MySQL查询执行(六):join查询
到底可不可以使用join
假设存在如下表结构:
-- 创建表t2
CREATE TABLE `t2` (`id` int(11) NOT NULL,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `a` (`a`)
) ENGINE=InnoDB;-- 向t2写入1000条数据
drop procedure idata;
delimiter ;;
create procedure idata()
begindeclare i int;set i=1;while(i<=1000)doinsert into t2 values(i, i, i);set i=i+1;end while;
end;;
delimiter ;
call idata();-- 创建表t1,写入100条数据
create table t1 like t2;
insert into t1 (select * from t2 where id<=100)Index Nested-Loop Join
查询语句:
select * from t1 straight_join t2 on (t1.a=t2.a);如果直接使用join语句, MySQL优化器可能会选择表t1或t2作为驱动表, 这样会影响我们分析SQL语句的执行过程。
所以, 为了便于分析执行过程中的性能问题, 我改用straight_join让MySQL使用固定的连接方式执行查询, 这样优化器只会按照我们指定的方式去join。
在这个语句里, t1 是驱动表, t2是被驱动表。
来看一下这条语句的explain结果:

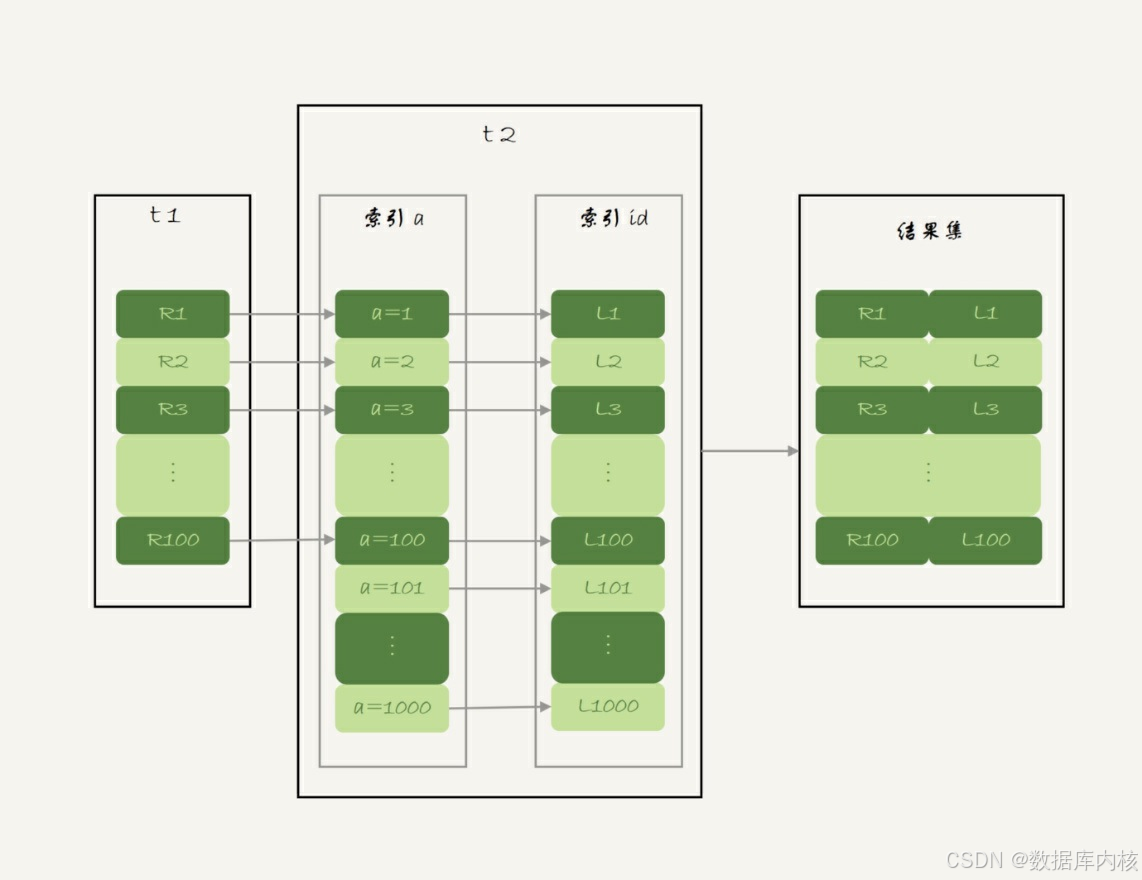
在这条语句里, 被驱动表t2的字段a上有索引, join过程用上了这个索引, 因此这个语句的执行流程是这样的:
- 从表t1中读入一行数据 R。
- 从数据行R中, 取出a字段到表t2里去查找。
- 取出表t2中满足条件的行, 跟R组成一行, 作为结果集的一部分。
- 重复执行步骤1到3, 直到表t1的末尾循环结束。
这个过程是先遍历表t1, 然后根据从表t1中取出的每行数据中的a值, 去表t2中查找满足条件的记录。
且在表t2中查找满足条件的记录时,可以使用t2表的索引,所以称之为索引嵌套循环(IndexNested-Loop Join),简称NLJ。
对应流程图如下:
在这个流程中:
- 对驱动表t1做了全表扫描, 这个过程需要扫描100行。
- 而对于每一行R, 根据a字段去表t2查找, 走的是树搜索过程。由于我们构造的数据都是一一对应的, 因此每次的搜索过程都只扫描一行, 也是总共扫描100行。
