【Python TensorFlow】进阶指南(续篇一)

在前两篇文章中,我们介绍了TensorFlow的基础知识及其在实际应用中的初步使用,并探讨了更高级的功能和技术细节。本篇将继续深入探讨TensorFlow的高级应用,包括但不限于模型压缩、模型融合、迁移学习、强化学习等领域,帮助读者进一步掌握TensorFlow的全面应用。
1. 模型压缩与量化
1.1 模型量化
模型量化可以减少模型的大小和计算复杂度,使其更适合在边缘设备上运行。量化通常涉及将浮点数权重转换为较低位宽的整数表示。
import tensorflow as tf
from tensorflow.keras import layers# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 导入量化工具
quantize_model = tf.keras.Sequential([tfmot.quantization.keras.quantize_annotate_layer(layer) for layer in model.layers
])# 应用量化方案
quantize_model = tfmot.quantization.keras.quantize_apply(quantize_model)# 重新编译模型
quantize_model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 量化训练
quantize_model.fit(x_train, y_train, epochs=5)
1.2 模型剪枝
模型剪枝是一种减少模型复杂度的技术,通过移除权重较小的连接来降低模型的参数数量。
import tensorflow_model_optimization as tfmot# 创建剪枝模型
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude# 创建模型
model = tf.keras.Sequential([prune_low_magnitude(layers.Dense(64, activation='relu', input_shape=(10,))),prune_low_magnitude(layers.Dense(64, activation='relu')),prune_low_magnitude(layers.Dense(10, activation='softmax'))
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 设置剪枝配置
pruning_params = {'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(initial_sparsity=0.50,final_sparsity=0.90,begin_step=0,end_step=np.ceil(1.6 * len(x_train)),frequency=100)
}# 应用剪枝
model = tf.keras.Sequential([tfmot.sparsity.keras.prune_low_magnitude(layer, **pruning_params) for layer in model.layers
])# 训练剪枝后的模型
model.fit(x_train, y_train, epochs=5)
2. 模型融合与集成
2.1 Stacking Ensemble
Stacking Ensemble 是一种集成学习方法,通过将多个模型的输出组合起来形成新的特征,然后使用另一个模型来预测最终结果。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from sklearn.ensemble import StackingClassifier# 定义基模型
def base_model():model = Sequential()model.add(Dense(64, activation='relu', input_shape=(10,)))model.add(Dense(10, activation='softmax'))model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])return model# 创建基模型实例
base_models = [KerasClassifier(build_fn=base_model, epochs=5) for _ in range(3)]# 创建集成模型
meta_model = KerasClassifier(build_fn=base_model, epochs=5)
stacked_model = StackingClassifier(estimators=[('model%d' % i, model) for i, model in enumerate(base_models)],final_estimator=meta_model)# 训练集成模型
stacked_model.fit(x_train, y_train)# 验证集成模型
score = stacked_model.score(x_test, y_test)
print("Stacked Ensemble accuracy:", score)
3. 迁移学习
3.1 使用预训练模型
迁移学习通过使用已经在大量数据上预训练的模型,可以节省大量的训练时间和资源。TensorFlow 提供了许多预训练模型,如 VGG16、InceptionV3 等。
from tensorflow.keras.applications import VGG16# 加载预训练模型
vgg16 = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))# 冻结预训练层
for layer in vgg16.layers:layer.trainable = False# 构建新模型
model = tf.keras.Sequential([vgg16,layers.Flatten(),layers.Dense(256, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
score = model.evaluate(x_test, y_test)
print("Transfer Learning accuracy:", score[1])
3.2 Fine-Tuning
Fine-Tuning 是另一种迁移学习方法,通过解冻部分预训练层并重新训练这些层来适应新的任务。
from tensorflow.keras.applications import VGG16# 加载预训练模型
vgg16 = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))# 解冻最后一部分卷积层
for layer in vgg16.layers[:-4]:layer.trainable = False# 构建新模型
model = tf.keras.Sequential([vgg16,layers.Flatten(),layers.Dense(256, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
score = model.evaluate(x_test, y_test)
print("Fine-Tuning accuracy:", score[1])
4. 强化学习
4.1 DQN(Deep Q-Network)
强化学习是机器学习的一个重要分支,旨在让智能体通过与环境交互来学习最优策略。DQN 是一种基于深度学习的强化学习算法。
import tensorflow as tf
from tensorflow.keras import layers# 创建 Q-Network
model = tf.keras.Sequential([layers.Dense(24, activation='relu', input_shape=(4,)),layers.Dense(24, activation='relu'),layers.Dense(2, activation='linear') # 输出动作空间大小
