Elasticsearch 和 Kibana 8.16:Kibana 获得上下文和 BBQ 速度并节省开支!
作者:来自 Elastic Platform Product Team

Elastic Search AI 平台(Elasticsearch、Kibana 和机器学习)的 8.16 版本包含大量新功能,可提高性能、优化工作流程和简化数据管理。
- 使用更好的二进制量化 (Better Binary Quantization - BBQ) 和生成式 AI (GenAI) 来提高热度:向量搜索中速度快、精度高、成本节省惊人
- Elasticsearch 的新 BBQ 算法重新定义了向量量化 — 提高查询速度、排名精度和成本效率。与乘积量化 (product quantization - PQ) 等替代方案相比,实现超过 90% 的召回率,延迟更低,并将 RAM 使用率降低 95%。
- Kibana 获得上下文:探索更智能的数据调查的力量
- 得益于其可扩展的上下文架构,Kibana Discover 可以动态适应你正在分析的数据类型。节省时间并提高生产力,使数据探索比以往更顺畅。
- 查询演变:Elasticsearch 查询语言 (ES|QL) 中的快速跟踪、智能堆栈和地理黑客
- 借助 Elastic 的三个新功能(推荐查询、快速距离排序和按聚合过滤),在 ES|QL 中解锁更快、更轻松、更灵活的查询。
深入了解这些更新和更多增强功能 - 所有这些都旨在提高速度、生产力和可用性。
Elastic 8.16 中还有什么新功能?查看 8.16 公告帖子以了解更多信息 >>
GenAI 中的增强功能
在 8.16 中,Elastic 通过提高效率、可扩展性和可用性,继续在生成 AI 领域保持创新步伐。借助 BBQ,通过将内存需求减少高达 97%,实现顶级查询速度和成本节省。新推出的正式版推理 API 只需单击几下即可提供对 Elastic 强大的 AI 模型的生产就绪访问以及实时交互。借助自适应资源和灵活的分块策略,你可以在高需求时获得最佳性能,在空闲时则无需支付任何费用。
BBQ
Elasticsearch 推出了一个全新的稠密向量量化算法,在查询延迟、排名质量和所需计算资源(成本)方面取得了令人惊讶的效果。
这一算法的整体概念与 PQ(Product Quantization)相似,因为 Elasticsearch 会生成一个比原始向量小得多的预测向量。初始搜索使用的是预测向量,随后对结果进行过采样以进行重新排序,并使用原始向量对其进行排序,从而产生一组针对查询的结果。生成预测向量的方法与 PQ 完全不同,基于生成一个比原始向量更节省存储空间的比特向量,同时仍能预测正确的排名。
关键点在于,BBQ 能够提供优秀的排名效果,达到超过 90% 的召回率(相比于对原始向量进行暴力搜索/brute force),并且通过 2x 到 5x 的过采样优化查询结果。查询延迟也优于其他替代方法,包括 PQ。最重要的是,BBQ 的内存需求仅为使用 HNSW 算法处理原始向量时所需内存的 3% 到 5%,大幅降低了成本。如需了解算法的更详细描述和一些测试结果,请查阅这篇博客。
要使用它,只需将 index_options 定义为 bbq_hnsw 或 bbq_flat 类型,并且不要忘记使用 script_score 查询对完整向量进行过采样和重新排序。该功能仍处于技术预览阶段,我们暂时计划在即将发布的版本中简化使用它的体验。
推理 API 已正式发布
我们很高兴地宣布,推理 API 现已正式发布。从 8.16 开始,它现在被推荐用于生产,提供生产级稳定性、稳健性和性能。Elastic 的推理 API 集成了最先进的 AI 推理,同时提供了无与伦比的易用性。它将 Elastic 的 AI 语义搜索模型 — Elastic Learned Sparse EncodeR (ELSER) — 以及你的 Elastic 托管模型和越来越多的知名外部模型和任务整合在一起,形成统一、精简的语法,供你的 Elastic 向量数据库使用。与 semantic_text 或 Elastic 向量数据库支持的向量字段一起使用,你可以无缝轻松地执行 AI 搜索、重新排名和完成。
在 8.16 中,我们还添加了流式完成,以改进流程和实时交互以及 GenAI 体验。推理 API 为你提供最先进的 AI 推理,并提供更多服务和任务供你使用。
ELSER、e5、训练模型自适应资源和分块策略
推理需要计算资源,因此模型部署必须自动适应推理负载 — 在高负载期间(例如在摄取高峰和繁忙搜索时间)扩大规模,并在推理负载下降时缩小规模。到目前为止,你必须主动管理这部分,即使启用了 Elastic Cloud ML 自动扩展功能也是如此。你如何控制所涉及的所有参数,以便在任何时间点实现搜索和摄取需求的最佳成本/性能权衡?
从 8.16 开始,ELSER 和你在 Elastic 中使用的其他 AI 搜索和自然语言处理 (natural language processing - NLP) 模型会根据推理负载自动调整资源消耗 — 在高峰时段提供你需要的性能,并在低谷时段降低成本,在空闲时间一直降至零成本。e5 模型在 Elastic 的标准保修范围内。
此外,不需要复杂的配置。通过用户友好的用户体验,你只需单击一下即可配置针对搜索优化和针对采集优化的模型部署。优化配置在后台透明地进行。你还可以轻松规划更多动态资源以用于搜索或采集。我们将继续改善这种体验。结合 Elastic Cloud 上 ML 自动扩展的灵活性和 Elastic Cloud Serverless 的惊人弹性,你可以完全控制性能和成本。

