PAT甲级 1076 Forwards on Weibo(30)
文章目录
- 题目
- 题目翻译
- 深度优先搜索(dfs)
- 宽度优先搜索(bfs)
- 总结
原题链接
题目

题目翻译
微博被称为中国的推特。在微博上,一个用户可能有很多粉丝,也可能关注许多其他用户。因此,通过粉丝关系形成了一个社交网络。当一个用户在微博上发表帖子时,他/她所有的粉丝都可以查看和转发他/她的帖子,然后这些帖子可以被他们的粉丝再次转发。现在,假设只计算L级的间接粉丝,需要计算任何一个特定用户的最大潜在转发量。
输入格式
每个输入文件包含一个测试用例。对于每个案例,第一行包含两个正整数:N(≤1000),用户的数量;L(≤6),被计算的间接粉丝的级别数。因此,所有用户都被假设编号从1到N。然后是N行,每行的格式如下:
M[i] user_list[i]
其中 M[i](≤100)是用户[i]关注的总人数;user_list[i] 是用户[i]关注的 M[i] 个用户的列表。保证没有人会关注自己。所有数字之间用空格分隔。
然后最后给出一个正整数 K,后面跟着 K 个用户ID用于查询。
输出格式
对于每个用户ID,你需要在一行中打印出这个用户可以触发的最大潜在转发量,假设每个可以看到初始帖子的人都会转发一次,并且只计算L级的间接粉丝。
基本思路
求一个用户的最大潜在转发量,就是一层一层地去找粉丝数,不超过L层。每次一层一层去找粉丝数时我们需要知道当前用户是在第几层?是否转发过?到这里,我一开始想到的是用dfs(深度优先搜索),但是最后一个用例超时了,应该是递归调用太多了,爆栈了。所以得用bfs(宽度优先搜索),将该层的用户编号和该用户的层数用一个队列存储起来,然后遍历每个用户的粉丝编号,如果没有转发过答案就+1,如果当前层数<最大层数L,就将它的粉丝编号和它的层数入队
深度优先搜索(dfs)
思路比较简单,先定义一个用户结构体userID,结构体里面存储vector容器,vector存储关注该用户的粉丝编号。再定义结构体数组user[M],将全部用户编号以及该用户的粉丝编号存储起来。
struct userID {vector<int> m;
}user[M];
再来看递归函数dfs的写法,将当前用户的粉丝编号遍历一遍,vis数组用来标记当前用户是否转发过,如果为false,最大转发量就+1,然后标记当前用户为true。然后再判断该层是否小于最大层数L,如果小于就继续递归该粉丝和下一层层数。
void dfs(int id,int l)
{for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if(l<L){dfs(user[id].m[i],l+1);}}
}
完整代码
#include<iostream>
#include<vector>