])# 编译模型
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.Huber()# 更新 Q-Network 参数
@tf.function
def update_target_network(main_network, target_network, tau=1.0):for main_weights, target_weights in zip(main_network.trainable_variables, target_network.trainable_variables):target_weights.assign(tau * main_weights + (1.0 - tau) * target_weights)# 训练 DQN
def train_dqn(state, action, reward, next_state, done):# 计算目标 Q 值target_q_values = target_network(next_state)max_future_q = tf.reduce_max(target_q_values, axis=1)expected_q = reward + (1 - done) * 0.99 * max_future_q# 获取当前 Q 值with tf.GradientTape() as tape:current_q = main_network(state)main_q_values = tf.reduce_sum(current_q * tf.one_hot(action, 2), axis=1)# 计算损失loss_value = loss(expected_q, main_q_values)# 更新 Q-Network 参数gradients = tape.gradient(loss_value, main_network.trainable_variables)optimizer.apply_gradients(zip(gradients, main_network.trainable_variables))# 更新目标网络参数update_target_network(main_network, target_network, tau=0.01)# 初始化主网络和目标网络
main_network = model
target_network = model# 训练循环
for episode in range(100):state = env.reset()done = Falsewhile not done:action = choose_action(main_network, state)next_state, reward, done, _ = env.step(action)train_dqn(state, action, reward, next_state, done)state = next_state
5. 高级主题
5.1 AutoML
AutoML 是一种自动化的机器学习流程,可以自动选择最佳的模型架构和超参数。
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import RandomizedSearchCV# 定义模型构造函数
def create_model(hidden_layers=[64], learning_rate=0.01):model = tf.keras.Sequential()model.add(layers.Dense(hidden_layers[0], activation='relu', input_shape=(10,)))for units in hidden_layers[1:]:model.add(layers.Dense(units, activation='relu'))model.add(layers.Dense(10, activation='softmax'))model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),loss='sparse_categorical_crossentropy',metrics=['accuracy'])return model# 创建 KerasClassifier
model = KerasClassifier(build_fn=create_model, epochs=5)# 设置超参数搜索空间
param_dist = {'hidden_layers': [[64], [64, 64], [128, 64]],'learning_rate': [0.01, 0.001, 0.0001]
}# 使用 RandomizedSearchCV 进行超参数搜索
search = RandomizedSearchCV(estimator=model, param_distributions=param_dist, n_iter=10, cv=3, verbose=1)
search.fit(x_train, y_train)# 输出最佳模型
best_model = search.best_estimator_
score = best_model.score(x_test, y_test)
print("AutoML accuracy:", score)
5.2 模型解释
模型解释是理解模型预测背后逻辑的关键步骤,可以帮助提升模型的信任度和透明度。
import shap# 使用 SHAP 解释模型
explainer = shap.KernelExplainer(model.predict_proba, x_train[:100])
shap_values = explainer.shap_values(x_test[:10])# 可视化 SHAP 值
shap.summary_plot(shap_values, x_test[:10], plot_type="bar")
6. 生产环境中的模型管理
6.1 模型版本控制
在生产环境中,管理不同版本的模型非常重要,可以使用模型存储库来记录模型的每次迭代。
import mlflow# 初始化 MLflow
mlflow.tensorflow.autolog()# 创建实验
mlflow.set_experiment("my-experiment")# 记录模型
with mlflow.start_run():model.fit(x_train, y_train, epochs=5)model.evaluate(x_test, y_test)# 查看实验结果
mlflow.ui.open_ui()
6.2 模型监控与评估
在模型上线后,持续监控模型的表现和评估其效果是非常重要的。
import tensorflow as tf
from tensorflow.keras import layers# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 使用 TensorBoard 监控模型
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")# 训练模型
model.fit(x_train, y_train, epochs=5, callbacks=[tensorboard_callback])# 启动 TensorBoard
!tensorboard --logdir logs
7. 结论
通过本篇的学习,你已经掌握了TensorFlow在实际应用中的更多高级功能和技术细节。从模型压缩与量化、模型融合与集成、迁移学习、强化学习,到高级主题如 AutoML、模型解释,再到生产环境中的模型管理,每一步都展示了如何利用TensorFlow的强大功能来解决复杂的问题。
相关文章:
【Python TensorFlow】进阶指南(续篇一)
在前两篇文章中,我们介绍了TensorFlow的基础知识及其在实际应用中的初步使用,并探讨了更高级的功能和技术细节。本篇将继续深入探讨TensorFlow的高级应用,包括但不限于模型压缩、模型融合、迁移学习、强化学习等领域,帮助读者进一…...