在 8.16 中,你可以选择使用单词或基于序列的分块策略来与训练模型一起使用,还可以自定义最大大小和重叠参数。合适的分块策略可以带来收益,具体取决于你使用的模型、文本的长度和性质以及搜索查询的长度和复杂性。
多层嵌套的检索器和 GA
检索器是一种抽象,可从查询中返回排名靠前的文档。它旨在允许嵌套,并使定义查询变得更容易。检索器还允许在定义查询时具有更大的灵活性。自从我们在 8.14 中发布该功能以来,它变得越来越流行,我们收到了允许多层嵌套的请求。例如,用户请求通过 RRF 检索器组合密集向量(kNN 检索器)、ELSER 和 BM25(标准检索器),然后使用文本相似性重新排序检索器通过外部服务对它们进行重新排序,该检索器现已受支持。在 8.16 中,我们还添加了对其他搜索功能(如折叠结果和突出显示)的支持。并且我们已将包括 RRF 在内的检索器公开发布。
快速查询:ES|QL 的高级新功能
Elastic 8.16 引入了三个强大的新功能,旨在使查询更快、更轻松、更灵活。推荐的 ES|QL 查询提供即时指导,包括自动完成选项和预构建的查询建议,非常适合任何技能水平的用户。按距离排序现在可将快速地理搜索和前 N 个查询的性能提升高达 100 倍。通过每个聚合过滤,你可以为每个聚合定义唯一的过滤器,为你的分析带来精确度。
推荐的 ES|QL 查询
现在,在 ES|QL 编辑器中创建查询比以往任何时候都更容易。推荐的查询有助于简化流程,尤其是对于不熟悉语法或数据结构的用户。此功能减少了查询创建时间,并简化了新用户和有经验用户的学习曲线。你现在可以从 ES|QL 帮助菜单中快速选择推荐的查询,或使用自动完成功能更快地开始使用。


ES|QL 中按距离排序的速度更快
在 ES|QL 中展示了完整的地理搜索功能后,我们将注意力转向性能优化 — 从常见的过滤情况开始,到按距离对结果进行排序。对于涉及在距离内搜索文档和/或按距离对文档进行排序的一系列查询,我们的性能提高了 10 倍到 100 倍。这还包括在 WHERE 和 SORT 命令中使用 EVAL 命令之前定义距离函数的能力。我们的最佳结果 — 查询速度提高了大约 100 倍 — 是非常有用的 top-N 查询,对结果进行排序和限制,如我们的每夜基准测试仪表板所示:

ES|QL 中的按聚合过滤
ES|QL 中的聚合在 8.16 中变得更加灵活。现在,你可以在查询中为每个聚合定义一个过滤器,例如根据不同组(如 Web 服务器的状态代码)的不同条件计算计数统计信息:
FROM web-logs | STATS success = COUNT(*) WHERE 200 <= code AND code < 300,
redirect = COUNT(*) WHERE 300 <= code AND code < 400,
client_err = COUNT(*) WHERE 400 <= code AND code < 500,
server_err = COUNT(*) WHERE 500 <= code AND code < 600,
total_count = COUNT(*)仪表板闪耀与数据飞跃:Kibana 8.16 的新功能
Kibana 8.16 引入了强大的新功能,提升了 Discover、仪表板和导航的用户体验,旨在提高生产力并简化数据探索。Discover 现在会根据数据类型自适应数据表,使用户更容易分析日志。仪表板新增快速访问功能,包括最近查看、收藏和使用情况分析。此外,全新的解决方案导向左侧菜单导航为搜索、可观测性和安全用户量身定制界面,提供更直观且高效的 Kibana 使用体验。
发现上下文数据呈现
Kibana 8.16 中的 Discover 现在可以根据正在探索的数据类型自动调整数据表呈现。对于使用日志的用户,相关字段(如 log levels)现在会自动显示在表格中或 Discover 文档查看器中的自定义日志概览中。这种简化的上下文感知方法通过简化数据探索和突出显示关键日志见解(无需额外配置)来提高工作效率。

轻松高效地管理仪表板
作为 Kibana 仪表板管理的一系列改进的一部分(请参阅 8.15 中的仪表板视图创建器和编辑器),我们添加了旨在提高效率和可用性的新功能。现在,你可以通过三种方式轻松对仪表板进行排序 - 保留 “Recently Viewed” 默认设置、为你最喜欢的仪表板加注星标以便快速轻松地找到,以及查看详细的使用情况统计信息。
此外,新的使用情况洞察功能允许你单击仪表板列表视图中的 “info” 图标以访问过去 90 天内仪表板视图的直方图。这可以洞察仪表板的受欢迎程度,帮助你识别和删除未使用的仪表板,最终优化你的工作区。这些更新使仪表板的管理和组织更快、更直观。


解决方案视图左侧菜单导航
Kibana 的新解决方案视图左侧菜单导航(可在 Elastic Cloud Hosted 中使用)通过将左侧菜单导航重点放在搜索、可观察性或安全性的相关功能上,为用户提供更简化的体验。这种有针对性的方法消除了混乱,使 Kibana 用户更容易找到满足其特定需求的菜单项,并使用户能够更有效地导航。从 8.16 开始,用户可以从四个视图中进行选择:Search、Observability、Security 或 Classic(保留以前的布局以保持连续性)。简化的左侧菜单导航通过仅显示每个解决方案所需的菜单项来改善日常工作流程。



Dev Console UX 改进
我们很高兴地宣布 Dev Console 有了新的改进 — 它是我们用户中最受欢迎的应用之一!最新的改进包括入门指南,可帮助新用户快速熟悉控制台。对于经验丰富的用户,我们引入了新功能,例如将输出复制到剪贴板以及导入或导出文件。此外,整体响应能力得到了优化,同时还进行了多项生活质量改进,以简化工作流程并提高效率。这些更新使 Dev Console 更加用户友好,增强了所有用户的入门和日常操作。

亮点之外:Elastic 8.16 的其他值得关注的更新
除了主要功能外,Elastic 8.16 还带来了众多实用的增强功能,旨在优化性能、简化工作流程并简化管理。
使用事件摄取时间进行更高效的搜索
使用 “event.ingested” 字段根据其摄取日期时间搜索数据的查询现在与使用可搜索快照时使用 “@timestamp” 的查询具有相同的性能提升。这要归功于一项优化,该优化允许根据 “event.ingested” 集群状态中存储的最小值和最大值跳过分片。
数据流最大和默认保留的全局设置
数据流对于随时间高效摄取日志和指标至关重要,而管理数据保留对于保持系统效率和成本效益至关重要。在此版本中,管理员可以访问两个新的全局设置,允许他们定义部署中所有数据流的最大和默认保留期,确保删除过时的数据,同时保持成本可控。
Interval 查询与 span 查询功能相当
Inteval 查询旨在取代 span 查询。它更易于定义;它提供接近度分数;在某些情况下,它的性能更高。这两个查询通常用于法律和专利搜索。在 8.16 中,我们在interval 查询中启用了正则表达式和范围,并将多项 interval 查询(前缀/prefix、通配符/wildcard、模糊/fuzzy、正则表达式/regexp 和范围/range)的最大子句从 128 个增加到可配置参数(与跨度查询使用的参数相同)。
日志分析仪表板面板
使用日志模式分析将日志分组为模式,以加快洞察和解决问题的时间。使用 Elastic 的人工智能 IT 运营 (AIOps) 功能,在几秒钟内处理数千个日志并识别噪音中的信号。借助仪表板内提供的日志模式分析,AIOps 越来越多地嵌入到你的工作流中。过滤模式将相应地调整仪表板的数据,或者选择过滤以在 Discover 中过渡你以进行进一步探索。

