机器学习系列----KNN分类
目录
前言
一.KNN算法的基本原理
二.KNN分类的实现
三.总结
前言
在机器学习领域,K近邻算法(K-Nearest Neighbors, KNN)是一种非常直观且常用的分类算法。它是一种基于实例的学习方法,也被称为懒学习(Lazy Learning),因为它在训练阶段不进行任何模型的构建,所有的计算都推迟到测试阶段进行。KNN分类的核心思想是:给定一个测试样本,找到在训练集中与其距离最近的K个样本,然后根据这K个样本的标签进行预测。
本文将介绍KNN算法的基本原理、如何实现KNN分类,以及在实际使用中需要注意的几点。
一.KNN算法的基本原理
KNN算法的基本流程如下:
(1)选择距离度量:通常我们使用欧氏距离来衡量两个样本点之间的距离,但也可以选择其他距离度量,如曼哈顿距离、余弦相似度等。
(2)选择K值:选择K的大小会直接影响分类效果。K值太小容易受到噪声数据的影响,而K值过大可能导致分类结果过于平滑。
(3)找到K个邻居:对于测试样本,根据距离度量选择与之最接近的K个样本。
(4)投票决策:通过这K个邻居的类别标签进行投票,测试样本的预测标签通常由出现频率最高的类别决定。
二.KNN分类的实现
在Python中,我们可以通过 sklearn 库来快速实现KNN分类器。下面是一个使用KNN进行分类的基本示例:
导入必要的库
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
加载数据集
我们使用sklearn自带的鸢尾花(Iris)数据集,该数据集包含150个样本,4个特征,3个类别。
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 标签
数据集拆分
将数据集拆分为训练集和测试集,训练集占80%,测试集占20%。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
初始化KNN分类器并训练
我们创建一个KNN分类器实例,选择K=3。
# 初始化KNN分类器,设置K=3
knn = KNeighborsClassifier(n_neighbors=3)# 在训练集上训练模型
knn.fit(X_train, y_train)
测试与评估
我们可以使用测试集来评估模型的准确性。
# 在测试集上做预测
y_pred = knn.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy * 100:.2f}%")
KNN分类的优缺点
优点
简单易懂:KNN算法简单直观,不需要复杂的训练过程。
无参数假设:KNN不需要像其他算法那样对数据做参数假设,适应性强。
适合多分类问题:KNN能够有效地处理多类问题。
缺点
计算开销大:在测试阶段需要计算每个测试点与所有训练数据的距离,计算量大,尤其在数据量较大时,效率较低。
对噪声敏感:由于KNN依赖于距离度量,数据中的噪声点可能会影响分类结果。
需要存储整个训练集:KNN算法是懒学习,需要将训练集存储在内存中,可能会对内存消耗产生较大影响。
K值的选择与调优
选择合适的K值是KNN分类器表现的关键。过小的K值(例如1)容易过拟合,受噪声影响较大,而过大的K值会导致欠拟合。常用的选择方法是通过交叉验证来选择K值。
from sklearn.model_selection import cross_val_score# 使用交叉验证选择K值
k_values = range(1, 21)
cv_scores = [np.mean(cross_val_score(KNeighborsClassifier(n_neighbors=k), X, y, cv=5)) for k in k_values]# 输出不同K值的交叉验证得分
for k, score in zip(k_values, cv_scores):print(f"K={k}, Cross-validation accuracy={score:.2f}")
import numpy as np
import math
from collections import Counter
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix, classification_report
import matplotlib.pyplot as plt# 计算欧几里得距离
def euclidean_distance(x1, x2):"""计算欧几里得距离x1, x2: 两个输入样本,numpy数组或列表"""return math.sqrt(np.sum((x1 - x2) ** 2))# 计算曼哈顿距离
def manhattan_distance(x1, x2):"""计算曼哈顿距离(L1距离)x1, x2: 两个输入样本,numpy数组或列表"""return np.sum(np.abs(x1 - x2))# 计算闵可夫斯基距离
def minkowski_distance(x1, x2, p=3):"""计算闵可夫斯基距离,p为距离的阶数x1, x2: 两个输入样本,numpy数组或列表p: 阶数,通常为 1 (曼哈顿距离) 或 2 (欧几里得距离)"""return np.power(np.sum(np.abs(x1 - x2) ** p), 1/p)# KNN 分类器类
class KNN:def __init__(self, k=3, distance_metric='euclidean'):"""初始化 KNN 分类器k: 最近邻的个数distance_metric: 距离度量方式,'euclidean' 为欧几里得距离,'manhattan' 为曼哈顿距离,'minkowski' 为闵可夫斯基距离"""self.k = kself.distance_metric = distance_metricdef fit(self, X_train, y_train):"""训练模型,保存训练数据X_train: 训练特征数据y_train: 训练标签数据"""self.X_train = X_trainself.y_train = y_traindef predict(self, X_test):"""对测试数据进行预测X_test: 测试特征数据返回预测标签"""predictions = [self._predict(x) for x in X_test]return np.array(predictions)def _predict(self, x):"""对单个样本进行预测x: 输入样本返回预测标签"""# 根据指定的距离度量方法计算距离if self.distance_metric == 'euclidean':distances = [euclidean_distance(x, x_train) for