机器视觉和计算机视觉的区别
机器视觉和计算机视觉的区别 1、本质上两者是一样的,都是将光信号转换成电信号,然后交给计算机处理; 2、二者侧重点不同,计算机视觉更偏向研究,更前沿,采集到图像后交给计算机进行分析处理,包括…...

RDD 算子全面解析:从基础到进阶与面试要点
Spark 的介绍与搭建:从理论到实践_spark环境搭建-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式…...

Vue.js动态组件使用
在 Vue.js 中,动态组件是一种功能强大的特性,它允许你在同一个挂载点根据条件动态地切换不同的组件。这通常通过 Vue 的 <component> 元素和 is 特性来实现。以下是如何在 Vue 3 中使用动态组件的详细指南: 基本用法 定义组件…...
智能合约在供应链金融中的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 智能合约在供应链金融中的应用 智能合约在供应链金融中的应用 智能合约在供应链金融中的应用 引言 智能合约概述 定义与原理 发展…...

【大数据技术基础 | 实验十】Hive实验:部署Hive
文章目录 一、实验目的二、实验要求三、实验原理四、实验环境五、实验内容和步骤(一)安装部署(二)配置HDFS(三)启动Hive 六、实验结果(一)启动结果(二)Hive基…...

Golang常见编码
1. URL 编码、解码 2. base64 编码、解码 3. hex 编码、解码 4. md5 编码 5. sha-1 编码 6. sha-256 编码 7. sha-512 编码 package mainimport ("crypto/md5""crypto/sha256""crypto/sha512""encoding/base64""encoding/h…...

搭建Spring gateway网关微服务
在使用微服务架构时,往往我们需要搭建一个网关服务,作为各个微服务的统一入口。Spring gateway作为网关服务的后起之秀,受到各大企业的欢迎。下面介绍下网关服务Spring gateway的搭建。 引入依赖,这一步比较重要,也需要…...

性能测试|JMeter接口与性能测试项目
前言 在软件开发和运维过程中,接口性能测试是一项至关重要的工作。JMeter作为一款开源的Java应用,被广泛用于进行各种性能测试,包括接口性能测试。本文将详细介绍如何使用JMeter进行接口性能测试的过程和步骤。 JMeter是Apache组织开发的基…...

spring boot 难点解析及使用spring boot时的注意事项
1、难点解析: 1.1 配置管理: --- 尽管Spring Boot强调“习惯优于配置”,但在实际项目中,仍然需要面对大量的配置问题。如何合理地组织和管理这些配置,以确保项目的稳定性和可维护性,是一个挑战。 --- Sp…...