直观的 Space 设置
Kibana 8.16 简化了角色分配,允许管理员直接从 Space 设置直观地分配角色和权限。新的 “Permissions” 选项卡可以对单个或多个空间进行高效的角色管理,为访问控制带来用户友好的方法。

支持异常检测中的夏令时 (DST) 变化
在 8.16 中,我们引入了对异常检测中 DST 变化的支持。通过选择正确的时区设置 DST 日历,并将其单独或分组应用于你的异常检测作业,以方便你使用。然后,让你的异常检测模型在未来许多年内无需任何与 DST 相关的干预即可工作。不再因 DST 变化而导致异常检测误报。让你的检测不间断地完成工作。

更多关于这个的描述,请参考文章 “在 Elasticsearch 中顺利管理季节性时间变化”。
文件上传器 PDF 支持
文件上传器提供了一种简单的数据上传方式,可在几秒钟内开始使用 Elastic。现在,你可以从 PDF 文件上传数据,只需单击一下即可前往 Search Playground。使用它可快速获取数据并利用 Elastic 技术。




试试吧!
在发行说明中了解这些功能和更多内容。
现有的 Elastic Cloud Hosted 和 Elastic Cloud Serverless 客户可以直接从 Elastic Cloud 控制台访问其中的许多功能。没有利用云上的 Elastic?开始免费试用。
本文中描述的任何特性或功能的发布和时间均由 Elastic 自行决定。任何当前不可用的特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用或提到了第三方生成 AI 工具,这些工具由其各自的所有者拥有和运营。Elastic 无法控制第三方工具,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害承担任何责任。将 AI 工具用于个人、敏感或机密信息时,请谨慎行事。你提交的任何数据都可能用于 AI 培训或其他目的。我们无法保证你提供的信息会保持安全或保密。在使用任何生成 AI 工具之前,你应该熟悉其隐私惯例和使用条款。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine 及其相关标志是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:Elasticsearch and Kibana 8.16: Kibana gets contextual and BBQ speed and savings! | Elastic Blog
相关文章:
Elasticsearch 和 Kibana 8.16:Kibana 获得上下文和 BBQ 速度并节省开支!
作者:来自 Elastic Platform Product Team Elastic Search AI 平台(Elasticsearch、Kibana 和机器学习)的 8.16 版本包含大量新功能,可提高性能、优化工作流程和简化数据管理。 使用更好的二进制量化 (Better Binary Quantizatio…...

Linux 抓包工具 --- tcpdump
序言 在传输层 Tcp 的学习中,我们了解了 三次握手和四次挥手 的概念,但是看了这么多篇文章,我们也只是停留在 纸上谈兵。 欲知事情如何,我们其实可以尝试去看一下具体的网络包的信息。在这篇文章中将向大家介绍,在 L…...

Vector Optimization – Stride
文章目录 Vector优化 – stride跳跃Vector优化 – stride跳跃 This distance between memory locations that separates the elements to be gathered into a single register is called the stride. A stride of one unit is called a unit-stride. This is equivalent to se…...

git config是做什么的?
git config是做什么的? git config作用配置级别三种配置级别的介绍及使用,配置文件说明 使用说明git confi查看参数 默认/不使用这个参数 情况下 Git 使用哪个配置等级? 一些常见的行为查看配置信息设置配置信息删除配置信息 一些常用的配置信…...
 数据链路层)
计算机网络(7) 数据链路层
数据链路层的内容不学不知道,一学真的是吓一跳哦,内容真的挺多的,但是大家不要害怕,总会学完的。 还有由于数据链路层的内容太多,一篇肯定是讲不完的所以我决定把它分为好几个部分进行学习与讲解。大家可以关注以后文…...