#include<cstring>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
struct userID {vector<int> m;
}user[M];
ll ans = 0;
void dfs(int id,int l)
{for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if(l<L){dfs(user[id].m[i],l+1);}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;user[x].m.push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;dfs(k[i], 1);cout << ans << endl;}return 0;
}
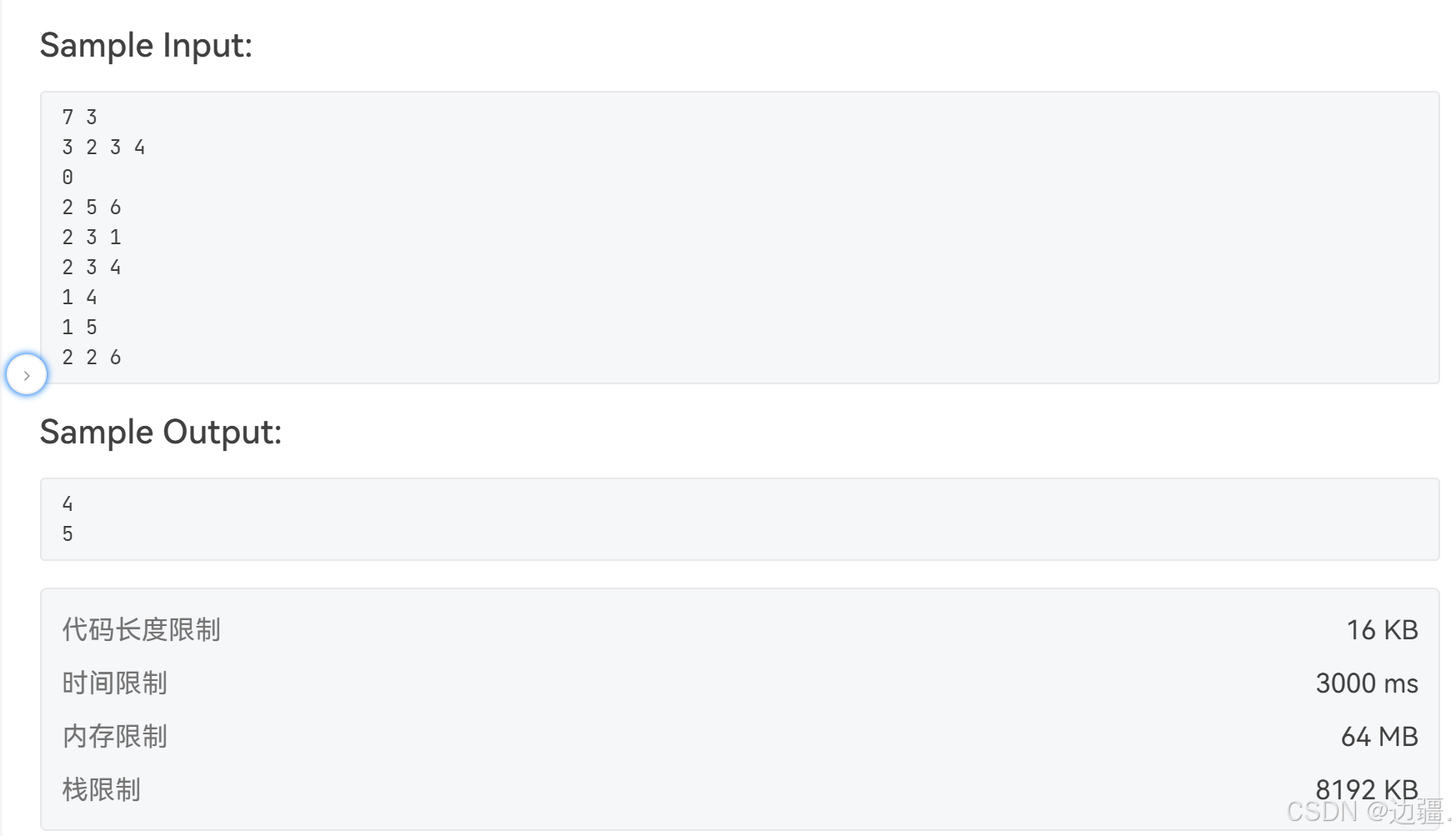
通过评测结果发现只过了90%的样例,最后一个运行超时。可能原因就是递归调用太多,导致栈溢出。
递归搜索dfs不行,可以尝试使用非递归搜索bfs
宽度优先搜索(bfs)
延续上述思路,先创建一个队列,该队列存储的是对组pair<int,int>,对组第一个数是用户编号id,第二个数是当前用户所在的层数
queue<pair<int, int>> q;
q.push({用户编号id,用户所在的层数});
步骤
(1)判断当前队列是否为空,如果不为空,获取队头,
(2)遍历该用户的所有关注者——>如果没有转发过则最大转发量+1(再将该关注者标志为转发过),判断该用户的当前层数是否小于最大层数L,如果小于则将该关注者的编号和所在层数入队,注意:关注者的所在层数要加一
q.push({ user[id].m[i],level + 1 });
将发表帖子的用户编号以及层数(层数为1)入队,再重复步骤(1)(2) 直到队列为空
void bfs(int id)
{queue<pair<int, int>> q;q.push({id,1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if (level < L){q.push({ user[id].m[i],level + 1 });}}}
}
完整代码
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
struct userID {vector<int> m;
}user[M];
ll ans = 0;
void bfs(int id)