通过投毒Bingbot索引挖掘必应中的存储型XSS
简介 在本文中,我将讨论如何通过从外部网站对Bingbot进行投毒,来在Bing.com上实现持久性XSS攻击。 什么是存储型或持久性XSS?存储型攻击指的是将恶意脚本永久存储在目标服务器上,例如数据库、论坛、访问日志、评论栏等。受害者在…...
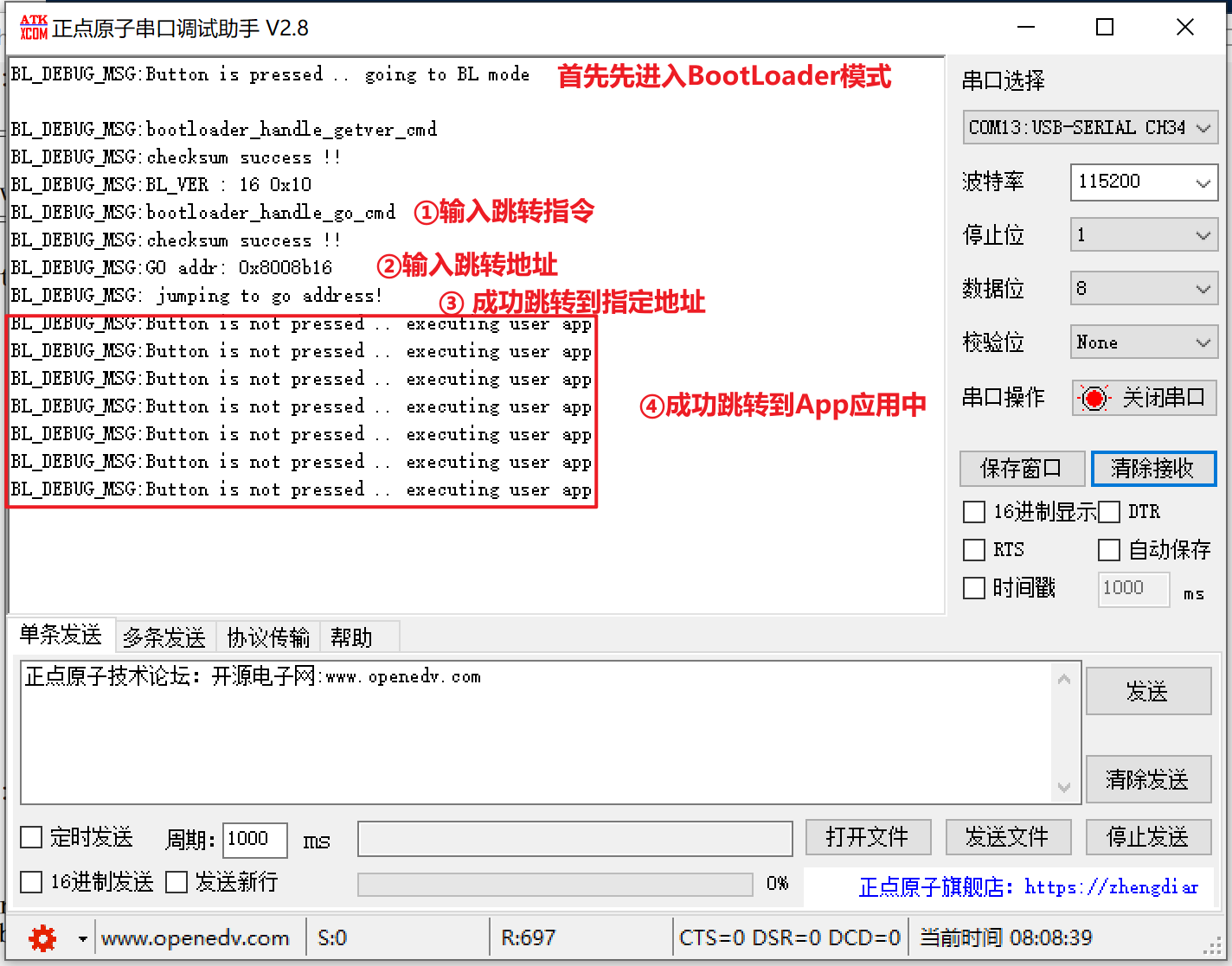
STM32 BootLoader 刷新项目 (九) 跳转指定地址-命令0x55
STM32 BootLoader 刷新项目 (九) 跳转指定地址-命令0x55 前面我们讲述了几种BootLoader中的命令,包括获取软件版本号、获取帮助、获取芯片ID、读取Flash保护Level。 下面我们来介绍一下BootLoader中最重要的功能之一—跳转!就像BootLoader词汇中的Boot…...

【Linux篇】面试——用户和组、文件类型、权限、进程
目录 一、权限管理 1. 用户和组 (1)相关概念 (2)用户命令 ① useradd(添加新的用户账号) ② userdel(删除帐号) ③ usermod(修改帐号) ④ passwd&…...

PET-文件包含
include发生错误报warning,继续执行。require发生错误直接error,不继续执行 无视扩展名,只要能解析,就能当可执行文件执行,哪怕文件后缀或没后缀 1 条件竞争 pass17 只需要知道tmp的路径。把xieshell.jpg上传&…...

