2024华为OD机试真题---中文分词模拟器
华为OD机试中的中文分词模拟器题目,通常要求考生对给定的不包含空格的字符串进行精确分词。这个字符串仅包含英文小写字母及英文标点符号(如逗号、分号、句号等),同时会提供一个词库作为分词依据。以下是对这类题目的详细解析
一、题目描述
给定一个连续不包含空格的字符串Q,该字符串仅包含英文小写字母及英文标点符号(逗号、分号、句号),同时给定词库,对该字符串进行精确分词。
说明:
1、精确分词:字符串分词后,不会出现重复。即"ilovechina",不同词库可分割为"i,love,china",“ilove,china”,不能分割出现重的"i,ilove,china",i出现重复。
2、标点符号不成词,仅用于断句。
3、词库:根据外部知识库统计出来的常用词汇例:
dictionary=["i","ove","china","lovechina","ilove"]
4、分词原则:采用分词顺序优先且最长匹配原则
- “ilovechina”,假设分词结果 [i,ilove,lo,love,ch,china,lovechina],则输出 [ilove,china]
- 错误输出:[i,lovechina],原因:“ilove”>优先于"lovechina" 成词
- 错误输出:[i,love,china],原因:“ilove”>"i"遵循最长匹配原则
二、输入描述
第一行输入待分词语句"ilovechina"
字符串长度限制:0<length<256
第二行输入中文词库
i,love,china,ch,na,ve,lo,this,is,this,word
词库长度限制:1<length<100000
三、输出描述
按顺序输出分词结果"i,love,china”
用例1
输入
ilovechina
i,love,china,ch,na,ve,lo,this,is,the,word
输出
i,love,china
说明
无
用例2
输入
iat
i,love,china,ch,na,ve,lo,this,is,the,word,beauti,tiful,ful
输出
i a,t
四、分词原则
- 精确分词:字符串分词后,不会出现重叠的情况。
- 分词顺序:按照字符串从左到右的顺序进行分词。
- 最长匹配:在分词时,优先匹配词库中最长的符合条件的词汇。
- 标点符号:标点符号不成词,仅用于断句。
五、代码实现
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Scanner;
import java.util.Set;public class PreciseSegmentation {public static void main(String[] args) {// 使用Scanner读取输入Scanner scanner = new Scanner(System.in);// 读取待分词的句子String Q = scanner.nextLine();// 读取词库字符串String dictionaryStr = scanner.nextLine();// 将词库转换为集合Set<String> dictionary = new HashSet<>(Arrays.asList(dictionaryStr.split(",")));// 分词结果List<String> result = new ArrayList<>();// 当前处理的起始位置int start = 0;// 开始分词处理while (start < Q.length()) {// 初始化结束位置int end = start + 1;// 用于存储最长匹配的词String longestMatch = null;// 寻找最长匹配的词while (end <= Q.length()) {// 获取子字符串String sub = Q.substring(start, end);// 检查子字符串是否在词库中if (dictionary.contains(sub)) {// 更新最长匹配的词if (longestMatch == null || sub.length() > longestMatch.length()) {longestMatch = sub;}}// 移动结束位置end++;}// 如果找到匹配的词,将其加入结果列表if (longestMatch != null) {result.add(longestMatch);// 更新起始位置start += longestMatch.length();} else {// 如果没有找到匹配的词,将单个字符加入结果列表result.add(Q.substring(start, start + 1));// 移动起始位置start++;}}// 输出结果System.out.println(String.join(",", result));}
}六、解题思路
解题思路如下:
-
输入读取:
- 使用
Scanner类从标准输入读取两行数据。第一行是待分词的句子Q,第二行是词库字符串dictionaryStr。
- 使用
-
词库转换:
- 将词库字符串
dictionaryStr按逗号分隔,转换为String类型的列表。 - 使用
HashSet来存储词库中的词汇,以便进行快速的查找操作。这是因为HashSet的查找时间复杂度为O(1),而列表的查找时间复杂度为O(n)。
- 将词库字符串
-
分词处理:
- 初始化一个空列表
result来存储分词结果。 - 初始化一个变量
start来记录当前处理的起始位置,初始值为0。 - 使用一个外层
