从0开始深度学习(28)——序列模型
序列模型是指一类特别设计来处理序列数据的神经网络模型。序列数据指的是数据中的每个元素都有先后顺序,比如时间序列数据(股票价格、天气变化等)、自然语言文本(句子中的单词顺序)、语音信号等。
1 统计工具
前面介绍了卷积神经网络架构,但是在处理序列数据时,需要新的神经网络架构,下面以股票价格为例:

我们用 x t x_{t} xt表示价格,其中 t t t表示时间步(time step),也就是在时间步 t t t时观察到的价格 x t x_{t} xt,我们通过下列公式来表示我们预测第 t t t日的价格:
x t ∼ P ( x t ∣ x t − 1 , … , x 1 ) . x_t \sim P(x_t \mid x_{t-1}, \ldots, x_1). xt∼P(xt∣xt−1,…,x1).
即,在已知 1 1 1 到 t − 1 t-1 t−1 的价格,求第 t t t 天的价格的概率分布。
1.1 自回归模型
为了实现这个预测,可以使用自回归模型:假设当前值 y t y_{t} yt 与过去的值 y t − 1 , y t − 2 , . . . y t − p y_{t-1} , y_{t-2} , ...y_{t-p} yt−1,yt−2,...yt−p 之间存在线性关系,一般形式为 :

其中:

大致分为两种策略:
①自回归模型: 假设在现实情况下相当长的序列 x t − 1 , … , x 1 x_{t-1}, \ldots, x_1 xt−1,…,x1可能是没价值的,因此我们只需要满足某个长度为 τ \tau τ的时间跨度, 即使用观测序列 x t − 1 , … , x t − τ x_{t-1}, \ldots, x_{t-\tau} xt−1,…,xt−τ。也就是说过长的历史序列可能并不必要,因此只需要关注较短的一段历史数据即可。因为只考虑观测值本身,所以叫自回归模型
②隐变量自回归模型: 即保留一些对过去观测的总结 h t h_{t} ht,这个“总结”是无法直观解释的,它是模型自助捕捉的内部关系依赖,然后同时更新预测值 x ^ t \hat{x}_t x^t和 h t h_t ht,即变为下列式子: x ^ t = P ( x t ∣ h t ) 和 h t = g ( h t − 1 , x t − 1 ) \hat{x}_t = P(x_t \mid h_{t}) 和h_t = g(h_{t-1}, x_{t-1}) x^t=P(xt∣ht)和ht=g(ht−1,xt−1)由于 h t h_{t} ht h t h_{t} ht从未被观测到,这类模型也被称为隐变量自回归模型,这里做出一个假设,即序列本身的动力学(数据随时间演变的方式)不会改变,意味着我们可以用过去的数据来推断未来的趋势,因为我们假定基本的动态规则是一致的。因此,整个序列的概率值可以表示为一系列条件概率的乘积:
P ( x 1 , … , x T ) = ∏ t = 1 T P ( x t ∣ x t − 1 , … , x 1 ) . P(x_1, \ldots, x_T) = \prod_{t=1}^T P(x_t \mid x_{t-1}, \ldots, x_1). P(x1,…,xT)=t=1∏TP(xt∣xt−1,…,x1).
注意,如果我们处理的是离散的对象(如单词), 而不是连续的数字,则上述的考虑仍然有效。我们需要使用分类器而不是回归模型来估计
1.2 马尔可夫模型
马尔可夫条件: 在自回归模型中,如果 t t t 时刻的数值,只与 x t − 1 , … , x t − τ x_{t-1}, \ldots, x_{t-\tau} xt−1,…,xt−τ 有关,而不是整个过去的序列,则称其满足马尔可夫条件。
如果 τ = 1 \tau = 1 τ=1 ,则得到了一个一阶马尔可夫模型, P ( x ) P(x) P(x)由如下公式表示:
P ( x 1 , … , x T ) = ∏ t = 1 T P ( x t ∣ x t − 1 ) 当 P ( x 1 ∣ x 0 ) = P ( x 1 ) . P(x_1, \ldots, x_T) = \prod_{t=1}^T P(x_t \mid x_{t-1}) \text{ 当 } P(x_1 \mid x_0) = P(x_1). P(x1,…,xT)=t=1∏TP(xt∣xt−1) 当 P(x1∣x0)=P(x1).
若当假设 x t x_t xt 仅是离散值时,可以使用动态规划可以沿着马尔可夫链精确地计算结果。
2 训练、预测
下面我们将用一个正弦函数和一些噪声生成1000个序列数据,并使用自回归模型进行训练和预测
2.1 生成数据
import torch
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import TensorDataset, DataLoaderT=1000
time=torch.arange(1,T+1,dtype=torch.float32)
x=torch.sin(0.01*time)+torch.normal(0,0.2,(T,))
# 绘制折线图
plt.plot(time, x)
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('Time Series Data')
plt.show()
运行结果