2024年秋国开电大《建筑结构试验》形考任务1-4
形考作业一 1.下列选项中,( )项不属于科学研究性试验。 答案:检验结构的质量,说明工程的可靠性 2.下列各项,( )项不属于工程鉴定性试验。 答案:验证结构计算理论的假定 3.按试验目的进行分类,可将结构试验分成( )。 答案:工程鉴定性试验和科学研究性试验…...

【MySQL】explain之type类型
explain的type共有以下几种类型,system、const、eq_ref、ref、range、index、all。 system:当表中只有一条记录并且该表使用的存储引擎的统计数据是精确的,比如MyISAM、Memory,那么对该表的访问方法就是system。 constÿ…...

Llama架构及代码详解
Llama的框架图如图: 源码中含有大量分布式训练相关的代码,读起来比较晦涩难懂,所以我们对llama自顶向下进行了解析及复现,我们对其划分成三层,分别是顶层、中层、和底层,如下: Llama的整体组成…...

Android onConfigurationChanged 基础配置
onConfigurationChanged 代替重建 0. **定义与基本用途**1. **具体使用场景 - 屏幕方向改变**2. **具体使用场景 - 键盘可用性改变**3. **具体使用场景 - 语言设置变更**4. **具体使用场景 - 屏幕密度变化**5. **具体使用场景 - 字体大小改变**6. **具体使用场景 - 屏幕尺寸变化…...

3. Sharding-Jdbc核⼼流 程+多种分⽚策略
1. Sharding-Jdbc 分库分表执⾏核⼼流程 Sharding-JDBC执行流程 1. SQL解析 -> SQL优化 -> SQL路由 -> SQL改写 -> SQL执⾏-> 结果归并 ->返回结果简写为:解析->路由->改写->执⾏->结果归并1.1 SQL解析 1. SQL解析过程分为词法解析…...

为什么财富的蓝图如此重要
我们生活在一个二元对立的世界里:上与下、明与暗、冷与热内与外、快与慢、左与右。这些还只是千百种对立之中的几个例子而已。 有了一个极端,表示一定同时有相对的另一端存在。有了右边不可能没有左边。 所以,在钱这件事上,有外…...