- 所以, 整个执行流程, 总扫描行数是200(加上回表)。
假设不使用join,只能用单表查询,则单表查询流程:
1)执行select * from t1, 查出表t1的所有数据, 这里有100行。
2)循环遍历这100行数据:
- 从每一行R取出字段a的值$R.a。
- 执行select * from t2 where a=$R.a。
- 把返回的结果和R构成结果集的一行。
这个查询过程,也是扫描了200行,但是总共执行了101条语句,比直接join多了100次交互。
除此之外,客户端还要自己拼接SQL语句和结果。
显然,直接join比较好。
问:驱动表是如何选择的?
答:在这个join语句执行过程中,驱动表是走全表扫描,而被驱动表是走树搜索。
1)驱动表时间复杂度:假设驱动表的行数是N, 执行过程就要扫描驱动表N行, 然后对于每一行, 到被驱动表上匹配一次。因此时间复杂度为:N + N*被驱动表时间复杂度。
2)被驱动表时间复杂度:假设被驱动表的行数是M。 每次在被驱动表查一行数据, 要先搜索索引a, 再搜索主键索引。 每次搜索一棵树近似复杂度是以2为底的M的对数, 记为log M, 所以在被驱动表上查一行的时间复杂度是 2*log M(加上回表)。
3)整体时间复杂度:N + N*2*log M。
因此,N对扫描行数的影响更大,应当让小表来做驱动表。
在被驱动表可以使用索引的情况下,有如下结论:
1)使用join语句, 性能比强行拆成多个单表执行SQL语句的性能要好。
2)如果使用join语句的话, 需要让小表做驱动表。
Simple Nested-Loop Join
查询语句:
select * from t1 straight_join t2 on (t1.a=t2.b);由于表t2的字段b上没有索引, 因此在使用上图的执行流程时, 每次到t2去匹配的时候, 就要做一次全表扫描。
这样算来, 这个SQL请求就要扫描表t2多达100次, 总共扫描100*1000=10万行。
因此,该算法时间复杂度过高。
Block Nested-Loop Join
基于Simple Nested-Loop Join算法做了改进。
在被驱动表上没有索引可用时,算法流程如下:
1)把表t1的数据读入线程内存join_buffer中, 由于我们这个语句中写的是select *, 因此是把整个表t1放入了内存。
2)扫描表t2, 把表t2中的每一行取出来, 跟join_buffer中的数据做对比, 满足join条件的, 作为结果集的一部分返回。
这个过程流程图如下:
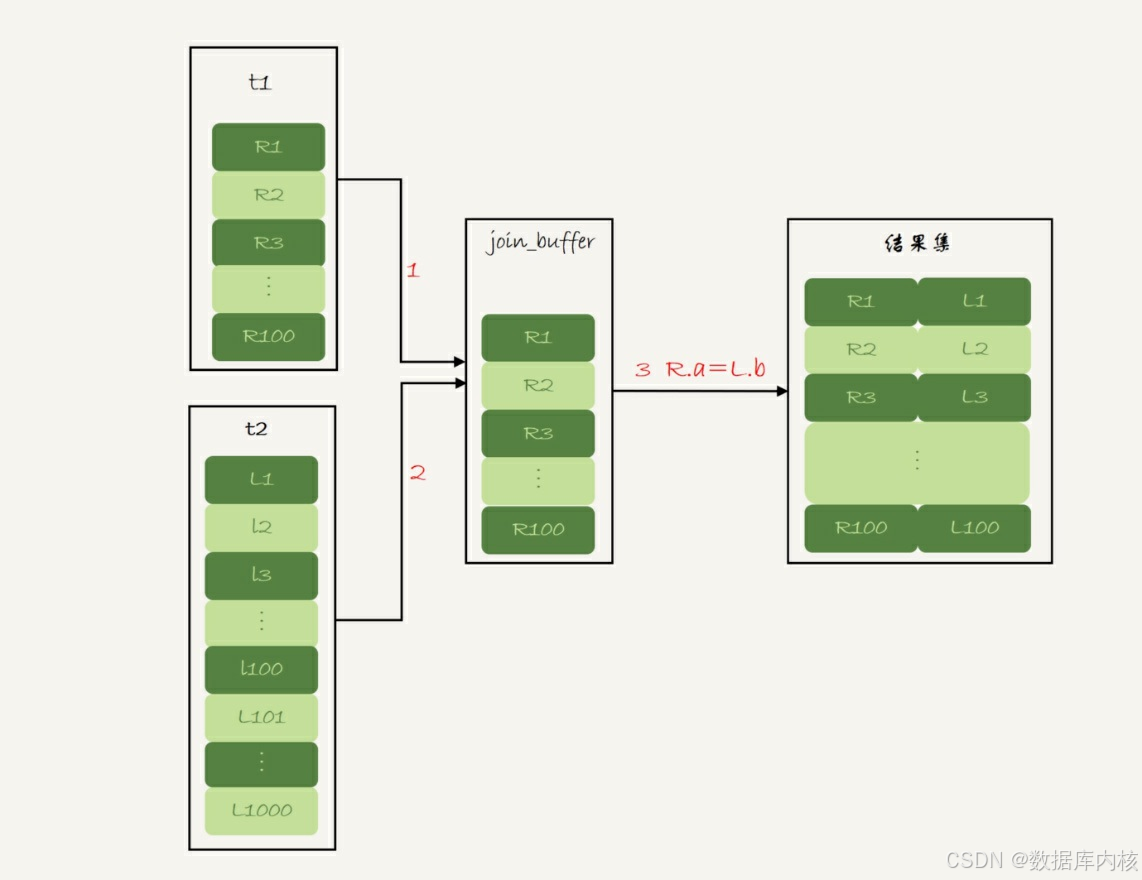
这条SQL语句的explain结果如下所示:

在这个过程中, 对表t1和t2都做了一次全表扫描, 因此总的扫描行数是1100。
由于join_buffer是以无序数组的方式组织的, 因此对表t2中的每一行, 都要做100次判断, 总共需要在内存中做的判断次数是: 100*1000=10万次。
如果使用Simple Nested-Loop Join算法进行查询, 扫描行数也是10万行。 因此, 从时间复杂度上来说, 这两个算法是一样的。 但是, Block Nested-Loop Join算法的这10万次判断是内存操作, 速度上会快很多, 性能也更好。
问1:在这种情况下,应该选择哪个表做驱动表?
答:假设小表的行数是N, 大表的行数是M, 那么在这个算法里:
1)两个表都做一次全表扫描, 所以总的扫描行数是M+N。
2)内存中的判断次数是M*N。
因此,调换这两个算式中的M和N没差别, 因此这时候选择大表还是小表做驱动表, 执行耗时是一样的。
问2:要是表t1是一个大表, join_buffer放不下怎么办呢?
答:join_buffer的大小是由参数join_buffer_size设定的, 默认值是256k。 如果放不下表t1的所有数据话, 策略很简单, 就是分段放。 我把join_buffer_size改成1200, 再执行:
select * from t1 straight_join t2 on (t1.a=t2.b);执行过程就变成了:
1)扫描表t1, 顺序读取数据行放入join_buffer中, 放完第88行join_buffer满了, 继续第2步。
2)扫描表t2, 把t2中的每一行取出来, 跟join_buffer中的数据做对比, 满足join条件的, 作为结果集的一部分返回。
3)清空join_buffer。
4)继续扫描表t1, 顺序读取最后的12行数据放入join_buffer中, 继续执行第2步。
执行流程图如下:
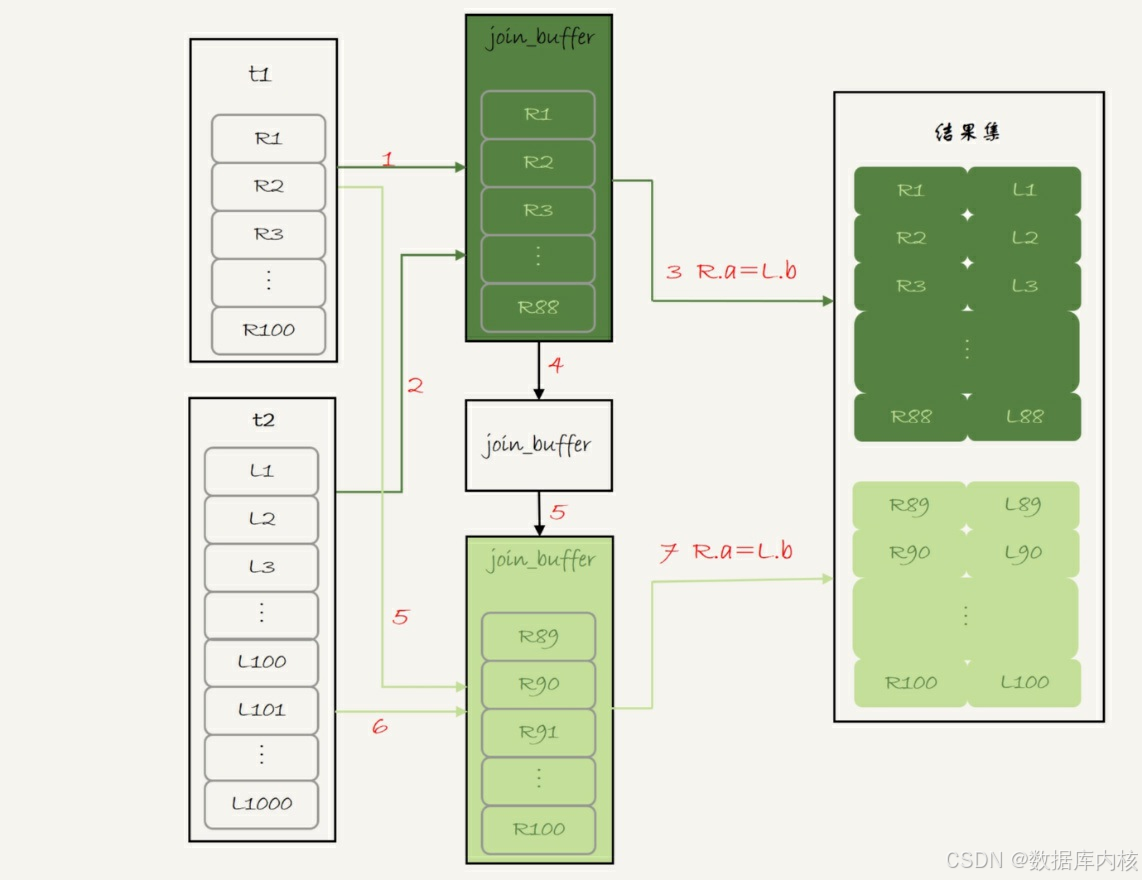
这个流程才体现出了这个算法名字中“Block”的由来, 表示“分块去join”。
可以看到, 这时候由于表t1被分成了两次放入join_buffer中, 导致表t2会被扫描两次。 虽然分成两次放入join_buffer, 但是判断等值条件的次数还是不变的, 依然是(88+12)*1000=10万次。
思考:这种情况下,驱动表该如何选择呢?
假设, 驱动表的数据行数是N, 需要分K段才能完成算法流程, 被驱动表的数据行数是M。
这里的K不是常数, N越大K就会越大, 因此把K表示为λ*N, 显然λ的取值范围是(0,1)。
所以, 在这个算法的执行过程中:
1)扫描行数是 N+λ*N*M。
2)内存判断 N*M次。
显然, 内存判断次数是不受选择哪个表作为驱动表影响的。 而考虑到扫描行数, 在M和N大小确定的情况下, N小一些, 整个算式的结果会更小。
因此,应该让小表当驱动表。
影响扫描行数的因素:
1)K(λ*N)越小,被驱动表的全表扫描次数就越少。
2)当N固定的时候,join_buffer_size越大,一次可以放入的行数越多,K也就越小,被驱动表的扫描次数也就越少。
所以,当join语句很慢的时候,可以是当调大join_buffer_size。
小结:思考题
思考1:能不能使用join语句?
1)如果可以使用IndexNested-Loop Join算法, 则可以使用join。
2)如果使用Block Nested-Loop Join算法, 扫描行数就会过多。 尤其是大表的join,这样可能要扫描被驱动表很多次,会占用大量的系统资源,尽量不使用join。
所以,在判断要不要使用join语句时,可以通过观察explain结果里面,Extra字段里面有没有出现“Block Nested Loop”字样。
思考2:如果要使用join, 应该选择大表做驱动表还是选择小表做驱动表?
1)如果是IndexNested-Loop Join算法, 应该选择小表做驱动表。
2)如果是Block Nested-Loop Join算法:
- 在join_buffer_size足够大的时候, 是一样的。
- 在join_buffer_size不够大的时候(这种情况更常见) , 应该选择小表做驱动表。
所以,应该尽可能的都是用小表做驱动表。
思考3:什么样的表算是小表?
查询语句如下:
select * from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=50;
select * from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=50;如果用第二个语句的话, join_buffer只需要放入t2的前50行, 显然是更好的。 所以这里, “t2的前50行”是那个相对小的表, 也就是“小表”。
另一组查询语句:
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;这个例子里, 表t1 和 t2都是只有100行参加join。 但是, 这两条语句每次查询放入join_buffer中的数据是不一样的:
1)表t1只查字段b, 因此如果把t1放到join_buffer中, 则join_buffer中只需要放入b的值。
2)表t2需要查所有的字段, 因此如果把表t2放到join_buffer中的话, 就需要放入三个字段id、 a和b。
此时,应该选择表t1作为驱动表。 也就是说在这个例子里, “只需要一列参与join的表t1”是那个相对小的表。
结论:在决定哪个表做驱动表的时候, 应该是两个表按照各自的条件过滤, 过滤完成之后, 计算参与join的各个字段的总数据量, 数据量小的那个表, 就是“小表”, 应该作为驱动表。
思考4:如果被驱动表是一个大表,并且是一个冷数据表,除了查询过程中可能会导致IO压力大以外,你觉得对这个MySQL服务还有什么更严重的影响吗?
答:如果一个使用BNL算法的join语句,多次扫描一个冷表,而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候,把冷表的数据页移到LRU链表头部。
1)如果冷表的数据量小于整个Buffer Pool的3/8,能够完全放入old区域,则不会影响young区域。
2)如果这个冷表很大,则业务正常访问的数据页,没有机会进入young区域。
解决办法:调整join_buffer_size,减少对被驱动表的扫描次数。
join语句怎么优化
针对Index Nested-Loop Join(NLJ)和Block Nested-Loop Join(BNL)算法都存在一定的优化空间。
假设存在表t1、t2:
-- 创建表t1,t2
create table t1(id int primary key,a int, b int, index(a));
create table t2 like t1;-- t1写入1000数据,字段a值为 1001-id;
-- t2写入100w数据,字段a值等于id值;
drop procedure idata;
delimiter ;;
create procedure idata()
begindeclare i int;set i=1;while(i<=1000)doinsert into t1 values(i, 1001-i, i);set i=i+1;end while;set i=1;while(i<=1000000)doinsert into t2 values(i, i, i);set i=i+1;end while;end;;
delimiter ;call idata();Multi-Range Read优化
Multi-Range Read优化又称MRR,该优化的主要目的是尽量使用顺序读盘。
思考:回表过程是一行行地查数据,还是批量地查数据?
答:主键索引是一棵B+树,在B+树上,每次只能根据一个主键id查到一行数据,因此,回表肯定是一行行搜索主键索引的。
假设执行如下语句:
select * from t1 where a>=1 and a<=100;基本流程如下:
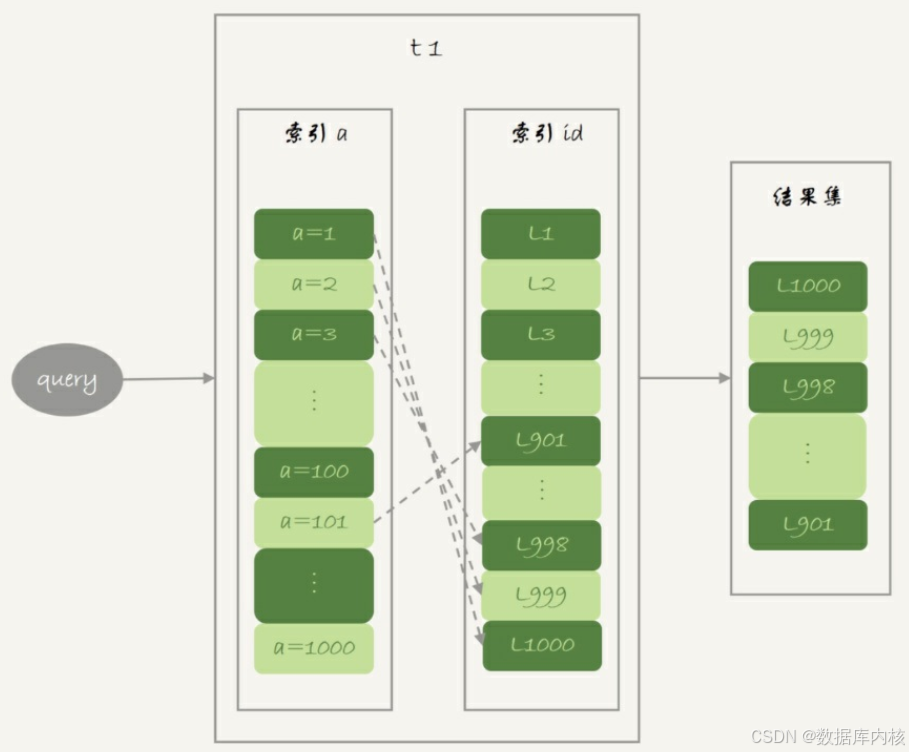
如果随着a的值递增顺序查询的话, id的值就变成随机的, 那么就会出现随机访问, 性能相对较差。 虽然“按行查”这个机制不能改, 但是调整查询的顺序, 还是能够加速的。
因为大多数的数据都是按照主键递增顺序插入得到的, 所以我们可以认为, 如果按照主键的递增顺序查询的话, 对磁盘的读比较接近顺序读, 能够提升读性能。
这也正是MRR优化的设计思路。此时,语句的执行流程:
1)根据索引a, 定位到满足条件的记录, 将id值放入read_rnd_buffer中。
2)将read_rnd_buffer中的id进行递增排序。
3)排序后的id数组, 依次到主键id索引中查记录, 并作为结果返回。
注1:read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。 如果步骤1中, read_rnd_buffer放满了, 就会先执行完步骤2和3, 然后清空read_rnd_buffer。 之后继续找索引a的下个记录, 并继续循环。
注2:如果想稳定地使用MRR优化的话,需要设置set optimizer_switch="mrr_cost_based=off"(官方文档的说法, 是现在的优化器策略, 判断消耗的时候, 会更倾向于不使用MRR, 把mrr_cost_based设置为off, 就是固定使用MRR了。)
使用MRR优化的执行流程和explain结果:
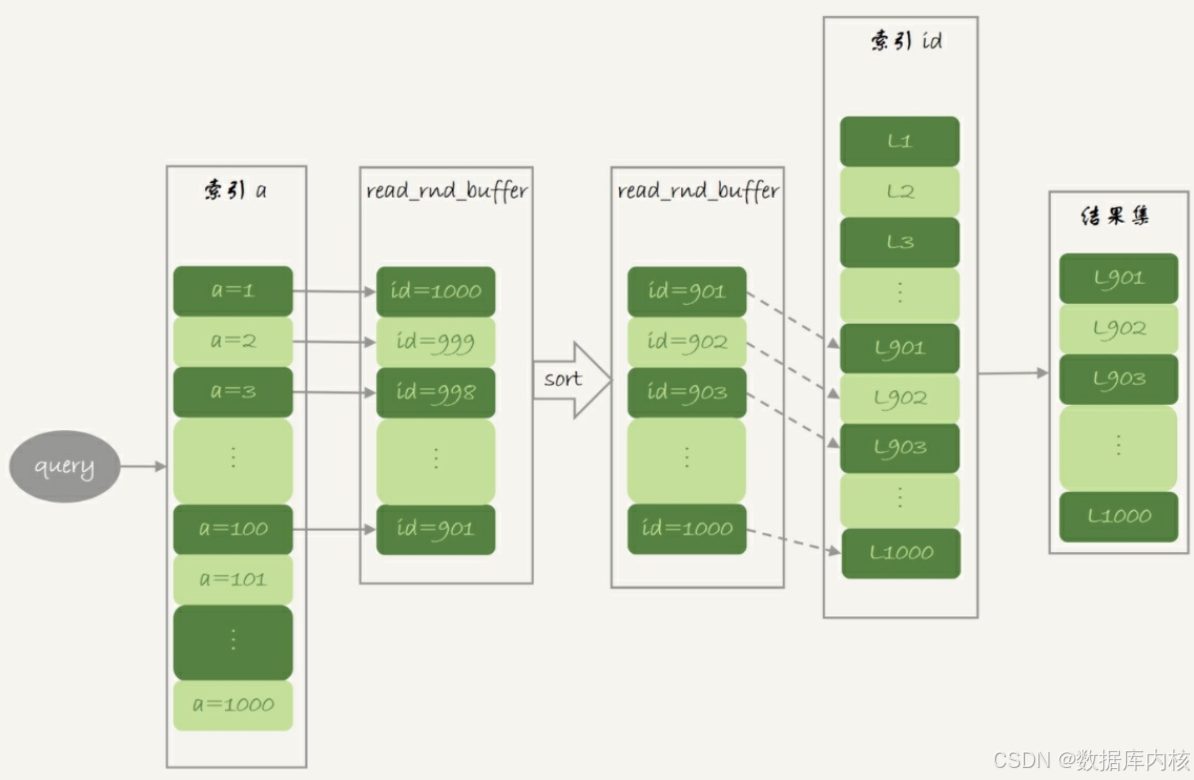