2.2 构造数据集
我们是准备用 y t = F ( X t ) y_t=F(X_t) yt=F(Xt),其中 X t = [ x t − τ , … , x t − 1 ] X_t= [x_{t-\tau}, \ldots, x_{t-1}] Xt=[xt−τ,…,xt−1],我们这里假设 τ = 4 \tau=4 τ=4,即用前四个数据来预测下一个数据,但是这样的话,前 4 4 4 个数据就没有历史样本去描述了,一般的做法是直接舍弃,或者用零序列去填充。
这里我们用600个数据进行训练,剩余的用于预测。
构建数据集时,使用滑动窗口去构建:

# 构造数据集
tau=4# 初始化特征矩阵,因为前四个值就是当前值的特征
features = torch.zeros((T - tau, tau))
for i in range(T - tau): # 用滑动窗口进行构建features[i,:]=x[i:tau+i]
print('features:',features.shape)
print(features[:5])labels = x[tau:].reshape((-1, 1))
print('labels:',labels.shape)
print(labels[:5])batch_size = 16
n = 600 # 只有前600个样本用于训练
dataset = TensorDataset(features[:n], labels[:n])
train_iter = DataLoader(dataset, batch_size=batch_size, shuffle=False)
运行结果

2.3 构造模型进行训练
# 构造模型
def init_weights(m):if type(m)==nn.Linear:nn.init.xavier_uniform_(m.weight)def net():net=nn.Sequential(nn.Linear(4,10),nn.ReLU(),nn.Linear(10,1))net.apply(init_weights)return net# 评估模型在给定数据集上的损失
def evaluate_loss(net, data_iter, loss):"""评估模型在给定数据集上的损失"""net.eval() # 设置模型为评估模式total_loss = 0.0with torch.no_grad(): # 不计算梯度for X, y in data_iter:y_hat = net(X)l = loss(y_hat, y)total_loss += l.sum().item() # 计算总损失net.train() # 恢复模型为训练模式return total_loss / len(data_iter.dataset)loss=nn.MSELoss(reduction='none')
lr=0.01
net=net()
optimzer=torch.optim.Adam(net.parameters(),lr)
loss_sum=[]
num_epoch=20
def train(net,num_epoch,train_iter,loss,optimzer,loss_sum):for epoch in range(num_epoch):for x,y in train_iter:optimzer.zero_grad()l=loss(net(x),y)l.sum().backward()optimzer.step()temp=evaluate_loss(net,train_iter,loss)loss_sum.append(temp)print("epoch ",epoch+1,": loss:",temp)train(net,num_epoch,train_iter,loss,optimzer,loss_sum)# 绘制折线图
plt.plot(range(num_epoch), loss_sum)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
运行结果

2.4 预测
# 使用模型进行预测
def predict(net, data_iter):net.eval() # 设置模型为评估模式predictions = []with torch.no_grad(): # 不计算梯度for X, y in data_iter:y_hat = net(X)predictions.extend(y_hat.numpy())net.train() # 恢复模型为训练模式return predictions# 获取测试集的预测结果
predictions = predict(net, test_iter)# 绘制预测结果与真实值的对比图
true_values = labels[n:].numpy()
plt.plot(true_values, label='True Values')
plt.plot(predictions, label='Predictions')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
运行结果