{queue<pair<int, int>> q;q.push({id,1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if (level < L){q.push({ user[id].m[i],level + 1 });}}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;user[x].m.push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;bfs(k[i]);cout << ans << endl;}return 0;
}
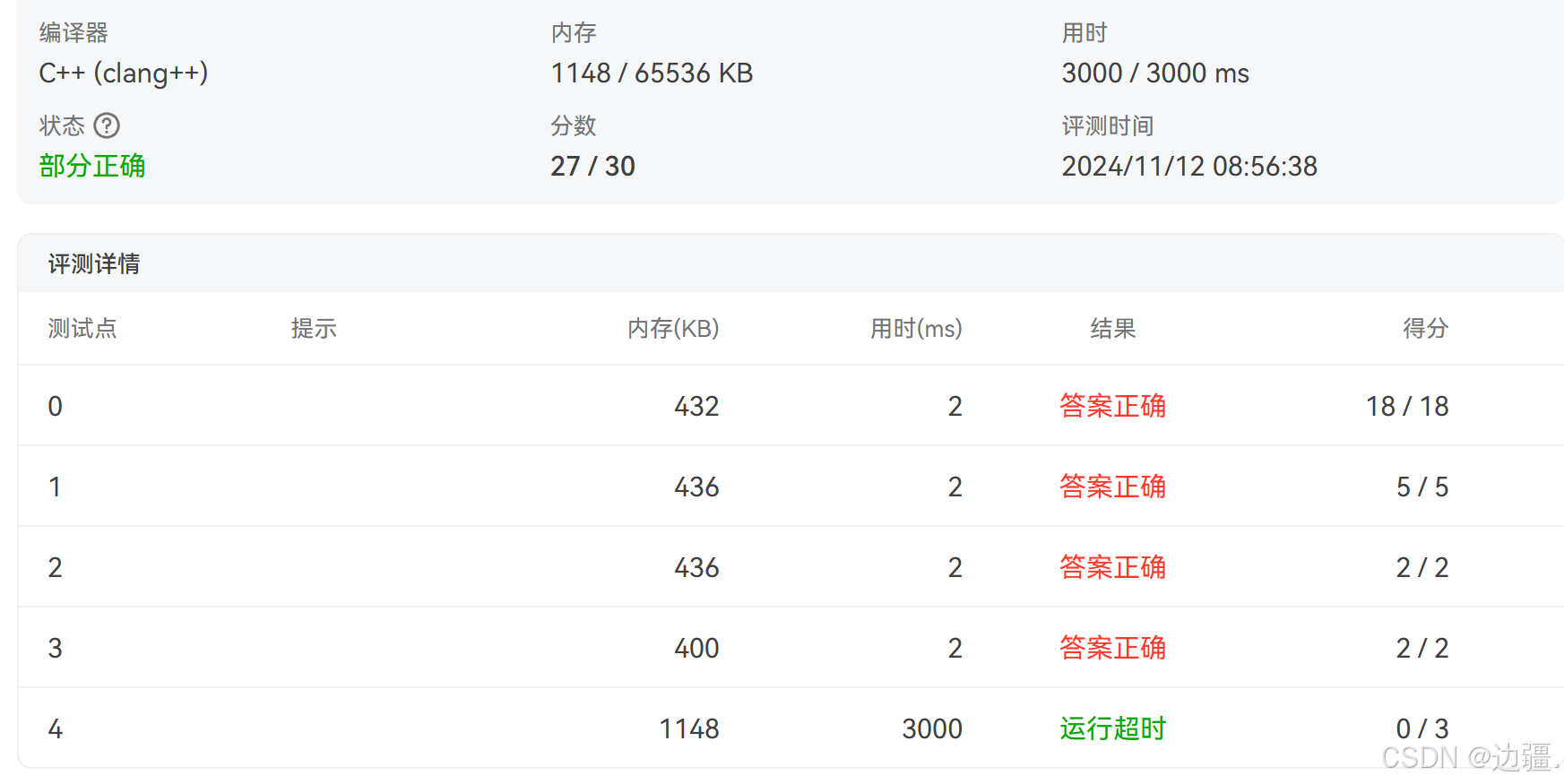
通过评测结果发现还是只过了90%的样例,报错结果是内存超限,那么可能的原因就是堆内存溢出。
我们仔细看下面的代码可以发现:不管当前用户的关注者是否转发过帖子,只要当前用户的层数小于最大层数L,那么该用户的所有关注者都会入队。实际上是没有必要的,如果该用户的某个关注者已经转发过,再将其入队会造成重复查询(到下一层再查询该关注者的所有关注者时,发现已经全部转发过),使内存消耗更大,从而导致堆内存溢出。
for (int i = 0; i < user[id].m.size(); i++)
{if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if (level < L){q.push({ user[id].m[i],level + 1 });}
}
那么应该怎么改?——>只有当前用户的关注者没有转发过且当前层数小于最大层数L,才能将关注者编号和下一层层数入队。
for (int i = 0; i < user[id].m.size(); i++)
{if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;if (level < L){q.push({ user[id].m[i],level + 1 });}}
}
这种写法相当于剪枝,就是将没有必要搜索而且不影响结果的分支去除掉,这样既提高了搜索效率,也节省了计算资源。
剪枝是一种在算法中减少搜索空间的技术,特别是在解决优化问题和决策问题时使用。它的核心思想是在搜索过程中提前排除那些不可能产生最优解或者不符合特定条件的分支,从而减少不必要的计算和资源消耗。
还有一种剪枝的写法(个人不建议)
for (int i = 0; i < user[id].m.size(); i++)
{//不推荐这种写法,因为可能还要将最高层的用户编号入队列,但是已经判断过最高层的用户是否转发过了
// if (vis[user[id].m[i]] == false && level<=L)
// {
// ans += 1;
// vis[user[id].m[i]] = true;
// q.push({ user[id].m[i],level + 1 });