x_train in self.X_train]elif self.distance_metric == 'manhattan':distances = [manhattan_distance(x, x_train) for x_train in self.X_train]elif self.distance_metric == 'minkowski':distances = [minkowski_distance(x, x_train) for x_train in self.X_train]else:raise ValueError(f"Unsupported distance metric: {self.distance_metric}")# 找到最近的 k 个邻居k_indices = np.argsort(distances)[:self.k]k_nearest_labels = [self.y_train[i] for i in k_indices]# 返回最常见的标签most_common = Counter(k_nearest_labels).most_common(1)return most_common[0][0]# 加载 Iris 数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 切分数据集为训练集和测试集,70% 训练集,30% 测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 标准化数据,以确保不同特征的数值范围一致
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 初始化 KNN 分类器
knn = KNN(k=5, distance_metric='minkowski') # 使用闵可夫斯基距离
knn.fit(X_train, y_train)# 预测
predictions = knn.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print(f"预测准确率: {accuracy * 100:.2f}%")# 输出混淆矩阵和分类报告
print("\n混淆矩阵:")
print(confusion_matrix(y_test, predictions))print("\n分类报告:")
print(classification_report(y_test, predictions))# 绘制预测结果与真实结果对比的图表
def plot_confusion_matrix(cm, classes, title='Confusion Matrix', cmap=plt.cm.Blues):"""绘制混淆矩阵cm: 混淆矩阵classes: 类别名"""plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)# 绘制网格thresh = cm.max() / 2.for i, j in np.ndindex(cm.shape):plt.text(j, i, format(cm[i, j], 'd'),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')# 计算混淆矩阵
cm = confusion_matrix(y_test, predictions)# 绘制混淆矩阵
plt.figure(figsize=(8, 6))
plot_confusion_matrix(cm, classes=iris.target_names)
plt.show()# 展示一些预测结果
for i in range(5):print(f"实际标签: {iris.target_names[y_test[i]]}, 预测标签: {iris.target_names[predictions[i]]}")
代码功能解释:
计算不同距离:
euclidean_distance:计算欧几里得距离。
manhattan_distance:计算曼哈顿距离。
minkowski_distance:计算闵可夫斯基距离,p 代表阶数,通常取 1(曼哈顿距离)或者 2(欧几里得距离)。
KNN 分类器:
在 KNN 类中,你可以选择不同的距离度量方式 ('euclidean', 'manhattan', 'minkowski'),通过 k 来设定邻居个数。
fit 方法保存训练数据,predict 方法对每个测试数据点进行预测。
_predict 方法对单个测试样本进行预测,通过计算与训练集中所有样本的距离来选择最近的 k 个邻居。
数据预处理:
使用 StandardScaler 来标准化数据,使得每个特征具有零均值和单位方差。
模型评估:
使用 accuracy_score 计算预测准确率。
使用 confusion_matrix 和 classification_report 来展示混淆矩阵和分类性能报告(包括精确度、召回率、F1 分数等)。
通过 matplotlib 绘制混淆矩阵,帮助可视化模型的分类效果。
数据集:
使用 sklearn.datasets 中的 Iris 数据集。该数据集包含 150 个样本,分别属于 3 个不同的鸢尾花种类,每个样本有 4 个特征。
输出:
准确率:模型对测试集的预测准确性。
混淆矩阵:展示真实标签与预测标签的对比。
分类报告:包含精确度、召回率、F1 分数等详细指标。
混淆矩阵图表:图形化展示分类性能。
这个实现包含了更多的功能,并且通过使用不同的距离度量方法,你可以探索 KNN 在不同设置下的表现。
三.总结
K 最近邻(KNN)算法是一种简单直观的监督学习算法,广泛应用于分类和回归问题。其核心思想是,通过计算待预测样本与训练集中的每个样本之间的距离,选择距离最近的 k 个样本(即“邻居”),然后根据这些邻居的标签或数值来进行预测。在分类问题中,KNN 通过多数投票原则决定最终分类结果;在回归问题中,则通常是取邻居标签的平均值。KNN 算法的优势在于不需要显式的训练过程,其预测过程依赖于对整个训练数据集的存储和计算,因此适合动态更新数据的场景。然而,KNN 算法的计算复杂度较高,尤其在数据集较大时,预测过程可能变得非常缓慢。为了提高效率,通常需要对数据进行预处理,如归一化或标准化,以消除不同特征尺度差异的影响。此外,K 值的选择以及距离度量方法(如欧几里得距离、曼哈顿距离等)会显著影响模型的表现,K 值过小可能导致过拟合,过大则可能导致欠拟合。KNN 的一个主要缺点是它对高维数据(即特征空间维度较大)不太敏感,因为高维空间的距离度量往往会失去区分度,导致“维度灾难”。总的来说,KNN 是一个易于理解和实现的算法,适用于样本量不大且特征维度较低的问题,但在大数据集和高维数据上可能不够高效。
相关文章:

机器学习系列----KNN分类
目录 前言 一.KNN算法的基本原理 二.KNN分类的实现 三.总结 前言 在机器学习领域,K近邻算法(K-Nearest Neighbors, KNN)是一种非常直观且常用的分类算法。它是一种基于实例的学习方法,也被称为懒学习(Lazy Learnin…...

贪心算法day 06
1.最长回文串 链接:. - 力扣(LeetCode) 思路:计算每个字符个数如果是偶数个那么肯定可以组成回文串,如果是奇数个就会有一个无法组成回文串,但是在最中间还是可以有一个不是成队的字符这个字符就从多的奇…...

HTML之列表学习记录
练习题: 图所示为一个问卷调查网页,请制作出来。要求:大标题用h1标签;小题目用h3标签;前两个问题使用有序列表;最后一个问题使用无序列表。 代码: <!DOCTYPE html> <html> <he…...

Redo与Undo的区别:数据库事务的恢复与撤销机制
在数据库中,redo 和 undo 是两个非常重要的概念,它们主要用于事务管理和恢复机制,确保数据的一致性和完整性。 下面分别解释这两个概念: Redo(重做) 定义:redo 操作记录了事务对数据库所做的所…...

【话题讨论】AI赋能电商:创新应用与销售效率的双轮驱动
目录 引言 一、AI技术在电商中的创新应用 1.1 购物推荐 1.2 会员分类 1.3 商品定价 1.4 用户体验 总结 二、AI技术提高电商平台销售效率 2.1 订单处理 2.2 物流配送 2.3 产品流转效率 2.4 库存管理和订单管理效率 2.5 实际案例分析 三、挑战和未来发展趋势 3.1…...

重构开发之道,Blackbox.AI为技术注入智能新动力
本文目录 一、引言二、Blackbox.AI实战体验2.1 基于网页界面生成前端代码进行应用开发2.2 与AI助手实现实时智能对话2.3 重塑大型文件交互方式2.4 链接Github仓库进行对话编程 三、总结 一、引言 在生产力工具加速进化的浪潮中,Blackbox.AI开始崭露头角,…...

机器学习在医疗健康领域的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 机器学习在医疗健康领域的应用 机器学习在医疗健康领域的应用 机器学习在医疗健康领域的应用 引言 机器学习概述 定义与原理 发展…...

M芯片Mac构建Dockerfile - 注意事项
由于MacBook的M芯片架构与intel不同,交叉构建Linux服务器docker镜像,需要以下步骤完成: 编写好Dockerfile在命令行中,执行构建命令: docker buildx build --platform linux/amd64 -t ${image_name}:${tag} ....

系统架构设计师论文
软考官网:中国计算机技术职业资格网 (ruankao.org.cn) 2019年 2019年下半年试题二:论软件系统架构评估及其应用...

速盾:CDN 和高防有什么区别?
在网络安全和性能优化领域,CDN(Content Delivery Network,内容分发网络)和高防服务是两个重要的概念,它们在功能、原理和应用场景方面存在诸多区别。 一、CDN (一)基本原理与功能 内容加速分发…...

goframe开发一个企业网站 rabbitmq队例15
RabbitMQ消息队列封装 在目录internal/pkg/rabbitmq/rabbitmq.go # 消息队列配置 mq:# 消息队列类型: rocketmq 或 rabbitmqtype: "rabbitmq"# 是否启用消息队列enabled: truerocketmq:nameServer: "127.0.0.1:9876"producerGroup: "myProducerGrou…...