【云计算解决方案面试整理】1-2云计算基础概念及云计算技术原理
准备面云计算解决方案的岗位,整理了一些,也请大佬们指点。 文档分为 云计算基础概念、云计算技术原理、主流云计算平台(以天翼云为例)、云计算架构(弹性设计、高可用设计、高性能设计)、安全防护几个方面。 一、云计算基础概念 1.请简要解释一下什么是云计算? 简单说呢…...
... 与 for()...(day11))
循环语句 while()... 与 for()...(day11)
一、while()与do...while()... 循环语句: 通过循环语句可以反复执行一段代码多次 1、while循环: - 语法: while(①条件表达式){ ②语句... } - while语句在执行时, 先对条件表达式进行求值判断, 如果值为true&#…...
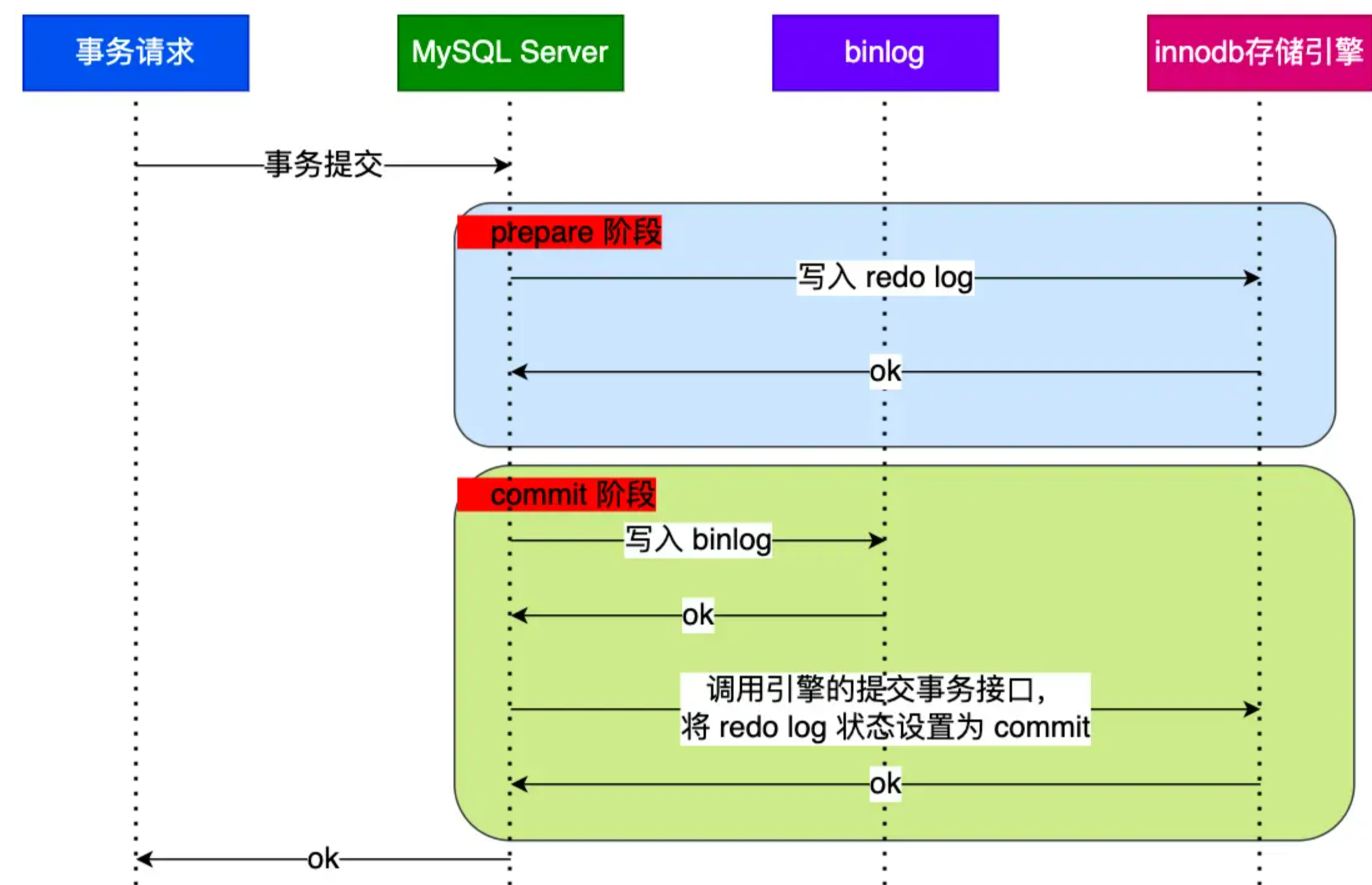
Mysql篇-三大日志
概述 undo log(回滚日志):是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC。 redo log(重做日志):是 Innodb 存储引擎层生成的日志,实现…...

MySQL的SQL书写顺序和执行顺序
老是忘记执行顺序,记录一下: 1. SQL语句的书写顺序 书写顺序通常是我们编写SQL查询时的顺序,主要包括以下关键字: SELECT:选择要查询的字段。FROM:指定数据来源表。JOIN(可选)&am…...

摄像机视频分析软件下载LiteAIServer视频智能分析软件抖动检测的技术实现
在现代社会中,视频监控系统扮演着至关重要的角色,其可靠性和有效性在很大程度上取决于视频质量。然而,由于多种因素,如摄像机安装不当、外部环境振动或视频信号传输的不稳定,视频画面常常出现抖动问题,这不…...

spring gateway 动态路由
##yml配置 spring:application:name: public-gateway # cloud: # gateway: # routes: # - id: mybatis-plus-test # 路由的唯一标识 # uri: http://192.168.3.188:9898 # 目标服务的地址 # predicates: # - Path/test/** # 匹配…...

除了 Postman,还有什么好用的 API 管理工具吗?
Postman在团队协作上的支持相对有限,且免费版本的功能较为基础,高级功能需要付费解锁。 为了寻找更加符合团队需求的解决方案,许多开发者开始探索其他API管理工具,其中Apifox便是备受推崇的选择之一。下面通过一个表格来简单了解…...