while循环来遍历整个待分词的句子Q,直到start变量的值等于句子的长度。
- 初始化一个空列表
-
最长匹配查找:
- 在外层循环内部,初始化一个变量
end来表示当前查找的结束位置,初始值为start + 1。 - 初始化一个变量
longestMatch来存储当前找到的最长匹配的词汇,初始值为null。 - 使用一个内层
while循环来查找从start到end之间的所有可能的子字符串,并检查它们是否在词库中。 - 如果找到一个匹配的词汇,并且它的长度大于当前
longestMatch的长度(或者longestMatch为null),则更新longestMatch的值。 - 每次内层循环结束时,
end的值都会增加1,以继续查找下一个可能的子字符串。
- 在外层循环内部,初始化一个变量
-
结果处理:
- 当内层循环结束后,检查
longestMatch是否为null。 - 如果
longestMatch不为null,说明找到了一个匹配的词汇,将其添加到result列表中,并更新start的值为start + longestMatch.length(),以便继续处理下一个词汇。 - 如果
longestMatch为null,说明在当前位置没有找到匹配的词汇,此时将当前位置的单个字符作为一个词汇添加到result列表中,并将start的值增加1。
- 当内层循环结束后,检查
-
输出结果:
- 使用
String.join(",", result)将result列表中的词汇用逗号连接起来,形成一个字符串。 - 输出该字符串作为分词结果。
- 使用
这个解题思路遵循了最长匹配原则和分词顺序优先的原则,确保了分词结果的准确性和合理性。同时,通过使用HashSet来存储词库中的词汇,提高了查找效率。
七、运行示例解析
运行示例解析如下:
输入:
- 待分词的句子:
ilovechina - 词库字符串:
i,love,china,ch,na,ve,lo,this,is,the,word
步骤解析:
-
初始化:
Q = "ilovechina"- 词库字符串被分割并存储在
HashSet中,即dictionary = {i, love, china, ch, na, ve, lo, this, is, the, word} result = [](空列表,用于存储分词结果)start = 0(当前处理的起始位置)
-
分词处理:
- 外层
while循环开始,条件是start < Q.length(),即start < 9。
第一次外层循环:
end = start + 1 = 1- 内层
while循环开始,条件是end <= Q.length(),即1 <= 9。sub = Q.substring(0, 1) = "i",dictionary.contains("i")返回true。- 更新
longestMatch = "i"。 end递增为2。sub = Q.substring(0, 2) = "il",dictionary.contains("il")返回false。end递增为3。sub = Q.substring(0, 3) = "ilo",dictionary.contains("ilo")返回false。end递增为4。sub = Q.substring(0, 4) = "ilov",dictionary.contains("ilov")返回false。end递增为5。sub = Q.substring(0, 5) = "ilove",dictionary.contains("ilove")返回false。end递增为6。sub = Q.substring(0, 6) = "ilovec",dictionary.contains("ilovec")返回false。end递增为7。sub = Q.substring(0, 7) = "ilovech",dictionary.contains("ilovech")返回false。end递增为8。sub = Q.substring(0, 8) = "ilovechi",dictionary.contains("ilovechi")返回false。end递增为9。sub = Q.substring(0, 9) = "ilovechina",dictionary.contains("ilovechina")返回false(虽然这不是词库中的词,但因为我们是从头开始找,所以会继续尝试更短的词)。- 内层循环结束,因为
end已经超过Q.length()。
longestMatch = "i",将其加入result,即result = ["i"]。- 更新
start = 1。
后续的外层循环(类似地处理):
start = 1时,找到longestMatch = "love",加入result,即result = ["i", "love"]。start = 6时,找到longestMatch = "china",加入result,即result = ["i", "love", "china"]。- 此时
start = 11,已经超过Q.length(),外层循环结束。
- 外层
-
输出结果:
- 使用
String.join(",", result)将result列表中的词汇用逗号连接起来,得到"i,love,china"。 - 输出该字符串。
- 使用
最终输出:
i,love,china
注意:在这个例子中,尽管词库中有一些无关的词(如ch, na, ve, lo等),但它们并没有影响分词的结果,因为分词算法总是尝试找到最长的匹配词。
相关文章:

2024华为OD机试真题---中文分词模拟器
华为OD机试中的中文分词模拟器题目,通常要求考生对给定的不包含空格的字符串进行精确分词。这个字符串仅包含英文小写字母及英文标点符号(如逗号、分号、句号等),同时会提供一个词库作为分词依据。以下是对这类题目的详细解析 一…...

Kubernetes网络揭秘:从DNS到核心概念,一站式综述
文章目录 一.overlay vs underlayL2 underlayL3 underlay 二、calico vs flannel2.1 calico架构2.2 flannel架构 三、iptables四、Vxlan五、kubernetes网络架构综述六、DNS七、Kubernetes域名解析策略 一.overlay vs underlay overlay网络是在传统网络上虚拟出一个虚拟网络&am…...

C#封装EPPlus库为Excel导出工具
1,添加NUGet包 2,封装工具类 using OfficeOpenXml; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Reflection;namespace GMWPF.utils {public class ExcelUtil<T>{/// <summary>///…...

【LeetCode】【算法】461. 汉明距离
LeetCode 461. 汉明距离 题目描述 两个整数之间的 汉明距离 指的是这两个数字对应二进制位不同的位置的数目。 给你两个整数 x 和 y,计算并返回它们之间的汉明距离。 思路 思路:将两个数转成二进制后求异或结果,就是它们之间的汉明距离。…...
)
Docker Compose部署Rabbitmq(延迟插件已下载)
整个工具的代码都在Gitee或者Github地址内 gitee:solomon-parent: 这个项目主要是总结了工作上遇到的问题以及学习一些框架用于整合例如:rabbitMq、reids、Mqtt、S3协议的文件服务器、mongodb github:GitHub - ZeroNing/solomon-parent: 这个项目主要是…...

生信技能62 - 常用机器学习算法的R语言实现
1. 加载R包和数据 # 安装R包, 是否update统一选择不更新n BiocManager::install("caret") BiocManager::install("randomForest") BiocManager::install("gbm") BiocManager::install("kernlab") BiocManager::install("glmnet…...

【3D Slicer】的小白入门使用指南二
3D Slicer中DICOM数据加载和三维可视化 任务 数据集下载和解压缩 加载和查看DICOM数据 1)将第一个数据集文件夹,整个往3Dslicer左侧拖动即可 得到 2)选中右侧patient 1就可显示出该患者的基本信息 (第二行蓝色是研究信息;第三行蓝色是序列信息)...

部署搭建AI相关项目时,不用魔法也能轻松自动下载所需大模型
背景 最近搭建了许多AI相关的自动化服务,有些时候因为国内服务器墙了 huggingface.co 访问,导致一些依赖文件和模型下载不下来,手动去下载又特别麻烦,今天教你一个小招,轻松解决这个问题 开搞 1:首先确定…...

