168.0.149:8112:8113# 监控工具
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
4. 创建 myid 文件
- 在每台机器上的zookeeper数据目录下创建myid, 然后执行以下命令
echo "1" > /opt/app/apache-zookeeper-3.6.4/data/myid # 在 192.168.0.170 机器上, 和zoo.cfg中的server.1对应
echo "2" > /opt/app/apache-zookeeper-3.6.4/data/myid # 在 192.168.0.171 机器上, 和zoo.cfg中的server.2对应
echo "3" > /opt/app/apache-zookeeper-3.6.4/data/myid # 在 192.168.0.149 机器上, 和zoo.cfg中的server.3对应
5. 启动参数更改
- 进入bin目录, 更改zkEnv.sh中的启动参数
vim /opt/app/apache-zookeeper-3.6.4/bin/zkEnv.sh
- 更改SERVER_JVMFLAGS, 设置jvm初始化内存与最大堆内存
export SERVER_JVMFLAGS="-Xms4g -Xmx4g"
6. sh文件授权
- 进入bin目录
cd /opt/app/apache-zookeeper-3.6.4/bin
- 授予.sh执行权限
chmod 755 *.sh
7. 启动集群
- 在每台机器上启动zk
/opt/app/apache-zookeeper-3.6.4/bin/zkServer.sh start
- 然后检查每台机器zk状态
/opt/app/apache-zookeeper-3.6.4/bin/zkServer.sh status
- 停止命令如下
/opt/app/apache-zookeeper-3.6.4/bin/zkServer.sh stop
8. 防火墙开启端口
- 开启端口
firewall-cmd --add-port=8111/tcp --permanent
firewall-cmd --add-port=8112/tcp --permanent
firewall-cmd --add-port=8113/tcp --permanent
- 重启防火墙
firewall-cmd --reload
验证集群
- 使用 Zookeeper 客户端连接
/opt/app/apache-zookeeper-3.6.4/bin/zkCli.sh -server ip:port
二、kafka集群安装
安装Kafka
1. 下载Kafka安装包
下载地址:https://kafka.apache.org/downloads
如果只是使用的话,下载二进制文件就行,不用选择source,在这里我选择下载kafka_2.13-3.5.2.tgz,scala版本为2.13,kafka版本为3.5.2。
2. 上传到服务器,并解压到指定目录。
tar -zxvf kafka_2.13-3.5.2.tgz -C /opt/app/kafka_2.13-3.5.2
3. 创建目录用于存放数据
mkdir -p /opt/app/kafka_2.13-3.5.2/data
4. 修改配置文件
修改kafka的配置文件,修改如下:
vim /opt/app/kafka_2.13-3.5.2/config/server.properties
############################# Server Basics ############################## 节点id, 集群中每个节点的唯一标识, 每台机器不能重复192.168.0.170为1,192.168.0.171为2,192.168.0.149为2
broker.id=1############################# Socket Server Settings #############################
# 设置 Kafka 监听的地址和端口, 需要对应机器的ip, 端口自定义
listeners=PLAINTEXT://192.168.0.170:8114# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=/opt/app/kafka_2.13-3.5.2/data# 分区数为 3,Kafka 会将主题数据分成 3 个分区,这可以提高并行消费的能力。
num.partitions=3# 当 Kafka 启动或发生崩溃时,它会执行数据恢复操作,以确保日志文件的一致性并重建索引文件。指定了每个数据目录中用于恢复的线程数。
num.recovery.threads.per.data.dir=2############################# Internal Topic Settings #############################
# 用于配置存储消费者偏移量(offsets)的内部主题 (__consumer_offsets 主题) 的副本数的参数。
offsets.topic.replication.factor=3