2.5 多步预测
# 多步预测
def multistep_predict(net, data_iter, steps):net.eval() multistep_predictions = []with torch.no_grad(): for X, y in data_iter:current_features = X.clone()for _ in range(steps):'''在每一步中,模型用 current_features 作为输入,并预测出 y_hat。然后将 y_hat 拼接到 current_features 的末尾,同时移除 current_features 的第一个时间步,保持输入长度不变。这样,y_hat 成为下一步的输入'''y_hat = net(current_features)current_features = torch.cat([current_features[:, 1:], y_hat], dim=1)multistep_predictions.extend(y_hat.numpy())net.train() return multistep_predictions# 获取测试集的不同步数的多步预测结果
steps = [4, 16, 32]
multistep_predictions = {step: multistep_predict(net, test_iter, step) for step in steps}# 绘制结果
plt.figure(figsize=(12, 6)) # 设置图像的宽度为12英寸,高度为6英寸
plt.plot(true_values, label='True Values')
plt.plot(ones_predictions, label='1-step Predictions')
for step, preds in multistep_predictions.items():plt.plot(preds, label=f'{step}-step Predictions')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()

上述的多步预测是迭代预测法,即用自己预测数据再去预测下一个数据,另一种方法是seq2seq,后面在介绍,迭代预测法如下图所示:

相关文章:
从0开始深度学习(28)——序列模型
序列模型是指一类特别设计来处理序列数据的神经网络模型。序列数据指的是数据中的每个元素都有先后顺序,比如时间序列数据(股票价格、天气变化等)、自然语言文本(句子中的单词顺序)、语音信号等。 1 统计工具 前面介绍…...

vue2使用 <component> 标签动态渲染不同的表单组件
在后台管理系统中,涉及到大量表单信息的修改和新增。现在想对模板中代码做一些简单的优化。 1. 使用 v-for 循环简化表单项 可以将表单项的定义提取到一个数组中,然后使用 v-for 循环来生成这些表单项。这将减少重复代码,提高可维护性。 2…...

C#实现在windows上实现指定句柄窗口的指定窗口坐标点击鼠标左键和右键的详细情况
在Windows编程中,有时我们需要对特定窗口进行操作,比如模拟鼠标点击。这在自动化测试、脚本编写或某些特定应用程序的开发中尤为常见。本文将深入探讨如何在C#中实现对指定句柄窗口进行鼠标点击操作,包括左键和右键点击。我们会从理论背景开始…...

探索Python自动化新境界:Invoke库的神秘面纱
文章目录 **探索Python自动化新境界:Invoke库的神秘面纱**第一部分:背景介绍第二部分:Invoke库是什么?第三部分:如何安装Invoke库?第四部分:Invoke库函数使用方法1. 定义任务2. 执行任务3. 任务…...

CSS样式实现3D效果
CSS 3D效果是通过CSS3中的transform和perspective等属性来实现的。这些属性允许你创建具有深度感和三维外观的网页元素。以下是一些常见的CSS 3D效果及其实现方法: 1. 3D旋转(Rotate) 使用transform: rotateX(), rotateY(), rotateZ()来分别…...

华为eNSP:MSTP
一、什么是MSTP? 1、MSTP是IEEE 802.1S中定义的生成树协议,MSTP兼容STP和RSTP,既可以快速收敛,也提供了数据转发的多个冗余路径,在数据转发过程中实现VLAN数据的负载均衡。 2、MSTP可以将一个或多个VLAN映射到一个Inst…...

modbus协议 Mthings模拟器使用
进制转换 HEX 16进制 (0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F表示0-15) dec 10进制 n(16进制) -> 10 abcd.efg(n) d*n^0 c*n^1 b*n^2 a*n^3 e*n^-1 f*n^-2 g*n^-3(10) 10 -> n(16进制) Modbus基础概念 高位为NUM_H&…...