// }//推荐这种写法if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;if (level < L){q.push({ user[id].m[i],level + 1 });}}
}
完整代码
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
struct userID {vector<int> m;
}user[M];
ll ans = 0;
void bfs(int id)
{queue<pair<int, int>> q;q.push({id,1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;if (level < L){q.push({ user[id].m[i],level + 1 });}}}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;user[x].m.push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;bfs(k[i]);cout << ans << endl;}return 0;
}
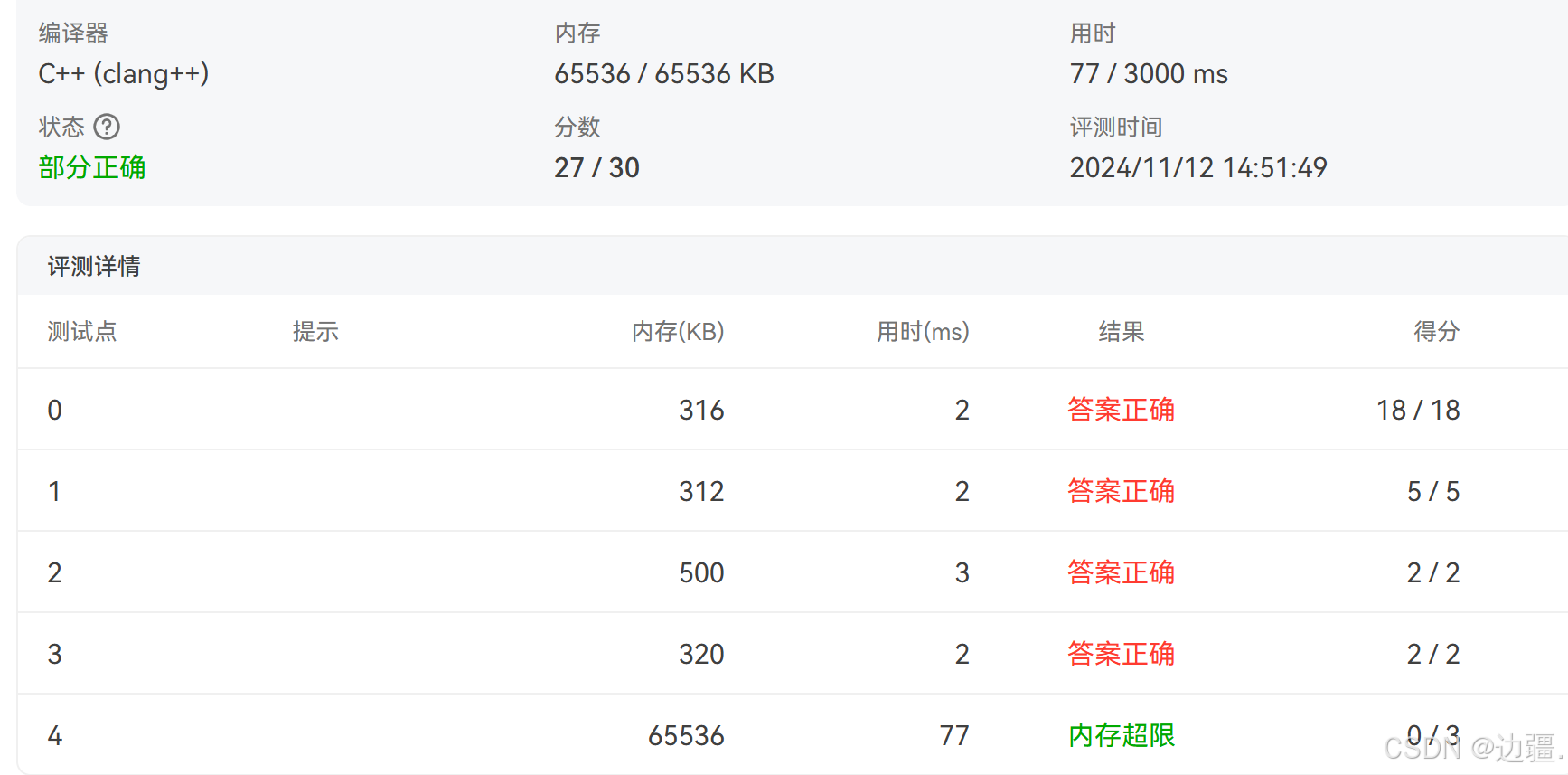
通过评测结果发现通过了全部样例
个人的另一种写法
此写法直接开辟了二维动态数组,省去了创建结构体和结构体数组,但实际上大同小异。
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
vector<vector<int>> vc(M);
ll ans = 0;
void bfs(int id)
{queue<pair<int, int>> q;q.push({id, 1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < vc[id].size(); i++){if (vis[vc[id][i]] == false){ans += 1;vis[vc[id][i]] = true;if (level < L){q.push({vc[id][i], level + 1});}}}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;vc[x].push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;bfs(k[i]);cout << ans << endl;}return 0;
}
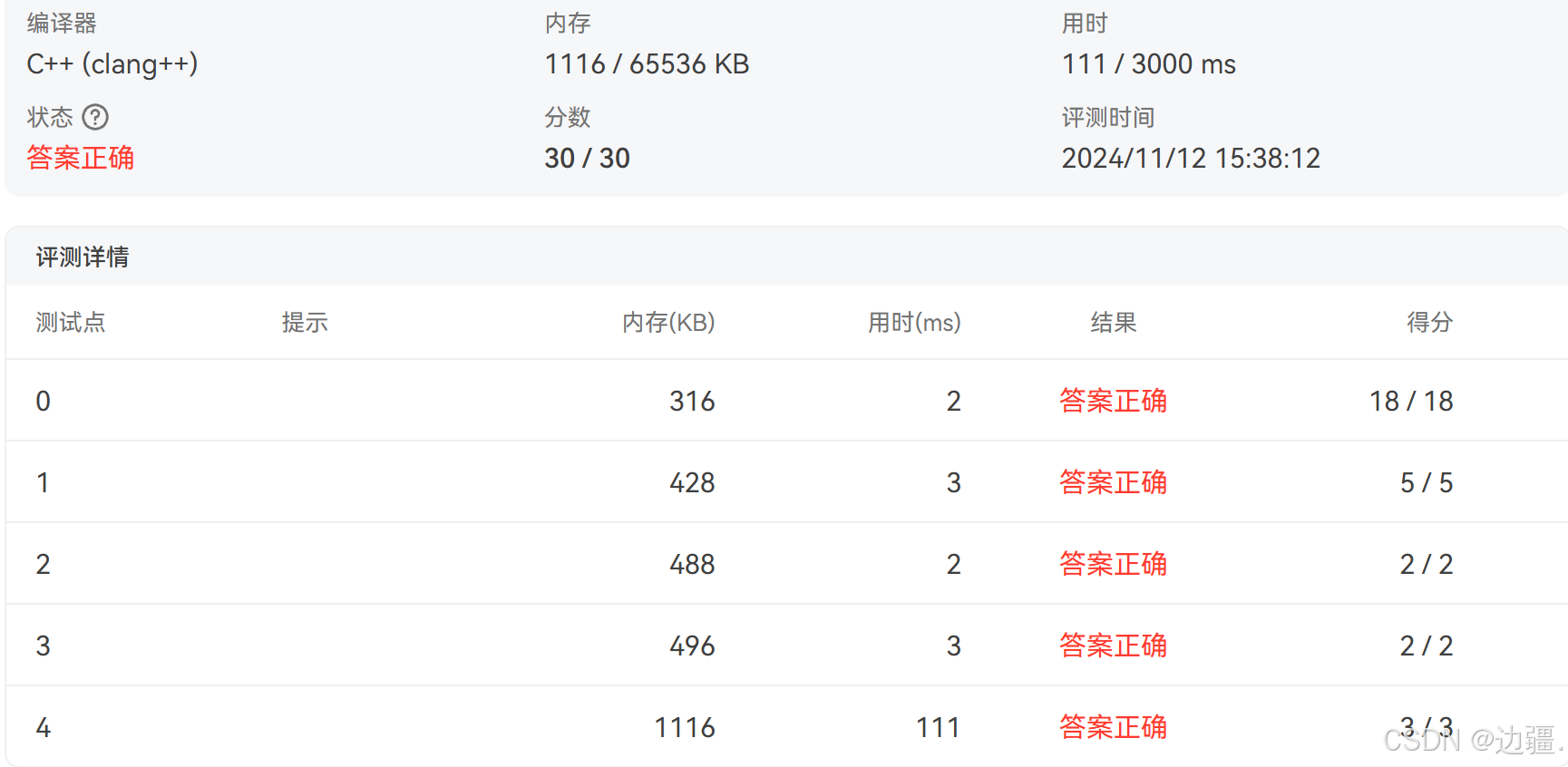
评测结果显示通过了全部样例
yxc的写法