zookeeper之节点基本操作
ZooKeeper是一个分布式协调服务,它的节点操作包括创建、查询、更新、删除等,以下是ZooKeeper节点的基本操作介绍: 1. 创建节点 持久节点(Persistent Node) 含义:持久节点是ZooKeeper中最基本的节点类型。创建后,除非显式删除,否则它将一直存在于ZooKeeper树中,即使创…...
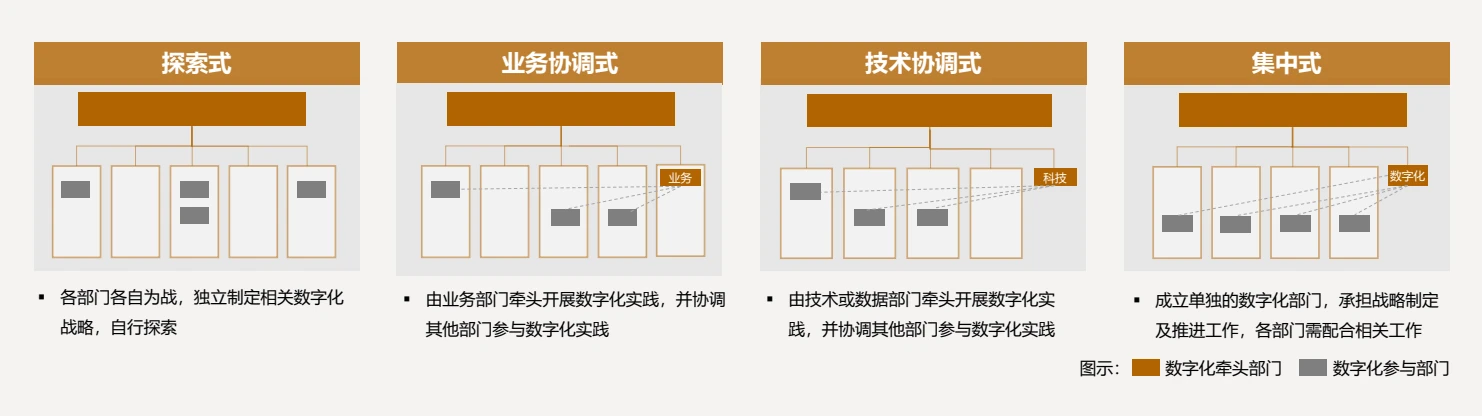
技术最好 ≠ 最适合:数字化转型切忌盲目追求最先进的技术
企业引入新兴技术时面临的挑战 企业在引入新兴技术时会面临一定挑战,根据调查结果显示,企业在引入新兴技术时做出决策的三个最重要考量因素分别是: 价格与投资回报 新兴技术成熟度 新兴技术与业务的适配性 不要盲目追求最先进的技术 企业…...

数字IC后端教程之Innovus hold violation几大典型问题
今天小编给大家分享下数字IC后端实现Physical Implementation过程中经常遇到的几个hold violation问题。每个问题都是小编自己在公司实际项目中遇到的。 数字后端实现静态时序分析STA Timing Signoff之min period violation Q1: 在Innouvs postCTS时序优化的log中我们经常会看…...

rust并发
文章目录 Rust对多线程的支持std::thread::spawn创建线程线程与 move 闭包 使用消息传递在线程间传送数据std::sync::mpsc::channel()for received in rx接收两个producer 共享状态并发std::sync::Mutex在多个线程间共享Mutex,使用std::sync::Arc 参考 Rust对多线程…...

力扣 最小路径和
又是一道动态规划基础例题。 题目 这道题可以类似不同路径。先把左上角格子进行填充,然后用一个数组去更新每走到一个格的数字总和,首先处理边界问题,把最左边的列只能由上方的行与原来的格子数值的和,同理,最上方的行…...

Scala中的可变Map操作:简单易懂指南 #Scala Map #Scala
引言 在编程中,Map是一种常见的数据结构,用于存储键值对。Scala提供了不可变Map和可变Map两种类型,它们在处理数据时有不同的特性和用途。本文将通过一个简单的示例,带你了解Scala中可变Map的基本操作,包括添加元素、…...

【go从零单排】XML序列化和反序列化
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 在 Go 语言中,处理 XML 数据主要使用 encoding/xml 包。这个包提供了…...

在 Oracle Linux 8.9 上安装Oracle Database 23ai 23.5
在 Oracle Linux 8.9 上安装Oracle Database 23ai 23.5 1. 安装 Oracle Database 23ai2. 连接 Oracle Database 23c3. 重启启动后,手动启动数据库4. 重启启动后,手动启动 Listener5. 手动启动 Pluggable Database6. 自动启动 Pluggable Database7. 设置开…...

在 Ubuntu 上安装 `.deb` 软件包有几种方法
在 Ubuntu 上安装 .deb 软件包有几种方法,可以使用命令行工具,也可以通过图形界面进行安装。以下是几种常见的安装方法: 方法 1:使用 dpkg 命令安装 .deb 包 打开终端。 使用 dpkg 命令安装 .deb 包: sudo dpkg -i /…...

一文了解Android本地广播
在 Android 开发中,本地广播(Local Broadcast)是一种轻量级的通信机制,主要用于在同一应用进程内的不同组件之间传递消息,而无需通过系统的全局广播机制。这种方法既可以提高安全性(因为广播仅在应用内传播…...