设计模式-七个基本原则之一-迪米特法则 + 案例
迪米特法则:(LoD) 面向对象七个基本原则之一 只与直接的朋友通信:对象应只与自己直接关联的对象通信,例如:方法参数、返回值、创建的对象。避免“链式调用”:尽量避免通过多个对象链进行调用。例如,a.getB().getC().do…...

【数学二】线性代数-二次型
考试要求 1、了解二次型的概念, 会用矩阵形式表示二次型,了解合同变换与合同矩阵的概念. 2、了解二次型的秩的概念,了解二次型的标准形、规范形等概念,了解惯性定理,会用正交变换和配方法化二次型为标准形。 3、理解正定二次型、正定矩阵的概念,并掌握其判别法. 二次型…...

320页PDF | 集团IT蓝图总体规划报告-德勤(限免下载)
一、前言 这份报告是集团IT蓝图总体规划报告-德勤。在报告中详细阐述了德勤为某集团制定的全面IT蓝图总体规划,包括了集团信息化目标蓝图、IT应用规划、数据规划、IT集成架构、IT基础设施规划以及IT治理体系规划等关键领域,旨在为集团未来的信息化发展提…...
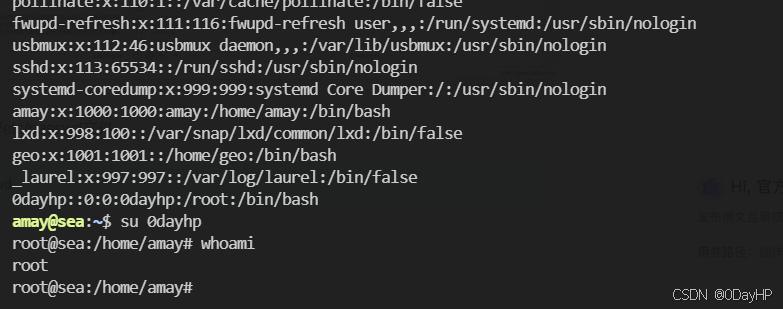
HTB:Sea[WriteUP]
目录 连接至HTB服务器并启动靶机 使用nmap对靶机TCP端口进行开放扫描 使用curl访问靶机80端口 使用ffuf对靶机进行了一顿FUZZ 尝试在Github上搜索版权拥有者 除了LICENSE还FUZZ出了version文件尝试访问 尝试直接在Github搜索该符合该版本的EXP 横向移动 使用john对该哈…...

Java 网络编程(一)—— UDP数据报套接字编程
概念 在网络编程中主要的对象有两个:客户端和服务器。客户端是提供请求的,归用户使用,发送的请求会被服务器接收,服务器根据请求做出响应,然后再将响应的数据包返回给客户端。 作为程序员,我们主要关心应…...

ECharts图表图例8
用eclipse软件制作动态单仪表图 用java知识点 代码截图:...

Redis中的线程模型
Redis 的单线程模型详解 Redis 的“单线程”模型主要指的是其 主线程,这个主线程负责从客户端接收请求、解析命令、处理数据和返回响应。为了深入了解 Redis 单线程的具体工作流程,我们可以将其分为以下几个步骤: 接收客户端请求 Redis 的主线…...