从图的explain结果中, 我们可以看到Extra字段多了Using MRR, 表示的是用上了MRR优化。而且, 由于我们在read_rnd_buffer中按照id做了排序, 所以最后得到的结果集也是按照主键id递增顺序的, 也就是与未使用MRR的结果集中行的顺序相反。
MRR能够提升性能的核心在于, 这条查询语句在索引a上做的是一个范围查询(也就是说, 这是一个多值查询) , 可以得到足够多的主键id。 这样通过排序以后, 再去主键索引查数据, 才能体现出“顺序性”的优势。
Batched Key Access
Batched Key Access算法是MySQL 5.6版本后开始引入的。
Batched Key Access优化又称BKA,该算法是针对BNL算法做出的优化。
NLJ算法流程图:
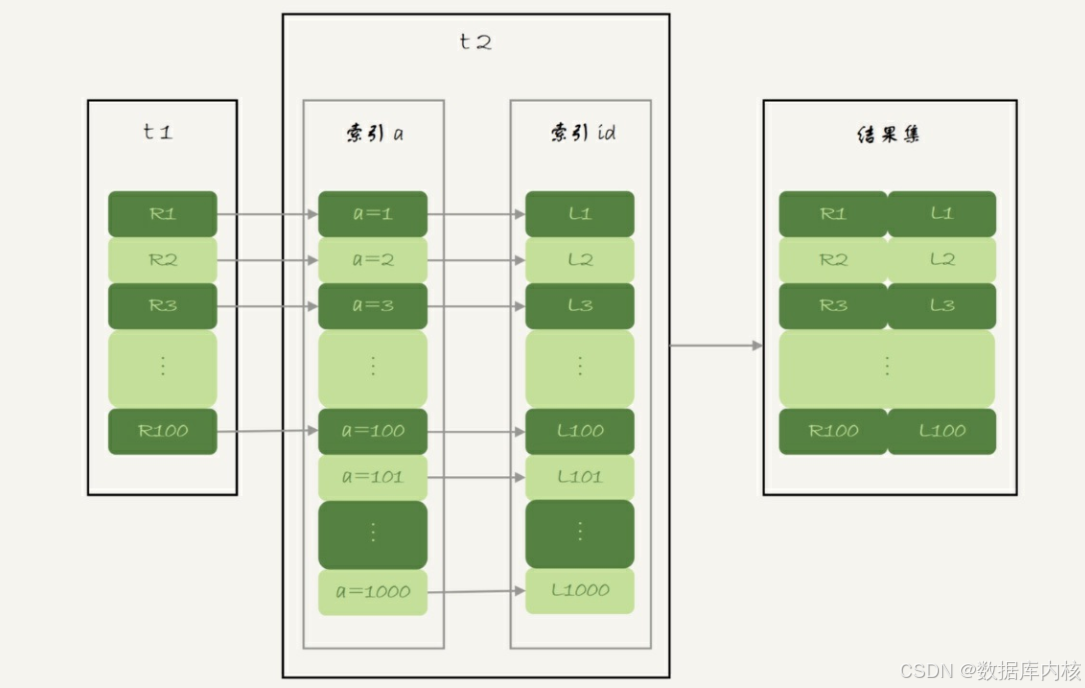
NLJ算法执行的逻辑是: 从驱动表t1, 一行行地取出a的值, 再到被驱动表t2去做join。 也就是说, 对于表t2来说, 每次都是匹配一个值。 这时, MRR的优势就用不上了。
问1:如何一次性地多传一些值给表t2呢?
答:从表t1中一次性多拿一些行出来,先放到一个临时内存(join_buffer)。即BNL中用到的join_buffer。
NLJ算法优化后的BKA算法流程:
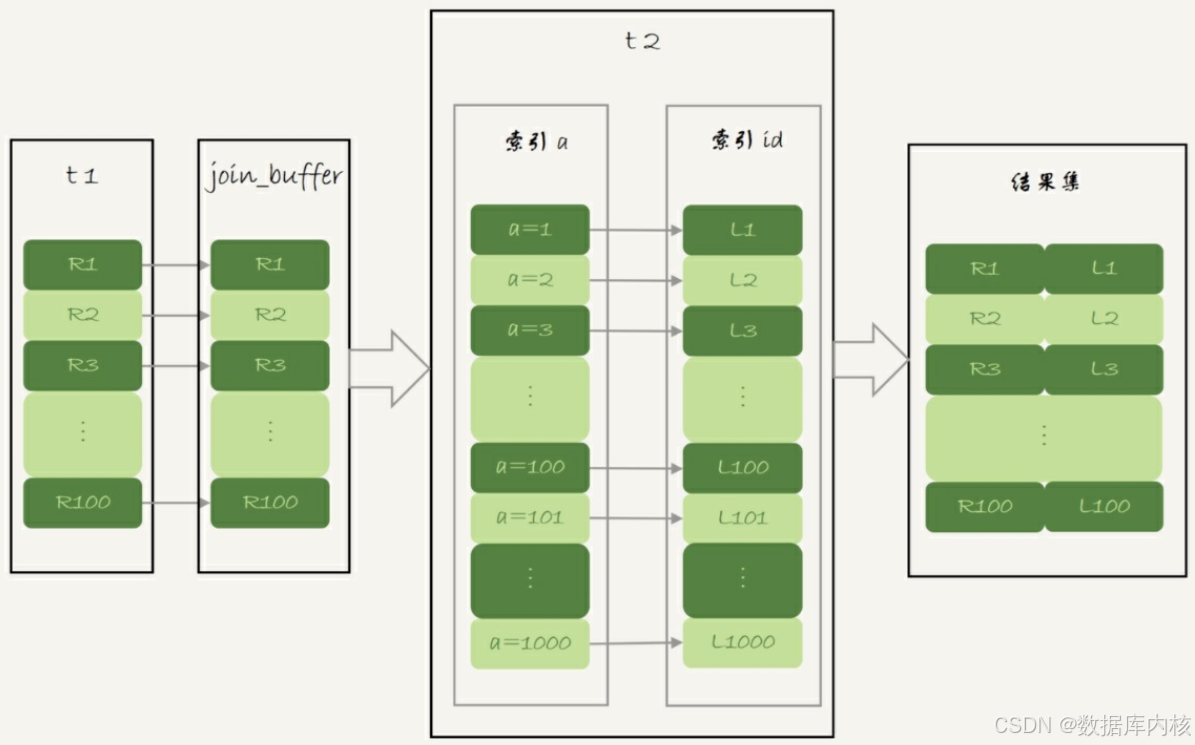
图中, 我在join_buffer中放入的数据是P1~P100, 表示的是只会取查询需要的字段。 当然, 如果join buffer放不下P1~P100的所有数据, 就会把这100行数据分成多段执行上图的流程。
感觉优化不是很明显!!!
问2:BKA算法要怎么启用呢?
答:如果要使用BKA优化算法的话, 你需要在执行SQL语句之前, 先设置:
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';其中, 前两个参数的作用是要启用MRR。 这么做的原因是, BKA算法的优化要依赖于MRR。
BNL算法的性能问题
影响Buffer Pool正常工作的两种情景:
1)如果一个使用BNL算法的join语句, 多次扫描一个冷表, 而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候, 把冷表的数据页移到LRU链表头部。(这种情况对应的, 是冷表的数据量小于整个Buffer Pool的3/8, 能够完全放入old区域的情况。)如果这个冷表很大,就会导致业务正常访问的数据页,没有机会进入young区域。因为冷表循环读磁盘和淘汰内存页,导致业务正常访问的数据页还没来得及进入young区域就被淘汰了。
2)由于join语句在循环读磁盘和淘汰内存页,进入old区域的数据页,很可能在1s内就被淘汰了。这样就会导致这个MySQL实例的Buffer Pool在这段时间内,young区域的数据页没有被合理地淘汰。
BNL算法对系统的影响主要包括以下三个方面:
1)可能会多次扫描被驱动表,占用IO资源。
2)判断join条件需要执行N*M次对比(N、M分别是两张表的行数),如果是大表就会占用非常多的CPU资源。
3)可能会导致Buffer Pool的热数据被淘汰,影响内容命中率。
我们执行语句之前, 需要通过理论分析和查看explain结果的方式, 确认是否要使用BNL算法。 如果确认优化器会使用BNL算法, 就需要做优化。 优化的常见做法是, 给被驱动表的join字段加上索引, 把BNL算法转成BKA算法。
BNL转BKA
一些情况下,可以直接在被驱动表上建立索引,这时就可以直接把BNL转成BKA算法了。
但是,有时也会遇到一些不适合在被驱动表上建索引的情况。如:
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;表t2中有100万行数据,但经过where条件过滤后,需要参与join的只有2000行数据。如果这条语句同时又是一个低频的SQL语句,那么再为这个语句在表t2的字段b上创建一个索引就很浪费了。
使用BNL算法进行join,语句执行流程如下:
1)把表t1的所有字段取出来, 存入join_buffer中。 这个表只有1000行, join_buffer_size默认值是256k, 可以完全存入。
2)扫描表t2, 取出每一行数据跟join_buffer中的数据进行对比:
- 如果不满足t1.b=t2.b, 则跳过。
- 如果满足t1.b=t2.b, 再判断其他条件, 也就是是否满足t2.b处于[1,2000]的条件, 如果是, 就作为结果集的一部分返回, 否则跳过。
对于表t2的每一行, 判断join是否满足的时候, 都需要遍历join_buffer中的所有行。 因此判断等值条件的次数是1000*100万=10亿次, 这个判断的工作量很大。