# Kafka 中的事务功能依赖于事务日志来记录所有的事务状态信息,这些信息用于确保事务的一致性和可靠性。
# 用于指定事务状态日志的副本数,也就是该日志在 Kafka 集群中的副本数。
transaction.state.log.replication.factor=3
# 如果 Kafka 集群有 3 个节点,建议将 transaction.state.log.min.isr 设置为 2。
# 这意味着事务状态日志需要至少 2 个副本是同步的才能继续写入事务。
# 这样可以保证即使一个副本不可用或出现故障,仍然有足够的副本来确保事务日志的一致性和容错性。
transaction.state.log.min.isr=2############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age#log.retention.ms=10000 # 当我们同时设置了保留时间和保留大小时,kafka满足其中任意一个条件时,就会删除日志段。
# 日志保留时间 72h
log.retention.hours=72
# 日志保留大小20GB
log.retention.bytes=21474836480
# 每个日志段大小1G
log.segment.bytes=1073741824
# 每5分钟扫描一次
log.retention.check.interval.ms=300000############################# Zookeeper ############################## 设置zk集群
zookeeper.connect=192.168.0.170:8111,192.168.0.171:8111,192.168.0.149:8111# zk连接超时时间
zookeeper.connection.timeout.ms=18000############################# Group Coordinator Settings ############################## The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0## 分区副本的最小同步数,通常配置为集群节点数减一
## 如果 replication.factor=3 且 min.insync.replicas=2,生产者在 acks=all 时,只有当至少 2 个副本完成了同步,写操作才会被确认。
min.insync.replicas=2
# 它定义了每个分区的数据在 Kafka 集群中有多少个副本,以提高数据的可靠性和容错性。
# 如果一个分区的某个副本所在的节点宕机,Kafka 可以从其他副本继续读取数据,确保数据可用性。
# 如果 default.replication.factor=3,那么每个新建主题的分区会默认有 3 个副本。
default.replication.factor=3# 允许删除主题
delete.topic.enable=true5. 启动参数更改
编辑启动文件
vim /opt/app/kafka_2.13-3.5.2/bin/kafka-server-start.sh
找到参数KAFKA_HEAP_OPTS设置的地方, 修改为如下
export KAFKA_HEAP_OPTS="-Xmx4G -Xms4G"
6. sh文件授权
- 进入bin目录
cd /opt/app/kafka_2.13-3.5.2/bin/
- 授予.sh执行权限
chmod 755 *.sh
7. 启动集群
- 在每台机器上启动kafka
/opt/app/kafka_2.13-3.5.2/bin/kafka-server-start.sh -daemon /opt/app/kafka_2.13-3.5.2/config/server.properties
- 查看启动状态
ps -ef|grep kafka.Kafka
- 停止命令如下
/opt/app/kafka_2.13-3.5.2/bin/kafka-server-stop.sh
8. 防火墙开启端口
firewall-cmd --add-port=8114/tcp --permanent;
firewall-cmd --reload
9. 创建主题
因为我们已经在配置文件中指定num.partitions=3和default.replication.factor=3,所以就不用在创建主题的时候指定分区数和副本数了
/opt/app/kafka_2.13-3.5.2/bin/kafka-topics.sh --create --topic my-topic --bootstrap-server 192.168.0.170:8114
10. 验证主题配置
创建成功后,可以使用 --describe 命令查看主题的配置信息:
/opt/app/kafka_2.13-3.5.2/bin/kafka-topics.sh --describe --topic my-topic --bootstrap-server 192.168.0.170:8114
主要检查分区数量(PartitionCount)和副本数量(ReplicationFactor)