实现uniapp-微信小程序 搜索框+上拉加载+下拉刷新
pages.json 中的配置 { "path": "pages/message", "style": { "navigationBarTitleText": "消息", "enablePullDownRefresh": true, "onReachBottomDistance": 50 } }, <template><view class…...

PostgreSQL 修改字段类型但是存在视图依赖
其实视图的存在与否在数据库界一直是一个话题。用好视图可以简化程序的很多代码,用不好视图不仅会给维护带来很多的不便,也会造成很大的性能问题。下面我从维护方面给出案例,以及当存在这种问题的时候,如何去解决这个问题。 假设…...

基于.NET 9实现实时进度条功能:前后端完整示例教程
要在基于.NET 9的应用中实现进度条功能,我们可以通过HttpContext.Response来发送实时的进度更新到前端。以下是一个简单的示例,展示了如何在ASP.NET Core应用中实现这一功能。 但是,我在.net framework4.7.2框架下,实际不了HttpC…...

力扣 LeetCode 19. 删除链表的倒数第N个结点(Day2:链表)
解题思路: 快慢指针 class Solution {public ListNode removeNthFromEnd(ListNode head, int n) {ListNode dummy new ListNode(-1);dummy.next head;ListNode fast dummy;ListNode slow dummy;for (int i 0; i < n; i) {fast fast.next;}while (fast.ne…...

音频格式转换
一、场景 项目需求需要App实现声纹识别功能,调用科大讯飞接口: 声纹识别 API 文档 | 讯飞开放平台文档中心 其接口要求音频文件格式为mp3 二、问题产生 在安卓端根据官方文档说明,系统并不支持直接录制mp3格式音频,支持格式如…...
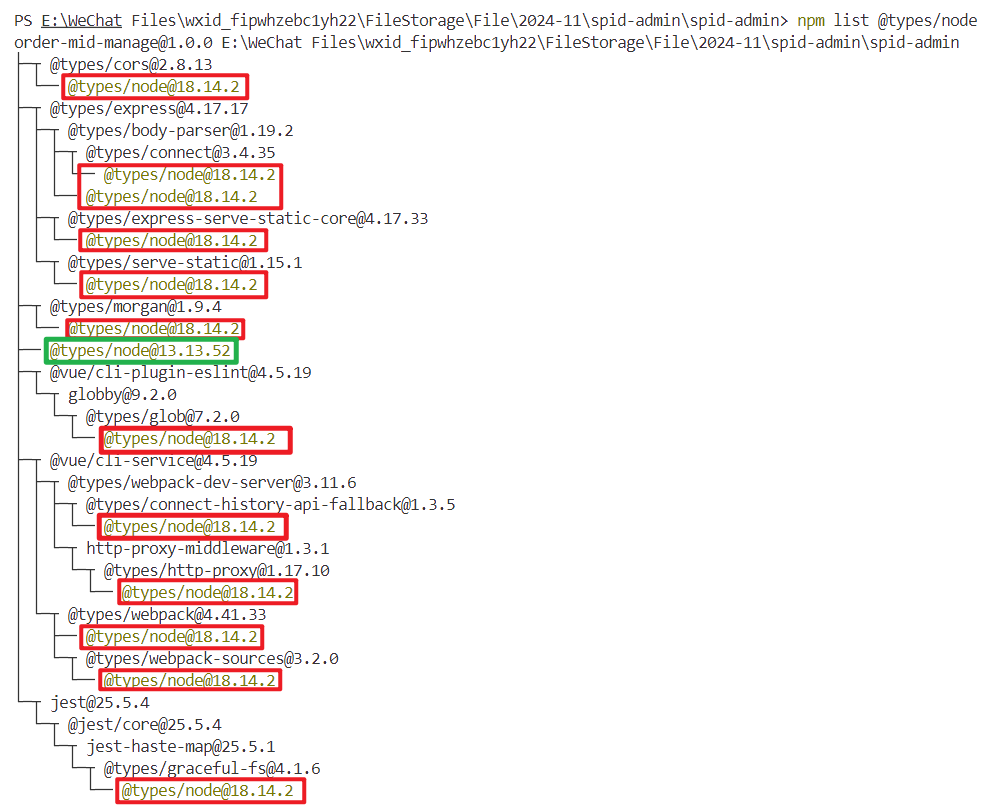
npm list @types/node 命令用于列出当前项目中 @types/node 包及其依赖关系
文章目录 作用示例常用选项示例命令注意事项 1、实战举例**解决方法**1. **锁定唯一的 types/node 版本**2. **清理依赖并重新安装**3. **设置 tsconfig.json 的 types**4. **验证 Promise 类型支持** **总结** npm list types/node 命令用于列出当前项目中 types/node 包及其…...