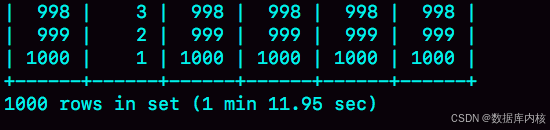
从图中可以看到,explain结果里Extra字段显示使用了BNL算法。 在我的测试环境里, 这条语句需要执行1分11秒。
问:既然在t2的字段b上创建索引浪费资源,但不创建索引的话这个语句的等值条件要判断10亿次,也是浪费资源。有两全其美的方法么?
答:可以使用临时表。使用临时表的大致思路:
1)把表t2中满足条件的数据放在临时表tmp_t中。
2)为了让join使用BKA算法, 给临时表tmp_t的字段b加上索引。
3)让表t1和tmp_t做join操作。
此时, 对应的SQL语句的写法如下:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b);语句序列的执行效果:

可以看到, 整个过程3个语句执行时间的总和还不到1秒, 相比于前面的1分11秒, 性能得到了大幅提升。
这个过程的消耗:
1)执行insert语句构造temp_t表并插入数据的过程中, 对表t2做了全表扫描, 这里扫描行数是100万。
2)之后的join语句, 扫描表t1, 这里的扫描行数是1000; join比较过程中, 做了1000次带索引的查询。 相比于优化前的join语句需要做10亿次条件判断来说, 这个优化效果还是很明显的。
不论是在原表上加索引, 还是用有索引的临时表, 我们的思路都是让join语句能够用上被驱动表上的索引, 来触发BKA算法, 提升查询性能。
扩展-hash join
思考:如果join_buffer里面维护的不是一个无序数组,而是一个哈希表的话,那么就不是10亿次判断,而是100万次hash查找。那么整条语句执行速度就快很多了吧?
答:是的。
这个优化思路,实际上可以在业务端实现,实现流程如下:
1)select * from t1;取得表t1的全部1000行数据, 在业务端存入一个hash结构, 比如C++里的set、 PHP的dict这样的数据结构。
2)select * from t2 where b>=1 and b
3)把这2000行数据, 一行一行地取到业务端, 到hash结构的数据表中寻找匹配的数据。 满足匹配的条件的这行数据, 就作为结果集的一行。
理论上,这个过程闭临时表方案的执行速度还要快一些。
小结:思考题
优化方法总结:
1)BKA优化是MySQL已经内置支持的, 建议你默认使用。
2)BNL算法效率低, 建议你都尽量转成BKA算法。 优化的方向就是给被驱动表的关联字段加上索引。
3)基于临时表的改进方案, 对于能够提前过滤出小数据的join语句来说, 效果还是很好的。
4)MySQL目前的版本还不支持hash join(MySQL 8.0.18开始支持hash join), 但你可以配合应用端自己模拟出来, 理论上效果要好于临时表的方案。
思考:对于下面这三个表的join语句,如果改写成straight_join,要怎么指定连接顺序,以及怎么给这三个表创建索引?
select * from t1 join t2 on(t1.a=t2.a) join t3 on (t2.b=t3.b) where t1.c>=X and t2.c>=Y and t3.c>=Z;第一原则是要尽量使用BKA算法。 需要注意的是, 使用BKA算法的时候, 并不是“先计算两个表join的结果, 再跟第三个表join”, 而是直接嵌套查询的。
具体实现是: 在t1.c>=X、 t2.c>=Y、 t3.c>=Z这三个条件里, 选择一个经过过滤以后, 数据最少的那个表, 作为第一个驱动表。 此时, 可能会出现如下两种情况。
1)如果选出来是表t1或者t3, 那剩下的部分就固定了。
- 如果驱动表是t1, 则连接顺序是t1->t2->t3, 要在被驱动表字段创建上索引, 也就是t2.a 和t3.b上创建索引。
- 如果驱动表是t3, 则连接顺序是t3->t2->t1, 需要在t2.b 和 t1.a上创建索引。
注:同时还需要在第一个驱动表的字段c上创建索引。
2)如果选出来的第一个驱动表是表t2的话, 则需要评估另外两个条件的过滤效果。
总之, 整体的思路就是, 尽量让每一次参与join的驱动表的数据集, 越小越好, 因为这样我们的驱动表就会越小。
相关文章:
MySQL查询执行(六):join查询
到底可不可以使用join 假设存在如下表结构: -- 创建表t2 CREATE TABLE t2 (id int(11) NOT NULL,a int(11) DEFAULT NULL,b int(11) DEFAULT NULL,PRIMARY KEY (id),KEY a (a) ) ENGINEInnoDB;-- 向t2写入1000条数据 drop procedure idata; delimiter ;; create pr…...