Ingress nginx 公开TCP服务
文章目录 背景搞起拓展( PROXY Protocol )参考 背景 公司业务繁多, HTTP、GRPC、TCP多种协议服务并存,Kubernetes流量入口复杂,所以萌生了通过LoadBalancer Ingress-nginx 的方式完全的结果入口流量,当然在高并发的场景下可以对…...

谷歌浏览器支持的开发者工具详解
谷歌浏览器(Google Chrome)是全球最受欢迎的网页浏览器之一,它不仅提供了快速、安全的浏览体验,还为开发者提供了强大的开发者工具。本文将详细介绍如何使用谷歌浏览器的开发者工具,并解答一些常见问题。(本…...

2025大厂Java后端面试:RAG高频考点【干货】
根据近期(2025-2026年)牛客网上字节、腾讯、阿里、快手、京东等大厂的Java后端面经,RAG(检索增强生成)已高频结合传统Java八股进行考察。📚 面试问题分类与总结1. 🏗️ RAG 基础概念与理解这是面…...

传统FPM项目怎么渐进式迁移到Swoole/Hyperf?
传统 FPM 项目渐进式迁移到 Swoole / Hyperf 完整方案下面是一份实战派迁移指南,不搞理想化"重写",而是一边赚钱一边换引擎。---一、先讲清楚:为啥要迁?要迁到哪?1.1 FPM 的痛点- 每个请求都要重新加载框架(Laravel 启动 30~80ms,Hyperf 启动后 0ms)- 不能保持长连…...

Python、BMA-Stacking融合LightGBM、GBDT、KNN多模型电商交易欺诈风险预警研究|附代码数据
全文链接:https://tecdat.cn/?p45916原文出处:拓端数据部落公众号封面:关于分析师在此对 Haoyang Ke 对本文所作的贡献表示诚挚感谢。他在浙江财经大学完成了数理统计专业的学习,专注机器学习、数据采集领域。他擅长 Python、R 语…...

为ClaudeCode配置Taotoken作为备用API解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为ClaudeCode配置Taotoken作为备用API解决访问限制 基础教程类,指导经常遇到ClaudeCode访问限制的开发者,如…...
)
MacBook卡顿想恢复出厂?别急着送修,试试Monterey自带的‘恢复出厂设置’(附机型支持清单)
MacBook系统卡顿自救指南:Monterey恢复出厂设置全解析 当你的MacBook开始出现响应迟缓、软件频繁崩溃或莫名卡顿的情况,很多用户的第一反应是考虑送修或寻找复杂的技术支持。然而,在macOS Monterey及后续版本中,苹果悄然引入了一项…...

Deepseek-V4-Flash-20260423 深度评测与实战指南
文章目录 ① 核心参数解析与架构初印象② 多轮对话响应速度与并发实测③ 复杂逻辑推理与代码生成质量解剖④ 长文本处理与关键信息提取案例⑤ 垂直领域知识准确性验证集锦⑥ 模型幻觉识别与能力边界测试⑦ 极端输入下的稳定性与避坑指南⑧ 不同场景下的性价比与选型建议 在开发…...

观测 TaoToken 在多模型间自动路由的稳定性与响应速度
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观测 TaoToken 在多模型间自动路由的稳定性与响应速度 在构建依赖大模型能力的应用时,服务的稳定性和响应速度是开发者…...

AI知识擦除:Gemini3.1Pro能否真正遗忘危险?
概念擦除:能否从 Gemini 3.1 Pro 中删除特定危险知识?——理性看待“遗忘”与“可控”在 2026 年的 AI 热点语境下,“可控”和“可验证”成为讨论主线。除了提升模型能力,人们也更关心另一件事:**当模型掌握了不希望被…...

优化缺陷密度,核心是从“事后救火”转向“全程预防”
优化缺陷密度,核心是从“事后救火”转向“全程预防”,通过系统化的流程和工具,在生产代码中构建 “计划-执行-检查-改进”的持续优化闭环。📈 第一步:测量与评估,建立基线测量缺陷密度:按质量阶…...

洛雪音乐音源完全指南:一键解锁全网高品质音乐资源
洛雪音乐音源完全指南:一键解锁全网高品质音乐资源 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否厌倦了在多个音乐平台间切换,只为寻找一首心仪的歌曲?…...