Topic: my-topic TopicId: 6941T0WBTpS9UaXJT-ytYw PartitionCount: 3 ReplicationFactor: 3 Configs: min.insync.replicas=2,segment.bytes=1073741824,retention.bytes=21474836480Topic: my-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2Topic: my-topic Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3Topic: my-topic Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
11. 查看主题列表
/opt/app/kafka_2.13-3.5.2/bin/kafka-topics.sh --bootstrap-server 192.168.0.170:8114 --list
12. 删除指定主题
/opt/app/kafka_2.13-3.5.2/bin/kafka-topics.sh --bootstrap-server 192.168.0.170:8114 --delete --topic topic-name
安装kafka可视化管理工具(可选)
在这里我选择kafkaUI-lite,下载下方的二进制安装包就行
https://gitee.com/freakchicken/kafka-ui-lite/releases/tag/v1.2.11
1. 上传,并解压。
tar -zxvf kafka-ui-lite-1.2.11.tar.gz -C /opt/app/kafka-ui-lite-1.2.11
2. 修改配置文件
如果想修改元数据库为mysql, 修改conf/application.properties中的以下配置
在这里我们直接使用linux自带的sqlite数据库
server.port=19092
spring.datasource.driver-class-name=org.sqlite.JDBC
spring.datasource.url=jdbc:sqlite::resource:data.db
spring.datasource.username=
spring.datasource.password=
查看系统有无sqlite
rpm -qa | grep sqlite
有sqlite就会有如下输出
sqlite-3.7.17-8.el7_7.1.x86_64
如果使用mysql数据库就需要执行sql目录下的sql脚本
[root@localhost sql]# pwd
/opt/app/kafka-ui-lite-1.2.11/sql
[root@localhost sql]# ll
总用量 8
-rw-r--r--. 1 root root 1540 4月 13 2021 ddl_mysql.sql
-rw-r--r--. 1 root root 1077 4月 13 2021 ddl_sqlite.sql
3. 启动kafka-ui-lite
进入到安装目录下,执行如下命令
# 前台启动
sh bin/kafkaUI.sh start
# 后台启动
sh bin/kafkaUI.sh -d start
# 关闭后台启动的进程
sh bin/kafkaUI.sh stop
4.日志输出
/opt/app/kafka-ui-lite-1.2.11/logs
5. 防火墙开启端口
# 开启kafka-ui-lite可视化管理工具端口
firewall-cmd --zone=public --add-port=19092/tcp --permanent
# 重新加载防火墙
firewall-cmd --reload
测试
1. 进入kafka管理页面
访问地址:http://192.168.1.100:19092
尽量不要使用此客户端创建主题, 我试了一下, 创建的主题无法正常生产消费消息
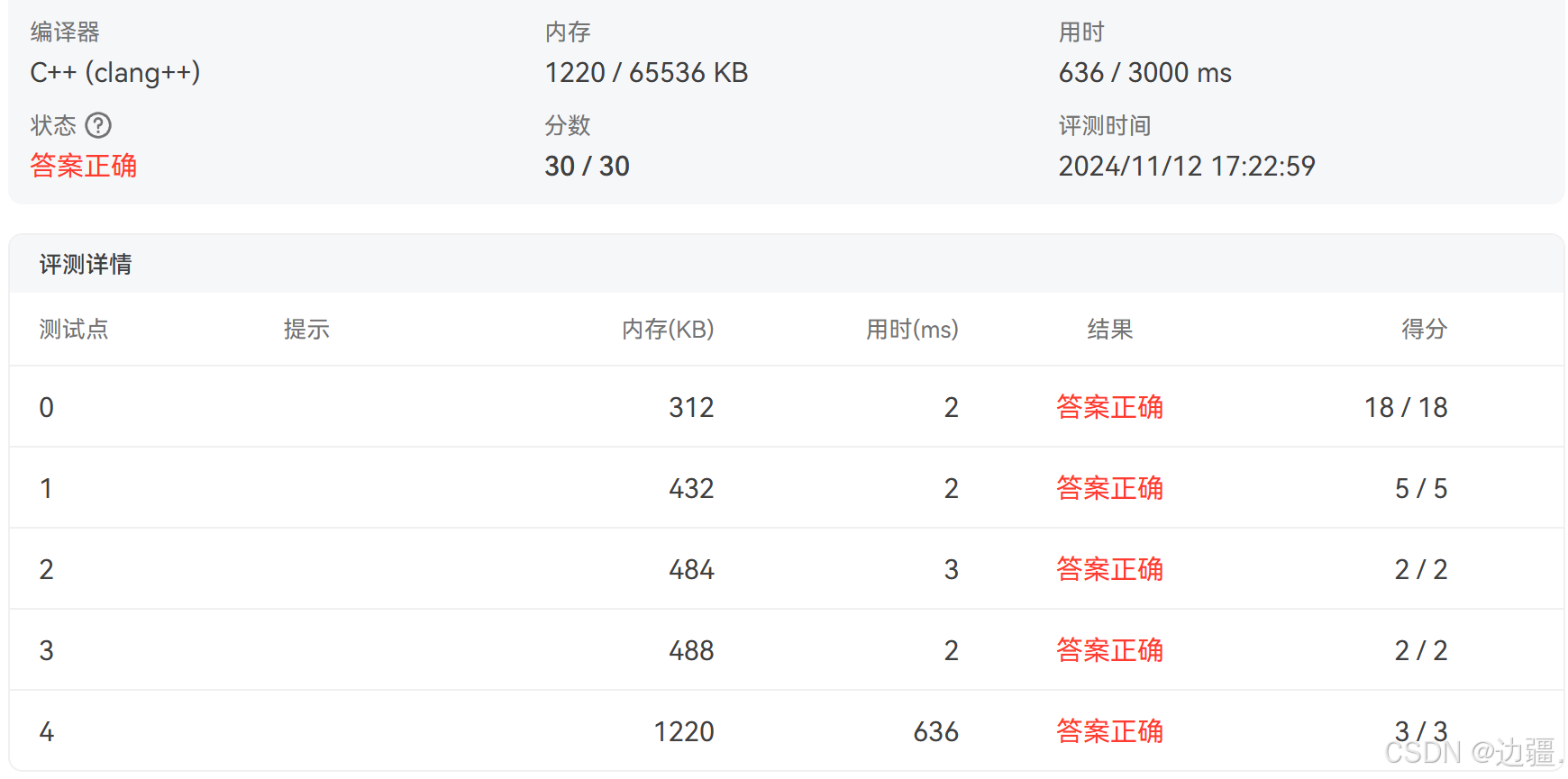
2. 添加配置
![[外链图片转存中...(img-fOjDvhqp-1731318632832)]](https://i-blog.csdnimg.cn/direct/726c4347d0a94854a2f5f8a618f246d3.png)
3. 生产、消费消息
![[外链图片转存中...(img-jb4lbhZl-1731318632833)]](https://i-blog.csdnimg.cn/direct/2d204bb34d044c0db0596c2ae3e37ccb.png)
4. 模拟节点宕机
可以随机停止一个zk节点, kafka节点, 测试一下集群是否能够正常生产消费
相关文章:
linux安装zookeeper和kafka集群
linux安装zookeeper和kafka集群 一、Zookeeper集群部署安装zookeeper1. 下载2. 上传, 解压3. 配置 Zookeeper 节点4. 创建 myid 文件5. 启动参数更改6. sh文件授权7. 启动集群8. 防火墙开启端口 验证集群 二、kafka集群安装安装Kafka1. 下载Kafka安装包2. 上传到服务器…...