内网安全-代理技术-socket协议
小迪安全网络架构图: 背景:当前获取window7 出网主机的shell。 1.使用msf上线,查看路由 run autoroute -p 添加路由: run post/multi/manage/autoroute 使用socks模块开启节点,作为流量跳板 msf6 exploit(multi/ha…...

选择排序(C语言)
一、步骤 选择排序的基本思想:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。 1.首先,我们先建立一个乱序数组,如࿱…...
✍Qt自定义带图标按钮
✍Qt自定义带图标按钮 📝问题引入 近段时间的工作中,有遇到这样一个需求 📝: 一个按钮,有normal、hover、pressed三种状态的样式,并且normal和hover样式下,字体颜色和按钮图标不一样。 分析…...

【Git】如何在 Git 项目中引用另一个 Git 项目:子模块与子树合并
如何在 Git 项目中引用另一个 Git 项目:子模块与子树合并 在进行软件开发时,我们经常会遇到需要将一个 Git 项目(B 项目)引用到另一个 Git 项目(A 项目)的情况。这种需求通常出现在以下场景: …...
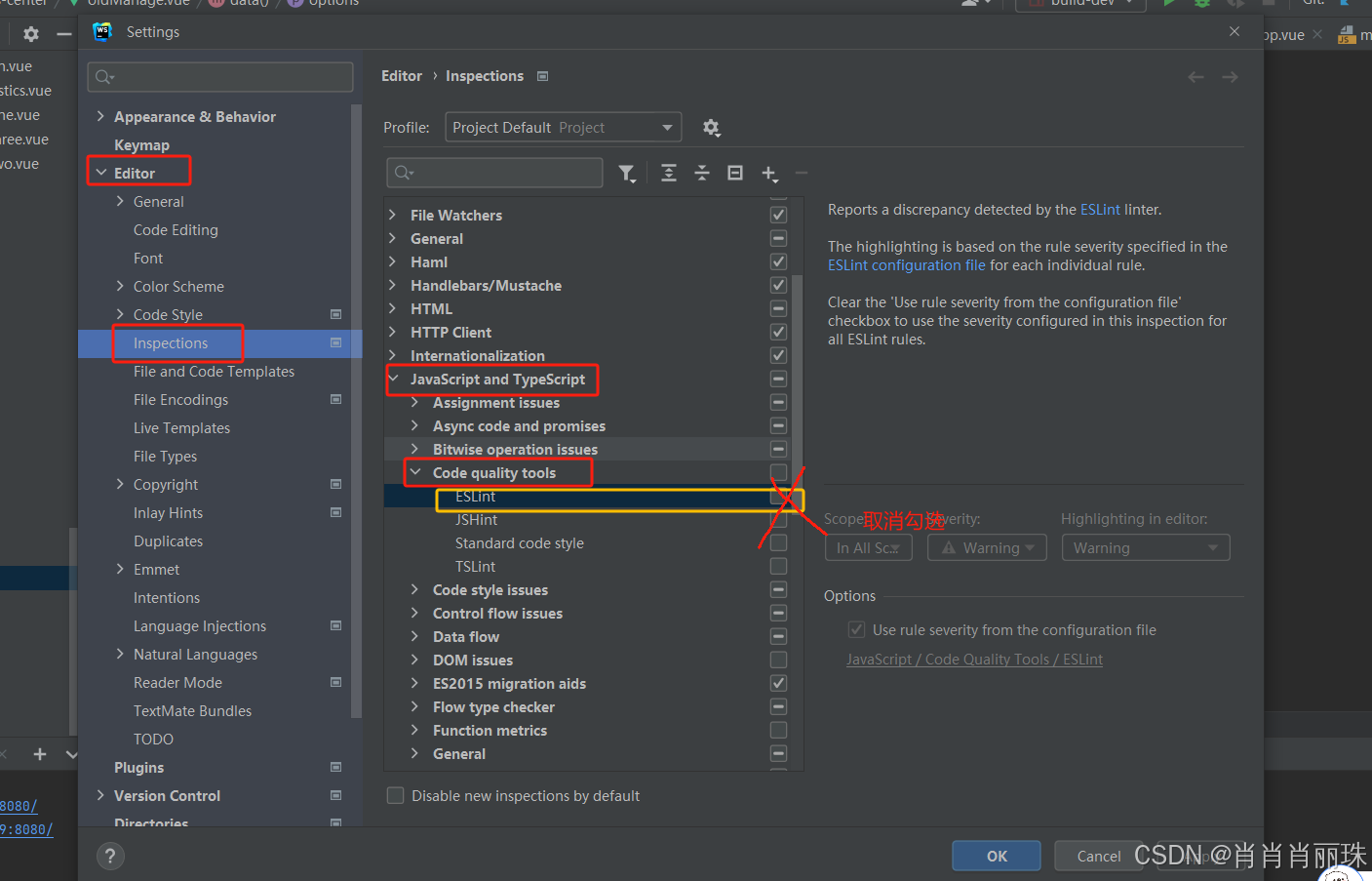
webstorm 打开prettier的项目代码后面会出现红色的波浪线
效果如图所有代码后面都有红色的波浪线。 解决File-Settings 找到Editor下面的inspections ...按照图示取消勾选ESLint再点Apply ok...