python习题练习
python习题 编写一个简单的工资管理程序系统可以管理以下四类人:工人(worker)、销售员(salesman)、经理(manager)、销售经理(salemanger)所有的员工都具有员工号,工资等属性,有设置姓名,获取姓名,获取员工号,计算工资等…...
:一条更新语句是如何执行的)
MySQL高级(二):一条更新语句是如何执行的
执行步骤 1. 解析 SQL 语句 MySQL 首先会解析你输入的 UPDATE 语句。解析器会检查语法是否正确,并将 SQL 语句转化为内部的数据结构(通常是语法树)。 示例 SQL 语句: UPDATE employees SET salary 5000 WHERE department Sa…...

在 Ubuntu 18.04 中搭建和测试 DNS 服务器
在 Ubuntu 18.04 中搭建和测试 DNS 服务器可以通过安装和配置 BIND(Berkeley Internet Name Domain)来实现。以下是详细的步骤: 1. 安装 BIND 打开终端并运行以下命令来安装 BIND: sudo apt update sudo apt install bind9 bin…...

算法学习第一弹——C++基础
早上好啊,大佬们。来看看咱们这回学点啥,在前不久刚出完C语言写的PTA中L1的题目,想必大家都不过瘾,感觉那些题都不过如此,所以,为了我们能更好的去处理更难的题目,小白兔决定奋发图强࿰…...

javaWeb小白项目--学生宿舍管理系统
目录 一、检查并关闭占用端口的进程 二、修改 Tomcat 的端口配置 三、重新启动 Tomcat 一、javaw.exe的作用 二、结束javaw.exe任务的影响 三、如何判断是否可以结束 结尾: 这个错误提示表明在本地启动 Tomcat v9.0 服务器时遇到了问题,原因是所需…...

如何优化Elasticsearch的查询性能?
优化Elasticsearch查询性能可以从以下几个方面进行: 合理设计索引和分片: 确保设置合理的分片和副本数,考虑数据量、节点数和集群大小。根据数据量和节点数量调整分片数量,避免使用过多分片,因为每个分片都需要额外的…...
蓝桥杯每日真题 - 第12天
题目:(数三角) 题目描述(14届 C&C B组E题) 解题思路: 给定 n 个点的坐标,计算其中可以组成 等腰三角形 的三点组合数量。 核心条件:等腰三角形的定义是三角形的三条边中至少有…...

从H264视频中获取宽、高、帧率、比特率等属性信息
背景 最近整理视频编解码的代码,早前在jetson上封装了jetson multimedia作为视频编解码的类,供其他同事和其他组使用,但该解码接口有一个问题,无法首先获取视频宽高信息,更无法直接获取视频的帧率、比特率等信息。 解…...

Cyberchef配合Wireshark提取并解析TCP/FTP流量数据包中的文件
前一篇文章中讲述了如何使用cyberchef提取HTTP/TLS数据包中的文件,详见《Cyberchef配合Wireshark提取并解析HTTP/TLS流量数据包中的文件》,链接这里,本文讲述下如何使用cyberchef提取FTP/TCP数据包中的文件。 FTP 是最为常见的文件传输协议,和HTTP协议不同的是FTP协议传输…...

Nginx中使用keepalive实现保持上游长连接实现提高吞吐量示例与测试
场景 HTTP1 .1之后协议支持持久连接,也就是长连接,优点在于在一个TCP连接上可以传送多个HTTP请求和响应, 减少了建立和关闭连接的消耗和延迟。 如果我们使用了nginx去作为反向代理或者负载均衡,从客户端过来的长连接请求就会被…...