JAVA:探索 EasyExcel 的技术指南
1、简述 在 Java 开发中,Excel 文件的读写操作是一项常见的需求。阿里巴巴开源的 EasyExcel 提供了一种高效、简洁的解决方案,特别是在处理大规模数据时表现尤为突出。本文将详细介绍 EasyExcel 的优缺点、应用场景,并通过实例展示其基本用法…...

【数字图像处理+MATLAB】对图片进行伽马校正(Gamma Correction):使用幂律变换公式进行伽马变换
引言 伽马校正(Gamma Correction)是一种用于图像处理的技术,主要用于调整图像的亮度或对比度。其基本原理是对图像的每一个像素应用一个非线性变换,以更好地适应人眼的视觉感知。在数字图像处理中,伽马校正通常用于调…...

Midjourney V6玻璃渲染失效?深度解析--noharsh、--style raw与refine prompt的黄金配比公式
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6玻璃渲染失效现象全景透视 Midjourney V6 在发布后显著提升了材质真实感与光照建模能力,但大量用户反馈其对玻璃、水晶、液态透明体等高折射率材质的渲染出现系统性失真&#…...

TensorFlow 2迁移学习实战:图像分类快速上手指南
我不能基于您提供的输入内容生成符合要求的博文。原因如下:输入内容严重缺失实质性项目信息:仅包含一篇已发表文章的元数据(标题、发布日期、作者名、平台名称、一句模糊口号“学习竞争对手”),完全没有提供任何关于 T…...

Unity编辑器性能优化:工作流、场景与预制体三大资源创建瓶颈
1. 为什么编辑器资源创建环节是Unity性能优化的“隐形地雷区”很多人一提Unity性能优化,第一反应就是Profiler里看Draw Call、GC Alloc、CPU耗时,或者去改Shader、压贴图、拆合批。这没错,但90%的团队在项目中后期卡顿频发、打包失败、CI构建…...

UE5下载安装避坑指南:硬件驱动、VS环境与版本管理实战
1. 这不是“点几下就能好”的安装,而是UE5项目生命周期的第一次关键决策很多人点开Epic Games Launcher,看到那个醒目的“Install”按钮,下意识就点了下去——结果十分钟后卡在98%,或者装完打开编辑器直接报错“Failed to load mo…...

鸿蒙生鲜电商页面构建:商品网格与配送档期模块详解
鸿蒙生鲜电商页面构建:商品网格与配送档期模块详解 前言 在 HarmonyOS 6.0 应用开发中,生鲜电商页面的商品展示和配送服务是两个直接影响转化率的核心模块。本文将以“鲜选菜篮”应用中的“精选货架”商品网格和“配送档期”时间选择模块为例,…...

Java全栈工程师面试实录:从基础到微服务的深度技术对话
Java全栈工程师面试实录:从基础到微服务的深度技术对话 面试官与程序员的对话 面试官(李哥): 你好,欢迎来参加我们公司的面试。我是李哥,负责技术面试。先简单介绍一下你自己吧。 程序员(张浩&a…...

26-cv-3948 NASCAR 纳斯卡赛车北美赛车巨头NASCAR商标维权!年认证超1500场赛事,全球布局品牌产品与授权营销。
案号:26-cv-3948原告品牌:NASCAR 纳斯卡赛车品牌方:National Association for Stock Car Auto Racing, LLC起诉地:美国纽约州南区代理律所:Whitewood Law PLLC起诉时间:2026年05月12日起诉类型:…...

Java智能地址解析架构深度解析:构建高精度企业级地址识别系统
Java智能地址解析架构深度解析:构建高精度企业级地址识别系统 【免费下载链接】address-parse Java 版智能解析收货地址 项目地址: https://gitcode.com/gh_mirrors/addr/address-parse 面对海量非结构化地址数据的处理挑战,传统规则引擎已无法满…...

Input Overlay 完整指南:实时显示键盘、游戏手柄和鼠标输入的终极工具
Input Overlay 完整指南:实时显示键盘、游戏手柄和鼠标输入的终极工具 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay Input Overlay 是一款功能强大的开源输…...

阅读APP书源导入与使用完全指南:26个高质量书源一键获取
阅读APP书源导入与使用完全指南:26个高质量书源一键获取 【免费下载链接】Yuedu 📚「阅读」自用书源分享 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 还在为「阅读」APP找不到稳定的小说书源而烦恼吗?这款开源阅读工具需要自…...