LSTM(长短期记忆网络)详解
1️⃣ LSTM介绍
标准的RNN存在梯度消失和梯度爆炸问题,无法捕捉长期依赖关系。那么如何理解这个长期依赖关系呢?
例如,有一个语言模型基于先前的词来预测下一个词,我们有一句话 “the clouds are in the sky”,基于"the clouds are in the",预测"sky",在这样的场景中,预测的词和提供的信息之间位置间隔是非常小的,如下图所示,RNN可以捕捉到先前的信息。

然而,针对复杂场景,我们有一句话"I grew up in France… I speak fluent French","French"基于"France"推断,但是它们之间的间隔很远很远,RNN 会丧失学习到连接如此远信息的能力。这就是长期依赖关系。
为了解决该问题,LSTM通过引入三种门遗忘门,输入门,输出门控制信息的流入和流出,有助于保留长期依赖关系,并缓解梯度消失【注意:没有梯度爆炸昂】。LSTM在1997年被提出
2️⃣ 原理
下面这张图是标准的RNN结构:
- x t x_t xt是t时刻的输入
- s t s_t st是t时刻的隐层输出, s t = f ( U ⋅ x t + W ⋅ s t − 1 ) s_t=f(U\cdot x_t+W\cdot s_{t-1}) st=f(U⋅xt+W⋅st−1),f表示激活函数, s t − 1 s_{t-1} st−1表示t-1时刻的隐层输出
- h t h_t ht是t时刻的输出, h t = s o f t m a x ( V ⋅ s t ) h_t=softmax(V\cdot s_t) ht=softmax(V⋅st)

LSTM的整体结构如下图所示,第一眼看到,反正我是看不懂。前面讲到LSTM引入三种门遗忘门,输入门,输出门,现在我们逐一击破,一个个分析一下它们到底是什么。

这是3D视角的LSTM:

首先来看遗忘门,也就是下面这张图:

遗忘门输入包含两部分
- s t − 1 s_{t-1} st−1:表示t-1时刻的短期记忆(即隐层输出),在LSTM中当前时间步的输出 h t − 1 h_{t-1} ht−1就是隐层输出 s t − 1 s_{t-1} st−1
- x t x_t xt:表示t时刻的输入
遗忘门输出为 f t f_t ft,公式表示为:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma\left(W_f\cdot[h_{t-1},x_t] + b_f\right) ft=σ(Wf⋅[ht−1,xt]+bf)
其中, W f W_f Wf和 b f b_f bf是遗忘门的参数, [ s t − 1 , x t ] [s_{t-1},x_t] [st−1,xt]表示concat操作。 σ ( ) \sigma() σ()表示sigmoid函数。
遗忘门定我们会从长期记忆中丢弃什么信息【理解为:删除什么日记】,输出一个在 0 到 1 之间的数值,1 表示“完全保留”,0 表示“完全舍弃”。
然后来看输入门:

输入门的输入包含两部分:
- s t − 1 s_{t-1} st−1:表示t-1时刻的短期记忆
- x t x_t xt:表示t时刻的输入
输入门的输出为新添加的内容 i t ∗ C ~ t i_t * \tilde{C}_t it∗C~t,其具体操作为:
i t = σ ( W i ⋅ [ s t − 1 , x t ] + b i ) C ~ t = tanh ( W C ⋅ [ s t − 1 , x t ] + b C ) \begin{aligned}i_{t}&=\sigma\left(W_i\cdot[s_{t-1},x_t] + b_i\right)\\\tilde{C}_{t}&=\tanh(W_C\cdot[s_{t-1},x_t] + b_C)\end{aligned} itC~t=σ(Wi⋅[st−1,xt]+bi)=tanh(WC⋅[st−1,xt]+bC)
输入门决定什么样的新信息被加入到长期记忆(即细胞状态)中【理解为:添加什么日记】。
然后,我们来更新长期记忆,将 C t − 1 C_{t-1} Ct−1更新为 C t C_t Ct。我们把旧状态 C t − 1 C_{t-1} Ct−1与遗忘门的输出 f t f_t ft相乘,忘记一些东西。接着加上输入门的输出 i t ∗ C ~ t i_t * \tilde{C}_t it∗C~t,新加一些东西,最终得到新的长期记忆 C t C_t Ct。具体操作为:

C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t=f_t*C_{t-1}+i_t*\tilde{C}_t Ct=ft∗Ct−1+it∗C~t
最后来看输出门:

输出门的输入包含:
- s t − 1 s_{t-1} st−1:表示t-1时刻的短期记忆
- x t x_t xt:表示t时刻的输入
- c t c_t ct:更新后的长期记忆
输出门的输出为 h t h_{t} ht和 s t s_{t} st, h t h_t ht作为当前时间步的输出, s t s_{t} st当做短期记忆输入到t+1,其具体操作为:
o t = σ ( W o [ s t − 1 , x t ] + b o ) s t = h t = o t ∗ t a n h ( C t ) \begin{aligned}&o_{t}=\sigma\left(W_{o} \left[ s_{t-1},x_{t}\right] + b_{o}\right)\\&s_{t}=h_{t}=o_{t}*\mathrm{tanh}\left(C_{t}\right)\end{aligned} ot=σ(Wo[st−1,xt]+bo)st=ht=ot∗tanh(Ct)
首先,我们运行一个 sigmoid 层来确定长期记忆的哪个部分将输出出去。接着,我们把长期记忆通过 tanh 进行处理(得到一个在-1到1之间的值)并将它和 o t o_{t} ot相乘,最终将输出copy成两份 h t h_t ht和 s t s_{t} st, h t h_t ht作为当前时间步的输出, s t s_{t} st当做短期记忆输入到t+1。
LSTM的结构分析完了,那为什么LSTM能够缓解梯度消失呢?
我前面写的这篇文章中介绍了为什么RNN会有梯度消失和爆炸:点这里查看
主要原因是反向传播时,梯度中有这一部分:
∏ j = k + 1 3 ∂ s j ∂ s j − 1 = ∏ j = k + 1 3 t a n h ′ W \prod_{j=k+1}^3\frac{\partial s_j}{\partial s_{j-1}}=\prod_{j=k+1}^3tanh^{'}W j=k+1∏3∂sj−1∂sj=j=k+1∏3tanh′W
LSTM的作用就是让 ∂ s j ∂ s j − 1 \frac{\partial s_j}{\partial s_{j-1}} ∂sj−1∂sj≈1
在LSTM里,隐藏层的输出换了个符号,从 s s s变成 C C C了,即 C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t=f_t*C_{t-1}+i_t*\tilde{C}_t Ct=ft∗Ct−1+it∗C~t。注意, f t f_t ft , i t 和 C ~ t i_{t\text{ 和}}\tilde{C}_t it 和C~t 都是 C t − 1 C_{t-1} Ct−1的复合函数(因为它们都和 h t − 1 h_{t-1} ht−1有关,而 h t − 1 h_{t-1} ht−1又和 C t − 1 C_{t-1} Ct−1有关)。因此我们来求一下 ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct:
∂ C t ∂ C t − 1 = f t + ∂ f t ∂ C t − 1 ⋅ C t − 1 + … \frac{\partial C_t}{\partial C_{t-1}}=f_t+\frac{\partial f_t}{\partial C_{t-1}}\cdot C_{t-1}+\ldots ∂Ct−1∂Ct=ft+∂Ct−1∂ft⋅Ct−1+…
后面的我们就不管了,展开求导太麻烦了。这里面 f t f_t ft是遗忘门的输出,1表示完全保留旧状态,0表示完全舍弃旧状态,如果我们把 f t f_t ft设置成1或者是接近于1,那 ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct就有梯度了。因此LSTM可以一定程度上缓解梯度消失,然而如果时间步很长的话,依然会存在梯度消失问题,所以只是缓解。
注意:LSTM可以缓解梯度消失,但是梯度爆炸并不能解决,因为LSTM不影响参数W
3️⃣ 代码
# 创建一个LSTM模型
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LSTM(nn.Module):def __init__(self,input_size,hidden_size,num_layers,output_size):super().__init__()self.num_layers=num_layersself.hidden_size=hidden_size# 定义LSTM层# batch_first=True则输入形状为(batch, seq_len, input_size)self.lstm=nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)# 定义全连接层,用于输出self.fc=nn.Linear(hidden_size,output_size)def forward(self, x):# self.lstm(x)会返回两个值# out:形状为 (batch,seq_len,hidden_size)# 隐层状态和细胞状态:形状为 (batch, num_layers, hidden_size);在这里,我们忽略隐层状态和细胞状态的输出,因此使用了占位符out, _ = self.lstm(x)out = self.fc(out)return outif __name__=='__main__':input_size=10hidden_size=64num_layers=1output_size=1net=LSTM(input_size,hidden_size,num_layers,output_size)# x的形状为(batch_size, seq_len, input_size)x=torch.randn(16,8,input_size)out=net(x)print(out.shape)
输出结果为:
torch.Size([16, 8, 1]),表示有16个batch,对于每个batch,有8个时间步,每个时间步的output大小为1
4️⃣ 总结
-
思考一个问题,对于多层LSTM,如何理解呢?