洞悉 Linux 系统运行细节,使用 atop 监测和回看系统负载状态
Linux系统的资源使用情况,你可以通过使用命令如free、top和netstat来实时监控内存、CPU及端口的使用状态。对于需要追踪历史资源消耗动态的场景,atop命令则能有效帮助用户查看过去的系统负载情况。 本篇教程的灵感源自一位小伙伴的真实经历:…...
“双十一”电商狂欢进行时,在AI的加持下看网易云信IM、RTC如何助力商家!
作为一年一度的消费盛会,2024年“双十一”购物狂欢节早已拉开帷幕。蹲守直播间、在主播热情介绍中点开链接并加购,也已成为大多数人打开“双11”的重要方式。然而,在这火热的购物氛围背后,主播频频“翻车”、优质主播稀缺、客服响…...

Python调用企业微信的扫一扫
在企业微信里面新建了一个应用,指向了搭建服务器上Django写的web应用。 web应用需要使用扫描二维码的功能,就使用了大家都评价效果好的微信的扫一扫,事实也证明微信的扫一扫很好,但实现这个功能还是花了自己不少时间,很…...

速盾:CDN和OBS能共用流量包吗?
CDN和OBS是两种不同的云服务,它们在内容分发和存储方面有着不同的功能和优势。虽然它们都可以用于提供高效的内容分发和存储服务,但是它们的流量包是不能共用的。 CDN,即内容分发网络,是一种通过将内容存储在全球分布的服务器上&…...

第8章 利用CSS制作导航菜单
8.1 水平顶部导航栏 水平莱单导航栏是网站设计中应用范围最广的导航设计,一般放置在页面的顶部。水平 导航适用性强,几乎所有类型的网站都可以使用,设计难度较低。 如果导航过于普通,无法容纳复杂的信息结构,就需要在…...