用 Python 从零开始创建神经网络(二):第一个神经元的进阶
第一个神经元的进阶 引言1. Tensors, Arrays and Vectors:2. Dot Product and Vector Additiona. Dot Product (点积)b. Vector Addition (向量加法) 3. A Single Neuron with NumPy4. A Layer of Neurons with NumPy5…...

一、文心一言问答系统为什么要分对话,是否回学习上下文?二、文心一言是知识检索还是大模型检索?三、文心一言的词向量、词语种类及多头数量
目录 一、文心一言问答系统为什么要分对话,是否回学习上下文? 二、文心一言是知识检索还是大模型检索? 三、文心一言的词向量、词语种类及多头数量 一、文心一言问答系统为什么要分对话,是否回学习上下文? 文心一言问答系统分对话的原因在于其设计初衷就是提供一个交互…...

C++ 的协程
现代C中的协程(coroutines)是C20引入的一项重大语言特性,它们允许函数在执行过程中可以暂停并稍后从暂停点恢复执行。协程提供了一种控制流机制,使得函数可以包含多个入口点和出口点,这与传统的单入口、单出口的函数模…...

D3的竞品有哪些,D3的优势,D3和echarts的对比
D3 的竞品 ECharts: 简介: ECharts 是由百度公司开发的一款开源的 JavaScript 图表库,提供了丰富的图表类型和高度定制化的配置选项。特点: 易于使用,文档详尽,社区活跃,支持多种图表类型(如折线图、柱状图、饼图、散点…...
)
大厂计算机网络高频八股文面试题及参考答案(面试必问,持续更新)
目录 请简述 TCP 和 UDP 的区别? TCP 和 UDP 分别对应的常见应用层协议有哪些? UDP 的优缺点是什么?它适用于哪些场景? UDP 如何实现可靠传输? 请简述 HTTP 和 HTTPS 的区别? HTTP 协议的工作原理是什么? HTTP 状态码有哪些常见的类型及其含义? HTTP 哪些常用的…...

【bayes-Transformer-GRU多维时序预测】多变量输入模型。matlab代码,2023b及其以上
% 1. 数据准备 X_train 训练数据输入; Y_train 训练数据输出; X_test 测试数据输入; % 2. 模型构建 inputSize size(X_train, 2); numHiddenUnits 100; numResponses 1; layers [ … sequenceInputLayer(inputSize) biLSTMLayer(numHiddenUnits, ‘OutputMode’, ‘se…...

动手学深度学习69 BERT预训练
1. BERT 3亿参数 30亿个词 在输入和loss上有创新 两个句子拼起来放到encoder–句子对 cls-class分类 sep-seperate 分隔符 分开每个句子 告诉是哪个句子 两个句子给不同的向量 位置编码不用sin cos, 让网络自己学习 bert–通用任务 encoder 是双向的,…...