注意:图中颜色相同的其实表达的值一样, h = s h=s h=s。- 第一层 LSTM 首先初始隐层状态 s 0 l a y e r 1 s^{layer1}_0 s0layer1和细胞状态 c 0 l a y e r 1 c^{layer1}_0 c0layer1,然后输入 x t − 1 x_{t-1} xt−1 生成隐层状态和输出 s t − 1 l a y e r 1 = h t − 1 l a r y e r 1 s^{layer1}_{t-1}=h_{t-1}^{laryer1} st−1layer1=ht−1laryer1和细胞状态 c t − 1 l a y e r 1 c^{layer1}_{t-1} ct−1layer1。
- 第二层 LSTM首先初始隐层状态 s 0 l a y e r 2 s^{layer2}_0 s0layer2和细胞状态 c 0 l a y e r 2 c^{layer2}_0 c0layer2,然后接收第一层的输出 h t − 1 l a r y e r 1 h_{t-1}^{laryer1} ht−1laryer1作为输入,生成 s t − 1 l a y e r 2 = h t − 1 l a r y e r 2 s^{layer2}_{t-1}=h_{t-1}^{laryer2} st−1layer2=ht−1laryer2和 c t − 1 l a y e r 2 c^{layer2}_{t-1} ct−1layer2
- 第N层 LSTM首先初始隐层状态 s 0 l a y e r N s^{layerN}_0 s0layerN和细胞状态 c 0 l a y e r N c^{layerN}_0 c0layerN,然后接收第N-1层的输出 h t − 1 l a r y e r N − 1 h_{t-1}^{laryer N-1} ht−1laryerN−1作为输入,生成最终的 s t − 1 l a y e r N = h t − 1 l a r y e r 2 s^{layerN}_{t-1}=h_{t-1}^{laryer2} st−1layerN=ht−1laryer2和 c t − 1 l a y e r N c^{layerN}_{t-1} ct−1layerN
-
为什么需要多层LSTM?
多层 LSTM 通过增加深度来增强模型的表示能力和复杂度,能够学习到更高阶、更抽象的特征 -
通过控制遗忘门的输出 f t f_t ft来控制梯度,以缓解梯度消失问题,但不能缓解梯度爆炸
5️⃣ 参考
-
理解 LSTM 网络
-
【LSTM长短期记忆网络】3D模型一目了然,带你领略算法背后的逻辑
-
关于RNN的梯度消失&爆炸问题
相关文章:
LSTM(长短期记忆网络)详解
1️⃣ LSTM介绍 标准的RNN存在梯度消失和梯度爆炸问题,无法捕捉长期依赖关系。那么如何理解这个长期依赖关系呢? 例如,有一个语言模型基于先前的词来预测下一个词,我们有一句话 “the clouds are in the sky”,基于&…...