C# 集合与泛型
文章目录 前言1.什么是集合?2.非泛型集合(了解即可)2.1常见的非泛型集合 3.泛型的概念4.常用的泛型集合4.1 List < T > <T> <T>4.2 Dictionary<TKey, TValue>4.3 Queue < T > <T> <T>4.4 S t a c…...

el-date-picker 设置开始时间和结束时间
<el-date-picker v-model"ruleForm.RECORDDATE" type"date" placeholder"日期" format"YYYY/M/D" value-format"YYYY/M/D" style"width: 100%;" :disabled-date"publishDateAfter" > </el-dat…...

【Docker】 常用命令
文章目录 介绍Docker和容器化技术什么是Docker?Docker的优势和应用场景Docker的应用场景包括但不限于: 安装和配置Docker安装Docker引擎配置Docker环境 Docker镜像命令搜索镜像拉取镜像查看本地镜像删除本地镜像 Docker容器命令创建容器启动容器停止容器…...

docker compose - 设置名字
只使用 docker compose up 启动容器,默认名字为当前文件夹的名字 设置 project-name,docker 客户端会显示设置的名字,方便区分 docker compose --project-name webtest up错误: docker compose up --project-name webtest 效果…...

工业拍卖平台、信息发布、租赁商城平台系统适用于全行业解决方案。
工业拍卖平台系统是为工业领域的资产交易、设备处置等提供线上拍卖服务的数字化平台。 主要功能: 拍卖信息发布:平台会展示待拍卖的工业资产详细信息,包括设备的名称、型号、规格、使用年限、生产厂家等基本信息,以及资产的图片…...
的使用心得)
一个win32 / WTL下多线程库(CThread类)的使用心得
说是多线程库,其实就是一个单独的.h文件,可以方便的放入WTL/win32工程中。 下载地址:CThread. 里面也简单介绍了 用法。 具体用法,首先自定义一个子线程类继承CThreadImpl<T>,注意他是个模板类。 class CMySu…...

使用wordpress搭建简易的信息查询系统
背景 当前有这样的一个需求,要实现让客户能够自助登录系统查询一些个人的信息,市面上没有特别符合我的需求的产品,经过一段时间的研究,想出了一个用wordpress实现简易信息查询系统,有两种方式。 方式一:使…...
PAT甲级 1076 Forwards on Weibo(30)
文章目录 题目题目翻译深度优先搜索(dfs)宽度优先搜索(bfs)总结 原题链接 题目 题目翻译 微博被称为中国的推特。在微博上,一个用户可能有很多粉丝,也可能关注许多其他用户。因此,通过粉丝关系…...

揭开 gRPC、RPC 、TCP和UDP 的通信奥秘
差异点 特性TCPUDPRPCgRPCHTTP工作层级传输层传输层应用层应用层应用层传输协议面向连接的传输协议无连接传输协议使用 TCP、HTTP 等协议HTTP/2HTTP/1.1, HTTP/2序列化格式字节流数据报文XML、JSON 或自定义Protocol BuffersJSON 或 XML特点可靠的连接传输无连接、快速传输远程…...

使用Web Worker来处理多线程操作,以及如何避免主线程卡顿。
在JavaScript中处理大量数据时,由于JavaScript是单线程的,所有的操作都在主线程上运行,因此处理大量数据可能导致页面卡顿和响应迟缓。为了避免这些问题,可以使用Web Workers来实现多线程操作,允许在后台线程中处理复杂…...
杂谈:业务说的场景金融是什么?
引言:市场格局的转变 在供应短缺的年代,是典型的卖方市场。为了保证稳定供货,买方会提前一段时间下单,也几乎没什么议价能力。卖方只需等着接单就行。 现在很多领域的供应商数量越来越多,而且随着互联网的普及&#…...

在vscode实现用和Chrome开发者工具中相同的快捷键进行面板切换
在Chrome开发者工具中,我们可以用 Ctrl [ 和 Ctrl ] 快捷键来切换面板,用起来很方便。 vscode中默认没有这两个快捷键,我们可以通过配置自定义快捷键来实现相同的功能。 配置方法: 1. 按 Ctrl K, Ctrl S 调出快捷键配置面板。…...