此写法用邻接表来存储图,需要注意的是一共有1000个点,每个点最多存100条边,所以点数N可以开1e3+10,边数M最多为1e5+10。
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;//点数和边数
const int N=1e3+10,M=1e5+10;int n,l;
int h[N],e[M],ne[M],idx; //用邻接表来存储图
bool st[N]; //状态数组//头节点
void add(int a,int b){e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}int bfs(int start){queue<int> q;memset(st, 0, sizeof st);q.push(start); //队列初始化st[start]=true;int res=0;//l为关注着的层数for(int i=0;i<l;i++){ //i为每层的关注者int sz=q.size();//注意:这个while中sz为每层关注着的人数,所以要暂存while(sz--){auto t=q.front();q.pop();//遍历start的第i层关注者for(int j=h[t];j!=-1;j=ne[j]){auto x=e[j]; //e[j]存放关注者的编号if(!st[x]){q.push(x);st[x]=true;res++;}}}}return res;
}int main(){cin>>n>>l;memset(h,-1,sizeof h);for(int i=1;i<=n;i++){int cnt; //第i名用户关注的总人数cin>>cnt;while(cnt--){int x;cin>>x;add(x,i); //i是x的粉丝,让x指向i}}int m;cin>>m;while(m--){int x;cin>>x;cout<<bfs(x)<<endl;}return 0;
}
评测结果显示通过了全部样例
总结
这道题的英文单词有点难理解,比如:forward:转发,follower:粉丝,indirect:间接地
这些单词需要结合上下文才能慢慢读懂,比如forward很多人会翻译成向前的意思
对于深度优先搜索(dfs)和宽度优先搜索(bfs),我们优先考虑能不能使用bfs+剪枝一次通过,因为dfs的局限性有点大,数据稍微大一点就很容易超时(当然也可以通过dfs+剪枝来降低时间复杂度,但是不确定能不能通过)
到这里就结束啦,对以上内容有异议的欢迎大家来讨论。
相关文章:
PAT甲级 1076 Forwards on Weibo(30)
文章目录 题目题目翻译深度优先搜索(dfs)宽度优先搜索(bfs)总结 原题链接 题目 题目翻译 微博被称为中国的推特。在微博上,一个用户可能有很多粉丝,也可能关注许多其他用户。因此,通过粉丝关系…...