机器学习 贝叶斯公式
这是条件概率的计算公式 𝑃(𝐴|𝐵)𝑃(B|A)𝑃(𝐴)/𝑃(𝐵) 全概率公式 𝑃(𝐵)𝑃(𝐵|𝐴)𝑃(𝐴)&am…...

Scala-注释、标识符、变量与常量-用法详解
Scala Scala-变量和数据类型-用法详解 Scala一、注释二、标识符规范三、变量和常量1. 变量(var)2. 常量(val)3. 类型推断与显式声明4. var 和 val 的区别5. Scala与Java对比Tips: 各位看客老爷万福金安,一键…...

大数据学习14之Scala面向对象--至简原则
1.类和对象 1.1基本概念 面向对象(Object Oriented)是一种编程思想,面向对象主要是把事物给对象化,包括其属性和行为。面向对象编程更贴近实际生活的思想,总体来说面向对象的底层还是面向过程,面向过程抽象…...

docker 安装之 windows安装
文章目录 1: 在Windows安装Docker报19044版本错误的时候,请大家下载4.24.1之前的版本(含4.24.1)2: Desktop-WSL kernel version too low3: docker-compose 安装 (v2.21.0) 1: 在Windows安装Docker报19044版本错误的时候,请大家下载…...

JS 实现游戏流畅移动与按键立即响应
AWSD 按键移动 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style>.box1 {width: 400px;height: 400px;background: yellowgreen;margin: 0 auto;position: relative;}.box2 {width: 50px;height:…...
LabVIEW大数据处理
在物联网、工业4.0和科学实验中,大数据处理需求逐年上升。LabVIEW作为一款图形化编程语言,凭借其强大的数据采集和分析能力,广泛应用于实时数据处理和控制系统中。然而,在面对大数据处理时,LabVIEW也存在一些注意事项。…...

NVR录像机汇聚管理EasyNVR多品牌NVR管理工具视频汇聚技术在智慧安防监控中的应用与优势
随着信息技术的快速发展和数字化时代的到来,安防监控领域也在不断进行技术创新和突破。NVR管理平台EasyNVR作为视频汇聚技术的领先者,凭借其强大的视频处理、汇聚与融合能力,展现出了在安防监控领域巨大的应用潜力和价值。本文将详细介绍Easy…...

海思3403对RTSP进行目标检测
1.概述 主要功能是调过live555 testRTSPClient 简单封装的rtsp客户端库,拉取RTSP流,然后调过3403的VDEC模块进行解码,送个NPU进行目标检测,输出到hdmi,这样保证了开发没有sensor的时候可以识别其它摄像头的视频流&…...

Vue之插槽(slot)
插槽是vue中的一个非常强大且灵活的功能,在写组件时,可以为组件的使用者预留一些可以自定义内容的占位符。通过插槽,可以极大提高组件的客服用和灵活性。 插槽大体可以分为三类:默认插槽,具名插槽和作用域插槽。 下面…...
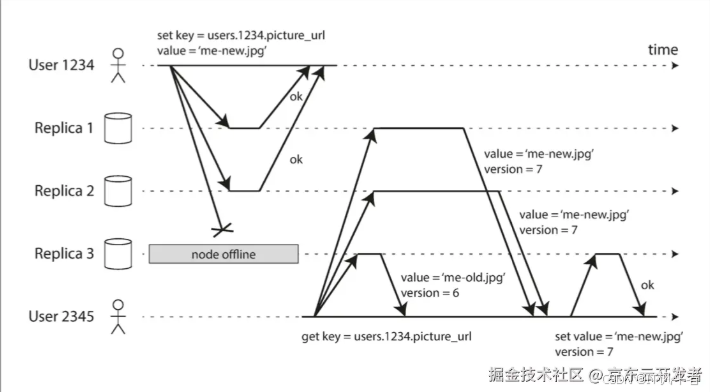
分布式服务高可用实现:复制
分布式服务高可用实现:复制 1. 为什么需要复制 我们可以考虑如下问题: 当数据量、读取或写入负载已经超过了当前服务器的处理能力,如何实现负载均衡?希望在单台服务器出现故障时仍能继续工作,这该如何实现ÿ…...