【ESP32+MicroPython】硬件控制基础
ESP32是一款功能强大的微控制器,具有多种硬件接口。本文以“ESP32硬件控制”为主题,逐步介绍GPIO(通用输入输出)、PWM(脉宽调制)、ADC(模数转换)等功能的原理与实现,并结…...

Python学习从0到1 day26 第三阶段 Spark ① 数据输入
要学会 剥落旧痂 然后 循此新生 —— 24.11.8 一、Spark是什么 定义: Apache Spark 是用于大规模数据处理的统一分析引擎 简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据…...

混合量子-经典机器学习在HPC环境下的性能调优与实战
1. 项目概述与核心价值在人工智能和计算科学的前沿,我们正站在一个关键的十字路口。一方面,以卷积神经网络为代表的经典机器学习模型,在处理图像识别、自然语言理解等任务上取得了巨大成功,但其对计算资源的需求正以惊人的速度膨胀…...

遗传算法融合线性规划:超参数调优的高效双层优化策略
1. 项目概述:当遗传算法遇上线性规划,超参数调优的新思路在机器学习项目的落地过程中,有一个环节既让人着迷又令人头疼,那就是超参数调优。模型架构的层数、神经元的数量、学习率、正则化强度……这些“旋钮”的微小转动ÿ…...

OpenAI Assistant API vs 开源框架:创业者该如何选择技术栈?
OpenAI Assistant API vs 开源框架:创业者该如何选择技术栈? 作者:老周,连续AI创业者,前大厂AI架构师,专注分享AI创业落地实战经验 引言 痛点引入 过去一年我接触了至少20个AI创业团队,80%的团…...

从岭回归到Lasso:正则化原理、稀疏性与ADMM算法实践
1. 项目概述:从岭回归到Lasso的深度解析在机器学习和统计建模的实践中,我们常常面临一个核心矛盾:模型在训练数据上表现优异,但在未见过的数据上却一塌糊涂,这就是所谓的“过拟合”。想象一下,你为了记住一…...

Unity Android启动卡在Waiting For Debugger原因与三套解决方案
1. 这个“Waiting For Debugger”到底在等谁?——从Unity启动流程看问题本质你刚在Android设备上点开调试中的Unity App,屏幕却卡在黑屏或白屏,Logcat里反复刷出一行红色日志:Waiting For Debugger。你反复检查USB调试开关、ADB权…...
)
ssm出租车投诉管理系统(10092)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...
下载与使用指南)
Cobalt Strike(CS)下载与使用指南
⚠️ 免责声明:本文内容仅用于合法授权的网络安全测试、实验室学习与企业安全防护研究。禁止将相关工具用于任何未授权攻击、非法入侵、数据窃取或破坏行为,否则可能违反当地法律法规。 一、什么是 Cobalt Strike(CS) 1.1 简介 …...

Burp Suite小白挖洞实战:公益漏洞挖掘的最小可行闭环
1. 这不是“无脑”,而是把重复动作压缩成肌肉记忆“使用Burp Suite插件如何无脑挖的第一个公益漏洞(小白挖洞)”——这个标题里最危险的词,不是“Burp Suite”,也不是“公益漏洞”,而是“无脑”。我带过二十…...

VisualGGPK2终极指南:5步轻松编辑《流放之路》游戏资源文件
VisualGGPK2终极指南:5步轻松编辑《流放之路》游戏资源文件 【免费下载链接】VisualGGPK2 Library for Content.ggpk of PathOfExile (Rewrite of libggpk) 项目地址: https://gitcode.com/gh_mirrors/vi/VisualGGPK2 VisualGGPK2是一款专为《流放之路》玩家…...
)
保姆级教程:在Ubuntu 20.04上搞定浙大lidar_IMU_calib(从编译到避坑)
保姆级教程:在Ubuntu 20.04上搞定浙大lidar_IMU_calib(从编译到避坑)当激光雷达(LiDAR)和惯性测量单元(IMU)需要协同工作时,标定这两个传感器之间的外参是必不可少的步骤。浙大开源项…...