深度学习-卷积神经网络CNN
案例-图像分类 网络结构: 卷积BN激活池化 数据集介绍 CIFAR-10数据集5万张训练图像、1万张测试图像、10个类别、每个类别有6k个图像,图像大小32323。下图列举了10个类,每一类随机展示了10张图片: 特征图计算 在卷积层和池化层结束后, 将特征…...

241114.学习日志——[CSDIY] [Cpp]零基础速成 [03]
CSDIY:这是一个非科班学生的努力之路,从今天开始这个系列会长期更新,(最好做到日更),我会慢慢把自己目前对CS的努力逐一上传,帮助那些和我一样有着梦想的玩家取得胜利!࿰…...

大模型研究报告 | 2024年中国金融大模型产业发展洞察报告|附34页PDF文件下载
随着生成算法、预训练模型、多模态数据分析等AI技术的聚集融合,AIGC技术的实践效用迎来了行业级大爆发。通用大模型技术的成熟推动了新一轮行业生产力变革,在投入提升与政策扶植的双重作用下,以大模型技术为底座、结合专业化金融能力的金融大…...

数据库SQL——什么是实体-联系模型(E-R模型)?
目录 什么是实体-联系模型? 1.实体集 2.联系集 3.映射基数 一对一(1:1) 一对多(1:n) 多对一(n:1) 多对多(m:n) 全部参与: 4.主码 弱实体集…...

在 MySQL 8.0 中,SSL 解密失败,在使用 SSL 加密连接时出现了问题
在 MySQL 8.0 中,SSL 解密失败通常指的是在使用 SSL 加密连接时出现了问题,导致无法建立加密通信。这个问题可能由多种原因引起,下面是一些常见的原因和排查方法: 1. 证书配置问题 确保您在 MySQL 配置中使用了正确的 SSL 证书和…...

React Native 全栈开发实战班 - 第四部分:用户界面进阶之动画效果实现
在移动应用中,动画效果 是提升用户体验的重要手段。合理的动画设计可以增强应用的交互性、流畅性和视觉吸引力。React Native 提供了多种实现动画的方式,包括内置的 Animated API、LayoutAnimation 以及第三方库(如 react-native-reanimated&…...

【CICD】GitLab Runner 和执行器(Executor
GitLab Runner 和执行器(Executor)是 GitLab CI/CD 管道中的两个重要组成部分。理解它们之间的关系有助于更好地配置和使用 CI/CD 流水线。runer是gitlab的ci-agent对接gitlab,而执行器是接受runer下发的ci的任务来干活的。也就是说gitrunner…...

实用教程:如何无损修改MP4视频时长
如何在UltraEdit中搜索MP4文件中的“mvhd”关键字 引言 在视频编辑和分析领域,有时我们需要深入到视频文件的底层结构中去。UltraEdit(UE)和UEStudio作为强大的文本编辑器,允许我们以十六进制模式打开和搜索MP4文件。本文将指导…...

mysqldump命令搭配source命令完成数据库迁移备份
mysqldump 命令使用 需保证mysqld在运行中, 这个命令的目的是将数据库导出到文件中,例如 mysqldump -uusername -ppassword database > db.sql 注意该命令不是在MySQL客户端(即MySQL命令行)执行的,而是在系统命…...

2026年企微会话存档涨价后,怎么买最划算?
2026 年企业微信官方会话存档价格大幅上调,基础费用直接翻倍。不少依赖会话存档做合规、质检的企业,陷入了 “合规刚需不能丢,成本暴涨扛不住” 的两难。其实,放弃纯官方接口自研,转向高性价比第三方服务商,…...

2026年高清家用投影仪推荐:明基W系列领衔
一、前言:高清家用投影仪的核心,在于4K清晰度与真实色彩还原2026年的家用投影仪市场,“高清”早已不是简单的1080P,而是全面迈入4K UHD时代。但真正意义上的“高清家用投影仪”,不仅需要830万像素的真4K分辨率…...

MCP39F501电能计量芯片:高精度单相计量方案与工程实践详解
1. 项目概述:为什么我们需要一颗专用的电能计量芯片?在智能家居、工业物联网和新能源领域,精确测量交流电(AC)的用电参数——比如电压、电流、功率、电能——是底层最核心的需求之一。你可能觉得,用个高精度…...

PolyHook 2.0导入导出表钩子:IatHook和EatHook的10个核心技巧
PolyHook 2.0导入导出表钩子:IatHook和EatHook的10个核心技巧 【免费下载链接】PolyHook_2_0 C20, x86/x64 Hooking Libary v2.0 项目地址: https://gitcode.com/gh_mirrors/po/PolyHook_2_0 PolyHook 2.0是一个功能强大的C20 x86/x64钩子库,提供…...

告别数据壁垒:用ArcGIS Editor for OSM插件,5分钟搞定OSM数据下载与本地编辑
告别数据壁垒:用ArcGIS Editor for OSM插件,5分钟搞定OSM数据下载与本地编辑 在空间数据分析领域,OpenStreetMap(OSM)作为开放的全球地理数据库,已成为许多GIS从业者的重要数据来源。然而,传统O…...

别再用理想模型了!用TINA-TI仿真μA741驱动容性负载,实测振铃现象与消除方案
别再用理想模型了!用TINA-TI仿真μA741驱动容性负载,实测振铃现象与消除方案 在模拟电路设计中,运放驱动容性负载时的稳定性问题堪称工程师的"头号公敌"。许多初学者在仿真阶段使用理想模型验证电路功能时一切正常,却在…...
)
告别手动传Token!用JMeter的JSON Extractor搞定接口自动化登录(附实战配置)
告别手动传Token!用JMeter的JSON Extractor实现无缝接口自动化登录 在接口测试的世界里,登录态管理就像一场永无止境的接力赛——每次请求都需要准确传递Token这个"接力棒"。传统的手工复制粘贴Token不仅效率低下,更是自动化测试流…...

终极Windows风扇控制指南:5分钟掌握智能调速告别噪音烦恼
终极Windows风扇控制指南:5分钟掌握智能调速告别噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份
英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想要在英雄联盟中展示与众不同的个人资料吗?LeaguePrank是一款开源免费的英雄联盟个性化工具&am…...

std::accumulate算法深度解析:从求和到通用折叠,解锁STL隐藏的瑞士军刀
1. 重新认识std::accumulate:不只是求和工具 第一次接触std::accumulate时,大多数人都是从求和开始的。确实,这个算法默认行为就是对范围内的元素进行累加。但如果你只把它当作一个高级计算器,那就太小看这个STL中的"瑞士军刀…...