[产品管理-77]:技术人需要了解的常见概念:科学、技术、技能、产品、市场、商业模式、运营
目录 一、概念定义 科学 技术 技能 产品 市场 商业模式 运营 二、上述概念在产品创新中的作用 一、概念定义 对于技术人来说,了解并掌握科学、技术、技能、产品、市场、商业模式、运营等常见概念的定义至关重要。以下是这些概念的详细解释: 科…...
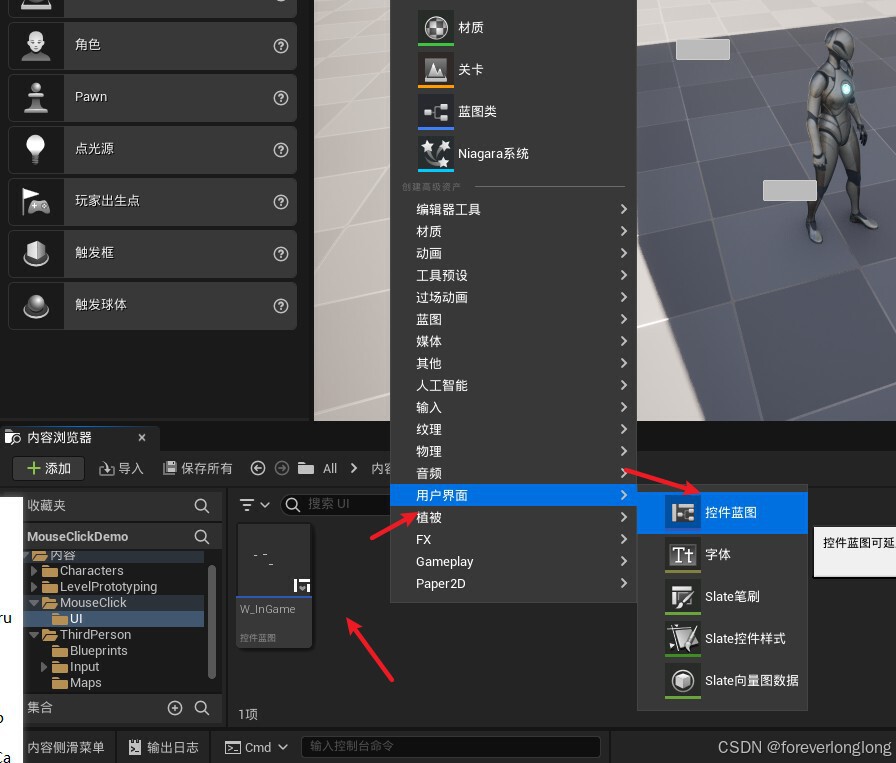
鼠标点击(一)与3D视口窗口的交互
(1) (2) (3)...
)
告别Excel!用Python复现地理探测器(附完整代码与示例数据)
告别Excel!用Python复现地理探测器(附完整代码与示例数据) 地理探测器作为分析空间分异性的重要工具,长期以来依赖Excel插件实现计算。但对于需要批量处理、自定义分析流程的研究者而言,这种封闭式操作存在明显局限。…...

Vue3 入门学习
Vue3 技术文章大纲Vue3 核心特性与优势Composition API 的设计理念与优势Composition API 是 Vue3 的核心特性之一,旨在解决 Options API 在复杂组件中逻辑分散的问题。通过 setup 函数,可以将相关逻辑组织在一起,提高代码的可读性和可维护性…...

明日方舟智能基建管理终极指南:5分钟实现全自动资源生产
明日方舟智能基建管理终极指南:5分钟实现全自动资源生产 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》繁琐的基建管理而头疼吗?每天花费大量时间手动…...
:当 Agent 拥有了物理世界的身体)
具身智能(Embodied AI):当 Agent 拥有了物理世界的身体
具身智能(Embodied AI):当Agent拥有了物理世界的身体,下一个十年的科技革命? 一、引言 (Introduction) 钩子 (The Hook) 你有没有过这样的幻想:下班回家推开门,AI机器人已经做好了你爱吃的糖醋排骨,把换下来的脏衣服扔进了洗衣机,甚至还帮你把刚到的快递拆好了?过去…...

为Claude Code配置Taotoken解决密钥被封与Token不足的烦恼
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决密钥被封与Token不足的烦恼 应用场景类,聚焦于使用Claude Code的编程助手用户ÿ…...

终极指南:如何用3行命令实现美国签证预约自动化抢号
终极指南:如何用3行命令实现美国签证预约自动化抢号 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 还在为美国签证面试预约的漫长等待而焦虑吗?手动刷新页面、熬夜守候已成为过去式。今天&…...

Claude Code 总被封号怎么办,用 Taotoken 稳定接入大模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 总被封号怎么办,用 Taotoken 稳定接入大模型服务 许多开发者在日常工作中依赖 Claude Code 作为编程助手&…...

如何实现快速排名?冷门制造业网站的3天起步法
小型机械厂、精细化工厂、模具厂拥有小众的工业产品。工业产品在网络上的搜索量极低。一款直径 50 毫米的硬质合金钻头,全球每月搜索量仅有 120 次。高空作业平台零部件的搜索量低至 50 次。极低的搜索热度带来一个现象:大型网络平台不参与这类词汇的竞争…...

RustRedOps COM组件操作指南:从IActiveScript到IShellDispatch的完整示例
RustRedOps COM组件操作指南:从IActiveScript到IShellDispatch的完整示例 【免费下载链接】RustRedOps RustRedOps is a repository for advanced Red Team techniques focused on Rust 项目地址: https://gitcode.com/gh_mirrors/ru/RustRedOps RustRedOps是…...

从CT扫描到AI模型:避开DICOM体位信息这个‘隐形坑’,提升医学影像分析准确率
从CT扫描到AI模型:避开DICOM体位信息这个‘隐形坑’,提升医学影像分析准确率 在医疗AI模型的开发过程中,数据预处理环节往往被工程师们视为"脏活累活"——既没有模型调参的成就感,也不如算法设计那样引人注目。然而&…...