基于yolov8、yolov5的车型检测识别系统(含UI界面、训练好的模型、Python代码、数据集)
摘要:车型识别在交通管理、智能监控和车辆管理中起着至关重要的作用,不仅能帮助相关部门快速识别车辆类型,还为自动化交通监控提供了可靠的数据支撑。本文介绍了一款基于YOLOv8、YOLOv5等深度学习框架的车型识别模型,该模型使用了…...

机器学习—决定下一步做什么
现在已经看到了很多不同的学习算法,包括线性回归、逻辑回归甚至深度学习或神经网络。 关于如何构建机器学习系统的一些建议 假设你已经实现了正则化线性回归来预测房价,所以你有通常的学习算法的成本函数平方误差加上这个正则化项,但是如果…...

Java Optional详解:避免空指针异常的优雅方式
在 Java 编程中,空指针异常(NullPointerException)一直是困扰开发者的常见问题之一。为了更安全、优雅地处理可能为空的值,Java 8 引入了 Optional 类。Optional 提供了一种函数式的方式来表示一个值可能存在或不存在,…...

SpringBoot开发——整合EasyExcel实现百万级数据导入导出功能
文章目录 一、EasyExcel 框架及特性介绍二、实现步骤1、项目创建及依赖配置(pom.xml)2、项目文件结构3、配置文件(application.yml)4、启动类 Application.java5、配置类 EasyExcelConfig.java6、服务接口定义及实现 ExcelService.java7、控制器类 ExcelController.java8、…...

AcWing 1097 池塘计数 flood fill bfs搜索
代码 #include <bits/stdc.h> using namespace std;const int N 1010, M N * N;typedef pair<int, int> PII;int n, m;char g[N][N]; bool st[N][N]; PII q[M];void bfs (int xx, int yy) {int hh 0, tt -1;q[ tt] {xx, yy};st[xx][yy] true;while (hh <…...

R门 - rust第一课陈天 -内存知识学习笔记
内存 #mermaid-svg-1NFTUW33mcI2cBGB {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-1NFTUW33mcI2cBGB .error-icon{fill:#552222;}#mermaid-svg-1NFTUW33mcI2cBGB .error-text{fill:#552222;stroke:#552222;}#merm…...
java itext后端生成pdf导出
public CustomApiResult<String> exportPdf(HttpServletRequest request, HttpServletResponse response) throws IOException {// 防止日志记录获取session异常request.getSession();// 设置编码格式response.setContentType("application/pdf;charsetUTF-8")…...

信号-3-信号处理
main 信号捕捉的操作 sigaction struct sigaction OS不允许信号处理方法进行嵌套:某一个信号正在被处理时,OS会自动block改信号,之后会自动恢复 同理,sigaction.sa_mask 为捕捉指定信号后临时屏蔽的表 pending什么时候清零&…...
)
38配置管理工具(如Ansible、Puppet、Chef)
每天五分钟学Linux | 第三十八课:配置管理工具(如Ansible、Puppet、Chef) 大家好!欢迎再次来到我们的“每天五分钟学Linux”系列教程。在前面的课程中,我们学习了如何安装和配置邮件服务器。今天,我们将探…...