揭开 gRPC、RPC 、TCP和UDP 的通信奥秘
差异点 特性TCPUDPRPCgRPCHTTP工作层级传输层传输层应用层应用层应用层传输协议面向连接的传输协议无连接传输协议使用 TCP、HTTP 等协议HTTP/2HTTP/1.1, HTTP/2序列化格式字节流数据报文XML、JSON 或自定义Protocol BuffersJSON 或 XML特点可靠的连接传输无连接、快速传输远程…...

使用Web Worker来处理多线程操作,以及如何避免主线程卡顿。
在JavaScript中处理大量数据时,由于JavaScript是单线程的,所有的操作都在主线程上运行,因此处理大量数据可能导致页面卡顿和响应迟缓。为了避免这些问题,可以使用Web Workers来实现多线程操作,允许在后台线程中处理复杂…...
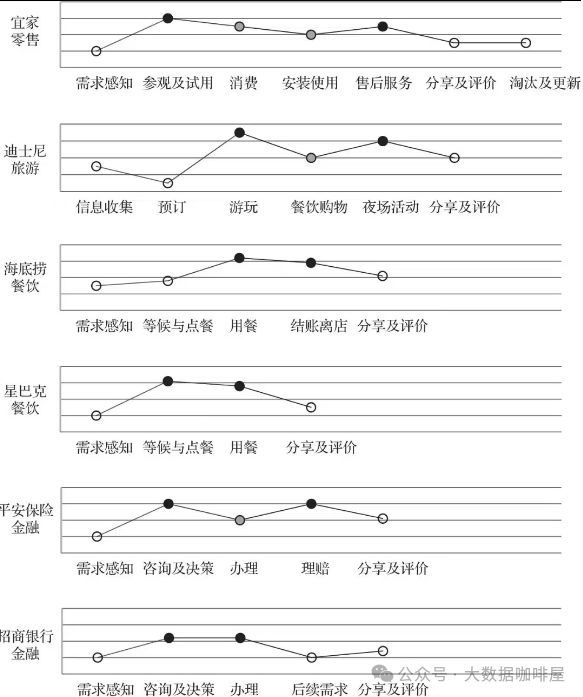
杂谈:业务说的场景金融是什么?
引言:市场格局的转变 在供应短缺的年代,是典型的卖方市场。为了保证稳定供货,买方会提前一段时间下单,也几乎没什么议价能力。卖方只需等着接单就行。 现在很多领域的供应商数量越来越多,而且随着互联网的普及&#…...