【2024软考架构案例题】你知道 Es 的几种分词器吗?Standard、Simple、WhiteSpace、Keyword 四种分词器你知道吗?
👉博主介绍: 博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家,WEB架构师,阿里云专家博主,华为云云享专家,51CTO 专家博主 ⛪️ 个人社区&#x…...

CANN-ATB多卡推理-昇腾NPU上Llama70B怎么切到8张卡
CANN-ATB多卡推理-昇腾NPU上Llama70B怎么切到8张卡 Llama2-70B 的权重 140GB,单张 Atlas 800I A2 的 64GB 显存放不下。ATB 的多卡推理用 Tensor Parallel 把模型切到多张 NPU 上,每张卡只存 1/N 的权重和 KV Cache。 Tensor Parallel 的切法 Llama2-70B…...

Rust技术周刊 2026年第16周
阅读原文: https://mp.weixin.qq.com/s/9en-gxsNB544aG6hgkwJVQ 本周 Rust 生态亮点:GPU 计算突破(KAIO 达 cuBLAS 92.5%、flodl 多 GPU 训练),Tokio 异步优化实战频出,扩展标准库路线图发布,Rust 进入 Pix…...

零极点分析:从系统稳定性到滤波器设计的核心工程工具
1. 项目概述:从“系统行为”的根源说起在信号处理、控制理论乃至电路设计的日常工作中,我们常常需要面对一个核心问题:如何预测、分析和设计一个系统的动态行为?无论是设计一个能稳定跟踪目标的控制器,还是优化一个音频…...

别再手动开两个终端了!群晖Docker部署MCSM面板后,配置Systemd服务实现开机自启动详解
群晖Docker部署MCSM面板的终极运维方案:Systemd服务配置全指南 在家庭服务器和小型私有云环境中,Minecraft服务器的管理一直是个既有趣又充满挑战的话题。MCSM面板作为一款开源的Minecraft服务器管理工具,凭借其友好的Web界面和丰富的功能&am…...

CANN/pypto:Tensor构造函数
pypto.Tensor构造函数 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Atlas A3 训练系列产品/Atlas A3 推理系列产品…...
)
玻璃材质提示词失效率高达67%?2024最新Glass Prompt Framework v3.0(含Cinema4D材质参数→MJ语义映射表)
更多请点击: https://kaifayun.com 第一章:玻璃材质提示词失效率的行业现状与归因分析 在当前AIGC图像生成领域,“glass material”(玻璃材质)类提示词的失效问题已成高频痛点。多项基准测试显示,主流多模…...

野兽派不是乱来:拆解Midjourney V6中色彩暴力、笔触失序与构图反叛的5层参数逻辑
更多请点击: https://kaifayun.com 第一章:野兽派不是乱来:Midjourney V6的美学暴动宣言 Midjourney V6 不是一次平滑迭代,而是一场蓄谋已久的视觉政变——它将“语义精确性”与“风格不可预测性”焊死在同一张提示词底片上。当 …...

远程会议还在发文档改来改去?我用 Rustpad 搭了个协作平台彻底解决
前言 远程会议开到一半,需要共同修订一份文档或代码提纲,这种场景估计不少人经历过。方案来来去去就那几个:发邮件等反馈、微信来回传文件、用腾讯文档但要登录账号……每种都有各自的鸡肋之处。后来我自己琢磨出一套更顺手的方案࿱…...
)
为什么你的ElevenLabs四川话输出总像“普通话+口音”?3步声学特征解耦法让韵律自然度提升2.8倍(附Python声谱可视化代码)
更多请点击: https://intelliparadigm.com 第一章:为什么你的ElevenLabs四川话输出总像“普通话口音”? ElevenLabs 当前并未提供原生四川话(西南官话成渝片)语音模型,其所谓“方言支持”实为在标准普通话…...

6款优质降AIGC平台 降痕效果拉满
写论文时不断攀升的AIGC率让人焦虑不已?别担心,这里整理了6款高效实用的降AIGC工具,堪称应对AI痕迹问题的"得力助手"。它们能有效识别并消除AI生成特征,降痕能力出众,助你轻松通过查重审核,彻底摆…...