深入eDP协议栈:从PSR SDP发送到Main Link开关,一次搞懂屏幕自刷新的完整信令流程
深入eDP协议栈:从PSR SDP发送到Main Link开关,一次搞懂屏幕自刷新的完整信令流程 在显示技术的演进中,嵌入式DisplayPort(eDP)协议因其高效能和低功耗特性,已成为移动设备和高端显示器的首选接口。其中&am…...

Omdia:2025年第一季度,东南亚手机市场下滑9%,但厂商利润率正在改善
Omdia最新研究显示,2026年第一季度东南亚智能手机市场出货量同比下降 9%,总量为 2160万部。然而,市场最值得关注的并非出货量下滑,而是平均售价(ASP)的变化:受存储成本上涨影响,2026…...
)
5G手机省电的秘密:一文搞懂NR C-DRX中的Inactivity Timer(附工作流程图解)
5G手机续航优化的核心技术:深入解析C-DRX中的Inactivity Timer机制 当你在咖啡厅刷社交媒体时,是否注意到手机屏幕熄灭后仍能即时收到消息?这种"随叫随到"的体验背后,是5G NR中一项精妙的省电技术——C-DRX(…...

Android BroadcastReceiver 深度解析:原理、实践与面试指南
引言 在 Android 开发中,BroadcastReceiver 是一个核心组件,用于处理系统级事件或应用内通信。它允许应用程序响应来自系统或其他应用的广播消息,如设备开机、网络状态变化或自定义事件。BroadcastReceiver 基于事件驱动的模型,帮助开发者实现松耦合的架构,提升应用的响应…...
)
告别手动调时!用ESP8266+STM32F103ZET6打造自动校时RTC时钟(附完整代码)
基于ESP8266与STM32的智能时钟系统:从NTP同步到RTC校时的全链路实践 在物联网和嵌入式系统开发中,精确的时间同步往往是许多应用的基础需求。无论是数据记录、事件触发还是用户界面显示,一个"永不走时"的时钟系统都能显著提升产品的…...

Taotoken多模型聚合在批量内容生成任务中的稳定性观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合在批量内容生成任务中的稳定性观察 1. 任务背景与挑战 在涉及大规模、长时间运行的内容生成任务中,…...
)
从迷宫到N皇后:用Python手把手带你吃透BFS和DFS(附Educoder通关代码)
从迷宫到N皇后:用Python手把手带你吃透BFS和DFS(附Educoder通关代码) 在算法学习的道路上,BFS(广度优先搜索)和DFS(深度优先搜索)就像是一对性格迥异的双胞胎。一个喜欢稳扎稳打层层…...
)
别再只会if-else了!用STM32状态机实现按键短按、长按、双击(附完整代码)
STM32状态机实战:从零设计支持短按、长按、双击的按键驱动库 在嵌入式开发中,按键处理看似简单,却是最能体现开发者设计功力的场景之一。传统的中断加延时消抖方式虽然能快速实现功能,但随着需求复杂化(比如需要区分短…...

# 让工具自己声明并发安全:我把调度逻辑砍到一行
让工具自己声明并发安全:我把调度逻辑砍到一行 这是 《写完一个 AI 编程助手之后,我才确定 prompt 工程不是重点》 的第四篇。前几篇讲了进程模型和权限系统,这一篇讲并发调度。 代码:[https://github.com/sishenaichipingguo/cod…...
)
Perplexity诗词搜索私有化部署全指南:在本地GPU上运行完整古诗理解Pipeline(含《全唐诗》向量化+平仄校验模块,资源包限今日领取)
更多请点击: https://intelliparadigm.com 第一章:Perplexity诗词歌赋搜索 Perplexity 作为一款以推理深度见长的 AI 搜索引擎,其在中文古典文学领域的检索能力尤为突出。不同于传统关键词匹配,它通过语义理解与上下文建模&#…...