信用评分中的算法公平性:从理论到实践的全面解析
1. 项目概述:当信用评分遇上算法公平性在金融科技领域,信用评分模型早已不是新鲜事物。从传统的逻辑回归到如今复杂的梯度提升树和神经网络,机器学习模型凭借其强大的预测能力,已经成为银行和金融机构进行信贷决策、管理风险的核心…...

ContextMenuManager:三步彻底掌控Windows右键菜单的终极免费工具
ContextMenuManager:三步彻底掌控Windows右键菜单的终极免费工具 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否每天都要在Windows右键菜单中…...

Ubuntu 22.04 LTS下,UE5打包的程序报‘Vulkan设备找不到’?别急着重装驱动,先试试这个库文件修复法
Ubuntu 22.04 LTS下解决UE5 Vulkan设备报错的深度修复指南当你在Ubuntu 22.04 LTS上已经确认NVIDIA驱动安装成功(通过nvidia-smi验证),但Unreal Engine 5打包的程序仍然抛出"Vulkan设备找不到"的错误时,问题往往比表面看…...

机器人数据采集路径优化:用最近邻算法高效求解高维相空间TSP
1. 项目概述与核心问题在机器人控制,尤其是对精度要求极高的领域,比如手术机器人,我们常常面临一个看似简单实则棘手的问题:如何让机器人高效地完成一系列指定动作,以收集用于训练机器学习模型的数据。这听起来像是“让…...

深入理解Java String不可变性
前言 在现代软件开发中,深入理解Java String不可变性是一个非常重要的技术点。本文将从原理到实践,带你深入理解这一技术,并通过完整的代码示例帮助你快速掌握核心知识点。 核心概念 基本原理 深入理解Java String不可变性的核心在于理解其底…...

机器学习加速格点QCD计算:从强子真空极化到重子质量修正
1. 项目概述:当格点QCD遇上机器学习在格点量子色动力学(Lattice QCD)的计算世界里,我们这些常年跟海量数据和超级计算机打交道的人,最头疼的问题之一就是“噪声”。这可不是实验室里嗡嗡响的那种声音,而是统…...

昇腾CANN ops-math LayerNorm:数值稳定性与 Warp Reduce 优化实战
LayerNorm 是现代神经网络的标配——Transformer 的每一层都有它。公式简单:μ mean(x), σ var(x), y (x-μ) / √(σε) * γ β。但 NPU 上的实现有三个陷阱:FP16 精度下 mean/variance 计算不稳定、Warp reduce 的并行归约需要跨 lane 同步、反向…...

基于KDTree的机器学习壁面函数:提升CFD湍流模拟精度与效率
1. 项目概述在计算流体力学(CFD)的湍流模拟领域,尤其是处理高雷诺数工程流动时,近壁面区域的精确建模一直是个核心挑战。直接对粘性底层进行网格解析(Wall-Resolved LES/DES)虽然精度高,但计算成…...

UE5.3与VS2022编译配置深度优化指南
1. 为什么UE5项目在VS2022里编译慢、报错多、改个头文件就全量重编?我第一次把团队刚升级的UE5.3项目拖进Visual Studio 2022时,整整等了17分42秒才完成首次编译——不是链接,是编译。中间还弹出6个“LNK2019未解析外部符号”、3个“C2039‘G…...

五轴联动机床:什么叫真正做出来了,什么叫组装贴牌
机床厂的数量从来不是问题。打开任何一份机床企业名录,数以千计的厂商密密麻麻排在那里,官网上都写着"五轴联动"“高精度数控”“航空级加工”。但做五轴联动整机与自主数控系统的工厂,放到整个行业里只是极小的一部分;…...