在vscode实现用和Chrome开发者工具中相同的快捷键进行面板切换
在Chrome开发者工具中,我们可以用 Ctrl [ 和 Ctrl ] 快捷键来切换面板,用起来很方便。 vscode中默认没有这两个快捷键,我们可以通过配置自定义快捷键来实现相同的功能。 配置方法: 1. 按 Ctrl K, Ctrl S 调出快捷键配置面板。…...

【ESP32+MicroPython】硬件控制基础
ESP32是一款功能强大的微控制器,具有多种硬件接口。本文以“ESP32硬件控制”为主题,逐步介绍GPIO(通用输入输出)、PWM(脉宽调制)、ADC(模数转换)等功能的原理与实现,并结…...

Python学习从0到1 day26 第三阶段 Spark ① 数据输入
要学会 剥落旧痂 然后 循此新生 —— 24.11.8 一、Spark是什么 定义: Apache Spark 是用于大规模数据处理的统一分析引擎 简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据…...

kafka消费者的消费分区策略有哪些,默认是哪个?
Kafka消费者的分区分配策略主要有以下几种,分别决定了如何将多个分区分配给消费者: 1. Range(范围分配) 描述:将分区连续地分配给消费者。每个消费者负责一段连续的分区。如果有多个消费者,那么消费者会按…...

前端常用时间操作汇总
(1)获取中国标准时间: let now new Date(); // Thu Nov 14 2024 17:13:49 GMT0800 (中国标准时间) (2)获取年份: let year now.getFullYear(); // 2024 (3)获取月份&…...

106. UE5 GAS RPG 使用MVVM
MVVM 是 Model-View-ViewModel的缩写,个人理解它和MVC很相似,有区别的地方在于,在MVC里,Controller会服务多个View,而MVVM里,每个View都拥有一个单独的ViewModel,所以ViewModel相当于精简版的Co…...

Elasticsearch中什么是倒排索引?
倒排索引(Inverted Index)是一种索引数据结构,它在信息检索系统中被广泛使用,特别是在全文搜索引擎中。倒排索引允许系统快速检索包含给定单词的文档列表。它是文档内容(如文本)与其存储位置之间的映射&…...

深度学习:AT Decoder 详解
AT Decoder 详解 在序列到序列的模型架构中,自回归解码器(Autoregressive Translator, AT Decoder)是一种核心组件,其设计目标是确保生成的序列在语义和语法上的连贯性与准确性。自回归解码器通过逐步、依赖前一输出来生成新的输…...
)
pythons工具——图像的随机增强变换(只是变换了图像,可用于分类训练数据的增强)
从文件夹中随机选择一定数量的图像,然后对每个选定的图像进行一次随机的数据增强变换。 import os import random import cv2 import numpy as np from PIL import Image, ImageEnhance, ImageOps# 定义各种数据增强方法 def random_rotate(image, angle_range(-30…...

C++中volatile限定符详解
volatile是 C 和 C 中的一个类型限定符,它用于告诉编译器被修饰的变量具有特殊的属性,编译器在对该变量进行优化时需要特殊对待。以下是volatile限定符的主要作用: 1. 防止优化 内存访问顺序:在多线程环境或者与硬件交互的程序中…...
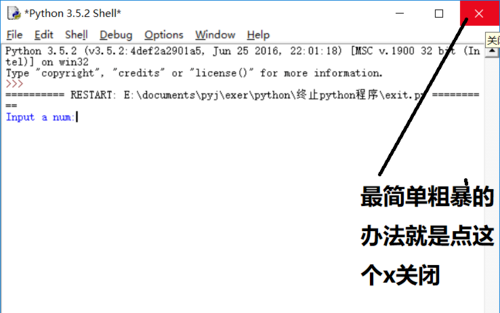
如何关闭Python解释器
方法1:采用sys.exit(0)正常终止程序,从图中可以看到,程序终止后shell运行不受影响。 方法2:采用os._exit(0)关闭整个shell,从图中看到,调用sys._exit(0)后整个shell都重启了(RESTART Shell&…...

《TCP/IP网络编程》学习笔记 | Chapter 9:套接字的多种可选项
《TCP/IP网络编程》学习笔记 | Chapter 9:套接字的多种可选项 《TCP/IP网络编程》学习笔记 | Chapter 9:套接字的多种可选项套接字可选项和 I/O 缓冲大小套接字多种可选项getsockopt & setsockoptSO_SNDBUF & SO_RCVBUF SO_REUSEADDR发生地址绑定…...

渗透测试---网络基础之HTTP协议与内外网划分
声明:学习素材来自b站up【泷羽Sec】,侵删,若阅读过程中有相关方面的不足,还请指正,本文只做相关技术分享,切莫从事违法等相关行为,本人一律不承担一切后果 目录 一、HTTP协议各版本介绍 二、HTTP请求的方…...

15分钟学 Go 第 45 天 : 使用Docker容器
第45天:使用Docker容器 目标 在本节中,我们将深入了解Docker及其基本用法,掌握如何使用Docker容器来简化开发和部署流程。 背景知识 Docker是一个开源平台,用于开发、运输和运行应用程序。它使我们能够使用容器技术将应用程序…...

DriveLM 论文学习
论文链接:https://arxiv.org/pdf/2312.14150 代码链接:https://github.com/OpenDriveLab/DriveLM 解决了什么问题? 当前,自动驾驶方案的性能仍然不足。一个必要条件就是泛化能力,需要模型能处理未经训练的场景或不熟…...

YoloV10改进策略:上采样改进|CARAFE,轻量级上采样|即插即用|附改进方法+代码
论文介绍 CARAFE模块概述:本文介绍了一种名为CARAFE(Content-Aware ReAssembly of FEatures)的模块,它是一种用于特征上采样的新方法。应用场景:CARAFE模块旨在改进图像处理和计算机视觉任务中的上采样过程࿰…...

摒弃传统持卡定位弊端 全方位筑牢井下应急安全屏障
摒弃传统持卡定位弊端 全方位筑牢井下应急安全屏障井下人员定位是矿山安全生产、应急救援、风险管控的核心基础支撑,直接关乎井下作业人员生命安全与矿山安全生产大局。长期以来,传统井下持卡定位模式凭借基础管控作用被广泛应用,但在深井开采…...
)
DeepSeek长上下文能力解密(官方未公开的context-aware attention调度机制)
更多请点击: https://codechina.net 第一章:DeepSeek长上下文能力解密(官方未公开的context-aware attention调度机制) DeepSeek系列模型在128K token上下文场景中展现出远超同规模模型的稳定性与推理一致性,其核心并…...

Taotoken的Token Plan套餐如何帮助初创公司控制AI实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的Token Plan套餐如何帮助初创公司控制AI实验成本 1. 成本不可预测:初创AI实验的常见困境 在产品原型和早期开…...

基于 Taotoken 构建支持多模型路由的智能写作助手 Agent
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于 Taotoken 构建支持多模型路由的智能写作助手 Agent 在开发智能写作工具时,一个常见的需求是让工具能够处理不同类…...

终极轻量级浏览器内核:miniblink49嵌入式HTML UI完整指南
终极轻量级浏览器内核:miniblink49嵌入式HTML UI完整指南 【免费下载链接】miniblink49 a lighter, faster browser kernel of blink to integrate HTML UI in your app. 一个小巧、轻量的浏览器内核,用来取代wke和libcef 项目地址: https://gitcode.c…...

Windows苹果设备连接问题终结者:一键安装驱动实现完美兼容
Windows苹果设备连接问题终结者:一键安装驱动实现完美兼容 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh…...

为内部知识库构建智能问答,利用Taotoken多模型能力选型优化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库构建智能问答,利用Taotoken多模型能力选型优化 当企业计划为内部知识库添加智能问答机器人时,…...

Adobe-GenP 3.0终极指南:5分钟掌握Adobe全系列软件激活技巧
Adobe-GenP 3.0终极指南:5分钟掌握Adobe全系列软件激活技巧 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款功能强大的Adobe Creat…...

观察Taotoken在多模型间自动路由与容灾切换的实际响应情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型间自动路由与容灾切换的实际响应情况 在构建依赖大模型服务的应用时,服务的连续性与稳定性是开发…...
)
AI动态简报之算力基建篇(2026.05.24)
关注方向:大模型 GPU算力 AI芯片 云计算 大模型API⚡ 第1条:全球九大云厂商资本支出上调至8300亿美元,年增79%核心信息:TrendForce集邦咨询最新报告将2026年全球九大CSP(谷歌、AWS、Meta、微软、甲骨文、字节跳动、…...